Two models are better than one. Experience Yandex.Translate
Once we already talked about how machine translation appeared and developed. Since then, another historical event has happened - neural networks and deep learning have finally conquered it. Among the tasks of natural language processing (Natural Language Processing, NLP), machine translation was one of the first to receive a strict statistical basis - as early as the early 1990s. But in the field of deep learning, he was a relatively late participant. In this post, we, the Yandex machine translation team, are discussing why it took so much time and what new opportunities were opened by machine translation based on neural networks.
We will also be happy to answer questions at the Yandex “From the Inside: From Algorithms to Measurements - in Translator, Alice and Search” meeting on March 1 (you can register or ask a question in the broadcast chat).
')
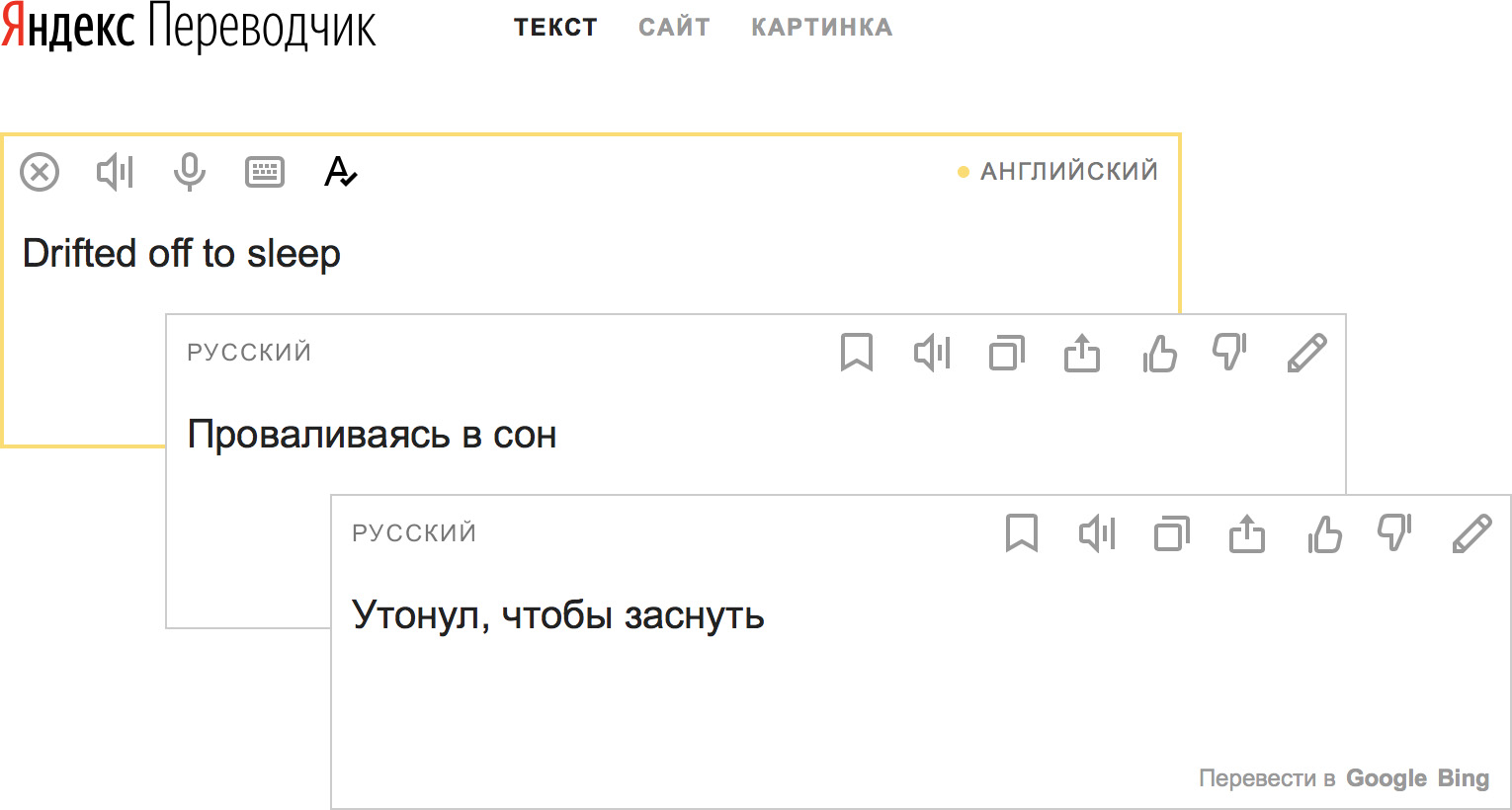
Just three years ago, almost all serious industrial and research machine translation systems were built using a conveyor of statistical models (“phrasal machine translation,” FMP), in which neural networks did not participate. Phrasal machine translation for the first time made machine translation available to the mass user in the early 2000s. With enough data and enough computing resources, the FMF allowed developers to create translation systems that basically gave an idea of the meaning of the text, but were full of grammatical and sometimes semantic errors.
The conveyor of statistical models, which was used to build FMP systems, is actually quite intricate. Based on leveled teaching sentences — for example, translations of Russian news articles into English — the system builds a statistical model that tries to “explain” each of the words of the target language with the words of the source language using “hidden” variables known as word alignments. ). The idea is intuitive, and the math (maximizing expectations, the EM algorithm) is pretty good .
An iterative EM algorithm — when at each step we make the best guess as to which source words correspond to which target words, and then these “guesses” are used as training data for the next iteration — quite similar to the approach we could apply to decoding menu in a foreign language. The problem is that it is based on separate words, and word-for-word translation is often impossible.
Word alignment models introduce various assumptions about independence in order to simplify the task of too large computational complexity (deciding which of the 2 ^ {JI} possible ways to align words in the original sentence of length I with the words in the target sentence of length J) to more acceptable sizes . For example, a hidden Markov model can be developed to solve this problem with complexity O (I ^ 2J).
Word-based models have never shown particularly good results. And everything looked rather sad until a method was proposed for constructing a translation model at the phrase level , on top of the alignment of words. After that, machine translation began to be used on the Internet - for translating websites in foreign languages or simply as an inexhaustible source of inspiration for memes .
FMP uses word alignment matrices to determine which pairs of phrases in a pair of sentences can serve as translations for each other. The resulting table of phrases becomes the main factor in the linear model, which, together with components such as the language model, is used to generate and select potential translations.

FMP very well remembers phrases from a parallel body of texts. Theoretically, one single example is enough for him to learn a phrasal translation, if only the words in this example are relatively well aligned. Although this may give the impression of a fluent language, in fact, the system does not really understand what it does.
The parameter space of the FMP system is huge, but the parameters themselves are extremely simple - “what is the probability of seeing this target phrase as a translation of this source phrase?” When the model is used for translation, each source sentence is divided into phrases that the system has seen before, and these phrases are translated independently of each other. from friend. Unfortunately, when these phrases are stitched together, inconsistencies between them turn out to be too noticeable.

Researchers engaged in speech recognition or images, have long been thinking about how to encode data, because a continuous signal is difficult to imagine in the discrete world of computers. But working on the processing of natural language is not particularly worried about this. It seemed pretty simple - you can replace the words with integer identifiers and index the model parameters with these numbers. This is exactly what N-gram language models and FMP systems do.
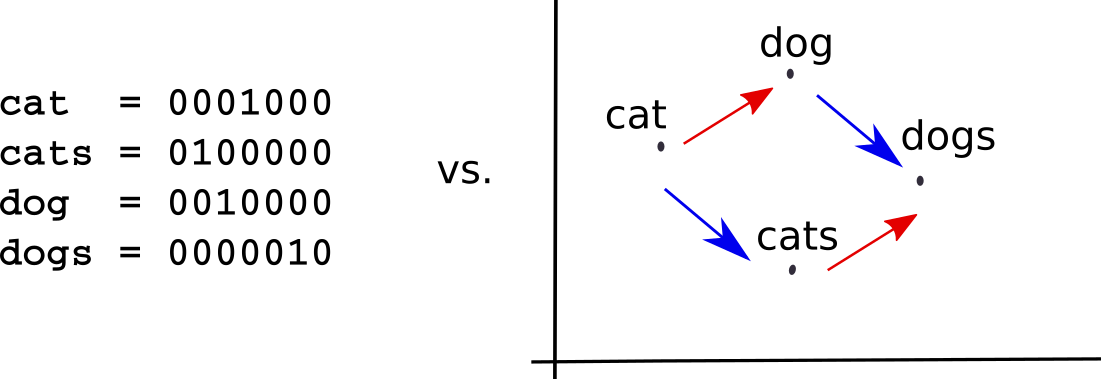
Unfortunately, in such a unitary encoding, all words are in some sense equally alike (or equally different from each other). This does not correspond to how people perceive language, when words are defined by how they are used, how they relate to other words and how they differ from them. This is a fundamental disadvantage of pre-neural models in the processing of natural language.
Neural networks are not easy to cope with such discrete categorical data, and for the automatic processing of the language we had to invent a new way of representing the input data. It is important that in this case the model itself learns the presentation of the data necessary for a specific task.
The word word representation (word embedding) used in neural machine translation, as a rule, matches each word in the input data with a vector of several hundred real numbers. When words are represented in such a vector space, the network can learn to model the relations between them as it would be impossible to do if the same words are presented as arbitrary discrete symbols, as in FMF systems.
For example, the model can recognize that, since “tea” and “coffee” often appear in similar contexts, both of these words should be possible in the context of the new word “spill”, which, say, in the training data only one of them occurred.
However, the process of teaching vector representations is clearly more statistically demanding than the mechanical memorization of examples used by FMP. In addition, it is not clear what to do with those rare input words that were not often encountered so that the network could build an acceptable vector representation for them.
The transition from discrete to continuous representations allows us to model dependencies much more flexibly. This is literally seen in the translations that are made by the machine translation system based on neural networks, which we built in Yandex (NMP).
A system based on the translation of phrases implicitly assumes that each source phrase can be translated independently of the rest of the sentence. It sounds like a recipe for a catastrophe, but in a discrete statistical model it is inevitable, because adding to the model only one bit of context information would double the number of parameters. This is the “curse of dimension” known in our business.
The only reason why a phrases MP generally works is that a language model is used to stitch independently translated phrases. This model is trained on large volumes of monolingual data and makes orthogonal independence assumptions, which can often compensate for phrase-level assumptions.
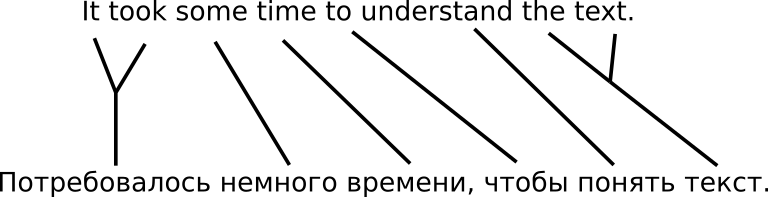
In the FM system, it was necessary to make decisions at each step which source words we “translate” at the moment (but in fact it is often quite difficult to build such an alignment between the source and target words). In the NMP decoder, we simply apply transformations to the vector of hidden states, generating target words step by step until the network decides to stop (or until we stop it).
The vector of hidden states, which is updated at each step, can store information from any part of the original sentence and any part of the translation already completed by this time. This lack of “explicit” assumptions about independence is perhaps the most important distinction between neural and phrasal machine translation systems. It is precisely this that most likely explains the feeling that translations of neural systems more accurately convey the general structure and meaning of the original sentence.
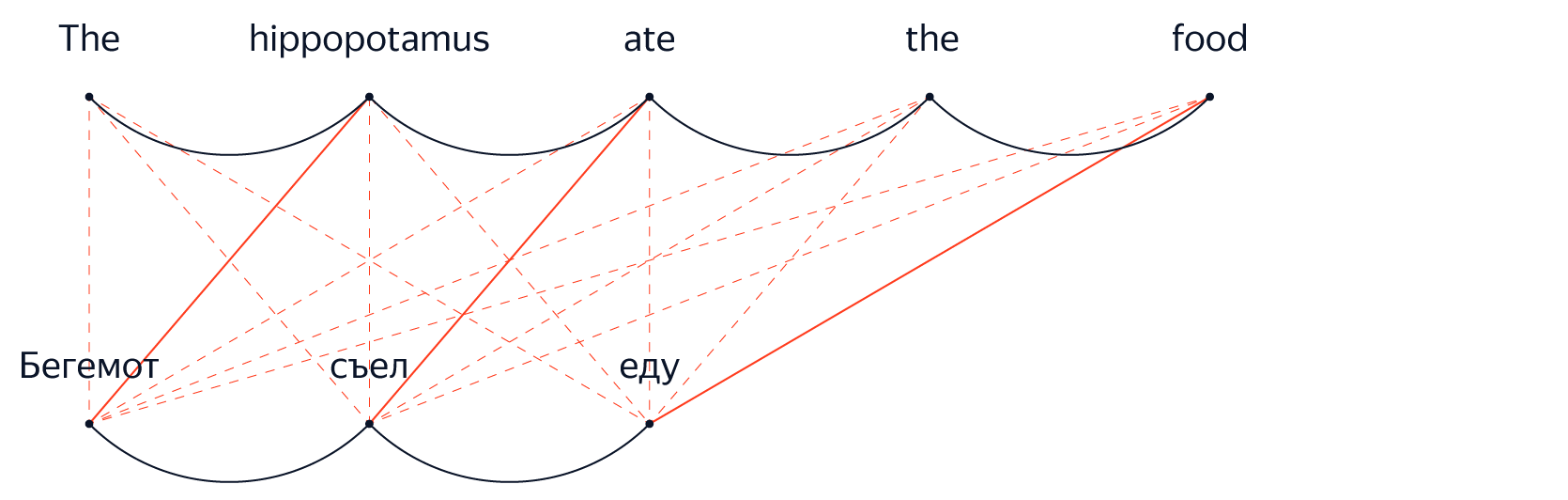
However, it is naive to say that the NMP models do not make any assumptions about independence simply because they do not explicitly exclude the context, as is the case in FMF. The most important developments in the architecture of the NMP over the past few years show that the key to quality improvement is the ability of the model to effectively transfer information between different parts of the proposal. The most suitable mechanism for dynamically and selectively distributing information from the representations generated by the encoder for different parts of the original sentence is called “attention”.
Having learned to “pay attention” to different parts of the source and target sentences in the translation process, the network tries to solve one of the fundamental problems of natural language processing: how to turn a linear sequence of words into something more structured, for example, a tree.

Neural and phrasal machine translation systems are quite unlike creations. Yandex.Translate has many years of experience in developing a FMP system. Last year, we began exploring the possibilities of integrating into our neural machine translation service.
Being, among other things, a search engine, we did not experience a lack of training data for both systems. Judging by the appraisal studies, we have created the most reliable phrasal machine translation system in the world for a pair of English-Russian.
Obviously, the latest NMP architectures could produce results no worse and even better than our phrase system. But suddenly there were disturbing signals in the behavior of our neural system - especially when translating user requests.
It is worth noting that Yandex.Translator strives to be able to translate everything that users can offer. And some of them offer rather strange things. The result is, to put it mildly, some discrepancy between the training and user data.
Recall that our system is trained on translations retrieved from the Internet. These are mainly high-quality translations, as a rule, without problems with spelling, punctuation, and other “trifles” that a user who is in a hurry to receive his translation may not really care about. In terms of topics, content and style, the texts that our users need to translate are often very different from the documents that fall into our teaching corpus.
While the average quality of translations of the FMP system is lower than that of the NMP, the dispersion of the perceived quality of the translations of the NMP can be much higher.
It seems that there are two explanations for this:
FMF just learns phrases from the corpus, so when it comes to low-frequency input data, it has a distinct advantage over NMP. On the other hand, the NWO must see the word several times in order to build an acceptable vector representation. It also tries very hard to model the dependencies in the data, so if it encounters garbage in the input data, it can easily produce ten times more garbage in the weekend.
This is not exactly what we wanted to see when we were preparing to tell how much better our translations became thanks to neural networks.
It takes a long time to earn user confidence in the product, but you can lose this trust in a matter of seconds. Translations like the ones shown above are probably a good way to achieve precisely the loss of trust.
Worse, not all users of our service will be able to assess the adequacy of translations, because not everyone knows the source or target language. Our duty to them is to avoid such worst translations.
Our two machine translation systems - phrasal and neural - behaved quite differently on the same input data. Each of them at the same time showed a fairly high quality of translation. Therefore, we remembered what we were taught in the first year of data analysis and built an ensemble system. The dissimilarity of systems often serves as the key to a successful ensemble.
Instead of combining the two systems during decoding in some complicated way, we chose a simpler approach: choose the result from one of the two systems. For this, we trained classifiers using CatBoost .

The first classifier, trained on a small, hand-marked set of stewids, revealed particularly catastrophic failures in the NMP model. The second, trained to predict the BLEU scoring difference between the output of the two systems on a larger set of pairs of parallel sentences, was used to catch less obvious errors. For example, such as under translation, when the neural network simply refuses to cooperate and leaves part of the original sentence untranslated.
Yandex users send millions of translation requests daily, while repeatedly having to translate many identical requests. As a rule, these requests are very short, therefore, they lack context. Unfortunately, the neural system is quite difficult to translate such short queries, since very few of the examples in which the system is trained consist of individual words or phrases. Despite the ensemble and CatBoost, we understood that sometimes all the power of deep learning may not be enough to give our users the best result.

Yandex.Translate is proud of the dictionary entries it offers to users. Yandex dictionaries are created automatically using a well-tuned machine learning pipeline optimized using user feedback and the crowdsourcing Yandex-Toloki platform.
We decided that by including the best translations from these dictionary entries into our system as constraints, we can significantly improve the quality of machine translation for the most frequent queries.
The last topic of today's post is that if machine translation has reached new heights thanks to a hybrid NMP, then from where can we expect further improvements?
One of the little-studied areas in machine translation is the use of context in the broadest possible sense. The context may include the previous sentence in the document, some information about the persons or entities mentioned in the text, or just information about where on the web page the text that we are currently translating is taken.
By analogy with the perception of context by today's NMP systems at the sentence level (which was beyond the power of the previous generation of FMP), we are experimenting to include more and more diverse types of context in our translation system in order to better translate the text in specific situations and for various tasks.
This idea is not too radical. Most translators will say that the more context or background information about the translated text and its audience, the easier it will be their work. In this sense, machine translation systems should not differ from people. And we already have positive results showing that the work in this direction is worth the effort invested.
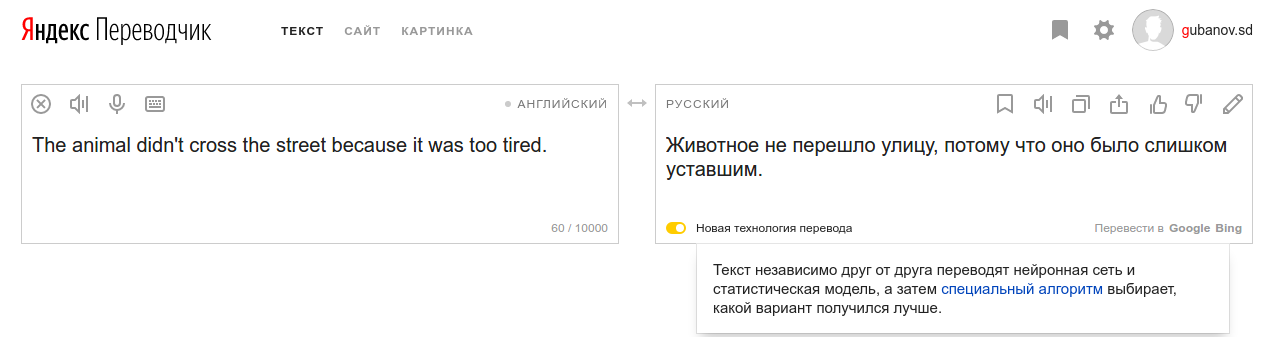
For example, an experimental system that uses the previous original sentence along with the current one when translating. It seems that the network is quite capable of learning to understand when it is necessary to “pay attention” to the words from the previous sentence. This works naturally for pronouns that have antecedents, thus avoiding this kind of trouble:

Another example is the system that we plan to launch in the near future on the Yandex Browser.
Every day, millions of users translate pages thanks to our integration in the Yandex Browser. Since the structure of the HTML page makes it easy to determine where the text is - in the navigation component, title, or block with content, we decided to use this information to improve our translations.
It is clear that in many cases the best translation of the word “Home” is likely to be “Home”. However, in the navigation bar of the website, it should certainly be translated as “Home”. Similarly, “Back” is probably best translated in such a context as “Back,” not “Back.”

By automatically marking out the training sample of parallel texts extracted from the Internet with the labels “navigation”, “title”, “content”, and then setting our system to predict these marks in the translation process, we significantly improved the quality in specific types of translation.
Of course, we could achieve only a retraining of the system on this rather specific distribution. Therefore, in order to avoid performance degradation in more standard areas, we included in the calculation of the learning loss function the Kulbach – Leibler distance between the predictions of our adapted model and the predictions of our common system. In fact, this is a model fining for excessively changing predictions.

As can be seen from the graphs, the quality of the data in the domain increases significantly, and as soon as our loss function is supplemented by taking into account the Kullback-Leibler distance, an increase in quality no longer leads to a deterioration of translation for documents outside the domain.
Very soon we will launch this system on Yandex. Browser. Hopefully, this is only the first of a number of improvements that we will make based on a better understanding of the user context and the “unjustified effectiveness of [recurrent] neural networks.”
We will also be happy to answer questions at the Yandex “From the Inside: From Algorithms to Measurements - in Translator, Alice and Search” meeting on March 1 (you can register or ask a question in the broadcast chat).
')
Phrasal machine translation
Just three years ago, almost all serious industrial and research machine translation systems were built using a conveyor of statistical models (“phrasal machine translation,” FMP), in which neural networks did not participate. Phrasal machine translation for the first time made machine translation available to the mass user in the early 2000s. With enough data and enough computing resources, the FMF allowed developers to create translation systems that basically gave an idea of the meaning of the text, but were full of grammatical and sometimes semantic errors.
The conveyor of statistical models, which was used to build FMP systems, is actually quite intricate. Based on leveled teaching sentences — for example, translations of Russian news articles into English — the system builds a statistical model that tries to “explain” each of the words of the target language with the words of the source language using “hidden” variables known as word alignments. ). The idea is intuitive, and the math (maximizing expectations, the EM algorithm) is pretty good .
An iterative EM algorithm — when at each step we make the best guess as to which source words correspond to which target words, and then these “guesses” are used as training data for the next iteration — quite similar to the approach we could apply to decoding menu in a foreign language. The problem is that it is based on separate words, and word-for-word translation is often impossible.
Word alignment models introduce various assumptions about independence in order to simplify the task of too large computational complexity (deciding which of the 2 ^ {JI} possible ways to align words in the original sentence of length I with the words in the target sentence of length J) to more acceptable sizes . For example, a hidden Markov model can be developed to solve this problem with complexity O (I ^ 2J).
Word-based models have never shown particularly good results. And everything looked rather sad until a method was proposed for constructing a translation model at the phrase level , on top of the alignment of words. After that, machine translation began to be used on the Internet - for translating websites in foreign languages or simply as an inexhaustible source of inspiration for memes .
FMP uses word alignment matrices to determine which pairs of phrases in a pair of sentences can serve as translations for each other. The resulting table of phrases becomes the main factor in the linear model, which, together with components such as the language model, is used to generate and select potential translations.
FMP very well remembers phrases from a parallel body of texts. Theoretically, one single example is enough for him to learn a phrasal translation, if only the words in this example are relatively well aligned. Although this may give the impression of a fluent language, in fact, the system does not really understand what it does.
The parameter space of the FMP system is huge, but the parameters themselves are extremely simple - “what is the probability of seeing this target phrase as a translation of this source phrase?” When the model is used for translation, each source sentence is divided into phrases that the system has seen before, and these phrases are translated independently of each other. from friend. Unfortunately, when these phrases are stitched together, inconsistencies between them turn out to be too noticeable.
What do neural networks give us?
Researchers engaged in speech recognition or images, have long been thinking about how to encode data, because a continuous signal is difficult to imagine in the discrete world of computers. But working on the processing of natural language is not particularly worried about this. It seemed pretty simple - you can replace the words with integer identifiers and index the model parameters with these numbers. This is exactly what N-gram language models and FMP systems do.
Unfortunately, in such a unitary encoding, all words are in some sense equally alike (or equally different from each other). This does not correspond to how people perceive language, when words are defined by how they are used, how they relate to other words and how they differ from them. This is a fundamental disadvantage of pre-neural models in the processing of natural language.
Neural networks are not easy to cope with such discrete categorical data, and for the automatic processing of the language we had to invent a new way of representing the input data. It is important that in this case the model itself learns the presentation of the data necessary for a specific task.
The word word representation (word embedding) used in neural machine translation, as a rule, matches each word in the input data with a vector of several hundred real numbers. When words are represented in such a vector space, the network can learn to model the relations between them as it would be impossible to do if the same words are presented as arbitrary discrete symbols, as in FMF systems.
For example, the model can recognize that, since “tea” and “coffee” often appear in similar contexts, both of these words should be possible in the context of the new word “spill”, which, say, in the training data only one of them occurred.
However, the process of teaching vector representations is clearly more statistically demanding than the mechanical memorization of examples used by FMP. In addition, it is not clear what to do with those rare input words that were not often encountered so that the network could build an acceptable vector representation for them.
No assumptions about independence
The transition from discrete to continuous representations allows us to model dependencies much more flexibly. This is literally seen in the translations that are made by the machine translation system based on neural networks, which we built in Yandex (NMP).
A system based on the translation of phrases implicitly assumes that each source phrase can be translated independently of the rest of the sentence. It sounds like a recipe for a catastrophe, but in a discrete statistical model it is inevitable, because adding to the model only one bit of context information would double the number of parameters. This is the “curse of dimension” known in our business.
The only reason why a phrases MP generally works is that a language model is used to stitch independently translated phrases. This model is trained on large volumes of monolingual data and makes orthogonal independence assumptions, which can often compensate for phrase-level assumptions.
Decoder states and hidden states
In the FM system, it was necessary to make decisions at each step which source words we “translate” at the moment (but in fact it is often quite difficult to build such an alignment between the source and target words). In the NMP decoder, we simply apply transformations to the vector of hidden states, generating target words step by step until the network decides to stop (or until we stop it).
The vector of hidden states, which is updated at each step, can store information from any part of the original sentence and any part of the translation already completed by this time. This lack of “explicit” assumptions about independence is perhaps the most important distinction between neural and phrasal machine translation systems. It is precisely this that most likely explains the feeling that translations of neural systems more accurately convey the general structure and meaning of the original sentence.
Calculation of dynamic dependencies
However, it is naive to say that the NMP models do not make any assumptions about independence simply because they do not explicitly exclude the context, as is the case in FMF. The most important developments in the architecture of the NMP over the past few years show that the key to quality improvement is the ability of the model to effectively transfer information between different parts of the proposal. The most suitable mechanism for dynamically and selectively distributing information from the representations generated by the encoder for different parts of the original sentence is called “attention”.
Having learned to “pay attention” to different parts of the source and target sentences in the translation process, the network tries to solve one of the fundamental problems of natural language processing: how to turn a linear sequence of words into something more structured, for example, a tree.
Putting it all together
Neural and phrasal machine translation systems are quite unlike creations. Yandex.Translate has many years of experience in developing a FMP system. Last year, we began exploring the possibilities of integrating into our neural machine translation service.
Being, among other things, a search engine, we did not experience a lack of training data for both systems. Judging by the appraisal studies, we have created the most reliable phrasal machine translation system in the world for a pair of English-Russian.
Obviously, the latest NMP architectures could produce results no worse and even better than our phrase system. But suddenly there were disturbing signals in the behavior of our neural system - especially when translating user requests.
It is worth noting that Yandex.Translator strives to be able to translate everything that users can offer. And some of them offer rather strange things. The result is, to put it mildly, some discrepancy between the training and user data.
Recall that our system is trained on translations retrieved from the Internet. These are mainly high-quality translations, as a rule, without problems with spelling, punctuation, and other “trifles” that a user who is in a hurry to receive his translation may not really care about. In terms of topics, content and style, the texts that our users need to translate are often very different from the documents that fall into our teaching corpus.
While the average quality of translations of the FMP system is lower than that of the NMP, the dispersion of the perceived quality of the translations of the NMP can be much higher.
It seems that there are two explanations for this:
- FMP remembers rare words and phrases better, so it has fewer “gaps” in language knowledge.
- NMP pays much more attention to context, so some noise in the input signal can affect the entire translation.
FMF just learns phrases from the corpus, so when it comes to low-frequency input data, it has a distinct advantage over NMP. On the other hand, the NWO must see the word several times in order to build an acceptable vector representation. It also tries very hard to model the dependencies in the data, so if it encounters garbage in the input data, it can easily produce ten times more garbage in the weekend.
Examples of stewids
This is not exactly what we wanted to see when we were preparing to tell how much better our translations became thanks to neural networks.
It takes a long time to earn user confidence in the product, but you can lose this trust in a matter of seconds. Translations like the ones shown above are probably a good way to achieve precisely the loss of trust.
Worse, not all users of our service will be able to assess the adequacy of translations, because not everyone knows the source or target language. Our duty to them is to avoid such worst translations.
The best of both worlds
Our two machine translation systems - phrasal and neural - behaved quite differently on the same input data. Each of them at the same time showed a fairly high quality of translation. Therefore, we remembered what we were taught in the first year of data analysis and built an ensemble system. The dissimilarity of systems often serves as the key to a successful ensemble.
Instead of combining the two systems during decoding in some complicated way, we chose a simpler approach: choose the result from one of the two systems. For this, we trained classifiers using CatBoost .
The first classifier, trained on a small, hand-marked set of stewids, revealed particularly catastrophic failures in the NMP model. The second, trained to predict the BLEU scoring difference between the output of the two systems on a larger set of pairs of parallel sentences, was used to catch less obvious errors. For example, such as under translation, when the neural network simply refuses to cooperate and leaves part of the original sentence untranslated.
How to cope with the mismatch of domains
Cherry on the cake
Yandex users send millions of translation requests daily, while repeatedly having to translate many identical requests. As a rule, these requests are very short, therefore, they lack context. Unfortunately, the neural system is quite difficult to translate such short queries, since very few of the examples in which the system is trained consist of individual words or phrases. Despite the ensemble and CatBoost, we understood that sometimes all the power of deep learning may not be enough to give our users the best result.
Yandex.Translate is proud of the dictionary entries it offers to users. Yandex dictionaries are created automatically using a well-tuned machine learning pipeline optimized using user feedback and the crowdsourcing Yandex-Toloki platform.
We decided that by including the best translations from these dictionary entries into our system as constraints, we can significantly improve the quality of machine translation for the most frequent queries.
Context adaptation
The last topic of today's post is that if machine translation has reached new heights thanks to a hybrid NMP, then from where can we expect further improvements?
One of the little-studied areas in machine translation is the use of context in the broadest possible sense. The context may include the previous sentence in the document, some information about the persons or entities mentioned in the text, or just information about where on the web page the text that we are currently translating is taken.
By analogy with the perception of context by today's NMP systems at the sentence level (which was beyond the power of the previous generation of FMP), we are experimenting to include more and more diverse types of context in our translation system in order to better translate the text in specific situations and for various tasks.
This idea is not too radical. Most translators will say that the more context or background information about the translated text and its audience, the easier it will be their work. In this sense, machine translation systems should not differ from people. And we already have positive results showing that the work in this direction is worth the effort invested.
For example, an experimental system that uses the previous original sentence along with the current one when translating. It seems that the network is quite capable of learning to understand when it is necessary to “pay attention” to the words from the previous sentence. This works naturally for pronouns that have antecedents, thus avoiding this kind of trouble:
Another example is the system that we plan to launch in the near future on the Yandex Browser.
Every day, millions of users translate pages thanks to our integration in the Yandex Browser. Since the structure of the HTML page makes it easy to determine where the text is - in the navigation component, title, or block with content, we decided to use this information to improve our translations.
It is clear that in many cases the best translation of the word “Home” is likely to be “Home”. However, in the navigation bar of the website, it should certainly be translated as “Home”. Similarly, “Back” is probably best translated in such a context as “Back,” not “Back.”
By automatically marking out the training sample of parallel texts extracted from the Internet with the labels “navigation”, “title”, “content”, and then setting our system to predict these marks in the translation process, we significantly improved the quality in specific types of translation.
Of course, we could achieve only a retraining of the system on this rather specific distribution. Therefore, in order to avoid performance degradation in more standard areas, we included in the calculation of the learning loss function the Kulbach – Leibler distance between the predictions of our adapted model and the predictions of our common system. In fact, this is a model fining for excessively changing predictions.
As can be seen from the graphs, the quality of the data in the domain increases significantly, and as soon as our loss function is supplemented by taking into account the Kullback-Leibler distance, an increase in quality no longer leads to a deterioration of translation for documents outside the domain.
Very soon we will launch this system on Yandex. Browser. Hopefully, this is only the first of a number of improvements that we will make based on a better understanding of the user context and the “unjustified effectiveness of [recurrent] neural networks.”
Source: https://habr.com/ru/post/350002/
All Articles