Making holes in torrents freeing up space and remaining on hand (part 1)

Warning: This graph is made for the script of the second part of the article for which I have not yet taken. Therefore, do not really pay attention to the data in it. The graphs for this article are at the end.
Use the information in this article at your own risk. We will erase the data from the files. The article is written for the Windows operating system and the NTFS file system. Also in the article are many images.
What is a sparse file?
Sparse file (eng. Sparse file) is a file in which sequences of zero bytes [1] are replaced with information about these sequences (list of holes).
Hole (eng. Hole) - a sequence of zero bytes within the file, not written to disk. Information about holes (offset from the beginning of the file in bytes and the number of bytes) is stored in the FS metadata.
On Geektimes there is also a small article about them: " Sparse files in NTFS "
The default operating system does not create sparse files. This flag can be set to the file programmatically or with the help of a utility.
Set the flag using the utility:
fsutil sparse setflag < > Programmatically (C ++ Windows):
DeviceIoControl( m_hFile, FSCTL_SET_SPARSE, NULL, 0, NULL, 0, &dwOut, NULL ) Automatically zero sequences in the file will not free up disk space and this also needs to be done programmatically or with the help of a utility.
Overwrite part of the utility help file with zeros:
fsutil sparse setrange < > <> <> Programmatically (C ++ Windows):
FILE_ZERO_DATA_INFORMATION range; range.FileOffset.QuadPart = start; range.BeyondFinalZero.QuadPart = start + size; DeviceIoControl( m_hFile, FSCTL_SET_ZERO_DATA, &range, sizeof(range), NULL, 0, &dwOut, NULL ); Simple files
For them, there are special utilities that free up space in the file where there is a large sequence of zeros without damaging it. But such files are rarely found.
Downloadable files
- With a sparse flag, the file will take up as much as the loaded data needs. This is useful when there are a lot of files in the download queue and their total size may exceed the available ones.
By parts hashes, you can identify parts filled with zeros and mark them already loaded. These parts will not load and take up disk space.
The function to search for empty pieces in the torrent (C ++ Shareaza)BOOL CBTInfo::IsZeroBlock(uint32 nBlock) const { static const uint32 ZeroHash[22][5] = { // Hash: 897256B6709E1A4DA9DABA92B6BDE39CCFCCD8C1 Size: 16384 { 0xB6567289, 0x4D1A9E70, 0x92BADAA9, 0x9CE3BDB6, 0xC1D8CCCF }, // Hash: 5188431849B4613152FD7BDBA6A3FF0A4FD6424B Size: 32768 { 0x18438851, 0x3161B449, 0xDB7BFD52, 0x0AFFA3A6, 0x4B42D64F }, // Hash: 1ADC95BEBE9EEA8C112D40CD04AB7A8D75C4F961 Size: 65536 { 0xBE95DC1A, 0x8CEA9EBE, 0xCD402D11, 0x8D7AAB04, 0x61F9C475 }, // Hash: 67DFD19F3EB3649D6F3F6631E44D0BD36B8D8D19 Size: 131072 { 0x9FD1DF67, 0x9D64B33E, 0x31663F6F, 0xD30B4DE4, 0x198D8D6B }, // Hash: 2E000FA7E85759C7F4C254D4D9C33EF481E459A7 Size: 262144 { 0xA70F002E, 0xC75957E8, 0xD454C2F4, 0xF43EC3D9, 0xA759E481 }, // Hash: 6A521E1D2A632C26E53B83D2CC4B0EDECFC1E68C Size: 524288 { 0x1D1E526A, 0x262C632A, 0xD2833BE5, 0xDE0E4BCC, 0x8CE6C1CF }, // Hash: 3B71F43FF30F4B15B5CD85DD9E95EBC7E84EB5A3 Size: 1048576 { 0x3FF4713B, 0x154B0FF3, 0xDD85CDB5, 0xC7EB959E, 0xA3B54EE8 }, // Hash: 7D76D48D64D7AC5411D714A4BB83F37E3E5B8DF6 Size: 2097152 { 0x8DD4767D, 0x54ACD764, 0xA414D711, 0x7EF383BB, 0xF68D5B3E }, // Hash: 2BCCBD2F38F15C13EB7D5A89FD9D85F595E23BC3 Size: 4194304 { 0x2FBDCC2B, 0x135CF138, 0x895A7DEB, 0xF5859DFD, 0xC33BE295 }, // Hash: 5FDE1CCE603E6566D20DA811C9C8BCCCB044D4AE Size: 8388608 { 0xCE1CDE5F, 0x66653E60, 0x11A80DD2, 0xCCBCC8C9, 0xAED444B0 }, // Hash: 3B4417FC421CEE30A9AD0FD9319220A8DAE32DA2 Size: 16777216 { 0xFC17443B, 0x30EE1C42, 0xD90FADA9, 0xA8209231, 0xA22DE3DA }, // Hash: 57B587E1BF2D09335BDAC6DB18902D43DFE76449 Size: 33554432 { 0xE187B557, 0x33092DBF, 0xDBC6DA5B, 0x432D9018, 0x4964E7DF }, // Hash: 44FAC4BEDDE4DF04B9572AC665D3AC2C5CD00C7D Size: 67108864 { 0xBEC4FA44, 0x04DFE4DD, 0xC62A57B9, 0x2CACD365, 0x7D0CD05C }, // Hash: BA713B819C1202DCB0D178DF9D2B3222BA1BBA44 Size: 134217728 { 0x813B71BA, 0xDC02129C, 0xDF78D1B0, 0x22322B9D, 0x44BA1BBA }, // Hash: 7B91DBDC56C5781EDF6C8847B4AA6965566C5C75 Size: 268435456 { 0xDCDB917B, 0x1E78C556, 0x47886CDF, 0x6569AAB4, 0x755C6C56 }, // Hash: 5B088492C9F4778F409B7AE61477DEC124C99033 Size: 536870912 { 0x9284085B, 0x8F77F4C9, 0xE67A9B40, 0xC1DE7714, 0x3390C924 }, // Hash: 2A492F15396A6768BCBCA016993F4B4C8B0B5307 Size: 1073741824 { 0x152F492A, 0x68676A39, 0x16A0BCBC, 0x4C4B3F99, 0x07530B8B }, // Hash: 91D50642DD930E9542C39D36F0516D45F4E1AF0D Size: 2147483648 { 0x4206D591, 0x950E93DD, 0x369DC342, 0x456D51F0, 0x0DAFE1F4 }, // Hash: 1BF99EE9F374E58E201E4DDA4F474E570EB77229 Size: 4294967296 { 0xE99EF91B, 0x8EE574F3, 0xDA4D1E20, 0x574E474F, 0x2972B70E }, // Hash: BCC8C0CA9E402EEE924A6046966D18B1F66EB577 Size: 8589934592 { 0xCAC0C8BC, 0xEE2E409E, 0x46604A92, 0xB1186D96, 0x77B56EF6 }, // Hash: DC44DD38511BD6D1233701D63C15B87D0BD9F3A5 Size: 17179869184 { 0x38DD44DC, 0xD1D61B51, 0xD6013723, 0x7DB8153C, 0xA5F3D90B }, // Hash: 7FFB233B3B2806328171FB8B5C209F48DC095B72 Size: 34359738368 { 0x3B23FB7F, 0x3206283B, 0x8BFB7181, 0x489F205C, 0x725B09DC } }; int i = 0; for(; m_nBlockSize > ( (uint64) 16384 << i ); i++) if ( i > 21 ) return FALSE; return memcmp( &m_pBlockBTH[ nBlock ], ZeroHash[ i ], sizeof( ZeroHash[ i ] ) ) == 0; }
Disadvantages:
The file is fragmented. This happens with regular files but with sparse it is more pronounced. The file is loaded in random order and the space for data is allocated as needed. Pieces of the file are scattered on the disk.
Partial deletion of unnecessary files in the distribution.
Sparse files allow you to gradually free up space for other data. The area specified by the fsutil sparse setrange freed and only zeros are read from it.
If you double-check these files, the client will mark the thinned areas as not loaded (if there were no zeros there initially) and will not distribute them. So that he does not try to download them back, you need to uncheck the download. At the same time, whole sections of the file will remain accessible to the swarm.
Benefit:
- Thus, we can stay on hand while freeing up enough space for downloading a new torrent.
- Staying on hand, we do not increase the load on other sources.
- The more sources distribute the higher the download speed.
Example
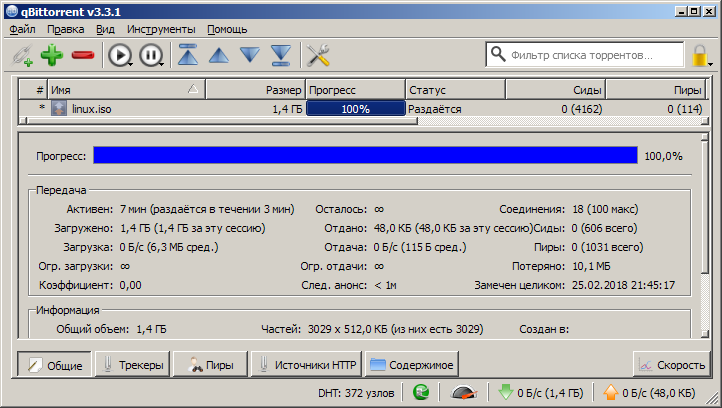
We have the file "linux.iso". Its size is 1.4 gigabytes. For a new download, we lack 1 gigabyte of free disk space.
Use fsutil sparse directly (not correct!)
fsutil sparse setflag linux.iso fsutil sparse setrange linux.iso 0 1073741824 We freed up 1 gigabyte of disk space, but in this way we clear a large contiguous area at the beginning of the file. If other sources repeat this, we will get a surplus of available parts at the end of the file and its beginning may be completely unavailable in the absence of a complete source.
We write a simple script for selecting a random position.
Because large numbers are used and for convenience we perform calculations in JavaScript
// if (WScript.Arguments.Length == 2) { // var file_size = parseInt( WScript.Arguments.Item(0) ); // var sparse_size = parseInt( WScript.Arguments.Item(1) ); if ( file_size > 0 && sparse_size > 0 && sparse_size < file_size ) { // if ( file_size / 2 > sparse_size ) // WScript.Echo( Math.round( ( file_size - sparse_size ) * Math.random() ), sparse_size ); else { // var data_size = file_size - sparse_size; var data_pos = Math.round( ( file_size - data_size ) * Math.random() ); // if ( data_pos > 0 ) WScript.Echo( 0, data_pos ); var sparse_pos = data_pos + data_size; // if ( sparse_pos < file_size ) WScript.Echo( sparse_pos, file_size - sparse_pos ); } } } We will get the file size and work with fsutil sparse in the batch file.
@rem %1 @rem %2 @setlocal @rem @echo This script will erase some of the data (%2 bytes) from the file: %1 @set /P AREYOUSURE=Are you sure (Y/[N])? @if /I "%AREYOUSURE%" NEQ "Y" goto END @rem fsutil sparse setflag %1 @rem sparse_light.js for /f "tokens=1,2" %%i in ('cscript //nologo "%~dp0sparse_light.js" %~z1 %2') do ( fsutil sparse setrange %1 %%i %%j ) :END @endlocal Call:
sparse_random.cmd linux.iso 1073741824 This script will erase one or two random sections of the file. The script is suitable for mashing a single file.
An example of using the script with qBittorent (many screenshots)
- Open qBittorent
- Select the desired torrent (in this case, linux.iso). Call the context menu and click "Suspend".

- We thin the file with the help of the script:
sparse_light.cmd G:\linux\linux.iso 500000000
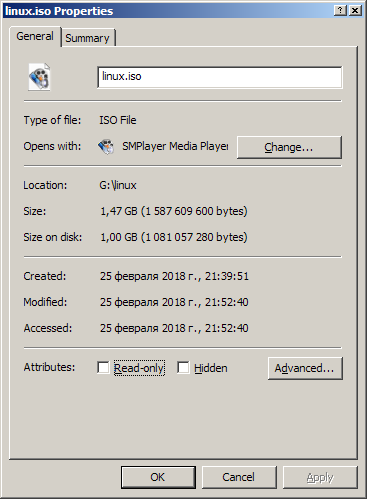
- Make sure that the specified amount of disk space is freed. Open the file properties and compare the "Size" and "Size on disk".
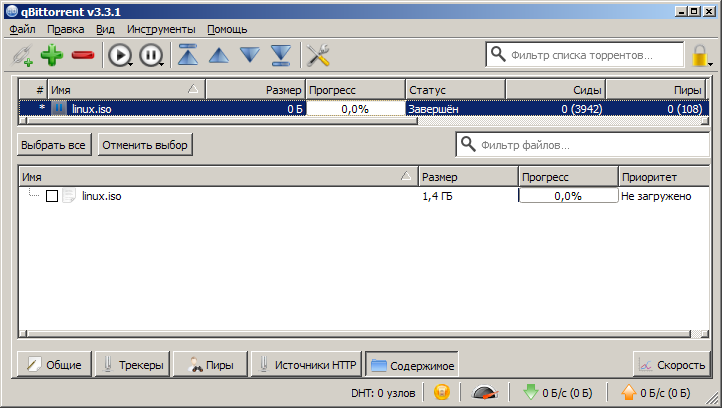
- In qBittorent, switch to the content tab.

- And remove the check mark next to the file so that after checking it does not start loading again
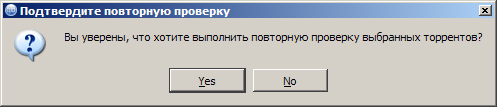
- Right-click on the distribution, we call the context menu and click the item "Check forcibly"

- Yes, we are sure that we want to re-check the selected torrents.
- After the end of the check. Right-click on the distribution, we call the context menu and click the "Resume" item
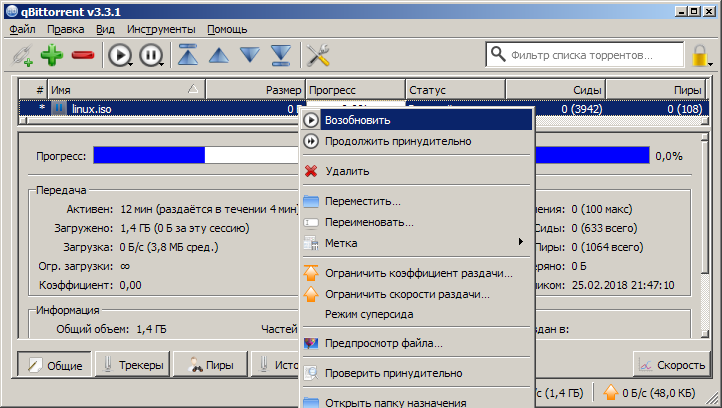
- So we stayed on hand and freed up some disk space.
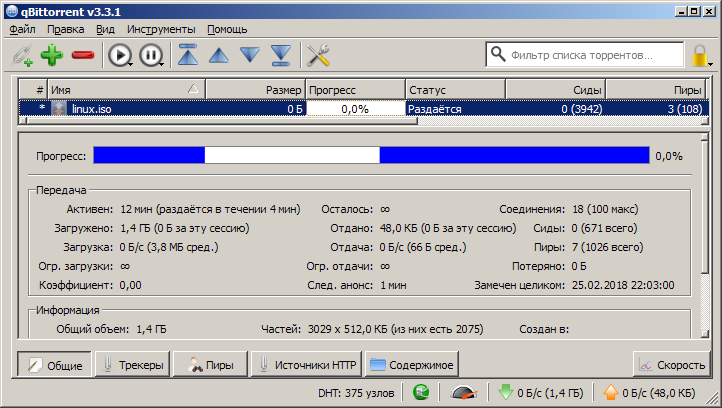
- Right-click on the distribution, we call the context menu and click the "Move" item (We should do this as the first item, but today I just thought about it)
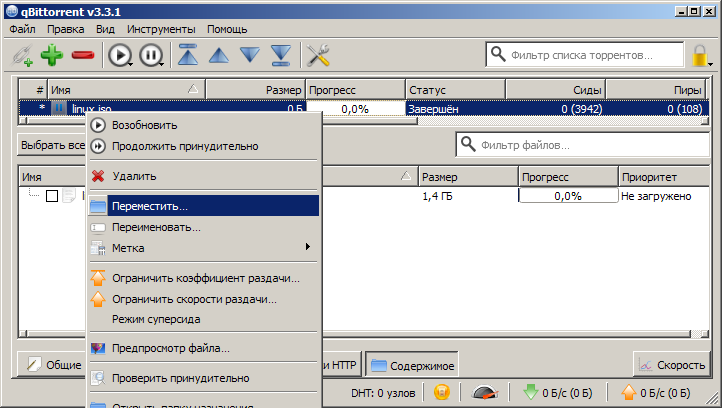
- We select the directory name so that it is clear that the files in it are not suitable for use.

We consider statistics in SVG

The file is divided into 100 blocks. Only full blocks are counted in the graphs. Each line in the grid is one swarm emulation. Below the grid with a milestone in the bottom drop availability graphs.
- In the blue graph, the bar below each block shows the number of cycles in which it was complete.
- In dark blue (in fact, translucent gray), the graph shows on the left (0%) on the right (100%) the percentage of data available and from top to bottom the number of cycles to which this percentage was available.
For those who want to play around with emulation: https://ivan386.imtqy.com/sparse_light/emulator.svg
Keyboard control:P/ - pause+/= - add one source-/_ - remove one source
Mouse control:
By clicking on the grid, you can select the percentage that will be erased from all sources. The more to the right, the more erased.
We sort graphics
- 5 sources erased 81% of the file from different positions. At the same time, 64% remained available in most cycles. Blocks on the edges while almost always remain inaccessible.
- 5 sources erased 49% of the file from different positions. 88% of the file is available.
Since less than half of the file is released, the script chooses the position to be erased. Thus, in the middle of the file, the blocks become less accessible than the edges.
- 5 sources erased 52% of the file from different positions. 86% of the file is available.
Selected to erase more than half of the file. The script in this case selects the position for the data and erases before and after this piece.
- 5 sources erased 40% of the file from different positions. 100% of the file is available. Here we see that when erasing up to 40% of the file with 5 sources, we will most likely get 100% availability of the file.

Charts 2 and 3 compensate each other.
Conclusion
This method of freeing up disk space is suitable for distributions with large files. We can erase a part and distribute further the rest when the contents are no longer needed.
Sources
')
Source: https://habr.com/ru/post/349950/
All Articles