Network code for the poor
The more you learn in your field of knowledge, the more clearly you understand that no one can know everything.
For some reason (why, my God, for what?), The development of games has become my area. Everyone who works in this field will tell you: never add a network multiplayer mode to a ready-made game, never drunk you are a clown.
Anyway, I did just that, and I hate myself for it. Surprisingly, it turned out great. None of us knows everything.
')
Problem number 1: resources
The first question I had was: how to tell the client that you need to use such and such a mesh for rendering the object?
Serialize the whole mesh? Not worth it, the client already has it on the disk.
Transfer the file name? Nah, ineffective and unsafe.
Well, maybe just a string identifier?
Fortunately, before I had time to implement my own delusional ideas, I looked at the report of Mike Acton, in which he spoke about the dangers of "lazy decision-making." The point is this: strings allow developers to lazily ignore decision making until the creation of a working application, when it is too late to correct errors.
If I rename the texture, I don’t want to receive error reports from players with the following screenshots:

I never wondered how powerful and complex the lines are. Half of the tasks in computer science are related to strings and their capabilities. Usually they require dynamic memory allocation or even something even more complex, such as ropes and a pool of strings.
I usually don’t bother with their length, so the line expands the space of possibilities to infinity, destroying the constraints necessary for the program’s predictable behavior during execution.
And here I use these complex monsters to identify objects . Yes, I used strings even to access the properties of objects. What a madness!
In short, I have developed in myself a strong installation: avoid lines where it is possible.
I wrote a preprocessor that creates some of the following header files during the build process:
namespace Asset { namespace Mesh { const int count = 3; const AssetID player = 0; const AssetID enemy = 1; const AssetID projectile = 2; } } Therefore, I can refer to meshes as follows:
renderer->mesh = Asset::Mesh::player; If I rename the mesh, the compiler will turn it into my problem, and not into the problem of some unfortunate player. And this is good!
The bad news is that I still need to interact with the file system, and for this you need to use strings.
The good news is that the preprocessor can save us again.
const char* Asset::Mesh::filenames[] = { "assets/player.msh", "assets/enemy.msh", "assets/projectile.msh", 0, }; Thanks to all this, I was able to easily transfer resources over the network.
These are just numbers! I can even check them out.
if (mesh < 0 || mesh >= Asset::Mesh::count) net_error(); // , ? Problem number 2: links to objects
The next question I had was: how can I politely ask a client to move / delete / process “the object that you used to know which one”.
And here again I was lucky to hear the advice of smart people, before shooting myself in the foot.
From the very beginning, I knew that I would need a bunch of lists of various kinds of objects, like these:
Array<Turret> Turret::list; Array<Projectile> Projectile::list; Array<Avatar> Avatar::list; Suppose I want to refer to the first object in the Avatar list, even without a network, just on a local machine. My first idea was to use a simple pointer:
Avatar* avatar; avatar = &Avatar::list[0]; At the same time there is a mountain of unobvious problems.
First, I compile for a 64-bit architecture, that is, the pointer occupies 8 bytes of memory entirely, even though most of them will most likely be filled with zeros. And memory is the main “bottleneck” of game speed.
Secondly, if I add a lot of objects to the array, it will be reassigned to another part of the memory, and the pointer will point to garbage.
Okay, fine. I will use instead of the pointer ID.
template<typename Type> struct Ref { short id; inline Type* ref() { return &Type::list[id]; } // "=" }; Ref<Avatar> avatar = &Avatar::list[0]; avatar.ref()->frobnicate(); The second problem: if I remove this Avatar from the list, then another Avatar will be moved to its place, and I will not know anything about it.
The program will continue to perform, majestically and calmly cracking everything until some player sends me an error report “the game behaves strangely.”
I prefer when the program explodes immediately to at least get an emergency dump with the line number.
All right, all right. Instead of deleting an avatar, I will assign a version number to it:
struct Avatar { short revision; }; template<typename Type> struct Ref { short id; short revision; inline Type* ref() { Type* t = &Type::list[id]; return t->revision == revision ? t : nullptr; } }; I do not delete the avatar completely, but mark it as “dead” and increment the version number. Now everything that tries to access it will receive a null pointer exception. And serializing links over the network is just a matter of passing two easily verifiable numbers.
Problem number 3: delta compression
If I had to cut my article down to one line, then it would be just a link to Glenn Fiedler's blog.
By the way, here it is: gafferongames.com
When I decided to implement my own version of Glenn's network code, I studied this article ,
in which one of the most serious problems of multiplayer games is considered in detail. Namely, the following: if you want to transmit the state of the whole world over the network 60 times per second, then you will score 17 Mbps from the width of the channel.
And this is only for one customer .
Delta compression is one of the best ways to reduce the amount of data transferred. If the client already knows where the object is, and he did not move, then we do not need to send his position again. But to implement it correctly can be quite difficult.
The first part is the most difficult: does the client even know where the object is located? The fact that I sent the position does not mean that the client received it. The client can send back confirmations like "I received the package 218, but this was 0.5 seconds ago and since then I haven’t received anything else."
That is, in order to send a packet to this client, I have to remember what the world looked like when I sent a packet 218, and perform a delta compression on it of the new packet. Another client could get everything up to package 224 inclusive, that is, for him I need to perform another delta compression. The point is that we have to keep a whole bunch of different copies of the whole world.
Someone asked a question on Reddit: “Isn't it a huge amount of memory?”
No, not huge.
I keep in memory 255 copies of the world in a single huge array. But that is not all -
each copy has enough space for the maximum number of objects (2048) even if only 2 are active.
If you store the state of the object as a position and rotation, then you need 7 float numbers: 3 on the coordinates XYZ and 4 on the quaternion. Each float number is 4 bytes. The game supports up to 2048 objects. 7 float * 4 bytes * 2048 objects * 255 copies = ...
14 MB. That is about half of the modern texture.
I can imagine how I would write this system five years ago in C #. I would immediately begin to worry about the memory used, just like that person with Reddit, without even thinking about the actual amount of data involved. I would write some unnecessary, insanely sophisticated, buggy-filled compression system. When you take a second and think about what the real data will be, this is called Data-Oriented Design . When I tell people about DOD, many immediately begin to say: “Wow, this is a very low-level approach. Looks like you want to max out your productivity. I don't have time for this. Yes, and my code works fine. " Let's break this phrase into statements.
Statement 1: “This is a very low-level approach.”
You see - I just multiplied four numbers, this is not quantum physics.
Statement 2: "We have to sacrifice readability and simplicity for the sake of speed."
Let's imagine two different solutions to this problem with network code. For clarity, let's imagine that we need only three copies of the world, each of which contains two objects.
Here is the solution I just described. Everything is statically located in the .bss segment . It never moves, is always the same size and does not use pointers at all:

But the characteristic for C # solution. Everything is randomly scattered across dynamic memory. The elements are redistributed or moved right in the middle of the frame, the array is chaotic, 64-bit pointers are everywhere:
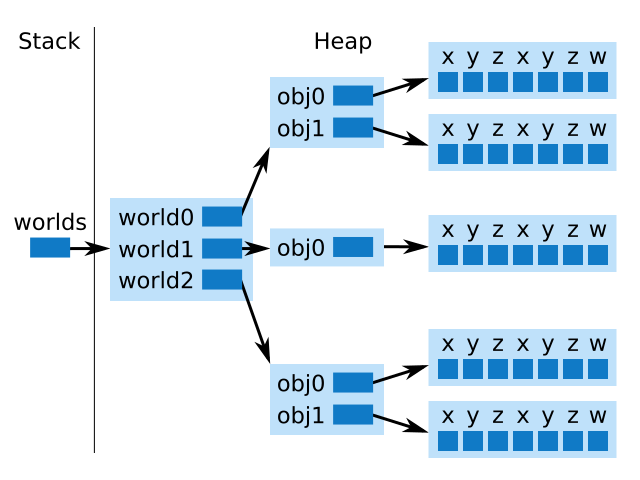
What is easier?
In fact, the second scheme is far from exhaustive. In the real world, C # territory is much more complicated. In the comments, they will probably correct me and tell me how C # actually works.
But this is my point of view. In my decision, I can easily construct a “good enough” mental model to understand what is actually happening in the car. And in the C # solution, I barely started the implementation. I have no idea how it will behave in the process of execution.
Assumption 3: "Writing code in this way is worth only for the sake of performance."
In my opinion, speed is a nice side effect of Data Oriented Design. The main advantage is clarity of thought. Five years ago, if I began to solve a problem, the first thing I would think was not about the task itself, but how to cram it into classes and interfaces.
Recently, I witnessed with my own eyes such an analysis paralysis on gamejam. My friend stalled on creating a grid for playing in the style of 2048 . He could not understand whether each number should be an object, or each grid cell, or all of them. I said, “The grid is an array of numbers. Each operation is a function that changes the grid. " Suddenly, everything became crystal clear to him.
Assumption 4: "My code is working fine."
I repeat: speed is not the main problem, but it is important. It was because of her that the whole world switched from Firefox to Chrome.
Try the experiment: run calc.exe. Now copy the 100 megabyte file from one folder to another.
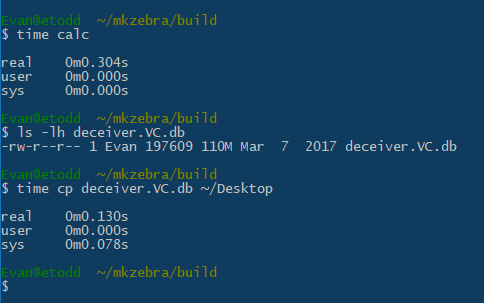
I do not know what calc.exe does for these infinite 300 ms, but you can draw your own conclusions from a two-minute study: calc.exe starts the Calculator.exe process, and one of the command line arguments is called "-ServerName".
Tell me, calc.exe "works fine"? Does adding to the server make it all easier, or just slow down and complicate it?
I do not want to be distracted from the topic. The point is that I want to think about the task before me and about the data related to it, and not about classes with interfaces. One of the objections to this way of thinking is that "this is too different from what I know."
Problem number 4: lag
Now I will briefly tell you about that part of the story in which the network code somehow works.
I immediately had problems with network latency. Games must respond to players instantly, even if the receiving package from the server takes 150 ms. Especially useless in a lagging network of bullets and shells. They can not aim.
I decided to reuse these 14 MB copies of the world. When the server receives a command to fire a shot, it rewinds the world back 150 ms to the moment the player was in when he pressed the shooting button. Then the server simulates the projectile and rewinds the world forward step by step until it coincides with the current state. And here he creates a shell.
As a result, my client instantly creates a fake shell, and then, when he receives information from the server that the shell has been created, replaces it with a real one. If everything goes well, then it should be in the same place due to the magic of the server time flywheel.
This is how it works in practice. A fake shell appears instantly, but passes right through the wall. The server receives a message and rewinds the projectile forward to the part where it hits the wall. 150 ms later, the client receives the packet and sees the effect of particles of hit.
The problem with the network code is that each mechanic requires its own approach to lag compensation. For example, in my game there is the ability "active armor". If players react quickly enough, they can reflect the damage back into enemies.
This ability falls apart in cases with a high lag. By the time the player sees that the projectile hits his character, the server has already registered a hit 100 ms back. But the package has not even reached the client. This means that we must anticipate the upcoming damage and react well before it hits. Watch the video above and notice how early I had to press a button.
To fix this, the server implements what I call “damage buffering”. Instead of instantly applying damage, a server for 100 ms (or any time it takes for the full path to the client and back) writes the damage to the buffer. At the end of this time, he either applies the damage, or, if the player has reacted, reflects it back.
Here is what it looks like in action. You can see a delay of 200 ms between the hit of a projectile and the application of damage.
Here is another example. In my game, players can throw themselves at enemies. With a perfect hit, the enemies die instantly, but the sliding blows they reflect and send you flying in the following way:
In which direction should the player bounce? The player needs to simulate a rebound even before the server finds out about it. The server and client must agree on the direction of the rebound, otherwise they will become out of sync, but they do not have time to exchange data in advance.
At first I tried to discretize the collision vector, so that only six possible directions remained. So I increased the likelihood that the client and server would choose the same direction, but still it did not guarantee anything.
As a result, I implemented another buffering system. When recognizing a hit, both the client and the server go into a “buffer” state in which the player stands and waits for the remote host to confirm the hit. To minimize jerks, the server always relies on the client in determining the direction of the rebound. If the client does not confirm the hits, the server acts as if nothing had happened, and continues to move the player along his original trajectory, rewinding him forward to compensate for the time during which he waited for confirmation.
Problem number 5: jitter
My server sends packets 60 times per second. But what will happen to the players whose computers give a higher frame rate? They will see a jerky animation.
The industry standard solution is interpolation. Instead of instantly using data received from the server. we buffer them for a short time and then smoothly mix them with the data we have.
In my previous attempt to implement network multiplayer, I tried to make sure that each object independently tracked its position data and smoothed itself. As a result, I got confused, and the system did not work as it should.
This time, since I can easily store the entire state of the world in a struct, it turned out that it was enough for me to write only two functions so that everything worked out. One function gets two states of the world and mixes them. Another function gets the state of the world and applies it to the game.
How big should the buffer delay be? Initially, I used a constant, but then I watched the video of Overwatch developers , in which they mention the adaptive interpolation delay. The buffer delay should smooth out not only the frequency of frames received from the server, but all fluctuations in the delivery time of the packets.
It was an easy win. Clients start with a small interpolation delay, and each time a packet is further interpolated, they increase their “lag counter”. When it exceeds a certain limit, clients ask the server to switch them to a higher interpolation delay.
Of course, such automated systems often act against the desire of the player, so you must add tuning capabilities to the algorithm!

Problem number 6: connect to the server in the middle of the match
Wait, I already have a way to serialize the entire game state. So what's the problem?
It turns out that serializing a new game state from scratch requires not one, but several packages. And to send a packet to the client it may take several attempts. It may take several hundred milliseconds to get a complete state, and as we have seen, it is an eternity. If the game is already underway, this time is enough to transfer 20 packets with new messages that the client is not yet ready to process, because it has not yet loaded.
The solution, you guessed it, is in another buffer.
I changed the message system so that it supports two separate message flows in one package. The first stream contains map data that is processed immediately upon receipt.
The second stream is the usual avalanche of game messages received while the client is loading. The client buffers these messages until it completes the download, and then processes them all until it overtakes the state of the server.
Problem number 7: partitioning issues
This part will be the most controversial.
Remember the worldly wisdom of game developers mentioned at the beginning of the article? "Never add a multiplayer network mode to a ready-made game."
It so happened that most of the network code is literally glued to this game with scotch tape. It is in its own source file for 5000 lines. The code is embedded in the game, writes some data to the memory, and then the game renders them.
Before you crucify me for this, wait a second. Which is better: group the whole network code in one place, or scatter it inside each game object?
I think both approaches have their advantages and disadvantages. In fact, in different parts of the game I used the first and second, for various reasons, from personal to technical.
But some design paradigms (* hhm * OOP) do not allow me to make such decisions. Of course, you need to insert the network code into the object! His data is private, so you still have to write an interface to access it. You may also have to use all sorts of intellectual transformations.
Conclusion
I'm not saying that you should write code like I did; just saying that this approach is still working for me. Examine the code and decide for yourself.
In each case, there is an objectively optimal approach to the solution, but people may disagree on which one. Strive to choose freely and be based on real constraints, and not on those that are due to a paradigm.
Thanks for reading. My game DECEIVER will appear in Kickstarter soon. Register on the site to download the demo!
Source: https://habr.com/ru/post/349732/
All Articles