Testing microservices: a reasonable approach
Driving force of microservices
The ability to develop, deploy and scale various business functions independently of each other is one of the most publicized advantages of switching to a microservice architecture.
While the rulers of thoughts are still unable to decide whether this statement is true or not, microservices have already managed to get into fashion - and to such an extent that for most startups they de facto have become the default architecture.
')
However, when it comes to testing (or, worse, developing ) microservices, it turns out that most companies still have an attachment to the antediluvian method of testing all the components together . Creating a complex infrastructure is considered a prerequisite for end-to-end testing, in which a test suite for each service must be performed — this is done to make sure that no regressions or incompatible changes appear in the services.
From translators. AT The original article by Cindy Sridharan uses a large number of terminology for which there are no well-established Russian counterparts. In some cases, used Anglicisms are used, it seems reasonable to us to write them in Russian, and in disputable cases, in order to avoid misinterpretation, we will write the original term.
Today, the world has no shortage of books and articles on best software testing practices. However, in our today's article we will focus solely on the topic of testing backend services and will not cover testing of desktop applications, systems with special technical security requirements, tools with a graphical interface and other types of software.
It is worth noting that different specialists put different meanings into the concept of a “distributed system”.
In our today's article, a “distributed system” refers to a system consisting of multiple moving parts, each of which has different guarantees and types of failures, these parts working together in unison to implement a specific business function. My description may be very remotely similar to the classical definition of distributed systems, but it applies to the systems I regularly come across with - and I’m ready to argue that it is the very majority of us that develop and support such systems. Further in the article we are talking about distributed systems, which are now called “microservice architecture”.
"Full stack in a box": a cautionary tale
I often have to deal with companies that are trying to fully reproduce the topology of services locally on developers' laptops. I had to face this delusion in person at the previous place of work, where we tried to deploy our entire stack in a Vagrant box. The Vagrant repository was called the “full stack in a box”; As you might have guessed, the idea was that one simple vagrant up team should have allowed any engineer in our company (even front-end and mobile developers) to deploy absolutely the entire stack on their working laptops.
As a matter of fact, it was not a full-fledged micro - service architecture of Amazon scale , containing thousands of services. We had two backend services: a gevent-based API server and background asynchronous Python asynchronous workers who had a whole tangle of native dependencies that included a boost to C ++ - and, if the memory keeps me, it was compiled from scratch every time a new box is launched on Vagrant.
My first working week in this company was entirely devoted only to locally raising a virtual machine and defeating a great many mistakes. Finally, by the evening of Friday, I managed to get Vagrant to work, and all the tests worked successfully on my PC. Finally, I decided to document all the problems I had to face, so that other developers would have less such problems.
And what do you think, when the new arrival of the developer began to customize Vagrant, then he ran into very different errors - and I could not even reproduce them on my machine. Truthfully, this whole fragile design also breathed its last incense on my laptop - I was afraid to even update the library for Python, since the pip install once executed managed to break the Vagrant settings, and stopped running the tests when it started locally.
In the process of debriefing, it turned out that Vagrant had similar business with programmers from mobile and web development teams; troubleshooting Vagrant has become a frequent source of requests coming to the support team, where I worked then. Of course, someone can declare that we just had to spend more time on fixing Vagrant settings once and for all, so that everything “just worked”, in my defense I would say that the described story took place in a startup where and engineering cycles forever are not enough.
Fred Hebert wrote a wonderful review of this article, and made a remark that describes my feelings exactly:
... please start the cloud on the developer's machine is equivalent to the need to support the new cloud provider, and the worst of all possible, with what you just had to face.
Even under the condition that you follow the most modern methods of operation - “infrastructure as a code”, immutable infrastructure - an attempt to deploy a cloudy environment locally will not do you any good, commensurate with the efforts that you take to raise it and provide long-term support.
After talking with my friends, I found out that the problem described poisons life not only for those who work in startups, but also for those who work in large organizations. Over the past few years I have been able to hear a lot of jokes about how easily such a structure falls apart and how expensive it is to exploit its support. Now I firmly believe that the idea of deploying the entire stack on developers laptops is flawed no matter what size your company has.
In fact, a similar approach to microservices is equivalent to creating a distributed monolith.
Prediction for 2020: monolithic applications are back in fashion after people have become familiar with the shortcomings of distributed monoliths.
As blogger Tyler Trit notes:
He laughed heartily over the discussion of microservices on Hacker News . "Developers should be able to deploy the environment locally, everything else is a sign of bad tools." Well, yes, of course, wise guy, try running 20 microservice units with different databases and dependencies on your MacBook. Oh yeah, I forgot that docker compose will solve all your problems.
Everywhere the same thing. People begin to create microservices without changing their “monolithic” mentality, and this always ends in a real theater of the absurd. "I need to run all this on my machine with the selected configuration of services in order to test a single change." What happened to us ...
If anybody, God forbid, accidentally sneezes, then my code will immediately become not testable. Well, good luck to you with a similar approach. Even despite the fact that large-scale integration tests affecting a significant number of services are an anti-pattern, it is still hard to convince others. Switching to microservices means using the right tools and methods. Stop using old approaches in a new context.
On the scale of the whole industry, we are still tied to the testing methodologies invented in an era far from us, which is strikingly different from the reality in which we are today. People are still passionate about ideas like full test coverage (so much so that in some companies merge will be blocked if a patch or brunch with a new feature reduces the coverage of the code base with tests by more than a certain percentage), development through testing and complete end-to-end system-level testing.
In turn, such beliefs lead to the fact that large engineering resources are invested in the construction of complex CI pipelines and intricate local development environments. Quickly enough, the support of such an expanded system turns into the need to contain a team that will create, maintain, troubleshoot and develop the infrastructure. And if big companies can afford such a deep level of sophistication, then all the rest is better to just perceive the testing as it is: this is the best possible verification of the system. If we are wise in assessing the value of our choice and making compromises, this will be the best option.
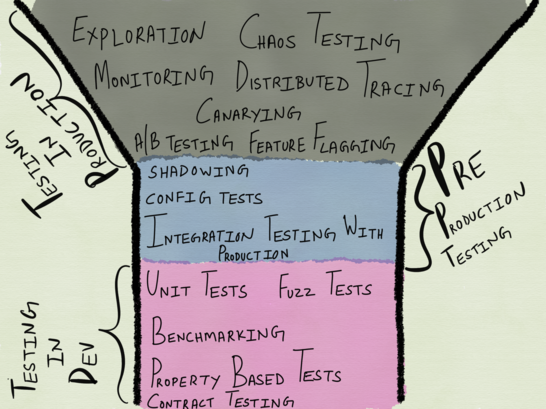
Spectrum Testing
Traditionally, it is assumed that testing is done before release. In some companies, there have been - and still exist - separate teams of testers (QA), whose main responsibility is to perform manual or automated tests for software created by development teams. As soon as the software component passes through QA, it is handed over to the operation team for launch (in the case of services), or released as a product (in the case of desktop applications and games).
This model is slowly but surely becoming a thing of the past - at least in relation to services; as far as I can tell from startups in San Francisco. Now the development teams are responsible for testing and for the operation of the services they create. I find this new approach to creating services incredibly powerful — it truly allows development teams to think about scale, goals, trade-offs and compensations across the whole range of testing methods — and in a realistic manner. In order to fully understand how our services function and to verify the correctness of their work, we obviously need the opportunity to choose the right subset of test methods and tools, taking into account the required parameters of availability, reliability and correctness of the service.
Just like with the language removed. Testing before deployment is a partial preparation for testing in production. To paraphrase your statement: testing before the deploem can teach, help to rehearse and strengthen the biased mental models of the system, and actually works against you in the lead, making you immune to reality.
By and large, the concept of "testing" can cover several activities that traditionally belong to the areas of "release engineering", operation or QA. Some of the methods listed in the table below are not strictly considered forms of testing — for example, the official definition of chaos engineering is classified as an experiment form; In addition, the above list is by no means exhaustive - it does not include vulnerability scanning ( penetrability testing ), penetration testing , threat modeling (simulation modeling ), and other testing methods. However, the table includes all the most popular testing methods that we encounter daily.

Of course, the taxonomy of testing methods in the table below does not quite reflect reality: as practice shows, some testing methods can fall into both categories at once. So, for example, “profiling” in it is referred to testing in production - however, it is often resorted to during development, so it can be attributed to testing in pre-production. Similarly, shadowing - a method in which a small amount of production traffic is driven through a small number of test instances - can be considered as testing in production (we use real traffic) and testing in pre-production (it does not affect real users).
Different programming languages have varying degrees of support for testing application in production. If you are writing to Erlang, then it is quite possible that you are familiar with the leadership of Fred Hebert on using virtual machine primitives for debugging production systems while they continue to work. Languages like Go come with built-in support for profiling heaps, locks, CPU and gorutin for any of the running processes (testing in production) or when running unit tests (this can be qualified as testing in pre-production).
Production Testing - Replacing Pre-Production Testing?
In my last article I paid a lot of attention to testing in post-production, mainly in terms of observability. Such forms of testing include monitoring, alerts, research, and dynamic instrumentation (inserting analyzing procedures into executable code). It is possible that such techniques as gating and the use of function flags can also be included in production testing ( feature flags , with which you can enable / disable functionality in code using configuration). User interaction and user experience evaluation — for example, A / B testing and real user monitoring also apply to production testing.
In narrow circles, there is a discussion that such testing methods can replace traditional testing in pre-production. Recently, a similar provocative discussion launched on Twitter by Sarah May . Of course, she immediately brings up several difficult topics in her, and I do not agree with everything in everything, but many of her comments correspond exactly to my feelings. Sarah states the following:
Popular wisdom states the following: before releasing a code, the full set of regression tests should turn green. You need to be sure that the changes do not break anything else else in the application. But there are ways to verify this without resorting to a set of regression tests. Especially now, with the flourishing of complex monitoring systems and understanding of the error rate on the operational side.
With sufficiently advanced monitoring and large scale, writing a code becomes his realistic strategy, his “push” in the prod and monitoring the number of errors. If as a result something in another part of the application breaks down, it will become very quickly understandable by the increased number of errors. You can fix a problem or roll back. Simply put, you allow your monitoring system to perform the same role as regression tests and continuous integration in other teams.
Many people perceived it as if it was worth removing testing before production as unclaimed, but I think the idea was not the point. Behind these words is a fact that many software developers and professional testers cannot accept - only manual or automated testing can often be insufficient measures - to the extent that sometimes they do not help us at all .
In the book " Lessons Learned in Software Testing " (there is no official translation into Russian, but there is an amateur one) there is a chapter called " Automated Testing ", in which the authors state that only a minority of bugs are found by automatic regression tests.
According to unofficial polls, the percentage of bugs that are detected by automated tests is surprisingly low. Projects with a significant number of successfully designed automated tests report that regression tests are capable of detecting 15 percent of the total number of bugs.
Automated regression tests usually help to detect more bugs during the development of the tests themselves than when performing tests at subsequent stages. However, if you take your regression tests and find a way to reuse them in different environments (for example, on a different platform or with other drivers), then your tests are more likely to detect problems. In fact, in this case they are no longer regression tests, since they are used to test configurations that have not been tested before. Testers report that this kind of automated tests can find from 30 to 80 percent of errors.
The book certainly has become a bit out of date, and I have not managed to find any recent research on the effectiveness of regression tests, but the fact that we are so accustomed to the fact that the best testing practices and disciplines are based on the absolute superiority of automated testing, and any attempt to doubt leads to the fact that you are considered a heretic. If I’ve understood something for myself from several years of observing how services fail, then this is what testing before production is the best possible verification of some small set of system guarantees, but at the same time, it alone will not be enough for checks of systems that will work for a long time and with frequently changing load.
Returning to what Sarah wrote about:
This strategy is based on numerous assumptions; it is based on the fact that the team has a complex operating system, which most development teams do not have. And that's not it. It is assumed that we can segment users, display each developer’s change-in-process on a different segment, and also determine the error rate for each segment. In addition, this strategy involves a grocery organization that feels comfortable when experimenting with "live" traffic. Again, if the team is already producing A / B testing for changes in the product on live traffic, this simply extends the idea to changes made by the developers. If you manage to do all this and get feedback on changes in real time - it will be just great.
Selection is mine, it seems to me, the largest block in the way of gaining greater confidence in the systems created. For the most part, the biggest obstacle to moving to a more integrated approach to testing is the necessary shift in thinking. The idea of habitual testing in pre-production is imparted to programmers from the very beginning of their career, while the idea of experimenting with live traffic is seen by them either as the prerogative of the operating engineers or as a meeting with something terrible like an alarm.
All of us are accustomed from childhood to inviolable holiness of production, with which we are not supposed to play, even if it makes it impossible for us to check our services, and all that remains to our lot are other environments that are only pale production shadows. Testing services in environments that are “as similar as possible” to production is akin to a dress rehearsal - it seems to be some benefit from this, but there is a huge difference between the performance in the full hall and the empty room.
Not surprisingly, this opinion was shared by many of the interlocutors of Sarah. Her answer to them was as follows:
They write to me here: “but your users will see more errors!” This statement is straightforwardly composed of unobvious delusions - I don’t even know where to start ...
Shifting responsibility for finding regressions from monitoring tests in production will result in users most likely generating more errors in your system. This means that you cannot afford to take a similar approach without a corresponding change in your code base - everything should work in such a way that errors are less noticeable (and have a smaller effect) on your users. In fact, this is a useful pressure that can help make your users' experience much better. Some people write to me that “users will generate more errors” -> “users will see more errors” -> “you don't care about your users!” No, this is absolutely not true, you just think wrong.
Here it hits the very point. If we transfer regression testing to post-production monitoring, then such a change will require not just a change of mindset, but also a willingness to take risks. More importantly, a complete revision of the system design is required, as well as serious investments in advanced release engineering practices and tools. In other words, here we are talking more than just about architecture with regard to failures - in fact, there is programming with regard to failures . While the gold standard has always been programming software that runs smoothly. And here the overwhelming majority of developers will definitely feel uncomfortable.
What to test in production, and what - in pre-production?
Since service testing is represented by a whole spectrum, both forms of testing should be taken into account during system design (and this implies both architecture and code). This will make it possible to understand what system functionality will definitely need to be tested before production, and which characteristics of it, more like a long tail of features , should be investigated in production using appropriate tools and instruments.
How to determine where these boundaries lie, and what testing method is suitable for a particular system functionality? This must be decided together by development and operation, and, again, this must be done at the system design stage. The top-down approach as applied to testing and monitoring after this stage has managed to prove its inconsistency.
Hiring a “SRE team” will not give additional reliability to your services. The top-down approach to reliability and stability does not work — a bottom-up approach is needed here. To achieve these goals, you must believe in SWE instead of continuing to flirt with exploitation.
Charity Majors made a report last year at Strangeloop , where she said that the distinction between observability and monitoring comes down to “known unknowns” and “unknown unknowns”.
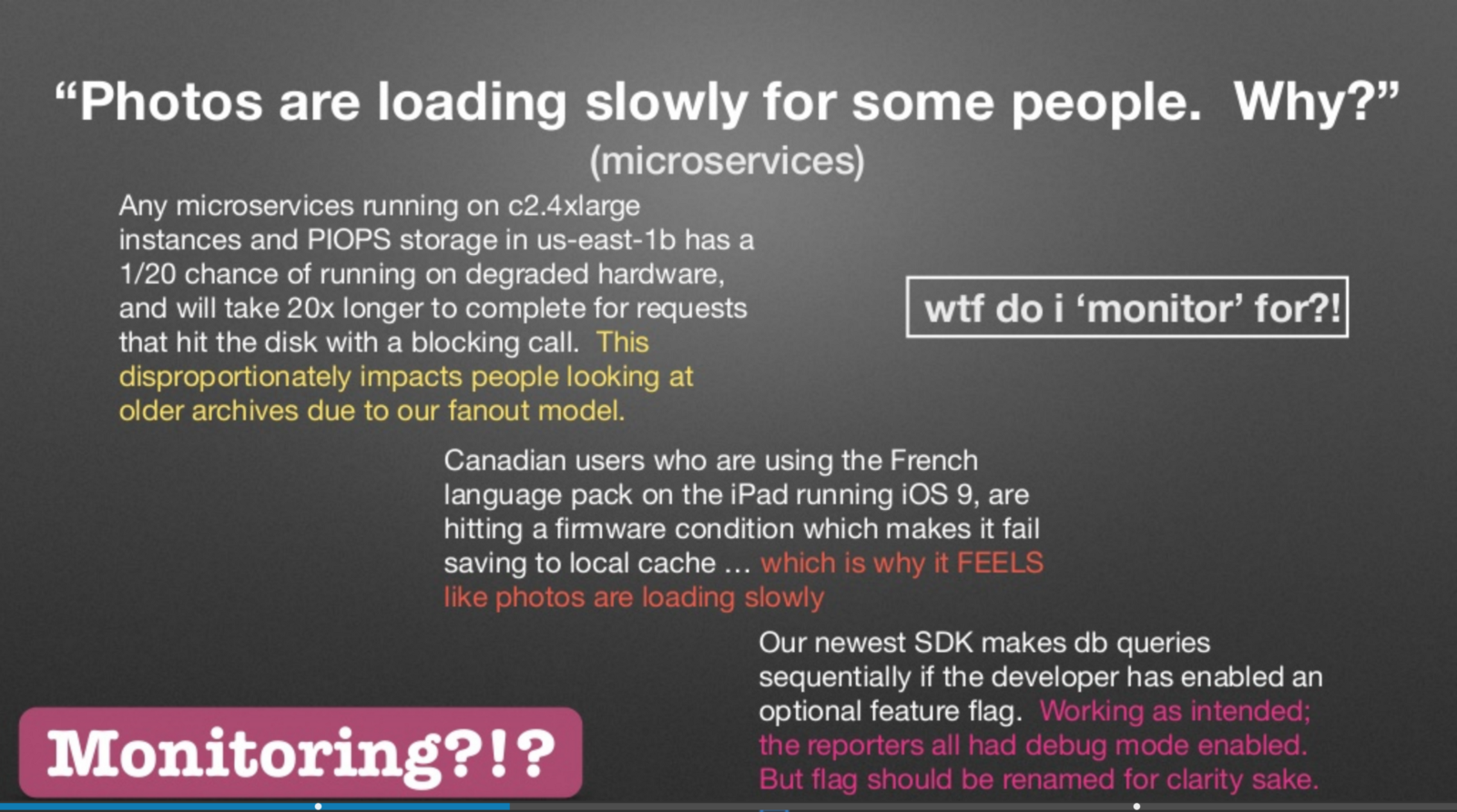
Slide from Charity Majors report on Strangeloop in 2017
Charity rights - the problems listed on the slide are not what you would ideally want to monitor. Similarly, these are not the problems that you would like to test in pre-production. Distributed systems are pathologically unpredictable, and it is impossible to envisage all the possible quagmires of the swamp, which may contain various services and subsystems. The sooner we reconcile with the fact that the very attempt to predict each way that a service can be performed, followed by writing a regression test case, is a foolish venture, the sooner we begin to engage in less dysfunctional testing.
As Fred Hebert noted in his review of this article:
... as a large service using many machines grows, the chances that the system will never be 100% efficient will increase. There will always be a partial failure in it somewhere. If tests require 100% performance, then please note - you have a problem.
In the past, I argued that “monitoring everything” is an anti-pattern. Now it seems to me that a similar statement applies to testing. You can not, and therefore should not try to test absolutely everything . The SRE book states that:
It turns out that after a certain point, an increase in reliability affects the service (and its users), instead of making life better! Extreme reliability has its price: maximizing stability limits the speed at which new functions are developed and the speed at which they are provided to users, and significantly increases their cost, which in turn reduces the number of functions that a team can implement and offer to users.
Our goal is to find obvious boundaries between the risk that the service will take on and the risk that the business is ready to bear. We strive to make the service reliable enough, but not more than what is required of us.
If you replace “reliability” with “testing” in the quote above, the advice from this will not cease to be less useful.
However, it is time to ask the following question: what is better for testing before production, and what after?
Exploratory testing is not intended to be tested prior to production.
Exploratory testing is an approach to testing that has been applied since the 80s. It is practiced mainly by professional testers; This approach requires less training from the tester, allows you to find critical bugs and has shown itself "more stimulating at the intellectual level than the execution of script tests . " I have never been a professional tester and have not worked in an organization that has a separate testing team, and therefore I learned about this type of testing only recently.
In the already mentioned book “ Lessons Learned in Software Testing ” in the chapter “ Think like a tester ” there is one very sensible piece of advice that sounds like this: to test, you must research .
To test something properly, you need to work with it. You have to figure it out. This is a research process, even if you have the perfect description of the product. As long as you do not explore this specification, scrolling through your head or working with the product itself, the tests you decide to write will be superficial. Even after you study the product at a sufficiently deep level, you will have to continue the study for the sake of finding problems. , , .
— , . ; , , .
«» «», , , , — , - .
, , , . , :
— . . . , . . .
: , , , .
: , , , , .
: , , , « », .
, , , , , , . , ; .
, , , - , . , , , , , / .
, . . , «» . , , , .
, . , — , — , .
, — . , , — . , «» , — , .
1000%, . , , ( , S3zure). — . «», Ops. .
( !) . , ; - , « ».
, :
- ;
- ;
- .
, :
- , ;
- 0 ?
- ?
- ;
- service discovery ?
- ?
- , ;
- graceful restart ;
- — — ;
- (, , event driven , , );
- - (- ).
, . , - .
( ) . , , :
- Consul ( « », , );
- , RPC- TTL;
- Confluent Python Kafka Python;
- pgbouncer , ( LIFO) , Postgres.
, :
, « » (, , « ») .
-
, , — .
. . , , — .
, ( , , ); , , . , — , , .
, — , , , — , .
, — , — . -, , ( , , , ), , «-» , «-» .
, , . , , , , .
, . - , . , - , , , .
, , .
-
- , , - . RPC-, .
, , , .
, () , , - . , ( JSON, , ), , - . - .
, « Succeeding with Agile » ( «Scrum. »), « Building Microservices: Designing Fine-Grained Systems ». -, , ( ), UI ( end-to-end ). , , , .
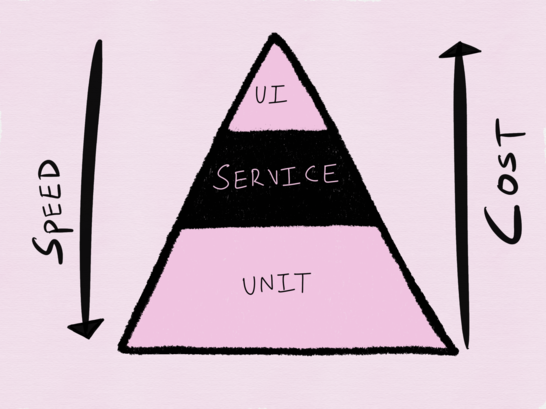
, . , , .
, ( , , ) - ( -), stateful- . , — — I/O ( , ), .
I/O
At PyCon 2016, Cory Bandfield presented a wonderful report where he argued that most libraries make the mistake of not separating protocol parsing from I / O — which ultimately makes both testing and code reuse difficult. This is indeed an extremely important idea, with which I absolutely agree.
However, I believe that not all types of I / O can be considered equal. Protocol development libraries, RPC clients, database drivers, AMQP clients, and others all perform I / O, but they all use different forms of I / O with different rates , which are determined by the limited microservice context.
For example, let's take testing microservice, which is responsible for managing users. In this case, it is more important for us to be able to check whether users have been successfully created in the database, rather than testing whether HTTP parsing works as it should. Of course, a bug in the HTTP parsing library can be a single point of failure for this service, but at the same time HTTP parsing plays only a supporting role in the general scheme, and it is secondary to the main duty of the service. In addition, the library for working with HTTP is the part that will be reused by all services (and therefore in this case, fuzzing can be of great benefit), it should become a common abstraction . As you know, the best method to find a balance when working with abstractions (even the most "full of holes") is, albeit reluctantly, to trust the promised service contract. Let such a decision be difficult to call an ideal way out, as for me, this compromise has every right to exist, if we are going to release at least something.
However, when it comes to microservice itself, the abstraction, which it is in relation to the rest of the system, includes state transitions that are directly mapped to a certain part of the business or infrastructure logic, and therefore this functionality must be tested at the level of a sealed unit.
Similarly, imagine that we have a network proxy server that uses Zookeper and service discovery to balance requests to dynamic backends; in this case, it is much more important to be able to test whether the proxy can correctly respond to the watch trigger and, if possible, set a new control value. This is exactly what unit is to be tested here.
The meaning of all the above is that the most important unit of functionality of microservice is the abstraction underlying I / O, which is used to interact with the backend, and therefore should be the same sealed unit of basic functionality that we will test.
The most interesting thing is that despite all this, the overwhelming majority of the “best practices” of testing such systems refers to the underlying I / O microservice not as an inseparable part, which also needs to be tested, but as an obstacle that needs to be eliminated with the help of . Up to the point that all unit testing in our days has become synonymous with the active use of mocks.
Unit testing of such a critical service for I / O with mocks is in essence a “blocking” of testing services, because it sacrifices speed for accuracy and teaches us to think about the systems we create, the opposite of how they actually work. . Here I would go further and say that unit testing with mocks (we can denote it by the term “mock testing” ) is for the most part a test of our incomplete, and most likely erroneous, mental model of the operation of critical business components of the system, on which we work, as a result of which we become hostages of one of the most insidious forms of bias.
I like the idea that mocking affects our thinking. Moki behave predictably, but networks and databases do not.
The biggest drawback of mocks as a testing tool is that when simulating a successful execution, as well as a failure, the mocks remain a programmer's mirage, never reflecting at least an approximate picture of the real world of production.
Here, some will say that it is better to cope with this problem in another way: track all possible failures at the network level and add them to the test set with additional mocks, which will cover all these test cases that we previously ignored. Well, besides the fact that considering all possible problems seems to be poorly possible, this approach is likely to lead to a bloated set of tests with a large number of different mocks that perform similar functions. And in the end, all this in turn will lay a heavy burden on the shoulders of those who in the future will be engaged in supporting this good.
If we are talking about support for tests, another weakness of mocks actively manifests itself here: they make the test code too detailed and difficult to understand. From my experience, this is especially true when whole classes are converted into mocks, and the implementation of mocks is embedded in the test as a dependency only so that the mock can confirm that a particular class method has been called the nth number of times or with certain parameters. This form of mocks is now actively used when writing tests to test the behavior of services.
My synopsis of using mock objects in tests is that you’ll end up testing implementation, not behavior, in almost all test cases. This is stupid: the first rule of a tautology club is the first rule of a tautology club.
In addition, you increase the size of your code base at times. In the end, you will be much harder to make changes.
Reconcile with mocking
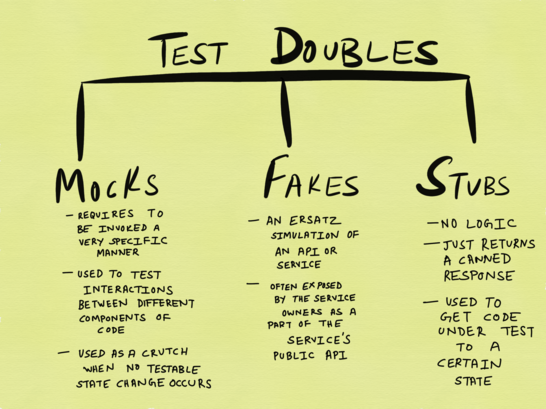
From the Google blog about testing, post about double objects
Moki, stubs and fakes are all kinds of so-called " test doubles ." Practically everything that I wrote before about moki is applicable to other forms of test twins. However, let's not go to extremes and argue that moki (and their variants) do not contain any advantages; similarly, not every unit test should always include I / O testing. In unit tests, it makes sense to include I / O only when the test involves a single I / O operation without any further side effects that we should prepare for (this is the main reason why I don’t see much point in testing the subscription publications in a similar way).
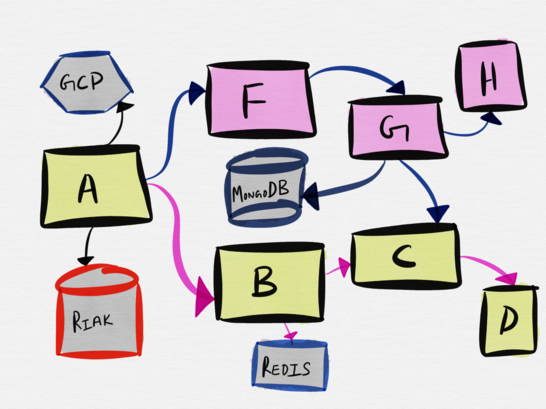
Consider the following topology of a very plausible example of microservice architecture.
The interaction of service A with service B includes the communication of service B with Redis and service C. However, the smallest unit tested here is the interaction of service A with service B , and the easiest way to test this interaction is to deploy a fake for service B and test the interaction of service A with a fake . Contract testing can be especially useful for testing such integrations. Soundcloud is known for using contract tests to test all of its 300+ microservices.
Service A also communicates with Riak. The minimum test unit in this case includes the actual message between service A and Riak , so it makes sense to deploy a local Riak instance for the duration of the test.
When it comes to integration with third-party services like GCP, AWS, Dropbox or Twilio, ideally, the bindings or SDKs provided by vendors already have some good fakes that we can use in our test suite. Even better, vendors offer the ability to make real API calls, but in test mode or in the sandbox, as this allows developers to test services in a more realistic manner. These services include Stripe, which provides test tokens.
So, we found out that test “twins” deserve their place in our testing spectrum, but don’t dwell on them as the only means of unit testing or overdoing them.
The inconspicuous advantages of unit tests
Unit testing is not limited to the methods we discussed with you. It would be an omission to start discussing unit tests and not talk about property-based testing and fuzzing. Popular with Haskell’s QuickCheck library (which was later ported to Scala and other languages) and the Python Hypothesis library, property-based testing allows you to run the same test several times with different inputs without the need for a programmer to generate a fixed set of input data test case. Jessica Kerr made an excellent report on this topic, and Fred Hebert even wrote a whole book on this topic . In his review of this article, Fred mentions various types of approaches to various tools for property-based testing:
Regarding property-based testing, I will say the following: most of the tools bring it closer to fuzzing, but if you try a little, you can conduct it in the manner of a white-box test with a more subtle approach. In other words, if fuzzing consists in finding out whether a given part of the system “falls” or not, then property-based testing helps to check whether a certain set of rules or properties is always observed in the system. There are 3 large families of property tests:
- The Haskell QuickCheck family . This variation is based on using type information to generate the data on which the test will be performed. The main advantage: tests become less, and their coverage and usefulness - higher. Disadvantage: hard to scale.
- Erlang QuickCheck family . This variation is based on dynamic data generators, which are composite functions. In addition to the functionality of the previous type, stateful modeling primitives are available in such frameworks. They look more like model checking, because instead of searching through a search, probabilistic searches are performed. Accordingly, here we move away from fuzzing to the “model checking” zone, which is a completely different family of testing methods. I used to listen to the reports, the authors of which drove such tests to different cloud providers and used them to detect “iron” errors.
- Hypothesis : a unique approach to business. It is based on a mechanism similar to fuzz ing, in which data is generated on the basis of a stream of bytes, which can become lighter / heavier on a scale of complexity. It has a unique device and is the most applicable tool among those listed. I'm not very familiar with the way the Hypothesis works under the hood, but this tool can do much more than its Haskell counterparts.
Fuzzing, on the other hand, allows you to feed in advance invalid and garbage input data to the application in order to make sure that the application terminates with a crash as planned.
For fuzzing, there are a large number of different tools: there are fuzzers that are based on coverage, such as afl , as well as the address sanitizer , thread sanitizer , memory sanitizer , undefined behavior sanitizer and leak sanitizer tools, and others.
Unit testing can provide other benefits besides the usual verification that something works as intended for a particular input dataset. Tests can act as excellent documentation for the API exposed by the application. Languages like Go allow you to create example tests , in which functions that begin with Example instead of Test live alongside normal tests in the _test.go file in any of the selected packages. These sample functions are compiled (and optionally executed) as part of the test suite of the package, and then displayed as part of the package documentation and allow them to run as tests. The meaning of this, according to the documentation , is as follows:
This approach ensures that when the API changes, the package documentation will not become obsolete.
Another advantage of unit tests is that they put some pressure on programmers and designers in terms of API structuring, which would be easy for third-party services to work with. A remarkable post “ Discomfort as a means of motivating changes ” was published on the Google blog about testing, which sheds light on the fact that the requirement from the authors of the API to provide its implementation in the form of fakes allows them to better understand those who will work with this API and reduce the number of pain in this world.
In 2016, I was a class organizing Python Twisted mitaps in San Francisco. One popular topic for discussion was that it was a mistake to make the event loop in Twisted global (which Python 3 would later reproduce in the asyncio implementation, which would terrify the Twisted community) and how much easier testing and use would be if Reactor ( which provides basic interfaces for all types of services, including network interaction, flows, event scheduling, and so on) was transmitted to consumers as an explicit dependency.
However, a reservation is required here. As a rule, a good API design and good testing are two completely independent goals, and in reality (however, this is not recommended ) it is not difficult to design an incredibly convenient and intuitive API that lacks testing. However, much more often, people design an API that tries to achieve 100% test coverage (no matter how you measure it, by code lines or otherwise), but it turns out to be a prematurely abstracted DRY artifact . Although mock-based unit testing is the way to a good API design, it does not guarantee that your code will run properly.
VCR - we cache or repeat test responses
Excessive use of mocks / fakes / test twins / stubs is not the most reliable choice of testing techniques (although sometimes this does not go away), but when VCR-style caching comes into play, debugging non-passing tests becomes even harder.
Given the general insecurity of mocks, I find it absolutely ridiculous for some individuals to go even further to write answers as fixtures ( test fixture ). I find this method ineffective, both as a way to accelerate integration tests (although they are integrational if such testing techniques are used) and in terms of accelerating unit tests . Excessive overload of your brain while debugging failed tests with a heap of extra layers is not worth the time spent on it.
Integration testing
If unit testing with mocks is so unreliable and implausible, does this mean that integration testing is in a hurry for us to help and save us?
Here is what I wrote on this issue in the past:
This may sound too radical, but good (and fast) integration testing (local and remote) for a couple with good instrumentation often works better than the desire to achieve 100% test coverage.
At the same time, large integration tests for each available service that interacts with ours do not scale very well. It will be slow by default, and integration tests bring maximum benefit only when feedback from them can be obtained quickly.
We need the best test patterns for distributed systems.
Some readers of my Twitter have pointed out to me that these two statements of mine are in conflict with each other; on the one hand, I urge to write more integration tests instead of unit tests, on the other hand I assert that integration tests do not scale well in the case of distributed systems. These points of view are not mutually exclusive, and perhaps my first statement really requires a detailed explanation.
The point here is not at all that unit-testing is replaced in this case by end-to-end end-to-end tests; , «», , - , « », .
. , , , I/O. , , . , Uber, , , , , , , , c , : « ». , , , , , . , , -.
Event Sourcing — , Kafka. ( Command and Query Responsibility Segregation ) - 10 . ( writes ) ( reads ). , , , .
, , , , (, , ).
; , .
, / . «» , «» ( ) , . , .
, , , . « ».
, , . , - ( I/O ), , — . :
, , , ( , observability ). , — ; , , — , , . , , .

, , , , . Consul . — API- ( ) , G .
, Macbook API, ( , ). . , , , , , .
-
80% API MongoDB, - MongoDB. E — LuaJIT, , , API. E , (watch) Consul , - Consul, , «» , . -, .
G, H, I K ( ).
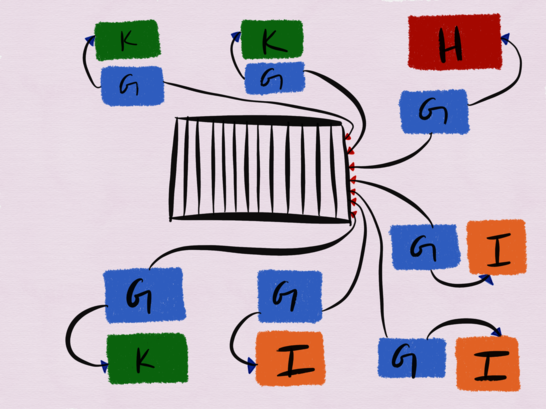
G — Python, Kafka , , H, I K. G , H, I K, - 15-20 G ( 7). G — , , Kafka, H, K I.
H, K I — . H — nginx ( , Openresty ) ( ), , LevelDB write through cache ( ) , MySQL, , Go. K — HAProxy, I — HTTP- LuaJIT. , H, I K Kafka. , .
: (eventual consistency) ?
, , , end-to-end , Kafka G, H, I K . , « », , , :
- K — HAProxy ( HAProxy )
- H ( ) , - . , , - nginx H . H , - nginx «» , - , « »:
, NGINX , .
, HTTP2, «» , , , nginx . , H, I K — , .
, , . , , - , .
Service Meshes
, service meshes — , , «» . staging staging ( , HTTP- , IP- ), , . - .
, «» — . , Facebook . https://t.co/zMrt1YXaB1
Service Meshes .
, , . ., , «» — .
, . , . , , , , .
Conclusion
. , , , , ( , ), . , .
«», . «» . !
, , , « » . .
, — , — , .
We love such large-scale conceptual discussions, especially seasoned with our own examples, because not only individual developers, but almost all project teams are involved in solving such issues. We invite experts, whose experience already allows us to discuss philosophical questions of software development, to speak at RIT ++ 2018 .
Source: https://habr.com/ru/post/349632/
All Articles