Key transparency & Coniks to protect data structures
Alexey Ermishkin ( Scratch )

Before, I would like to explain a little bit about my attitude to the blockchain topic. I really love blockchain technology, recently everything that revolves around - SEO, cryptocurrency, smart contracts - everything is fine and excellent, but this is not all that a blockchain can do, and this is not all of its philosophy.
Blockchain is not only smart contracts and cryptocurrencies , which generally began to be reduced to the word "crypto". For me, as a cryptographer, this is especially hard on the ears.
')
Blockchain - not necessarily distributed systems. If you look at the definition of the word "Blockchain", this is a distributed database with consensus and everything else. No, it is absolutely not.
Blockchain technology existed 4 years before Bitcoin . You probably also use it, but do not realize that this is a blockchain. This is Git , and I will prove it very easily.
Below we present to your attention the decoding of the report by Alexey Ermishkin ( Scratch ) on the use of the blockchain, as a mathematical concept, for organizing a database with control of the integrity of the content .
The topic of this article we consider the example of communication between traditional Alice and Bob. In this case, these are not people, but robots, because when they want to communicate via a secure channel, for example, some sensors or small devices, they have far fewer opportunities to fully use everything that is already written for people for example, TLS certificates, SSH, VPN and everything else.
So Alice wants to talk to Bob. Unfortunately, she only knows his name or some kind of identifier, for example, mail or phone. To enable it to obtain its public key, a key server is used. But storing keys in a simple key-value-storage is absolutely insecure, since they can be removed from there, replaced or returned to the existing key answer 404, as if it is not there.

Therefore, the server must have several very important and unique properties:
1. Presence / absence of a key
The server, of course, must be able to return the keys that are in it, but in addition to this, it must strictly prove that there is no key in it. Until today, this task has not been solved by anyone.
2. Key history
Bob and Alice should be able to track the history of the keys. That is, when Bob changes his key to a new one, he has to make sure that, over time, no one did anything with his keys: he did not replace, did not delete.
3. One result for all
Alice and Bob should see the same state in which the database is located. A malicious server (if it is one) can show one key history to Bob, and Alice a completely different one, which will have a completely different key. This is completely unacceptable from a security point of view.
4. Obfuscation of Identity
And the last, though not the most important thing, we want hackers and just people who look at it from outside, for example, auditors, could not know anything about whose identifiers and what data lie in the database. But at the same time, the server is obliged to strictly prove everything to customers who use its services.
Of course, after Alice and Bob learned each other’s keys, a secure communication protocol is needed. Today, if you only have public keys, you are left alone. You will have to write some crutches. They are good and bad, but most often people write them themselves.
Blockchain
Let us return to the blockchain topic, so the blockchain existed 4 years before the advent of Bitcoin.

If you look at how git works and the commit tree, you can clearly see that each commit is, in principle, a block. It has a hash link to the previous commit. Please, here is the Block and here is the chain !
For example, if we talk about smart contracts, then Git Hooks is their prototype, that is, it is the logic that works in the blockchain and influences how it is formed. Enthusiasts even wrote a comic cryptocurrency - gitcoin . This is just a git repository with Git Hooks, which adds coins to someone who launches a commit whose hash is smaller than the hash of a previous commit — a sort of proof-of-work a la Bitcoin.
Thus, for me, the blockchain is more of a mathematical concept: a database, not necessarily distributed, but necessarily c monitoring the integrity of the content.
Key transparency & Coniks
Today we will talk about the technology that was born at the junction of the other two, Coniks and Certificate transparency.
Coniks is an academic project by researchers from Princeton and Stanford who have decided to help people safely store, in particular, public keys (and not only).
Then Google took a closer look at this project, and at the stage of a not very realized concept, he forked and crossed with his technology Certificate transparency , which is a large log containing all the certificates ever issued so that some employee could The certification authority would not issue a test certificate for the Google.com domain.
These technologies solve the problem of secure storage of public keys, which are tied to user IDs, but in addition to public keys, you can actually store anything.

Merkle tree
Next, let's talk about a single algorithmic structure, about which those who are already familiar with the blockchain, have probably heard - this is the Merkle tree. Of course, this structure has nothing to do with the German Chancellor. Ralph Merkle is a mathematician.
Few people know that the popular Diffie-Hellman public key exchange protocol actually has a full name — the Diffie-Hellman-Merkle protocol. Merkle came up with the whole theoretical basis for him, and Diffie and Hellman wrote a practical implementation. The protocol is named after them, but they themselves say that this is still the Diffie-Hellman-Merkle protocol.
What did Merkle come up with?

For example, there is an array of transactions (files). Each of these files (here 16) are considered hashes. Then they are taken in pairs and each pair is once again considered hashes. This is repeated until one hash is obtained, which is called the root of the tree and depends on all the hashes that were below.
This structure is remarkable in that in order to prove that a file is in this tree, you need only 4 intermediate hashes (blue blocks in the diagram). When we provide them to the client, he hashes them in pairs in pairs and as a result gets the same root. This root usually lies in the block header, and all transactions together with the tree can be located, in principle, separately.

Another great feature of this tree is that, no matter how large, the root (since this is a hash) is always the same size. If the hash is 256 bits, the root will always be 32 bytes.

Therefore, most often light Bitcoin nodes or some other blockchain simply exchange trees. This is enough to trace the integrity of the blocks. If you need any specific transaction from the block, you need to download this block entirely and check if it is there, such a tree works fine to prove that there is something in it.
But what would we think of to prove the absence?
Let's expand our consciousness a bit and imagine that the tree contains all possible hashes from zero to the very last, consisting of all binary ones.
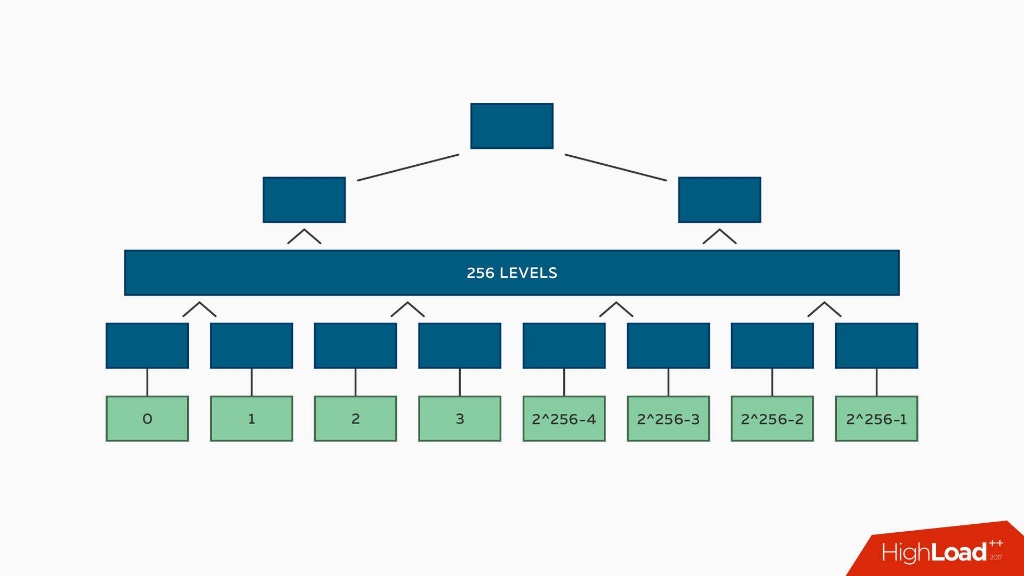
If the hash is 256 bits, then all the hashes from 0 to 2,256-1 are in the tree. This is such a large number that I think that not a single person, even engaged in HighLoad, is able to cheat such a tree. What to do, how to use it.
Sparse Merkle Tree
In fact, almost all the leaves of such a tree will be empty, that is, nothing will lie in them. Level 2 hashes will most often be two-0 hashes, level-3 hashes will be two hashes from two 0 hashes. Such a tree can be emulated, despite its huge size, and only those parts that really contain data are used.
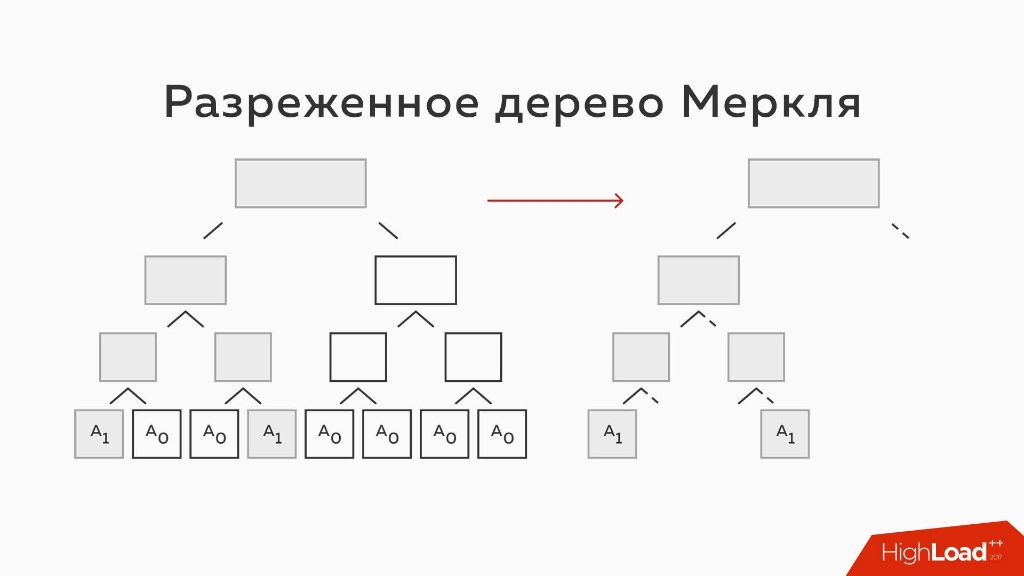
Presence / absence of a key
As shown in the diagram, parts that are not used are simply not stored. Instead of nodes that are empty parts of the tree, a stub is put — for example, a node marked as empty. When we reach it, we understand that there is nothing there. Since this is a balanced binary tree, and places for all hashes are reserved in it, the path to each hash will be that same hash. For example, the first bit 1 - we go to the left, 0 - to the right, etc.
The fact that the path to each hash is the hash itself makes it possible to strictly prove not only the presence but also the absence of information in the database. We can provide a path to the nearest empty node, and say: “We have such a path and such a root of the tree, there is nothing further - you can check everything!” This will be strict evidence of the absence of information in this node.

Since the tree is huge, but at the same time there is nothing in it, it is called a discharged Merkle tree and, as we have said, allows us to prove the presence and absence of information in the database. Now it’s just not fair to answer 404 to a public key request!
You can put some information into this tree and work with it over time. The blockchain will help us with this, of course .
Key history
Let's break time into epochs. For example, once every 5 minutes we will:
- collect all the changes that users want to make to this tree,
- apply them, re-counting the root of the tree,
- sign this root and previous.

We get the same blockchain, it's just not based on a lot of blocks, each of which has a small tree, but on one big Merkle tree. This allows you to build a key history that cannot be retroactively changed.
One result at all
Now we need to make sure that Alice and Bob see the same thing, i.e. so that the server does not provide different stories to different users. Make it very easy. First, you can get third-party auditors who would check the base. The database contains impersonal data, so there are no problems with it.
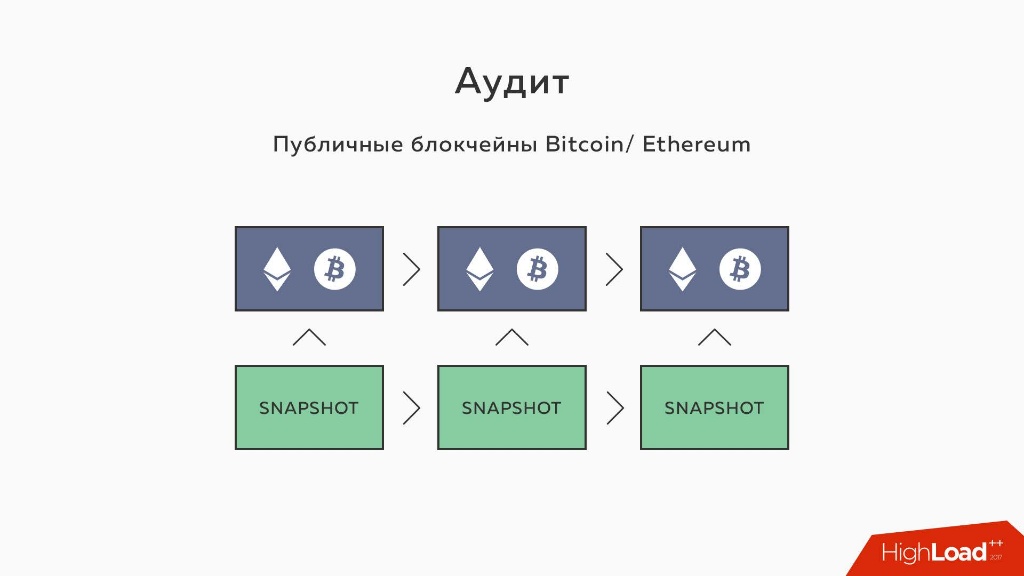
But you can also use public blockchains and, for example, simply put hashs from each epoch into the same Bitcoin, Ethereum, etc. The epoch behind the epoch we will put them there. This technology is called anchorage (anchoring).
We provide Alice with proof that at time X we had such a tree. She checks his hash in a public blockchain, and makes sure that everything is fine. And we achieve that all users at any time see the same thing.
Obfuscation Identity
We need not only to prove that everyone sees everything the same, but we also need to protect the user data that lies in our database. First of all, we protect the public keys themselves.

When Bob puts a key into the database, we add it to a random set of bytes, run it through a hash, and what happens is called an add-on (or commitment). It lies in a tree, and when someone asks us to prove that the structure of the tree is properly built, we provide him with this addition.
But when Alice asks us for the data of Bob, we show her the “random salt”, give the public key, she performs the same operations and makes sure that the place where the key lies in the database contains exactly what Bob put there, not someone else.

So, if someone cunning looks at this base and decides to find out what lies there, he will not see anything.
But this is not all, we must be able to hide the very name of Bob from the base. We can’t do this simply with the help of hashing, because every student can go through usernames with brute force. Therefore, they invented such a wonderful thing as the Verifiable Random Function .
Alice asks the server:
- Give me, please, the key of Bob, and tell me what index you put in this tree.
The server responds to it with some kind of absolute rubbish, from which Alice’s hair stands on end:
- What did you give me, server? How can you even say that?
- All OK! Here is my proof!

In essence, the server reads a digital signature on Bob’s name. But this is not an ordinary digital signature that we use every day, but deterministic . If you take any OpenSSL or crypto library and read the digital signature from any line 10 times, we get 10 different digital signatures. Here it is always the same. There are still a few added elements, but in principle it works that way.
Then the hash of this digital signature is used as an index in the tree for Bob. Thus, without having a private key, we don’t have a theoretical possibility at all (except the one that asymmetric cryptography is ever cracked) to find out whose name is on this index.
We can even at each iteration (for each epoch) add simply random, absolutely random hashes to the database and thus hide the true number of users that are in the database. Of course, the one who watches the database will know the maximum number, but it will be impossible to know exactly how many users came, and which of them changed which data.
Thus, Alice is happy, and Bob is safe, and we have learned how to protect the user data that we have in the database.
This key server is already there. You can download it by requesting Key transparency in GitHub Google. Of course, it is still in the “Proof of concept” stage, but this is already a working version. We are already starting to use it for storing users' public keys.
Summary
Key Transparency and Coniks allow you to:
- Prove both the presence and absence of records in the database.
- Monitor the integrity of information to account holders and their interlocutors.
- Hide data using Verifiable Random Function.
- Audit third parties without compromising user data.
- Unlike traditional blockchains, they have a very small proof size .
The maximum audit path, consisting of the hashes needed to prove the presence of an element in the tree, is 256 hashes. This is a couple of kilobytes, in contrast to those 150-200 GB that need to be downloaded in Bitcoin in order to make sure that the transaction is in such and such a block.
I think this is a truly unique thing that is worth exploring, developing and, of course, enjoying.
True, as I said, today everyone who has to work with clean private public keys has to write his crutches. Therefore, when WhatsApp rolled out its cryptography update, they, in addition to the messaging protocol, also implemented the protocol for the transport layer called Noise. We liked it very much, and we made an add-on over the Noise Protocol framework, which we called NoiseSocket. We will probably talk about it in future reports and articles.

About the speaker and his team
Alexey Ermishkin represents the company Virgil Security, which develops cryptographic solutions for developers and businesses, in particular, on an industrial scale implements E2E encryption. This is point-to-point encryption, when the sender knows the recipient's public key in advance, and in their opinion, this is the only correct way to ensure the security of the transmitted data.

Contacts:
» Virgilsecurity.com
» Github.com/virgilsecurity
» Twitter.com/virgilsecurity
Alexey will continue the topic at the upcoming DeCenter TokenConf , which will have twenty more no less steep reports and speakers. Have time to join , the train has almost moved.
Source: https://habr.com/ru/post/349448/
All Articles