How to predict an Oscar winner according to social networks or how I spent my day off
It was a snowy Sunday, moreover, forgiven, and in the morning it was decided to throw off the blanket and start preparing his body, swept away during the Maslenitsa, for the summer beach season. Peter is not very supportive of outdoor sports this season, the gym membership has ended, so after 5 km of cross-country skiing the energy required release.
Of course, it was not possible to simply stick to the Internet, and I remembered the idea of predicting the winner of the Oscar in 2018 , the results of which will be known very soon on March 4th. This idea was formed in communication with one interesting person, so thank him for the idea.
I didn’t want to mess with the formation of a data set, kaggle didn’t have one either, but I wanted to do something unusual and interesting. Adjusted the problem: to determine public opinion about the winner of the Oscar?
But in the beginning it is necessary to figure out what is going on in the film industry and who, at least, is nominated.
The 90th Oscar awards ceremony for merits in the field of cinema for 2017 will be held on March 4, 2018 in the Dolby Theater (Hollywood, Los Angeles). Comedian Jimmy Kimmel will hold the ceremony for the second year in a row. The nominees were announced on January 23, 2018 ( who cares ).
')
So, all the nominations are not interesting to me, so we will explore public attention in the following nominations: best film, best actor, best actress, best soundtrack. Denote the data for the preparation of requests.
But first you need to provide access to the Twitter API.
Since I did not have a data set, I had to think a little and formulate criteria for evaluating public opinion on Twitter:
1) The need to search and process messages distributed at the current time (resent), which will determine the changes in public opinion, trends. Use the Twitter API method for this.
2) The need to determine the potential distribution, i.e. I currently have 10 subscribers, I publish a message that retweets 2 of my subscribers, which have 25 subscribers each. T. o. the number of spreads is 2, and potentially possible is 10 + 25 + 25 = 60.
3) The need to determine the tone of messages, as well as the attitude of positive to negative. To do this, we form two dictionaries of positive and negative words. Using the Bayes formula (link), we define the conditional probability of the message tonality.
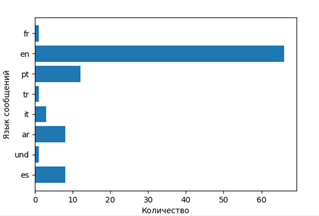
4) (Optional) Definition of message language. In different countries, cinema is perceived differently. We refer to the mentality.
Distribution of references
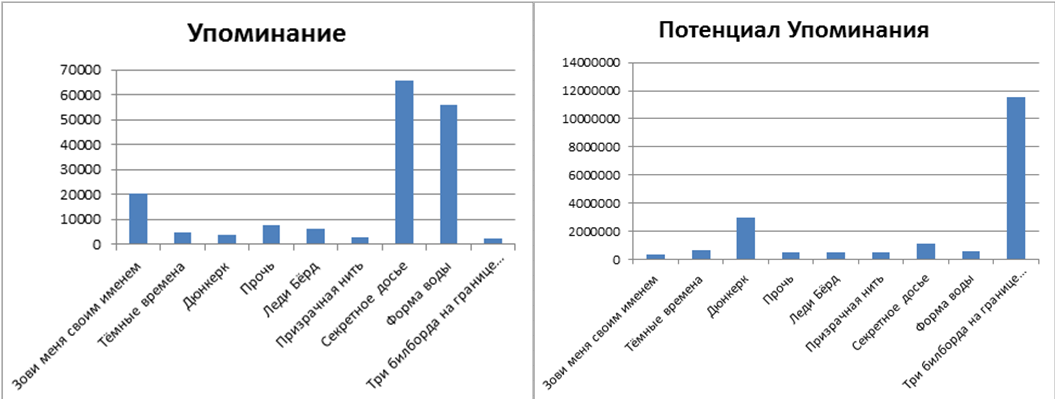
Attitude of Twitter users to nominated films
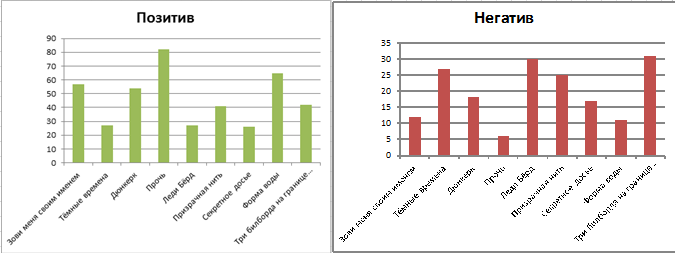
That is, find out about which films speak in which languages (respectively, and countries).
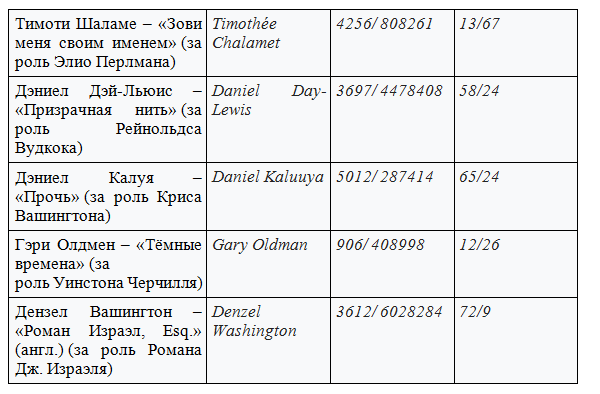
(presented in tabular form)
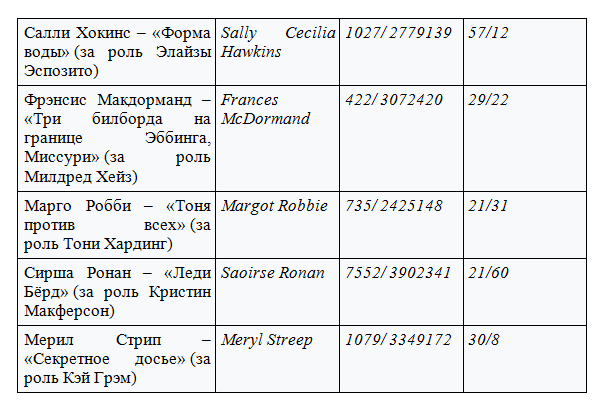
(presented in tabular form)
Of course, this “slice” of public opinion can only partly show an attitude to films. For more in-depth analysis, it is necessary to collect data from Twitter during the intermediate time, especially when information leads appear. But, at the moment, the leader of public opinion are: The form of water . I think even in the evening to see!
Also, social networks allow you to analyze and classify the audience. Reference to the repository and dictionaries for learning the tonality model .
Of course, it was not possible to simply stick to the Internet, and I remembered the idea of predicting the winner of the Oscar in 2018 , the results of which will be known very soon on March 4th. This idea was formed in communication with one interesting person, so thank him for the idea.
I didn’t want to mess with the formation of a data set, kaggle didn’t have one either, but I wanted to do something unusual and interesting. Adjusted the problem: to determine public opinion about the winner of the Oscar?
But in the beginning it is necessary to figure out what is going on in the film industry and who, at least, is nominated.
What is Oscar (version 20! 8)
The 90th Oscar awards ceremony for merits in the field of cinema for 2017 will be held on March 4, 2018 in the Dolby Theater (Hollywood, Los Angeles). Comedian Jimmy Kimmel will hold the ceremony for the second year in a row. The nominees were announced on January 23, 2018 ( who cares ).
')
So, all the nominations are not interesting to me, so we will explore public attention in the following nominations: best film, best actor, best actress, best soundtrack. Denote the data for the preparation of requests.
Nomination best movie
- Call me your name
- Dark times
- Dunkirk
- Away
- Lady bird
- Ghost thread
- Secret Dossier
- Water form
- Three billboards on the border of Ebbing, Missouri
Twitter as a public opinion survey platform
But first you need to provide access to the Twitter API.
CONSUMER_KEY = '' CONSUMER_SECRET = '' OAUTH_TOKEN = '' OAUTH_TOKEN_SECRET = '' auth = twitter.oauth.OAuth(OAUTH_TOKEN, OAUTH_TOKEN_SECRET, CONSUMER_KEY, CONSUMER_SECRET) twitter_api = twitter.Twitter(auth=auth) Since I did not have a data set, I had to think a little and formulate criteria for evaluating public opinion on Twitter:
1) The need to search and process messages distributed at the current time (resent), which will determine the changes in public opinion, trends. Use the Twitter API method for this.
tweet=twitter_api.search.tweets(q=(e1.get()), count="100") p = json.dumps(tweet) res2 = json.loads(p) 2) The need to determine the potential distribution, i.e. I currently have 10 subscribers, I publish a message that retweets 2 of my subscribers, which have 25 subscribers each. T. o. the number of spreads is 2, and potentially possible is 10 + 25 + 25 = 60.
i=0 while i<len(res2['statuses']): tweet=str(i+1)+') '+str(res2['statuses'][i]['created_at'])+' '+(res2['statuses'][i]['text'])+'\n' retweet_count.append(res2['statuses'][i]['retweet_count']) followers_count.append(res2['statuses'][i]['user']['followers_count']) friends_count.append(res2['statuses'][i]['user']['friends_count']) print u' ', sum(retweet_count) print u' ', sum(followers_count)+sum(friends_count) 3) The need to determine the tone of messages, as well as the attitude of positive to negative. To do this, we form two dictionaries of positive and negative words. Using the Bayes formula (link), we define the conditional probability of the message tonality.
def format_sentence(sent): return({word: True for word in nltk.word_tokenize(sent.decode('utf-8'))}) pos = [] with open("pos_tweets.txt") as f: for i in f: pos.append([format_sentence(i), 'pos']) neg = [] with open("neg_tweets.txt") as f: for i in f: neg.append([format_sentence(i), 'neg']) training = pos[:int((.8)*len(pos))] + neg[:int((.8)*len(neg))] test = pos[int((.8)*len(pos)):] + neg[int((.8)*len(neg)):] classifier = NaiveBayesClassifier.train(training) classifier.show_most_informative_features() 4) (Optional) Definition of message language. In different countries, cinema is perceived differently. We refer to the mentality.
stopwords = nltk.corpus.stopwords.words('english') en_stop = get_stop_words('en') stemmer = SnowballStemmer("english") #print stopwords[:10] total_word=[] lang=[] while i<len(res2['statuses']): lang.append(res2['statuses'][i]['lang']) w7=Label(window,text=u" ", font = "Times") w7.place(relx=0.65, rely=0.1) f = Figure(figsize=(6, 4)) a = f.add_subplot(111) t = Counter(lang).keys() y_pos = np.arange(len(t)) performance = Counter(lang).values() error = np.random.rand(len(t)) s = Counter(lang).values() a.barh(y_pos,s) a.set_yticks(y_pos) a.set_yticklabels(t) a.invert_yaxis() a.set_ylabel(u' ') a.set_xlabel(u'') canvas = FigureCanvasTkAgg(f, master=window) canvas.show() canvas.get_tk_widget().place(relx=0.52, rely=0.12)#pack(side=TOP, fill=BOTH, expand=1) canvas._tkcanvas.place(relx=0.52, rely=0.12)#pack(side=TOP, fill=BOTH, expand=1) The output is presented in charts.
Distribution of references
Attitude of Twitter users to nominated films
Display the language distribution
That is, find out about which films speak in which languages (respectively, and countries).
- Call me your name

- Dark times
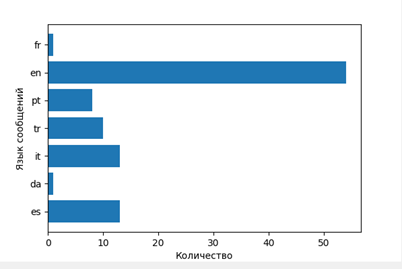
- Dunkirk
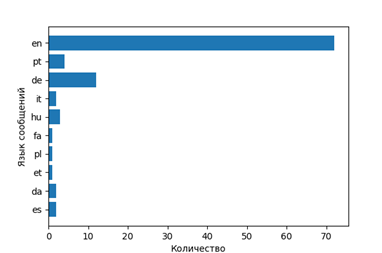
- Away
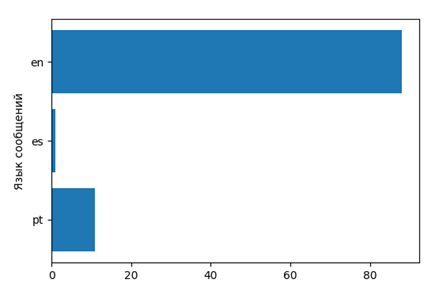
- Lady bird
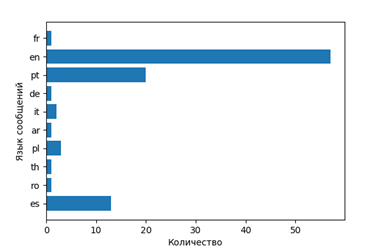
- Ghost thread
- Secret Dossier

- Water form

- Three billboards on the border of Ebbing, Missouri

Nomination best actor
(presented in tabular form)
Nomination best actress
(presented in tabular form)
Suggestions for improvement
Of course, this “slice” of public opinion can only partly show an attitude to films. For more in-depth analysis, it is necessary to collect data from Twitter during the intermediate time, especially when information leads appear. But, at the moment, the leader of public opinion are: The form of water . I think even in the evening to see!
Also, social networks allow you to analyze and classify the audience. Reference to the repository and dictionaries for learning the tonality model .
Source: https://habr.com/ru/post/349436/
All Articles