Search under the hood. Cloud indexing
In the last article, I talked about how a search engine can find out that a particular web page exists and save it to itself in the repository. But finding out that a webpage exists is just the beginning. It is much more important in a split second to have time to find those pages that contain keywords entered by the user. I will talk about how this works in today's article, illustrating my story with a “learning” implementation, which is nevertheless designed to be able to scale up to the size of the entire Internet indexing and take into account the current state of large data analysis technologies.

At the same time, I was able to consider the main functions and methods of Apache Spark, so this article can also be viewed as a small tutorial on Spark.
Task statement
A more formal formulation of the problem, which I will analyze today: there is a repository containing a set of web pages downloaded from the Internet by a crawler . It is necessary to design a mechanism that allows for fractions of a second to provide links to all web pages from this repository, including all keywords contained in a user request. This mechanism should be:
- scalable by the amount of data - potentially we should be able to process the entire Internet;
- scalable by the number of requests per second: for “adult” search engines, such as Yandex and Google, the number of search requests can reach tens of thousands of requests per second.
Some of the important limitations of the task being analyzed today:
- As part of this article, I will not try to organize the pages found. The engine will return just a lot. The task of ordering, or, more correctly, ranking, is a separate important task, which I will analyze in the following articles.
- My implementation will imply the presence of all the words from the search query. Modern search engines allow you to correct typos, search for synonyms, etc., but in the end it all the same boils down to several queries “by all” words and combining or intersecting their results.
Let's now analyze how to solve the problem within the limits of the set limits.
Invert Index
Consider the following data structure: a dictionary whose keys are words from our language, values — sets of web pages where this word occurs:
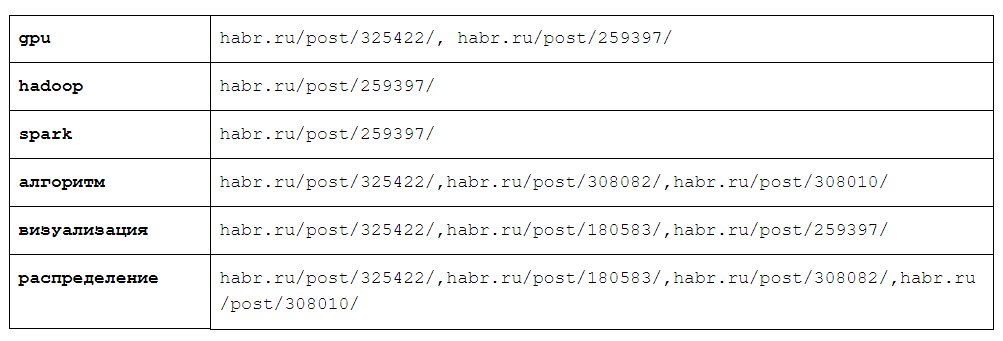
This data structure is called the inverted index, and it is the key to the search engine. So key that, for example, Yandex is even named after her (yandex is nothing but y et a nother i ndex ).
In reality, this dictionary will be much larger than in the above example: the number of elements in it will be equal to the number of different words on web pages, and the maximum size of the set for one element will be all web pages in the indexed part of the Internet.
Suppose we were able to build such a data structure. In this case, the search for web pages containing words from the query will occur as follows:
- We split the query into words.
- For each word, go to the reverse index and extract a lot of web pages.
- The result is the intersection of all the sets extracted in clause 1.
For example, if we search all web pages for the query “visualization algorithm” and the reverse index corresponds to the one shown in the table, then the resulting set will contain only one web page - habr.ru/post/325422/ , since it only contains at the intersection of the sets for the words "algorithm" and "visualization."
In order to build such a data structure, you can use the MapReduce approach. I have a separate article about this approach, but the basic idea is this:
- At the first stage ( map step ), you can convert source objects (in our case, documents) into key-value pairs (the keys are words, and the values are the URL of the document).
- Key-value pairs are automatically grouped by key ( shuffle step ).
- To process all values for a given key ( step reduce ). In our case, save in reverse index.
Below in the implementation section, I will show how to implement the described algorithm using the popular open source tool for working with big data - apache spark.
A little nlp
The abbreviation NLP in the field of data analysis is understood to be computer processing of natural language (Natural Language Processing, not to be confused with pseudoscientific neuro-linguistic programming). When working with a search engine, you cannot avoid even a distant collision with language processing, so we need some concepts and tools from this area. As a library of working with natural language, I will use the popular library for python NLTK .
Tokenization
The first concept from the NLP domain that we need is tokenization. When describing working with a reverse index, I used the word concept. However, the word is not a very good term for a search engine developer, since web pages contain many different character sets that are not a word in the direct sense of the word (for example, masha545 or 31337). Therefore, we will use tokens instead. The NLTK library has a special module for selecting tokens: nltk.tokenize . There are various ways to split text into tokens. We will use the simplest way to select tokens - tokenization by regexp:
#code from nltk.tokenize import RegexpTokenizer tokenizer = RegexpTokenizer(r'[-a-z0-9]+') text = " , ." tokenizer.tokenize(text.lower()) #result ['', '', '', '', '', '', '', '', '', ''] Lemmatization
Many languages, especially Russian, are rich in word forms. It is clear that when we search for the word "computer", we expect that there will be pages containing the word "computer", "computers" and so on. To do this, all the tokens must be brought into the so-called "normal form". This can be done with different tools. For example, on github there is a library pymystem , which is a wrapper over a library developed by Yandex. For simplicity, I will use the method of stemming - the rejection of insignificant endings - and use for this the Russian language stemmer, included in the nltk library:
#code from nltk.stem.snowball import RussianStemmer stemmer = RussianStemmer() tokens = ['', '', '', '', '', '', '', '', '', ''] stemmed_tokens = [stemmer.stem(token) for token in tokens] print(stemmed_tokens) #result ['', '', '', '', '', '', '', '', '', ''] Cut off insignificant words
In the reverse index for each word we store the set of URL pages in which this word is published. The problem is that some words (for example, the preposition "in") are found on almost every web page. At the same time, the information content of the presence or absence of such words on the page is very small. Therefore, in order not to store huge arrays in the index and not do extra work, we will simply ignore such words.
To determine the set of words that will be ignored, for each word you can calculate the proportion of web pages on which this word occurs, and put a certain limit on this frequency. Calculation of the frequency of words is a classic problem in the map-reduce paradigm, you can read more about this in my articles .
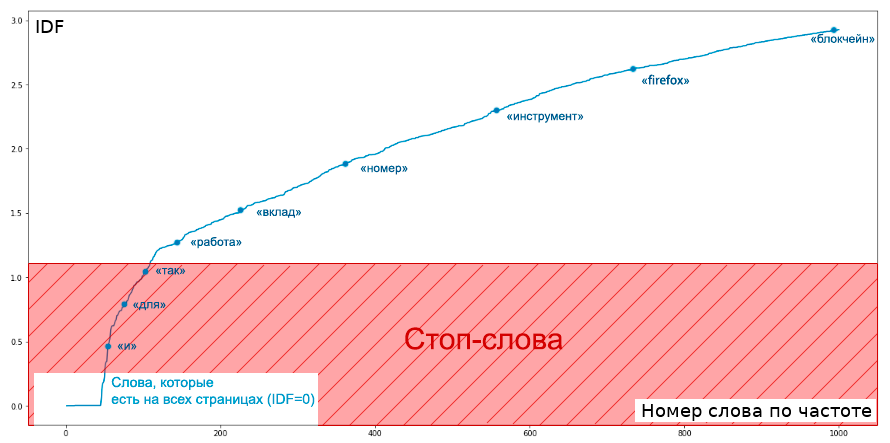
For my implementation, I calculated not just the word frequency, but some of its monotonous transformation - the Inverse Document Frequency (IDF), which we will later also use for ranking documents. By the method of “gaze”, I determined that the appropriate constant for cutting off words would be approximately equal to 1.12, between the words “for” and “code” (the word “code” is very often found in Habré).
Indexing

The architecture of my academic search engine
Apache spark
There are quite a few documents that I index - a few million. To process them, you need tools for working with big data. I chose apache spark , which is one of the most popular frameworks to date. Since I use amazon web services for my implementation, I used the Spark distribution kit, which is part of the elastic map reduce . Apache Spark has several options for presenting datasets. One of the main ones - the so-called Resilient Distributed Dataset (RDD) - is essentially a distributed data array that can be processed in parallel. I will use it for my implementation (although there are other APIs for working with sparks, which in some cases can be faster, see for example the Dataframe API )
Since the data in our case is stored on the Amazon object storage (S3), first we need to provide the necessary information for working with this storage:
#sc- spark context, def init_aws_spark(sc, config): sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", config.AWS_ACCESS_KEY) sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", config.AWS_SECRET_KEY) Then you can create RDD from the data stored on S3 ( which the crawler saved there ), and at the same time parse documents from json-format:
rdd = sc.textFile("s3a://minicrawl/habrahabr.ru/*",) jsons_rdd = rdd.map(lambda doc: json.loads(doc)) Here we have applied one of the basic functions of Spark - map, which applies the function to all elements of the array, doing it in parallel on all nodes of the cluster.
Next, we apply this function several times to preprocess text:
Clearing HTML Markup
There is nothing particularly interesting here, I use the lxml library for parsing html and removing the markup:
import copy import lxml.etree as etree def stringify_children(node): if str(node.tag).lower() in {'script', 'style'}: return [] from lxml.etree import tostring parts = [node.text] for element in node.getchildren(): parts += stringify_children(element) return ''.join(filter(None, parts)).lower() def get_tree(html): parser = etree.HTMLParser() tree = etree.parse(StringIO(html), parser) return tree.getroot() def remove_tags(html): tree = get_tree(html) return stringify_children(tree) def get_text(doc): res = copy.deepcopy(doc) res['html'] = res['text'] res['text'] = remove_tags(res['html']) return res clean_text_rdd = jsons_rdd.map(get_text).cache() Tokenization and stemming
from nltk.tokenize import RegexpTokenizer from nltk.stem.snowball import RussianStemmer def tokenize(doc): tokenizer = RegexpTokenizer(r'[-a-z0-9]+') res = copy.deepcopy(doc) tokens = tokenizer.tokenize(res['text']) res['tokens'] = list(filter(lambda x: len(x) < 15, tokens)) return res def stem(doc): stemmer = RussianStemmer() res = copy.deepcopy(doc) res['stemmed'] = [stemmer.stem(token) for token in res['tokens']] return res stemmed_docs = clean_text_rdd.map(tokenize).map(stem).cache() The cache () function, called after the map () function, prompts you to cache this dataset. If this is not done, with repeated use, the spark will count it again.
Filter high-frequency words on spark
As I wrote, we will filter words for which the IDF measure is less than 1.12. To do this, we first need to calculate the frequency of all words. This is a straightforward classic big data analysis task :
def get_words(doc): return [(word, 1) for word in set(doc['stemmed'])] word_counts = stemmed_docs.flatMap(get_words)\ .reduceByKey(lambda x, y: x+y) It uses two interesting Spark functions:
- flatMap - works like a map, but returns not one value for one value of the input dataset, but several. In our case, we return a key-value pair (<word>, 1) for each word at least once in the document.
- reduceByKey - allows you to process all values for a single key. In our case, sum up.
Next, we calculate the IDF for all tokens:
doc_count = stemmed_docs.count() def get_idf(doc_count, doc_with_word_count): return math.log(doc_count/doc_with_word_count) idf = word_counts.mapValues(lambda word_count: get_idf(doc_count, word_count)) Get a list of high-frequency stop words:
idf_border = 1.12 stop_words_list =idf.filter(lambda x: x[1] < idf_border).keys().collect() stop_words = set(sop_words) Spark functions are used here:
- filter () - leaves in the dataset only elements that match a specific criterion;
- keys () - leaves only keys in dataset (there is a similar function values (), which leaves only values);
- collect () - collects distributed data into a local list. After this, it is no longer possible to perform Sparsk functions on it.
I got 50 stop words , among which there are both obvious: " in ", " o ", " not ", and less obvious, but logical for habr: " habrabra ", " mobile ", " sandboxes ", " support "," registration ".
Reverse Index Building
The task to build a dataset of the word -> set of URLs is very similar to the task of counting the number of documents in which the word occurs, with one difference: we will not add one every time, but add a new URL to the set.
def token_urls(doc): res = [] for token in set(doc['stemmed']): if token not in stop_words: res.append((token, doc['url'])) return res index_rdd = stemmed_docs.flatMap(token_urls)\ .aggregateByKey(set(),\ lambda x, y: x.union({y}), lambda x, y: x.union(y)) Here, in addition to the previously used flatMap function, the aggregateByKey function is also used, which is very similar to reduceByKey, but takes three parameters:
- empty battery object in which the result will accumulate;
- a function that adds one value to the battery;
- a function that can drain two batteries into one. Values for one key can be aggregated in parallel, this function is needed to combine partially aggregated results.
Then it remains only to maintain the reverse index. In order to save it, any distributed key-value storage will be suitable for us. I chose aerospike - it is fast, well distributed. Write a directly serialized url set to the value for the token:
In general, everything is simple:
import pickle storage = LazyAerospike(config.AEROSPIKE_ADDRESS) results = index_rdd.map(lambda x: storage.put(x[0], pickle.dumps(x[1]))).collect() Here I use pickle - the standard Python method of serializing almost any objects. I also use a small wrapper over the standard aerospike client, which allows you to initialize the connection to the database at the time of the first write or read. This is necessary, since spark cannot parallelize the connection to the database across all nodes of the cluster; you have to reconnect every time.
class LazyAerospike(object): import aerospike def __init__(self, addr, namespace='test', table='index'): self.addr = addr self.connection = None self.namespace = namespace self.table = table def check_connection(self): if self.connection is None: config = { 'hosts': [ (self.addr, 3000) ] } self.connection = self.aerospike.Client(config).connect() def _get_full_key(self, key): return (self.namespace, self.table, key) def put(self, key, value): self.check_connection() key_full = self._get_full_key(key) self.connection.put(key_full, {'value': value}) return True def get(self, key): self.check_connection() key_full = self._get_full_key(key) value = self.connection.get(key_full) return value[2]['value'] API for data retrieval
It remains to write a function that will be executed during a user request. Everything is simple with it: we split the request for tokens, extract sets of URLs for each token and intersect them:
def index_get_urls(keyword): raw_urls = storage.get(keyword) return pickle.loads(raw_urls) def search(query): stemmer = RussianStemmer() tokenizer = RegexpTokenizer(r'[-a-z0-9]+') keywords_all = [stemmer.stem(token) \ for token in tokenizer.tokenize(query)] keywords = list(filter(lambda token: \ token not in stop_words, keywords_all)) if len(keywords) == 0: return [] result_set= index_get_urls(keywords[0]) for keyword in keywords[1:]: result_set=\ result_set.intersection(index_get_urls(keyword)) return result_set We start and make sure that everything works as it should (here I run on a small sample):
Conclusion
This search engine, of course, is much more complex. For example, I store sets very nonoptimally, it would be enough to store only their id-names instead of urls themselves. Nevertheless, the architecture turned out to be distributed and could potentially work on a large part of the Internet and under heavy loads.
In production, you most likely will not need to implement the search engine with your hands - it’s better to use ready-made solutions, such as ElasticSearch for example.
However, understanding the basics of how the reverse index works can help to properly configure and use it, and it can be very useful for solving similar problems.
In this article, I did not touch on the most interesting, in my opinion, part of the search - ranking. He will be discussed in the following articles.
')
Source: https://habr.com/ru/post/349404/
All Articles