How is Alice. Yandex lecture
In this lecture, technological solutions are first considered, on the basis of which Alice works — Yandex’s voice assistant. The leader of the dialogue systems development team Boris Yangel hr0nix tells how his team teaches Alice to understand the desires of the user, to find answers to the most unexpected questions and at the same time behave decently.
- I'll tell you what's inside Alice. Alice is big, there are many components in it, so I’ll go over the surface a little.
Alice is a voice assistant launched by Yandex on October 10, 2017. It is in the Yandex application on iOS and Android, as well as in a mobile browser and as a separate application under Windows. There you can solve your problems, find information in a dialogue format, communicating with it with text or voice. And there is a killer feature that made Alice quite famous in runet. We use not only pre-known scenarios. Sometimes, when we do not know what to do, we use the full power of deep learning to generate a response on behalf of Alice. This is quite funny and allowed us to ride the HYIP train.
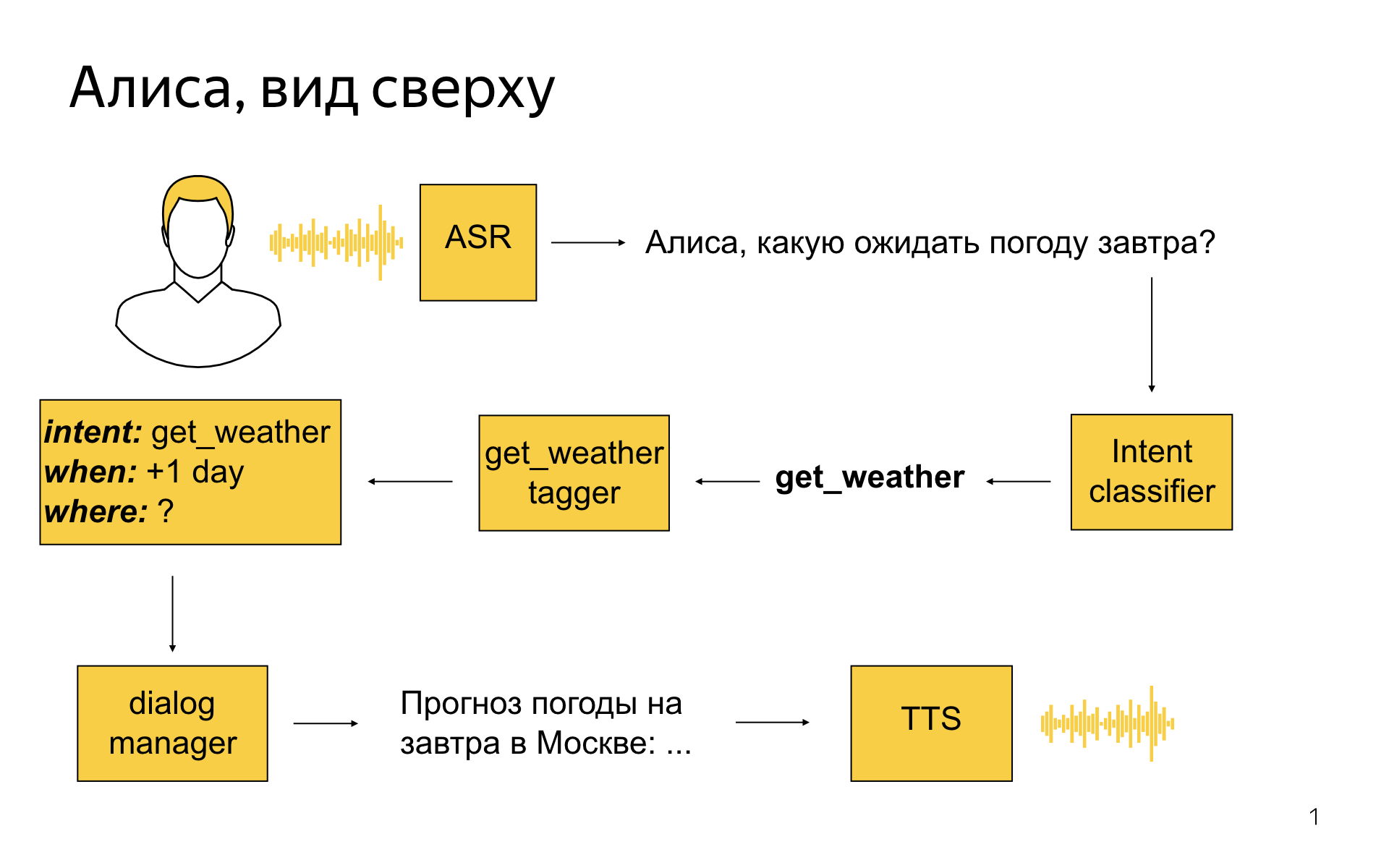
What does Alice look like high-level?
The user says: “Alisa, what weather will we expect tomorrow?”
')
First of all, we stream it into the recognition server, it turns it into text, and this text then goes into the service that my team is developing, into an entity such as an integer classifier. This is a machine learning thing whose task is to determine what the user wanted to say with his own phrase. In this example, the intents classifier could say: OK, the user probably needs the weather.
Then for each intent there is a special model called a semantic tegger. The task of the model is to isolate useful nuggets of information in what the user said. A weather tegger could say that tomorrow is the date for which the user needs weather. And we turn all these parsing results into some structured representation, which is called a frame. It will say that it is an intent weather, that the weather is needed for +1 day from the current day, and where it is unknown. All this information enters the dialog manager module, which, in addition to this, knows the current context of the dialogue, knows what has happened up to this point. He receives the results of the analysis of the replica at the entrance, and he must decide what to do with them. For example, he can go to the API, find out the weather for tomorrow in Moscow, because the user's geolocation is Moscow, even though he did not indicate it. And to say - generate a text that describes the weather, then send it to a speech synthesis module that will speak to the user in Alice’s beautiful voice.

Dialog Manager. There is no machine learning, no reinforcement learning, there are only configs, scripts and rules. It works predictably, and it’s clear how to change it, if needed. If the manager comes and says change, then we can do it in a short time.
At the heart of the Dialog Manager concept is a concept known to those involved in dialogue systems like form-filling. The idea is that the user fills in some kind of virtual form with his replicas, and when he fills in all the required fields in it, his need can be met. Event-driven engine: every time a user does something, some events happen that you can subscribe to, write their handlers in Python and thus construct the logic of the dialogue.
When you need to generate a phrase in scripts - for example, we know what the user is talking about the weather and need to answer about the weather - we have a powerful template language that allows us to write these phrases. This is how it looks.

This is an add-on to the Jinja2 python-language templating system, to which all sorts of linguistic tools have been added, such as the ability to incline words or align numerals and nouns, so that coherent text can be easily written, randomized text pieces to increase Alice’s speech variability.

In the intents classifier, we managed to try many different models, ranging from logistic regression to gradient boosting, recurrent networks. As a result, we stopped at the classifier, which is based on the nearest neighbors, because it has a bunch of good properties that other models do not have.
For example, you often need to deal with intents for which you have literally a few examples. It is impossible to just learn the usual multiclass classifiers in this mode. For example, it turns out that in all the examples, of which there are only five, there was a particle “a” or “how”, which was not in other examples, and the classifier finds the simplest solution. He decides that if the word “how” occurs, then this is exactly the intent. But this is not what you want. You want the semantic proximity of what the user said to the phrases that lie in the train for this intent.
As a result, we pre-train the metric on a large dataset, which tells how semantically close two phrases are, and then use this metric, looking for the nearest neighbors in our trainset.
Another good quality of this model is that it can be quickly updated. You have new phrases, you want to see how Alice's behavior changes. All you need is to add their many potential examples for the classifier of the nearest neighbors, you do not need to re-select the entire model. For example, for our recurrent model, it took several hours. It is not very convenient to wait a few hours when you change something to see the result.

Semantic tegger. We tried conditional random fields and recurrent networks. Networks, of course, work much better, it is not a secret to anyone. We do not have unique architectures there, the usual bidirectional LSTM with attention, plus or minus state-of-the-art for the tagging task. Everybody does it and we do it.
The only thing is that we actively use the N-best hypotheses, we do not generate only the most likely hypothesis, because sometimes we need not the most likely. For example, we often reweigh hypotheses, depending on the current state of the dialog in the dialog manager.
If we know that at the previous step we asked a question about something, and there is a hypothesis where a tegger found something and a hypothesis where he did not, then probably, all other things being equal, the first is more likely. Such tricks allow us to slightly improve the quality.
And the machine-trained tegger sometimes makes mistakes, and it is not entirely accurate to find the meaning of slots in the most plausible hypothesis. In this case, we are looking for a hypothesis in N-best, which is in better agreement with what we know about the types of slots, which also allows us to earn some quality.
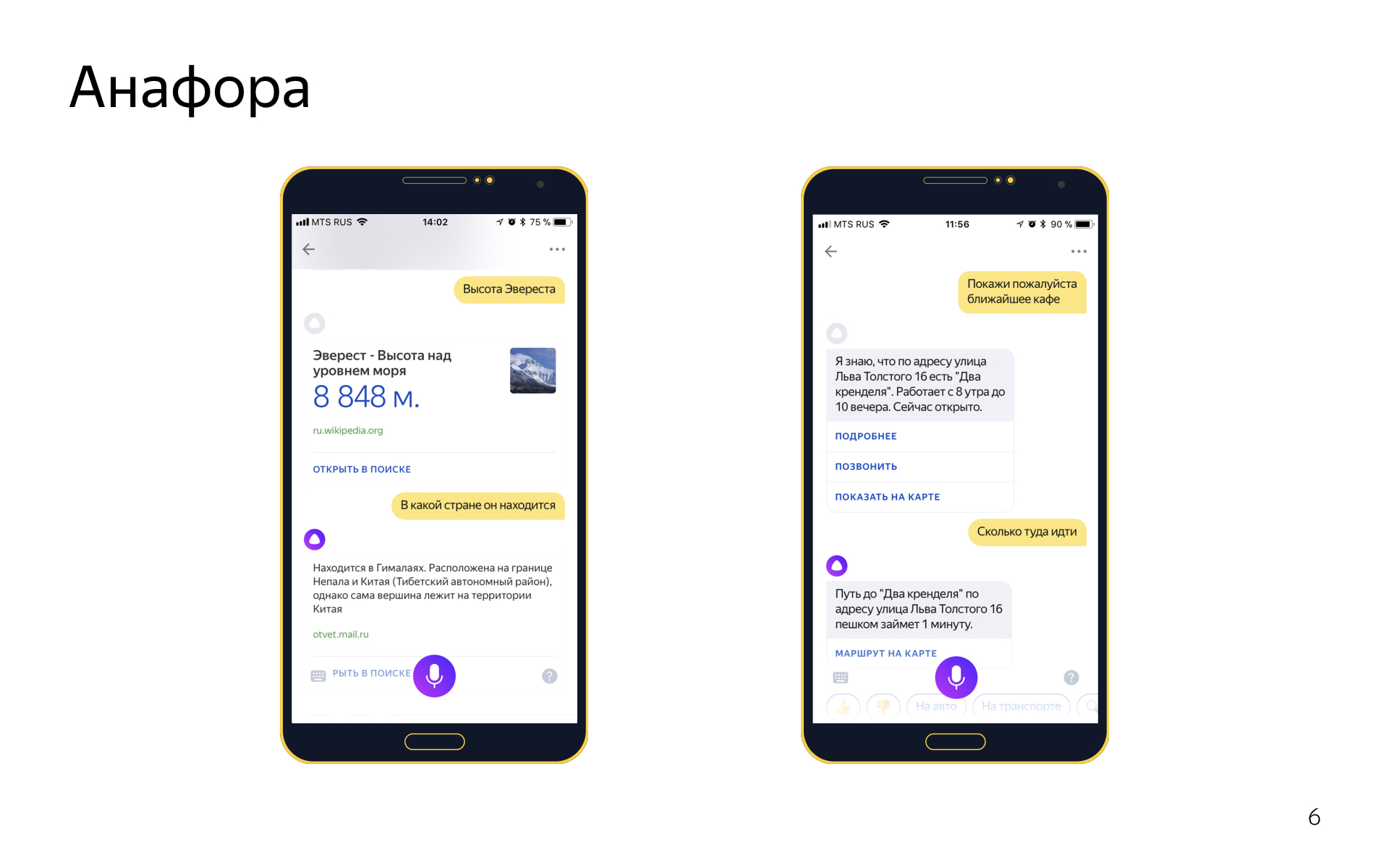
Even in the dialogues there is such a phenomenon Anaphora. This is when you use a pronoun to refer to an object that was previously in the dialogue. Say, say "the height of Everest," and then "in what country it is located." We are able to resolve anaphores. For this we have two systems.

One general-purpose system that can work on any replicas. It works on top of parsing all user replicas. If we see a pronoun in its current cue, we look for known phrases in what he said earlier, count the speed for each of them, see if we can substitute pronouns for it, and choose the best if we can.
We also have an anaphor resolution system based on form filling, it works like this: if there was a geoobject in the previous intent, and there is a slot for the geoobject in the current intent, and it is not populated, and we also hit the current intent with the pronoun “there”, then probably the previous geoobject can be imported from the form and substituted here. This is a simple heuristic, but it makes a good impression and works great. In the part of intents, one system works, and in part both. We look where it works, where it does not work, flexibly customize it.
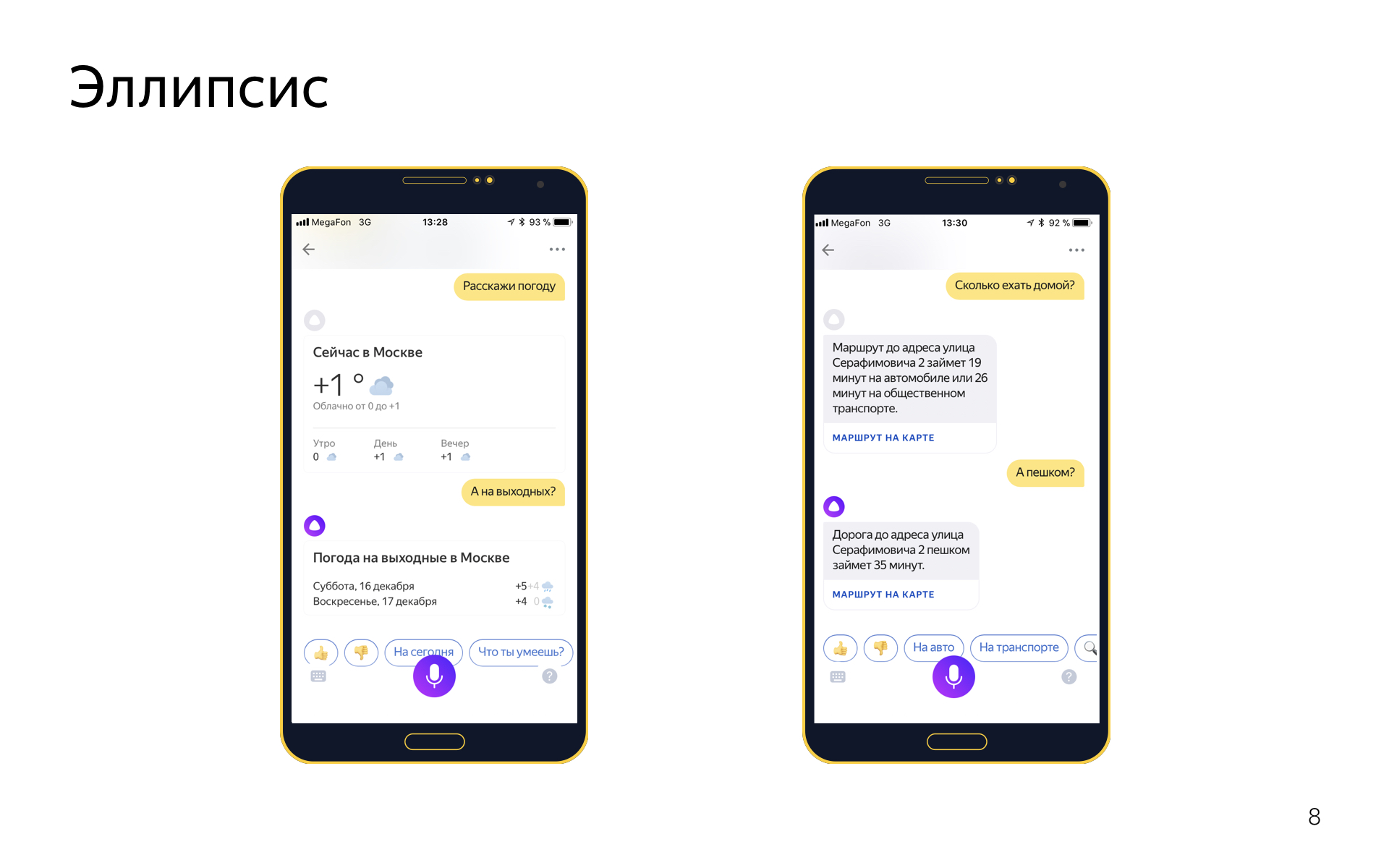
There is an ellipse. This is when in a dialogue you omit some words, because they are implied from the context. For example, you can say “tell the weather,” and then “and on weekends?”, Meaning “tell the weather on the weekend,” but you want to repeat these words, because this is useless.
We also know how to work with ellipses in the following way. Elliptical or clarifying phrases are separate intents.

If there is an get_weather intent for which there are phrases like “tell the weather”, “what is the weather today”, then he will have a pair intent get_weather_ellipsis, in which various weather updates are: “and for tomorrow”, “and for the weekend”, “and what is there in Sochi "and so on. And these elliptic intents in the classifier of intents compete on equal terms with their parents. If you say “but in Moscow?”, The classifier of intents, for example, would say that with a probability of 0.5 this is a refinement in the intensity of the weather, and with a probability of 0.5 it is a refinement in the search for organizations, for example. And then the dialogue engine is re-weighted by the scores, which were assigned by the classifier of intents, which were assigned with regard to the current dialogue, because, for example, it knows that there was a conversation about the weather before, and this was hardly a clarification about the search for organizations, rather it was about the weather. .
This approach allows learning and defining ellipses without context. You can simply type examples of elliptical phrases from somewhere without what was before. This is quite convenient when you make new intents that are not in the logs of your service. You can either fantasize or invent something, or try to collect long dialogues on a crowdsourcing platform. And you can easily synthesize for the first iteration of such elliptical phrases, they will somehow work, and then collect logs.

Here is the jewel of our collection, we call it a chatterer. This is the neural network that, in any incomprehensible situation, is responsible for something on behalf of Alice and allows to conduct with her often strange and often amusing dialogues.

Talk - actually fallback. In Alice, it works in such a way that if the intents classifier cannot confidently determine what the user wants, the other binary classifier first tries to solve it - maybe this is a search query and we will find something useful in the search and send it there? If the classifier says no, this is not a search query, but just chatter, then a fallback to the chat will work. A chat is a system that receives the current context of a dialogue, and its task is to generate the most relevant answer. Moreover, scenario dialogues can also be part of the context: if you talked about the weather, and then said something incomprehensible, the talker will work.

This allows us to do these things. You asked about the weather, and then she somehow commented on the talker. When it works, it looks very cool.
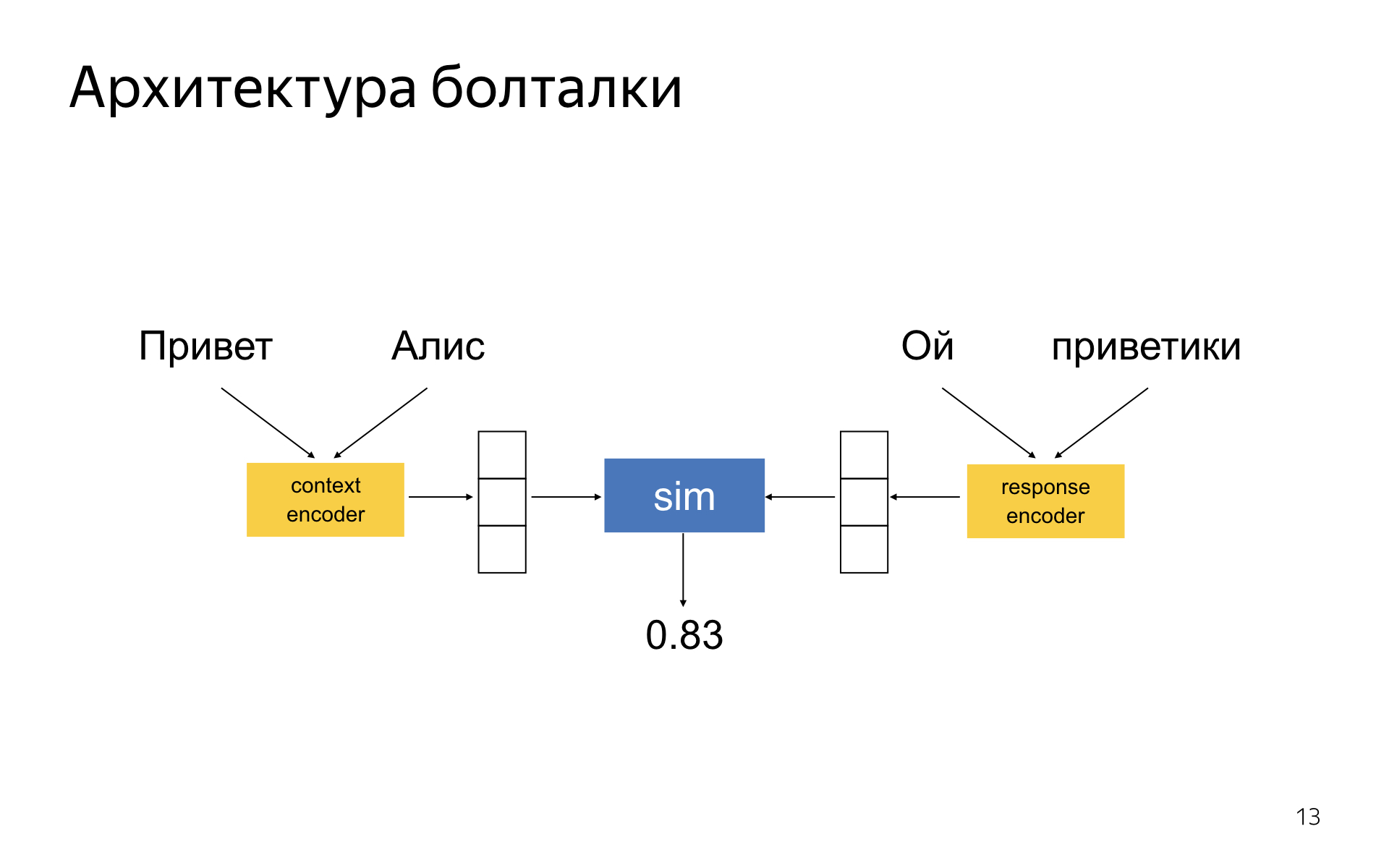
Boltalka is a DSSM-like neural network, where there are two encoder towers. One encoder encodes the current dialog context, the other is the candidate response. You get two embedding-vectors for the answer and the context, and the network is trained so that the cosine distance between them is the greater, the more relevant the response in the context and the more inappropriate. In the literature, this idea has long been known.

Why does everything seem to work well with us - it seems like a bit better than in the articles?
There is no silver bullet. There is no technology that allows you to suddenly make a cool talking neural network. We managed to achieve good quality, because we have won everywhere as a little. We have long picked up the architecture of these tower-encoder so that they work best. It is very important to choose the right scheme for sampling negative examples in training. When you study on interactive cases, you have only positive examples that were once said by someone in such a context. And there are no negative ones - they need to be somehow generated from this body. There are many different techniques, and some work better than others.
It is important how you choose the answer from the top candidates. You can choose the most likely answer offered by the model, but this is not always the best thing to do, because when training, the model did not take into account all the characteristics of a good answer that exist from a product point of view.
It is also very important what data sets you use, how you filter them.

In order to make a bit of quality out of this, you need to be able to measure everything you do. And here our pride is that we can measure all aspects of the quality of the system on our crowdsourcing platform using a button. When we have a new algorithm for generating results, we can generate a response from a new model on a special test package in a few clicks. And - to measure all aspects of the quality of the resulting model in Toloka. The main metric we use is the logical relevance of responses in context. Do not talk nonsense, which is in no way connected with this context.
There are a number of additional metrics that we try to optimize. This is when Alice addresses the user to “you”, speaks about herself in the masculine gender and says all sorts of audacity, nastiness and nonsense.
Highly, I told everything I wanted. Thank.
- I'll tell you what's inside Alice. Alice is big, there are many components in it, so I’ll go over the surface a little.
Alice is a voice assistant launched by Yandex on October 10, 2017. It is in the Yandex application on iOS and Android, as well as in a mobile browser and as a separate application under Windows. There you can solve your problems, find information in a dialogue format, communicating with it with text or voice. And there is a killer feature that made Alice quite famous in runet. We use not only pre-known scenarios. Sometimes, when we do not know what to do, we use the full power of deep learning to generate a response on behalf of Alice. This is quite funny and allowed us to ride the HYIP train.
What does Alice look like high-level?
The user says: “Alisa, what weather will we expect tomorrow?”
')
First of all, we stream it into the recognition server, it turns it into text, and this text then goes into the service that my team is developing, into an entity such as an integer classifier. This is a machine learning thing whose task is to determine what the user wanted to say with his own phrase. In this example, the intents classifier could say: OK, the user probably needs the weather.
Then for each intent there is a special model called a semantic tegger. The task of the model is to isolate useful nuggets of information in what the user said. A weather tegger could say that tomorrow is the date for which the user needs weather. And we turn all these parsing results into some structured representation, which is called a frame. It will say that it is an intent weather, that the weather is needed for +1 day from the current day, and where it is unknown. All this information enters the dialog manager module, which, in addition to this, knows the current context of the dialogue, knows what has happened up to this point. He receives the results of the analysis of the replica at the entrance, and he must decide what to do with them. For example, he can go to the API, find out the weather for tomorrow in Moscow, because the user's geolocation is Moscow, even though he did not indicate it. And to say - generate a text that describes the weather, then send it to a speech synthesis module that will speak to the user in Alice’s beautiful voice.
Dialog Manager. There is no machine learning, no reinforcement learning, there are only configs, scripts and rules. It works predictably, and it’s clear how to change it, if needed. If the manager comes and says change, then we can do it in a short time.
At the heart of the Dialog Manager concept is a concept known to those involved in dialogue systems like form-filling. The idea is that the user fills in some kind of virtual form with his replicas, and when he fills in all the required fields in it, his need can be met. Event-driven engine: every time a user does something, some events happen that you can subscribe to, write their handlers in Python and thus construct the logic of the dialogue.
When you need to generate a phrase in scripts - for example, we know what the user is talking about the weather and need to answer about the weather - we have a powerful template language that allows us to write these phrases. This is how it looks.
This is an add-on to the Jinja2 python-language templating system, to which all sorts of linguistic tools have been added, such as the ability to incline words or align numerals and nouns, so that coherent text can be easily written, randomized text pieces to increase Alice’s speech variability.
In the intents classifier, we managed to try many different models, ranging from logistic regression to gradient boosting, recurrent networks. As a result, we stopped at the classifier, which is based on the nearest neighbors, because it has a bunch of good properties that other models do not have.
For example, you often need to deal with intents for which you have literally a few examples. It is impossible to just learn the usual multiclass classifiers in this mode. For example, it turns out that in all the examples, of which there are only five, there was a particle “a” or “how”, which was not in other examples, and the classifier finds the simplest solution. He decides that if the word “how” occurs, then this is exactly the intent. But this is not what you want. You want the semantic proximity of what the user said to the phrases that lie in the train for this intent.
As a result, we pre-train the metric on a large dataset, which tells how semantically close two phrases are, and then use this metric, looking for the nearest neighbors in our trainset.
Another good quality of this model is that it can be quickly updated. You have new phrases, you want to see how Alice's behavior changes. All you need is to add their many potential examples for the classifier of the nearest neighbors, you do not need to re-select the entire model. For example, for our recurrent model, it took several hours. It is not very convenient to wait a few hours when you change something to see the result.
Semantic tegger. We tried conditional random fields and recurrent networks. Networks, of course, work much better, it is not a secret to anyone. We do not have unique architectures there, the usual bidirectional LSTM with attention, plus or minus state-of-the-art for the tagging task. Everybody does it and we do it.
The only thing is that we actively use the N-best hypotheses, we do not generate only the most likely hypothesis, because sometimes we need not the most likely. For example, we often reweigh hypotheses, depending on the current state of the dialog in the dialog manager.
If we know that at the previous step we asked a question about something, and there is a hypothesis where a tegger found something and a hypothesis where he did not, then probably, all other things being equal, the first is more likely. Such tricks allow us to slightly improve the quality.
And the machine-trained tegger sometimes makes mistakes, and it is not entirely accurate to find the meaning of slots in the most plausible hypothesis. In this case, we are looking for a hypothesis in N-best, which is in better agreement with what we know about the types of slots, which also allows us to earn some quality.
Even in the dialogues there is such a phenomenon Anaphora. This is when you use a pronoun to refer to an object that was previously in the dialogue. Say, say "the height of Everest," and then "in what country it is located." We are able to resolve anaphores. For this we have two systems.
One general-purpose system that can work on any replicas. It works on top of parsing all user replicas. If we see a pronoun in its current cue, we look for known phrases in what he said earlier, count the speed for each of them, see if we can substitute pronouns for it, and choose the best if we can.
We also have an anaphor resolution system based on form filling, it works like this: if there was a geoobject in the previous intent, and there is a slot for the geoobject in the current intent, and it is not populated, and we also hit the current intent with the pronoun “there”, then probably the previous geoobject can be imported from the form and substituted here. This is a simple heuristic, but it makes a good impression and works great. In the part of intents, one system works, and in part both. We look where it works, where it does not work, flexibly customize it.
There is an ellipse. This is when in a dialogue you omit some words, because they are implied from the context. For example, you can say “tell the weather,” and then “and on weekends?”, Meaning “tell the weather on the weekend,” but you want to repeat these words, because this is useless.
We also know how to work with ellipses in the following way. Elliptical or clarifying phrases are separate intents.
If there is an get_weather intent for which there are phrases like “tell the weather”, “what is the weather today”, then he will have a pair intent get_weather_ellipsis, in which various weather updates are: “and for tomorrow”, “and for the weekend”, “and what is there in Sochi "and so on. And these elliptic intents in the classifier of intents compete on equal terms with their parents. If you say “but in Moscow?”, The classifier of intents, for example, would say that with a probability of 0.5 this is a refinement in the intensity of the weather, and with a probability of 0.5 it is a refinement in the search for organizations, for example. And then the dialogue engine is re-weighted by the scores, which were assigned by the classifier of intents, which were assigned with regard to the current dialogue, because, for example, it knows that there was a conversation about the weather before, and this was hardly a clarification about the search for organizations, rather it was about the weather. .
This approach allows learning and defining ellipses without context. You can simply type examples of elliptical phrases from somewhere without what was before. This is quite convenient when you make new intents that are not in the logs of your service. You can either fantasize or invent something, or try to collect long dialogues on a crowdsourcing platform. And you can easily synthesize for the first iteration of such elliptical phrases, they will somehow work, and then collect logs.
Here is the jewel of our collection, we call it a chatterer. This is the neural network that, in any incomprehensible situation, is responsible for something on behalf of Alice and allows to conduct with her often strange and often amusing dialogues.
Talk - actually fallback. In Alice, it works in such a way that if the intents classifier cannot confidently determine what the user wants, the other binary classifier first tries to solve it - maybe this is a search query and we will find something useful in the search and send it there? If the classifier says no, this is not a search query, but just chatter, then a fallback to the chat will work. A chat is a system that receives the current context of a dialogue, and its task is to generate the most relevant answer. Moreover, scenario dialogues can also be part of the context: if you talked about the weather, and then said something incomprehensible, the talker will work.
This allows us to do these things. You asked about the weather, and then she somehow commented on the talker. When it works, it looks very cool.
Boltalka is a DSSM-like neural network, where there are two encoder towers. One encoder encodes the current dialog context, the other is the candidate response. You get two embedding-vectors for the answer and the context, and the network is trained so that the cosine distance between them is the greater, the more relevant the response in the context and the more inappropriate. In the literature, this idea has long been known.
Why does everything seem to work well with us - it seems like a bit better than in the articles?
There is no silver bullet. There is no technology that allows you to suddenly make a cool talking neural network. We managed to achieve good quality, because we have won everywhere as a little. We have long picked up the architecture of these tower-encoder so that they work best. It is very important to choose the right scheme for sampling negative examples in training. When you study on interactive cases, you have only positive examples that were once said by someone in such a context. And there are no negative ones - they need to be somehow generated from this body. There are many different techniques, and some work better than others.
It is important how you choose the answer from the top candidates. You can choose the most likely answer offered by the model, but this is not always the best thing to do, because when training, the model did not take into account all the characteristics of a good answer that exist from a product point of view.
It is also very important what data sets you use, how you filter them.
In order to make a bit of quality out of this, you need to be able to measure everything you do. And here our pride is that we can measure all aspects of the quality of the system on our crowdsourcing platform using a button. When we have a new algorithm for generating results, we can generate a response from a new model on a special test package in a few clicks. And - to measure all aspects of the quality of the resulting model in Toloka. The main metric we use is the logical relevance of responses in context. Do not talk nonsense, which is in no way connected with this context.
There are a number of additional metrics that we try to optimize. This is when Alice addresses the user to “you”, speaks about herself in the masculine gender and says all sorts of audacity, nastiness and nonsense.
Highly, I told everything I wanted. Thank.
Source: https://habr.com/ru/post/349372/
All Articles