Information architecture and technology DITA. Based on a lecture in Yandex
Darwin Information Typing Architecture (DITA) is an XML technology for automating processes related to technical documentation. During its existence, DITA has accumulated a large variety of opportunities, approaches to content organization, as well as specific mechanisms for their implementation. It is not surprising to get lost in them, and this often leads to the appearance of incomprehensible, inefficient and simply inconvenient automation solutions for documentation. Project Director of Philosoft Company Mikhail Ostrogorsky lays it all out on the shelves.
The proposed article was written based on a small report made by the author on one of the “ Hyperbats ”, which from time to time appear in Yandex. It’s not that I’m too dissatisfied with myself as a speaker, but in this case it’s not the best idea to publish a verbatim transcript of oral speech, in my opinion.
First, the text on the technical topic requires a certain design. It needs lists, tables, diagrams, code snippets. But I don’t know how to speak with tables, and the listings do not fit well on slides. Secondly, in two months I managed to prepare an example that illustrates the report’s material well, and it would be strange not to use it now. Therefore, I ask you to regard this article as an important and rather voluminous addition to the oral report, and not as its altered transcript.
In conclusion, I warmly thank my colleagues from Yandex for the opportunity to address such a wide audience not only verbally, but also in writing. I hope these materials will benefit interested specialists and technical managers.
')
The creators of the DITA technology have provided it with an extensive repertoire of functionality. Technically, these features are implemented in the DITA markup language and in the DITA Open Toolkit software package, which is designed to convert the input material (as I will call content later) into one human-readable format. In addition, these features are better or worse supported by third-party software products. Such support is especially needed in XML editors and content management systems, so today you will find it in every more or less developed software product of this class.
It would seem that the abundance of functionality is an obvious advantage of any technology. However, being alone with him, we find ourselves in the position of a person who was first invited to a dinner party in an expensive restaurant. Unknown dishes, many different and at the same time similar forks and knives. What is what is not clear.

Speaking of restaurants. Tables in them are usually served according to the order of dishes. Filed at the very beginning we eat with an external pair of instruments, the next - the one that is embedded in it, etc. It is not clear just what to do with the instruments that were placed behind the plate. Therefore, mastering non-trivial technology, it is better to start from tasks, not tools. First, we study the “lunch” menu and see what each of the “dishes” represents, then we will learn to tackle the appropriate forks from the right end.
DITA technology carries a number of functionalities designed to assemble output documents from numerous blocks of the source material. But they benefit only if these blocks are successfully allocated and correctly connected to each other.
Despite the uniqueness of each documentation project, the structural problems that the authors are forced to solve when it is run are mostly well known. The latter makes it possible to make such a decomposition of the material so that the solution of these problems lends itself well to automation.
By information architecture is meant a material decomposition method chosen for a specific project or product. Of course, this decomposition should be made in the calculation of the possibility of assembly provided by the technology used. Here we will focus on DITA technology, but for any other technology this principle will remain unchanged.
A significant part of the structural problems, the solution of which should be provided by the information architecture, is associated with repetitions of the same text in different documents or even within the same document. Such repetitions are due to cultural traditions and peculiarities of human perception, therefore, it is not possible to abandon them.
When preparing documentation manually for repetitions you have to pay a high price:
Errors arise because making any change to a non-unique text leads to a complete check of the entire material and a similar editing of each repetition. With a sufficient amount of material, this operation is almost impossible to perform with the necessary accuracy.
In addition, if the documentation is developed by a group of authors, each of them, being left to himself, practices his own ways of presenting the material. Because of this, the exposition as a whole turns out to be non-unified, which also has to be considered an error. Even if in each case the information is transmitted correctly, inconsistency (structural, stylistic, terminological) can confuse the reader and push him to wrong actions.
Thus, one of the main tasks that should be addressed by the information architecture is to provide the necessary repetitions in the output documents , but to eliminate them in the material with which the authors work.
We illustrate the principle stated above with a simplified example (Table 1). At the same time we will get acquainted with the main elements of any information architecture: topics , maps of documents and including links . They are inherent not only in DITA technology, but also in any modern documentation automation technology.
Table 1. Simplified example of building information architecture
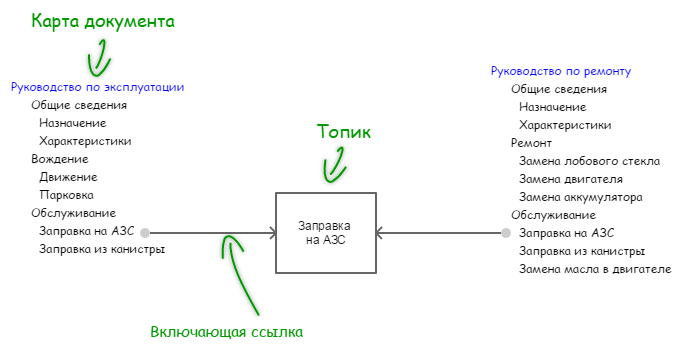
In fig. Figure 1 shows the reuse of a partition. (In English-language literature, the term reuse is often used, but I would not like to enrich the Russian language with the word “reuse”).
Sections that are used repeatedly are called topics . The tree structure (in fact, an empty table of contents) used to merge topics into a document will be called a map of this document.
Figure 1. Reuse topic
The volume of the topic should be as small as possible.
The topic should relate to any one topic that has clear boundaries. For example, a topic can reveal the meaning of a particular concept, describe a procedure, contain one set of reference data, etc.
The content and style of the topic should be such as to ensure its relative isolation from other topics. The topic should be, as far as possible, understandable by itself, like an encyclopedia article or a good answer to a question. Otherwise, the authors will have to manually correct this topic each time it is included in the new context.
In fig. 2 shows a deeper level of information architecture. At this level, not documents, but topics are exposed to decomposition.
Figure 2. Reuse sidebar
Information architecture will only be saved if the following conditions are met.
Ubiquity It is necessary to strictly adhere to decisions made on architecture, follow them systematically, and not occasionally. If topics are used, then all the material should be divided into them; if there are sample boxes, then all of them should be taken out of the topics and collected in some library, etc.
Collectivity As a rule, large sets of documentation are created by several authors. Information architecture provides the ability to achieve effective division of labor within the team. For example:
- technical security specialists or lawyers may compose libraries of frames, the text of which will be carefully verified;
- authors who have understood well in hotel-specific issues can write topics dedicated to them;
- An editor who sees the entire task, can map the documents and ensure the release of the entire set of documentation.
Further consideration of the techniques of building information architecture, as well as the functionality of the DITA technology, which make the application of these techniques possible, is based on one cross-cutting example.
The plot of the example is as follows. Imagine that we need to organize the production of technical documentation for electric vehicles. Now we have two models of electric vehicles, but their number may further increase.
The description of each part of the example is made according to the following principle:
- requirements for output documents;
- requirements for implementation;
- architectural solution;
- implementation by means of DITA.
A complete set of source code for the end-to-end example is available on my blog .
The set of technical documentation for each model includes the following documents:
- manual;
- advertising booklet.
The manual describes the entire model. The advertising booklet contains only general information about it.
Figure 3. Operator's manual (content) and advertising booklet

The repetition of the same text in the draft (in the source material, and not in the output) should be minimized.
This is a standard solution for DITA technology. It has already been described above. Nevertheless, let us tell about it again and add a few important details.
All documentation material will be presented in the form of a set of topics. To store the topics we will use the folder structure in the file system.
Each output document will have its own map. The document map contains its structure , i.e. the sequence of all its sections, taking into account their nesting. Binding of the topic to the section of the document structure is carried out with the help of an inclusive link. The inclusive link should be defined in the document map, it points to the topic that is mapped to the section of the document structure (not vice versa).
Despite the technical ability to use the same card for the formation of different output documents (for example, using profiling, see below), this is not recommended. If the project expands, for example, as the number of models increases, such an approach can lead to an overly confusing structure that cannot be understood. Try to follow a simple rule: one card - one output document. Although here, as will be shown below, its costs arise.
The proposed solution looks and is commonplace. Unbanal decisions will manifest themselves in the course of further decomposition of the project material.
An example of a document map (in this case, this is an advertising booklet on the Zaragoza model) is given below.
The use of remote maps and references to keys will be discussed in the following sections of the article.
To generate the output documents, the DITA Open Toolkit package is used in combination with the DITA2PDF2 plugin included in its composition, which is responsible for generating the output documents in PDF format.
Since the advertising booklet has a non-standard design, customization has been prepared for it so-called. It is a set of XSLT styles that change the standard behavior of the DITA2PDF2 plugin. This customization is part of the end-to-end example.
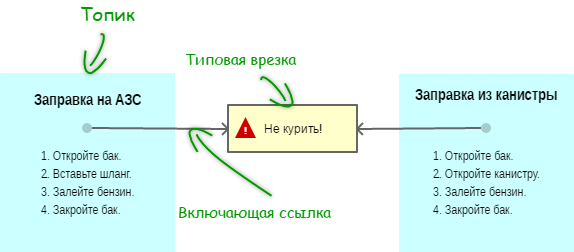
According to the condition of our imaginary task, each procedure describing one or another scenario of using an electric vehicle must begin (not necessarily from the very beginning) with a typical sidebar. This box contains a note regarding driver safety, as well as a link to the “Safety” section (Figure 4).
Each procedure describing a particular service scenario for an electric vehicle must also begin with a typical sidebar, but slightly different. Later in the project may be required and other typical sidebar.
Figure 4. Using typical sidebars

All documentation sets must be resistant to changing the text of a typical frame. If changes are made to the text of the standard box (for example, a literary correction has been made or the requirements of new regulatory and technical documents have been taken into account), they should be reflected equally in all operating manuals.
Create a library of sample text. It will be a single file in DITA format. In this file we will store all fragments of type text. The maintenance of a standard text library will be entrusted to one of the authors, who is particularly well versed in the regulatory framework for technical safety.
An example of a sidebar view in the sample text library is shown below. To identify the type of sidebar used attribute @ id. Its value must be unique, at least within the library file.
An example of including a link from a topic to a sample box is shown below. To indicate a typical sidebar, use the @conref attribute.
The text of the topics can contain relatively short string values, for example, the name of the company, the name of the product line, the name of the specific model (Fig. 5). In software documentation, these values often include the version number of the software product, the name of the hardware platform, the version of the operating system, the name of the customer, etc.
Figure 5. Text parameterization and its adaptation to the context
If such lines appear in the text, which otherwise would be the same in all documents, there is a temptation to get rid of them somehow, and make topics common to all output documents. For example, instead of the product name, you can use the perivational name of the product , instead of the direct name of the company, the word developer or company , etc.
The idea is good, but it does not always work.
First, marketing considerations play a role, and anyway, somewhere in the document you will have to at least once specify the original names explicitly.
Secondly, short lines are not necessarily names. These can be values of some important parameters, technical limitations, network addresses, port numbers or other data that the reader would prefer to see here, rather than look for them somewhere else in the document.
Therefore, it is impossible to completely get rid of string values. But to consider two texts as different only because they differ from each other in a dozen or so characters, and to place them on this basis in separate topics, you see, it is insulting.
If the text of the topic as a whole is the same for all models, then a single copy of this topic should exist in the project. Values that may change from time to time or from model to model should be incorporated into such topics automatically when generating the output documents.
Values that are the same for all models, but may change from time to time (the company, the entire product line), we will assign names and set in a common portable map . A shared portable card will exist in a single copy for the entire project. We will include the general portable map in the map of each document in the project.
The values that change from model to model (for example, the name of the model) will be assigned names and set in the remote model map . The remote model card will exist in a single copy for each model. The portable model card will be included in the map of each document related to this model.
In DITA technology, named values are called keys .
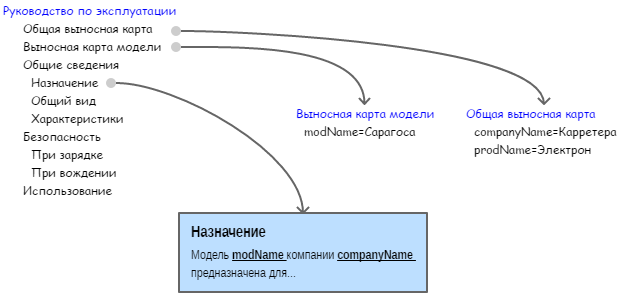
In the text of the topic, we will not use the values themselves, but references to the names of the keys. When generating a message, each link to the key name will be automatically replaced with the actual values of this key specified in the external map (Fig. 6).
Figure 6. Parameterization of the topic text using keys and remote maps
An example of the definition of a key in a remote model card is shown below. In the general remote card, the same syntax is used to determine the key.
Examples of including links from a document map to portable maps are shown below.
An example of a link to the name of a key in the text of the topic is shown below. When forming the output document, the name of the product line and the model name will be inserted into the text. The link to the key name is represented by the keyword element. The key name is specified in the @keyref attribute.
Not only string values, but also more complex constructions can appear in the text of topics. So, on fig. 5, in addition to string values, a figure and a table are shown. They belong to a specific model of an electric vehicle, but are incorporated in a topic that is common to all models.
If the text of the topic as a whole is the same for all models, then it should be common. In other words, the project should have a single copy of this topic, and maps of all documents, if necessary, should contain inclusive references to it.
Fragments that may change from time to time or from model to model should be incorporated into common topics automatically when generating output documents.
It is impossible to solve this problem using key parameterization, since the figures and tables are not reduced to string values. For their presentation, full-fledged XML markup is needed. The insertion of such fragments inside the common text is done with the help of indirect inclusive references.
The fragments of the XML markup that are incorporated into common topics will be called permutations.
We collect all the wildcard fragments related to a particular model into one file. We will call this file the model library by analogy with the standard text library. Yes, this is a library of standard text, only related to a particular model, and not to the project as a whole.
To point to the model library, we define a special key in the external model map. The value of this key will be the path to the model library.
We include the link from the general topic to the desired wildcard fragment from the name of this key and the unique identifier of this wildcard fragment in the model library (Fig. 7).
Figure 7. Indirect including link from general topic to wildcard fragment
Below is an example of how a key is specified in the model's external map indicating the library file of this model. The href attribute is used to point to the file in which wildcards are located.
An example of indirect including links from the text of the topic to the substitute fragment is shown below. The image element entirely is an indirect, inclusive link. When generating the output document, it will be completely replaced by the wildcard fragment, which this indirect inclusive link points to. The @conkeyref attribute is used to point to the wildcard fragment. Its value is made up of the name of the key (in the example modInfo) and the value of the @ id attribute of the desired wildcard fragment (in the example imgGeneralView). These two parts of the value of the @conkeyref attribute are typed through a slash.
Now we will learn not to add text to topics, but to throw it out from there.
It happens that the topic contains all the necessary information, however, for each specific output, it is redundant. For example, in the topic “Technical characteristics” (I remind you, this is a general topic of the project level), the following table follows the technical characteristics table:
- an indication of the need to service an electric car only in a company service center (otherwise the company does not guarantee the stated parameters);
- advertising praises to the engineers who developed such an outstanding electric machine.
The first box is relevant in the instruction manual, but looks unprofitable in the advertising booklet. The second tie-in, on the contrary, is needed only in an advertising booklet, and in the instruction manual it is already useless. We require that each of these frames be displayed only in the output document where it is needed (Fig. 8).
Figure 8. Text due to output genre
Similarly, a general topic may contain fragments of text that relate only to a particular model (Fig. 9).
Figure 9. Text due to product model

It is easy to imagine other dependencies, for example, some delicate information should be included in the advanced version of the manual for service support centers, but it is not advisable to inform them to end users.
If the topic contains not too numerous fragments that may be redundant in a given context, and each such context can be described by a small number of formal signs of the output document, then filters should be applied to the text of this topic. Creating multiple topics that differ from each other only in such fragments is not allowed.
If a fragment is to be included in the output document or excluded from the output document when certain conditions are fulfilled or not fulfilled, we will call it conditional . Each conditional fragment will be labeled reflecting the conditions for its inclusion in the document or exclusions from the document.
When forming the output document, we will indicate exactly which conditions for it are fulfilled. Unsuitable snippets will be automatically excluded from the output.
For working with conditional fragments, DITA technology offers an advanced profiling mechanism. It allows you to organize filtering conditional fragments in several different ways for several attributes simultaneously.
The DITA specification provides several non-semantic attributes that authors are free to use for profiling, interpreting their values in any way that is meaningful in a particular project.
The rules for selecting conditional fragments when profiling are quite flexible. In some cases, it is more convenient to leave in the output document only neutral fragments and obviously suitable conditional fragments. In other cases, it is easier to exclude obviously inappropriate conditional fragments from the output document.
In general, the main thing in this profiling is not to get confused. Not having the strength to describe the whole mechanism in a small (and without that already too big?) Article, let us give an example of including neutral and clearly suitable fragments in the output document.
An example of markup of the source text of a topic with profiling is given below. To indicate the genre of the document, the @ props attribute is used. Valid values for this attribute are not specified by the DITA specification. They are selected in the development of an information architecture and are part of an agreement adopted at the level of this project.
In order for the profiling to take place, the assembly script of the DITA Open Toolkit package, when generating the output document, among other things, must be passed the so-called DITAVAL file. Instructions should be included in it to include in the output document or exclude from the output document conditional fragments that have certain values of the profiling attributes. An example of such a file is shown below.
One of the main methodological and stylistic principles of writing technical documentation says: this should be described similarly. For example, if we describe the procedures performed by the user, we must always do this on the same plan.
The point is not that somewhere there is the most correct plan for describing a user procedure in the world. Of course not, and in general, user procedures can be described in different ways. But within the framework of one project, it is necessary to establish a plan for the description of the user procedure that is uniform for all authors, and follow it all. Otherwise, inconsistency will begin, and it makes the use of documentation very difficult, because it forces the reader to constantly wonder whether the differences observed by him are significant or accidental.
Different authors participating in a project (or one author participating in a project for a long time) should describe the same type of phenomena or actions in a uniform manner.
We classify topics, distributing them into several information types. The set of information types in the general case is determined by the features of a particular project. There is a steady (and enshrined in DITA) tradition to begin the classification of topics from their division into three basic information types :
- theoretical;
- procedural;
- reference.
Further classification may consist of a deeper specialization of the three basic information types (for example, we will distinguish between user and installation procedures), and the creation of fundamentally new ones.
For each information type we develop a typical structure . A typical structure can be dictated by the following features, necessarily inherent in the topic, which belongs to this information type:
- a set of rubrics that form the internal structure of the topic;
- the sequence and nesting of headings;
- Mandatory completion of certain categories;
- obligatory presence in some headings of a typical text set for them.
When creating a new topic, the author must first select his information type from the list available in this project. After creating a topic, the author does not receive a “clean sheet”, but a relatively rigid template, which he must follow when writing a topic.
The problem of unification of style is often tried to be solved with the help of standards and trainings. In part, they help. But DITA technology, unlike many others, makes it possible to technically force authors to uniformity. For this, the following possibilities are provided.
- Use of basic DITA information types: topic, concept, task, reference, troubleshooting . Each information type is described using a DTD and a schema. If the author types the text of the topic in a more or less modern XML editor (usually it happens), then the latter imposes on it the structure provided by the information type selected when creating this topic.
- Specialization of basic information types, i.e. creating your own DTD or topic schemes based on embedded ones.
Using specialized information types may require additional configuration of the XML editors and the DITA Open Toolkit.
In this case study, not specialization is applied, but templateization. «» . , , , .
. ( XML- ), .
-?
!
, , . , , .
XSLT ( XSLT-) ( runtime-).
, , DITA, . — .
— .
, - . , . ( , , ..) . . , . , - !
, « » , « » , , . , .
( ) , , . , - , .
. . « ». .
-. , , , - .
, DITA — .
, . , , . , , .
, , , . DITA ( ) , , « ». - , «» , , , . , .
Foreword
The proposed article was written based on a small report made by the author on one of the “ Hyperbats ”, which from time to time appear in Yandex. It’s not that I’m too dissatisfied with myself as a speaker, but in this case it’s not the best idea to publish a verbatim transcript of oral speech, in my opinion.
First, the text on the technical topic requires a certain design. It needs lists, tables, diagrams, code snippets. But I don’t know how to speak with tables, and the listings do not fit well on slides. Secondly, in two months I managed to prepare an example that illustrates the report’s material well, and it would be strange not to use it now. Therefore, I ask you to regard this article as an important and rather voluminous addition to the oral report, and not as its altered transcript.
In conclusion, I warmly thank my colleagues from Yandex for the opportunity to address such a wide audience not only verbally, but also in writing. I hope these materials will benefit interested specialists and technical managers.
')
Tools and tasks. No, on the contrary
The creators of the DITA technology have provided it with an extensive repertoire of functionality. Technically, these features are implemented in the DITA markup language and in the DITA Open Toolkit software package, which is designed to convert the input material (as I will call content later) into one human-readable format. In addition, these features are better or worse supported by third-party software products. Such support is especially needed in XML editors and content management systems, so today you will find it in every more or less developed software product of this class.
It would seem that the abundance of functionality is an obvious advantage of any technology. However, being alone with him, we find ourselves in the position of a person who was first invited to a dinner party in an expensive restaurant. Unknown dishes, many different and at the same time similar forks and knives. What is what is not clear.
Speaking of restaurants. Tables in them are usually served according to the order of dishes. Filed at the very beginning we eat with an external pair of instruments, the next - the one that is embedded in it, etc. It is not clear just what to do with the instruments that were placed behind the plate. Therefore, mastering non-trivial technology, it is better to start from tasks, not tools. First, we study the “lunch” menu and see what each of the “dishes” represents, then we will learn to tackle the appropriate forks from the right end.
The concept of information architecture
DITA technology carries a number of functionalities designed to assemble output documents from numerous blocks of the source material. But they benefit only if these blocks are successfully allocated and correctly connected to each other.
Despite the uniqueness of each documentation project, the structural problems that the authors are forced to solve when it is run are mostly well known. The latter makes it possible to make such a decomposition of the material so that the solution of these problems lends itself well to automation.
By information architecture is meant a material decomposition method chosen for a specific project or product. Of course, this decomposition should be made in the calculation of the possibility of assembly provided by the technology used. Here we will focus on DITA technology, but for any other technology this principle will remain unchanged.
Unification of the presentation of the material
A significant part of the structural problems, the solution of which should be provided by the information architecture, is associated with repetitions of the same text in different documents or even within the same document. Such repetitions are due to cultural traditions and peculiarities of human perception, therefore, it is not possible to abandon them.
When preparing documentation manually for repetitions you have to pay a high price:
- increases the burden on authors, labor costs increase;
- when documentation is updated, errors accumulate in it.
Errors arise because making any change to a non-unique text leads to a complete check of the entire material and a similar editing of each repetition. With a sufficient amount of material, this operation is almost impossible to perform with the necessary accuracy.
In addition, if the documentation is developed by a group of authors, each of them, being left to himself, practices his own ways of presenting the material. Because of this, the exposition as a whole turns out to be non-unified, which also has to be considered an error. Even if in each case the information is transmitted correctly, inconsistency (structural, stylistic, terminological) can confuse the reader and push him to wrong actions.
Thus, one of the main tasks that should be addressed by the information architecture is to provide the necessary repetitions in the output documents , but to eliminate them in the material with which the authors work.
Topics, maps of documents, including links
We illustrate the principle stated above with a simplified example (Table 1). At the same time we will get acquainted with the main elements of any information architecture: topics , maps of documents and including links . They are inherent not only in DITA technology, but also in any modern documentation automation technology.
Table 1. Simplified example of building information architecture
| Repeat character | Repeat damage | Architectural solution | Recoil |
| Different documents may include the same sections. | If any section changes, you will have to make changes everywhere with the risk of missing the right one. | Each document included in the package consists of small sections united by a table of contents. | The author corrected the section once, and the changes were reflected in all documents. - Saved time. - Eliminated errors |
| Different sections may contain the same text fragments, for example, typical safety boxes. | If any fragment changes, you will have to make changes everywhere with the risk of missing the right one. | Each sample fragment is placed in a separate file. In the sections we leave only the inclusive links to it. | The author corrected the fragment once, and the changes were reflected in all documents. - Saved time. - Eliminated errors |
In fig. Figure 1 shows the reuse of a partition. (In English-language literature, the term reuse is often used, but I would not like to enrich the Russian language with the word “reuse”).
Sections that are used repeatedly are called topics . The tree structure (in fact, an empty table of contents) used to merge topics into a document will be called a map of this document.
Figure 1. Reuse topic
The volume of the topic should be as small as possible.
The topic should relate to any one topic that has clear boundaries. For example, a topic can reveal the meaning of a particular concept, describe a procedure, contain one set of reference data, etc.
The content and style of the topic should be such as to ensure its relative isolation from other topics. The topic should be, as far as possible, understandable by itself, like an encyclopedia article or a good answer to a question. Otherwise, the authors will have to manually correct this topic each time it is included in the new context.
In fig. 2 shows a deeper level of information architecture. At this level, not documents, but topics are exposed to decomposition.
Figure 2. Reuse sidebar
Division of authorship
Information architecture will only be saved if the following conditions are met.
Ubiquity It is necessary to strictly adhere to decisions made on architecture, follow them systematically, and not occasionally. If topics are used, then all the material should be divided into them; if there are sample boxes, then all of them should be taken out of the topics and collected in some library, etc.
Collectivity As a rule, large sets of documentation are created by several authors. Information architecture provides the ability to achieve effective division of labor within the team. For example:
- technical security specialists or lawyers may compose libraries of frames, the text of which will be carefully verified;
- authors who have understood well in hotel-specific issues can write topics dedicated to them;
- An editor who sees the entire task, can map the documents and ensure the release of the entire set of documentation.
Pass-through example
Further consideration of the techniques of building information architecture, as well as the functionality of the DITA technology, which make the application of these techniques possible, is based on one cross-cutting example.
The plot of the example is as follows. Imagine that we need to organize the production of technical documentation for electric vehicles. Now we have two models of electric vehicles, but their number may further increase.
| All names are fictional, all matches are random. |
- requirements for output documents;
- requirements for implementation;
- architectural solution;
- implementation by means of DITA.
A complete set of source code for the end-to-end example is available on my blog .
Layout of output from topics
Output Requirements
The set of technical documentation for each model includes the following documents:
- manual;
- advertising booklet.
The manual describes the entire model. The advertising booklet contains only general information about it.
Figure 3. Operator's manual (content) and advertising booklet
Requirements for implementation
The repetition of the same text in the draft (in the source material, and not in the output) should be minimized.
Architectural solution
This is a standard solution for DITA technology. It has already been described above. Nevertheless, let us tell about it again and add a few important details.
All documentation material will be presented in the form of a set of topics. To store the topics we will use the folder structure in the file system.
Each output document will have its own map. The document map contains its structure , i.e. the sequence of all its sections, taking into account their nesting. Binding of the topic to the section of the document structure is carried out with the help of an inclusive link. The inclusive link should be defined in the document map, it points to the topic that is mapped to the section of the document structure (not vice versa).
Despite the technical ability to use the same card for the formation of different output documents (for example, using profiling, see below), this is not recommended. If the project expands, for example, as the number of models increases, such an approach can lead to an overly confusing structure that cannot be understood. Try to follow a simple rule: one card - one output document. Although here, as will be shown below, its costs arise.
The proposed solution looks and is commonplace. Unbanal decisions will manifest themselves in the course of further decomposition of the project material.
Implementation by means of DITA
An example of a document map (in this case, this is an advertising booklet on the Zaragoza model) is given below.
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE map PUBLIC "-//OASIS//DTD DITA Map//EN" "map.dtd"> <map id="modSaragosaDatasheet" xml:lang="ru"> <title> «<keyword keyref="prodName"/> <keyword keyref="modName"/>»</title> <!-- --> <mapref href="Common/prodkeys.ditamap"/> <mapref href="Saragosa/modkeys.ditamap"/> <!-- --> <topicref href="Common/topics/overview.dita"/> <topicref href="Common/topics/generalView.dita"/> <topicref href="Common/topics/techParams.dita"/> </map> The use of remote maps and references to keys will be discussed in the following sections of the article.
To generate the output documents, the DITA Open Toolkit package is used in combination with the DITA2PDF2 plugin included in its composition, which is responsible for generating the output documents in PDF format.
Since the advertising booklet has a non-standard design, customization has been prepared for it so-called. It is a set of XSLT styles that change the standard behavior of the DITA2PDF2 plugin. This customization is part of the end-to-end example.
Typing text to library
Output Requirements
According to the condition of our imaginary task, each procedure describing one or another scenario of using an electric vehicle must begin (not necessarily from the very beginning) with a typical sidebar. This box contains a note regarding driver safety, as well as a link to the “Safety” section (Figure 4).
Each procedure describing a particular service scenario for an electric vehicle must also begin with a typical sidebar, but slightly different. Later in the project may be required and other typical sidebar.
Figure 4. Using typical sidebars
Requirements for implementation
All documentation sets must be resistant to changing the text of a typical frame. If changes are made to the text of the standard box (for example, a literary correction has been made or the requirements of new regulatory and technical documents have been taken into account), they should be reflected equally in all operating manuals.
Architectural solution
Create a library of sample text. It will be a single file in DITA format. In this file we will store all fragments of type text. The maintenance of a standard text library will be entrusted to one of the authors, who is particularly well versed in the regulatory framework for technical safety.
Implementation by means of DITA
An example of a sidebar view in the sample text library is shown below. To identify the type of sidebar used attribute @ id. Its value must be unique, at least within the library file.
<note id="noteSafety" type="important"> <p> — . «».</p> </note> <note id="noteSafetyMnt" type="important"> <p> — . «».</p> </note> An example of including a link from a topic to a sample box is shown below. To indicate a typical sidebar, use the @conref attribute.
<note conref="../../Common/topics/_snippets.dita#commonText/noteSafety"/> Text parameterization
Output Requirements
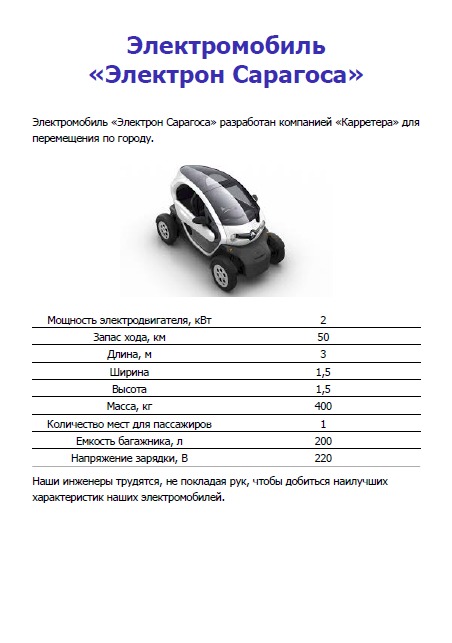
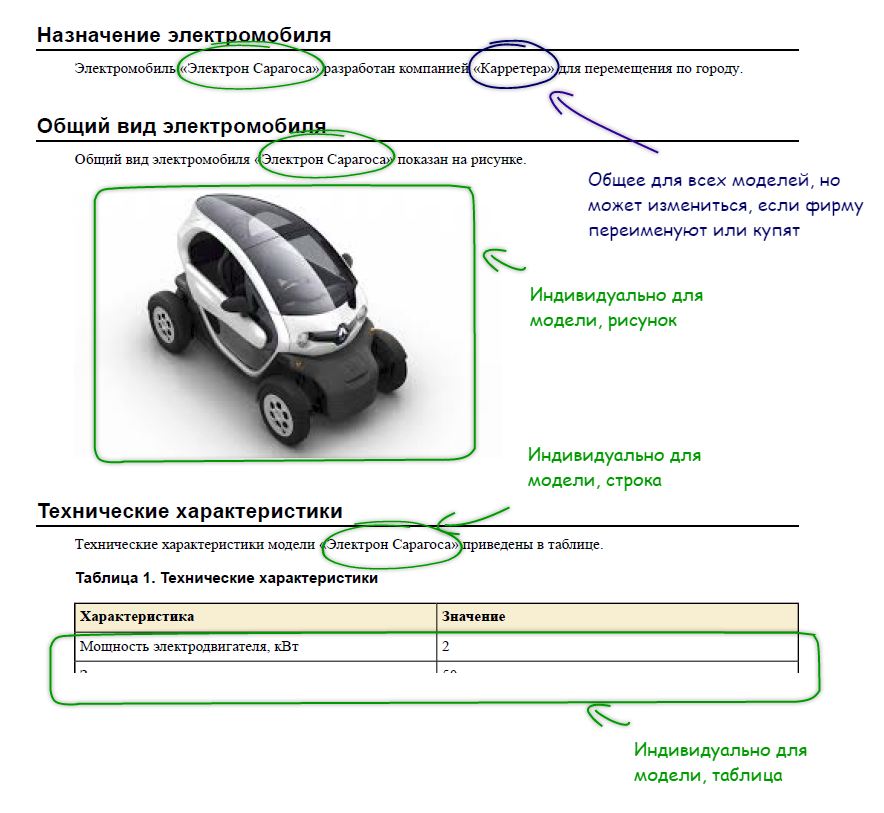
The text of the topics can contain relatively short string values, for example, the name of the company, the name of the product line, the name of the specific model (Fig. 5). In software documentation, these values often include the version number of the software product, the name of the hardware platform, the version of the operating system, the name of the customer, etc.
Figure 5. Text parameterization and its adaptation to the context
If such lines appear in the text, which otherwise would be the same in all documents, there is a temptation to get rid of them somehow, and make topics common to all output documents. For example, instead of the product name, you can use the perivational name of the product , instead of the direct name of the company, the word developer or company , etc.
The idea is good, but it does not always work.
First, marketing considerations play a role, and anyway, somewhere in the document you will have to at least once specify the original names explicitly.
Secondly, short lines are not necessarily names. These can be values of some important parameters, technical limitations, network addresses, port numbers or other data that the reader would prefer to see here, rather than look for them somewhere else in the document.
Therefore, it is impossible to completely get rid of string values. But to consider two texts as different only because they differ from each other in a dozen or so characters, and to place them on this basis in separate topics, you see, it is insulting.
Requirements for implementation
If the text of the topic as a whole is the same for all models, then a single copy of this topic should exist in the project. Values that may change from time to time or from model to model should be incorporated into such topics automatically when generating the output documents.
Architectural solution
Values that are the same for all models, but may change from time to time (the company, the entire product line), we will assign names and set in a common portable map . A shared portable card will exist in a single copy for the entire project. We will include the general portable map in the map of each document in the project.
The values that change from model to model (for example, the name of the model) will be assigned names and set in the remote model map . The remote model card will exist in a single copy for each model. The portable model card will be included in the map of each document related to this model.
In DITA technology, named values are called keys .
In the text of the topic, we will not use the values themselves, but references to the names of the keys. When generating a message, each link to the key name will be automatically replaced with the actual values of this key specified in the external map (Fig. 6).
Figure 6. Parameterization of the topic text using keys and remote maps
Implementation by means of DITA
An example of the definition of a key in a remote model card is shown below. In the general remote card, the same syntax is used to determine the key.
<keydef keys="modName"> <topicmeta> <keywords> <!-- --> <keyword></keyword> </keywords> </topicmeta> </keydef> Examples of including links from a document map to portable maps are shown below.
<!-- --> <mapref href="Common/prodkeys.ditamap"/> <!-- --> <mapref href="Saragosa/modkeys.ditamap"/> An example of a link to the name of a key in the text of the topic is shown below. When forming the output document, the name of the product line and the model name will be inserted into the text. The link to the key name is represented by the keyword element. The key name is specified in the @keyref attribute.
<p props="manual"> «<keyword keyref="prodName"/> <keyword keyref="modName"/>» .</p> Adaptation of the general text to the context
Output Requirements
Not only string values, but also more complex constructions can appear in the text of topics. So, on fig. 5, in addition to string values, a figure and a table are shown. They belong to a specific model of an electric vehicle, but are incorporated in a topic that is common to all models.
Requirements for implementation
If the text of the topic as a whole is the same for all models, then it should be common. In other words, the project should have a single copy of this topic, and maps of all documents, if necessary, should contain inclusive references to it.
Fragments that may change from time to time or from model to model should be incorporated into common topics automatically when generating output documents.
Architectural solution
It is impossible to solve this problem using key parameterization, since the figures and tables are not reduced to string values. For their presentation, full-fledged XML markup is needed. The insertion of such fragments inside the common text is done with the help of indirect inclusive references.
The fragments of the XML markup that are incorporated into common topics will be called permutations.
We collect all the wildcard fragments related to a particular model into one file. We will call this file the model library by analogy with the standard text library. Yes, this is a library of standard text, only related to a particular model, and not to the project as a whole.
To point to the model library, we define a special key in the external model map. The value of this key will be the path to the model library.
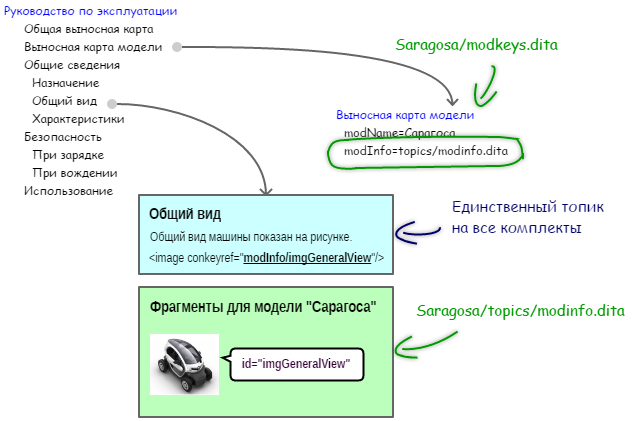
We include the link from the general topic to the desired wildcard fragment from the name of this key and the unique identifier of this wildcard fragment in the model library (Fig. 7).
Figure 7. Indirect including link from general topic to wildcard fragment
Implementation by means of DITA
Below is an example of how a key is specified in the model's external map indicating the library file of this model. The href attribute is used to point to the file in which wildcards are located.
<keydef keys="modInfo" href="topics/modinfo.dita"/> An example of indirect including links from the text of the topic to the substitute fragment is shown below. The image element entirely is an indirect, inclusive link. When generating the output document, it will be completely replaced by the wildcard fragment, which this indirect inclusive link points to. The @conkeyref attribute is used to point to the wildcard fragment. Its value is made up of the name of the key (in the example modInfo) and the value of the @ id attribute of the desired wildcard fragment (in the example imgGeneralView). These two parts of the value of the @conkeyref attribute are typed through a slash.
<fig> <image conkeyref="modInfo/imgGeneralView"/> </fig> Text filtering
Output Requirements
Now we will learn not to add text to topics, but to throw it out from there.
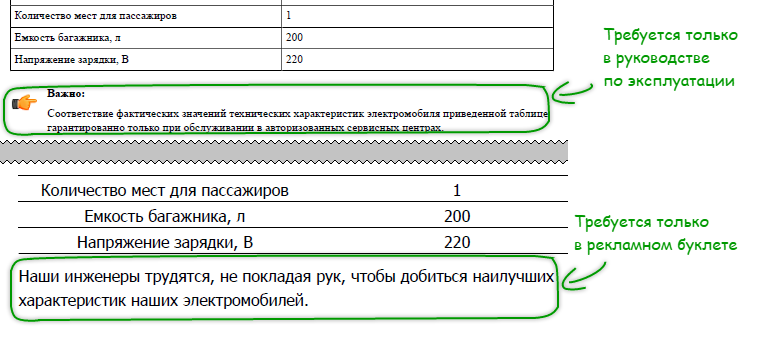
It happens that the topic contains all the necessary information, however, for each specific output, it is redundant. For example, in the topic “Technical characteristics” (I remind you, this is a general topic of the project level), the following table follows the technical characteristics table:
- an indication of the need to service an electric car only in a company service center (otherwise the company does not guarantee the stated parameters);
- advertising praises to the engineers who developed such an outstanding electric machine.
The first box is relevant in the instruction manual, but looks unprofitable in the advertising booklet. The second tie-in, on the contrary, is needed only in an advertising booklet, and in the instruction manual it is already useless. We require that each of these frames be displayed only in the output document where it is needed (Fig. 8).
Figure 8. Text due to output genre
Similarly, a general topic may contain fragments of text that relate only to a particular model (Fig. 9).
Figure 9. Text due to product model
It is easy to imagine other dependencies, for example, some delicate information should be included in the advanced version of the manual for service support centers, but it is not advisable to inform them to end users.
Requirements for implementation
If the topic contains not too numerous fragments that may be redundant in a given context, and each such context can be described by a small number of formal signs of the output document, then filters should be applied to the text of this topic. Creating multiple topics that differ from each other only in such fragments is not allowed.
Architectural solution
If a fragment is to be included in the output document or excluded from the output document when certain conditions are fulfilled or not fulfilled, we will call it conditional . Each conditional fragment will be labeled reflecting the conditions for its inclusion in the document or exclusions from the document.
When forming the output document, we will indicate exactly which conditions for it are fulfilled. Unsuitable snippets will be automatically excluded from the output.
Implementation by means of DITA
For working with conditional fragments, DITA technology offers an advanced profiling mechanism. It allows you to organize filtering conditional fragments in several different ways for several attributes simultaneously.
The DITA specification provides several non-semantic attributes that authors are free to use for profiling, interpreting their values in any way that is meaningful in a particular project.
The rules for selecting conditional fragments when profiling are quite flexible. In some cases, it is more convenient to leave in the output document only neutral fragments and obviously suitable conditional fragments. In other cases, it is easier to exclude obviously inappropriate conditional fragments from the output document.
In general, the main thing in this profiling is not to get confused. Not having the strength to describe the whole mechanism in a small (and without that already too big?) Article, let us give an example of including neutral and clearly suitable fragments in the output document.
An example of markup of the source text of a topic with profiling is given below. To indicate the genre of the document, the @ props attribute is used. Valid values for this attribute are not specified by the DITA specification. They are selected in the development of an information architecture and are part of an agreement adopted at the level of this project.
<note type="important" props="manual"> <p> . </p> </note> <sectiondiv props="datasheet"> <p> , , .</p> </sectiondiv> In order for the profiling to take place, the assembly script of the DITA Open Toolkit package, when generating the output document, among other things, must be passed the so-called DITAVAL file. Instructions should be included in it to include in the output document or exclude from the output document conditional fragments that have certain values of the profiling attributes. An example of such a file is shown below.
<?xml version="1.0" encoding="UTF-8"?> <val> <!-- "" --> <prop att="product" val="" action="include"/> <prop att="props" val="manual" action="include"/> <!-- – ! --> <prop att="product" val="" action="exclude"/> <prop att="props" val="datasheet" action="exclude"/> </val> Typing and templating topics
Output Requirements
One of the main methodological and stylistic principles of writing technical documentation says: this should be described similarly. For example, if we describe the procedures performed by the user, we must always do this on the same plan.
The point is not that somewhere there is the most correct plan for describing a user procedure in the world. Of course not, and in general, user procedures can be described in different ways. But within the framework of one project, it is necessary to establish a plan for the description of the user procedure that is uniform for all authors, and follow it all. Otherwise, inconsistency will begin, and it makes the use of documentation very difficult, because it forces the reader to constantly wonder whether the differences observed by him are significant or accidental.
Requirements for implementation
Different authors participating in a project (or one author participating in a project for a long time) should describe the same type of phenomena or actions in a uniform manner.
Architectural solution
We classify topics, distributing them into several information types. The set of information types in the general case is determined by the features of a particular project. There is a steady (and enshrined in DITA) tradition to begin the classification of topics from their division into three basic information types :
- theoretical;
- procedural;
- reference.
Further classification may consist of a deeper specialization of the three basic information types (for example, we will distinguish between user and installation procedures), and the creation of fundamentally new ones.
For each information type we develop a typical structure . A typical structure can be dictated by the following features, necessarily inherent in the topic, which belongs to this information type:
- a set of rubrics that form the internal structure of the topic;
- the sequence and nesting of headings;
- Mandatory completion of certain categories;
- obligatory presence in some headings of a typical text set for them.
When creating a new topic, the author must first select his information type from the list available in this project. After creating a topic, the author does not receive a “clean sheet”, but a relatively rigid template, which he must follow when writing a topic.
Implementation by means of DITA
The problem of unification of style is often tried to be solved with the help of standards and trainings. In part, they help. But DITA technology, unlike many others, makes it possible to technically force authors to uniformity. For this, the following possibilities are provided.
- Use of basic DITA information types: topic, concept, task, reference, troubleshooting . Each information type is described using a DTD and a schema. If the author types the text of the topic in a more or less modern XML editor (usually it happens), then the latter imposes on it the structure provided by the information type selected when creating this topic.
- Specialization of basic information types, i.e. creating your own DTD or topic schemes based on embedded ones.
Using specialized information types may require additional configuration of the XML editors and the DITA Open Toolkit.
In this case study, not specialization is applied, but templateization. «» . , , , .
. ( XML- ), .
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE task PUBLIC "-//OASIS//DTD DITA Task//EN" "task.dtd"> <task id="concept_hy5_32sn_qcb" xml:lang="ru"> <title> </title> <taskbody> <prereq> <!-- --> <note conref="../../Common/topics/_snippets.dita#commonText/noteSafety"/> </prereq> <context> <!-- , --> <p><b> :</b></p> </context> <steps> <step> <cmd></cmd> </step> </steps> </taskbody> </task> -?
!
, , . , , .
XSLT ( XSLT-) ( runtime-).
, , DITA, . — .
— .
, - . , . ( , , ..) . . , . , - !
, « » , « » , , . , .
( ) , , . , - , .
. . « ». .
-. , , , - .
, DITA — .
Conclusion
, . , , . , , .
, , , . DITA ( ) , , « ». - , «» , , , . , .
Source: https://habr.com/ru/post/348842/
All Articles