Microservice madness will be held in 2018
It was with such a thesis made by Dave Kerr, whose article gathered 90 comments a month, provoked heated discussions on Reddit and Hacker News , and we were so interested that we decided to urgently translate it. Taking this opportunity, let us take an interest: do you want the reprint of Sam Newman’s founding book “ Creating Microservices ”, which was last published here in 2016, or does Mr. Kerr’s skepticism seem reasonable to you?
Read and comment!
In the past couple of years, the topic of microservices has become very popular. “Fanaticism” of microservice lovers is reduced to something like this syllogism:
Here I will describe in detail what microservices are, why this paradigm is so attractive, and what are the main challenges that it poses to you.
')
In the final, I will formulate a few simple questions, which are probably worth answering myself, thinking - are microservices suitable for you?

What are microservices, and why are they so popular?
Let's start with the basics. Here's how to implement a hypothetical video sharing platform: first as a monolith (a single large structure), and then as microservices:
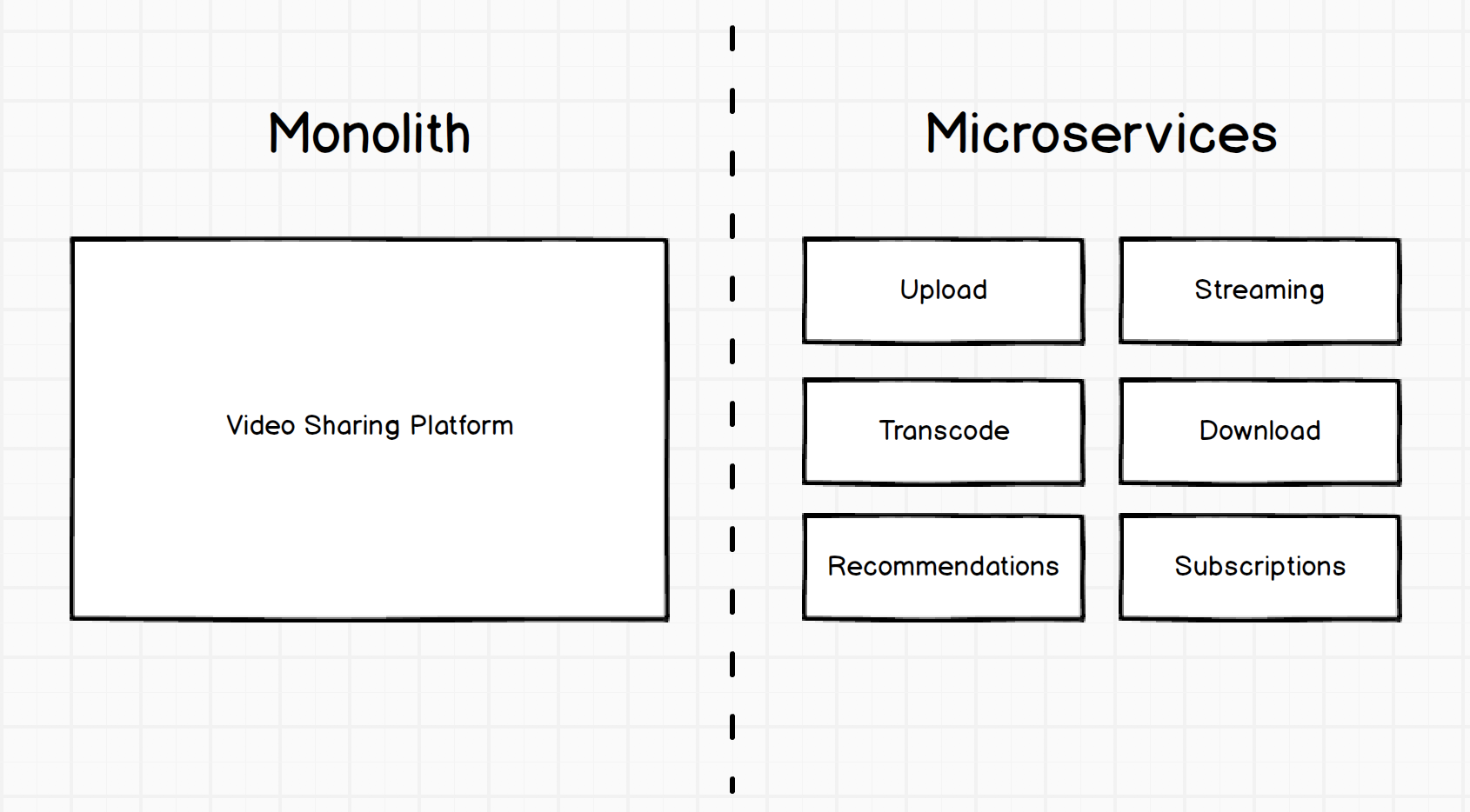
The difference is that in the first case we have one big structure, and in the second - a set of small specific services. Each service plays a specific role.
If to draw the scheme with such detailing - it is, of course, attractive. Potential merits:
Independent development : small independent components can be created by small independent teams. The group can modify the changes in the “Download” service without interfering with the development of the “Recode” service - or even without knowing about it. The time required to familiarize with the component is significantly reduced, and it is easier to develop new features.
Independent deployment : Each individual component can be deployed independently of the others. Thus, new features can be rolled out faster, with less risk. If we modify or fix the Streaming Video component, we can deploy it as needed, and we do not need to deploy other components.
Independent Scalability : All components can be scaled independently of each other. In the hot season, when new shows are coming out, the Download component can be enhanced to cope with the increased load, and this does not require building up all the other components. Elastic scaling, it turns out, is not so difficult to implement, the cost of development is reduced.
Reuse : Each component has a small specific function. Thus, they are easy to adapt for use in other systems, services, or products. Thus, the “transcoding” component can be used in business elements or even turned into a new component of business logic, possibly providing transcoding options for other groups.
With such an approximation, the superiority of microservices over the monolith seems obvious. So, what's the matter - why is this paradigm most recently in favor? Where was she before?
If they are so cool, why hasn't anyone done it before?
There are two answers to this question. First: engaged - as far as our technical capabilities allowed. Second, only the latest technological breakthroughs allowed to bring microservice technology to a new level.
When I began to write the answer to this question, I got a long explanation, so I decided to put it in a separate article and publish it later. At this stage, I will not describe the paths from one program to many, I will not dwell on ESB and service-oriented architecture, component design, limited contexts, etc.
Those who are interested can read about this path separately. I would prefer to say that, one way or another, we did it earlier, but thanks to the recent surge in popularity of container technologies (in particular, Docker) and orchestration (for example, Kubernetes, Mesos, Consul, etc.), this pattern has become much easier to implement. from a technical point of view.
So, if we take for granted that we can really build a microservice system, then we should carefully consider: is it necessary? Theoretically, in the most general terms, the benefits are clear, and what are the challenges?
What is the problem with microservices?
If microservices are so great, so what's the deal? These are some of the major issues that I see.
The task of the developer is complicated
For the developer, everything can be seriously complicated. If a programmer wants to develop a whole sequence , or a feature that potentially covers a multitude of services, then he will have to run them all on one machine, or connect to them. Often it is much more difficult than taking and running a single program.
This problem is partially solved with the help of appropriate tools, but as the number of services in the system increases, it will be harder for the developer to run the entire system.
The tasks of the operators are complicated
For teams that do not develop services, but support them, the increase in complexity can be explosive. It is necessary to manage not several services, but several dozens, hundreds or thousands. More services, more communication paths, more potential points of failure.
Devops tasks are complicated
It is possible that someone jarred over that in the two previous points exploitation and support are treated separately, especially considering how popular the practice of devops is today (by the way, I use it with both hands). Doesn't devops solve these problems?
The problem is that in many organizations, operation and support are still performed by different teams, and it is in such an organization that the transition to microservices is likely to be slowed down.
For organizations already practicing devops, everything is also complicated. Being a developer and an operator at the same time is already difficult (but it is necessary to write good programs), but if you also need to understand the nuances of container orchestration systems, especially systems that are rapidly developing, it is extremely difficult. Here I come to the next item.
Need serious experience
If such work is done by experts, the result can be great. But imagine an organization where, even when operating a single monolith system, everything is not going smoothly. Name at least one reason why things can get better if the company increases the number of systems, and hence the complexity of their operation?
Yes, with effective automation, monitoring, orchestration, etc. all this is possible. But the problem is usually not in technology, but in the shortage of people who can use it effectively. Such skill sets are very much in demand today, and it is difficult to find a good specialist.
In real systems, the boundaries between components are often fuzzy.
In all the examples in which the advantages of microservices were demonstrated, we talked about independent components. However, they are often simply not independent. On paper, some subject areas may seem clearly delineated, but if you go deeper, in particular, it turns out that the problem is more complicated than you thought.
Here everything can become quite difficult. If the boundaries of components in your system are not clearly defined, then what happens is: although, theoretically, services can be deployed independently of each other, in practice it turns out that they are interdependent and therefore you have to deploy a set of services as a group.
This means that you have to manage the agreed versions of the services, that is, services whose reliability has been proven, interactions have been verified. But in this case, we are no longer talking about an independently deployable system, since developing a new feature requires carefully orchestrating the simultaneous deployment of multiple services.
Often ignored are state related complications.
In the previous example, I mentioned that to deploy features, you may need to simultaneously roll out multiple versions of different services as a single group. It is suggesting that this problem is resolved if you use sensible deployment techniques, for example, blue / green deployment options (which is done with little effort on most orchestration platforms), or when several versions of the service are used in parallel — the consuming channels themselves determine which version use.
Such techniques allow you to remove a lot of problems if the services do not save state. But, to be honest, it is easy to work with such services. In fact, if you are working with stateless services, it is better not to contact the microservice configuration at all and immediately try a serverless model.
In fact, many services require maintaining state . Continuing the example with our video sharing platform, an example of such a service could be a subscription. New versions of the subscription service can store information in a subscription database in a different configuration. If you operate both services in parallel, then two schemes work simultaneously in your system. If you are implementing a green / blue deployment, and other services depend on the data provided in this new configuration, then you need to update them at the same time. If the subscription service cannot be deployed and you have to roll back, then you may need to roll back all dependent services, which can lead to avalanche-like consequences.
Again, it suggests that when using NoSQL databases, such problems with schemas disappear - but this is not the case. Databases that do not impose a specific schema do not generate schema-free systems — simply the management of such a schema is usually implemented at the application level, and not at the database level. The key problem in this case is to understand the configuration of your data as it develops. From her nowhere to go.
Communication difficulties are often ignored.
When building a vast network of interdependent services, it is likely that it will be necessary to provide active communication between them. Here a few more problems arise. First, the number of potential points of failure increases significantly. It should be borne in mind that some network calls will not go through, and this means that when one service calls another, it must be programmed for a minimum number of attempts.
Now, when the service can potentially cause many other services, we find ourselves in a difficult situation.
Suppose a user uploads a new video to our video platform. We need to start the download service, transfer the data to the transcoding service, update the subscriptions, update the recommendations, etc. All these calls require orchestration to one degree or another, and if the call doesn’t pass, you need to try again.
Such a retry logic can become difficult to manage. Synchronous operations are often not feasible, because there are too many potential points of failure. In this case, it is most reasonable to organize communication using asynchronous patterns. The most difficult thing in this case is that a system with asynchronous communication, by definition, requires building a system with state preservation. As I mentioned in the previous paragraph, it is very difficult to manage systems with state saving and with distributed states.
If the communication between the services of the microservice system is carried out with the help of message queues, we, in essence, have a large database (message queue or broker) “gluing together” these services. Again, at first glance, such a system may not seem problematic, but later it comes around to you. A service in version X can record a message in a specific format, and other services that depend on this message will also need to be updated if the sending service changes the details of the message it sends.
You can write such services that can process messages in many different formats, but it will be hard to manage such services. In this case, when deploying new versions of services, situations are possible when different services try to process messages from the same queue, perhaps even transmitted by different versions of the sending service. Then there may be complex borderline cases. In order to avoid them, it may be easier to allow only certain versions of messages to exist: that is, deploy a set of versions of a certain set of services as a consistent whole and ensure that outdated versions of messages will be discarded first.
Here, again, you can make sure that in practice, independent deployment is not so easy to organize, if you look at the details.
Versioning can be tricky
To partially eliminate the above problems, you need to very carefully manage the versioning. Again, it often seems that if you stick to a standard like semserver, then this problem is solved. No, not solved. It is reasonable to stick to Semserver, but you still have to keep track of the versions of services and APIs, and see which ones can interact.
Such problems can very quickly become very complicated, and reach a point where you yourself will not be able to imagine which services normally interact with each other.
It is notorious how difficult it is to manage dependencies in a system consisting of Java modules, C libraries, etc. Difficulties with conflicts between independent components consumed by a specific object are solved very hard.
They are complex, even if the dependencies are static - and they can be patched, updated, edited, etc .; but, if the dependencies themselves are living services, then they probably already cannot be simply updated; you will have to drive a lot of versions at once (the attendant difficulties are described above), or to stop the system until it is completely updated and fixed again.
Distributed transactions
In situations where it is necessary to preserve the integrity of transactions within the entire operation, microservices can become a real headache. It is difficult to work with the distributed state, orchestration of many small modules, each of which may fail, is still a task.
You can try to get around this problem by making the operations idempotent, with the possibility of retries, etc., in many cases it will work. But scenarios are possible when we need to implement only two outcomes of a transaction - “succeeded” or “failed”, and not to provide an intermediate state. The price of such a maneuver or an attempt to implement such a system using microservices can be very high.
Microservices can be disguised monolith
Yes, single services and components can be deployed separately, but in most cases it will be necessary to use any orchestration platform, for example, Kubernetes. If you use a managed service, for example, GKE from Google or EKS from Amazon, then complex cluster management will be largely automated.
However, if you manage the cluster yourself, then you are dealing with a large, complex system, failures in which are unacceptable. Yes, a separate service may have all the advantages described above, but it will be necessary to manage the cluster very carefully. Deploying such a system can be difficult, updating is difficult, recovering from a failure is difficult, and so on.
Often, the fundamental advantages go nowhere, but it is important not to simplify the system and not to underestimate the additional difficulties associated with managing another large and complex system. Yes, managed services may be useful, but many of them have just appeared (for example, Amazon EKS appeared only at the end of 2017).
Finally: do not confuse microservices with architecture
I specifically tried not to use the words in the article with the letter “a”. But my friend Zoltan , who read this article (we co-authored it), noticed a very important thing.
Microservice architecture does not exist. Microservices is just another implementation principle for components, nothing more, nothing less. The presence or absence of microservices in the system does not mean that its architectural problems have been solved.
In many respects, microservices are more concerned with packaging and operation, and not with system design as such. When engineering such systems, one of the most important tasks is to properly distinguish the components.
Regardless of what size your services are, whether they are packed in Docker containers or not - it is always important to think about how to fold the system out of the elements. There is no single answer, there are always many options.
Read and comment!
In the past couple of years, the topic of microservices has become very popular. “Fanaticism” of microservice lovers is reduced to something like this syllogism:
In Netflix, the devops practice is fine. Netfix is a microservice. Therefore: if I become a microservice, I’ll succeed in devops.There are examples when microservice patterns were introduced at the cost of tremendous efforts, and their supporters did not quite understand what the costs of this work were, and whether microservices are great in solving this particular problem.
Here I will describe in detail what microservices are, why this paradigm is so attractive, and what are the main challenges that it poses to you.
')
In the final, I will formulate a few simple questions, which are probably worth answering myself, thinking - are microservices suitable for you?
What are microservices, and why are they so popular?
Let's start with the basics. Here's how to implement a hypothetical video sharing platform: first as a monolith (a single large structure), and then as microservices:
The difference is that in the first case we have one big structure, and in the second - a set of small specific services. Each service plays a specific role.
If to draw the scheme with such detailing - it is, of course, attractive. Potential merits:
Independent development : small independent components can be created by small independent teams. The group can modify the changes in the “Download” service without interfering with the development of the “Recode” service - or even without knowing about it. The time required to familiarize with the component is significantly reduced, and it is easier to develop new features.
Independent deployment : Each individual component can be deployed independently of the others. Thus, new features can be rolled out faster, with less risk. If we modify or fix the Streaming Video component, we can deploy it as needed, and we do not need to deploy other components.
Independent Scalability : All components can be scaled independently of each other. In the hot season, when new shows are coming out, the Download component can be enhanced to cope with the increased load, and this does not require building up all the other components. Elastic scaling, it turns out, is not so difficult to implement, the cost of development is reduced.
Reuse : Each component has a small specific function. Thus, they are easy to adapt for use in other systems, services, or products. Thus, the “transcoding” component can be used in business elements or even turned into a new component of business logic, possibly providing transcoding options for other groups.
With such an approximation, the superiority of microservices over the monolith seems obvious. So, what's the matter - why is this paradigm most recently in favor? Where was she before?
If they are so cool, why hasn't anyone done it before?
There are two answers to this question. First: engaged - as far as our technical capabilities allowed. Second, only the latest technological breakthroughs allowed to bring microservice technology to a new level.
When I began to write the answer to this question, I got a long explanation, so I decided to put it in a separate article and publish it later. At this stage, I will not describe the paths from one program to many, I will not dwell on ESB and service-oriented architecture, component design, limited contexts, etc.
Those who are interested can read about this path separately. I would prefer to say that, one way or another, we did it earlier, but thanks to the recent surge in popularity of container technologies (in particular, Docker) and orchestration (for example, Kubernetes, Mesos, Consul, etc.), this pattern has become much easier to implement. from a technical point of view.
So, if we take for granted that we can really build a microservice system, then we should carefully consider: is it necessary? Theoretically, in the most general terms, the benefits are clear, and what are the challenges?
What is the problem with microservices?
If microservices are so great, so what's the deal? These are some of the major issues that I see.
The task of the developer is complicated
For the developer, everything can be seriously complicated. If a programmer wants to develop a whole sequence , or a feature that potentially covers a multitude of services, then he will have to run them all on one machine, or connect to them. Often it is much more difficult than taking and running a single program.
This problem is partially solved with the help of appropriate tools, but as the number of services in the system increases, it will be harder for the developer to run the entire system.
The tasks of the operators are complicated
For teams that do not develop services, but support them, the increase in complexity can be explosive. It is necessary to manage not several services, but several dozens, hundreds or thousands. More services, more communication paths, more potential points of failure.
Devops tasks are complicated
It is possible that someone jarred over that in the two previous points exploitation and support are treated separately, especially considering how popular the practice of devops is today (by the way, I use it with both hands). Doesn't devops solve these problems?
The problem is that in many organizations, operation and support are still performed by different teams, and it is in such an organization that the transition to microservices is likely to be slowed down.
For organizations already practicing devops, everything is also complicated. Being a developer and an operator at the same time is already difficult (but it is necessary to write good programs), but if you also need to understand the nuances of container orchestration systems, especially systems that are rapidly developing, it is extremely difficult. Here I come to the next item.
Need serious experience
If such work is done by experts, the result can be great. But imagine an organization where, even when operating a single monolith system, everything is not going smoothly. Name at least one reason why things can get better if the company increases the number of systems, and hence the complexity of their operation?
Yes, with effective automation, monitoring, orchestration, etc. all this is possible. But the problem is usually not in technology, but in the shortage of people who can use it effectively. Such skill sets are very much in demand today, and it is difficult to find a good specialist.
In real systems, the boundaries between components are often fuzzy.
In all the examples in which the advantages of microservices were demonstrated, we talked about independent components. However, they are often simply not independent. On paper, some subject areas may seem clearly delineated, but if you go deeper, in particular, it turns out that the problem is more complicated than you thought.
Here everything can become quite difficult. If the boundaries of components in your system are not clearly defined, then what happens is: although, theoretically, services can be deployed independently of each other, in practice it turns out that they are interdependent and therefore you have to deploy a set of services as a group.
This means that you have to manage the agreed versions of the services, that is, services whose reliability has been proven, interactions have been verified. But in this case, we are no longer talking about an independently deployable system, since developing a new feature requires carefully orchestrating the simultaneous deployment of multiple services.
Often ignored are state related complications.
In the previous example, I mentioned that to deploy features, you may need to simultaneously roll out multiple versions of different services as a single group. It is suggesting that this problem is resolved if you use sensible deployment techniques, for example, blue / green deployment options (which is done with little effort on most orchestration platforms), or when several versions of the service are used in parallel — the consuming channels themselves determine which version use.
Such techniques allow you to remove a lot of problems if the services do not save state. But, to be honest, it is easy to work with such services. In fact, if you are working with stateless services, it is better not to contact the microservice configuration at all and immediately try a serverless model.
In fact, many services require maintaining state . Continuing the example with our video sharing platform, an example of such a service could be a subscription. New versions of the subscription service can store information in a subscription database in a different configuration. If you operate both services in parallel, then two schemes work simultaneously in your system. If you are implementing a green / blue deployment, and other services depend on the data provided in this new configuration, then you need to update them at the same time. If the subscription service cannot be deployed and you have to roll back, then you may need to roll back all dependent services, which can lead to avalanche-like consequences.
Again, it suggests that when using NoSQL databases, such problems with schemas disappear - but this is not the case. Databases that do not impose a specific schema do not generate schema-free systems — simply the management of such a schema is usually implemented at the application level, and not at the database level. The key problem in this case is to understand the configuration of your data as it develops. From her nowhere to go.
Communication difficulties are often ignored.
When building a vast network of interdependent services, it is likely that it will be necessary to provide active communication between them. Here a few more problems arise. First, the number of potential points of failure increases significantly. It should be borne in mind that some network calls will not go through, and this means that when one service calls another, it must be programmed for a minimum number of attempts.
Now, when the service can potentially cause many other services, we find ourselves in a difficult situation.
Suppose a user uploads a new video to our video platform. We need to start the download service, transfer the data to the transcoding service, update the subscriptions, update the recommendations, etc. All these calls require orchestration to one degree or another, and if the call doesn’t pass, you need to try again.
Such a retry logic can become difficult to manage. Synchronous operations are often not feasible, because there are too many potential points of failure. In this case, it is most reasonable to organize communication using asynchronous patterns. The most difficult thing in this case is that a system with asynchronous communication, by definition, requires building a system with state preservation. As I mentioned in the previous paragraph, it is very difficult to manage systems with state saving and with distributed states.
If the communication between the services of the microservice system is carried out with the help of message queues, we, in essence, have a large database (message queue or broker) “gluing together” these services. Again, at first glance, such a system may not seem problematic, but later it comes around to you. A service in version X can record a message in a specific format, and other services that depend on this message will also need to be updated if the sending service changes the details of the message it sends.
You can write such services that can process messages in many different formats, but it will be hard to manage such services. In this case, when deploying new versions of services, situations are possible when different services try to process messages from the same queue, perhaps even transmitted by different versions of the sending service. Then there may be complex borderline cases. In order to avoid them, it may be easier to allow only certain versions of messages to exist: that is, deploy a set of versions of a certain set of services as a consistent whole and ensure that outdated versions of messages will be discarded first.
Here, again, you can make sure that in practice, independent deployment is not so easy to organize, if you look at the details.
Versioning can be tricky
To partially eliminate the above problems, you need to very carefully manage the versioning. Again, it often seems that if you stick to a standard like semserver, then this problem is solved. No, not solved. It is reasonable to stick to Semserver, but you still have to keep track of the versions of services and APIs, and see which ones can interact.
Such problems can very quickly become very complicated, and reach a point where you yourself will not be able to imagine which services normally interact with each other.
It is notorious how difficult it is to manage dependencies in a system consisting of Java modules, C libraries, etc. Difficulties with conflicts between independent components consumed by a specific object are solved very hard.
They are complex, even if the dependencies are static - and they can be patched, updated, edited, etc .; but, if the dependencies themselves are living services, then they probably already cannot be simply updated; you will have to drive a lot of versions at once (the attendant difficulties are described above), or to stop the system until it is completely updated and fixed again.
Distributed transactions
In situations where it is necessary to preserve the integrity of transactions within the entire operation, microservices can become a real headache. It is difficult to work with the distributed state, orchestration of many small modules, each of which may fail, is still a task.
You can try to get around this problem by making the operations idempotent, with the possibility of retries, etc., in many cases it will work. But scenarios are possible when we need to implement only two outcomes of a transaction - “succeeded” or “failed”, and not to provide an intermediate state. The price of such a maneuver or an attempt to implement such a system using microservices can be very high.
Microservices can be disguised monolith
Yes, single services and components can be deployed separately, but in most cases it will be necessary to use any orchestration platform, for example, Kubernetes. If you use a managed service, for example, GKE from Google or EKS from Amazon, then complex cluster management will be largely automated.
However, if you manage the cluster yourself, then you are dealing with a large, complex system, failures in which are unacceptable. Yes, a separate service may have all the advantages described above, but it will be necessary to manage the cluster very carefully. Deploying such a system can be difficult, updating is difficult, recovering from a failure is difficult, and so on.
Often, the fundamental advantages go nowhere, but it is important not to simplify the system and not to underestimate the additional difficulties associated with managing another large and complex system. Yes, managed services may be useful, but many of them have just appeared (for example, Amazon EKS appeared only at the end of 2017).
Finally: do not confuse microservices with architecture
I specifically tried not to use the words in the article with the letter “a”. But my friend Zoltan , who read this article (we co-authored it), noticed a very important thing.
Microservice architecture does not exist. Microservices is just another implementation principle for components, nothing more, nothing less. The presence or absence of microservices in the system does not mean that its architectural problems have been solved.
In many respects, microservices are more concerned with packaging and operation, and not with system design as such. When engineering such systems, one of the most important tasks is to properly distinguish the components.
Regardless of what size your services are, whether they are packed in Docker containers or not - it is always important to think about how to fold the system out of the elements. There is no single answer, there are always many options.
Source: https://habr.com/ru/post/348740/
All Articles