Experiment with binary code in Glimmer
Translation of an article about the experiment with a binary code in Glimmer , co-authors of the publication: Sarah Clutterbuck, Chad Hietala and Tom Dale.
Just over a year ago, Ember.js underwent significant changes. In close collaboration between the LinkedIn engineers and the Open Source community, we replaced Ember with the new engine for Randirang, Glimmer VM, which improved performance and significantly reduced the size of the compiled templates.
Glimmer refers to Handlebars patterns as a functional programming language and compiles them into a sequence of instructions that can be executed in a browser. These instructions, or opcodes (approx. Translator operation codes) are encoded into a compact data structure in the form of JSON.
')
When we migrated our web site linkedin.com to Glimmer, we saw significant improvements in load times. In addition to reducing the size of files by 40%, we also reduced the time spent by the browser on the analysis of JavaScript, due to the compilation of templates in JSON. Moreover, this change improved boot time in 90% of cases by more than 1 second.
In this article, we will discuss a recent experiment to further improve loading times, completely eliminating the time required to parse compiled templates.
About six months ago, the Ember.js team announced the release of Glimmer.js as a separate component library. Separating the presentation layer allowed us to take the best from Ember and the Glimmer virtual machine, and pass it on to developers who create lightweight products, such as mobile apps for emerging markets, or SEO pages.
Glimmer's breakthrough allowed our team to conduct many experiments in the coming months.
Recently, for example, we presented a gibid render, in which html is generated on the server and then rehydrated happens (for example, see the translator here ) in the browser. This is just the beginning of the performance benefits provided by the Glimmer virtual machine architecture.
The Web’s holy grail of performance is the ability to quickly boot up, quickly update when the user performs actions (maintaining performance 60fps), and ensuring the default performance, which means that large teams with less experienced developers can create effective web applications without significant intervention. .
Traditionally, there is a dilemma between delivering the minimum amount of JavaScript code to run instant downloads and the ability to have a complex responsive UI. It seems that the fundamental compromise is that as the application grows, productivity and productivity decrease. With Glimmer, our goal is to create light, fast and productive applications. One of the keys to achieving this goal is to reduce the costs of each new component added to the application.
When switching from JavaScript to JSON, the cost of parsing compiled templates is reduced, we combined Glimmer with advanced browser functions to completely eliminate the parsing step.
When optimizing load times, most developers try to reduce file sizes in order to speed up downloads. But in JavaScript-based applications, startup performance is also affected by the ability of the browser to analyze, compile, and evaluate your code. What is significant, since the analysis and compilation of JavaScript code on mobile devices is 2-5 times slower than on desktop computers. Only this single step can significantly affect the overall performance of the application.
Today, most frameworks compile the view (view) in JavaScript functions. The costs of parsing such JavaScript code are often hidden, and as new functions are added, the application runs slower and slower.
As mentioned above, Glimmer compiles templates into a sequence of opcodes, which are transmitted to the browser as JSON. Due to the fact that the JSON grammar is much simpler than the JavaScript grammar, the JSON parser can work 10 times faster than the JavaScript parser when parsing the same data.
But it still means that the time of parsing will increase as the size of the template increases, the truth is already slower. What if we could bypass the parsing step altogether?
In recent years, browsers have learned to perfectly handle binary data. Using a low-level API, such as ArrayBuffer , JavaScript programs can process binary data as quickly as their native counterparts. We took advantage of this to compile templates into our own bytecode format, which the Glimmer virtual machine can perform directly. Similar to the JVM bytecode format, the Glimmer bytecode is a platform-independent binary format that encodes the instruction set of the Glimmer virtual machine into a stream of bytes consisting of opcodes and its operators. Instead of running into the performance of parsing JSON or JavaScript, now we are only limited by the ability of the browser to copy raw bytes from the network.
As with many virtual machines, the instructions in the Glimmer virtual machine are recognized by numbers. a bytecode is just an encoded sequence of these numbers. The uniqueness of Glimmer lies in the fact that its command set is intended for rendering DOM in a browser.
For example, a pattern
will be compiled into the following JSON format at build time:
In the browser at the last JSON compilation step, the format will be turned into an array of numbers, each number is an operation code or operand:
Notice that the strings in our JSON were replaced by integers. This is because we use the so-called “string interning” technique, which eliminates duplication of identical strings, here the strings are replaced by a shift in the pool of string constants, which in practice significantly reduces the file size (just imagine how many times you repeat the string div in your templates).
Initially, our bytecode encoded each operation as four 32-bit integers, where the first 32-bit number described the type of operation (opcode), and the remaining 96 bits described up to three instruction arguments (operands).
Despite the fact that this approach is effective for executing code, there is a minus - the size of the files with byte-code is larger than necessary. This is because we always reserve space for three operands, although most instructions do not need operands or accept only one operand. Thus, the program is filled with empty bytes, which should not have been there. In addition, the Glimmer instruction set contains only 80 opcodes, so we can reduce the reserved space for opcodes to 8 bits.
Ultimately, we stopped at a more compact coding scheme, which was still 16-bit. The first 8 bits are an opcode, the next 2 bits are used to encode the number of operands, and the last 6 bits are reserved for future use. Each operand, if any, is encoded in an additional 16 bits.
With this coding scheme, each instruction can take from two to six bytes, it looks like this:
This new scheme reduces the size of the compiled program by 50%. "Decoding" of this scheme has a slight overhead, since we simply mask and shift the bits to find out the length of the opcode and the length of the operand.
One of the problems we encountered was to move the entire compilation phase into the project builder. Previously, we performed the last step of compiling templates in the browser as soon as the JavaScript code of the application was loaded. This allowed us to combine compiled templates with JavaScript objects, such as component classes that processed user actions.
The first step was to provide all levels of compilation on Node.js. We created a new interface called “bundle compiler”, which encapsulated all levels of compilation into one API, which allowed the build tools to turn the “bundle” of templates into byte-code.
Then we faced an additional problem: when compiling to bytecode, how would we “connect” this bytecode back to the right JavaScript objects at runtime? To solve this problem, we introduced the concept of “handles” (handlers). A handler is a unique numeric identifier that is associated with external objects in a template, such as components or helpers. During compilation, we associate each external object with a handler, which is encoded into bytecode. For example, if we see a call to the <UserProfile /> component, we can associate it with the handler with identifier 42 (assuming that 41 unique components have already been called before).
A component call for this is compiled into several opcodes in the Glimmer command set. One of these instructions is 0x003b PushComponentDefinition , which pushes the component's JavaScript class onto the virtual machine (VM) stack. When compiling to bytecode, this instruction will create four bytes: 0x00 0x3b 0x01 0x2A . The first two bytes encode the opcode PushComponentDefinition . The second two bytes encode the operand, which in this case is a processor (the number 42).
And so what happens when we run the bytecode in the browser? How to turn the whole number 42 into a living, breathing JavaScript class? We call this trick the “external module table”. This is a small fragment of the generated JavaScript code that unites the two worlds, defining a data structure that allows you to effectively map handlers with the corresponding JavaScript classes.
In our example, we have associated UserProfile with handler 42, so our plug-in table is an array, where the class UserProfile is 42 elements in the array.
During the execution of a bytecode, a helper object called a “resolver” turns the handler into a corresponding JavaScript object. Since each handler is also an offset in the array, this code is simple and fast:
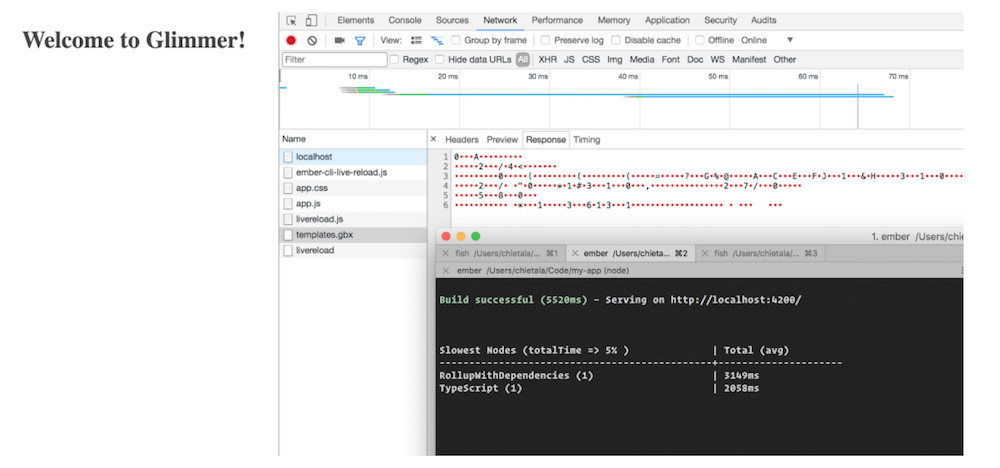
Build the project in .gbx format (Glimmer Binary Experience), transfer to the browser, and VM rendering the header in the browser.
We simply integrated the bytecode compiler into the internal application to prove the concept of Glimmer.js and look forward to collecting real results in the production application. This will help us assess the impact of these changes in the real world with different participants on different hardware, operating systems, browsers, and bandwidth combinations.
Since Glimmer's bytecode reduces file size and completely eliminates the cost of parsing and compiling the last step, we expect significant improvements in application launch time, especially on devices with weak hardware capabilities, where the CPU is a bottleneck. Perhaps more importantly, the process of matching the file format and the internal elements of a virtual machine in the direction of a well-defined binary format opens up many interesting experiments in the future. In particular, our chosen bytecode format means that we are in a good position to research and change some parts of the Glimmer virtual machine in the direction of WebAssembly technology, reducing the cost of parsing and further improving performance at runtime.
We are all LinkedIn big fans of open source, and all the work described above was opened on GitHub. If we are interested in the Glimmer project, we invite you to the Glimmer VM and Glimmer.js repositories on GitHub.
Many thanks to Chad Hietale and Tom Dale , who set about compiling a bytecode on LinkedIn. In addition, thanks to Yehuda Katz and Godfrey Chen for helping to realize this vision in the open source community.
Just over a year ago, Ember.js underwent significant changes. In close collaboration between the LinkedIn engineers and the Open Source community, we replaced Ember with the new engine for Randirang, Glimmer VM, which improved performance and significantly reduced the size of the compiled templates.
Glimmer refers to Handlebars patterns as a functional programming language and compiles them into a sequence of instructions that can be executed in a browser. These instructions, or opcodes (approx. Translator operation codes) are encoded into a compact data structure in the form of JSON.
')
When we migrated our web site linkedin.com to Glimmer, we saw significant improvements in load times. In addition to reducing the size of files by 40%, we also reduced the time spent by the browser on the analysis of JavaScript, due to the compilation of templates in JSON. Moreover, this change improved boot time in 90% of cases by more than 1 second.
In this article, we will discuss a recent experiment to further improve loading times, completely eliminating the time required to parse compiled templates.
Expanding the experiment with Glimmer.js
About six months ago, the Ember.js team announced the release of Glimmer.js as a separate component library. Separating the presentation layer allowed us to take the best from Ember and the Glimmer virtual machine, and pass it on to developers who create lightweight products, such as mobile apps for emerging markets, or SEO pages.
Glimmer's breakthrough allowed our team to conduct many experiments in the coming months.
Recently, for example, we presented a gibid render, in which html is generated on the server and then rehydrated happens (for example, see the translator here ) in the browser. This is just the beginning of the performance benefits provided by the Glimmer virtual machine architecture.
The Web’s holy grail of performance is the ability to quickly boot up, quickly update when the user performs actions (maintaining performance 60fps), and ensuring the default performance, which means that large teams with less experienced developers can create effective web applications without significant intervention. .
Traditionally, there is a dilemma between delivering the minimum amount of JavaScript code to run instant downloads and the ability to have a complex responsive UI. It seems that the fundamental compromise is that as the application grows, productivity and productivity decrease. With Glimmer, our goal is to create light, fast and productive applications. One of the keys to achieving this goal is to reduce the costs of each new component added to the application.
Instant Templates
When switching from JavaScript to JSON, the cost of parsing compiled templates is reduced, we combined Glimmer with advanced browser functions to completely eliminate the parsing step.
When optimizing load times, most developers try to reduce file sizes in order to speed up downloads. But in JavaScript-based applications, startup performance is also affected by the ability of the browser to analyze, compile, and evaluate your code. What is significant, since the analysis and compilation of JavaScript code on mobile devices is 2-5 times slower than on desktop computers. Only this single step can significantly affect the overall performance of the application.
Today, most frameworks compile the view (view) in JavaScript functions. The costs of parsing such JavaScript code are often hidden, and as new functions are added, the application runs slower and slower.
As mentioned above, Glimmer compiles templates into a sequence of opcodes, which are transmitted to the browser as JSON. Due to the fact that the JSON grammar is much simpler than the JavaScript grammar, the JSON parser can work 10 times faster than the JavaScript parser when parsing the same data.
But it still means that the time of parsing will increase as the size of the template increases, the truth is already slower. What if we could bypass the parsing step altogether?
In recent years, browsers have learned to perfectly handle binary data. Using a low-level API, such as ArrayBuffer , JavaScript programs can process binary data as quickly as their native counterparts. We took advantage of this to compile templates into our own bytecode format, which the Glimmer virtual machine can perform directly. Similar to the JVM bytecode format, the Glimmer bytecode is a platform-independent binary format that encodes the instruction set of the Glimmer virtual machine into a stream of bytes consisting of opcodes and its operators. Instead of running into the performance of parsing JSON or JavaScript, now we are only limited by the ability of the browser to copy raw bytes from the network.
Glimmer bytecode encoding
As with many virtual machines, the instructions in the Glimmer virtual machine are recognized by numbers. a bytecode is just an encoded sequence of these numbers. The uniqueness of Glimmer lies in the fact that its command set is intended for rendering DOM in a browser.
For example, a pattern
<h1>Hello World</h1>will be compiled into the following JSON format at build time:
[ ["open-element", "h1", []], ["text", "Hello World"], ["close-element"] ] In the browser at the last JSON compilation step, the format will be turned into an array of numbers, each number is an operation code or operand:
const Program = [25, 1, 0, 0, 22, 2, 0, 0, 32, 0, 0, 0]; Notice that the strings in our JSON were replaced by integers. This is because we use the so-called “string interning” technique, which eliminates duplication of identical strings, here the strings are replaced by a shift in the pool of string constants, which in practice significantly reduces the file size (just imagine how many times you repeat the string div in your templates).
Initially, our bytecode encoded each operation as four 32-bit integers, where the first 32-bit number described the type of operation (opcode), and the remaining 96 bits described up to three instruction arguments (operands).
Despite the fact that this approach is effective for executing code, there is a minus - the size of the files with byte-code is larger than necessary. This is because we always reserve space for three operands, although most instructions do not need operands or accept only one operand. Thus, the program is filled with empty bytes, which should not have been there. In addition, the Glimmer instruction set contains only 80 opcodes, so we can reduce the reserved space for opcodes to 8 bits.
Ultimately, we stopped at a more compact coding scheme, which was still 16-bit. The first 8 bits are an opcode, the next 2 bits are used to encode the number of operands, and the last 6 bits are reserved for future use. Each operand, if any, is encoded in an additional 16 bits.
With this coding scheme, each instruction can take from two to six bytes, it looks like this:
/* Fixed Opcode */ /* Operand? */ /* Operand? */ /* Operand? */ [0bIIIIIIIILLRRRRRR, 0bAAAAAAAAAAAAAAAA, 0bAAAAAAAAAAAAAAAA, 0bAAAAAAAAAAAAAAAA] /* I = instruction (opcode) type L = operand length R = reserved A = operand value */ view raw This new scheme reduces the size of the compiled program by 50%. "Decoding" of this scheme has a slight overhead, since we simply mask and shift the bits to find out the length of the opcode and the length of the operand.
Eliminating the gap between bytecode and javascript
One of the problems we encountered was to move the entire compilation phase into the project builder. Previously, we performed the last step of compiling templates in the browser as soon as the JavaScript code of the application was loaded. This allowed us to combine compiled templates with JavaScript objects, such as component classes that processed user actions.
The first step was to provide all levels of compilation on Node.js. We created a new interface called “bundle compiler”, which encapsulated all levels of compilation into one API, which allowed the build tools to turn the “bundle” of templates into byte-code.
Then we faced an additional problem: when compiling to bytecode, how would we “connect” this bytecode back to the right JavaScript objects at runtime? To solve this problem, we introduced the concept of “handles” (handlers). A handler is a unique numeric identifier that is associated with external objects in a template, such as components or helpers. During compilation, we associate each external object with a handler, which is encoded into bytecode. For example, if we see a call to the <UserProfile /> component, we can associate it with the handler with identifier 42 (assuming that 41 unique components have already been called before).
A component call for this is compiled into several opcodes in the Glimmer command set. One of these instructions is 0x003b PushComponentDefinition , which pushes the component's JavaScript class onto the virtual machine (VM) stack. When compiling to bytecode, this instruction will create four bytes: 0x00 0x3b 0x01 0x2A . The first two bytes encode the opcode PushComponentDefinition . The second two bytes encode the operand, which in this case is a processor (the number 42).
And so what happens when we run the bytecode in the browser? How to turn the whole number 42 into a living, breathing JavaScript class? We call this trick the “external module table”. This is a small fragment of the generated JavaScript code that unites the two worlds, defining a data structure that allows you to effectively map handlers with the corresponding JavaScript classes.
In our example, we have associated UserProfile with handler 42, so our plug-in table is an array, where the class UserProfile is 42 elements in the array.
import UserProfile from './src/ui/components/UserProfile/component'; /* ...other component imports */ export let table = [ /* Component1 */, /* Component2 */, /* ... */, /* Component41 */, UserProfile, /* Component43 */, /* ... */ ]; During the execution of a bytecode, a helper object called a “resolver” turns the handler into a corresponding JavaScript object. Since each handler is also an offset in the array, this code is simple and fast:
resolve<U>(handle: number): U { return this.table[handle]; } Build the project in .gbx format (Glimmer Binary Experience), transfer to the browser, and VM rendering the header in the browser.
What's next
We simply integrated the bytecode compiler into the internal application to prove the concept of Glimmer.js and look forward to collecting real results in the production application. This will help us assess the impact of these changes in the real world with different participants on different hardware, operating systems, browsers, and bandwidth combinations.
Since Glimmer's bytecode reduces file size and completely eliminates the cost of parsing and compiling the last step, we expect significant improvements in application launch time, especially on devices with weak hardware capabilities, where the CPU is a bottleneck. Perhaps more importantly, the process of matching the file format and the internal elements of a virtual machine in the direction of a well-defined binary format opens up many interesting experiments in the future. In particular, our chosen bytecode format means that we are in a good position to research and change some parts of the Glimmer virtual machine in the direction of WebAssembly technology, reducing the cost of parsing and further improving performance at runtime.
We are all LinkedIn big fans of open source, and all the work described above was opened on GitHub. If we are interested in the Glimmer project, we invite you to the Glimmer VM and Glimmer.js repositories on GitHub.
Thanks
Many thanks to Chad Hietale and Tom Dale , who set about compiling a bytecode on LinkedIn. In addition, thanks to Yehuda Katz and Godfrey Chen for helping to realize this vision in the open source community.
Source: https://habr.com/ru/post/348586/
All Articles