Relationship functionality
In classical relational databases, the binary connection of tuples is based on the use of keys: primary and external. At the same time, the interpretation of this connection is carried out outside the logical structure of the database, where it (the interpretation) can be of a rather arbitrary character. Naturally, within the limits prescribed by the relational model.
In the object paradigm, their identifiers are used to implement the connection of objects. Moreover, if the connection of objects to give a strict symmetric form: as a pair, a straight line | back link, it allows you to almost completely replace the Select natural navigation links. But last but not least, the symmetric form makes the connection of objects a full and independent element of the logical structure of the database, having its own behavior and functional dependence on other existing connections.
This article is devoted to the consideration of a variety of behavioral aspects of communication objects, the implementation of which allows you to integrate a significant part of the business logic of the application directly into the logical structure of the database, thereby saving the developer from the coding routine.
(The author allowed himself to deviate from the generally accepted terminological canons, wanting to give the presentation a little more figurativeness).
')
From the informational point of view, the connection of two objects should be understood only as a mutual exchange of identifiers, according to the principle - “I see you”, and nothing more. At the same time, the object itself is an instance of the data class, and the connection of class objects is the practical implementation of the rules established by the class relationship declaration, an instance of one of the four fundamental abstract entities used to model the subject area.
Each of the classes linked by a relation takes into its possession a reference attribute typed by the opposite class of a relationship, the value of which in the class object becomes the identifier of an object of the opposed class. The class relationship not only establishes the rules for the connection of objects, but also serves as a natural context (transport and condition) for organizing the interaction of attributes localized in different classes.
The type of relationship establishes a measure of the quantitative interaction of objects derived from related classes. As you know, there are only three options for this measure: one-to-one , many-to-one , and many-to-many .
The many-to-one relationship , which is conveniently called a multiple relationship , has a clearly expressed causality vector: the primary recipient of a value (reference) is always a reference attribute on the ” many ” side, and the attribute value on the ” one ” side is a derived list of values (reference ). This is where the terminology of the attributes of this relationship that is often used further arises into a direct link attribute and a backlink attribute .
In a fully symmetrical one-to-one relationship (it is also a unitary relation ), each of the peer reference attributes can act as the initiator of creating a connection of objects, and be the primary recipient of the value. The division into direct and reverse link attributes in this respect is purely situational in nature. And this is despite the fact that one of them will receive its value as a result of the assignment of the value to the opposite attribute.
The conceptual meaning of a many-to-many relationship is rather ambiguous, which makes it a subject for separate consideration.
A graphical representation of the plural and unitary relations, which will be further used in the illustrations, looks something like this:

This notation is used because the arrow graphic image is intuitively associated with both the image of the dependency vector and the image attribute of the backward link. Marking a reference attribute with a type and name is not a required element of the image. The reference attribute is typed by the opposite class of the relationship, and, accordingly, borrows the name of this class.
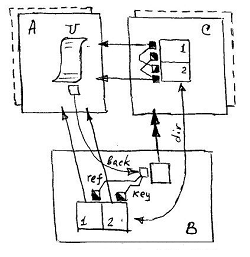
The symmetry of the connection of objects is caused by the causal dependence of the values of the reference attributes of the connected objects. Like any other dependency, it is implemented by a connector , which we will further call a reference connector . The reference connector is a priori active , which ensures permanent logical consistency and integrity of reference values. In its work, the reference connector uses, besides the reference attributes itself, also the service attributes Own and Del . The declaration of the plurality of connector is:
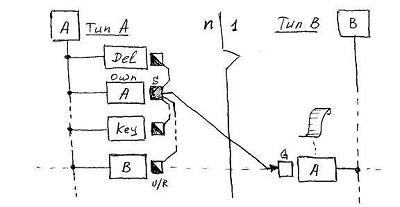 The Own service attribute is typed by its own class, and in the class object stores its own identifier of this object ( IDO ). It is this attribute that is used by all types of relationships as the source of the value transmitted by the relationship connector to the reciprocal link attribute of the same type.
The Own service attribute is typed by its own class, and in the class object stores its own identifier of this object ( IDO ). It is this attribute that is used by all types of relationships as the source of the value transmitted by the relationship connector to the reciprocal link attribute of the same type.
The Del service attribute is used by the relationship connector as a lock context . When a class A object is logically deleted, its Del attribute will be initialized, which will cause a call to the Unset method to the base socket of the connector, which in turn will lead to a call to the address of the attribute B. A set method with an “empty” value and a key, and as a result, the corresponding entry will be removed from the list of backlinks B .. {A}.
The Key attribute ( key -context of the connector) defaults to the base class attribute . The value of this attribute is used by the connector as a key, and the IDO attribute Own is paired to the value being passed. The reciprocal link attribute B. {A}, which receives this pair, has a simple list functionality that directly generates the list of backlinks itself.
Well, the actual attribute of the direct link A. [B] is just a ref context that provides the connector with the IDO of the target object. When the attribute A. [B] receives the stored value during the implementation of the link, it calls the Reset method to the address of the base socket of the connector, which in turn will call the Set method with the object IDO and key, and the address B. As a result, a new entry will be added to the list of backlinks B. {A}. Further, any subsequent change in the values of the attributes of the Key and the direct link A. [B] will be followed by consecutive calls to Unset and Reset with corresponding changes in the list of backlinks.
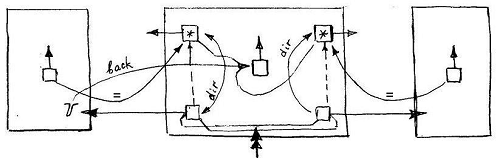
In the unitary relation, the key- context is obviously not used, but there are two reference connectors that provide the mirror symmetry of the implementation:
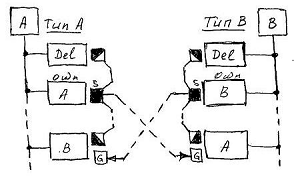 Looking closely at the submitted declaration, it may seem like there are all prerequisites for looping the process of assigning a reference value, but this is not so. The Set method does not generate derived recursive calls if the value it received from outside is equivalent to the one already in place.
Looking closely at the submitted declaration, it may seem like there are all prerequisites for looping the process of assigning a reference value, but this is not so. The Set method does not generate derived recursive calls if the value it received from outside is equivalent to the one already in place.
In addition to the two reference attributes, at least one connector is involved in the formation of a relationship, combining a set of sockets with appropriately set flags. I would like to emphasize that this entire volume of declarations is hidden behind the facade of the visual designer of the data model, which uses predefined methods and forms for representing the abstract meta-relation to create instances of it. All that the constructor needs to create an instance of a relationship is its type and descriptors of the classes to be linked.
I would also like to emphasize once again: neither the class relationship , nor the attribute connector are not entities of the data model , and they are not interpreted in any way. The data model operates only on classes, attributes, and sockets. The relationship and connector are entities of the application model , which in turn is a representation (form of representation) of the data model.
Consider such an operation as the transfer of goods from the warehouse to the warehouse : in the object of the delivery invoice it is necessary to address two warehouse objects at once. Such a need is realized by simply increasing the power of the relationship , replacing the atomic form of storing the derived values of the reference attribute A. [B] with an enumerated (array).
 By increasing the power of the plural relation (the multiplicity of the link), the model constructor will create an additional element for the direct link attribute, and another relationship connector to it, similar to the existing one, which uses the new element as the source of the address pointer ( ref- context). Note that the increase in power did not affect the declaration of the back link attribute B .. {A}, with the exception of adding one more incoming socket. (This and the following figures show only the necessary contexts).
By increasing the power of the plural relation (the multiplicity of the link), the model constructor will create an additional element for the direct link attribute, and another relationship connector to it, similar to the existing one, which uses the new element as the source of the address pointer ( ref- context). Note that the increase in power did not affect the declaration of the back link attribute B .. {A}, with the exception of adding one more incoming socket. (This and the following figures show only the necessary contexts).
Similarly, an increase in the power of the unitary relation is realized.
 Since this type of relationship has an additional internal symmetry, the number of elements of the reference attributes on both sides of the relationship will always be the same.
Since this type of relationship has an additional internal symmetry, the number of elements of the reference attributes on both sides of the relationship will always be the same.
In turn, the backlink attribute of the plural relation can ensure the existence of more than one list. By default, the first (main) list uses the base class attribute as a key (for the Invoice, this will be the Date attribute). Suppose that for any purpose you need another list with a different sorting order, for example, by the total invoice amount. By creating a new list declaration, the relationship constructor will create an additional element (A2) for the backlink attribute, as well as an additional reference connector. The new connector is similar to the primary connector, but the Total attribute is used as the key source not for Date anymore.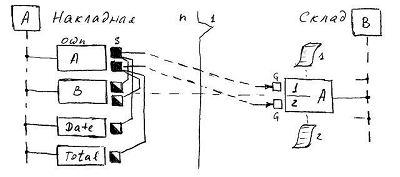 Note and emphasize: adding a new list does not change the power of the relationship.
Note and emphasize: adding a new list does not change the power of the relationship.
If in the properties of the list you specify an additional logical context, then only those records will fall into it for which the context value is true . This option will be useful, for example, when maintaining “white-gray” accounting. And since all three contexts of the base reference connector are already used, you can use the free lock context of one of the context sockets. For example: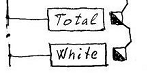
As you can see, unlike ref - and key - contexts, the lock context can be cascaded up, creating an additional logical context (condition) for an existing one.
It seems obvious that the referenced object cannot be arbitrarily deleted. Accordingly, in order to preserve referential integrity, it is necessary to control the presence of actual external links to the object.
As we remember, the object is logically deleted when initializing the value of the service attribute Del . In order to provide the ability to control external links, each backlink attribute, when created, automatically creates a separate passive connector to the Del attribute.
 In the Set method, the specialized service functionality of the Del attribute checks all incoming connectors, and as soon as one of them returns true (the list of backlinks is not empty), the functionality will generate an exception that terminates the transaction. But you can not bring up the exception. The Get method, addressed to the Del attribute, polls the connectors, and returns false if the object can be deleted without conflict.
In the Set method, the specialized service functionality of the Del attribute checks all incoming connectors, and as soon as one of them returns true (the list of backlinks is not empty), the functionality will generate an exception that terminates the transaction. But you can not bring up the exception. The Get method, addressed to the Del attribute, polls the connectors, and returns false if the object can be deleted without conflict.
There are relationships that, from a conceptual point of view, are usually regarded as " parental ". For example, the Invoice and its conditionally “ child ” Records , which may exist solely in the context of the Invoice. The opposite behavior is expected here: the Invoice object can not only be deleted if there are backlinks from Record objects, but it should also, in the process of its own deletion, delete all its Records . The required reaction can be provided by setting the virtual Owner flag in the properties of the relation, after which the following changes will be made to the data model:
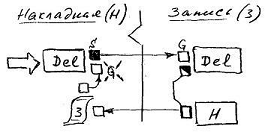
First, an active connector will be added, linking the Del attributes in the Invoice and Record classes, and secondly, clearing the Get flag will de-activate the connector linking Del to the corresponding list of backlinks.
Consider a system of three classes connected by a plural relation :
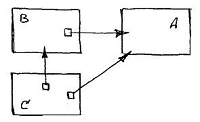
An object of class C has direct pointers to objects B and A , and object B has a pointer to A. Since there are no additional rules and restrictions, the objects C and B connected by reciprocal link in the most general case can consistently address various objects of class A as well .
Slightly change the example, making it a certain semantic load.
Let C be the student class, B the faculty , A the university . It seems obvious that the Student is registered exclusively in the educational institution, at the Faculty of which he undergoes specialized training. In other words, for the Student, the pointer to the university is determined by the pointer to the Faculty . This rule is established by creating a connector that binds the attributes of a direct reference to class A in classes B and C through the relation C → B. Note that bind attributes have the same type - class A.
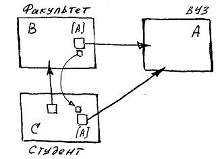
The declaration of the active linking of reference attributes by the standard connector will automatically ensure the required consistency of the reference values of C. [A] = B. [A] under any external influences. Indeed:
The declaration of the active dependency of the attributes of the direct link C. [A] = B. [A] gives rise to a direct logical consequence:

The derived back- connector is absolutely passive, it is not initiated by changing the attribute C. [A], since the corresponding flags ( Unset / Reset ) of the context socket are turned off, and it does not participate in the process of working out external influences. This connector is used in the process of organizing the assignment of a value to the reference attribute C. [A], which will be discussed in detail later. In the meantime, we note that the list of backlinks, addressed by the back- connector, if viewed as a source of data, provides many homogeneous values, without being able to automatically select one of them.
Meanwhile, there is the same condition under which one can choose from the list a strictly defined one and at the same time a single element. For this, the list must have a unique property based on the key value, and the key itself is required.
Consider an example of all the same three classes, but, for greater clarity, in a slightly different interpretation: class A is some Journal , whose Records (class C ) should be grouped by Calendar Days (class B ). Every Day in the Journal is unique in its Date ( D ) calendar date value. This uniqueness is ensured by the slightly upgraded list functionality assigned to the backlink attribute A. {B}, which generates a transactional exception when trying to add an entry to the list with a key value already existing in the list.
The back connector has also undergone some changes: it uses the Date (D) attribute as the key context, and has become semi-active : its contexts are active (the Unset / Reset flags are set for all context sockets of the connector), with the Set socket flag set off .

With active context sockets, any change in the values of the attributes C. [A] or C .D activates the back connector, which will retrieve the value of C. D, and use it as a key when accessing the list A. {B}, then the resulting value ( The object B IDO will be assigned to the target attribute. Thereby, automatic positioning (in other words, grouping) of objects of class C to objects of class B is realized.
What happens if you enter a date for the C .D value for which there is no corresponding Day object? In this case, the back connector naturally returns the value NUL, and the Day reference will be de-initialized.
It is worth noting that occasionally this behavior is also required, but most often the required Day object corresponding to the entered date must be created automatically. To implement this behavior, the attribute C. [B] is assigned the Autoset functionality. This functionality (discussed below) when it is initiated by the back- connector, will automatically create a new object of class B , then assign the identifier of the created object to the attribute of the direct link as a value.
But this is not enough. In order to preserve referential integrity, the attributes D and { A } of a new object B must automatically obtain strictly defined values, namely, those coinciding with the current values of the similar attributes of object C. For these purposes, the B .D → C .D and B. [A] → C. [A] connectors enable the transfer of the value transfer , namely: the incoming Get- socket of the connector belonging to the C attributes .D and C. [A] In addition, the Set flag is set . Then, when assigning a value to the attribute C. [B], the transport context of the connectors B .D → C .D and B .. [A] → C. [A], these connectors will be initiated to transfer the values to object B. Let's pay attention - the declaration of dependencies given in the diagram ensures automatic preservation of logical and referential integrity when changing any of the values.
The above set of declarations, which implements the grouping of objects by attribute value, is created by the internal model constructor in two steps. If the uniqueness option is enabled in the properties of the backlink attribute in a certain common class, then the relation to which the given attribute belongs becomes unique. At the same time, the target link class itself can now act as a class, grouping links by the value of its base attribute. A relationship with such a class of any third class, which also has a relationship with a general class, acquires an option (in the properties dialog) that allows you to select an attribute in the third class tuple, according to the value of which the grouping is implemented.
Slightly modernize the previous example: let the place of the absolute attribute D in classes A and C take the attribute of a direct link to class D (the list of backlinks is generally the same as the key to the value: calendar date or IDO object identifier). And for greater clarity, we will change the semantic meaning of the classes: class A is the Goods , class D is the Warehouse , class C is the invoice / delivery note (movement of the Goods). Then the semantic load on class B is unambiguously derived: it is Commodity-in-Warehouse . If you replace the Warehouse with the Supplier or the Buyer , then Class B will become the Goods-at-Supplier / Buyer .
Corresponding to the changes made, the declaration will look like this:

Any Record when receiving specific pointers to the Warehouse and Goods objects will automatically receive a pointer to the Goods-on-Warehouse object, and in the case of the absence of such, it will automatically create it. Note: the connection of two classes, Product and Warehouse , through the third class ( Product-on-Warehouse ) is a variant of the many-to-many relationship, an alternative to the direct exchange of the values of the two attributes of the reciprocal link. Moreover, this option also has the property of uniqueness. In other words, for each pair of objects the Goods and the Warehouse , which connects their object Goods-in-Warehouse, exists in a single copy. This behavior is due to the uniqueness property of the list of backlinks, for which the pointer-attribute to the opposite class is used as the key source. And it doesn't matter at all in which of the two classes ( Goods or Warehouse ) the list is unique, the same list of backlinks (with the usual list functionality) in the opposite class will actually contain a unique set of keys.
A direct implementation of a many-to-many relationship looks like two interacting lists of backlinks in each of the classes being linked. Such an implementation has, in general, an insignificant practical meaning: only a statement of the fact of the connection of objects, without the possibility of realizing through this relationship a consistent interaction of the attributes of these classes. Therefore, in practice, the desired interaction of attributes is realized through the attributes of the third class associated with the relationship with the target classes. In real-world application models, such constructs are found all the time, and are created in the most arbitrary fashion, without pretending to be distinguished as a separate type of relationship.
It is quite another thing when the relationship through the third class has the property of uniqueness, as in the Stock-in-Stock from the example above. Here, the specificity of the third class (connection class) is not so much the use of relationship attributes as sources of a key, but its conceptual “production” of the relationship of classes. Therefore, such a unique (by identifiers) relationship of classes through the third class will be further considered as a many-to-many relationship. This type of name can be called both a unique relation and a projection relation .
A projection relationship is created as a result of executing a dialog, during which classes are linked by relationship, after which the corresponding constructor method creates the third projection class itself, with assigning it the corresponding composite name, and all other necessary declarations of relationship attributes and their connecting connectors . , , , -. , , - .
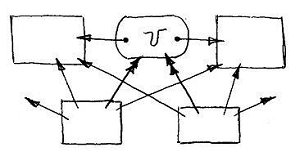
, . , , -, - .
By increasing the multiplicity of a relationship, we thereby allow an object of one class to address two or more objects of another class, which in turn can also be considered as a logical analogue of the many-to-many relationship considered earlier .

Based on this, it should be assumed that the multiple form of the relationship must have its own projection - a unique form of the multiple relation, a pointer to the object of which can be obtained automatically.
And such a unique relationship will indeed be created if, in the process of creating a relationship-projection dialogue, we choose the same class as the target classes. And after the relationship between a simple class and a projection class is created, the declaration of attributes and connectors takes the following form:
With all the oddities of its appearance, it is a logical and quite a workable declaration, which is practically used, for example, in accounting - for receiving objects of mutual correspondence of balance accounts. As a matter of fact, this is where the name was borrowed - the correspondence used further to denote a multiple unique relation implemented by the projection class.
What should be noted in the above declaration: in contrast to the usual projection, which connects any pair of objects with its only copy, correspondencesuch a link is implemented in two instances, one for each combination of pointers in the elements of a direct link. For these purposes, in all interactions, including the formation of a list of backlinks, reference pointers, acting both as values and as keys, are complemented by an index of the element in which they are located. In addition, to block meaningless dual addressing, a special functionality can be assigned to a reference attribute in a projection class, which prevents both elements from having the same value.
– Set IDO . , . , , . , , Create , , , . (, ). IDO , Autoset .
. , . , IDO « », .
, , , , ( ) . Data- ( ), IDOin accordance with the choice made. The selection dialog can be direct or cascade, which is set on the basis of existing back- connectors. The source for the formation of the dialogue list is the corresponding list of backlinks.
This functionality is assigned to the attribute of a direct link in order to implement the relationship by automatically creating a derived object of the target relationship class. Autoset
functionality can be triggered by both the inbound connector and the external Update event . In this case, the relationship target object will be created by the functional only if the reference attribute in the source object does not have a stored value.
There is a solid rule of logical interaction of values, according to which a value belonging to a specific domain can only be associated with a value whose domain is in the source or includes the source. In this case, only the value with an equal or more extensive domain can accept the initial value. The largest domain (after Undefined Type ) for an attribute of the type Logical , which can take the value of any other type. Simply put, the connector can only associate the same type of attributes, which was observed in all the examples considered earlier. But in the following declaration, the passive connector, linking the attributes of the reciprocal link ( A. {B} → C .{D}) , , .
, , , . .
, , , , , . , , , unchanged. It is a different matter when the transactional nature of the impact is obvious. In this case, a previously not initialized static attribute can and should form a stored value as part of a general change in the state of the base. As can be seen from the declaration, the connector in question and its target attribute C. {D} will be triggered by assigning the value to the attribute C. [A], that is, transactionally. And if the derived value at this moment does not exist, the attribute C .. {D} begins its formation on the original sample provided by the connector.
As a value, the list of backlinks is derived from the direct links. In other words, attribute C .{D} , — D , . Create . ( – , ) — . , , , .
– , .
( ) , . – , , .
, , , , , . .
, , , .
Through an internal relationship, an attribute can create a connector to itself. This is a very effective technique that allows you to implement various kinds of generalization of values, including the generalization of the "progressive total".
The functional meaning of the internal relationship is determined by its type.
-- , .
: , Autoset , . - Update .
Examples of use - the passage of a part of the processing cycle, organized as a sequence of operations, or the estimated periods of the year: quarterly or monthly, with cumulative totals at the beginning and end of the period. If the power of the chain relation is increased to three, the objects of the class can form a logical similarity of the three-dimensional crystal lattice. Such a construction can be used for a variety of behavioral modeling, including in physical environments.
-- , , ( - ). – , . – -.
, , , .
, :

1. , , , .
2. , ( ) .
It should be noted that these restrictions apply only to the implementation of the multiple relations of a class with an internal recursive relationship with other classes, and do not apply to analogous unitary relations. These rules, characteristic of hierarchies in general, are not strict, but are recommendatory in nature. Compliance with these rules at the object model level is not controlled at all, and is entirely assigned to the interface part of the application.
, - , , , - , . , :

, - .
, - , , , , , :
( [*]) , , . : .
( ) , , (=). , 2. ( 1 3), , . , : Get , , . , , .
, , .
The need for a structured interface arises whenever it is necessary to obtain unified access to different entities through relationships . In other words, entities with a different set of details should be reduced to a homogeneous (in terms of details) set. Well, at least then, to present them as a general list.
The first solution to this problem provides us with a class inheritance mechanism : a descendant class inherits a tuple of ancestor class attributes. This is quite enough, for example, to bring all the wealth of types of financial documents into one list of the type Date , Number , Document Name / Operation , Amount .
This solution can be conventionally called the interface " on top ". It works well, but unfortunately not all entities have a common ancestor. A typical example is given to us by the specifics of accounting in construction: several Customers finance large Construction sites , which consist of several Construction Objects , the works on which are structured by type of work , and are included in various Agreements (with the Customer ). Work progress is required (funding, expenses incurred, man-hours, ...) summarize the a la Gantt chart into the big picture . . , , -- , – , -, . , :

«» ( Autoset ) , " " ( ), . “ " , , [*]. , , , « ».
( ) " " ( ), , — " ". , , , . «» " ", , , -, .
Probably it should be noted that the existence of such different variants of partial structural unification suggests the idea that there is no universal interface solution in nature.
In the data object model, any structural type most naturally exists as a custom class whose ID ( IDC ) is a handle to this data type. Accordingly, the interface data structure can be defined as a class, and its use as an attribute value should be considered as a peculiar modification of the unitary relationship , in which the attribute of a direct link to the interface class does not store the object ID of the interface class (IDO), but the object itself. Since an object that is “included” as a value loses its independence, along with it, it ceases to have its own descriptor. Now its identifier is a composite value in terms of the IDO of the owner object + IDA of the attribute in which it is located. This solution allows you not to worry about the method of creating the included object and realizing the relationship with it - all this happens automatically when you create the owner object during the initialization of its attributes.
Since it is initially assumed that the “interface” object will be included in the composition of objects of various classes, the traditional way of ensuring the symmetry of a relationship by creating a reference attribute in each of the classes being linked ceases to be optimal. In fact, with this method, in the tuple of the “interface” class, a certain number of reference attributes will be declared, of which, in the actual implementation of the relationship, only one will always get the value. Therefore, another option was chosen, asymmetrical in the declaration, but nonetheless maintaining reference symmetry during implementation.
In the interface class, the role of the reverse link attribute for all created interface relations is performed by the same attribute, Own , which, in order for it to accept a value of any reference type, is forcibly assigned the type User Defined Type . In fact, the purpose of this type of attribute Own and plays the role of a flag that marks the class as " interface ".
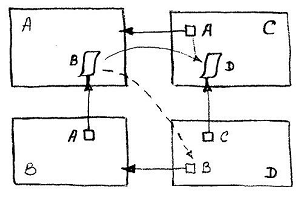
The final declarations of the " interface " relationship (right), compared to the declarations of the usual unitary relationship (left), look like this:

The logic of defining an interface type also establishes the order of its use: the class declared by the interface forms an independent data type (structural type), which is complemented by a standard set of types that participate in the formation of the menu for choosing the attribute typing dialog. If you select this type and assign it to an attribute, the model constructor will create all the declarations shown in the diagram.
In fact, utility classes are ordinary data classes that are used by the data management system to solve its internal utilitarian tasks. The difference between service classes and others is only that they are created by the control system automatically, when generating a new database, and accordingly have fixed descriptors that are known a priori by the system.
The set of data objects, symmetrically linked by reciprocal links, is a closed system, within which the natural inter-object navigation is not limited by anything. But since, for reasons of reliability and safety, direct access to objects is prohibited, the problem of entry into such a system arises. To overcome it, it helps to use a service class , called a Super Class , and a Super Object derived from it, with fixed values of IDC and IDO descriptors.
When the designer creates an application for each new user class, a plural relationship with the Super class is automatically created for this class . Thus, the previously mentioned set of service attributes of the class ( Type , Own and Del ) is complemented by the fourth member - the attribute of a direct link to the Super Class. The superclass, in turn, receives a backlink attribute, typed by the IDC descriptor of the newly created class. Thus, upon the creation of custom classes, the Super Class becomes a kind of owner of their full set, which allows using the Super Class with its fixed handle as an entry point to the actual data model. Remarkably, the attribute identifier ( IDA ) of the reciprocal link in the Super Class oddly coincides in value with its class identifier ( IDC ).
In the process of creating a derived object ( Create ), its service attributes are automatically initialized, including the direct link attribute to the Super Class , which receives a fixed Super Object IDO . At the same time, as a result, a pointer to a new object adds to the corresponding list of back links of the Super Object . Thus, solely upon the observance of the standard rules for the implementation of relations, the Super Object becomes the owner of the lists of objects of each class, in other words, the full set of objects. This circumstance allows you to use the Super Object as a natural entry point into the database , which opens access to the lists of class objects.
Pay attention to the important point - the data class, like a declaration, does not have a physical pointer to the list of its own objects. Between data and metadata there can be no other connection than the logical one.
And one more detail: when organizing an object selection dialog, the Data cursor by default, unless otherwise specified, uses a list of backlinks of the target class from the Super object .
Any application needs global values that are permanently available to all parts of the application. For the declaration of such values, the service class Global is used , in the derived object of which they are stored. The specificity of the Global class is the fact that it is related to the Super Class not by a plural relation , like all other classes, but by a one-to-one unitary relation. In other words, with respect to the Super Object, Global exists in a single copy, and since its position in the Super Object tuple is known, its values are accessed in one step.
Depending on the features of their use, the entire set of global values can be divided into groups. The first group consists of isolated values that are used by themselves, usually in interface forms, such as the name of the organization (own). To access these values, a route is sufficient: Super Class → Global → Attribute .
The second group is formed by the so-called borrowed values, such as the VAT rate . In order to use the borrowed value, the class must have a relationship with the Global class, and obviously multiple . If such a relationship is declared, the model constructor in addition to it creates a connector that allows the object being created to automatically receive a pointer to a Global object.

In addition to absolute , reference values can also be global. Such values are most often used as default values that are set when setting up an application, for example, references to Currency objects that make up a Ruble-Dollar pair. Since many (Global) -c- type relationships will strain common sense, global reference values are created somewhat differently: the Undefined Type attribute is first created, in atomic (for a single link) or enumerated (for several links) form, and then its type is overridden by the User Defined Type = IDC of the target class. In other words, the attribute of a direct link is created without a declaration of the relation itself. This technique is used everywhere where there is no practical sense in declaring a relation, and an attribute of the desired type is needed (as, for example, when implementing the recursive projection discussed above).
In addition, all values stored by the Global object are divided into common and user-defined . General, such as Organization Name or VAT Rate , are the same for all database users. Unlike the Reporting period or the pointer to the default warehouse (for a specific storekeeper, for example), which must be individual for each user. For the formation and storage of user values are used objects of class User .
The main purpose of the User class is to build an authentication system for end users of the database on its basis. If during the authorization the username and password entered by the user coincide with the values of the corresponding attributes in one of the User objects, then the authorization is considered successful, after which the values of all other attributes of this object are available to this user (and only him) as global values.
It is implemented as follows. The classes Global and User are related by a multiple relation . When creating a new static attribute in the User class, the Global class automatically creates a pairwise same-type and dynamic attribute of the same name ( user ), which after creation receives a passive incoming connector from the pair attribute to it in User . When accessing a user attribute in Global , this attribute attempts to get its value through a connector, and at this point the runtime replaces the list of back references to User objects with a pointer to the only such object obtained when authorizing the user.
Note that an attribute can get its value by a connector through a list of backlinks from a variety of sources or by converting these values into a unique one (for example, by summation), or if there is a condition (context) that allows to single out only one set of values. In the absence of the corresponding condition or conversion (functional), the attribute is prohibited to create an incoming connector through the backlink attribute. For a custom attribute in the Global class, this restriction is overcome by artificial means.
A little higher in the text it was already mentioned that the set of related objects forms a closed system, the only entry point to which is a Super-object . Within the limits of one physical database there can be an arbitrary set of such closed systems. Each such system can be considered as a logical database, completely isolated from other similar logical bases. Each logical base has its own entry point, its Super Object . In other words, to generate a new logical base, you need to create another object derived from the Super Class .
This task is solved with the help of three service classes: User → Global : Super class , with the Global class leading in this bundle. It is the Global class that is associated with the logical database, and each derived object of this class stores the user name of its “own” base in the corresponding attribute. Having a one-to-one relationship allows the creation of a Global object to automatically create and associate with it a new Super Object . Regarding the Global object (considered as an instance of a logical local database ), objects of the User class (named Users of this local base instance) are created. After passing through the authorization procedure, for this User in his record in the Clients Table are stored descriptors ( IDO ) not only of the Users object, but also the Global and Super objects associated with it. It is the user pointer to the Super Object (the root element of the local database) that will be used by the management system as a value that is automatically assigned to the corresponding service attribute of an object of any class when creating this object at the initiative of this particular user.
What is important to note is that all mutually isolated logical databases obey their common data model rules, which operate throughout the entire physical database space.
When it is created, the heir class receives the full tuple of attributes of the ancestor class, and together with the attributes of the heir class, it receives the full set of ancestor class relationships. And at the same time pops up an interesting detail.
Each new class, regardless of how it was created, must form its own relationship with the Super Class in order to have a complete list of its objects in an explicit form. But the heir class cannot directly create such a relationship, since it already inherits the attribute of a direct link to the superclass within the entire ancestor tuple. In addition, although the ancestor class does not create its own objects, nevertheless its list of backlinks in a super-object should include a complete list of objects derived from all its child classes. (For an example: there is a set of all Documents in general, and there is a private set only of the Consignment Note .)
The list of objects for the ancestor class will be formed without any interference with the existing declarations, since all its heirs received its parental relationship with the superclass. For the heir class, the class constructor implements a partial creation of a new relationship — the existing attribute of a direct link is used (a new one is not created), a reverse link attribute is created in the pair in the superclass, and both attributes are linked by a reference connector .
Thus, the inheritance partially violates the bilateral symmetry of the relationship with the superclass: one direct pointer to the super-object will now correspond to two or more (depending on the depth of inheritance) pointer backward link in the super-object. But such an exception to the rules is private and seems logically justified.
The domain of the values of the reference attribute is formed by the identifiers of objects derived from the opposed relationship class and all its successor classes. In applications, there is often a need to forcefully narrow down the domain of values of a referenced attribute, limiting it to a single class.
Consider the following example:

An abstract Counterparty has one of two organizational forms: Legal or Individual (heirs of the Counterparty class). In barter transactions, the Counterparty plays a specific Role : it can be the Supplier , the Buyer, or both. Obviously, there is a very specific relationship between the Counterparty and the Role , which we will separately consider a little later. The Consignment Class is an abstract commodity exchange operation in which natural plural relations with the Counterparty and the Role are declared. In our example of specific operations, there are exactly two: Receipt and Expense , the heirs of the Consignment Note and its relations.
The heirs of the Consignment note use the relationship with the Counterparty in the form in which it was inherited. Both the Incoming and Outgoing Invoices implement this relationship by selecting the target object from the general list of Counterparties , in which both Legal Entities and Individuals are equally present.
The inherited relationship with the Role requires redefinition , as the subject of the reference for the Invoice can only be the Supplier , and for the Expenditure note , only the Buyer . The redefinition of inherited relationships ( domain narrowing ) is achieved by replacing the ancestor class identifier with the inheritor class identifier in the attribute properties, for which the reference attribute provides the corresponding dialog to the model constructor. Note that after clarifying the relationship from a direct link in the Receipt and Expenditure invoice, only the invoice objects corresponding to their role will automatically be included in the lists of backlinks of the Supplier and the Buyer . But a symmetric redefinition of the relationship also for the reference attributes of these classes will be considered good form.
In the previous example, the Consignment Note logically links the Counterparty with its Role . Consider this relationship in more detail, using the same set of classes, but presented in a slightly different perspective:

The counterparty can be both a supplier and a buyer at the same time. This fact is declared by the creation of two separate unitary relations of the Counterparty with these classes, without creating a common relationship with the Role . At the same time, a common ancestor is required, as it carries not only the relationship with the Consignment note , but also an additional set of attributes common for the Supplier and the Buyer , for example, for organizing various mutual settlements. The logical connection of the Counterparty with the Role is as follows (for example, the Supplier – Payment receipt pair ): The Counterparty acquires the status of a Supplier (forms an object of the Supplier class, and realizes a relationship with this object) if there is at least one Invoice . In order for this connection to get a physical implementation, and work as an internal rule of the data model, you should use the Autoset functionality, as shown in the figure:

From the left part of the figure, it is clear that the presence of a unitary relationship between the Counterparty and the Supplier allows the Invoice to potentially receive a value for any of its direct link attributes when the pointer is assigned to another direct link attribute. , Autoset . back -. , , , . , . back - Autoset , , – . , , , back - .
:

Create , . , , . , .
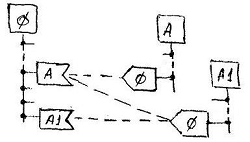
The value of the attribute S from class B is distributed by three connectors: one common - to the attribute S of the ancestor class A , and two private - to the attributes D and K of its heirs A1 and A2 . Depending on which pointer to which object from the heirs, A1 or A2 , will be received by object B , in the addressable object only one of the two attributes, D or K , will receive its value. The S attribute will get its value anyway.

This behavior is provided by the selective properties of the ref context of the connector, namely due to the presence in the declarations of the ref socket identifier IDC of the target class of the connector. The external connector will perform its transfer function only if the ref context provides it with the IDO of the target object. And this will happen only in the case when the value of the reference attribute - the object IDO is included in the domain of values of the type declared in the properties of the ref - socket.
Well, it just suggests an association with the if statement , which checks the type conformity before performing the action.
, , . , (no Select ) .
, - , , , . , , .
In the object paradigm, their identifiers are used to implement the connection of objects. Moreover, if the connection of objects to give a strict symmetric form: as a pair, a straight line | back link, it allows you to almost completely replace the Select natural navigation links. But last but not least, the symmetric form makes the connection of objects a full and independent element of the logical structure of the database, having its own behavior and functional dependence on other existing connections.
This article is devoted to the consideration of a variety of behavioral aspects of communication objects, the implementation of which allows you to integrate a significant part of the business logic of the application directly into the logical structure of the database, thereby saving the developer from the coding routine.
(The author allowed himself to deviate from the generally accepted terminological canons, wanting to give the presentation a little more figurativeness).
')
From the informational point of view, the connection of two objects should be understood only as a mutual exchange of identifiers, according to the principle - “I see you”, and nothing more. At the same time, the object itself is an instance of the data class, and the connection of class objects is the practical implementation of the rules established by the class relationship declaration, an instance of one of the four fundamental abstract entities used to model the subject area.
Each of the classes linked by a relation takes into its possession a reference attribute typed by the opposite class of a relationship, the value of which in the class object becomes the identifier of an object of the opposed class. The class relationship not only establishes the rules for the connection of objects, but also serves as a natural context (transport and condition) for organizing the interaction of attributes localized in different classes.
Types of relationships
The type of relationship establishes a measure of the quantitative interaction of objects derived from related classes. As you know, there are only three options for this measure: one-to-one , many-to-one , and many-to-many .
The many-to-one relationship , which is conveniently called a multiple relationship , has a clearly expressed causality vector: the primary recipient of a value (reference) is always a reference attribute on the ” many ” side, and the attribute value on the ” one ” side is a derived list of values (reference ). This is where the terminology of the attributes of this relationship that is often used further arises into a direct link attribute and a backlink attribute .
In a fully symmetrical one-to-one relationship (it is also a unitary relation ), each of the peer reference attributes can act as the initiator of creating a connection of objects, and be the primary recipient of the value. The division into direct and reverse link attributes in this respect is purely situational in nature. And this is despite the fact that one of them will receive its value as a result of the assignment of the value to the opposite attribute.
The conceptual meaning of a many-to-many relationship is rather ambiguous, which makes it a subject for separate consideration.
A graphical representation of the plural and unitary relations, which will be further used in the illustrations, looks something like this:
This notation is used because the arrow graphic image is intuitively associated with both the image of the dependency vector and the image attribute of the backward link. Marking a reference attribute with a type and name is not a required element of the image. The reference attribute is typed by the opposite class of the relationship, and, accordingly, borrows the name of this class.
Reference connector
The symmetry of the connection of objects is caused by the causal dependence of the values of the reference attributes of the connected objects. Like any other dependency, it is implemented by a connector , which we will further call a reference connector . The reference connector is a priori active , which ensures permanent logical consistency and integrity of reference values. In its work, the reference connector uses, besides the reference attributes itself, also the service attributes Own and Del . The declaration of the plurality of connector is:
The Del service attribute is used by the relationship connector as a lock context . When a class A object is logically deleted, its Del attribute will be initialized, which will cause a call to the Unset method to the base socket of the connector, which in turn will lead to a call to the address of the attribute B. A set method with an “empty” value and a key, and as a result, the corresponding entry will be removed from the list of backlinks B .. {A}.
The Key attribute ( key -context of the connector) defaults to the base class attribute . The value of this attribute is used by the connector as a key, and the IDO attribute Own is paired to the value being passed. The reciprocal link attribute B. {A}, which receives this pair, has a simple list functionality that directly generates the list of backlinks itself.
Well, the actual attribute of the direct link A. [B] is just a ref context that provides the connector with the IDO of the target object. When the attribute A. [B] receives the stored value during the implementation of the link, it calls the Reset method to the address of the base socket of the connector, which in turn will call the Set method with the object IDO and key, and the address B. As a result, a new entry will be added to the list of backlinks B. {A}. Further, any subsequent change in the values of the attributes of the Key and the direct link A. [B] will be followed by consecutive calls to Unset and Reset with corresponding changes in the list of backlinks.
In the unitary relation, the key- context is obviously not used, but there are two reference connectors that provide the mirror symmetry of the implementation:
Creating a relationship
In addition to the two reference attributes, at least one connector is involved in the formation of a relationship, combining a set of sockets with appropriately set flags. I would like to emphasize that this entire volume of declarations is hidden behind the facade of the visual designer of the data model, which uses predefined methods and forms for representing the abstract meta-relation to create instances of it. All that the constructor needs to create an instance of a relationship is its type and descriptors of the classes to be linked.
I would also like to emphasize once again: neither the class relationship , nor the attribute connector are not entities of the data model , and they are not interpreted in any way. The data model operates only on classes, attributes, and sockets. The relationship and connector are entities of the application model , which in turn is a representation (form of representation) of the data model.
Relationship power
Consider such an operation as the transfer of goods from the warehouse to the warehouse : in the object of the delivery invoice it is necessary to address two warehouse objects at once. Such a need is realized by simply increasing the power of the relationship , replacing the atomic form of storing the derived values of the reference attribute A. [B] with an enumerated (array).
Similarly, an increase in the power of the unitary relation is realized.
In turn, the backlink attribute of the plural relation can ensure the existence of more than one list. By default, the first (main) list uses the base class attribute as a key (for the Invoice, this will be the Date attribute). Suppose that for any purpose you need another list with a different sorting order, for example, by the total invoice amount. By creating a new list declaration, the relationship constructor will create an additional element (A2) for the backlink attribute, as well as an additional reference connector. The new connector is similar to the primary connector, but the Total attribute is used as the key source not for Date anymore.
If in the properties of the list you specify an additional logical context, then only those records will fall into it for which the context value is true . This option will be useful, for example, when maintaining “white-gray” accounting. And since all three contexts of the base reference connector are already used, you can use the free lock context of one of the context sockets. For example:
As you can see, unlike ref - and key - contexts, the lock context can be cascaded up, creating an additional logical context (condition) for an existing one.
Referential integrity management
It seems obvious that the referenced object cannot be arbitrarily deleted. Accordingly, in order to preserve referential integrity, it is necessary to control the presence of actual external links to the object.
As we remember, the object is logically deleted when initializing the value of the service attribute Del . In order to provide the ability to control external links, each backlink attribute, when created, automatically creates a separate passive connector to the Del attribute.
There are relationships that, from a conceptual point of view, are usually regarded as " parental ". For example, the Invoice and its conditionally “ child ” Records , which may exist solely in the context of the Invoice. The opposite behavior is expected here: the Invoice object can not only be deleted if there are backlinks from Record objects, but it should also, in the process of its own deletion, delete all its Records . The required reaction can be provided by setting the virtual Owner flag in the properties of the relation, after which the following changes will be made to the data model:
First, an active connector will be added, linking the Del attributes in the Invoice and Record classes, and secondly, clearing the Get flag will de-activate the connector linking Del to the corresponding list of backlinks.
Mutual relationship relationship
Consider a system of three classes connected by a plural relation :
An object of class C has direct pointers to objects B and A , and object B has a pointer to A. Since there are no additional rules and restrictions, the objects C and B connected by reciprocal link in the most general case can consistently address various objects of class A as well .
Slightly change the example, making it a certain semantic load.
Let C be the student class, B the faculty , A the university . It seems obvious that the Student is registered exclusively in the educational institution, at the Faculty of which he undergoes specialized training. In other words, for the Student, the pointer to the university is determined by the pointer to the Faculty . This rule is established by creating a connector that binds the attributes of a direct reference to class A in classes B and C through the relation C → B. Note that bind attributes have the same type - class A.
The declaration of the active linking of reference attributes by the standard connector will automatically ensure the required consistency of the reference values of C. [A] = B. [A] under any external influences. Indeed:
- for any receipt / change of the value of C. [B], the connector will be initiated (by Unset / Reset methods) to transfer the value of the attribute B. [A] to the attribute C. [A];
- when the value of the attribute B. [A] changes, the new value will be transferred to all C objects from the list of backlinks B .. {C};
The declaration of the active dependency of the attributes of the direct link C. [A] = B. [A] gives rise to a direct logical consequence:
- if object C has a current value of C. [A] (for example, the Student has already chosen the university for training), the scope for determining the allowable values of the attribute C. [B] will be the list of backlinks for the attribute A. {B} (list of Faculties of this university ). In its first approximation, this consequence takes the form of a constraint, which in the data model is explicitly expressed by the automatic creation of the connector C. [B] = A. {B}, hereinafter referred to as the back connector , derived from the direct connector declaration of C .. [A] = B. [A].
The derived back- connector is absolutely passive, it is not initiated by changing the attribute C. [A], since the corresponding flags ( Unset / Reset ) of the context socket are turned off, and it does not participate in the process of working out external influences. This connector is used in the process of organizing the assignment of a value to the reference attribute C. [A], which will be discussed in detail later. In the meantime, we note that the list of backlinks, addressed by the back- connector, if viewed as a source of data, provides many homogeneous values, without being able to automatically select one of them.
Meanwhile, there is the same condition under which one can choose from the list a strictly defined one and at the same time a single element. For this, the list must have a unique property based on the key value, and the key itself is required.
Grouping by value
Consider an example of all the same three classes, but, for greater clarity, in a slightly different interpretation: class A is some Journal , whose Records (class C ) should be grouped by Calendar Days (class B ). Every Day in the Journal is unique in its Date ( D ) calendar date value. This uniqueness is ensured by the slightly upgraded list functionality assigned to the backlink attribute A. {B}, which generates a transactional exception when trying to add an entry to the list with a key value already existing in the list.
The back connector has also undergone some changes: it uses the Date (D) attribute as the key context, and has become semi-active : its contexts are active (the Unset / Reset flags are set for all context sockets of the connector), with the Set socket flag set off .
With active context sockets, any change in the values of the attributes C. [A] or C .D activates the back connector, which will retrieve the value of C. D, and use it as a key when accessing the list A. {B}, then the resulting value ( The object B IDO will be assigned to the target attribute. Thereby, automatic positioning (in other words, grouping) of objects of class C to objects of class B is realized.
What happens if you enter a date for the C .D value for which there is no corresponding Day object? In this case, the back connector naturally returns the value NUL, and the Day reference will be de-initialized.
It is worth noting that occasionally this behavior is also required, but most often the required Day object corresponding to the entered date must be created automatically. To implement this behavior, the attribute C. [B] is assigned the Autoset functionality. This functionality (discussed below) when it is initiated by the back- connector, will automatically create a new object of class B , then assign the identifier of the created object to the attribute of the direct link as a value.
But this is not enough. In order to preserve referential integrity, the attributes D and { A } of a new object B must automatically obtain strictly defined values, namely, those coinciding with the current values of the similar attributes of object C. For these purposes, the B .D → C .D and B. [A] → C. [A] connectors enable the transfer of the value transfer , namely: the incoming Get- socket of the connector belonging to the C attributes .D and C. [A] In addition, the Set flag is set . Then, when assigning a value to the attribute C. [B], the transport context of the connectors B .D → C .D and B .. [A] → C. [A], these connectors will be initiated to transfer the values to object B. Let's pay attention - the declaration of dependencies given in the diagram ensures automatic preservation of logical and referential integrity when changing any of the values.
The above set of declarations, which implements the grouping of objects by attribute value, is created by the internal model constructor in two steps. If the uniqueness option is enabled in the properties of the backlink attribute in a certain common class, then the relation to which the given attribute belongs becomes unique. At the same time, the target link class itself can now act as a class, grouping links by the value of its base attribute. A relationship with such a class of any third class, which also has a relationship with a general class, acquires an option (in the properties dialog) that allows you to select an attribute in the third class tuple, according to the value of which the grouping is implemented.
Grouping by links
Slightly modernize the previous example: let the place of the absolute attribute D in classes A and C take the attribute of a direct link to class D (the list of backlinks is generally the same as the key to the value: calendar date or IDO object identifier). And for greater clarity, we will change the semantic meaning of the classes: class A is the Goods , class D is the Warehouse , class C is the invoice / delivery note (movement of the Goods). Then the semantic load on class B is unambiguously derived: it is Commodity-in-Warehouse . If you replace the Warehouse with the Supplier or the Buyer , then Class B will become the Goods-at-Supplier / Buyer .
Corresponding to the changes made, the declaration will look like this:
Any Record when receiving specific pointers to the Warehouse and Goods objects will automatically receive a pointer to the Goods-on-Warehouse object, and in the case of the absence of such, it will automatically create it. Note: the connection of two classes, Product and Warehouse , through the third class ( Product-on-Warehouse ) is a variant of the many-to-many relationship, an alternative to the direct exchange of the values of the two attributes of the reciprocal link. Moreover, this option also has the property of uniqueness. In other words, for each pair of objects the Goods and the Warehouse , which connects their object Goods-in-Warehouse, exists in a single copy. This behavior is due to the uniqueness property of the list of backlinks, for which the pointer-attribute to the opposite class is used as the key source. And it doesn't matter at all in which of the two classes ( Goods or Warehouse ) the list is unique, the same list of backlinks (with the usual list functionality) in the opposite class will actually contain a unique set of keys.
Many-to-many relationship
A direct implementation of a many-to-many relationship looks like two interacting lists of backlinks in each of the classes being linked. Such an implementation has, in general, an insignificant practical meaning: only a statement of the fact of the connection of objects, without the possibility of realizing through this relationship a consistent interaction of the attributes of these classes. Therefore, in practice, the desired interaction of attributes is realized through the attributes of the third class associated with the relationship with the target classes. In real-world application models, such constructs are found all the time, and are created in the most arbitrary fashion, without pretending to be distinguished as a separate type of relationship.
It is quite another thing when the relationship through the third class has the property of uniqueness, as in the Stock-in-Stock from the example above. Here, the specificity of the third class (connection class) is not so much the use of relationship attributes as sources of a key, but its conceptual “production” of the relationship of classes. Therefore, such a unique (by identifiers) relationship of classes through the third class will be further considered as a many-to-many relationship. This type of name can be called both a unique relation and a projection relation .
A projection relationship is created as a result of executing a dialog, during which classes are linked by relationship, after which the corresponding constructor method creates the third projection class itself, with assigning it the corresponding composite name, and all other necessary declarations of relationship attributes and their connecting connectors . , , , -. , , - .
, . , , -, - .
By increasing the multiplicity of a relationship, we thereby allow an object of one class to address two or more objects of another class, which in turn can also be considered as a logical analogue of the many-to-many relationship considered earlier .
Based on this, it should be assumed that the multiple form of the relationship must have its own projection - a unique form of the multiple relation, a pointer to the object of which can be obtained automatically.
And such a unique relationship will indeed be created if, in the process of creating a relationship-projection dialogue, we choose the same class as the target classes. And after the relationship between a simple class and a projection class is created, the declaration of attributes and connectors takes the following form:
With all the oddities of its appearance, it is a logical and quite a workable declaration, which is practically used, for example, in accounting - for receiving objects of mutual correspondence of balance accounts. As a matter of fact, this is where the name was borrowed - the correspondence used further to denote a multiple unique relation implemented by the projection class.
What should be noted in the above declaration: in contrast to the usual projection, which connects any pair of objects with its only copy, correspondencesuch a link is implemented in two instances, one for each combination of pointers in the elements of a direct link. For these purposes, in all interactions, including the formation of a list of backlinks, reference pointers, acting both as values and as keys, are complemented by an index of the element in which they are located. In addition, to block meaningless dual addressing, a special functionality can be assigned to a reference attribute in a projection class, which prevents both elements from having the same value.
Relationship implementation
– Set IDO . , . , , . , , Create , , , . (, ). IDO , Autoset .
. , . , IDO « », .
, , , , ( ) . Data- ( ), IDOin accordance with the choice made. The selection dialog can be direct or cascade, which is set on the basis of existing back- connectors. The source for the formation of the dialogue list is the corresponding list of backlinks.
Autoset functionality
This functionality is assigned to the attribute of a direct link in order to implement the relationship by automatically creating a derived object of the target relationship class. Autoset
functionality can be triggered by both the inbound connector and the external Update event . In this case, the relationship target object will be created by the functional only if the reference attribute in the source object does not have a stored value.
Reproduction set
There is a solid rule of logical interaction of values, according to which a value belonging to a specific domain can only be associated with a value whose domain is in the source or includes the source. In this case, only the value with an equal or more extensive domain can accept the initial value. The largest domain (after Undefined Type ) for an attribute of the type Logical , which can take the value of any other type. Simply put, the connector can only associate the same type of attributes, which was observed in all the examples considered earlier. But in the following declaration, the passive connector, linking the attributes of the reciprocal link ( A. {B} → C .{D}) , , .
, , , . .
, , , , , . , , , unchanged. It is a different matter when the transactional nature of the impact is obvious. In this case, a previously not initialized static attribute can and should form a stored value as part of a general change in the state of the base. As can be seen from the declaration, the connector in question and its target attribute C. {D} will be triggered by assigning the value to the attribute C. [A], that is, transactionally. And if the derived value at this moment does not exist, the attribute C .. {D} begins its formation on the original sample provided by the connector.
As a value, the list of backlinks is derived from the direct links. In other words, attribute C .{D} , — D , . Create . ( – , ) — . , , , .
– , .
( ) , . – , , .
, , , , , . .
, , , .
Through an internal relationship, an attribute can create a connector to itself. This is a very effective technique that allows you to implement various kinds of generalization of values, including the generalization of the "progressive total".
The functional meaning of the internal relationship is determined by its type.
Chained relationship
-- , .
: , Autoset , . - Update .
Examples of use - the passage of a part of the processing cycle, organized as a sequence of operations, or the estimated periods of the year: quarterly or monthly, with cumulative totals at the beginning and end of the period. If the power of the chain relation is increased to three, the objects of the class can form a logical similarity of the three-dimensional crystal lattice. Such a construction can be used for a variety of behavioral modeling, including in physical environments.
Recursive relation
-- , , ( - ). – , . – -.
, , , .
, :
1. , , , .
2. , ( ) .
It should be noted that these restrictions apply only to the implementation of the multiple relations of a class with an internal recursive relationship with other classes, and do not apply to analogous unitary relations. These rules, characteristic of hierarchies in general, are not strict, but are recommendatory in nature. Compliance with these rules at the object model level is not controlled at all, and is entirely assigned to the interface part of the application.
Recursive projection
, - , , , - , . , :
, - .
, - , , , , , :
( [*]) , , . : .
( ) , , (=). , 2. ( 1 3), , . , : Get , , . , , .
, , .
The need for a structured interface arises whenever it is necessary to obtain unified access to different entities through relationships . In other words, entities with a different set of details should be reduced to a homogeneous (in terms of details) set. Well, at least then, to present them as a general list.
The first solution to this problem provides us with a class inheritance mechanism : a descendant class inherits a tuple of ancestor class attributes. This is quite enough, for example, to bring all the wealth of types of financial documents into one list of the type Date , Number , Document Name / Operation , Amount .
This solution can be conventionally called the interface " on top ". It works well, but unfortunately not all entities have a common ancestor. A typical example is given to us by the specifics of accounting in construction: several Customers finance large Construction sites , which consist of several Construction Objects , the works on which are structured by type of work , and are included in various Agreements (with the Customer ). Work progress is required (funding, expenses incurred, man-hours, ...) summarize the a la Gantt chart into the big picture . . , , -- , – , -, . , :
«» ( Autoset ) , " " ( ), . “ " , , [*]. , , , « ».
( ) " " ( ), , — " ". , , , . «» " ", , , -, .
Probably it should be noted that the existence of such different variants of partial structural unification suggests the idea that there is no universal interface solution in nature.
Interface type
In the data object model, any structural type most naturally exists as a custom class whose ID ( IDC ) is a handle to this data type. Accordingly, the interface data structure can be defined as a class, and its use as an attribute value should be considered as a peculiar modification of the unitary relationship , in which the attribute of a direct link to the interface class does not store the object ID of the interface class (IDO), but the object itself. Since an object that is “included” as a value loses its independence, along with it, it ceases to have its own descriptor. Now its identifier is a composite value in terms of the IDO of the owner object + IDA of the attribute in which it is located. This solution allows you not to worry about the method of creating the included object and realizing the relationship with it - all this happens automatically when you create the owner object during the initialization of its attributes.
Since it is initially assumed that the “interface” object will be included in the composition of objects of various classes, the traditional way of ensuring the symmetry of a relationship by creating a reference attribute in each of the classes being linked ceases to be optimal. In fact, with this method, in the tuple of the “interface” class, a certain number of reference attributes will be declared, of which, in the actual implementation of the relationship, only one will always get the value. Therefore, another option was chosen, asymmetrical in the declaration, but nonetheless maintaining reference symmetry during implementation.
In the interface class, the role of the reverse link attribute for all created interface relations is performed by the same attribute, Own , which, in order for it to accept a value of any reference type, is forcibly assigned the type User Defined Type . In fact, the purpose of this type of attribute Own and plays the role of a flag that marks the class as " interface ".
The final declarations of the " interface " relationship (right), compared to the declarations of the usual unitary relationship (left), look like this:
The logic of defining an interface type also establishes the order of its use: the class declared by the interface forms an independent data type (structural type), which is complemented by a standard set of types that participate in the formation of the menu for choosing the attribute typing dialog. If you select this type and assign it to an attribute, the model constructor will create all the declarations shown in the diagram.
Service classes
In fact, utility classes are ordinary data classes that are used by the data management system to solve its internal utilitarian tasks. The difference between service classes and others is only that they are created by the control system automatically, when generating a new database, and accordingly have fixed descriptors that are known a priori by the system.
Super class
The set of data objects, symmetrically linked by reciprocal links, is a closed system, within which the natural inter-object navigation is not limited by anything. But since, for reasons of reliability and safety, direct access to objects is prohibited, the problem of entry into such a system arises. To overcome it, it helps to use a service class , called a Super Class , and a Super Object derived from it, with fixed values of IDC and IDO descriptors.
When the designer creates an application for each new user class, a plural relationship with the Super class is automatically created for this class . Thus, the previously mentioned set of service attributes of the class ( Type , Own and Del ) is complemented by the fourth member - the attribute of a direct link to the Super Class. The superclass, in turn, receives a backlink attribute, typed by the IDC descriptor of the newly created class. Thus, upon the creation of custom classes, the Super Class becomes a kind of owner of their full set, which allows using the Super Class with its fixed handle as an entry point to the actual data model. Remarkably, the attribute identifier ( IDA ) of the reciprocal link in the Super Class oddly coincides in value with its class identifier ( IDC ).
In the process of creating a derived object ( Create ), its service attributes are automatically initialized, including the direct link attribute to the Super Class , which receives a fixed Super Object IDO . At the same time, as a result, a pointer to a new object adds to the corresponding list of back links of the Super Object . Thus, solely upon the observance of the standard rules for the implementation of relations, the Super Object becomes the owner of the lists of objects of each class, in other words, the full set of objects. This circumstance allows you to use the Super Object as a natural entry point into the database , which opens access to the lists of class objects.
Pay attention to the important point - the data class, like a declaration, does not have a physical pointer to the list of its own objects. Between data and metadata there can be no other connection than the logical one.
And one more detail: when organizing an object selection dialog, the Data cursor by default, unless otherwise specified, uses a list of backlinks of the target class from the Super object .
Global class
Any application needs global values that are permanently available to all parts of the application. For the declaration of such values, the service class Global is used , in the derived object of which they are stored. The specificity of the Global class is the fact that it is related to the Super Class not by a plural relation , like all other classes, but by a one-to-one unitary relation. In other words, with respect to the Super Object, Global exists in a single copy, and since its position in the Super Object tuple is known, its values are accessed in one step.
Depending on the features of their use, the entire set of global values can be divided into groups. The first group consists of isolated values that are used by themselves, usually in interface forms, such as the name of the organization (own). To access these values, a route is sufficient: Super Class → Global → Attribute .
The second group is formed by the so-called borrowed values, such as the VAT rate . In order to use the borrowed value, the class must have a relationship with the Global class, and obviously multiple . If such a relationship is declared, the model constructor in addition to it creates a connector that allows the object being created to automatically receive a pointer to a Global object.
In addition to absolute , reference values can also be global. Such values are most often used as default values that are set when setting up an application, for example, references to Currency objects that make up a Ruble-Dollar pair. Since many (Global) -c- type relationships will strain common sense, global reference values are created somewhat differently: the Undefined Type attribute is first created, in atomic (for a single link) or enumerated (for several links) form, and then its type is overridden by the User Defined Type = IDC of the target class. In other words, the attribute of a direct link is created without a declaration of the relation itself. This technique is used everywhere where there is no practical sense in declaring a relation, and an attribute of the desired type is needed (as, for example, when implementing the recursive projection discussed above).
In addition, all values stored by the Global object are divided into common and user-defined . General, such as Organization Name or VAT Rate , are the same for all database users. Unlike the Reporting period or the pointer to the default warehouse (for a specific storekeeper, for example), which must be individual for each user. For the formation and storage of user values are used objects of class User .
Class user
The main purpose of the User class is to build an authentication system for end users of the database on its basis. If during the authorization the username and password entered by the user coincide with the values of the corresponding attributes in one of the User objects, then the authorization is considered successful, after which the values of all other attributes of this object are available to this user (and only him) as global values.
It is implemented as follows. The classes Global and User are related by a multiple relation . When creating a new static attribute in the User class, the Global class automatically creates a pairwise same-type and dynamic attribute of the same name ( user ), which after creation receives a passive incoming connector from the pair attribute to it in User . When accessing a user attribute in Global , this attribute attempts to get its value through a connector, and at this point the runtime replaces the list of back references to User objects with a pointer to the only such object obtained when authorizing the user.
Note that an attribute can get its value by a connector through a list of backlinks from a variety of sources or by converting these values into a unique one (for example, by summation), or if there is a condition (context) that allows to single out only one set of values. In the absence of the corresponding condition or conversion (functional), the attribute is prohibited to create an incoming connector through the backlink attribute. For a custom attribute in the Global class, this restriction is overcome by artificial means.
Local Databases
A little higher in the text it was already mentioned that the set of related objects forms a closed system, the only entry point to which is a Super-object . Within the limits of one physical database there can be an arbitrary set of such closed systems. Each such system can be considered as a logical database, completely isolated from other similar logical bases. Each logical base has its own entry point, its Super Object . In other words, to generate a new logical base, you need to create another object derived from the Super Class .
This task is solved with the help of three service classes: User → Global : Super class , with the Global class leading in this bundle. It is the Global class that is associated with the logical database, and each derived object of this class stores the user name of its “own” base in the corresponding attribute. Having a one-to-one relationship allows the creation of a Global object to automatically create and associate with it a new Super Object . Regarding the Global object (considered as an instance of a logical local database ), objects of the User class (named Users of this local base instance) are created. After passing through the authorization procedure, for this User in his record in the Clients Table are stored descriptors ( IDO ) not only of the Users object, but also the Global and Super objects associated with it. It is the user pointer to the Super Object (the root element of the local database) that will be used by the management system as a value that is automatically assigned to the corresponding service attribute of an object of any class when creating this object at the initiative of this particular user.
What is important to note is that all mutually isolated logical databases obey their common data model rules, which operate throughout the entire physical database space.
Relationship Inheritance
When it is created, the heir class receives the full tuple of attributes of the ancestor class, and together with the attributes of the heir class, it receives the full set of ancestor class relationships. And at the same time pops up an interesting detail.
Each new class, regardless of how it was created, must form its own relationship with the Super Class in order to have a complete list of its objects in an explicit form. But the heir class cannot directly create such a relationship, since it already inherits the attribute of a direct link to the superclass within the entire ancestor tuple. In addition, although the ancestor class does not create its own objects, nevertheless its list of backlinks in a super-object should include a complete list of objects derived from all its child classes. (For an example: there is a set of all Documents in general, and there is a private set only of the Consignment Note .)
The list of objects for the ancestor class will be formed without any interference with the existing declarations, since all its heirs received its parental relationship with the superclass. For the heir class, the class constructor implements a partial creation of a new relationship — the existing attribute of a direct link is used (a new one is not created), a reverse link attribute is created in the pair in the superclass, and both attributes are linked by a reference connector .
Thus, the inheritance partially violates the bilateral symmetry of the relationship with the superclass: one direct pointer to the super-object will now correspond to two or more (depending on the depth of inheritance) pointer backward link in the super-object. But such an exception to the rules is private and seems logically justified.
Domain Refinement
The domain of the values of the reference attribute is formed by the identifiers of objects derived from the opposed relationship class and all its successor classes. In applications, there is often a need to forcefully narrow down the domain of values of a referenced attribute, limiting it to a single class.
Consider the following example:
An abstract Counterparty has one of two organizational forms: Legal or Individual (heirs of the Counterparty class). In barter transactions, the Counterparty plays a specific Role : it can be the Supplier , the Buyer, or both. Obviously, there is a very specific relationship between the Counterparty and the Role , which we will separately consider a little later. The Consignment Class is an abstract commodity exchange operation in which natural plural relations with the Counterparty and the Role are declared. In our example of specific operations, there are exactly two: Receipt and Expense , the heirs of the Consignment Note and its relations.
The heirs of the Consignment note use the relationship with the Counterparty in the form in which it was inherited. Both the Incoming and Outgoing Invoices implement this relationship by selecting the target object from the general list of Counterparties , in which both Legal Entities and Individuals are equally present.
The inherited relationship with the Role requires redefinition , as the subject of the reference for the Invoice can only be the Supplier , and for the Expenditure note , only the Buyer . The redefinition of inherited relationships ( domain narrowing ) is achieved by replacing the ancestor class identifier with the inheritor class identifier in the attribute properties, for which the reference attribute provides the corresponding dialog to the model constructor. Note that after clarifying the relationship from a direct link in the Receipt and Expenditure invoice, only the invoice objects corresponding to their role will automatically be included in the lists of backlinks of the Supplier and the Buyer . But a symmetric redefinition of the relationship also for the reference attributes of these classes will be considered good form.
In the previous example, the Consignment Note logically links the Counterparty with its Role . Consider this relationship in more detail, using the same set of classes, but presented in a slightly different perspective:
The counterparty can be both a supplier and a buyer at the same time. This fact is declared by the creation of two separate unitary relations of the Counterparty with these classes, without creating a common relationship with the Role . At the same time, a common ancestor is required, as it carries not only the relationship with the Consignment note , but also an additional set of attributes common for the Supplier and the Buyer , for example, for organizing various mutual settlements. The logical connection of the Counterparty with the Role is as follows (for example, the Supplier – Payment receipt pair ): The Counterparty acquires the status of a Supplier (forms an object of the Supplier class, and realizes a relationship with this object) if there is at least one Invoice . In order for this connection to get a physical implementation, and work as an internal rule of the data model, you should use the Autoset functionality, as shown in the figure:
From the left part of the figure, it is clear that the presence of a unitary relationship between the Counterparty and the Supplier allows the Invoice to potentially receive a value for any of its direct link attributes when the pointer is assigned to another direct link attribute. , Autoset . back -. , , , . , . back - Autoset , , – . , , , back - .
:
Create , . , , . , .
The value of the attribute S from class B is distributed by three connectors: one common - to the attribute S of the ancestor class A , and two private - to the attributes D and K of its heirs A1 and A2 . Depending on which pointer to which object from the heirs, A1 or A2 , will be received by object B , in the addressable object only one of the two attributes, D or K , will receive its value. The S attribute will get its value anyway.
This behavior is provided by the selective properties of the ref context of the connector, namely due to the presence in the declarations of the ref socket identifier IDC of the target class of the connector. The external connector will perform its transfer function only if the ref context provides it with the IDO of the target object. And this will happen only in the case when the value of the reference attribute - the object IDO is included in the domain of values of the type declared in the properties of the ref - socket.
Well, it just suggests an association with the if statement , which checks the type conformity before performing the action.
Summary
, , . , (no Select ) .
, - , , , . , , .
Source: https://habr.com/ru/post/348560/
All Articles