We build a distributed reactive application and solve consistency problems.

Today, many companies, starting a new project or improving existing systems, are wondering which development option is more justified - use the “classical” three-layer approach or design the system as a set of loosely coupled components?
In the first case, we can optimally use all the accumulated experience and existing infrastructure, but we will have to endure long cycles of planning and releases, difficulties in testing and in ensuring uninterrupted work. In the second case, there are risks in the management of the infrastructure and the distributed application itself.
In this article I will tell you how and why we chose the second option at 2GIS to build a new system, how we solved the emerging problems and what benefits we got from it. Under the cut - about Amazon S3, Apache Kafka, Reactive Extensions (Rx), eventual consistency and GitHub, tight deadlines and the inability to assemble a team of the required size from engineers using one technology stack.
What is an Advertising Management System and why do we need advertising?
2GIS makes a profit from the sale of advertising opportunities to companies that want to be more visible to users of 2GIS products. In advertising sales there are two components - it is the sales process itself and the management of advertising content. In this article, we will focus on the second component and consider some details of a system called the Advertising Management System (AMS), an application for managing advertising materials in 2GIS.
Back in 2011, a sales system was launched at 2GIS, which opened up new opportunities for increasing the volume and effectiveness of advertising sales. At that time, there were not so many types of advertising content, so the module for managing advertising materials was part of the sales system. Over time, the requirements for the module increased: new types of content appeared, the moderation process started, a more transparent audit of changes was required.
All this led to the fact that at the end of 2016, a new project was launched to allocate the module for managing advertising content into a separate system - AMS, where it would be possible to initially solve all current needs and lay the necessary foundation for development.
The main purpose of AMS is to provide automation of the creation, moderation and release of advertising in 2GIS products. The users of the system are 2GIS sales managers, the advertisers themselves, as well as 2GIS moderators. AMS works in all countries where 2GIS is present and is localized into several languages, the main of which are Russian and English. To understand how AMS works, let's look at the main stages of working with advertising material.
Imagine that a certain company decided to increase the number of orders. You can attract the attention of users, for example, by placing a company logo and a short comment in the search results, and choosing a corporate background color and adding a call-to-action button in the card. All this is done by the advertiser himself or his sales manager. Then the advertising material is sent for moderation, and after checking the moderator is delivered to all 2GIS products.
The main distinctive feature of the system is that all data in it is versionable. This means that any change in advertising content, whether text or binary data, leads to the fact that a new version of advertising material is created “side by side” with the previous version. This allows you to always have complete information - who, when and what changes made. This is very important in terms of legislation. To solve this problem, it was decided to store the data that makes up the promotional material in an Amazon S3-compatible repository that provides out-of-the-box versioning.
However, in order to effectively design a system, you need to have a clear and understandable data storage level API that works in terms of our specific subject area. This is how the internal Storage API appeared, adapting the CRUD API S3 storage in the API for storing advertising materials, that is, objects of a strictly defined structure. This Storage API has its own name - VStore (Versioned Storage), and its development is being done openly on GitHub .
Initially, VStore was conceived as a fairly simple REST service, but during the development process it became obvious that at this level some other tasks also needed to be solved. For example, transcoding and distributing binary content or deleting unused data (“garbage collection”). But more on that later.
S3 perfectly allows you to store data, but does not allow to perform effective search queries. Therefore, the project also includes the familiar SQL database, which contains metadata about advertising materials for search scenarios, as well as data necessary for the implementation of full-fledged business cases.
At the beginning of the project we needed to solve another problem - at that time we did not have the opportunity to assemble a team of the required size from engineers using one technology stack. And the terms, as always, were rather tight.
Therefore, we assembled a team from different “worlds”, and the system was designed as a set of isolated modules that could be written using different programming languages and run in Docker containers. We are very lucky that at the same time Kubernetes began to be actively exploited in 2GIS. So we took the path of microservices.
AMS infrastructure
Currently, AMS consists of four large modules:
- VStore solves the issues of versioned storage of objects of a strictly defined structure and completely abstracts S3 storage, interacting with it as efficiently as possible. At this level, the content of advertising materials is monitored for compliance with configured rules (the number of characters in the text, the size and format of bitmaps, the validation of vector graphics, and much more). All content distribution is the responsibility of VStore.
- AMS API is essentially the backend of the entire system. The AMS API uses VStore to execute cases that require the creation or editing of promotional materials, including working with binary data. All meta information about promotional materials AMS API stores in a relational database. Frontend AMS, as well as other company systems, interact with the AMS API.
- Frontend AMS is a UI application for performing all user cases with promotional materials. It is this application that 2GIS sales managers and advertisers use in their work.
- The AMS admin panel is needed in order to customize the very rules and restrictions on the content of advertising materials depending on the type and language of publication. These rules are dictated by the products of 2GIS, where advertising will be displayed.
These modules are implemented independently in different languages in isolated repositories. All engagement contracts are carefully aligned, so development moves in parallel and efficiently. Each of these modules is launched as one or several Docker containers lifted to Kubernetes.
In general, Kubernetes is one of the parts of the 2GIS common platform on which many services of the company work. This platform also includes a unified logging infrastructure built on ELK, as well as all the capabilities of monitoring services using Prometheus. For a simple and convenient build and deployment of any applications in the company, an internal specially configured GitLab is used. Why and how all this was created, read this article .
The process of assembling all AMS components and their deployment in all 2GIS data centers is also automated. The modules have their own internal release cycles and versions that are consistent with the versions of the other components. All this allows for a minute to raise an isolated test stand to check for changes in any part of the system or to deploy applications on staging or production. You can learn more about how this works , by looking at the recording of the report with DevDay .
Closer to the point
Microservices and weak connectivity is, of course, good: isolation, parallel development in several languages, and ease of change management. However, this method of application composition requires solving a number of architectural tasks. And the first one is communication between components.
You can transfer data in two ways - synchronously and asynchronously. In the first case, we send a request to a specific endpoint. Requests are blocked until an answer is received, or the waiting time expires. This method allows you to implement cases that require confirmation of the action and the result of the operation. The second way is sending and receiving messages, that is, implementing the producer / consumer pattern.
In reality, you have to use both of these methods together. So, for synchronous cases, we use the HTTP protocol and REST services, and all message passing is based on Apache Kafka .
Consider the basic case of AMS - the creation of promotional material. Let me remind you that the promotional material may consist of a set of different elements, the content of which is either text or binary. Therefore, to create promotional material, you need:
- Determine the type and number of items.
- If there are items with binary content, you need to create a time-limited session to download binary files.
- Send a prototype of advertising material to the client side to render the UI.
- When downloading binary content, you need to check it (type and size of the picture, the presence of the alpha channel) and return the link to the client; in case the checks fail, delete the downloaded file.
- If all the required values are filled and the new advertising material is sent to the server, you need to check all the text values (hypertext, the number of characters in the whole and in each word, the number of words, etc.).
- If all checks have passed, you need to create advertising material in the versioned store using VStore and save the meta information (name, link to the company, moderation status) in the relational database.
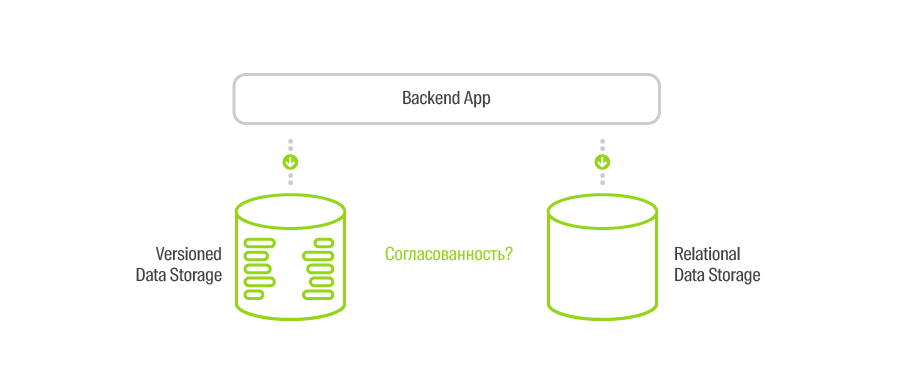
What could go wrong here? In the case of a distributed application - very much.
If any of the REST services is unavailable, then due to the synchronism of the case itself, promotional material will not be created. But still there is a nuance.
Imagine a situation where the AMS API creates an object through the VStore by sending a POST request. VStore successfully processes it by sending a response. Despite all the successes, there is a possibility that this answer will not reach the AMS API, for example, due to the network “flashing”. What then? Then the AMS API will consider that the object has not been created and will tell the user about it (for simplicity, we assume that there are no retry-cycles). But if we try to create this object again, we will either create a duplicate (if we generate a new identifier), or we cannot complete the creation, since the object already exists. In both cases, we obtain the mismatch of the repositories.
Another tricky case
Before proceeding to the description of the solution, take a look at another point.
Let's say we create advertising material. We prepared a session for downloading binary content and letting the user upload a picture. Having checked everything beforehand, we load it into the storage and return a certain key (link).
But what if the user didn’t like what the loaded picture looks like, and he uploaded another (or third, fourth)? In fact, only the last loaded picture will be included in the promotional material, and the rest will not be used at all.
And what if, after all the manipulations, the user decided not to create advertising material at all and left? All downloaded binary content has become garbage that needs to be removed.
How to do it guaranteed and efficiently?
silver bullet
In this article, I used the term “microservices” a couple of times, and this could cause a reasonable resentment among fans to argue about terminology. Indeed, microservices are often referred to as a collection of completely independent small applications, each of which has its own interaction contract, model of the pre-domain area and its own data store. In our case, all backend services use shared storage.
Anyway, I am of the opinion that the term “microservices” can be used in this case, and the presence of one domain model logically leads to the use of shared repositories. So, having one core domain model, we can reuse it in different components, and, therefore, we can reuse the logic of storing and reading data. This is quite rational, since changes in the basic domain model will inevitably affect the business logic of all parts of the application. The main thing here is to correctly define the boundaries and responsibilities of the application, and correctly identify the core domain model.
But let's see how we can solve most of the data coordination tasks based on the two tools we have - versioned storage (S3) and messaging infrastructure (Apache Kafka).
If you look a little wider, you can see that data versioning is one of the implementations of the immutable property. Having this property and a guarantee of the order of versions / messages, we can always build a system, the data in which will be finally coordinated ( eventual consistency ).
Let's change the implementation case of the promotional material case a little by adding some side effects (the changes are highlighted in bold):
- Determine the type and number of items.
- If there are elements with binary content, you need to send a message about the attempt to create a session and create a time-limited session to download binary files.
- Send a prototype of advertising material to the client side to render the UI.
- When downloading binary content, you need to check it (type and size of the picture, the presence of the alpha channel, etc.), send a message that the file with a specific key was downloaded , and return the link to the client; in case the checks have passed, delete the downloaded file and do not send the message .
- If all the required values are filled and the new advertising material is sent to the server, you need to check all the text values (hypertext, the number of characters in the whole and in each word, the number of words, etc.).
- If all checks have passed, you need to send a message about the attempt to create an object with a given key , create advertising material in the versioned store using VStore and save the meta information (name, linking to the company, moderation status) in the relational database.
Thus, together with changes in the data, we still send events in the order they occur. This is all that is needed to implement a huge number of scenarios. Moreover, their implementation can be completely independent of each other with the help of the same microservices that run as separate background processes.
Now the task of data consistency in storages is solved relatively easily: the background process receives events about attempts to create an object, finds out whether it was possible to create an object, and checks its presence in the SQL storage. If the synchronous case described above still fails, it will be eliminated asynchronously. The time interval during which the system will be mismatched will be lower, the more effectively we work with Apache Kafka. And this is where the reactive approach comes in handy.
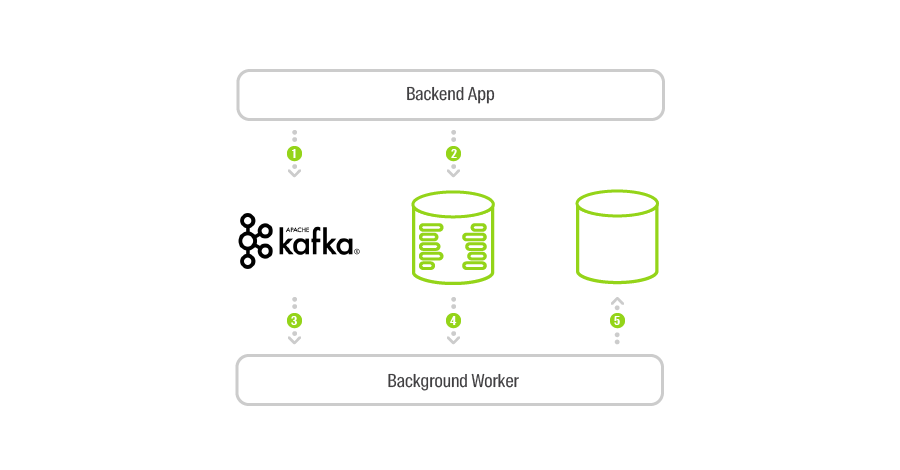
Let's now see how, with the same messages in Kafka, you can effectively implement the cleaning of unused binary files. It's simple.
Having created another background microservice, we can move through the queue of messages about the facts of the session creation. As soon as the session is over, and therefore, new files cannot be uploaded, we need to find out whether, during the session's active period, objects that referred to files from this session were created or modified. Kafka provides an API for working with time intervals (since every message in Kafka has a timestamp), so it’s easy to do. If we find out that there were no links to any of the files, we can delete the entire session with all the files. Otherwise, we will only delete unused files.

Having the application architecture described, it is quite simple to implement completely different scenarios - from sending notifications to users to building complex analytical models based on events that took place in the system. All you need to do is start another background process. Or disable it in case of uselessness.
Reactive approach
What is it and how can this paradigm help us work effectively with Apache Kafka? Let's figure it out. To understand the basic idea, I’ll quote from The Reactive Manifesto ( translation ):
Systems built as Reactive Systems are more flexible, loosely coupled and scalable . This makes it easier to develop and amenable to change. They are significantly more tolerant of disaster and disaster. Reactive Systems are highly responsive, giving users effective interactive feedback. "
In the context of the task before us, special emphasis should be placed on the words “highly responsive” and “effective interactive feedback”. The main point is that the use of a reactive approach will allow us to build a system so as to receive instant response and have minimally low delays in receiving and processing messages.
There are several tools that help implement systems using “reactive”.We used Reactive Extensions in the implementation for .NET. At the heart of this library is the concept of observable sequence, that is, a collection that notifies subscribers about the appearance of new elements. Having such a collection, Rx.NET allows you to build a message processing pipeline using various operations, the simplest of which are filtering, projection, grouping, buffering, and others.
How to make friends Kafka and Rx? Very easy. The client library API for working with Kafka requires the client to specify a function that will be called when a new message appears (in .NET it is a subscription to the event) and a circular call to the Poll method. Rx.NET has a special Observable.FromEventPattern method for switching from this type of API to Observable . Here you can see the real production code.
Thus, the use of Rx.NET allows very seamless integration of Apache Kafka and our application, while obtaining high efficiency, low latency and very simple and readable code .
Conclusion
Distributed applications are not easy. If we had no reason to make AMS multi-component, perhaps we would again follow the path of "classical" architectures.
Let me remind you that to build a solution we needed:
- Support efficient versioning of any data.
- To develop on different technological stacks and at the same time have a good understanding within the team.
- Have very short release cycles and roll out changes to production several times a day.
- Provide ease of testing due to the relative simplicity and isolation of individual services.
- Design your application to provide fault tolerance and ease of scaling.
In addition, at the time of the start of the project, we had:
- The platform for the work of applications based on Kubernetes.
- Competently configured and supported by Apache Kafka cluster.
- Considerable experience in developing backends, which allowed to manage technological risks.
Currently we have 50-70 http requests per second (RPS), the number of messages sent by Kafka per second is measured in hundreds. This load is mainly provided by internal users - 2GIS employees. But an application designed in this way gives us the opportunity to increase sales through the advertiser's personal account and be ready for sales growth in any country of presence of 2GIS. Thanks to the microservice approach, we can relatively easily implement new features and manage the stability of the application.
Some technical details of the work of VStore can be found in the video of the report on techno.2gis.ru .
The VStore code is open and actively developed on GitHub . See, comment, ask questions.
')
Source: https://habr.com/ru/post/348510/
All Articles