Writing a Microsoft DNS server plugin to protect against IDN spoofing
IDN spoofing is the generation of domain names “similar” to the selected one, usually used to force the user to follow a link to the attacker's resource. Next, we consider a more specific version of the attack.
Imagine that the attacked company owns the organization.org domain, and within this company the internal portal.organization.org resource is used. The purpose of the attacker is to get the user credentials, and for this he sends the link via e-mail or messenger used in the company.

')
Having received a similar message with high probability you can not notice that the link leads somewhere not there. After clicking on the link, a login / password will be requested, and the victim, thinking that he is on the internal resource, will enter his account details. The attacker's chances are especially high if he has already penetrated the perimeter, having compromised the system of any employee, and is now fighting for the privileges of the system administrator.
An absolute “protection against a fool” cannot be invented here, but you can try to intercept this attack at the stage of resolving a name via a dns request.
For protection, we will need to consistently memorize the encountered names in the intercepted dns queries. The company uses its internal resources, so we quickly find in the request for portal.organization.org. As soon as we met the name “similar” to the previously encountered one, we can replace the dns response by returning an error instead of the attacker's ip address.
What could be the algorithms for determining the "similarity"?
Most likely the corporate server will not be bind, which is a standard rather for web-hosting providers or providers, but microsoft dns server due to the widespread use of the active directory. And the first problem I encountered when writing a filter to microsoft dns server - I did not find the API for filtering dns requests. This problem can be solved in different ways, I chose the inject dll and IAT hook for api working with sockets.
To understand the methodology, it will be necessary to know the PE format, you can read more, for example, here . The executable file consists of headers, a table of sections and the sections themselves. The sections themselves are a data block that the loader must map to memory at a relative address (Relative Virtual Address - RVA), and all resources, code, and other data are contained within sections. Also inside the heading there are links (RVA) to a number of tables required for the operation of the application, within this article two-import table and export table will be important. The import table contains a list of functions that are necessary for the application to work, but are in other files. The export table is the “inverse” table, which contains the list of functions that are exported from this file, or, in the case of export forwarding, the file name and the function name for resolving the dependency are indicated.
Inject dll will do without all the annoying CreateRemoteThread. I decided to use PE export forwarding - this is a well-known technique when, in order to boot into the desired process, a dll with the name equal to any dll name from the exe-file import table is created in the exe-file directory (the main thing is not to use HKEY_LOCAL_MACHINE \ System \ CurrentControlSet \ Control \ Session Manager \ KnownDLLs). In the created dll, the export table is copied from the target dll, but instead of a pointer to the code of the exported function, you need to write the RVA to the forward-string like "endpoint! Sendto". The microsoft dns server itself is implemented as a HKEY_LOCAL_MACHINE \ System \ CurrentControlSet \ services \ DNS service, which is in% systemroot% \ system32 \ dns.exe
The final injecting algorithm in the dns server will be as follows:
And why the last step? The fact is that in windows there is a built-in firewall, and, by default, in windows server the right to listen to port 53 is only in the% systemroot% \ system32 \ dns.exe application. If you try to start it from another directory, you will not have access rights to the network. And why did I copy it at all? In order to minimize the impact on the entire system and not touch the original dnsapi.dll. It turns out that if you can create symlink to an application, you can get its network rights. By default, only administrators have the right to create symlink, but rather unexpectedly finding that by giving the user the right to create symlink, you give him the opportunity to bypass the built-in firewall.
Once loaded into the process from DllMain, you can create a stream and set the capture. In the simplest case, our dns service will inform the client of the ip-address for the name by sending a UDP packet from port 53 using the sendto function from ws2_32.dll. The standard assumes the possibility of using TCP port 53 if the answer is too large, and it is obvious that intercepting sendto will be useless in this case. However, it is more laborious to handle the tcp case, but in a similar way. While I will tell the simplest case with UDP. So, we know that the code from dns.exe imports the sendto function from ws2_32.dll and will use it to respond to the dns request. To intercept functions, there are also quite a lot of different ways, classic is splicing, when the first sendto instructions are replaced with jmp in their function, and after its completion, the transition to previously sent sendto instructions and further inside the sendto function is performed. Splicing will work even if GetProcAddress is used to call sendto, not an import table, but if you use an import table, then it is easier to use an IAT hook instead of splicing. To do this, find the import table in the downloaded dns.exe image. The table itself has a somewhat confusing structure and you will have to go into the description of the PE format for details.
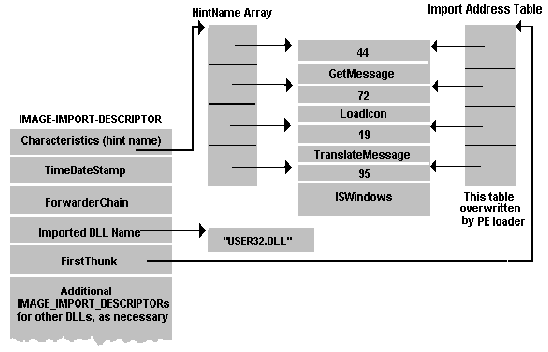
The main thing is that the system, in the process of loading the image, writes to the import table a pointer to the beginning of the sendto function. This means that in order to intercept the sendto call, you simply need to replace the address of the original sendto in the import table with the address of its function.
So, we set the interception and began to receive data. The prototype of the sendto function looks like this:
If s is a socket on port 53, then according to the buf pointer there will be a dns-answer of len size. The format itself is described in RFC1035 , I will briefly describe what needs to be done to get to the data of interest.
The message structure in the standard is described as:

In the header of the necessary information: message type, error code and the number of elements in the sections. The title itself looks like this:
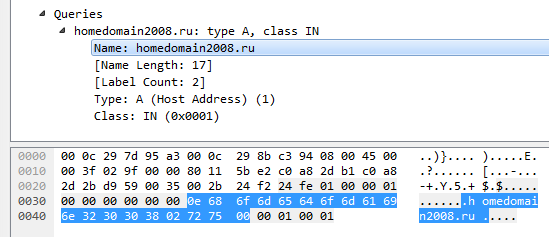
Section Question will have to disassemble in order to get to Answer. The section itself consists of as many blocks as indicated in the header (q_count). Each block consists of the name, type, and class of the request. The name is encoded as a sequence of strings, each of which begins with a byte with the length of the string. At the end is a zero-length string. For example, the name homedomain2008.ru would look like this:
The Answers section looks similar: a block consists of a name, a type, a class, a ttl, and additional data. The IP address will be contained in the add. data. With the analysis of the name there is another difficulty. Apparently, to reduce the size of the message, instead of the label length, you can find a link to another data area. It is encoded as follows: if the 2 high-bits of the length are 11, then the next byte, as well as the lower bits of the length, should be interpreted as an offset in bytes relative to the beginning of the message. Further parsing of the name must be done by clicking on this offset.
So, we intercepted the necessary API, disassembled the dns-answer, now we need to make a decision: to skip this response further or return an error. For each name that is not yet present in the database, it is necessary to check from the answer whether it is “suspicious” or not.
We will consider “suspicious” such names for which the result of the skeleton function from Unicode Technical Standard tr39 matches the result from any of the names from the base, or those names that differ from those present in the base by rearranging the internal letters. To implement the checks we will store 2 tables. The first one will consist of skeleton results for all names from the base, write the rows in the second table, which were obtained from the base lines by removing the first and last characters from each label except the first level, and then sorting the remaining characters of each label. Now, if a new name is included in one of the two tables, then we consider it suspicious.
The meaning of the skeleton function in determining the similarity of two strings, for this, for each string, characters are normalized. For example, Xl– will be converted to Xloe, and thus, comparing the result of a function, you can determine the similarity of unicode strings.
An example of the implementation described above can be found on github .
Obviously, the stated solution in practice cannot provide normal protection, since besides minor technical problems with interception, there is still a big problem with the detection of “similar” names. It would be nice to handle:
Imagine that the attacked company owns the organization.org domain, and within this company the internal portal.organization.org resource is used. The purpose of the attacker is to get the user credentials, and for this he sends the link via e-mail or messenger used in the company.
')
Having received a similar message with high probability you can not notice that the link leads somewhere not there. After clicking on the link, a login / password will be requested, and the victim, thinking that he is on the internal resource, will enter his account details. The attacker's chances are especially high if he has already penetrated the perimeter, having compromised the system of any employee, and is now fighting for the privileges of the system administrator.
An absolute “protection against a fool” cannot be invented here, but you can try to intercept this attack at the stage of resolving a name via a dns request.
For protection, we will need to consistently memorize the encountered names in the intercepted dns queries. The company uses its internal resources, so we quickly find in the request for portal.organization.org. As soon as we met the name “similar” to the previously encountered one, we can replace the dns response by returning an error instead of the attacker's ip address.
What could be the algorithms for determining the "similarity"?
- UTS39 Confusable Detection (http://www.unicode.org/reports/tr39/#Confusable_Detection) Unicode is not only a
valuabletable ofmechs, but also a bunch of standards and recommendations. In UTS39, the algorithm for normalizing unicode strings is defined, at which strings that differ in homoglyphs (for example, Russian a and Latin a) will be reduced to the same form - Words differing by permutations of internal letters. It's pretty easy to confuse organization.org and orgainzation.org
- Replacing the first level domain. The first level of the name usually does not make any sense, and an employee of the company seeing the “organization” can ignore the difference in .org or .net, although exceptions are possible
Most likely the corporate server will not be bind, which is a standard rather for web-hosting providers or providers, but microsoft dns server due to the widespread use of the active directory. And the first problem I encountered when writing a filter to microsoft dns server - I did not find the API for filtering dns requests. This problem can be solved in different ways, I chose the inject dll and IAT hook for api working with sockets.
To understand the methodology, it will be necessary to know the PE format, you can read more, for example, here . The executable file consists of headers, a table of sections and the sections themselves. The sections themselves are a data block that the loader must map to memory at a relative address (Relative Virtual Address - RVA), and all resources, code, and other data are contained within sections. Also inside the heading there are links (RVA) to a number of tables required for the operation of the application, within this article two-import table and export table will be important. The import table contains a list of functions that are necessary for the application to work, but are in other files. The export table is the “inverse” table, which contains the list of functions that are exported from this file, or, in the case of export forwarding, the file name and the function name for resolving the dependency are indicated.
Inject dll will do without all the annoying CreateRemoteThread. I decided to use PE export forwarding - this is a well-known technique when, in order to boot into the desired process, a dll with the name equal to any dll name from the exe-file import table is created in the exe-file directory (the main thing is not to use HKEY_LOCAL_MACHINE \ System \ CurrentControlSet \ Control \ Session Manager \ KnownDLLs). In the created dll, the export table is copied from the target dll, but instead of a pointer to the code of the exported function, you need to write the RVA to the forward-string like "endpoint! Sendto". The microsoft dns server itself is implemented as a HKEY_LOCAL_MACHINE \ System \ CurrentControlSet \ services \ DNS service, which is in% systemroot% \ system32 \ dns.exe
The final injecting algorithm in the dns server will be as follows:
- Create a directory% systemroot% \ system32 \ dnsflt (you can any other, finding the directory in system32 is optional).
- Copy there% systemroot% \ system32 \ dnsapi.dll is the dll from which dns.exe imports something, you can choose any other “not knowndll”.
- Rename the copied dll to endpoint.dll - we will use this name in the forward line.
- We take our injected dll and append the correct export table to it, copy our dll to% systemroot% \ system32 \ dnsflt
- In the registry in the HKEY_LOCAL_MACHINE \ System \ CurrentControlSet \ services \ DNS key, in the ImagePath change the new binary address% systemroot% \ system32 \ dnsflt \ dns.exe
- Create a symlink from% systemroot% \ system32 \ dnsflt \ dns.exe to% systemroot% \ system32 \ dns.exe
And why the last step? The fact is that in windows there is a built-in firewall, and, by default, in windows server the right to listen to port 53 is only in the% systemroot% \ system32 \ dns.exe application. If you try to start it from another directory, you will not have access rights to the network. And why did I copy it at all? In order to minimize the impact on the entire system and not touch the original dnsapi.dll. It turns out that if you can create symlink to an application, you can get its network rights. By default, only administrators have the right to create symlink, but rather unexpectedly finding that by giving the user the right to create symlink, you give him the opportunity to bypass the built-in firewall.
Once loaded into the process from DllMain, you can create a stream and set the capture. In the simplest case, our dns service will inform the client of the ip-address for the name by sending a UDP packet from port 53 using the sendto function from ws2_32.dll. The standard assumes the possibility of using TCP port 53 if the answer is too large, and it is obvious that intercepting sendto will be useless in this case. However, it is more laborious to handle the tcp case, but in a similar way. While I will tell the simplest case with UDP. So, we know that the code from dns.exe imports the sendto function from ws2_32.dll and will use it to respond to the dns request. To intercept functions, there are also quite a lot of different ways, classic is splicing, when the first sendto instructions are replaced with jmp in their function, and after its completion, the transition to previously sent sendto instructions and further inside the sendto function is performed. Splicing will work even if GetProcAddress is used to call sendto, not an import table, but if you use an import table, then it is easier to use an IAT hook instead of splicing. To do this, find the import table in the downloaded dns.exe image. The table itself has a somewhat confusing structure and you will have to go into the description of the PE format for details.
The main thing is that the system, in the process of loading the image, writes to the import table a pointer to the beginning of the sendto function. This means that in order to intercept the sendto call, you simply need to replace the address of the original sendto in the import table with the address of its function.
So, we set the interception and began to receive data. The prototype of the sendto function looks like this:
int sendto( _In_ SOCKET s, _In_ const char *buf, _In_ int len, _In_ int flags, _In_ const struct sockaddr *to, _In_ int tolen ); If s is a socket on port 53, then according to the buf pointer there will be a dns-answer of len size. The format itself is described in RFC1035 , I will briefly describe what needs to be done to get to the data of interest.
The message structure in the standard is described as:
In the header of the necessary information: message type, error code and the number of elements in the sections. The title itself looks like this:
struct DNS_HEADER { uint16_t id; // identification number uint8_t rd : 1; // recursion desired uint8_t tc : 1; // truncated message uint8_t aa : 1; // authoritive answer uint8_t opcode : 4; // purpose of message uint8_t qr : 1; // query/response flag uint8_t rcode : 4; // response code uint8_t cd : 1; // checking disabled uint8_t ad : 1; // authenticated data uint8_t z : 1; // its z! reserved uint8_t ra : 1; // recursion available uint16_t q_count; // number of question entries uint16_t ans_count; // number of answer entries uint16_t auth_count; // number of authority entries uint16_t add_count; // number of resource entries }; Section Question will have to disassemble in order to get to Answer. The section itself consists of as many blocks as indicated in the header (q_count). Each block consists of the name, type, and class of the request. The name is encoded as a sequence of strings, each of which begins with a byte with the length of the string. At the end is a zero-length string. For example, the name homedomain2008.ru would look like this:
The Answers section looks similar: a block consists of a name, a type, a class, a ttl, and additional data. The IP address will be contained in the add. data. With the analysis of the name there is another difficulty. Apparently, to reduce the size of the message, instead of the label length, you can find a link to another data area. It is encoded as follows: if the 2 high-bits of the length are 11, then the next byte, as well as the lower bits of the length, should be interpreted as an offset in bytes relative to the beginning of the message. Further parsing of the name must be done by clicking on this offset.
So, we intercepted the necessary API, disassembled the dns-answer, now we need to make a decision: to skip this response further or return an error. For each name that is not yet present in the database, it is necessary to check from the answer whether it is “suspicious” or not.
We will consider “suspicious” such names for which the result of the skeleton function from Unicode Technical Standard tr39 matches the result from any of the names from the base, or those names that differ from those present in the base by rearranging the internal letters. To implement the checks we will store 2 tables. The first one will consist of skeleton results for all names from the base, write the rows in the second table, which were obtained from the base lines by removing the first and last characters from each label except the first level, and then sorting the remaining characters of each label. Now, if a new name is included in one of the two tables, then we consider it suspicious.
The meaning of the skeleton function in determining the similarity of two strings, for this, for each string, characters are normalized. For example, Xl– will be converted to Xloe, and thus, comparing the result of a function, you can determine the similarity of unicode strings.
An example of the implementation described above can be found on github .
Obviously, the stated solution in practice cannot provide normal protection, since besides minor technical problems with interception, there is still a big problem with the detection of “similar” names. It would be nice to handle:
- Combinations of permutations and omoglyphs.
- Adding \ replacing characters not considered skeleton.
- UTS tr39 is not limited to skeleton, you can still limit the mixing of character sets in one label.
- Japanese full width point and other label separator.
- As well as such wonderful things as rnicrosoft.com
Source: https://habr.com/ru/post/348428/
All Articles