Big Migration: How we raised a private cloud at RISC
In a previous post, we started a story about our private cloud. In large companies, projects of this scale are legacy and unexpected surprises in the migration process. Today we want to share our experience in the migration of different systems and show a small piece of our infrastructure, densely littered with the “DSP” vultures and all sorts of NDAs.

In a small company, an admin can deploy a server on Gentoo in an exotic configuration, which is more convenient for him to work with. When in the area of responsibility of the business scale of VTB, then every detail is evaluated at numerous meetings by a large number of people. Otherwise, the deployment and operation of new systems can turn into big problems.
RISC systems are widespread in the banking sector, and we are no exception. Some of our services are already running on or being translated to RISC-architecture. At the same time, cloud providers for projects of our scale mainly work with x86. After evaluating all the pros and cons, we decided to do without changing the architecture and not transfer all services to x86, leaving RISC with what worked successfully on RISC before the cloud was introduced. Moreover, part of the x86-services during the project, on the contrary, was transferred to RISC.
')
Why did we decide to do this? Migration in itself is associated with risks that we could not allow. A number of mission-critical systems withstand the necessary parameters of work only at RISC - here the stability of these systems is higher. With comparable configurations of RISC and x86 machines, our ABS and Oracle databases demonstrate great performance at first. Finally, RISC allows you to spend less on maintenance, which is also important for the banking sector. And in general, neither the harsh security department nor the legislation will allow third-party trust in internal business-critical services for migration.
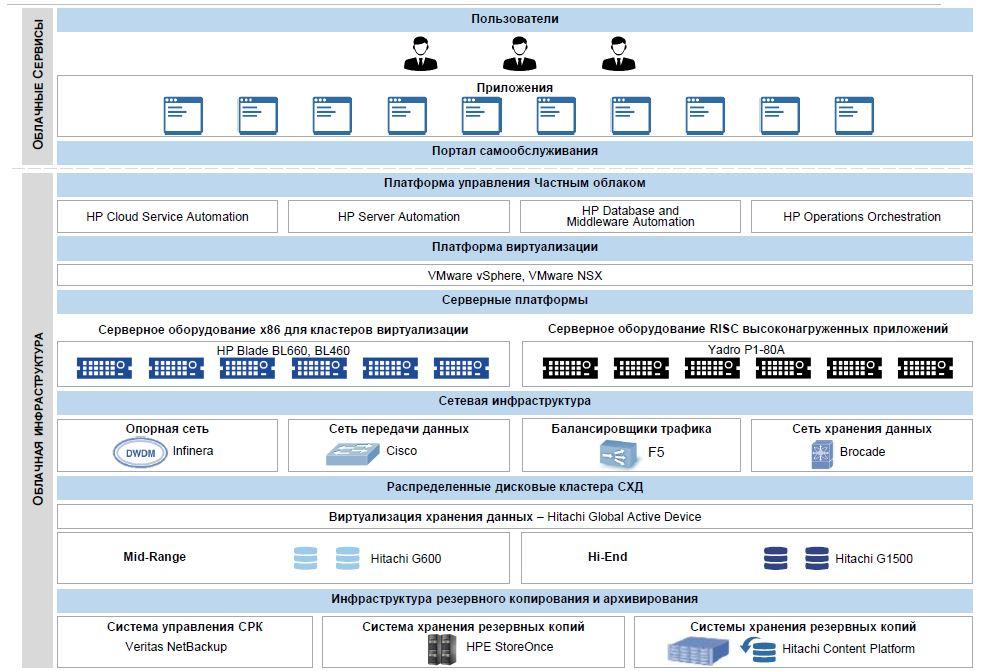
A private cloud is not only capable of taking on existing mission-critical systems, but also has broad functionality in working with RISC-based systems. Previously, the process of deploying a test or industrial system for the tasks described above took many months to plan, purchase, and put equipment into operation. Now, with a few mouse clicks, an engineer can get, for example, a new Veritas Infoscale cluster of two LPAR pairs with resource groups configured for a DR scenario. And there are dozens of such flexible patterns and scripts in the cloud, from allocating a simple virtual or physical server for a specific task to deploying a cluster on the required technology.
Of course, no one refused x86, a huge number of tasks are still being solved on x86 systems. The cloud has a unified self-service portal based on HP technologies and products and is a single entry point for managing both x86 and RISC systems.
The core of the cloud system are the IBM P1-80A servers, the heart of which is the IBM POWER8 processor. IBM uses these servers in its Watson supercomputer. Their key advantage is a large number of cores and support for SMT8, an analogue of Intel Hyper-threading. Services that work well in parallel load feel great on the basis of systems with these CPUs.
Each server has 16 POWER8 processors with a clock frequency of 4.02 GHz, 4 processors per system node. Each processor has 12 cores, giving a total of 192 cores per server. In order to efficiently use processor resources, the physical servers P1-80A are combined in the Power Enterprise Pool, and the Mobile Capacity on Demand (CoD) licensing scheme is also used. Each server has 8 TB of RAM. The built-in disk subsystem is represented by SSD 24x387GB SFF carriers in the expansion shelf. Virtual Partitioning (LPAR) technologies are used to launch and operate applications, and Live Partition Mobility technologies are used to migrate virtual partitions between physical servers.
For us, a big advantage in concluding contracts for implementation and support was that equipment suppliers come from Russia. Our partner is the Russian company Yadro, which actively implements solutions based on RISC architecture and has everything you need to work with our domestic cryptography (which is critical for banks). Yadro is the first OEM-partner of IBM in Russia, which has the necessary certificates for the assembly of computing systems and storage systems based on their decisions.
Deploying a cloud system on RISC was not an easy task - as far as we know, no one did this before us in Russia at this level. The process of moving began in the summer of 2017 and is now in full swing. We carefully planned everything so that the transfer did not affect the work of our services. Work is in full swing: migration has affected more than 60 different IT systems.
We approach everything carefully. We actively use the test pre-environment, once again not experimenting with the transition to x86. In the course of the migration, they switched to newer generations of POWER processors and Oracle DBMS versions, and also began to use arrays with FMD and SSD as external data stores. Abandoned HP UX and SPARC. In general, they reduced the number of vendors and types of equipment, and left the end-of-life platform.
Following the results of an upgrade and migration collected statistics on a number of critical systems. So in the centralized automated banking system (CABS) "New Athena" the time for passing a ruble payment order has decreased. We decompose in stages of a business process:
In addition, for most of the procedures of the settlement system, the speed of execution has increased by 2 times. The average processing time for a single document decreased from 92 to 84 milliseconds.
Finally, the system for servicing legal entities and individuals Mbank also showed significant progress: the processing time of a single branch transaction in Novosibirsk decreased from 464 to 227 milliseconds, in Yekaterinburg - from 179 to 130 milliseconds.
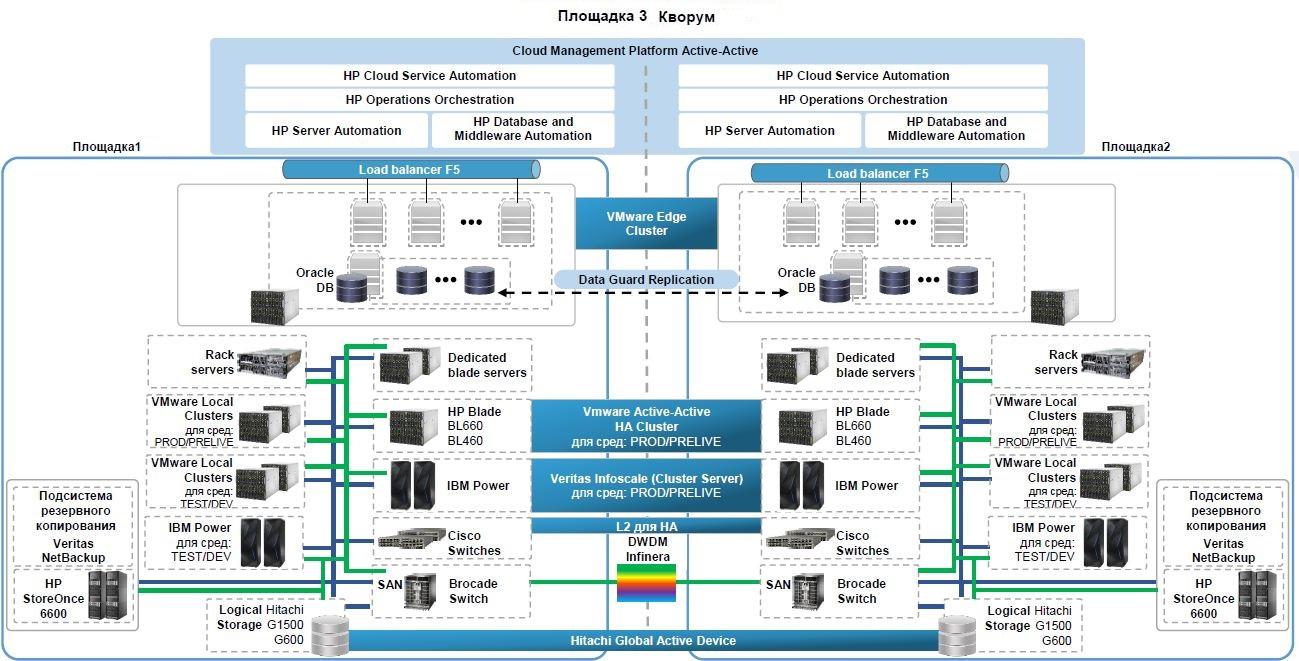
When designing the cloud, resiliency requirements (DR) were taken into account, the cloud was deployed in two geographically dispersed sites. Front-end geobalancing is performed using the BigIP F5 platform. Disaster Recovery at the storage level is implemented through the HDS Global Access Device (GAD) technology, with the cluster arbiter at the third site. Each LUN issued to a host, if necessary, replicates to both sites and has independent paths from arrays located at different sites.
Now the introduction of the cloud is in full swing. As a result of the move, we plan to get an even more reliable system for servicing the tasks of the VTB group, a little extra gray hair from responsible engineers, and quite substantial savings in financial terms. At the same time, the cloud now allows increasing the power of computing systems based on RISC, adds the ability to scale highly loaded and critical systems and facilitates the migration of existing services from a standalone RISC platform to a new, flexible, scalable, fault tolerant.
What x86 did not suit us
In a small company, an admin can deploy a server on Gentoo in an exotic configuration, which is more convenient for him to work with. When in the area of responsibility of the business scale of VTB, then every detail is evaluated at numerous meetings by a large number of people. Otherwise, the deployment and operation of new systems can turn into big problems.
RISC systems are widespread in the banking sector, and we are no exception. Some of our services are already running on or being translated to RISC-architecture. At the same time, cloud providers for projects of our scale mainly work with x86. After evaluating all the pros and cons, we decided to do without changing the architecture and not transfer all services to x86, leaving RISC with what worked successfully on RISC before the cloud was introduced. Moreover, part of the x86-services during the project, on the contrary, was transferred to RISC.
')
Why did we decide to do this? Migration in itself is associated with risks that we could not allow. A number of mission-critical systems withstand the necessary parameters of work only at RISC - here the stability of these systems is higher. With comparable configurations of RISC and x86 machines, our ABS and Oracle databases demonstrate great performance at first. Finally, RISC allows you to spend less on maintenance, which is also important for the banking sector. And in general, neither the harsh security department nor the legislation will allow third-party trust in internal business-critical services for migration.
A private cloud is not only capable of taking on existing mission-critical systems, but also has broad functionality in working with RISC-based systems. Previously, the process of deploying a test or industrial system for the tasks described above took many months to plan, purchase, and put equipment into operation. Now, with a few mouse clicks, an engineer can get, for example, a new Veritas Infoscale cluster of two LPAR pairs with resource groups configured for a DR scenario. And there are dozens of such flexible patterns and scripts in the cloud, from allocating a simple virtual or physical server for a specific task to deploying a cluster on the required technology.
Of course, no one refused x86, a huge number of tasks are still being solved on x86 systems. The cloud has a unified self-service portal based on HP technologies and products and is a single entry point for managing both x86 and RISC systems.
What is common between VTB and IBM Watson?
The core of the cloud system are the IBM P1-80A servers, the heart of which is the IBM POWER8 processor. IBM uses these servers in its Watson supercomputer. Their key advantage is a large number of cores and support for SMT8, an analogue of Intel Hyper-threading. Services that work well in parallel load feel great on the basis of systems with these CPUs.
Each server has 16 POWER8 processors with a clock frequency of 4.02 GHz, 4 processors per system node. Each processor has 12 cores, giving a total of 192 cores per server. In order to efficiently use processor resources, the physical servers P1-80A are combined in the Power Enterprise Pool, and the Mobile Capacity on Demand (CoD) licensing scheme is also used. Each server has 8 TB of RAM. The built-in disk subsystem is represented by SSD 24x387GB SFF carriers in the expansion shelf. Virtual Partitioning (LPAR) technologies are used to launch and operate applications, and Live Partition Mobility technologies are used to migrate virtual partitions between physical servers.
For us, a big advantage in concluding contracts for implementation and support was that equipment suppliers come from Russia. Our partner is the Russian company Yadro, which actively implements solutions based on RISC architecture and has everything you need to work with our domestic cryptography (which is critical for banks). Yadro is the first OEM-partner of IBM in Russia, which has the necessary certificates for the assembly of computing systems and storage systems based on their decisions.
Migration
Deploying a cloud system on RISC was not an easy task - as far as we know, no one did this before us in Russia at this level. The process of moving began in the summer of 2017 and is now in full swing. We carefully planned everything so that the transfer did not affect the work of our services. Work is in full swing: migration has affected more than 60 different IT systems.
We approach everything carefully. We actively use the test pre-environment, once again not experimenting with the transition to x86. In the course of the migration, they switched to newer generations of POWER processors and Oracle DBMS versions, and also began to use arrays with FMD and SSD as external data stores. Abandoned HP UX and SPARC. In general, they reduced the number of vendors and types of equipment, and left the end-of-life platform.
Progress
Following the results of an upgrade and migration collected statistics on a number of critical systems. So in the centralized automated banking system (CABS) "New Athena" the time for passing a ruble payment order has decreased. We decompose in stages of a business process:
- Automatic processing from DBO - from 107 ms to 32 ms;
- Reading - from 88 ms to 20 ms;
- Card file processing - from 158 ms to 31 ms.
In addition, for most of the procedures of the settlement system, the speed of execution has increased by 2 times. The average processing time for a single document decreased from 92 to 84 milliseconds.
Finally, the system for servicing legal entities and individuals Mbank also showed significant progress: the processing time of a single branch transaction in Novosibirsk decreased from 464 to 227 milliseconds, in Yekaterinburg - from 179 to 130 milliseconds.
Fault tolerance and conclusions
When designing the cloud, resiliency requirements (DR) were taken into account, the cloud was deployed in two geographically dispersed sites. Front-end geobalancing is performed using the BigIP F5 platform. Disaster Recovery at the storage level is implemented through the HDS Global Access Device (GAD) technology, with the cluster arbiter at the third site. Each LUN issued to a host, if necessary, replicates to both sites and has independent paths from arrays located at different sites.
Now the introduction of the cloud is in full swing. As a result of the move, we plan to get an even more reliable system for servicing the tasks of the VTB group, a little extra gray hair from responsible engineers, and quite substantial savings in financial terms. At the same time, the cloud now allows increasing the power of computing systems based on RISC, adds the ability to scale highly loaded and critical systems and facilitates the migration of existing services from a standalone RISC platform to a new, flexible, scalable, fault tolerant.
Source: https://habr.com/ru/post/348326/
All Articles