As I prepared a visual novel
Hi, Habr!
The other day I wanted to get the resources of one visual novel created with Ren'Py (Yes, yes, that same "Infinite Summer") . It was experimentally established that all of them are stored in the archive.rpa file. I found ready-made scripts to unpack on Github, but I decided to get them myself, Haskell to help ...
archive.rpa
First, let's look at what exactly we are dealing with, that is, how resources are stored in our “archive”. Open it in dhex or in a similar program:
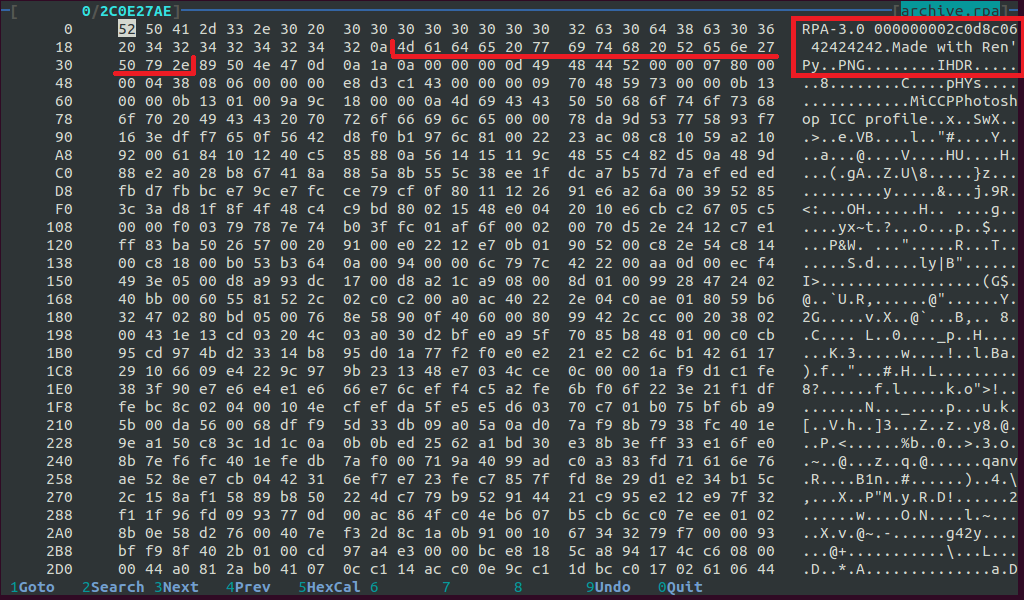
What do we see? First, the data on Ren'Py, then something else, and then the beginning of the PNG file! Here it is!
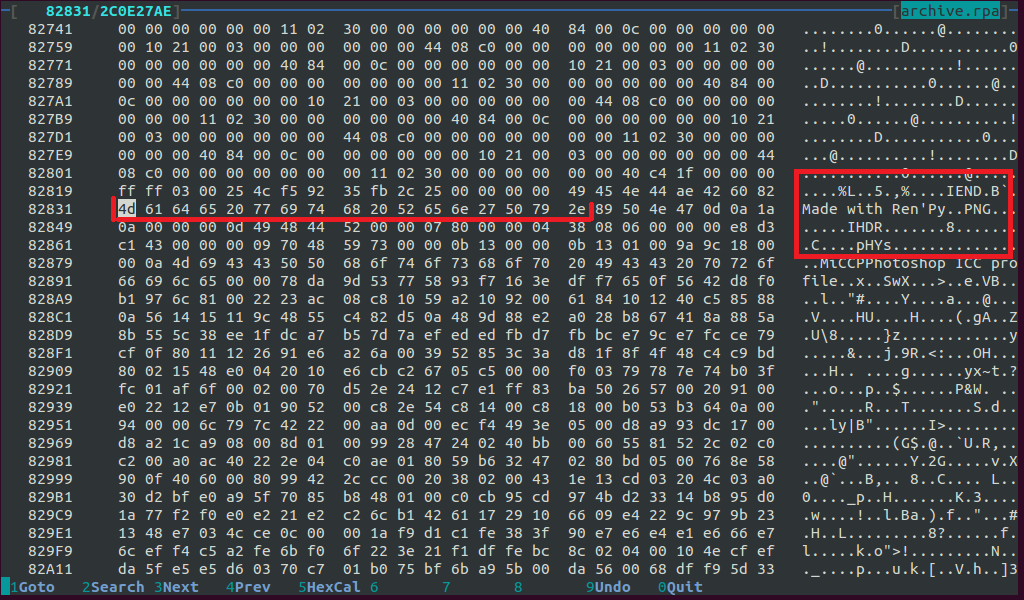
Add to the end of the PNG:
The type of a binary file can be determined by its first bytes (the so-called "magic number"). In PNG, the magic bytes are as follows: 89 50 4e 47 0d 0a 1a 0a. The end of the PNG file is also always the same: 49 45 4e 44 ae 42 60 82
A list of "magic numbers" of other formats can be found here.
Aha PNG is over, after it bytes 4d 61 64 65 20 77 69 74 68 20 52 65 6e 27 50 79 2e (in ASCII: "Made with Ren'Py."), After which - the beginning of a new PNG. Conclusion: resource data in .rpa archives is separated by this sequence of bytes. Time to think about the program.
Write the code
So what exactly should the program do? This:
- Read file
- Split it into resource files
- Write resource files to a user-defined folder.
- Attach an extension to each file.
We break into pieces
Let's start with the file splitting function:
Extractor.hs:
module Extractor where import qualified Data.ByteString.Lazy as B import Data.List.Split extractRes :: B.ByteString -> [B.ByteString] extractRes bs = map B.pack $ splitOn magicSep $ B.unpack bs magicSep = [0x4d, 0x61, 0x64, 0x65, 0x20, 0x77, 0x69, 0x74, 0x68, 0x20, 0x52, 0x65, 0x6e, 0x27, 0x50, 0x79, 0x2e] Here, magicSep is the very "magic" bytes that share resource files. The extractRes function takes a byte string, converts it into a list, breaks it into file byte lists, and each of these lists is converted back into a byte string. One question remains: why did I use a lazy kind of byte strings? We will get an answer soon.
Install the extension
ExtensionId.hs:
module ExtensionId where import qualified Data.ByteString.Lazy as B import Data.List (isPrefixOf) import System.Directory type FileType = String readExtension :: FilePath -> IO (Maybe FileType) readExtension path = B.readFile path >>= (return . getExtension) writeExtension :: FilePath -> Maybe FileType -> IO () writeExtension _ Nothing = return () writeExtension path (Just ext) = renameFile path $ path ++ ext getExtension :: B.ByteString -> Maybe FileType getExtension = magicLookup magicMap magicLookup :: [(B.ByteString, FileType)] -> B.ByteString -> Maybe FileType magicLookup [] _ = Nothing magicLookup ((magic, fileType) : rest) bytes | (B.unpack magic) `isPrefixOf` (B.unpack bytes) = Just fileType | otherwise = magicLookup rest bytes magicMap = [(pngMagic, ".png"), (jpgMagic, ".jpg"), (oggMagic, ".ogg")] pngMagic = B.pack [0x89, 0x50, 0x4e, 0x47] jpgMagic = B.pack [0xff, 0xd8, 0xff] oggMagic = B.pack [0x4f, 0x67, 0x67, 0x53] Here we see two main functions: readExtension and writeExtension . It is easy to guess that one reads the first bytes of the file and on its basis sets the extension, and the second renames the file according to it. The entire dirty job of defining the extension is taken by the magicLookup function, which simply goes through the list of known "magic numbers" and compares them with the beginning of the file. magicMap is a list of matches of bytes and extensions, pngMagic , jpgMagic and oggMagic - the "magic numbers" of file formats. Their list can be expanded by the reader, but I knew for sure that there is nothing in the archive except for these formats.
Ufff ...
Our dear Main.hs remained:
module Main where import qualified Data.ByteString.Lazy as B import System.Environment import System.Directory import System.FilePath import System.IO import ExtensionId import Extractor main :: IO () main = do args <- getArgs if (length args) /= 2 then usage else extractToFolder (args !! 0) (args !! 1) extractToFolder :: FilePath -> FilePath -> IO () extractToFolder input output = do b <- doesFileExist input if b then do b <- doesDirectoryExist output if b then do c <- confirm $ "Folder " ++ output ++ " already exists, overwrite it? (y/n): " if c then do removeDirectoryRecursive output createDirectory output extractToFolder' input output else return () else extractToFolder' input output else putStrLn $ "Input file " ++ input ++ " does not exist" extractToFolder' :: FilePath -> FilePath -> IO () extractToFolder' input output = do bytes <- B.readFile input let bs = extractRes bytes doNastyWork bs 0 where doNastyWork [] _ = putStrLn "Done." doNastyWork (bs : rest) n = do let path = output </> ("extraction_" ++ (show n)) B.writeFile path bs ext <- readExtension path writeExtension path ext putStrLn $ (show $ n + 1) ++ " files processed..." doNastyWork rest (n + 1) confirm :: String -> IO Bool confirm q = do putStr q hFlush stdout line <- getLine case head line of 'y' -> return True 'n' -> return False _ -> confirm q usage :: IO () usage = putStrLn "Usage: extractrpa [ARCHIVE] [OUTPUT FOLDER]" What is it here? The main function simply checks the number of arguments, and if there are two, it delegates the dirty work. (also not very clean) extractToFolder functions, otherwise sends us smoking manual read usage .
In extractToFolder ’s about the same thing: validation of input (fool protection), and if the folder to which it should be output does not exist or the user has agreed to destroy its contents, it turns to extractToFolder' for help extractToFolder'
In other languages, the data processing method is approximately as follows: we read all the data, after which we divide them into parts, after which we write each data to a file and give an extension. Haskell also offers a slightly different approach: process data as it arrives. This is possible thanks to lazy calculations (that's why I used lazy byte strings). This approach allows the user to better see the processing, which is already a good thing. extractToFolder' is a kind of conveyor on which the archive is processed: read the file, break it up into parts, until the parts run out we write them into files with unique names.
Well, that's all, we type in the terminal cherished commands:
$ ghc --make Main.hs -o extractrpa ... $ extractrpa archive.rpa archive ... Done. And enjoy cleverly styrenny artfully mined content!
Questions, complaints, suggestions - please comment!
')
Source: https://habr.com/ru/post/348320/
All Articles