GCCGO versus "standard" implementation

Which Go benchmarks show the best results when compiled by gccgo and why?
Answers to these questions under the cut.
Introduction
Currently there are two of the most mature implementations of the Go programming language:
- gc (5g / 6g / 8g / etc.) is the first, "standard" implementation.
- gccgo is the frontend of the GCC compiler for Go.
Task setting: find such benchmarks from the standard Go distribution that run in less time when compiling gccgo. For each significant deviation find the causes of the observed effect.
The previous similar comparison was made in 2013:
benchmarking Go 1.2rc5 vs gccgo .
Missing technical details that may be important for reproducing and validating results can be found in the github repository .
What and how was measured
Since gccgo is lagging behind releases from gc, Go 1.8.1 (GCC 7.2) was used.
Many Benchmark* functions from the standard library packages, as well as all tests from $GOROOT/test/bench/go1 .
The full list is listed in packages.txt .
For GCC, the flags used are " -O3 -march=native ".
Results are available for Intel Core and Intel Xeon .
AVX2 and FMA were available on both machines.
More information about test machines can be found in the / stats section.
Benchstat was used to identify statistically significant deviations.
An additional test was a comparison with the Go tip version (1.10).
Some of the discrepancies in Go 1.10 are corrected, but some of the advantages of gccgo may persist forever due to the special approach of gc, in which compile time is an important indicator.
The big picture: all results in a single diagram
Before building a general diagram, the following actions were performed:
- Removed anomalies such as zero runtime (explanation below).
- Removed benchmarks with the same execution time (
gccgo.time=gc.time). - The runtime difference is smoothed using logarithms.
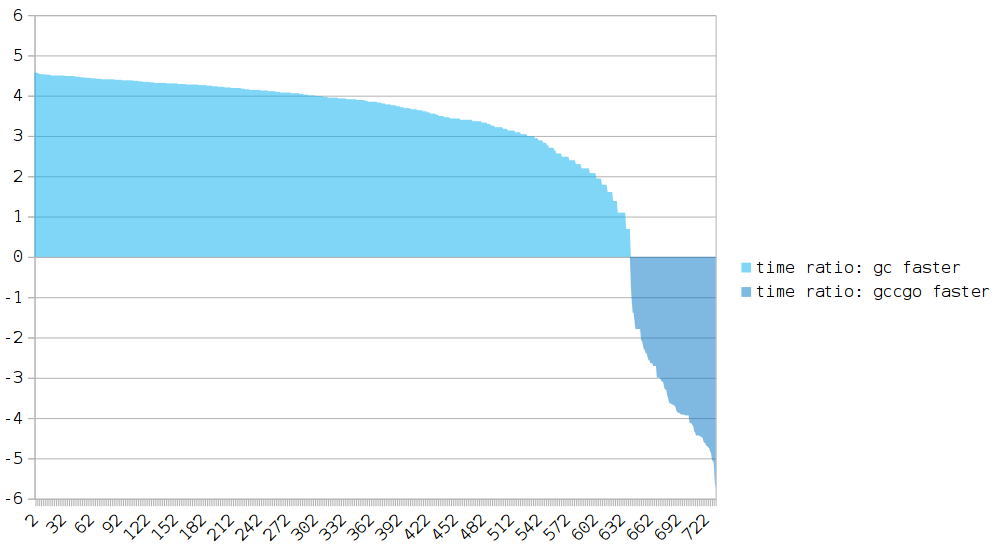
Axis X: benchmarks.
Y axis: the ratio of the gccgo runtime to gc.
If the value of Y is above 0, the program compiled by gccgo runs slower.
Most tests have significantly better results on gc.
The main advantage over gccgo is escape analysis .
There are also deviations in favor of the gccgo (118/808 tests).
Narrowing the search area
Any slight discrepancy in performance is inevitable in any case, so instead of examining all 118 cases, we will filter:
- First remove all the results in which the delta is less than ~ 10%.
- For the remaining tests we will compare with Go 1.10.
We remove those that in Go 1.10 caught up (or overtook) gccgo. - All that remains is considered in more detail.
The first two points led to intermediate tables that can be viewed.
in the section / human-readable .
=> ~62 . => ~39 1.10. => ~26 . All 118 tests were investigated.
Some of them didn’t look stable enough.
For some of the results, I did not find a clear explanation.
Because of this, for the final format, it was decided to perform the filtering described above.
In the repository, to which the link was repeatedly cited, you can find the "raw" data
according to which anyone can make an analysis in the way he considers more correct.
The most interesting results
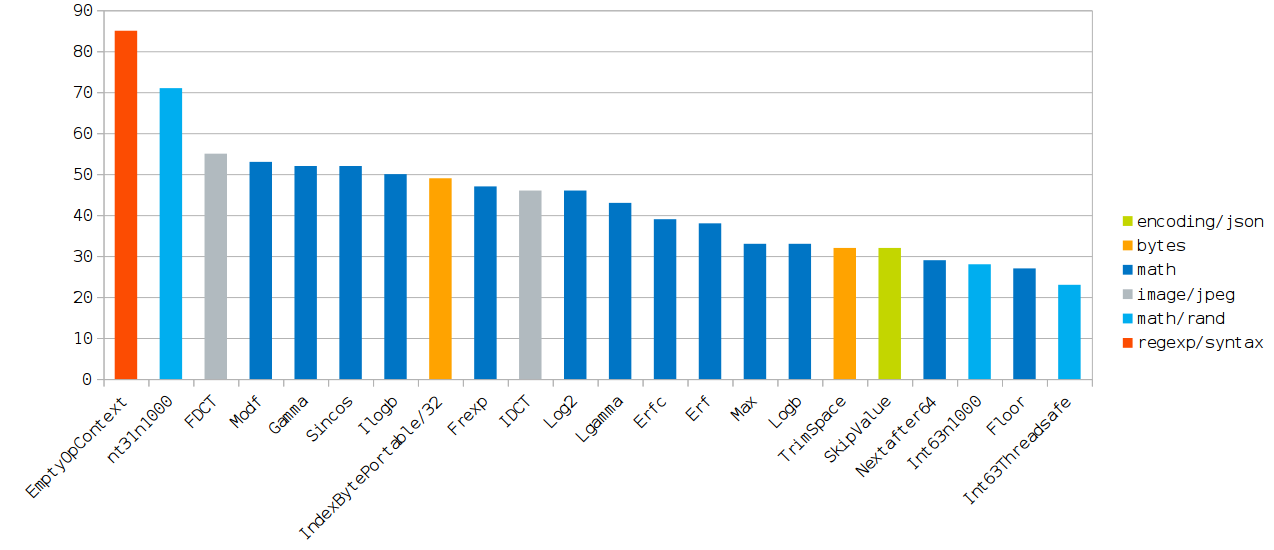
(The diagram is clickable.)
In the table below, each of the tests is assigned one or more of the most significant reasons, which lead to the acceleration observed above in comparison with gc.
If they are eliminated, then the performance becomes almost identical.
Almost all the reasons are in the form of GCC optimization flags.
These flags were found by selecting (enabling / disabling) the minimum set of optimization flags that would reduce the performance gap.
A description of the GCC optimization flags can be found here .
| Title | The most significant reasons |
|---|---|
EmptyOpContext | Unused call result [1] |
Int31n1000 | Unused call result; -finline-functions |
FDCT | -ftree-loop-vectorize |
Modf | -mavx |
Gamma | -mfma |
Sincos | -mfma |
Ilogb | -mfma |
IndexBytePortable/32 | Slowing on short cycles [2] |
Frexp | Unused call result; -finline-functions |
IDCT | -ftree-loop-vectorize |
Log2 | -mfma (depends on Frexp ) |
Lgamma | -mfma |
Erfc | -mfma |
Erf | -mfma |
Max | -mfma ; -finline-functions |
Logb | -mavx |
TrimSpace | -finline-functions |
SkipValue | -msse4.1 |
Nextafter64 | -finline-functions ; -ftree-loop-vectorize |
Int63n1000 | -finline-functions |
Floor | -mavx ( -mavx instruction) |
Int63Threadsafe | -finline-functions |
[1] The benchmark tests the performance of the function, ignoring
return result. Sometimes this leads to the removal of the call by the optimizer.
[2] It is for the test with n=32 that this slowdown occurs.
It was not possible to reproduce this result in a free context.
The rest of the article deals with the most significant optimizations that led to the observed results. Also touched on the topic is not quite correct benchmarks, which do not work for gccgo, but still work for gc.
gccgo = better inlining
By default, Go 1.10 can embed only leaf functions. Leaf functions are functions that do not contain calls to other functions. Exceptions are other leaf functions, if the "embedding budget" of the containing function is not exceeded by embedding its body.
Simplified, here are the restrictions for inline functions:
- Total (after all embeddings) does not exceed a certain threshold of complexity.
- Does not contain prohibited items. golang # 14768 - for-loops cannot be inlined .
- Sheet is. golang # 19348 - enable mid-stack inlining .
The calculation of the "price function" occurs before optimizations.
This often leads to the fact that if it matters to you whether a function is embedded or not, you will have to change the structure of the code to be semantically equivalent, but at a lower price, without taking into account optimizations.
Moreover, the current model has a flaw: cascaded embedded calls increase the total cost of the function. This makes inline wrapper functions not so free from the inliner's point of view.
You can check whether a function is embedded or not using special compiler flags. On the effect of gcflags="-l=4" read closer to the conclusion.
gccgo = better constant folding
How often have you seen similar benchmarks on Go?
func foo(i int) int { /* . , "". */ } func BenchmarkFoo(b *testing.B) { for i := 0; i < bN; i++ { foo(50) // foo } } Notice the comment to the line calling foo(50) .
The optimizer can remove both the call itself and the entire cycle inside the BenchmarkFoo .
For gccgo, this is the right way to get benchmarks that run 0 nanoseconds:
// YCbCrToRGB/(0|128|255) YCbCrToRGB/*. // gc.time gccgo.time delta YCbCrToRGB/* 12.1ns ± 0% 0.0ns -100.00% (p=0.008 n=5+5) RGBToYCbCr/* 12.8ns ± 0% 0.0ns -100.00% (p=0.008 n=5+5) YCbCrToRGBA/* 13.8ns ± 0% 0.7ns ± 0% -94.78% (p=0.000 n=5+4) NYCbCrAToRGBA/* 18.5ns ± 0% 1.0ns ± 6% -94.72% (p=0.008 n=5+5) The following is a fairly common idiom:
var sink int func BenchmarkBar(b *testing.B) { for i := 0; i < bN; i++ { sink = bar(50) } } She has two problems:
- Constant function argument
- The assumption that the assignment of a global (non-exported) variable magically cancels unwanted optimizations.
Both of these problems are also found in the benchmarks of the standard Go library.
gccgo can embed the values of global variables that in its opinion do not change in the program. In gc (at least for now) only constants and local data are subject to this optimization.
When the sink value is not used anywhere, it will not matter whether this variable changes or not. Like unused exportable functions, gccgo deletes variables that no one “reads”.
If the function call is embedded (and this happens more often in gccgo), then there is a risk of a complete calculation of the loop body (potentially along with the loop itself) at the compilation stage.
In real-world applications, it is not often possible to “collapse” entire cycles at the compilation stage, but some Go benchmarks fall under this optimization.
In them we get a magical acceleration of 100%.
gccgo = better machine-dependent optimizations
The gc compiler does not generate instructions from extensions after SSE2 .
This makes binaries under x64 more portable, but potentially less optimal.
With flags such as -march=native , gccgo can generate
more efficient code for a specific machine on which you plan to run the application.
We can also attribute vectorization to machine-specific optimizations, since its efficiency is rather limited without access to AVX extensions.
In the current version of gc, there is no vectoring per se, unless you consider combining several movements into one (up to 16 bytes, using SSE).
Due to the fact that Go has no traditional intrinsic functions, it is necessary to write assembler implementations to achieve maximum acceleration.
Go 1.10 assembler supports most of the instructions available on modern x86_64.
There is a chance that you can use AVX512 in Go 1.11 ( golang # 22779 - AVX512 design ).
| Assembler functions are not built in, which sometimes puts an end to productivity, unless you implement the entire algorithm in assembly language. |
gccgo = better calling convention
For both GOARCH=386 and for GOARCH=amd64 gc uses a stack to pass arguments and return the results of functions. In the 64-bit mode, more registers are available, so using the stack for this purpose is not optimal.
There is some discussion of the register-based calling convention .
It is not easy to judge the potential performance gains at this stage, because now the optimizer does not perform some transformations that are beneficial only for reg->reg displacements. Nowadays, mem->reg->mem movements are much more characteristic.
5-10%, discussed in the discussion above, may well turn into 15-30% for individual functions.
| One of the main drawbacks of the new calling convention is the inability of all existing assembly code, which is abound even inside Go. |
Include mid-stack inlining
Evaluate the effect of -gcflags="-l=4" on those benchmarks, where gccgo showed the best results by using more opportunities for embedding functions.
Ratio is calculated as gccgo.time/gc.time .
| Title | Ratio to | Ratio after |
|---|---|---|
math/rand/Int31n1000 | 0.77 | 1.00 (+0.23) |
math/rand/Int63n1000 | 0.82 | 0.93 (+0.11) |
math/rand/Int63Threadsafe | 0.80 | 1.00 (+0.20) |
math/Frexp | 0.84 | 0.84 (=) |
math/Max | 0.73 | 0.73 (=) |
math/Nextafter64 | 0.61 | 0.81 (+0.20) |
bytes/TrimSpace | 0.70 | 0.80 (+0.10) |
( Note : these tests were run with a different configuration, as a separate experiment.)
Opinion Russ Cox on the use of -l=4 in Go 1.9 / 1.10:
-l = 4 is explicitly untested and unsupported for production use.
If you’re doing that, you’ll get programs that get you to keep both pieces.
Link to the message
Conclusion
Making the right performance measurements for gccgo is more difficult than for gc.
It feels like you are implementing benchmarks for C ++ rather than Go (similar "problems").
For some specific tasks, gccgo can give some performance boost.
For example, mathematical calculations with the inclusion of the correct GCC optimization flags receive a measurable acceleration, but the rest of the application will be hit.
Considering the features of the most typical programs on Go, the more important part of the application is likely to slow down (an exception may be simple command line utilities).
Like all performance measures, this study should be evaluated in the context of the specific versions that were used in the comparison.
A significant step forward for gccgo would be high-quality escape analysis.
For gc from the upcoming revolutions, we can name the above-mentioned new convention of challenges and full integration of functions.
')
Source: https://habr.com/ru/post/348230/
All Articles