Software sound synthesis on early personal computers. Part 2
This is an article about the first software synthesizers that were once created on the most common personal computers. I give some practical examples on the implementation of simple methods of sound synthesis in a historical context.
Go to the first part

')
My first personal computer was the clone ZX Spectrum 48K. In this model, there was no “musical coprocessor” and the sound capabilities were limited by the built-in speaker, which could be controlled by outputting zeros or ones to a special one-bit port. The guide to the ZX-BASIC, there was only one team to work with the sound - BEEP, which was required to set the pitch and duration. This was enough for simple monophonic melodies in the spirit of the once popular electronic musical cards.
However, as I quickly caught, the quality of the computer sound outputted through the speaker depended heavily on the talent of the programmer. This was especially noticeable in the games: in many of them the sound was primitive, but there were also surprisingly good-sounding musical things. The highest quality works were reproduced during static screensavers. The loudspeaker volume at the same time was felt below normal (so much so that sometimes you had to put your ear to the keyboard in order to catch the nuances of the composition). Often, you could hear the whistle and distortion, as if a bad recording. But, with all this, it was clearly possible to distinguish several simultaneously sounding voices, there was a change of timbres, work with an amplitude envelope, spatial effects, the sound of drums. By the ZX Spectrum, I'll be back after some retreat.
An example of one-bit synthesis for the ZX Spectrum, by Tim Follin
One-bit music is the oldest among other computer music. Back in the early 50s, melodies were played on the first computers in Australia and England. Of course, in those days, the creators of computers did not think about any tasks from the field of music. The speaker was intended solely for the purpose of debugging and diagnosing the operation of a computer. However, in their free time and spending a lot of energy on it, hackers of the early 50s forced their computers to play simple melodies. In the arsenal of the then computer musicians there were only two levels of signal supplied to the speaker.
The appearance of the speaker on one of the first microcomputers, the Apple II, was due to Steve Wozniak’s desire to port Breakout to his computer. There were sounds in the original Atari slot machine, so Wozniak added a speaker to the Apple II. A serious problem for a programmer when working with a speaker was the need to combine audio output with other tasks. For the correct formation of the meander, it was necessary to carefully check the processor cycles. In this respect, the situation was somewhat simpler in the IBM PC, since the task of generating the meander could be assigned to a separate timer chip. But even this microcircuit didn’t help too much in using pulse-width modulation (PWM, PWM) - a way to output multi-bit audio data to a speaker.
Outputting multi-bit sound to a speaker using PWM consists of transmitting audio data using a rectangular carrier signal, the pulse width of which is modulated (controlled) by amplitude level values. When the next amplitude value is received, the computer spends additional time generating a carrier with a fixed period, which depends on the desired sound capacity. In the case of PWM for the presence of only two levels of quantization of the signal, one has to pay with a significantly increased resolution in the time domain when transmitting data. Not surprisingly, the most effective PWM was used not on microcomputers, but on PCs. The reasons are associated with both speed and memory, because with the help of PWM, digitized music was most often reproduced. This kind of music was especially nice in the PC games of the second half of the 80s from the French company Loriciel .
To complete the PC theme, I will mention one common approach to imitating polyphonic sound for a speaker. In most cases, at the gameplay stage, it was too expensive to output multi-bit sound using PWM. Instead, the voices being played out simply alternated with a predetermined time interval. The shorter the period of alternation, the more high-quality “polyphonic” sound can be obtained, but this will require more activity from the processor. It is curious that this kind of reception has long been known in classical music under the name of hidden polyphony and was used, for example, in Bach suites for cello solo. The sensation of polyphony by a listener with hidden polyphony is, to a greater extent, a psychoacoustic effect. The phenomenon of a similar kind arises in one-bit music and during the performance of drum sounds. All other voices simply fall silent while the real mixing of channels is not used, but the listener's brain automatically completes the sound that does not exist at the moment.
An example of one-bit synthesis for the ZX Spectrum, by Jonathan Smith and Keith Tinman
Let's return finally to the ZX Spectrum. The one-bit music of the second half of the 80s for this microcomputer was distinguished by a special originality. The ZX Spectrum, of course, did not have PC capabilities to effectively support the sound output approaches mentioned above. But at the same time, the popularity of Speccy has stimulated the interest of developers to search for non-trivial methods of playing sound using the speaker.
The simplest single-bit synthesis by the mid-80s was well known to the developers of the ZX Spectrum. Typical sound effects can be found in many games of the time. When generating a rectangular signal (by sequentially sending zeros and ones to the speaker port), it is possible to control the following parameters: frequency, phase of the signal and pulse width. As a result, by modulating the frequency according to some law, one can obtain a kind of FM synthesis, which was discussed in one of the previous sections. In addition, using regular phase reset, it is easy to get the characteristic hard sync sound (it was already discussed in the SAM section). Finally, PWM-based effects are achievable. Here it is important to distinguish the PWM approach to output multi-bit sound, where the carrier frequency can be megahertz, from the PWM affecting the timbre, in the spirit of the sound of the famous SID (Commodore C64) and 2A03 (NES) sound chips. By controlling the above parameters you can get a fairly wide palette of interesting timbres. The only drawback - it all works in single-voice mode.
One of the first on the ZX Spectrum multichannel single-bit synthesis began to apply Tim Follin (Tim Follin). The young musician and programmer from England (at the time of creating his famous single-bit synthesizers he was 15-16 years old) used 2-3 channels for his first compositions for games, but by 1987 his music consisted of more than 5 channels using several timbres, amplitude envelopes, spatial effects and percussion.
Instead of a meander, whose pulse width is half the period, Follin used a waveform with a very narrow pulse width. The result was a characteristic “needle” timbre, vaguely reminiscent of the sound of reed instruments, such as the harmonica. At the same time, in given narrow limits, the pulse width could be adjusted, which reflected on the volume, and, additionally, on the timbre. Mixing multiple virtual channels Follin implemented using serial output values to the port in the spirit of hidden polyphony, but at a much higher frequency than in the case of a PC.
On this basis, the composer created more complex elements, such as amplitude envelopes, flanger effects and echoes. The uniqueness of the compositions of Follin is due to the fact that their author was at that time not only a talented musician with an excellent taste, but also a good programmer, who independently realized his single-bit synthesizers.
By the way, some microcomputers of the 80s, which include sound chips, also used elements of software synthesis. For a greater variety of timbres, resourceful musicians used a number of tricks related to the modulation of sound chip parameters. For example, on the Commodore C64, complex voices were assembled from several basic waveforms by quickly switching them, and on the Atari ST, the simulated PWM sound in the spirit of the SID chip was implemented by controlling one of the hardware channels of the YM2149F chip using a timer interrupt.
Over time, pulse-width modulation, which is used in high-quality audio systems, has replaced the PWM as a method for outputting multi-bit data. But where is classic one-bit sound used today? Apparently, the theme of synthesis for the dynamics was inexhaustible, since the enthusiasts of ZX Spectrum and today continue to improve their engines with the number of channels, which has already exceeded a dozen. In the academic field, scientific articles are written about the aesthetics of one-bit music , and even single-bit generators are used in chamber music concerts.
Let's take a look at Tim Follin’s music program, published in the August 1987 issue of Your Sinclair. The article, entitled Star Tip 2, says only that the above code uses 3 channels of sound.

Star Tip 2 from Your Sinclair
Fortunately, the result of disassembling a HEX dump printed in a magazine can be found on the Internet . It can be seen that the program consists of a small player, followed by a number of frames of musical data.
How does the synthesis of Star Tip 2? Each voice is determined by the period and width of the pulse. Instead of real mixing, voices are output to the speaker sequentially. There are 16 possible pulse widths. This parameter is set at once for all 3 voices being output and corresponds to the overall volume felt at the moment. The rest of the code for frame execution is related to the organization of the “amplitude” envelope, which dynamically controls the common for the voices parameter of the pulse width.
The synthesis is organized in such a way that after the sequential processing of the vote counters and the possible output of data to the speaker, some more ticks are used to organize the envelopes. Moreover, after the completion of the playback of the next frame, a certain number of cycles is spent on reading the parameters of the next frame. All these delays do not have such a destructive effect on sound as one would expect.
When modeling Star Tip 2 on Python, there is a problem with the sampling rate. 44100 Hz is not enough for organizing the withdrawal of votes, taking into account the necessary control of the width of narrow pulses. The best option would be to execute the player code at the frequency of the Z80 processor (3.5 MHz) with a further decrease in the frequency of the result to 44100 Hz. Oversampling, or, more specifically, lowering the sampling rate (decimation or decimation) must be done carefully, with preliminary removal of frequencies that lie outside the target range, rather than simply discarding unnecessary samples. A simple implementation of the filter for decimation is to use a moving average (see the decimate function). Please note that in the code below, I use a decimation factor of only 32 to speed up the program. The constants T1 and T2 were chosen by ear and given the known length of the melody.

A fragment of the composition Star Tip 2, on an enlarged scale, is represented by a “needle” waveform
Source
Frames
Sound
Unusual sound at 26 seconds in a wav file is created using the flanger effect, by introducing a very short delay between identical voices.
Resampling algorithms are widely used in implementations of modern software synthesizers. In particular, the use of such algorithms is another, in addition to FM-synthesis with feedback already known to us, a way to combat the phenomenon of frequency overlap when reproducing waveforms. In addition, as this example shows, it is difficult to dispense with such algorithms when modeling the sound of old sound chips (AY-3-8910, SID, etc.).
In 1985, the Commodore Amiga 1000 personal computer was born, in which a special Paula chip was used to work with sound. Paula's capabilities were strikingly different from typical sound chips used in home computers of the time. The Amiga had 4 hardware audio channels with a bit width of 8 bits each and a sample rate tuned for each channel up to 28.8 kHz (without additional tweaks). Similar characteristics were possessed by the Sampler of the early 80s, popular among musicians, the E-MU Emulator. From the point of view of the programmer, the organization of multichannel audio output in this computer was practically without the participation of the central processor.
Although Amiga was positioned as a computer for creative people, it was still defeated in a fight with the Atari ST for the attention of professional musicians. Atari ST had built-in MIDI support, but the Amiga didn't have it. Moreover, on the first Amiga there were certain problems with the use of a serial port for connecting via MIDI. As a result, Amiga has become an excellent system for computer amateur musicians who have written the necessary programs for themselves - music trackers with their peculiar notation of musical events and samples as instruments.
Software synthesizers for Amiga were rare, which is explainable, including the lack of processor speed. However, Amiga software synthesis existed, for example, in the form of FM synthesizers (FMsynth). The very first implementation of Amiga software synthesis was the MusiCraft application, which was used by Commodore to demonstrate the capabilities of the new computer. In 1986, MusiCraft was sold to Aegis and, after some modifications, entered the market under the name Sonix.
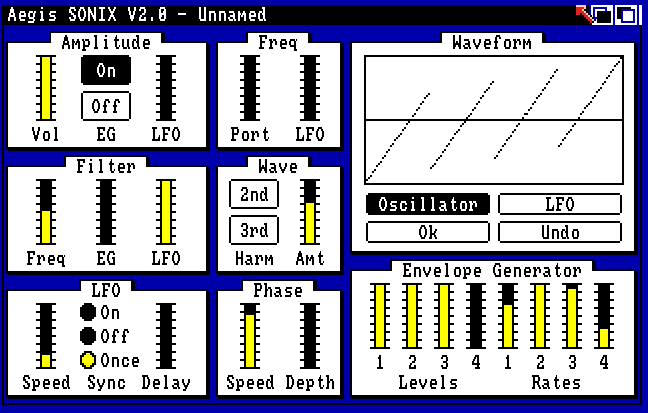
Sonix Parameters Window
Sonix is a real-time analog synthesizer model with polyphony with up to 4 voices. The capabilities of this old-fashioned software synthesizer are not so different from modern VSTi-plug-ins: there is an oscillator with a choice of waveform, a filter with adjustable cutoff frequency (but no resonance), ADSR envelope, LFO (low frequency signal generator). The waveform for the oscillator and the LFO can be drawn with the mouse. Sonix used an ingenious solution to imitate the sound of a resonance: by pressing the screen button, the image of a waveform is simply replaced by several of its repetitions within the same period, which leads to a characteristic sound. Also available is a flanger effect with customizable parameters. Although the capabilities of Sonix seem quite modest by the present time, the synthesizer is distinguished by a rather wide palette of sounds. The only, somewhat strange today seems to be the decision of the developers to use the classical stave to write music in Sonix.
Now let's try to create, in the spirit of Sonix, a model of an oscillator and an analog synthesizer filter. As an oscillator, a sawtooth generator will be used. To get rid of the clearly audible manifestations of the effect of frequency overlap, we use FM-synthesis with feedback. It is interesting to note that by controlling the feedback level you can immediately get some effect of the low-pass filter, but this will work only for a specific oscillator, and not for any input signal.
As in the case of Sonix, our task will be to create a low-pass filter without controlling the resonance. Note the implementation of the low-order filter 1 order (see the definition of class Lp1 in the code below). Although such a filter does not have a high frequency slope, it only requires one multiplication and can be used, for example, to smooth the values of control parameters. In addition, this filter can be used as a building block for building more complex filters in cascade form. In particular, the famous Muga filter contains 4 series 1 order connected low-pass filters. Such a cascade scheme is implemented in this example.
The additional oscillator lfo1 (sine wave generator) is used to automate the control of the cutoff frequency of the filter. For the demonstration, I took the famous note sequence from On the Run by Pink Floyd.
Source
Sound
Modeling filters analog synthesizers - an extensive topic on which we can recommend a good modern book The Art of VA Filter Design . The author of this book, Vadim Zavalishin, in the late 90s created the software synthesizer Sync Modular and, further, became one of the key developers of the famous synthesizer NI Reaktor. The Core technology developed by Zavalishin relates to the very blocks and wires, an example of which was described in one of the previous sections. In the case of Core, graphs are translated into efficient machine code every time their structure changes and this happens right in the process of working with a synthesizer.
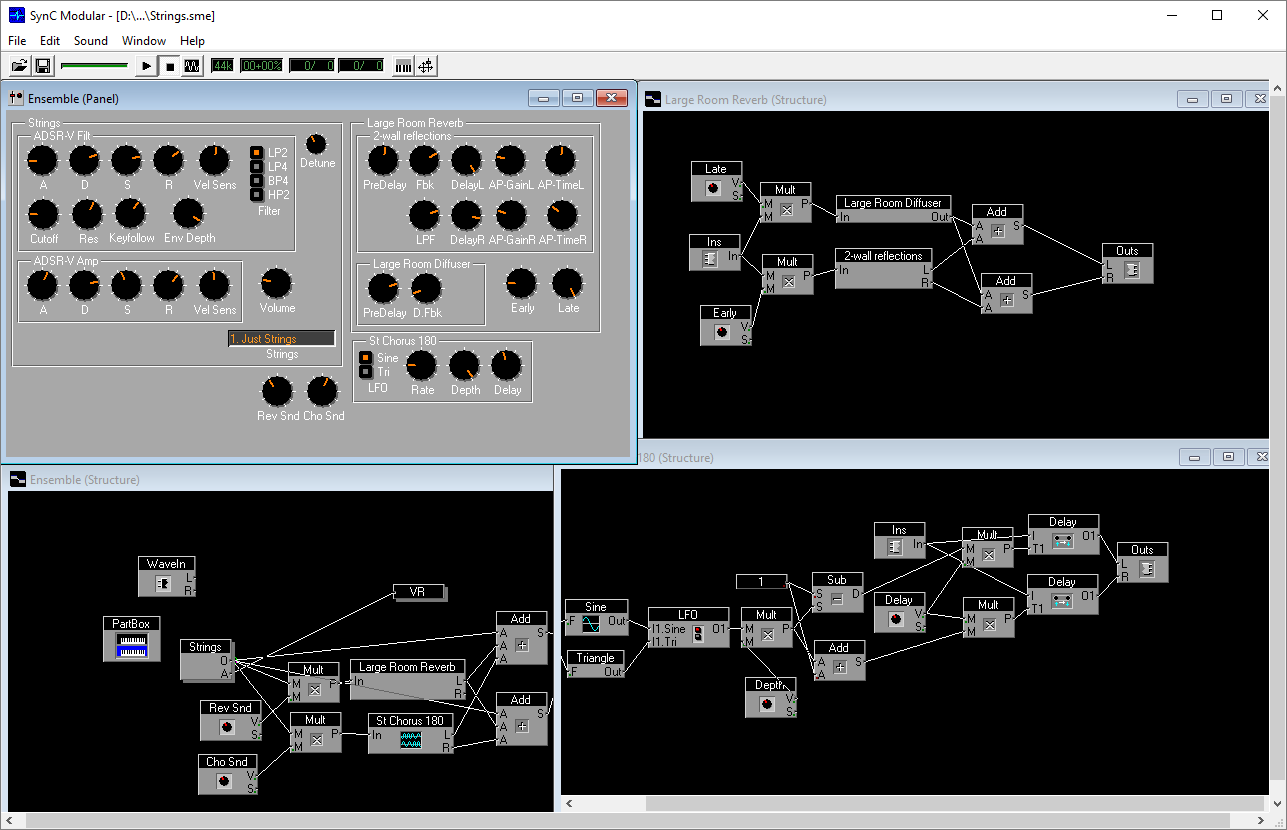
Sync Modular Interface
1988 year. An unusual duet is playing on the stage of the concert hall. It consists of a professional violinist and a computer that generates the sound of strings in real time using synthesis based on physical modeling. In this way, Steve Jobs decided to complete the presentation of his new brainchild - the NeXT personal computer. Jobs did everything in his power to ensure that the sound capabilities of the new computer were unrivaled among competitors. NeXT's sophisticated sound synthesis was performed using a main 32-bit processor, a math coprocessor, and a dedicated DSP processor dedicated to audio-related tasks. Audio output to the NeXT was carried out in stereo, 44100 Hz, 16 bit.
Jobs understood that in order to fully use the powerful hardware, he would need a team of computer sound professionals. For this reason, he turned to Julius Smith, one of the best experts in the field of musical digital signal processing from Stanford University.
Smith and another Stanford native, David Jaffe, created the Music Kit for NeXT. This system combined the MIDI approach to working with note events with the approach of describing sound modules and connections between them from the MUSIC N. The Music Kit took control of the DSP processor, distributed resources and provided the developer with a high-level interface as a set of objects that could be used in creating final GUI applications related to sound.
As part of the Music Kit, various types of sound synthesis were implemented. The variant, which was presented at the 1988 presentation, is based on the Karplus-Strong algorithm (Karplus-Strong). This is a surprisingly simple algorithm, invented in the late 70s, which allows you to simulate the sound of damped string vibrations. In the original version, this algorithm uses a cyclic buffer (delay line), the length of which corresponds to the oscillation period of the simulated string. To create initial conditions for damped oscillations, random values are placed in the buffer. Further, sequential reading from the buffer is accompanied by averaging of the next pair of neighboring samples, that is, filtering, which can be implemented without multiplication operations. Carplus-Strong Smith developed the approach to synthesis based on digital waveguides (digital waveguide), which is now a general approach to the physical modeling of various acoustic instruments. This technology was used by Yamaha and Korg in their synthesizers based on physical modeling.
Applications for the Music Kit, as well as the NeXT computer itself, were known mainly in the university environment. Among the developments there are several visual musical programming environments (SynthEdit, SynthBuilder), as well as a singing voice synthesizer (SPASM). In addition, using the Music Kit, physical models of a wide variety of acoustic instruments were created.
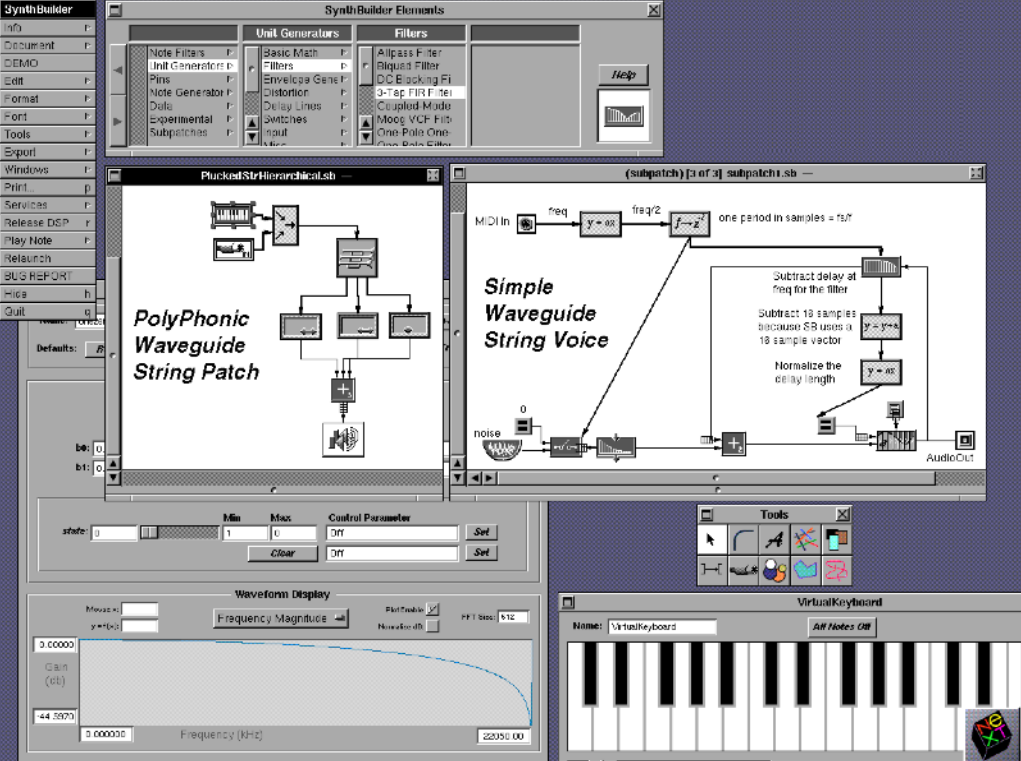
SynthBuilder based on the Music Kit
Since the beginning of the 90s, the Music Kit system has evolved within the walls of Stanford University, and Steve Jobs made a respectable decision to open its code . There was a version of the Music Kit for PC, but, unfortunately, it did not receive distribution.
In this example, we consider the implementation of a simple model of acoustic bass guitar by the Karplus-Strong method. The model will consist of the following elements: noise generator, delay line, low-pass filter. The key element is the delay line, which simulates the vibration of the string. At the moment of the next “hit on the string”, the values from the noise generator fall into the buffer of the delay line and the number of these values depends on the strength of the “hit”. Random values create a more natural sound effect, when each hit on the string is slightly different from the previous one. The buffer length of the delay line corresponds to the oscillation period and the reading of the next sample of the result occurs on an index that moves within the size of the buffer. To create the effect of string oscillations, in which high harmonics decay faster than low harmonics, a low-pass filter is used, which is applied to the value at the current index in the buffer of the delay line.
In the original version of the algorithm, the low-pass filter is a simple averaging of the values of two samples, which can be implemented without a multiplication operation, but with this implementation an undesirable effect is manifested: high notes fade out too fast, and low notes, respectively, too slowly. The code below uses a low-pass filter of the first order, implemented in the previous section. This filter, using the appropriate parameter, allows you to set for a particular note the desired value of the cutoff frequency.
Source
Sound
It remains to add that as a demonstration of the sound, I chose the bass riff from the composition of Chameleon Herbie Hancock.
In the 90s, software synthesizers for PC and Mac experienced rapid development. Among the most unusual programs we can mention MetaSynth, with the help of which, in the spirit of the Soviet synthesizer “ANS” E.A. Murzin, it was possible to generate sound based on the image. One of the MetaSynth users was the famous electronic musician Efex Twin (Aphex Twin). In 1999, Steinberg released the second version of its VST audio plug-in format, which supported the input MIDI data. So there were so popular today VST synthesizers.
In recent years, basic research on sound synthesis has focused on the detailed modeling of the elements of analog synthesizers. Synthesis based on the physical modeling of acoustic instruments and more exotic approaches to the creation of timbres turned out to be not much in demand by musicians. I think that at the moment most musicians simply do not have artistic tasks that require the use of complex and abstract sound synthesis schemes.
However, sophisticated sound design is still in demand in the movies. One of the historical and inspiring examples of computer sound design is the Deep Note composition, created by James A. Moorer from Stanford University. This short composition was played in American cinemas every time the THX technology logo appeared on the screen. Creating DeepNote required from its author knowledge in the field of musical programming. This kind of composition, where typical musical elements are practically not used, is difficult to compose in modern editors designed for an established user work process. Another example from the field of cinema is Kyma’s visual music programming system., which in our time is used in the sound of Hollywood films.
Optimism is also a recent (2010) out of a serious textbook Andy Farnell (Andy Farnell) Designing the Sound . This book is completely devoted to computer sound synthesis with examples on the Pure Data visual audio language.
Finally, complex algorithmic sound design schemes can be used in computer games. In particular, this concerns the modeling of natural phenomena or the sounds of various mechanisms, engine noise. Corresponding sound synthesis methods have been used in games for some time, and it is hoped to be used more widely in the future.
Go to the first part
')
Single bit synthesis
My first personal computer was the clone ZX Spectrum 48K. In this model, there was no “musical coprocessor” and the sound capabilities were limited by the built-in speaker, which could be controlled by outputting zeros or ones to a special one-bit port. The guide to the ZX-BASIC, there was only one team to work with the sound - BEEP, which was required to set the pitch and duration. This was enough for simple monophonic melodies in the spirit of the once popular electronic musical cards.
However, as I quickly caught, the quality of the computer sound outputted through the speaker depended heavily on the talent of the programmer. This was especially noticeable in the games: in many of them the sound was primitive, but there were also surprisingly good-sounding musical things. The highest quality works were reproduced during static screensavers. The loudspeaker volume at the same time was felt below normal (so much so that sometimes you had to put your ear to the keyboard in order to catch the nuances of the composition). Often, you could hear the whistle and distortion, as if a bad recording. But, with all this, it was clearly possible to distinguish several simultaneously sounding voices, there was a change of timbres, work with an amplitude envelope, spatial effects, the sound of drums. By the ZX Spectrum, I'll be back after some retreat.
An example of one-bit synthesis for the ZX Spectrum, by Tim Follin
One-bit music is the oldest among other computer music. Back in the early 50s, melodies were played on the first computers in Australia and England. Of course, in those days, the creators of computers did not think about any tasks from the field of music. The speaker was intended solely for the purpose of debugging and diagnosing the operation of a computer. However, in their free time and spending a lot of energy on it, hackers of the early 50s forced their computers to play simple melodies. In the arsenal of the then computer musicians there were only two levels of signal supplied to the speaker.
The appearance of the speaker on one of the first microcomputers, the Apple II, was due to Steve Wozniak’s desire to port Breakout to his computer. There were sounds in the original Atari slot machine, so Wozniak added a speaker to the Apple II. A serious problem for a programmer when working with a speaker was the need to combine audio output with other tasks. For the correct formation of the meander, it was necessary to carefully check the processor cycles. In this respect, the situation was somewhat simpler in the IBM PC, since the task of generating the meander could be assigned to a separate timer chip. But even this microcircuit didn’t help too much in using pulse-width modulation (PWM, PWM) - a way to output multi-bit audio data to a speaker.
Outputting multi-bit sound to a speaker using PWM consists of transmitting audio data using a rectangular carrier signal, the pulse width of which is modulated (controlled) by amplitude level values. When the next amplitude value is received, the computer spends additional time generating a carrier with a fixed period, which depends on the desired sound capacity. In the case of PWM for the presence of only two levels of quantization of the signal, one has to pay with a significantly increased resolution in the time domain when transmitting data. Not surprisingly, the most effective PWM was used not on microcomputers, but on PCs. The reasons are associated with both speed and memory, because with the help of PWM, digitized music was most often reproduced. This kind of music was especially nice in the PC games of the second half of the 80s from the French company Loriciel .
To complete the PC theme, I will mention one common approach to imitating polyphonic sound for a speaker. In most cases, at the gameplay stage, it was too expensive to output multi-bit sound using PWM. Instead, the voices being played out simply alternated with a predetermined time interval. The shorter the period of alternation, the more high-quality “polyphonic” sound can be obtained, but this will require more activity from the processor. It is curious that this kind of reception has long been known in classical music under the name of hidden polyphony and was used, for example, in Bach suites for cello solo. The sensation of polyphony by a listener with hidden polyphony is, to a greater extent, a psychoacoustic effect. The phenomenon of a similar kind arises in one-bit music and during the performance of drum sounds. All other voices simply fall silent while the real mixing of channels is not used, but the listener's brain automatically completes the sound that does not exist at the moment.
An example of one-bit synthesis for the ZX Spectrum, by Jonathan Smith and Keith Tinman
Let's return finally to the ZX Spectrum. The one-bit music of the second half of the 80s for this microcomputer was distinguished by a special originality. The ZX Spectrum, of course, did not have PC capabilities to effectively support the sound output approaches mentioned above. But at the same time, the popularity of Speccy has stimulated the interest of developers to search for non-trivial methods of playing sound using the speaker.
The simplest single-bit synthesis by the mid-80s was well known to the developers of the ZX Spectrum. Typical sound effects can be found in many games of the time. When generating a rectangular signal (by sequentially sending zeros and ones to the speaker port), it is possible to control the following parameters: frequency, phase of the signal and pulse width. As a result, by modulating the frequency according to some law, one can obtain a kind of FM synthesis, which was discussed in one of the previous sections. In addition, using regular phase reset, it is easy to get the characteristic hard sync sound (it was already discussed in the SAM section). Finally, PWM-based effects are achievable. Here it is important to distinguish the PWM approach to output multi-bit sound, where the carrier frequency can be megahertz, from the PWM affecting the timbre, in the spirit of the sound of the famous SID (Commodore C64) and 2A03 (NES) sound chips. By controlling the above parameters you can get a fairly wide palette of interesting timbres. The only drawback - it all works in single-voice mode.
One of the first on the ZX Spectrum multichannel single-bit synthesis began to apply Tim Follin (Tim Follin). The young musician and programmer from England (at the time of creating his famous single-bit synthesizers he was 15-16 years old) used 2-3 channels for his first compositions for games, but by 1987 his music consisted of more than 5 channels using several timbres, amplitude envelopes, spatial effects and percussion.
Instead of a meander, whose pulse width is half the period, Follin used a waveform with a very narrow pulse width. The result was a characteristic “needle” timbre, vaguely reminiscent of the sound of reed instruments, such as the harmonica. At the same time, in given narrow limits, the pulse width could be adjusted, which reflected on the volume, and, additionally, on the timbre. Mixing multiple virtual channels Follin implemented using serial output values to the port in the spirit of hidden polyphony, but at a much higher frequency than in the case of a PC.
On this basis, the composer created more complex elements, such as amplitude envelopes, flanger effects and echoes. The uniqueness of the compositions of Follin is due to the fact that their author was at that time not only a talented musician with an excellent taste, but also a good programmer, who independently realized his single-bit synthesizers.
By the way, some microcomputers of the 80s, which include sound chips, also used elements of software synthesis. For a greater variety of timbres, resourceful musicians used a number of tricks related to the modulation of sound chip parameters. For example, on the Commodore C64, complex voices were assembled from several basic waveforms by quickly switching them, and on the Atari ST, the simulated PWM sound in the spirit of the SID chip was implemented by controlling one of the hardware channels of the YM2149F chip using a timer interrupt.
Over time, pulse-width modulation, which is used in high-quality audio systems, has replaced the PWM as a method for outputting multi-bit data. But where is classic one-bit sound used today? Apparently, the theme of synthesis for the dynamics was inexhaustible, since the enthusiasts of ZX Spectrum and today continue to improve their engines with the number of channels, which has already exceeded a dozen. In the academic field, scientific articles are written about the aesthetics of one-bit music , and even single-bit generators are used in chamber music concerts.
Practice
Let's take a look at Tim Follin’s music program, published in the August 1987 issue of Your Sinclair. The article, entitled Star Tip 2, says only that the above code uses 3 channels of sound.
Star Tip 2 from Your Sinclair
Fortunately, the result of disassembling a HEX dump printed in a magazine can be found on the Internet . It can be seen that the program consists of a small player, followed by a number of frames of musical data.
How does the synthesis of Star Tip 2? Each voice is determined by the period and width of the pulse. Instead of real mixing, voices are output to the speaker sequentially. There are 16 possible pulse widths. This parameter is set at once for all 3 voices being output and corresponds to the overall volume felt at the moment. The rest of the code for frame execution is related to the organization of the “amplitude” envelope, which dynamically controls the common for the voices parameter of the pulse width.
The synthesis is organized in such a way that after the sequential processing of the vote counters and the possible output of data to the speaker, some more ticks are used to organize the envelopes. Moreover, after the completion of the playback of the next frame, a certain number of cycles is spent on reading the parameters of the next frame. All these delays do not have such a destructive effect on sound as one would expect.
When modeling Star Tip 2 on Python, there is a problem with the sampling rate. 44100 Hz is not enough for organizing the withdrawal of votes, taking into account the necessary control of the width of narrow pulses. The best option would be to execute the player code at the frequency of the Z80 processor (3.5 MHz) with a further decrease in the frequency of the result to 44100 Hz. Oversampling, or, more specifically, lowering the sampling rate (decimation or decimation) must be done carefully, with preliminary removal of frequencies that lie outside the target range, rather than simply discarding unnecessary samples. A simple implementation of the filter for decimation is to use a moving average (see the decimate function). Please note that in the code below, I use a decimation factor of only 32 to speed up the program. The constants T1 and T2 were chosen by ear and given the known length of the melody.
A fragment of the composition Star Tip 2, on an enlarged scale, is represented by a “needle” waveform
def decimate(samples, m): x_pos = 0 x_delay = [0] * m y = 0 for i, x in enumerate(samples): y += x - x_delay[x_pos] x_delay[x_pos] = x x_pos = (x_pos + 1) % len(x_delay) samples[i] = y / m return samples[::m] # M = 32 # ON = 0.5 OFF = 0 # T1 = 6 T2 = 54 def out(samples, x, t): samples += [x] * t # 3 def engine(samples, dur, t1, t2, vol, periods): counters = periods[:] t1_counter = t1 t2_counter = t2 update_counter = t1 width = 1 is_slide_up = True for d in range(dur): for i in range(3): counters[i] -= 1 if counters[i] == 0: out(samples, ON, width * T1) out(samples, OFF, (16 - width) * T1) counters[i] = periods[i] # : update_counter -= 1 if update_counter == 0: update_counter = 10 if is_slide_up: t1_counter -= 1 if t1_counter == 0: t1_counter = t1 width += 1 if width == 15: width = 14 is_slide_up = False else: t2_counter -= 1 if t2_counter == 0: t2_counter = t2 if width - 1 != vol: width -= 1 out(samples, samples[-1], T2) # def play(samples, frames): dur = 0 vol = 0 t1 = 0 t2 = 0 i = 0 while frames[i] != 0: if frames[i] == 0xff: dur = frames[i + 2] << 8 | frames[i + 1] t1, t2, vol = frames[i + 3:i + 6] i += 6 else: engine(samples, dur, t1, t2, vol, frames[i: i + 3]) i += 3 samples = [0] with open("startip2.txt") as f: frames = [int(x, 16) for x in f.read().split()] play(samples, frames) write_wave("startip2.wav", decimate(samples, M)) Source
Frames
Sound
Unusual sound at 26 seconds in a wav file is created using the flanger effect, by introducing a very short delay between identical voices.
Resampling algorithms are widely used in implementations of modern software synthesizers. In particular, the use of such algorithms is another, in addition to FM-synthesis with feedback already known to us, a way to combat the phenomenon of frequency overlap when reproducing waveforms. In addition, as this example shows, it is difficult to dispense with such algorithms when modeling the sound of old sound chips (AY-3-8910, SID, etc.).
Sonix
In 1985, the Commodore Amiga 1000 personal computer was born, in which a special Paula chip was used to work with sound. Paula's capabilities were strikingly different from typical sound chips used in home computers of the time. The Amiga had 4 hardware audio channels with a bit width of 8 bits each and a sample rate tuned for each channel up to 28.8 kHz (without additional tweaks). Similar characteristics were possessed by the Sampler of the early 80s, popular among musicians, the E-MU Emulator. From the point of view of the programmer, the organization of multichannel audio output in this computer was practically without the participation of the central processor.
Although Amiga was positioned as a computer for creative people, it was still defeated in a fight with the Atari ST for the attention of professional musicians. Atari ST had built-in MIDI support, but the Amiga didn't have it. Moreover, on the first Amiga there were certain problems with the use of a serial port for connecting via MIDI. As a result, Amiga has become an excellent system for computer amateur musicians who have written the necessary programs for themselves - music trackers with their peculiar notation of musical events and samples as instruments.
Software synthesizers for Amiga were rare, which is explainable, including the lack of processor speed. However, Amiga software synthesis existed, for example, in the form of FM synthesizers (FMsynth). The very first implementation of Amiga software synthesis was the MusiCraft application, which was used by Commodore to demonstrate the capabilities of the new computer. In 1986, MusiCraft was sold to Aegis and, after some modifications, entered the market under the name Sonix.
Sonix Parameters Window
Sonix is a real-time analog synthesizer model with polyphony with up to 4 voices. The capabilities of this old-fashioned software synthesizer are not so different from modern VSTi-plug-ins: there is an oscillator with a choice of waveform, a filter with adjustable cutoff frequency (but no resonance), ADSR envelope, LFO (low frequency signal generator). The waveform for the oscillator and the LFO can be drawn with the mouse. Sonix used an ingenious solution to imitate the sound of a resonance: by pressing the screen button, the image of a waveform is simply replaced by several of its repetitions within the same period, which leads to a characteristic sound. Also available is a flanger effect with customizable parameters. Although the capabilities of Sonix seem quite modest by the present time, the synthesizer is distinguished by a rather wide palette of sounds. The only, somewhat strange today seems to be the decision of the developers to use the classical stave to write music in Sonix.
Practice
Now let's try to create, in the spirit of Sonix, a model of an oscillator and an analog synthesizer filter. As an oscillator, a sawtooth generator will be used. To get rid of the clearly audible manifestations of the effect of frequency overlap, we use FM-synthesis with feedback. It is interesting to note that by controlling the feedback level you can immediately get some effect of the low-pass filter, but this will work only for a specific oscillator, and not for any input signal.
As in the case of Sonix, our task will be to create a low-pass filter without controlling the resonance. Note the implementation of the low-order filter 1 order (see the definition of class Lp1 in the code below). Although such a filter does not have a high frequency slope, it only requires one multiplication and can be used, for example, to smooth the values of control parameters. In addition, this filter can be used as a building block for building more complex filters in cascade form. In particular, the famous Muga filter contains 4 series 1 order connected low-pass filters. Such a cascade scheme is implemented in this example.
The additional oscillator lfo1 (sine wave generator) is used to automate the control of the cutoff frequency of the filter. For the demonstration, I took the famous note sequence from On the Run by Pink Floyd.
# # FM- , # Sine class Saw: def __init__(self): self.o = Sine() self.fb = 0 def next(self, freq, cutoff=2): o = self.o.next(freq, cutoff * self.fb) # self.fb = (o + self.fb) * 0.5 return self.fb # - 1 class Lp1: def __init__(self): self.y = 0 # cutoff 0..1 def next(self, x, cutoff): self.y += cutoff * (x - self.y) return self.y # E3, G3, A3, G3, D4, C4, D4, E4, 165 BPM ON_THE_RUN = [82.41, 98, 110, 98, 146.83, 130.81, 146.83, 164.81] osc1 = Saw() lfo1 = Sine() flt1 = Lp1() flt2 = Lp1() flt3 = Lp1() flt4 = Lp1() samples = [] for bars in range(16): for freq in ON_THE_RUN: for t in range(int(sec(0.09))): x = osc1.next(freq) cutoff = 0.5 + lfo1.next(0.2) * 0.4 x = flt1.next(x, cutoff) x = flt2.next(x, cutoff) x = flt3.next(x, cutoff) x = flt4.next(x, cutoff) samples.append(0.5 * x) write_wave("on_the_run.wav", samples) Source
Sound
Modeling filters analog synthesizers - an extensive topic on which we can recommend a good modern book The Art of VA Filter Design . The author of this book, Vadim Zavalishin, in the late 90s created the software synthesizer Sync Modular and, further, became one of the key developers of the famous synthesizer NI Reaktor. The Core technology developed by Zavalishin relates to the very blocks and wires, an example of which was described in one of the previous sections. In the case of Core, graphs are translated into efficient machine code every time their structure changes and this happens right in the process of working with a synthesizer.
Sync Modular Interface
Music kit
1988 year. An unusual duet is playing on the stage of the concert hall. It consists of a professional violinist and a computer that generates the sound of strings in real time using synthesis based on physical modeling. In this way, Steve Jobs decided to complete the presentation of his new brainchild - the NeXT personal computer. Jobs did everything in his power to ensure that the sound capabilities of the new computer were unrivaled among competitors. NeXT's sophisticated sound synthesis was performed using a main 32-bit processor, a math coprocessor, and a dedicated DSP processor dedicated to audio-related tasks. Audio output to the NeXT was carried out in stereo, 44100 Hz, 16 bit.
Jobs understood that in order to fully use the powerful hardware, he would need a team of computer sound professionals. For this reason, he turned to Julius Smith, one of the best experts in the field of musical digital signal processing from Stanford University.
Smith and another Stanford native, David Jaffe, created the Music Kit for NeXT. This system combined the MIDI approach to working with note events with the approach of describing sound modules and connections between them from the MUSIC N. The Music Kit took control of the DSP processor, distributed resources and provided the developer with a high-level interface as a set of objects that could be used in creating final GUI applications related to sound.
As part of the Music Kit, various types of sound synthesis were implemented. The variant, which was presented at the 1988 presentation, is based on the Karplus-Strong algorithm (Karplus-Strong). This is a surprisingly simple algorithm, invented in the late 70s, which allows you to simulate the sound of damped string vibrations. In the original version, this algorithm uses a cyclic buffer (delay line), the length of which corresponds to the oscillation period of the simulated string. To create initial conditions for damped oscillations, random values are placed in the buffer. Further, sequential reading from the buffer is accompanied by averaging of the next pair of neighboring samples, that is, filtering, which can be implemented without multiplication operations. Carplus-Strong Smith developed the approach to synthesis based on digital waveguides (digital waveguide), which is now a general approach to the physical modeling of various acoustic instruments. This technology was used by Yamaha and Korg in their synthesizers based on physical modeling.
Applications for the Music Kit, as well as the NeXT computer itself, were known mainly in the university environment. Among the developments there are several visual musical programming environments (SynthEdit, SynthBuilder), as well as a singing voice synthesizer (SPASM). In addition, using the Music Kit, physical models of a wide variety of acoustic instruments were created.
SynthBuilder based on the Music Kit
Since the beginning of the 90s, the Music Kit system has evolved within the walls of Stanford University, and Steve Jobs made a respectable decision to open its code . There was a version of the Music Kit for PC, but, unfortunately, it did not receive distribution.
Practice
In this example, we consider the implementation of a simple model of acoustic bass guitar by the Karplus-Strong method. The model will consist of the following elements: noise generator, delay line, low-pass filter. The key element is the delay line, which simulates the vibration of the string. At the moment of the next “hit on the string”, the values from the noise generator fall into the buffer of the delay line and the number of these values depends on the strength of the “hit”. Random values create a more natural sound effect, when each hit on the string is slightly different from the previous one. The buffer length of the delay line corresponds to the oscillation period and the reading of the next sample of the result occurs on an index that moves within the size of the buffer. To create the effect of string oscillations, in which high harmonics decay faster than low harmonics, a low-pass filter is used, which is applied to the value at the current index in the buffer of the delay line.
In the original version of the algorithm, the low-pass filter is a simple averaging of the values of two samples, which can be implemented without a multiplication operation, but with this implementation an undesirable effect is manifested: high notes fade out too fast, and low notes, respectively, too slowly. The code below uses a low-pass filter of the first order, implemented in the previous section. This filter, using the appropriate parameter, allows you to set for a particular note the desired value of the cutoff frequency.
# "" ( Lp1 ), # amp: , # freq: , # dur: def pluck(samples, amp, freq, dur): flt = Lp1() delay_buf = [0] * int(SR / freq) delay_pos = 0 for i in range(int(len(delay_buf) * amp)): delay_buf[i] = random.random() for t in range(int(sec(dur))): delay_buf[delay_pos] = flt.next(delay_buf[delay_pos], 220 / len(delay_buf)) samples.append(amp * delay_buf[delay_pos]) delay_pos = (delay_pos + 1) % len(delay_buf) # dur, # , # , def rest(samples, dur): for t in range(int(sec(dur))): samples.append(samples[-1]) samples = [] for i in range(4): pluck(samples, 0.7, 58, 0.27) pluck(samples, 0.4, 62, 0.27) pluck(samples, 0.4, 66, 0.27) pluck(samples, 0.6, 69, 0.27) pluck(samples, 0.5, 138, 0.01) rest(samples, 0.13) pluck(samples, 0.7, 123, 0.13) rest(samples, 0.27) pluck(samples, 0.7, 139, 0.47) rest(samples, 0.07) pluck(samples, 0.7, 78, 0.27) pluck(samples, 0.4, 82, 0.27) pluck(samples, 0.4, 87, 0.27) pluck(samples, 0.6, 92, 0.27) pluck(samples, 0.5, 184, 0.01) rest(samples, 0.13) pluck(samples, 0.7, 139, 0.13) rest(samples, 0.27) pluck(samples, 0.7, 165, 0.47) rest(samples, 0.07) write_wave("chameleon.wav", samples) Source
Sound
It remains to add that as a demonstration of the sound, I chose the bass riff from the composition of Chameleon Herbie Hancock.
Conclusion
In the 90s, software synthesizers for PC and Mac experienced rapid development. Among the most unusual programs we can mention MetaSynth, with the help of which, in the spirit of the Soviet synthesizer “ANS” E.A. Murzin, it was possible to generate sound based on the image. One of the MetaSynth users was the famous electronic musician Efex Twin (Aphex Twin). In 1999, Steinberg released the second version of its VST audio plug-in format, which supported the input MIDI data. So there were so popular today VST synthesizers.
In recent years, basic research on sound synthesis has focused on the detailed modeling of the elements of analog synthesizers. Synthesis based on the physical modeling of acoustic instruments and more exotic approaches to the creation of timbres turned out to be not much in demand by musicians. I think that at the moment most musicians simply do not have artistic tasks that require the use of complex and abstract sound synthesis schemes.
However, sophisticated sound design is still in demand in the movies. One of the historical and inspiring examples of computer sound design is the Deep Note composition, created by James A. Moorer from Stanford University. This short composition was played in American cinemas every time the THX technology logo appeared on the screen. Creating DeepNote required from its author knowledge in the field of musical programming. This kind of composition, where typical musical elements are practically not used, is difficult to compose in modern editors designed for an established user work process. Another example from the field of cinema is Kyma’s visual music programming system., which in our time is used in the sound of Hollywood films.
Optimism is also a recent (2010) out of a serious textbook Andy Farnell (Andy Farnell) Designing the Sound . This book is completely devoted to computer sound synthesis with examples on the Pure Data visual audio language.
Finally, complex algorithmic sound design schemes can be used in computer games. In particular, this concerns the modeling of natural phenomena or the sounds of various mechanisms, engine noise. Corresponding sound synthesis methods have been used in games for some time, and it is hoped to be used more widely in the future.
Source: https://habr.com/ru/post/348192/
All Articles