SQL keys in full detail
The Internet is full of dogmatic commandments about how to choose and use keys in relational databases. Sometimes disputes even go into holivars: use natural or artificial keys? Auto-increment integers or UUIDs?
After reading sixty-four articles, scrolling through sections of five books and asking a bunch of questions in IRC and StackOverflow, I (the author of the original article Joe “begriffs” Nelson ), I think, put the pieces of the puzzle together and now I can reconcile the opponents. Many disputes regarding the keys arise, in fact, because of a wrong understanding of someone else's point of view.
Let's divide the problem into parts, and in the end we will collect it again. To begin, let us ask the question - what is the “key”?
Let's forget for a minute about the primary keys, we are interested in a more general idea. The key is a column or columns that do not have duplicate values in the rows. In addition, the columns must be irreducibly unique, that is, no subset of the columns is so unique.
')
For example, consider the table for counting cards in a card game:
If we track one deck (that is, without duplicate cards), then the combination of shirt and face is unique and we would not want to add the same shirt and face to the table twice, because it would be redundant. If the map is in the table, then we saw it, otherwise - we did not see it.
We can and should set the database to this restriction by adding the following:
Neither
In a more general situation, when you need to track several decks of cards, you can add a new field and record how many times we have seen a card:
Although the triple
Also, there may be several keys in the table without problems, and we must declare them all in order to observe their uniqueness in the database.
Here are two examples of tables with multiple keys.
For the sake of brevity, there are no other limitations in the examples that would be in practice. For example, maps should not have a negative number of views, and a NULL value is unacceptable for most of the columns considered (with the exception of the
What we called simply “keys” in the previous section is usually called “candidate keys”. The term “candidate” implies that all such keys compete for the honorable role of a “primary key” (primary key), and the remaining ones are assigned to “alternative keys” (alternate keys).
It took some time for the mismatch between keys and the relational model to disappear in SQL implementations, the earliest databases were sharpened under the low-level concept of a primary key. Primary keys in such databases were required to identify the physical location of the string on media with sequential access to data. Here is how Joe Selco explains it:
In modern SQL, there is no need to focus on the physical presentation of information; tables model relationships and the internal order of rows is not important at all. However, now the SQL server by default creates a clustered index for primary keys and, according to the old tradition, physically builds the order of the rows.
In most databases, the primary keys are preserved as a relic of the past, and they hardly provide anything but a reflection or definition of physical location. For example, in a PostgreSQL table, a primary key declaration automatically imposes a NOT NULL constraint and determines the default foreign key. In addition, primary keys are the preferred columns for the JOIN operator.
The primary key does not cancel the possibility of declaring other keys. At the same time, if no key is assigned primary, the table will still work normally. Lightning, in any case, will not strike you.

The keys discussed above are called “natural” because they are the properties of the object being simulated interesting in and of themselves, even if no one wants to make a key out of them.
The first thing to remember when examining the table for possible natural keys is to try not to be too smart. The user sqlvogel on StackExchange gives the following advice:
Practice shows that it is necessary to impose a restriction on the key, when the column is unique with the available values and will remain that under probable scenarios. And if necessary, the restriction can be eliminated (if it bothers you, then we will tell you about the stability of the key.)
For example, a database of members of a hobby club may be unique in two columns - first_name, last_name. With a small amount of data, duplicates are unlikely, and it is quite reasonable to use such a key until a real conflict occurs.
As the database grows and the amount of information increases, choosing a natural key can become more difficult. The data stored by us are a simplification of external reality, and do not contain some aspects that distinguish objects in the world, such as their coordinates changing with time. If an object does not have any code, then how to distinguish between two cans of drink or two boxes of oatmeal, except by their location in space or by slight differences in weight or packaging?
That is why standardization bodies create and apply distinctive marks on products. Vehicle Identification Number (VIN) is stamped on cars, an ISBN is printed in books, there is a UPC on the food packaging. You can argue that these numbers do not seem natural. So why do I call them natural keys?
The naturalness or artificiality of unique properties in a database is relative to the outside world. The key, which, when created in a standardization body or a state institution, was artificial, becomes natural for us, because in the whole world it becomes a standard and / or printed on objects.
There are many industry, public, and international standards for various sites, including currencies, languages, financial instruments, chemicals, and medical diagnoses. Here are some of the values that are often used as natural keys:
We recommend declaring keys when it is possible and reasonable, maybe even a few keys per table. But remember that all of the above may have exceptions.

Taking into account that the key is a column, in each row of which there are unique values, one of the ways to create it is a scam - you can write imaginary unique values into each row. These are artificial keys: invented code used to refer to data or objects.
It is very important that the code is generated from the database itself and is unknown to anyone other than database users. This is what distinguishes artificial keys from standardized natural keys.
The advantage of natural keys is to protect against duplication or inconsistency of rows of the table, artificial keys are useful because they allow people or other systems to more easily refer to a row, and also increase the speed of search and merge operations, since they do not use string comparisons (or multi-column) keys.
Artificial keys should be chosen, taking into account possible ways of their transmission, in order to minimize typos and errors. It should be noted that the key can be pronounced, read typed, sent via SMS, read handwritten, entered from the keyboard and embedded in the URL. Additionally, some artificial keys, such as credit card numbers, contain a checksum so that when certain errors occur they can at least be recognized.
Examples:
Consider that as soon as you introduce the world to your artificial key, people will start giving special attention to it in a strange way. Just look at the "thieves" license plates or the system for creating pronounced identifiers, which has become a notorious automated curse generator .
Even if we restrict ourselves to numeric keys, there is a taboo of the thirteenth floor type. Despite the fact that proquints have a greater density of information on the spoken syllable, the numbers are also quite good in many cases: in the URL, pin-keyboards and handwritten entries, if the recipient knows that the key consists only of numbers.
However, please note that you should not use a sequential order in publicly open numeric keys, as this allows you to rummage through resources (
The PostgreSQL wiki has an example of a pseudo-encryption function:
This function is the inverse of itself (i.e.,
Here's how to use pseudo_encrypt:
This solution saves random values in the
In the previous example, normal-sized integer values were used for
Another way to confuse a sequence of integers is to convert it to short strings. Try using the pg_hashids extension:
Here again it will be faster to store the whole numbers in the table and convert them on demand, but measure the performance and see if it really makes sense.
Now, clearly distinguishing between the meaning of artificial and natural keys, we see that the “natural vs. artificial” disputes are a false dichotomy. Artificial and natural keys are not mutually exclusive! In one table there can be both. In fact, a table with an artificial key should also provide a natural key, with rare exceptions, when there is no natural key (for example, in the coupon code table):
If you have an artificial key and you do not declare natural keys when they exist, then leave the latter unprotected:
The only argument against declaring additional keys is that each new one carries with it another unique index and increases the cost of writing to the table. Of course, it depends on how important the data is to you, but, most likely, the keys are still worth declaring.
Also worth declaring a few artificial keys, if any. For example, an organization has applicants for work (Applicants) and employees (Employees). Each employee was once a candidate, and refers to candidates by their own identifier, which must also be the key of the employee. One more example, you can set an employee ID and login name as two keys in Employees.

As already mentioned, an important type of artificial key is called a “surrogate key”. It should not be short and transferable, like other artificial keys, but is used as an internal label, always identifying a string. It is used in SQL, but the application does not explicitly refer to it.
If you are familiar with the system columns from the PostgreSQL system, then you can take surrogates almost as a database implementation parameter (like ctid), which, however, never changes. The value of the surrogate is selected once for each line and then never changes.
Surrogate keys are great as foreign keys, with cascading constraints
On the other hand, foreign keys to publicly transmitted keys must be labeled
Do not make surrogate keys "natural."As soon as you show the value of the surrogate key to the end users, or, worse, let them work with this value (in particular through a search), you will in fact give the key meaning. Then the displayed key from your database can become a natural key in someone else's database.
Forcing external systems to use other artificial keys specifically designed for transmission allows us, if necessary, to change these keys in accordance with changing needs, while at the same time maintaining the internal integrity of the links using surrogates.
«bigserial»,
, , . , .
:
: (128-), . (universally unique identifier, UUID) , .
, UUID , ? , !
PostgreSQL? , , , .
, . , UUID — , : 5bd68e64-ff52-4f54-ace4-3cd9161c8b7f. , (128-) uuid, PostgreSQL bigint, .., , .
UUID , , ? , , ( ) UUID. , UUID , SQL psql , . , .
UUID , (write amplification) - (write-ahead log, WAL). , UUID.
write amplification. , . PostgreSQL , «» . , . PostgreSQL , .
PostgreSQL / / , (write-ahead log), . UUID ( 4 8 ) WAL . (full-page write, FPW).
UUID (, «snowflake» Twitter
FPW UUID, WAL. .
Scheme:
, UUID , write-ahead log.
, WAL . , :
:
2 20 UUID , , , .
:
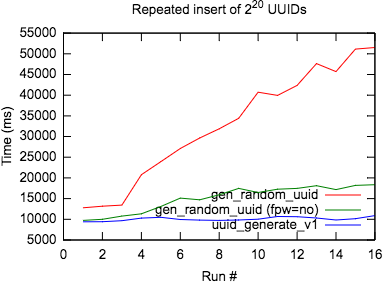
UUID
WAL :
,
uuid_generate_v1:
, , . - ,
, , .
:
, . , - . , « » .
. -, , , - , ++ , 8 , DevOps . .
After reading sixty-four articles, scrolling through sections of five books and asking a bunch of questions in IRC and StackOverflow, I (the author of the original article Joe “begriffs” Nelson ), I think, put the pieces of the puzzle together and now I can reconcile the opponents. Many disputes regarding the keys arise, in fact, because of a wrong understanding of someone else's point of view.
Content
- What is the "keys"?
- Curious case of primary keys
- The choice of natural keys
- Artificial keys
- Surrogate keys
- Auto-increment BIGINT
- UUID
- Results and recommendations
Let's divide the problem into parts, and in the end we will collect it again. To begin, let us ask the question - what is the “key”?
What is the "keys"?
Let's forget for a minute about the primary keys, we are interested in a more general idea. The key is a column or columns that do not have duplicate values in the rows. In addition, the columns must be irreducibly unique, that is, no subset of the columns is so unique.
')
For example, consider the table for counting cards in a card game:
CREATE TABLE cards_seen ( suit text, face text ); If we track one deck (that is, without duplicate cards), then the combination of shirt and face is unique and we would not want to add the same shirt and face to the table twice, because it would be redundant. If the map is in the table, then we saw it, otherwise - we did not see it.
We can and should set the database to this restriction by adding the following:
CREATE TABLE cards_seen ( suit text, face text, UNIQUE (suit, face) ); Neither
suit (shirt) nor face (face) is unique, we can see different cards with the same shirt or face. Since (suit, face) unique, and the individual columns are not unique, it can be argued that their combination is irreducible, and (suit, face) is the key.In a more general situation, when you need to track several decks of cards, you can add a new field and record how many times we have seen a card:
CREATE TABLE cards_seen ( suit text, face text, seen int ); Although the triple
(suit, face, seen) turns out to be unique, it is not the key, because the subset (suit, face) must also be unique. This is necessary because two lines with the same shirt and face, but different values seen will be contradictory information. Therefore, the key is (suit, face) , and there are no more keys in this table.Uniqueness constraints
In PostgreSQL, the preferred way to add a uniqueness constraint is its direct declaration, as in our example. Using indexes to enforce uniqueness constraints may be necessary in some cases, but it is not necessary to contact them directly. It is not necessary to manually create indexes for columns already declared unique; such actions will simply duplicate the automatic index creation.
Also, there may be several keys in the table without problems, and we must declare them all in order to observe their uniqueness in the database.
Here are two examples of tables with multiple keys.
-- CREATE TABLE tax_brackets ( min_income numeric(8,2), max_income numeric(8,2), tax_percent numeric(3,1), UNIQUE(min_income), UNIQUE(max_income), UNIQUE(tax_percent) ); -- CREATE TABLE flight_roster ( departure timestamptz, gate text, pilot text UNIQUE(departure, gate), UNIQUE(departure, pilot) ); For the sake of brevity, there are no other limitations in the examples that would be in practice. For example, maps should not have a negative number of views, and a NULL value is unacceptable for most of the columns considered (with the exception of the
max_income column for tax groups, in which NULL can denote infinity).Curious case of primary keys
What we called simply “keys” in the previous section is usually called “candidate keys”. The term “candidate” implies that all such keys compete for the honorable role of a “primary key” (primary key), and the remaining ones are assigned to “alternative keys” (alternate keys).
It took some time for the mismatch between keys and the relational model to disappear in SQL implementations, the earliest databases were sharpened under the low-level concept of a primary key. Primary keys in such databases were required to identify the physical location of the string on media with sequential access to data. Here is how Joe Selco explains it:
The term “key” meant the sort key of a file that was needed to perform any processing operations on a sequential file system. A set of punched cards was read in one and only one order; it was impossible to "go back." The first tape drives imitated the same behavior and did not allow bidirectional access. That is, the original Sybase SQL Server to read the previous line required to "rewind" the table to the beginning.
In modern SQL, there is no need to focus on the physical presentation of information; tables model relationships and the internal order of rows is not important at all. However, now the SQL server by default creates a clustered index for primary keys and, according to the old tradition, physically builds the order of the rows.
In most databases, the primary keys are preserved as a relic of the past, and they hardly provide anything but a reflection or definition of physical location. For example, in a PostgreSQL table, a primary key declaration automatically imposes a NOT NULL constraint and determines the default foreign key. In addition, primary keys are the preferred columns for the JOIN operator.
The primary key does not cancel the possibility of declaring other keys. At the same time, if no key is assigned primary, the table will still work normally. Lightning, in any case, will not strike you.
Finding Natural Keys
The keys discussed above are called “natural” because they are the properties of the object being simulated interesting in and of themselves, even if no one wants to make a key out of them.
The first thing to remember when examining the table for possible natural keys is to try not to be too smart. The user sqlvogel on StackExchange gives the following advice:
Some people have difficulty choosing the “natural” key because they come up with hypothetical situations in which a certain key may not be unique. They do not understand the very meaning of the problem. The meaning of the key is to determine the rule according to which attributes at any time should be and always will be unique in a particular table. The table contains data in a specific and well-understood context (in the "subject area" or in the "area of discourse") and the application of a restriction in this particular area is of the only importance.
Practice shows that it is necessary to impose a restriction on the key, when the column is unique with the available values and will remain that under probable scenarios. And if necessary, the restriction can be eliminated (if it bothers you, then we will tell you about the stability of the key.)
For example, a database of members of a hobby club may be unique in two columns - first_name, last_name. With a small amount of data, duplicates are unlikely, and it is quite reasonable to use such a key until a real conflict occurs.
As the database grows and the amount of information increases, choosing a natural key can become more difficult. The data stored by us are a simplification of external reality, and do not contain some aspects that distinguish objects in the world, such as their coordinates changing with time. If an object does not have any code, then how to distinguish between two cans of drink or two boxes of oatmeal, except by their location in space or by slight differences in weight or packaging?
That is why standardization bodies create and apply distinctive marks on products. Vehicle Identification Number (VIN) is stamped on cars, an ISBN is printed in books, there is a UPC on the food packaging. You can argue that these numbers do not seem natural. So why do I call them natural keys?
The naturalness or artificiality of unique properties in a database is relative to the outside world. The key, which, when created in a standardization body or a state institution, was artificial, becomes natural for us, because in the whole world it becomes a standard and / or printed on objects.
There are many industry, public, and international standards for various sites, including currencies, languages, financial instruments, chemicals, and medical diagnoses. Here are some of the values that are often used as natural keys:
- ISO 3166 country codes
- ISO 639 language codes
- Currency codes according to ISO 4217
- ISIN exchange symbols
- UPC / EAN, VIN, GTIN, ISBN
- login names
- email addresses
- rooms numbers
- mac address in network
- (latitude, longitude) for points on the surface of the earth
We recommend declaring keys when it is possible and reasonable, maybe even a few keys per table. But remember that all of the above may have exceptions.
- Not everyone has an email address, although this may be acceptable in some database usage conditions. In addition, people change their email addresses from time to time. (More on key stability later.)
- ISIN trade names change from time to time, for example, the characters GOOG and GOOGL do not accurately describe the reorganization of a company from Google into Alphabet. Sometimes there may be confusion, such as with TWTR and TWTRQ, some investors mistakenly bought the last during the Twitter IPO.
- Social Security numbers are used only by US citizens, have confidentiality restrictions and are reused after death. In addition, after the theft of documents, people can get new numbers. Finally, the same number can identify both the person and the tax ID.
- Zip codes are a poor choice for cities. Some cities have a common index, or vice versa, there are several indices in one city.
Artificial keys
Taking into account that the key is a column, in each row of which there are unique values, one of the ways to create it is a scam - you can write imaginary unique values into each row. These are artificial keys: invented code used to refer to data or objects.
It is very important that the code is generated from the database itself and is unknown to anyone other than database users. This is what distinguishes artificial keys from standardized natural keys.
The advantage of natural keys is to protect against duplication or inconsistency of rows of the table, artificial keys are useful because they allow people or other systems to more easily refer to a row, and also increase the speed of search and merge operations, since they do not use string comparisons (or multi-column) keys.
Non-surrogate artificial keys are convenient for references to a string outside the database. An artificial key briefly identifies data or an object: it can be specified as a URL, attached to an account, dictated by telephone, received in a bank or printed on a license plate. (The license plate of the car is a natural key for us, but it was designed by the state as an artificial key.)Surrogates
Artificial keys are used as a binding - regardless of changes to the rules and columns, one line can always be identified in the same way. The artificial key used for this purpose is called the “surrogate key” and requires special attention. Surrogates will be discussed below.
Artificial keys should be chosen, taking into account possible ways of their transmission, in order to minimize typos and errors. It should be noted that the key can be pronounced, read typed, sent via SMS, read handwritten, entered from the keyboard and embedded in the URL. Additionally, some artificial keys, such as credit card numbers, contain a checksum so that when certain errors occur they can at least be recognized.
Examples:
- For US license plates, there are rules on the use of ambiguous features, such as
Oand0. - Hospitals and pharmacies should be especially careful, given the doctors' handwriting.
- Do you pass the confirmation code to the sms? Do not go beyond the GSM 03.38 character set.
- Unlike Base64, which encodes arbitrary byte data, Base32 uses a limited set of characters that is convenient for people to use and process on older computer systems.
- Proquints are readable, writable, and spoken identifiers. These are the pronounced (PRO-nouncable) fives (QUINT-uplets) of uniquely understood consonants and vowels.
Consider that as soon as you introduce the world to your artificial key, people will start giving special attention to it in a strange way. Just look at the "thieves" license plates or the system for creating pronounced identifiers, which has become a notorious automated curse generator .
Even if we restrict ourselves to numeric keys, there is a taboo of the thirteenth floor type. Despite the fact that proquints have a greater density of information on the spoken syllable, the numbers are also quite good in many cases: in the URL, pin-keyboards and handwritten entries, if the recipient knows that the key consists only of numbers.
However, please note that you should not use a sequential order in publicly open numeric keys, as this allows you to rummage through resources (
/videos/1.mpeg , /videos/2.mpeg , and so on), and also creates a leak of information about data. Overlay a network of its Feistel on a sequence of numbers and preserve its uniqueness, while hiding the order of numbers.The PostgreSQL wiki has an example of a pseudo-encryption function:
CREATE OR REPLACE FUNCTION pseudo_encrypt(VALUE int) returns int AS $$ DECLARE l1 int; l2 int; r1 int; r2 int; i int:=0; BEGIN l1:= (VALUE >> 16) & 65535; r1:= VALUE & 65535; WHILE i < 3 LOOP l2 := r1; r2 := l1 # ((((1366 * r1 + 150889) % 714025) / 714025.0) * 32767)::int; l1 := l2; r1 := r2; i := i + 1; END LOOP; RETURN ((r1 << 16) + l1); END; $$ LANGUAGE plpgsql strict immutable; This function is the inverse of itself (i.e.,
pseudo_encrypt(pseudo_encrypt(x)) = x ). Exact reproduction of a function is a kind of security through obscurity, and if someone guesses that you used the Feistel network from the PostgreSQL documentation, it will be easy for him to get the original sequence. However, instead of (((1366 * r1 + 150889) % 714025) / 714025.0) you can use another function with a range of values from 0 to 1, for example, just experiment with the numbers in the previous expression.Here's how to use pseudo_encrypt:
CREATE SEQUENCE my_table_seq; CREATE TABLE my_table ( short_id int NOT NULL DEFAULT pseudo_encrypt( nextval('my_table_seq')::int ), -- … UNIQUE (short_id) ); This solution saves random values in the
short_id column, but if it is important to maintain high processing speeds, then you can store the incremental sequence itself in the table and convert it when you request a display using pseudo_encrypt . As we will see later, indexing randomized values can lead to an increase in the recording volume.In the previous example, normal-sized integer values were used for
short_id , for bigint there are other Feistel functions, for example XTEA .Another way to confuse a sequence of integers is to convert it to short strings. Try using the pg_hashids extension:
CREATE EXTENSION pg_hashids; CREATE SEQUENCE my_table_seq; CREATE TABLE my_table ( short_id text NOT NULL DEFAULT id_encode( nextval('my_table_seq'), ' long string as table-specific salt ' ), -- … UNIQUE (short_id) ); INSERT INTO my_table VALUES (DEFAULT), (DEFAULT), (DEFAULT); SELECT * FROM my_table; /* ┌──────────┐ │ short_id │ ├──────────┤ │ R4 │ │ ya │ │ Ll │ └──────────┘ */ Here again it will be faster to store the whole numbers in the table and convert them on demand, but measure the performance and see if it really makes sense.
Now, clearly distinguishing between the meaning of artificial and natural keys, we see that the “natural vs. artificial” disputes are a false dichotomy. Artificial and natural keys are not mutually exclusive! In one table there can be both. In fact, a table with an artificial key should also provide a natural key, with rare exceptions, when there is no natural key (for example, in the coupon code table):
-- : , -- "code" CREATE TABLE coupons ( code text NOT NULL, amount numeric(5,2) NOT NULL, redeemed boolean NOT NULL DEFAULT false, UNIQUE (code) ); If you have an artificial key and you do not declare natural keys when they exist, then leave the latter unprotected:
CREATE TABLE cars ( car_id bigserial NOT NULL, vin varchar(17) NOT NULL, year int NOT NULL, UNIQUE (car_id) -- -- UNIQUE (vin) ); -- , INSERT INTO cars (vin, year) VALUES ('1FTJW36F2TEA03179', 1996), ('1FTJW36F2TEA03179', 1997); The only argument against declaring additional keys is that each new one carries with it another unique index and increases the cost of writing to the table. Of course, it depends on how important the data is to you, but, most likely, the keys are still worth declaring.
Also worth declaring a few artificial keys, if any. For example, an organization has applicants for work (Applicants) and employees (Employees). Each employee was once a candidate, and refers to candidates by their own identifier, which must also be the key of the employee. One more example, you can set an employee ID and login name as two keys in Employees.
Surrogate keys
As already mentioned, an important type of artificial key is called a “surrogate key”. It should not be short and transferable, like other artificial keys, but is used as an internal label, always identifying a string. It is used in SQL, but the application does not explicitly refer to it.
If you are familiar with the system columns from the PostgreSQL system, then you can take surrogates almost as a database implementation parameter (like ctid), which, however, never changes. The value of the surrogate is selected once for each line and then never changes.
Surrogate keys are great as foreign keys, with cascading constraints
ON UPDATE RESTRICT necessary to match the immutability of the surrogate.On the other hand, foreign keys to publicly transmitted keys must be labeled
ON UPDATE CASCADE to provide maximum flexibility. (A cascading update is performed at the same isolation level as the transaction surrounding it, so don’t worry about concurrent access problems — the database can handle if you choose a strict isolation level.)Do not make surrogate keys "natural."As soon as you show the value of the surrogate key to the end users, or, worse, let them work with this value (in particular through a search), you will in fact give the key meaning. Then the displayed key from your database can become a natural key in someone else's database.
Forcing external systems to use other artificial keys specifically designed for transmission allows us, if necessary, to change these keys in accordance with changing needs, while at the same time maintaining the internal integrity of the links using surrogates.
Auto-increment bigint
«bigserial»,
IDENTITY . ( , PostgreSQL 10 , Oracle, IDENTITY, . CREATE TABLE .), , . , .
:
- 1 , . , , , , JOIN . ( , , , .)
nextval()SQL, , .- , , , .
- , . , , - . .
- ( , ) -.
UUID
: (128-), . (universally unique identifier, UUID) , .
, UUID , ? , !
PostgreSQL? , , , .
, . , UUID — , : 5bd68e64-ff52-4f54-ace4-3cd9161c8b7f. , (128-) uuid, PostgreSQL bigint, .., , .
UUID , , ? , , ( ) UUID. , UUID , SQL psql , . , .
UUID , (write amplification) - (write-ahead log, WAL). , UUID.
write amplification. , . PostgreSQL , «» . , . PostgreSQL , .
PostgreSQL / / , (write-ahead log), . UUID ( 4 8 ) WAL . (full-page write, FPW).
UUID (, «snowflake» Twitter
uuid_generate_v1() uuid-ossp PostgreSQL) . FPW.FPW UUID, WAL. .
- EC2 ami-aa2ea6d0
- Ubuntu Server 16.04 LTS (HVM)
- EBS General Purpose (SSD)
- c3.xlarge
- vCPU: 4
- RAM GiB: 7.5
- Disk GB: 2 x 40 (SSD)
- PostgreSQL,
- ftp.postgresql.org/pub/source/v10.1/postgresql-10.1.tar.gz
./configure --with-uuid=ossp CFLAGS="-O3"
- , :
- max_wal_size='10GB';
- checkpoint_timeout='2h';
- synchronous_commit='off';
Scheme:
CREATE EXTENSION "uuid-ossp"; CREATE EXTENSION pgcrypto; CREATE TABLE u_v1 ( u uuid PRIMARY KEY ); CREATE TABLE u_crypto ( u uuid PRIMARY KEY ); , UUID , write-ahead log.
SELECT pg_walfile_name(pg_current_wal_lsn()); /* , pg_walfile_name -------------------------- 000000010000000000000001 */ , WAL . , :
pg_waldump --stats 000000010000000000000001 :
- UUID,
gen_random_uuid()( pgcrypto ) uuid_generate_v1()( [uuid-ossp] (https://www.postgresql.org/docs/10/static/uuid-ossp.html)gen_random_uuid(),full_page_writes='off'. , FPW.
2 20 UUID , , , .
-- , psql 16 \timing INSERT INTO u_crypto ( SELECT gen_random_uuid() FROM generate_series(1, 1024*1024) ); :
UUID
WAL :
gen_random_uuid() N (%) (%) FPI (%) ---- - --- ----------- --- -------- --- XLOG 260 ( 0.15) 13139 ( 0.09) 484420 ( 30.94) Heap2 765 ( 0.45) 265926 ( 1.77) 376832 ( 24.07) Heap 79423 ( 46.55) 6657121 ( 44.20) 299776 ( 19.14) Btree 89354 ( 52.37) 7959710 ( 52.85) 404832 ( 25.85) uuid_generate_v1() N (%) (%) FPI (%) ---- - --- ----------- --- -------- --- XLOG 0 ( 0.00) 0 ( 0.00) 0 ( 0.00) Heap2 0 ( 0.00) 0 ( 0.00) 0 ( 0.00) Heap 104326 ( 49.88) 7407146 ( 44.56) 0 ( 0.00) Btree 104816 ( 50.12) 9215394 ( 55.44) 0 ( 0.00) gen_random_uuid() with fpw=off N (%) (%) FPI (%) ---- - --- ----------- --- -------- --- XLOG 4 ( 0.00) 291 ( 0.00) 64 ( 0.84) Heap2 0 ( 0.00) 0 ( 0.00) 0 ( 0.00) Heap 107778 ( 49.88) 7654268 ( 46.08) 0 ( 0.00) Btree 108260 ( 50.11) 8956097 ( 53.91) 7556 ( 99.16)
,
gen_random_uuid WAL - (full-page images, FPI), . , . FPW , , . , ZFS FPW, .uuid_generate_v1() – . uuid-ossp , RDS Citus Cloud, .uuid_generate_v1:
MAC- . , UUID , , , , .
, , . - ,
uuid_generate_v1mc() , mac- ., , .
:
- .
<table_name>_iduuiduuid_generate_v1(). . , JOIN, ..JOIN foo USING (bar_id)JOIN foo ON (foo.bar_id = bar.id). .- , JOIN, .
- , URL . pg_hashids, .
ON UPDATE RESTRICT, UUID , –ON UPDATE CASCADE. , .
, . , - . , « » .
. -, , , - , ++ , 8 , DevOps . .
Source: https://habr.com/ru/post/348172/
All Articles