Four ways to fool a deep learning neural network

Neural networks are already widely used. Chat bots, image recognition, speech-to-text conversion, and automatic translations from one language to another are just some of the applications of deep learning that are actively supplanting other approaches. And the reason is mainly in the wider possibilities of generalization when processing large amounts of data.
What about targeted attacks? Is it possible to use the features of the work of neural networks and create such data that will be classified erroneously? In this article, we will look at several ways to complement data that delude deep learning neural networks. And what is even more interesting, this data for a person looks unchanged.
Article structure
The article used a number of research papers on adversarial training.
You will need basic knowledge of neural networks like gradient descent (Gradient Descent).
Explanation and examples of the use of competitive training
This is probably one of the first works where it is demonstrated how to distort the pixels of the image so that the classifier makes a wrong decision. The method is based on the fact that images are usually represented as 8-bit values (each pixel can have only one integer value in the range from 0 to 255, that is, a total of 2 values) . Therefore, if the distortions do not exceed the minimum value that can be represented in the image, then the classifier should completely ignore them and consider the distorted image unchanged. But the authors show that this is not the case.
They determine the erroneous classification of input data by the equation
Here
- input data intended to mislead the neural network.
- output data of the classifier according to the unchanged image (which is classified correctly).
- this component of the equation is more interesting. This is a special vector added to the original input data so that the entire network makes an erroneous classification decision. That is, the equation reads like this: “The network may make a mistake in the classification if such data are added to the original input data, so that the result will cause the neural network to relate it to another class”. This is a completely obvious definition. Where is more interesting how to find value .
is defined as:
- this is a sign function. She is responsible only for the sign of value. If the value is positive, the function is 1, if negative, then –1.
- These are gradients (related to input data).
- the cost function (cost function) used to train the neural network.
- model parameters.
- input data.
- the target output, that is, the "erroneous" class.
Since the entire network is differentiable, the gradient values can be easily found using the backpropagation error method (backprop).
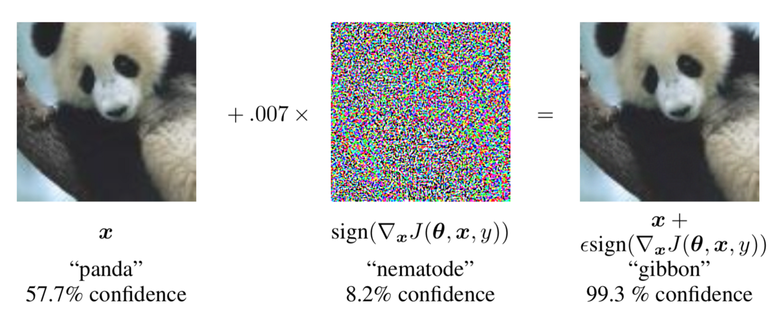
With the help of gradient values, the panda is classified incorrectly.
Therefore, by changing the input data and finding out by analyzing which direction to change (using the information on gradients), you can easily force the network to incorrectly classify the image. In the picture above - the magnitude of the gradients that are applied to the image (in this case equal to 0.007).
One-pixel attack designed to fool deep learning neural networks
In previous work, small changes were sought for the whole image to deceive the neural network. And here the authors went even further. They claim that they do not need to change the entire image. Instead, it is enough to change a small part so that the resulting picture is mistakenly assigned to another class.
For given input probability of belonging to the class equals . The task is described by the equation
- optimized malicious class (adversarial class).
- malicious data (adversarial data) (the same as in previous work), which are added to the input data. However, in this case There is a restriction:
This formula means that the number of elements in the vector must be less than a configurable parameter . means zero norm (0th norm) - the number of nonzero elements in the vector. Maximum value of elements generated , limited, as in previous work.
How to find the right attack vector
In a previous paper, backpropagation (backprop) was used to optimize for the sake of getting the correct values of the malicious data. I believe that it is not fair to give access to the gradients of the model, since it becomes possible to understand exactly how the model “thinks”. Therefore, optimization for malicious input is facilitated.
In this paper, the authors decided not to use them. Instead, they resorted to differential evolution (Differential Evolution). With this method, samples are taken on the basis of which the "child" samples are generated, and then only those that are better than the "parent" ones are left. Then a new iteration of generating “child” samples is performed.
This does not allow obtaining information about gradients, and finding the correct values for malicious input data is possible without knowing how the model works (this is possible even if the model is not differentiable, unlike the previous method).
That's what the authors did:

The result is a single pixel attack. The pictures are changed only one pixel by one, and as a result, the neural network classified them incorrectly. In parentheses are the wrong category after the attack.
For CIFAR 10 value remained equal , that is, only one pixel could be changed. A competitor was able to deceive the classifier, and he attributed the images to completely different classes.
Malicious patch
The adversarial patch is a very recent ( and very popular ) method for generating malicious images. In the previous two techniques, malicious data was added to the original input data. This means that the malicious data depends on the input data itself.
The authors of the malicious patch pick up some data that is suitable for all images. The term “patch” in this case must be understood literally: it is a smaller image (relative to the input images), which is superimposed over the input ones in order to deceive the classifier.
Optimization works according to this equation:
- selected patch.
- target (i.e. erroneous) class.
Here it is interesting that:
This is a patch application feature. In fact, it simply decides (randomly) where and how to patch the input image. - patch itself. - input image. - the place of the patch. - patch conversion (for example, scaling and rotation).
It is important to note that in relation to the above equation, the system has been trained on all images in dataset (ImageNet), on all possible transformations. And the patch deceived the classifier on ALL dataset images. This is the main difference of this method from the previous two. There, the neural network was trained in one image, and this method allows you to choose a patch that works on a large sample of images.
The patch can be easily optimized using the error back-propagation method.
Try it yourself
The author's work provides an image of a patch that can be applied to your images to deceive the classifier. The patch works, even if you print and put it next to the physical object.

"Did you hear that?" Attack to speech recognition systems
You can fool not only models that classify images. The authors of this work demonstrate how to mislead the model of automatic speech recognition.
The peculiarity of the sound data is that the input data cannot be easily changed using the back propagation error method. The reason is that the input data for the audio classifier goes through a transform for which you want to calculate the FFT coefficients (Mel Frequency Cepstral Coefficients, MFCC) , they are then used as input data for the model. Unfortunately, the calculation of the MFCC is not a differentiable function, so optimizing the input data using the error propagation back method will not work.
Instead, the authors used a genetic algorithm similar to that discussed above. The input parent data is modified, resulting in the child data. Those "descendants" are preserved that better deceive the classifier; they, in turn, are also modified, and so on and on.
Conclusion
Deep learning is an excellent tool, and it will be used increasingly. And it is very important to know how to deceive neural networks, forcing them to misclassify. This allows you to assess the boundaries of the alleged deception of such systems and find ways to protect.
Another method of deception has been developed at MIT, but the work has not yet been published. It is argued that this method can achieve a 1000-fold acceleration of the generation of malicious input data. The announcement of the study can be viewed here .
')
Source: https://habr.com/ru/post/348140/
All Articles