Visualization of data for moviegoers: scrap movie recommendations and make interactive graph

Once I stumbled upon an interactive map lastfm and decided to definitely make a similar project for films. Under the cut there is a story about how to collect data, build a graph and create your own interactive demo using the data from a film search and imdb as an example. We will look at the Scrapy scraping framework, go over large graph visualization techniques and deal with the tools for interactively displaying large graphs in the browser.
1. Data collection: Scrapy
As a data source, I chose a film search. However, later it turned out that this is very small and I scraped IMDb. To make a graph, for each movie you need to know the list of recommended films. If you search, you can find enough parsers for movie search and all sorts of unofficial api, but nowhere is there any way to get recommendations. IMDb openly shares its dataset, but there are no recommendations there either. Therefore, there is only one choice left: to write your spider.
On Habré there are already several articles about scraping, so I’ll skip the review of possible approaches. In a nutshell: if you are writing in python and do not want to write your framework, use Scrapy . Almost everything you need is already provided for.
Scrapy is really very powerful and at the same time very simple tool. The entry threshold is quite low, but at the same time Scrapy easily scales to projects of any size and complexity. It really contains everything you need. From tools directly parsing and HTTP requests, processing and saving the received elements, to managing the project work, including ways to bypass the block, pause and resume scraping, etc.
Creating a project begins with the scrapy startproject mycoolproject , after which you get a ready-made structure with the templates of the necessary elements and the files of the minimum working configuration. To make a working project out of this, it’s enough to describe how to parse the page — that is, create a spider and put it in the spiders folder inside the project, and describe exactly what information you want to extract — that is, inherit your class from the scrapy.item class in the scrapy.item script. Thus, you can make a fully working project in less than an hour. There are built-in tools for saving the results: for example, writing to csv or json, but it is better to use an external database if the project is not for five minutes. Behavior associated with the processing of results, including the preservation is specified in pipelines.py . The last important file remains - settings.py whose purpose is clear from the title. Here you can set the project configuration related, for example, using a proxy, timing between requests and many others.
And so, in steps:
- We look in the articles once , twice and in the documentation how to create a project for Scrapy. By analogy, we create our own class for items.
import scrapy class MovieItem(scrapy.Item): '''Movie scraped info''' movie_id = scrapy.Field() name = scrapy.Field() like = scrapy.Field() genre = scrapy.Field() date = scrapy.Field() country = scrapy.Field() director = scrapy.Field() - We are looking for the elements we need on the page and get them xpath. This can be done, for example, through chrome: right-click on an element, select the inspect element, again click the right mouse button in the code, and look for the copy -> xpath item. For debugging, you can run scrapy-shell and transfer the page url to it:
scrapy-shell https://www.kinopoisk.ru/film/518214/. You will have a response object instantiated from which you can get the necessary elements.
$scrapy-shell https://www.kinopoisk.ru/film/sakhar-i-korica-1915-201125/ $response.xpath('//span[@itemprop="director"]/a/span/text()').extract_first() ' ' - We adjust processing of the received objects. I chose to save the record in the sqlite database, because it is very simple.
- We check that everything works by setting the
CLOSESPIDER_PAGECOUNT=5parameter at startup to limit the number of requests. - To battle! Create a directory to save intermediate results, for example
crawls1. Run the spider with thescrapy crawl myspider -s JOBDIR=crawls1parameterscrapy crawl myspider -s JOBDIR=crawls1: now, if something goes wrong, we can restart the spider from the same place where it ended. The relevant section in the documentation .
1.1 Bypass restrictions on the number of requests.
Film search banned me at the stage of debugging a spider, when I sent every few minutes a pack of 5 requests with a timeout of 1 second. To circumvent the restrictions, there are many options. For scrapie, ready-made examples of using a torus, randomly searching a proxy from the list, or connecting to paid rotating proxy services are easy to do. Since we have a “weekend project”, I chose rotating proxy - the fastest option to implement, although I have to connect to a paid service. How it works: you connect to a specific ip: port of your proxy provider, and at the output you get a new ip for each request. From the scrapy side, you need to add one line in your project's settings.py file and in each request, pass a parameter for the ip: port pair.
We are looking for the appropriate section in settings.py and add a line to it:
DOWNLOADER_MIDDLEWARES = { 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware':543 } Then in each request of your spider:
scrapy.Request(url=url, callback=self.parse, meta={'proxy':'http://YOU_RPROXY_IP:PORT'}) The author of the project that inspired me started with Nightwish and then went around lastfm wide recommendations, like a tree - so it turned out to be a connected graph. My approach was similar. From a film search, you can get movies by id, which apparently just corresponds to the sequence number of the movie on the site. If you just take all the id idling up, it will not work out very well, because most of the films do not have recommendations and will be single points that will turn into noise on the map. ID of fresh films have about 500000 order - this is quite a lot for visual drawing, so let's start with the list of the top 250 films and we will iteratively bypass the lists of recommendations of each movie.
I expected to get about 100,000 films, but after the night of scraping it turned out that the spider stopped at ~ 12,600. The recommendations in the film search on this end. As it was mentioned at the beginning, I climbed on IMDb for new data. Scrapping IMDb was even easier. A couple of hours to rewrite the finished project and a new spider is ready for launch. After two or three days of crawling (8 requests per second so as not to become impudent), the spider stopped gathering 173+ thousands of films. The full code of the spiders can be viewed on a githaba: film search and IMDb .
2. Visualization
On the one hand, graph visualization tools are a whole zoo. On the other hand, when it comes to very large graphs, this zoo suddenly scatters somewhere. I have chosen for myself two tools for such cases: these are sfdp from graphviz and gephi . SFDP is a CLI utility with a wide range of parameters, capable of drawing graphs per million nodes, but in our case it is not the most convenient tool, because we need to control the styling process. For cases like ours, Gephi is great - this is an application with a graphical interface and a universal set of styling, for almost every taste.
Exporting data for a graph is done using a simple python script. I usually use the dot format because it is very simple, which is called "human readable". Initially, the format is intended for use in graphviz, but is now supported by many other applications for working with graphs.
Format description
At the beginning we write the header of the digraph kinopoisk {\n and do not forget to write a closing bracket at the end of the file } . In each line we describe the edges of the graph node1 -> node2; and close the list. Description of the format here: official docks and simple examples in wikipedia .
digraph sample { 1 -> 2; 1 -> 3; 5 -> 4 [weight="5"]; 4 [shape="circle"]; } digraph - means that we declare a directed graph. If not directed, then we just write a graph . sample is the name of our graph (optional). Each line contains edges or vertices. If the edges are not directed, then instead of -> we write -- . You can declare edge or vertex parameters in square brackets. In this example, we set the edge between nodes 5 and 4 a weight equal to five, and the top 4 forms a circle. The names of the vertices do not have to be denoted by numbers, they can be strings. For more examples and parameters see the documentation. In our case, the possibilities described above are quite enough.
2.1 Comparison of styling
For large graphs, gephi has two reasonable options: OpenOrd and ForceAtlas 2. OpenOrd is a very fast approximate algorithm, but has few adjustable parameters. ForceAtlas is similar to other classic force-directed algorithms, gives more accurate results, is very flexible in setting, but you have to pay for it with time. Below are examples of the work of both algorithms on a graph that represents a grid.


Model graph-grid. Left OpenOrd, right ForceAtlas.
You might think that OpenOrd should not be used at all if there is time to wait for a more accurate result. In fact, it is not uncommon for graphs to happen when ForceAtlas assembles all the nodes in one tight lump, and OpenOrd shows at least some structure.
To speed up the process, I used OpenOrd as an initial approximation and then “smeared” the graph using ForceAtlas. In order to have at least something clear on the image, you need to eliminate the overlapping of nodes on each other. For this, it is convenient to use the Yifan Hu piling — to smear the clusters a little, and noverlap, to completely eliminate the overlap. On the elimination of the overlay in the graph of kinopoisk, the night was gone, imdb could not be managed for the whole weekend.


3. Export Results: Interactive Map
Gephi can export images to svg, png and many other formats. But with big data come great difficulty. Only one beautiful picture is not enough. We want to see the names of the films and how they are related. If we draw the labels of the nodes, then with such a number of them we will get a completely unreadable loop of letters. There are options to use SVG and scale it until something becomes visible, or to draw only the most important tags. But there is a better option, on which I decided to focus. Making an interactive map.
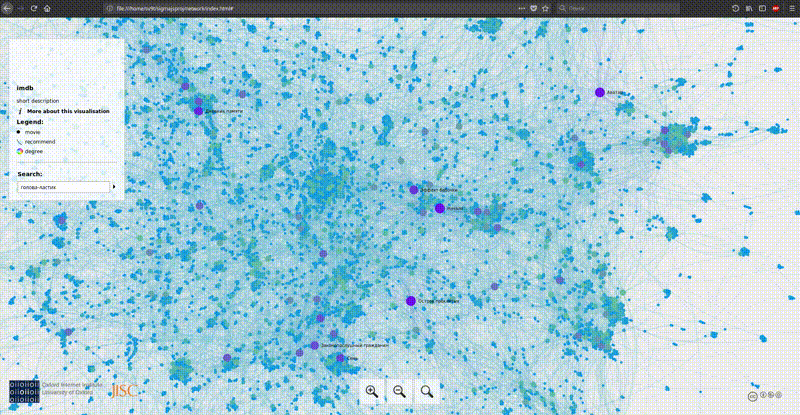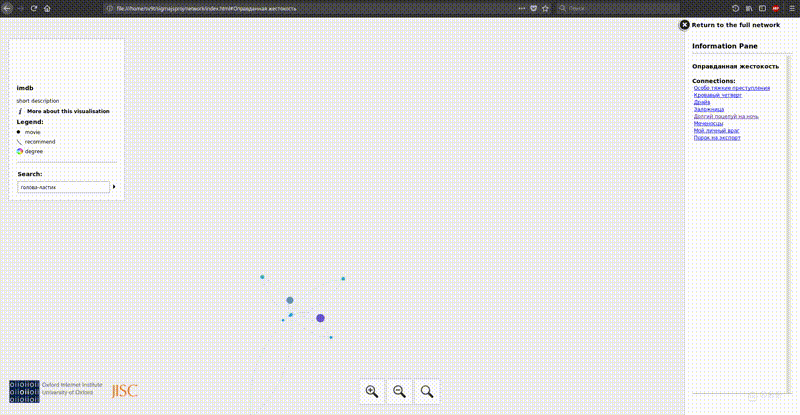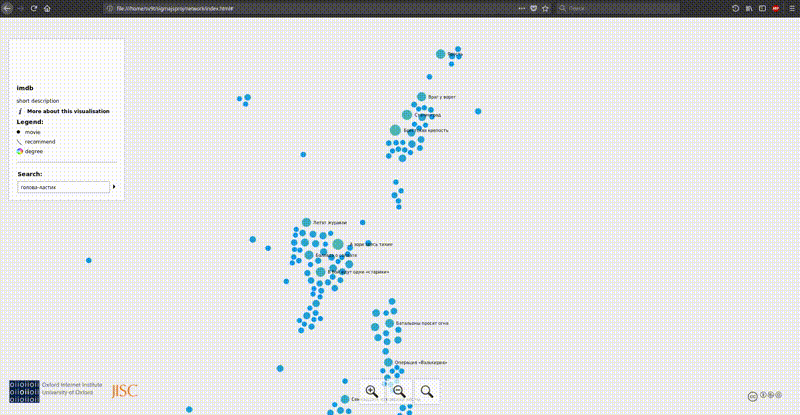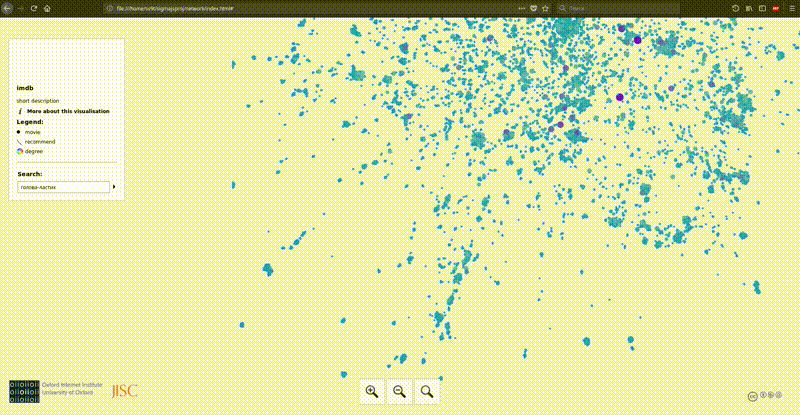
Tool overview:
sigma.js
The first option, one of the simplest and at the same time the most obvious, is a plugin for gephi with export to the sigma.js template. On the gif above it just. Install the plugin via the gephi menu, after which we have a new export menu item in the file tab. We fill in the form, export and get ready-made working visualization. Simple and powerful. The result can be seen here . Disadvantage: on large graphs, the browser barely copes.
gefx-js
The next option is even simpler than the previous one and is generally very similar. gefx-js - you just need to export your project from gephi to gexf format and put it in a folder with a template. Is done. The disadvantage is exactly the same as in the previous case. Moreover, if using sigmajs I could view the imdb graph at least locally, then with gefx-js it simply did not boot.
openseadragon
For cases when you need to show a very large picture there is a seadragon . The principle is exactly the same as when rendering geographic maps: when scaling, new tiles are loaded that correspond to the current zoom and viewport. That is exactly what the author of the project that inspired me did. Lack of one: interactivity at least. It is impossible to select nodes, it is difficult to see where the edges go. It is impossible to "look behind" the overlap of nodes and edges.
shinglejs
But what if you made something like a mixture of the previous versions, so that when scaled, the graph was loaded with tiles, but not with pictures, but as in the first case, with interactivity of nodes and edges? The finished solution was literally a miracle, it is shinglejs .
Pros: You can render very (very, very) large graphs in the browser, while maintaining interactivity.
Cons: Not as beautiful as sigmajs, data preparation is not trivial.

Not so beautiful, but very bright
To visualize the imdb graph, I chose the last option. There was no choice in general. The result can be seen here , and then a little bit about how to prepare the data for such visualization.
Export data to shinglejs:
As I have already said, exporting data in the latter case is not very simple, so I will give an example of how to unload a graph from gephi for shinglejs.
- Exporting a graph from gephi in gdf format is probably the only easy way to get the coordinates of nodes in a table. The file structure is this: first there is a table with a description of nodes, then a table with a description of edges.
- We read the file and we get from it the description of tops and edges. I did this with pandas, then chopped the data frame into two: edges and nodes. About working with pandas .
- We change the names of the columns in accordance with the shinglejs docks and export them to json. Shinglejs does not support direct export of flowers, but for each node you can specify "communities" and color them already. Therefore, the film ratings are unloaded as community tags.
- In the source code of the main page, do not forget to specify a list of colors for communities. To color a node from the list of colors, the element with the number is taken which is calculated as follows:
id %. - We glue the files into one. I did this through bash:
cat start imdbnodes.json middle imdbedges.json end > imdbdata.json, after creating thestart, middle, stopfiles with the contents of "{"nodes":", ", "relations":" and "}, respectively . - Further, according to the instructions from the office. the site
- Do not forget to create a bitmap and put it in the folder with the graph data, otherwise at a great distance you will see only a few nodes or nothing at all. The author of the project, it seems, did not specify this detail, but by default the example will try to load the files
image_2400.jpgandimage_1200.jpg, and not npm as it may seem after building the default project.
4. Interesting observations
On the column lastfm there is an obvious clustering associated with the countries of origin of musical groups, for example, Japanese pop and rock, Greek metal, etc. Exactly the same thing happens with movies. Korean, Turkish, Japanese and Brazilian films are very clearly separated. In imdb, a large cluster of cartoons stands out far from the main mass. On both graphs, a cluster of films about superheroes from comics is going very tightly. It seems to be obvious, but nevertheless, unexpectedly, that bad films gather in one big cloud. There are separate clusters of music videos, children’s youtube blogs and fan movies around the Harry Potter universe.
5. What else can you do with this data?
I am sure that readers will be able to come up with and make on the obtained data many more interesting projects. Such ideas immediately come to my mind:
- Cluster and compile thematic collections. I worked perfectly DBSCAN almost from the first call. (An example will be next)
- Make your own recommendation systems
- Collect interesting statistics about films in general
- Of course, expand your movie library.
5.1 DBSCAN
There are many special methods for graph clustering, and all of them are worthy of individual articles. I used the method for the graphs not intended as an experiment. The reasoning was as follows: once the graph has visually decomposed into clouds of similar films, the areas where films are especially close together can be found using DBSCAN . Let's see what this method does, without going into deep details. The name DBSCAN stands for density-based scan, that is, using this method, we merge points that are quite close to each other. This is formalized through two main hyperparameters - this is the radius in which we are looking for neighbors for each point and the minimum number of neighbors.
1. Get the coordinates.
To do this, export our graph from gephi in gdf format. We read the file as a csv with pandas:
data = pd.read_csv('./kinopoisk.gdf') # gdf - # , # pandas , # nan data_nodes = data[data['y DOUBLE'].apply(lambda x: not np.isnan(x))] Let's draw now and see what it looks like.
plt.figure(figsize=(7, 7)) plt.scatter(data['x DOUBLE'].values, data['y DOUBLE'].values, marker='.', alpha=0.3); 
Great, DBSCAN should handle this.
2. Clustered.
We select the parameters and look at the distribution of cluster sizes. No serious work was planned, so I evaluated the quality "by eye".
from sklearn.cluster import DBSCAN coords = data_nodes[['x DOUBLE', 'y DOUBLE']].values dbscan = DBSCAN(eps=70, min_samples=5, leaf_size=30, n_jobs=-1) labels = dbscan.fit_predict(coords) plt.hist(labels, bins=50); 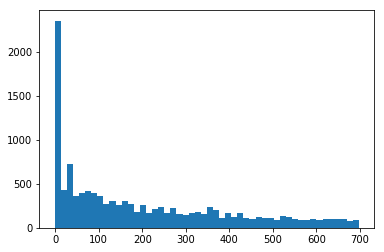
Cluster size distribution
Let's color our dots in the colors of the clusters and see how the result is similar to the truth.
plt.figure(figsize=(8, 8)) for l in set(labels): coordsm = coords[labels == l] plt.scatter(coordsm[:,0], coordsm[:,1], marker='.', alpha=0.3); 
Looks like what we wanted to get.
Let's try to get a cluster of a movie in the form of a list. I did not take care of making a convenient way to get the list, so this time without a code. Below is a list of films that fall into one cluster with the "real ghouls." In my opinion not bad.
| movie_id | name | date | genre | country | director |
|---|---|---|---|---|---|
| 271695 | Third planet from the sun | 1996-01-09 | fantasy | USA | Terry Hughes |
| 663135 | Neighbors | 2012-09-26 | comedy | USA | Chris Koch |
| 277375 | Aliens | 1997-11-07 | a cartoon | France | Jim Gomez |
| 81845 | Sweeney Todd, Demon Barber of Fleet Street | 2007-12-03 | musical | USA | Tim Burton |
| 445196 | Hands and legs for love | 2010-10-29 | thriller | Great Britain | John landis |
| 271878 | Red hotel | 2007-12-05 | comedy | France | Gerard Kravchik |
| 3609 | Plunkett and Maclaine | 1999-01-22 | action movie | Great Britain | Jake scott |
| 183497 | Bourke and Hare | 1972-02-03 | horrors | Great Britain | Vernon Sewell |
| 3482 | Doctor and Devils | 1985-10-04 | horrors | Great Britain | Freddie Francis |
| 2528 | Values of the Addams Family | 1993-11-19 | fantasy | USA | Barry Sonnenfeld |
| 503578 | Lullaby | 2010-02-12 | fantasy | Poland | Julius Makhulsky |
| 87404 | Red Tavern | 1951-10-19 | comedy | France | Claude Otan-Lara |
| 5293 | Addams Family | 1991-11-22 | fantasy | USA | Barry Sonnenfeld |
| 18089 | Body Snatchers | 1945-02-16 | horrors | USA | Robert Wise |
| 271846 | Seller of the dead | 2008-10-10 | horrors | USA | Glenn MacQuade |
| 272111 | Freshly buried | 2007-09-09 | drama | Canada | Chaz Thorn |
| 34186 | Elvira: Master of Darkness | 1988-09-30 | comedy | USA | James Signorelli |
| 818981 | Real ghouls | 2014-01-19 | comedy | New Zealand | Jemaine clement |
| 8421 | Edward Scissorhands | 1990-12-06 | fantasy | USA | Tim Burton |
| 5622 | Sleepy Hollow | 1999-11-17 | horrors | USA | Tim Burton |
| 2389 | Beatlejus | 1988-03-29 | fantasy | USA | Tim Burton |
This approach seems to me interesting because we get a list of similar films that are not necessarily linked by direct recommendations, and are not even necessarily achievable in a small number of steps when traversing the graph. That is, so you can find a movie that will fall if you simply click on similar movies directly on the site.
')
PS
Thanks to all the friends who were ready to answer my questions, to all movie lovers - new discoveries, and to the quality data datasaentists!
Source: https://habr.com/ru/post/348110/
All Articles