Robots instead of the best employees: machine learning for expert answers
One of the current Devim projects is the development of a scoring service for a microfinance institution (MFI). The project was carried out by our Data Science team Andrei Davydenko and Dmitry Gorelov datasanta . We talk about what tasks were solved, what factors were taken into account, as well as the results obtained. The basis of the currently proposed solution is the approach in which automatic processing of applications is carried out taking into account the probability of rejection / approval of similar existing applications by underwriters (experts). This approach made it possible to carry out the project in a short time and take into account some features of business goals. Among the interesting results: as it turned out, the decisions of underwriters when issuing loans can be accurately predicted by a statistical model ( AUC > 0.93).
We hope that the publication will be of interest not only to specialists in scoring, but also to everyone who is interested in machine learning and its application in practice.
Material prepared by Data Science team Devim 
Content:
- Introduction
- Problems of training models without the answers of experts
- Project Phases
- Autoscore
- 4.1. Understanding of business goals
- 4.2. Preparation and study of data
- 4.3. Simulation and evaluation
- 4.4. Implementation and next steps
- 4.1. Understanding of business goals
- Other uses
- Advantages and disadvantages of the approach
- Conclusion
Literature
1. Introduction
More and more companies want to replace employees with robots. The goal is to reduce costs in the face of increasing competition in the markets and rising salary expectations of employees.
But the implementation of the algorithm underlying the actions of the robot is not always a trivial task. For example, processing a customer's request in a queuing system may include analyzing various factors, including age, income, customer relationship history, and information about the current situation in the company. This requires taking into account short-term and long-term business goals. Often, all these factors are difficult to formalize and even list. However, experts who are well aware of the specifics of a business can make decisions effectively enough to ensure the desired performance of the company. The cost of the work of experts is quite high, to find or “grow” an expert in the company is a long and laborious process. The question boils down to how to teach the robot to do the work of an expert.
We are considering an approach based on “copying” the actions of an expert. It is assumed that there is a database of observations with parameters of possible situations and information about the actions of experts in relevant situations. Through the use of a model that has been trained according to the available data, it becomes possible to take part of the decisions automatically, thereby unloading or “replicating” employees.

We analyze the advantages and disadvantages of this approach and illustrate it on the example of our experience in implementing autoscoring for MFIs.
2. Problems of training models without the answers of experts
There is an alternative approach when the model predicts not the expert’s decision, but some target indicator (target variable). When it comes to issuing loans, the model can be trained to predict late payments under the contract. However, here a number of issues arise that require substantial costs for their solution. As a result, the decision will still be partly subjective.
First, the choice of the target variable is not obvious . For scoring the target variable, a delay of 15 days or 30 days or some other number of days can be selected. How the probability of delay is transformed into the final decision on approval / rejection of the application also remains a question. These issues need to be addressed on the basis of the ratio of losses from non-return and profit upon return, which requires a special study for a specific MFI and is associated with significant time and money costs. In addition, the company's current goals may conflict with the target variable: for example, launching an advertising campaign to increase the flow of customers will result in solutions that are not optimal in the short-term period of such an action.
Secondly, data for training , including the values of the target variable of the model, may be missing . For example, when creating a new product / opening a branch in a new city or country, it is impossible to immediately obtain information about the target.
Third, since there are no data on loan defaults for rejected applications, autoscoring will most likely produce incorrect predictions of non-return . This problem is known in the literature as analysis of rejected applications or reject inference. The nature of the dependencies between the target variable and the characteristics may be different for samples with approved and rejected applications. Then the selection properties of approved applications will differ from the selection properties of all applications, so-called. TTD sampling (TTD = through-the-door). For the same reason, it is impossible to assess the quality of the model (for example, by the AUC criterion) with reference to the TTD sample. However, in the end, it is the TTD indicator that should characterize the performance of the model.
The problem of analyzing rejected applications is described in the literature (Anderson, 2007) ; relevant special tools were developed as part of autoscoring systems such as SAS and Deductor. But the available solutions are still based on the task of the parameters determined subjectively.
When the model is trained according to the experts' answers, the above questions are not so critical, because: 1) the target variable is determined, 2) data can be obtained in the required amount by interviewing experts, 3) TTD sampling is used.
3. Project Phases
The implementation of intelligent data processing systems includes a large number of interrelated tasks that must be solved in a certain order. In order to regulate the process of implementing a data analytics project, many firms use the CRISP-DM standard (Cross-Industry Standard Process for Data Mining - a cross-industry standard process for data mining) (Shearer, 2000) . The CRISP-DM methodology allows you to formalize tasks and document project progress in order to use resources efficiently.
According to CRISP-DM, the project includes the following phases:

In the case of our approach, CRISP-DM is also applicable. The following describes (simplified) the tasks that we solved, and how they relate to the phases of the standard.
In order to reduce publication and to maintain commercial secrets, we do not give some details, focusing on the main results of the project.
4. Autoscore
4.1. Understanding of business goals
Project Background
The task of refusal / approval of an application submitted to the MFI for a one-time repayment loan is automated. The decision must be made on the basis of a set of data about a potential client.
Input information:
- Profile data (name, income, marital status and other information)
- Credit amount
- Information from the credit bureau “Equifax”, including a scoring score (product “Scoring MFI 2.0”) and information on each client’s loan agreement
- The results of the query in the data bank of the enforcement proceedings (DB IP)
It is important that the information of the CII is paid. Therefore, it is advisable to request it only when it is impossible to make a decision on approval / refusal on the basis of other information.
Applications are processed manually by underwriters based on the aggregate of available information, including the BKI reports.
Goals and success criteria
The model should automate the decision making process and make a decision instead of the underwriter.
Model output is one of three options:
- Automatically approve;
- Automatically refuse;
- Submit underwriter.
Ultimately, the goal is to reduce the costs of processing applications by automatically processing part of the traffic, while not greatly reducing (preferably, not reducing at all) the quality of decisions on requests.
Tasks and success criteria:
Problem number 1: Auto-failure on the database IP
In many cases, the database IP contains information that is already enough to refuse to issue a loan.
It will be considered a successful model of auto-failure, which will almost accurately be able to predict the refusal for the client on the basis of the information of the database IP, questionnaire data and the amount of the loan. Such a model will save resources on requests to the CIB and manual processing of traffic.
Problem number 2 : Auto-approval or auto-cancel on the basis of all information (including the response from the CII)
If the model of auto-failure on the data base of the IP has not determined the automatic failure, a model is needed that uses information from the CII to automatically make a decision on the application.
In this case, the model will be successful if it is possible to ensure a sufficiently low level of discrepancies between the decisions on the model and the decisions of the underwriters. The maximum allowable percentage of discrepancies must be established based on stress testing. The model found will save resources on manual processing of traffic, and will also create the basis for scalable solutions (including for the automatic issuance of loans online).
The deadlines of the project were quite short (3 months), so the team tried to find the most simple solution, which, however, would lead to an acceptable result.
4.2. Preparation and study of data
Data on applications were collected over a period of six months. Accordingly, for each application there was a decision of the underwriter. The accept rate is quite low — less than 10%. And for applications for which records are found in the IP database, the accept rate is even lower. With such an accept rate, it is difficult to obtain a reliable model for predicting default due to the previously described problem of analyzing rejected applications (aka reject inference ).
Prediction of underwriter's decisions is a simpler task, since approvals / waivers are known for all applications (except pending).
As part of the applications, there was a credit history (CI) in XML format. Each CI has been converted to a feature set for a specific application. We followed the common guidelines for identifying a feature set for KI-based autoscoring. Very rarely, when describing information on loan agreements, there were data omissions or errors / inaccuracies (for example, there were no dividers between rubles and kopecks).
The IP PI was used: for each application, for example, there is a number of IP on a given client, as well as a total debt in rubles.
According to the personal data additional signs were generated. For example, the gender of the client based on the last letters in the middle name and last name.
Numerical characteristics were converted to obtain symmetric distributions and to analyze emissions. In particular, it was found that the Box-Cox method can be used to obtain close to normal distributions. Indicators in rubles (such as amounts of arrears) have a log-normal distribution, which simplifies the analysis. Emissions were determined by the Tukey method .
In general, there were no significant problems with the quality of data that could affect the quality of the model - the data are fairly complete and correct.
4.3. Simulation and evaluation
Problem number 1
For the implementation of auto-failure on the basis of the questionnaire and the database IP, logistic regression was applied. The underwriter solution was used as the target variable. That is, the regression model in this case estimates the probability that the underwriter will decide to refuse to issue a loan. If the probability is high enough, the application can be automatically rejected.
The advantages of logistic regression consist in a simple interpretation of the results, the possibility of checking assumptions, the transparency of the algorithm for business, and the speed of implementation of the auto-failure service.
In the course of building an auto-failure algorithm, two basic questions need to be solved: 1) how to select features, 2) how to choose a threshold probability value.
For the selection of signs, the algorithm was used stepwise regression . This algorithm successively excludes variables from the model in order to find the best model by optimizing the value of the information criterion.
The nature of the dependencies between the probability of failure and the set of features for applications where income is indicated, and for applications with zero income, differed significantly. Therefore, as a result, 2 logistic regression models were obtained.
The following characteristics were used to assess the quality of the model and select a probability threshold value. Having constructed a sequence of possible threshold values (from 0 to 1 with a step of 0.01), we have defined for each possible value:
- What percentage of traffic will be automatically diverted by the auto-failure model;
- How many approvals (applications that underwriters could approve) will be mistakenly rejected by the auto-failure model (as a percentage of the total current number of approvals).
The relationship between these indicators is displayed on the graph:
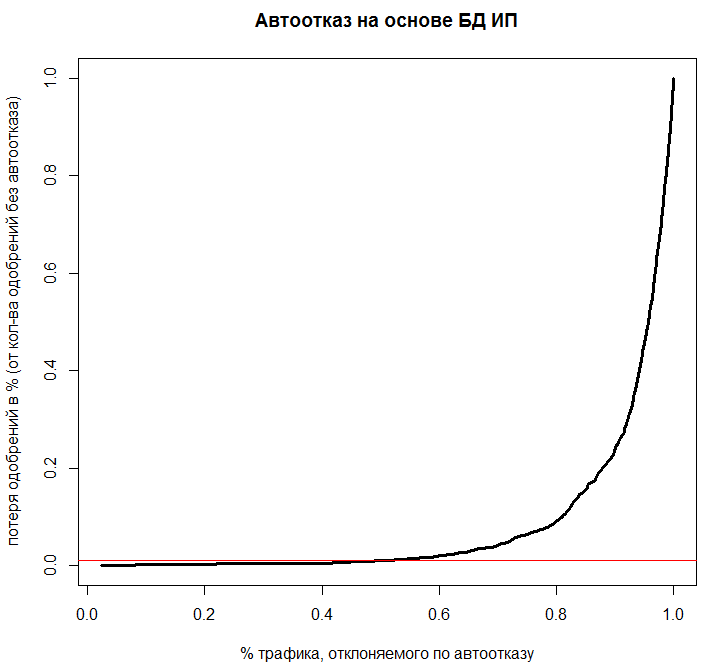
The graph shows that when a deviation of 40% of traffic according to a model of auto-failure, no more than 1% of “good” applications will be rejected (ie, those that the underwriters would approve). Such a compromise was assessed as advantageous on the basis of an analysis of the ratio of the price of purchasing additional data for rejected bids and the lost benefit from “good” bids.
Problem number 2
Used standard methods for the task of autoscoring. However, the important difference is that the underwriter's binary answer was used as the target variable. Signs include information from the CII and data from the questionnaire.
A random forest algorithm was used to predict the target variable. Due to the fact that the value of the target variable is known for the entire TTD sample, the quality of the model can be assessed by all available observations. During cross-validation, the value of AUC = 0.93 was obtained, which characterizes the high accuracy of the model:
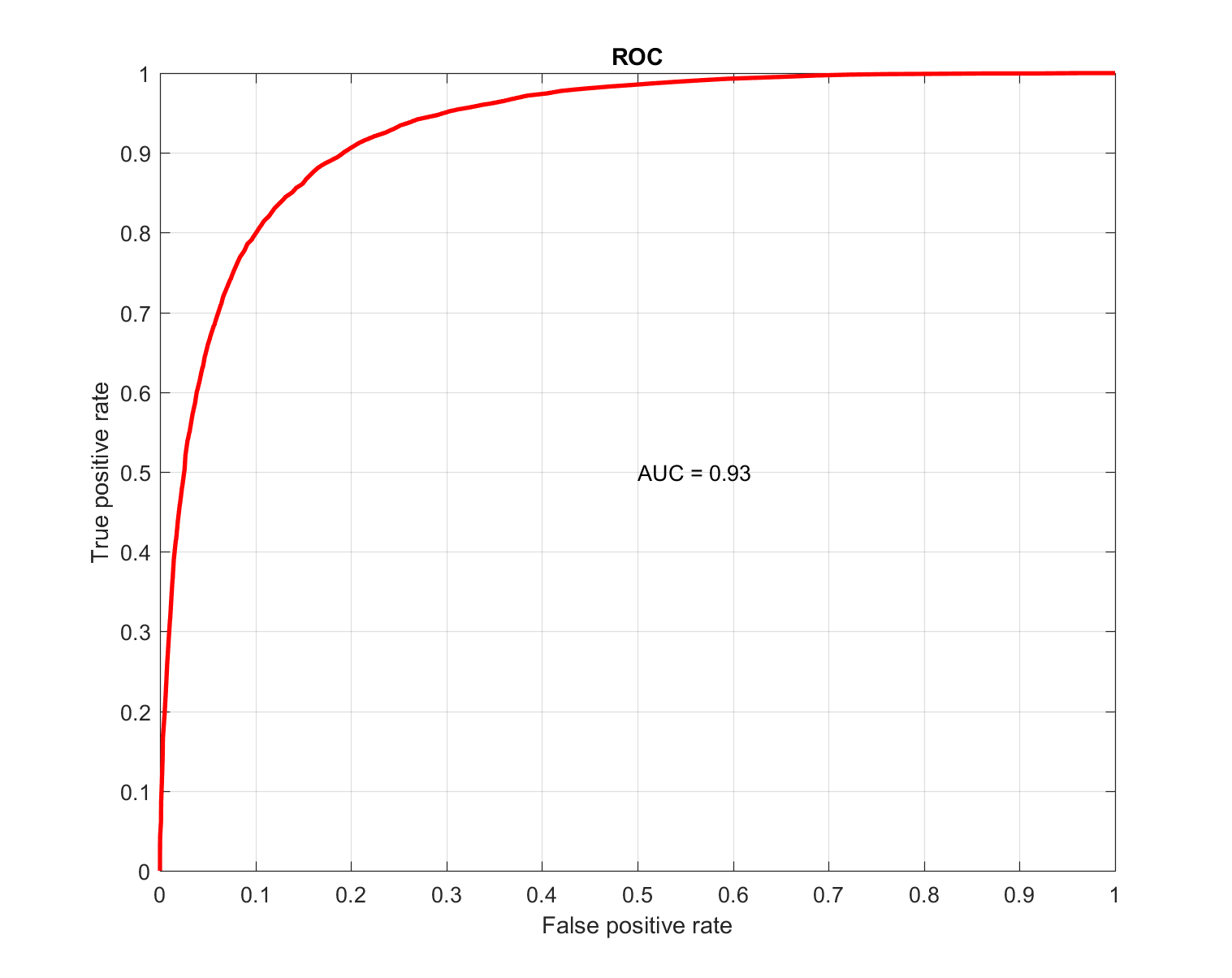
Also, by analogy with task 1, a relationship was built between the percentage of automatically processed traffic and the percentage of inconsistencies between the solutions of the model and the underwriters. Under the test sample, underwriters' solutions and models differed in no more than 7-8% of cases. In general, during the stress tests, these indicators were acceptable for the model to work in automatic mode.
4.4. Implementation and next steps
To monitor quality in real-time mode, the following metrics are used:
- Specificity (aka true negative rate) - the percentage of the coincidence of the model's decisions with the decisions of the underwriter on failures;
- Recall (aka true positive rate) - the percentage of coincidence of the model’s decisions with the decisions of the underwriter for approvals;
- Accept rate - the percentage of approved applications (must match the accept rate of underwriters).
Further directions are the addition of new features and the use of combined training schemes for the model, when the target variable is not only the fact of approval / rejection of the application, but also data on the real delay. The implementation of such a solution requires the study of possible effects arising due to the lack of data on rejected applications.
5. Other uses
In addition to credit scoring, training according to expert answers can be applied to a huge variety of tasks: estimating the cost of used cars, evaluating real estate, evaluating the effectiveness of advertising campaigns, and even choosing the color of lipstick or selecting gifts.

6. Advantages and disadvantages of the approach
Benefits
- The main advantage of the model (compared to the classical approach) is the speed of implementation, saving resources in developing the system and the ability to evaluate the quality of solutions using simple metrics;
- No need for “analysis of rejected applications”;
- With this approach, we are not trying to detract from the role of an expert and fully automate the task (implementation of an approach with less risk will be perceived as hostile compared to full automation). On the contrary, the value of the expert only increases. In this case, the expert may spend more time on consideration of one case / application when making decisions.
disadvantages
- Nonoptimality It is known that human judgments in conditions of uncertainty are suboptimal and contain systematic errors (Tversky & Kahneman, 1974) . Experts may overestimate / underestimate the likelihood of certain events, which ultimately leads to non-optimal results of the model trained by the answers of experts. Also, experts cannot effectively assess the impact of a combination of a large number of factors on a target indicator; therefore, heuristics are used, i.e. Estimate really existing dependences in a simplified form.
- Required amount of relevant data for training. For example, manual underwriting should still be maintained for a training sample and continuous online testing and quality monitoring.
7. Conclusion
The result of applying the approach is the possibility of scaling up a business ten or more times. Acceptable indicators of the percentage of automatically processed traffic and the number of discrepancies with the solutions of underwriters were achieved. Underwriting model training has made it possible to speed up and simplify the process of implementing autoscoring and fits well with the CRISP-DM methodology.
In general, “copying” experts can have a positive impact on the return on investment (ROI) for projects to develop and implement intelligent data processing systems.
At the same time, a number of features of this approach should be taken into account. Firstly, the approach is not optimal in terms of minimizing risks or maximizing profits, but at the same time it allows you to save on expert fees and / or get a scalable system. Secondly, expert decisions must be sufficiently substantiated and effective for this to be used as a model for teaching the model. That is, experts really should give good answers, which generally lead to the desired results.
The trained model can also be considered as a temporary, but workable solution to the problem. At this time, data can accumulate and develop a better solution based on the addition of a target indicator to the model, which must first be selected and justified.
Literature
Anderson, R. (2007). Credit scoring toolkit: theory and practice for retail credit risk management and decision automation. Oxford: Oxford University Press.
Shearer C. (2000). The CRISP-DM model for the new blueprint for data mining, Journal of Data Warehousing , Vol. 5, pp. 13-22.
Tversky, A., Kahneman D. (1974). Judgment under Uncertainty: Heuristics and Biases, Science , New Series, Vol. 185, No. 4157. (Sep. 27, 1974), pp. 1124-1131.
')
Source: https://habr.com/ru/post/348092/
All Articles