Gas savings in smart Ethereum contracts
In Ethereum, each transaction requires a certain amount of gas - a special entity. There are different ways to reduce costs. Some of them have already been implemented. I want to start by discussing the issue of optimizing the cost of creating a smart contract.
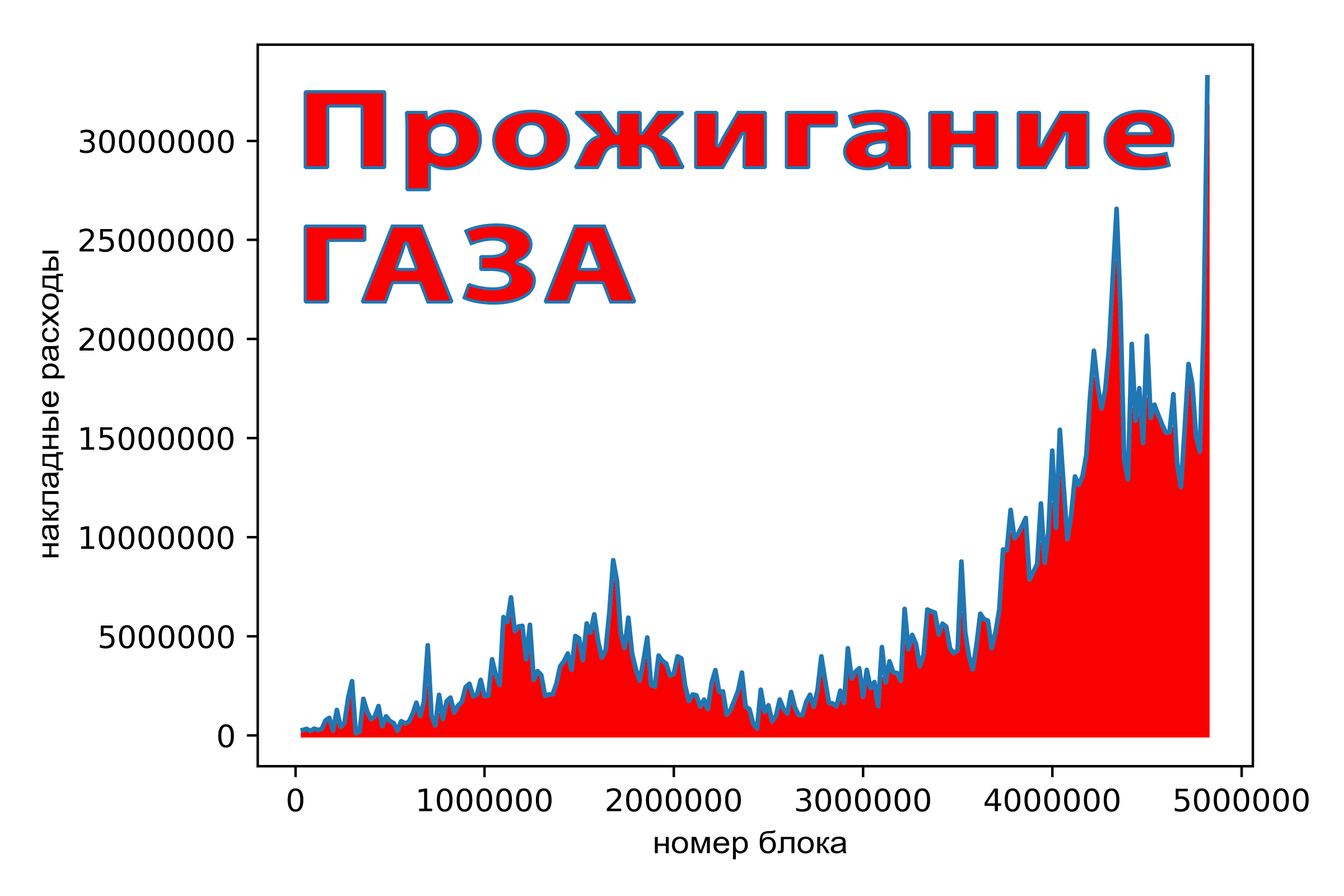
As you can see, you can significantly reduce gas consumption, reducing costs. Before we get into the details let's discuss the issue of optimizing programs.
How do optimizers work?
Let's look at the following simple C program.

The program will take some time to execute if compiled without optimization. If you run an optimized version of the program, it will be executed instantly. The reason is that the compiler will find that the variable x in the main () function is not used anywhere in the following code, so the function call calculate () can not be executed at all. Here is the result of the optimization:

Let's slightly change the return value in the original main () function as follows:

Now the compiler will be powerless to help us with optimization. Only manual optimization remains.
Manual optimization
Immediately, I note that manual optimization is a creative process, since there are many places and opportunities for improvement in real-world programs. On the other hand, we can use the profiler to look for bottlenecks in the program. And when the problem is localized, you can use one of the many approaches to optimization, more efficient algorithms, and so on.
Let's take a close look at the calculate () function from the previous example. At each iteration of the inner loop, the variable r changes from 0 to 1 and vice versa. The initial value is 0, so we only need to know whether the number of iterations will be even or not. If at least one of the parameters a or b is even, then there will be an even number of iterations, so the return value will be 0. Thus, we obtain the following optimized version of the function calculate () :

Dangerous optimizations
Optimizations are good because they speed up the program, reduce memory consumption or I / O operations, and so on. At the same time, optimizations can degrade performance or even prove dangerous.
One of the problems associated with various environments and parameters. For example, the program was optimized for running on a cluster, and we use it on a separate computer. Or the program is optimized for speed and all input files are fully loaded into RAM. Most likely, there will be problems if there is not enough memory for too large files.
Sometimes optimizations can lead to a security issue. (Here you can also remember about Specter with Meltdown.) Many programs use the standard memset () function to clear variables with confidential information, such as keys and passwords. But compilers often simply remove these calls, since the updated values of variables are not used further. Until recently, the cleanup function in the OpenSSL project was as follows:

Of course, the problem with the memset () function is an exception to the rule. Optimizers generate the correct code, and circumstances of use can lead to errors. But the source of the incorrect code is people.
Manual optimizations are very dangerous. Earlier, I showed an optimized version of the calculate () function, but this was an incorrect optimization. It all started with a true statement:
If at least one of the parameters a or b is even, then there will be an even number of iterations, so the return value will be 0.
This is an implication, so under a false condition, the result can be anything. Is a situation possible when both a and b are odd, but the number of iterations will be even?
The answer is yes. If the value of either a or b is negative, then there will be no iteration at all. Therefore, a correct manual optimization will result in the following code:

Ethereum Virtual Machine
The Ethereum Virtual Machine (Ethereum Virtual Machine, EVM) is the main hardware of the Ethereum platform. In simplified form, its architecture is presented in the following diagram:

Three types of memory can be distinguished: account balances (balances of accounts), contract code (code) and contract storage (storage). Each account (personal wallet or contract) has its own balance in Ethereum currency (ETH). For each smart contract its code is stored (executable program for EVM), as well as its own memory for storing variables. The contract code does not change after creation.
Ethereum blockchain consists of many blocks in a certain order. Each block is a set of transactions and receipts. The state of EVM (its memory) is completely determined by the entire set of previous transactions. To get an EVM state at time N, we must take an EVM state at time N-1, and then execute all transactions from block N. Therefore, knowing all blockchain transactions, we can determine the state of EVM at any time in the past. The process is illustrated in the following diagram:
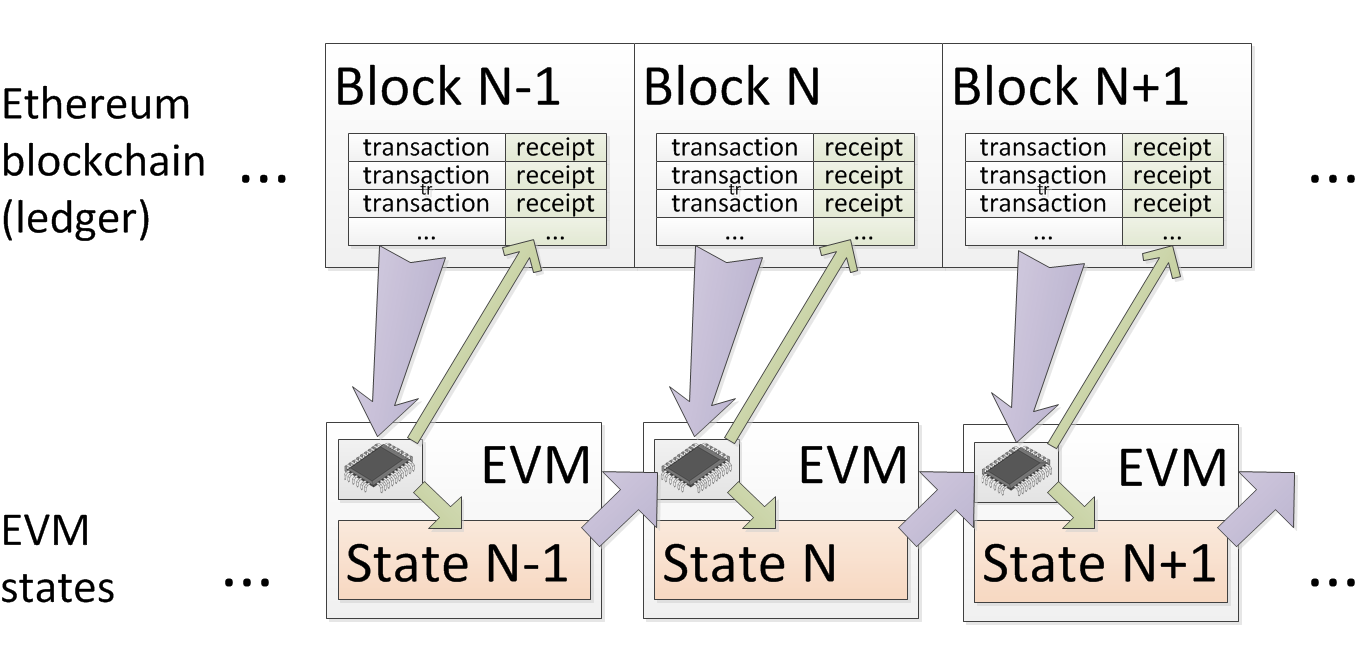
I note that if we fix the state of EVM at the moment M, that is, the state of EVM, which will be unattainable in the future regardless of the transactions performed after the block M.
Consider two sets of transactions: T and U. I will call these transactions "equivalent" if the processing of transactions T in block N will lead EVM to an "identical" state as processing U instead of T in the same block N. I put in quotes, since it is allowed the difference in the balance of the sender and the miner of the N block due to the difference in gas costs between the sets of transactions T and U.
All time and memory costs are included in the cost of gas, so the main goal of optimization is to reduce gas costs. One of the approaches to optimization is the search for "equivalent" transactions with lower gas costs. It is about removing the redundant code, but not changing the algorithms, etc. Similar to the first example with the calculate () function above.
Creating smart contracts
There are two different types of transactions. Now I am going to discuss only the transactions for creating smart contracts. The contract creation transaction performs two basic actions in EVM: it initializes the storage of the contract and saves bytecode. Initialization of the repository is the result of invoking the contract constructor with the migration parameters. All other contract methods are stored in code. This process is depicted in the following diagram:

The question of optimizing the contract code will leave for future articles. Today we will focus on optimizing the contract deployment code.
Contract Deployment Code Optimization
In the previous section, we discussed that there is an obvious optimization goal - minimizing gas consumption. At the same time, it is necessary to make sure that the optimized transaction is "equivalent" to the original one.
I used the original contract deployment bytecode, available from the Ethereum blockchain. No contract source code was required for this task. After that, I performed a trace of the contract deployment performance and left only the required code. The process of optimizing the code can be represented as follows:

The previous example is simplified, although the approach used may be applicable to more complex transactions.
Lower score
The execution of each individual instruction in EVM has its cost in the amount of gas. Although there are many ways to achieve the same result, we can easily get a lower bound. To do this, sum up the following numbers:
- Payment for contract deployment code data;
- The fee for creating a contract;
- The number of different variables in the storage multiplied by the cost of the SSTORE operator;
- The size of the contract byte-code in words multiplied by the cost of writing to memory and the cost of the RETURN instruction;
- The number of events multiplied by the corresponding cost.
This lower bound can be used as the basis and goal of optimization.
Here he assumed that the contract byte-code would be copied from the deployment transaction data. On-the-fly bytecode generation situations are exceptions.
Statistics and results
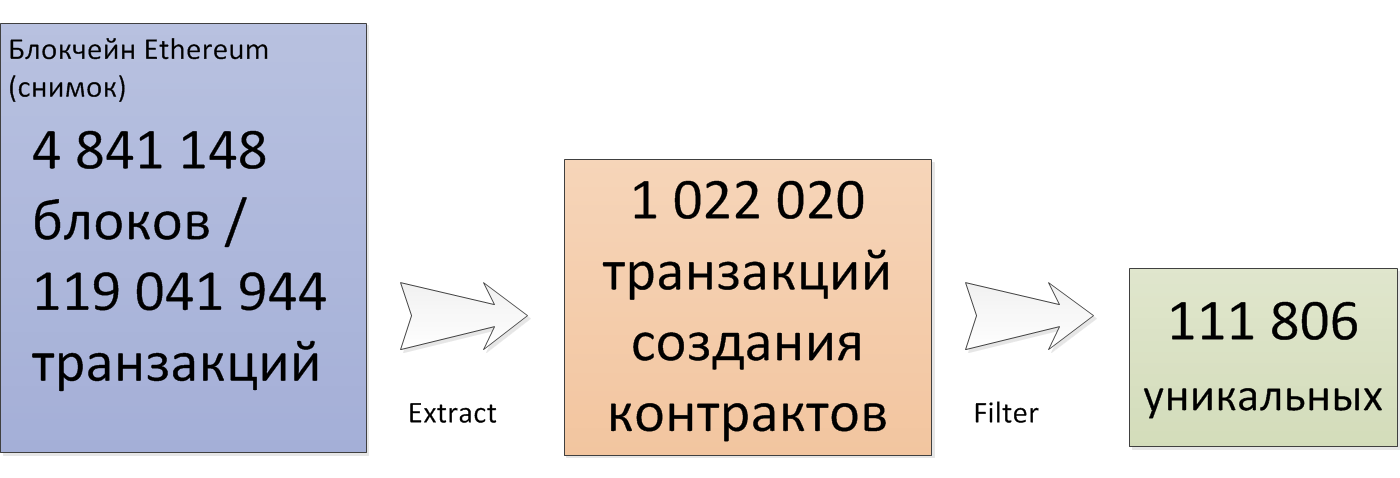
I took a snapshot of the Ethereum blockchain on block # 4841148. At this point in the blockchain, there were 119041944 transactions, of which only 1022020 transactions to create a contract. I compared the input data of these transactions and found 111806 unique contract deployment codes.
Each of the unique deployment codes launched in the Ganache CLI (formerly TestRPC) and received a receipt of execution and a contract byte code. Simultaneously, I performed a naive optimization, and also considered the lower bound. The optimized code was tested on the local blockchain, after which the results were compared with the source code. The process is illustrated in the following diagram:

During processing, he ignored the erroneous transactions and contracts that other contracts created. I call the optimizer naive, because it ignores any values previously obtained on the stack, creating new ones each time.
For each processed transaction received three numbers: the initial processing costs, the costs for the optimized version and the lower estimate. All values were calculated in the current value of transactions. The following results were obtained:
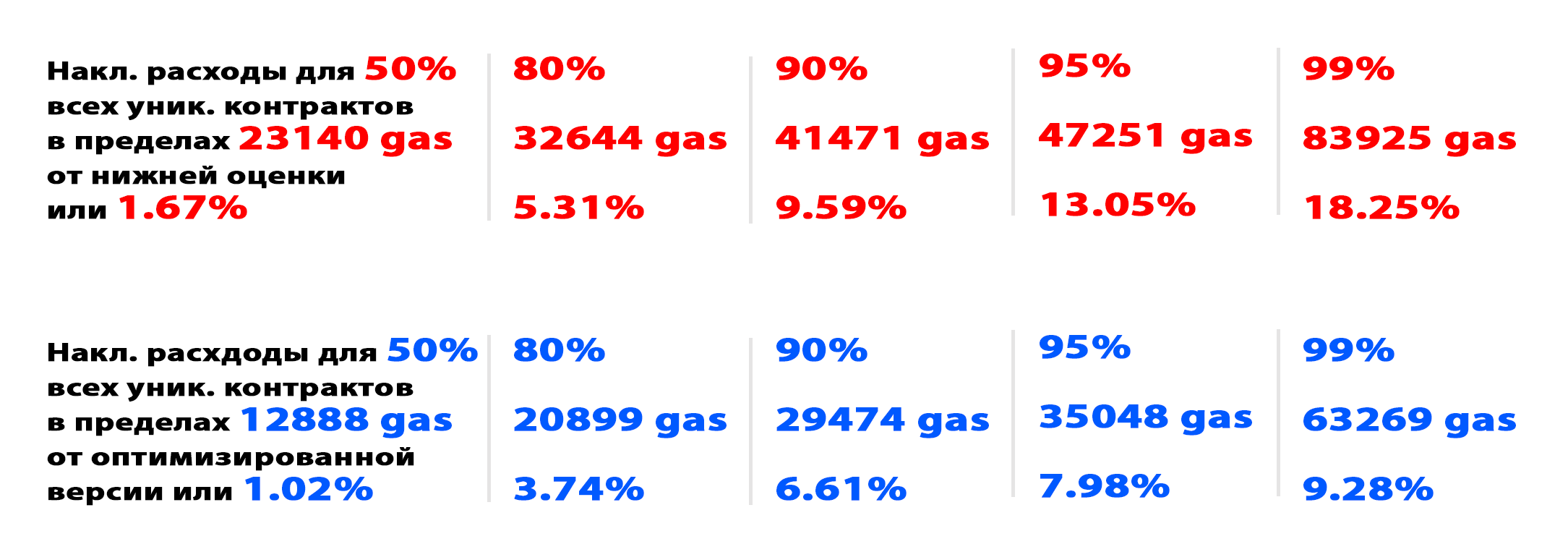
From the table you can see that even a naive optimization saves gas. Unfortunately, the quantity is not that big. On the other hand, in theory, more than 10% of gas can be saved only for 10% of contracts. In practice, with naive optimization, I managed to achieve savings of 10% for only 0.3% of contracts.
Considering all these numbers, we can remember that contract creation is a one-time process, so I can conclude that the optimization of the deployment of smart contracts is not an important issue for Ethereum now. I am sure that I will return to this issue in the future, and now there are still many interesting optimization problems associated with the byte-code of the contracts themselves.
Human factor
Small mistakes can cancel the results of all previous efforts. For example, 2131132 gas units were spent for transaction transaction 0xdfa1..7fbb . This is 23% more gas than required. Someone simply duplicated the contract deployment code before sending. As a result, 6Kb of data was not used at all.
What's next?
The question of optimization when deploying smart contracts appeared as a side effect. This topic is quite simple to understand, so I decided to start with it.
To be continued...
')
Source: https://habr.com/ru/post/348062/
All Articles