Rook - "self-service" data store for Kubernetes

On January 29, the technical committee of CNCF (Cloud Native Computing Foundation), behind Kubernetes, Prometheus and other Open Source products from the world of containers and cloud native, announced the adoption of the Rook project into its ranks. An excellent opportunity to get to know this “Kubernetes distributed data storage orchestrator” closer.
What kind of Rook?
Rook is software written on Go ( distributed under the free Apache License 2.0), designed to endow data warehouses with automated functions that make them self-managing, self-scaling, and self-healing . For this, Rook automates (for data warehouses used in the Kubernetes environment): deployment, bootstrapping, configuration, provisioning, scaling, upgrades, migrations, disaster recovery, monitoring and resource management.
')
The project is in alpha stage and specializes in orchestrating Ceph distributed storage system in Kubernetes clusters. The authors also announce plans to support other storage systems, but this will not happen in the next release.
Components and technical device
The basis of the work of Rook inside Kubernetes is a special operator (we wrote more about Kubernetes Operators in this article ) automating the configuration of the repository and implementing its monitoring.
So, the Rook operator is represented as a container that contains everything necessary for the deployment and subsequent maintenance of the repository. Among the duties of the operator:
- creating a DaemonSet for Ceph storage daemons ( ceph-osd ) with a simple RADOS cluster;
- creation of Ceph monitoring pods (with ceph-mon , checking the cluster status; for the quorum, in most cases, three instances unfold, and if any of them fall, a new one rises) ;
- CRDs ( Custom Resource Definitions ) management for the cluster itself, storage pools , object stores (sets of resources and services for serving HTTP requests that perform PUT / GET for objects - they are compatible with S3 and Swift API) , as well as file systems ;
- initialization of podov for start of all necessary services;
- creating agents Rook.
Rook agents are represented by separate decks that are deployed on each Kubernetes node. The agent's purpose is to configure the FlexVolume plugin that provides support for storage volumes in Kubernetes. The agent implements storage operation: connects network storage devices, mounts volumes, formats file system, etc.
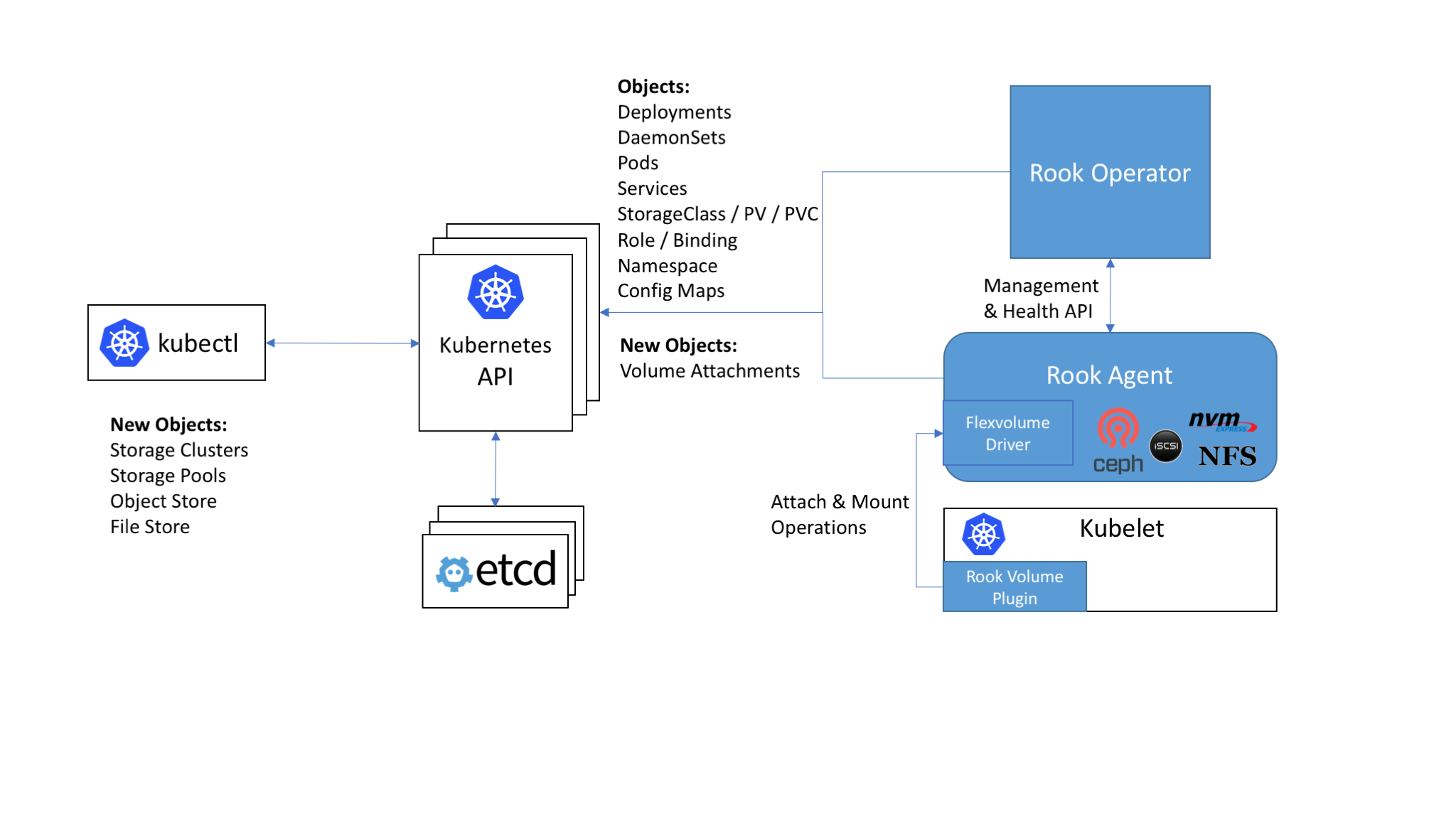
The place and role of the Rook components in the general Kubernetes cluster scheme
Rook offers three types of storage:
- block ( Block ,
StorageClass) - mounts storage to a single hearth; - Object ( Object ,
ObjectStore) - available inside and outside the Kubernetes cluster (by S3 API); - Shared File System (
Filesystem) is a file system that can be mounted for reading and writing from a variety of pods.
The internal structure of the Rook includes:
- Mons - pods for Ceph monitoring (with ceph-mon already mentioned);
- OSDs - pods with ceph-osd daemons (Object Storage Daemons);
- MGR - with ceph-mgr daemon (Ceph Manager), providing additional monitoring capabilities and interfaces for external systems (monitoring / control);
- RGW (optional) - pods with object storage;
- MDS (optional) - pods from a shared file system.

All Rook daemons (Mons, OSDs, MGR, RGW, MDS) are compiled into a single binary (
rook ) running in a container.For a short presentation of the Rook project, this small (12 slides) presentation from Bassam Tabbara (CTO at Quantum Corp) can also be useful.
Rook operation
The Rook operator fully supports Kubernetes version 1.6 and higher (and, in part, the older release of K8s - 1.5.2) . Its installation in the simplest scenario looks like this:
cd cluster/examples/kubernetes kubectl create -f rook-operator.yaml kubectl create -f rook-cluster.yaml In addition, Helm chart has been prepared for the Rook operator, thanks to which the installation can be carried out like this:
helm repo add rook-alpha https://charts.rook.io/alpha helm install rook-alpha/rook There are a small number of configuration options (for example, you can disable RBAC support if this feature is not used in your cluster), which are transferred to
helm install via the parameter --set key=value[,key=value] (or stored in a separate YAML file , and transmit - via -f values.yaml ).After installing the Rook operator and running the sweepstakes with its agents, it remains to create the Rook cluster itself, the simplest configuration of which is as follows (
rook-cluster.yaml ): apiVersion: v1 kind: Namespace metadata: name: rook --- apiVersion: rook.io/v1alpha1 kind: Cluster metadata: name: rook namespace: rook spec: dataDirHostPath: /var/lib/rook storage: useAllNodes: true useAllDevices: false storeConfig: storeType: bluestore databaseSizeMB: 1024 journalSizeMB: 1024 Note : Special attention should be paid to the
dataDirHostPath attribute, the correct value of which is necessary to save the cluster after reboots. For cases of its use as a permanent storage location for Rook data on Kubernetes, the authors recommend to have at least 5 GB of free disk space in this directory.It remains to actually create a cluster from the configuration and make sure that the subs were created in the cluster (in the
rook namespace): kubectl create -f rook-cluster.yaml kubectl -n rook get pod NAME READY STATUS RESTARTS AGE rook-api-1511082791-7qs0m 1/1 Running 0 5m rook-ceph-mgr0-1279756402-wc4vt 1/1 Running 0 5m rook-ceph-mon0-jflt5 1/1 Running 0 6m rook-ceph-mon1-wkc8p 1/1 Running 0 6m rook-ceph-mon2-p31dj 1/1 Running 0 6m rook-ceph-osd-0h6nb 1/1 Running 0 5m An upgrade of the Rook cluster (to the new version) is a procedure that at this stage requires a sequential update of all its components in a certain sequence, and it can be started only after you have verified that the current Rook installation is completely healthy. Detailed step-by-step instructions on the example of updating Rook version 0.5.0 to 0.5.1 can be found in the project documentation .
Last November, a performance comparison with EBS was published on the Rook blog. His results are worthy of attention, and if absolutely briefly, they are:
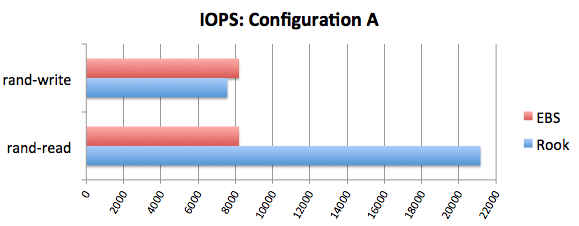

Perspectives
The current status of Rook is alpha, and the last major release to date is version 0.6 , released in November 2017 (the latest fix - v0.6.2 - was released on December 14). Already in the first half of 2018, releases of more mature versions are expected: beta and stable (officially ready for use in production).
According to the roadmap project, developers have a detailed vision on the development of Rook in at least two upcoming releases: 0.7 (its readiness in the GitHub tracker is estimated at 60%) and 0.8. The expected changes include the transfer of Ceph Block and Ceph Object support to beta status, dynamic provisioning of volumes for CephFS, advanced logging system, automated cluster updates, support for snapshots for volumes.
Accepting Rook in the number of CNCF projects (at the very early stage, “inception-level”, along with linkerd and CoreDNS ) is a kind of guarantee of growing interest in the product. As far as it consolidates in the world of cloud applications, it will become better clear after the emergence of stable versions, which, of course, will bring Rook new "testers" and users.
PS
Read also in our blog:
- “ Create a permanent repository with Ceph based provisioning in Kubernetes ”;
- “ Operators for Kubernetes: how to run stateful applications ”;
- " CoreDNS - DNS server for the cloud native world and Service Discovery for Kubernetes ";
- “ Container Networking Interface (CNI) - network interface and standard for Linux containers ”;
- " Infrastructure with Kubernetes as an affordable service ."
Source: https://habr.com/ru/post/348044/
All Articles