False alarms. New technique of catching two birds with one stone

The problem of false positives. Accuracy and completeness.
If there is a universal pain point for DLP systems, then this is, without a doubt, false positives. They can be caused by incorrect policy settings, but the point is that even if the integrator tried, and everything is implemented-correctly, false alarms still do not disappear. And a lot of them. If you hear that someone does not have them, do not believe, “everybody lies”. We have been in the industry for a long time, and we are regularly testing all serious competitive solutions. False positives are the scourge of all modern DLPs, from which customers primarily suffer.
In this article, we will talk about a new approach to filtering information traffic policies for information security risk. The method is based on the use of two stages of filtering, which distinguishes it from traditional single-level filtering. This approach allows us to more effectively solve the problem of false positives, i.e. reduce waste and share missed incidents.
Today there will be a little theory, and in a week - a lot of practice.
')
First of all, we recall two properties that determine the quality of any information filtering mechanism, namely: accuracy and completeness (precision and recall, in the language of statistics - errors of the I-st and II-nd kind).
Imagine a certain company with information traffic. It contains a certain sample of documents, consisting of a set of A - valuable documents. The filtering mechanism should reveal them in the information traffic. Accuracy is the proportion of documents correctly marked as valuable among all those marked by the filter, and completeness is the proportion correctly found from the previously known set of valuable documents A. Let's try to paint it in the form of formulas to make it a little clearer.
For example, A = 10 commercial offers. Our filter found B = 8 documents correctly and C = 4 is false, therefore, we did not find the D = 2 document. Then:
Naturally, accuracy and completeness oppose each other. We illustrate this with a simple example filtering condition.
Key words, number of attachments, number of recipients, file formats, vocabulary tonality, and a million conditions are the conditions for detecting information about the risk of information security. Without loss of generality, we will select the file size V as such a condition.
Let for some organization the distribution of the number of files of valuable information and garbage by file size is as follows:

Then the struggle for accuracy will give the following search result (files found with a size> V):
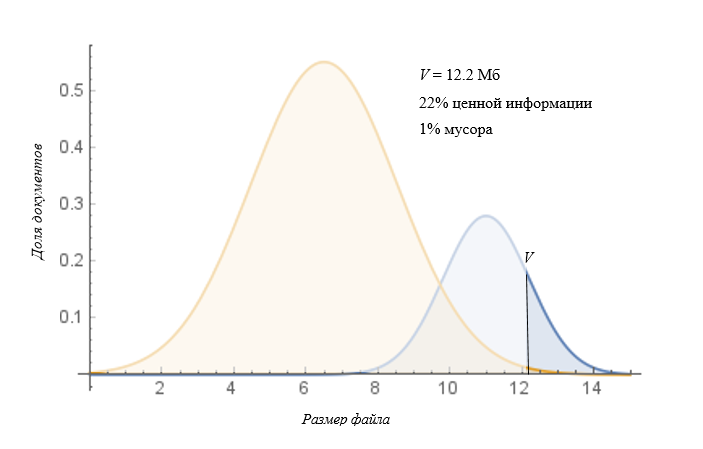
Naturally, such a filtering policy is not suitable for the most banal reason - we lose sight of the lion’s share of important information, which is unacceptable. However, at the same time, this policy gives us a significant advantage. It is known that IS incidents of high criticality are immediately analyzed, and such an approach, in which we immediately receive the most critical incidents without unnecessary waste, allows us to increase the speed of response.
The fight for completeness will look like this (found files of size> V):
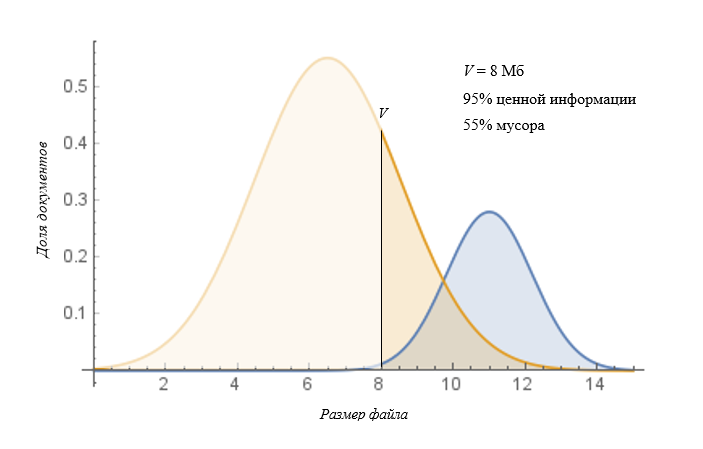
In this situation, more familiar and characteristic of domestic realities, the information security policy marks out much more traffic, while keeping almost all the incidents. But in this case, the result does not allow to call such an approach effective. The reason for this is again the time factor. The security officer is faced with a large number of false positives, which slows down the response to incidents of high severity.
It is rarely possible to achieve 100% accuracy and 100% completeness due to, generally speaking, the random nature of the analyzed data. What are the marketing statements of vendors about the almost negative number of false positives in their products? Sometimes DLP developers deliberately veil one of the indicators, passing it off as detection quality, and thus make arithmetic an involuntary servant of a biased presentation of information.
At the same time, high accuracy and completeness, as a rule, are found in exact sciences (physics, chemistry, biology). For example, by a single state of a protein chain, you can define a unique (if a person does not have a twin or a clone) a chain of DNA and its carrier. A criminal can be identified by a unique fingerprint, and the chemical composition of a substance can be determined by a unique absorption spectrum. In the detection of information, there is also room for such solutions. We are talking about finding information on a unique basis (the sum of MD5, or its relative - a digital fingerprint). In all the above situations, we have a “property” that uniquely separates the desired object from the “garbage”.
However, for obvious reasons, this technology is only effective for protecting immutable files, which is not enough in real life.
 It should be noted that the process of information transfer is not the object of studying classical exact sciences, even though it already has a strong mathematical apparatus of information theory, founded by Claude Shannon in his work on communication theory more than 70 years ago (“ Communication Theory in Secret Systems ”, "The mathematical theory of communication ").
It should be noted that the process of information transfer is not the object of studying classical exact sciences, even though it already has a strong mathematical apparatus of information theory, founded by Claude Shannon in his work on communication theory more than 70 years ago (“ Communication Theory in Secret Systems ”, "The mathematical theory of communication ").It is not difficult to guess that accuracy and completeness are the very two hares mentioned in the title of the article. In the second part, we will tell you how not to miss any of them and solve the “damn question” of all DLP systems - the problem of false positives.
The authors:
Maxim Buzinov, Senior Mathematician, Solar Security Company.
Galina Ryabova, Head of Solar Dozor, Solar Security.
Source: https://habr.com/ru/post/347992/
All Articles