In a section: the news aggregator on Android with backend. Distributed Message Processing Systems (Spark, Storm)
Introduction (with links to all articles)

The main component of the system that processes raw data from “spiders” performs data enrichment, their indexing and subsequent search is the message processing system, since Only such systems can adequately respond to peak loads of input data, the shortage of certain types of resources and can be easily horizontally scalable.
')
When analyzing the future use of the system processing requests or incoming data, the following requirements were highlighted:
As a final solution, the Apache Storm framework was chosen. For Apache Spark fans: given the prevalence of this framework (using Spark Streaming or now Spark Structured Streaming), all further narration will be built in comparison with the Apache Spark functionality.
Taking into account the fact that both systems have highly intersecting sets of functions, the choice was not easy, however, since More control over the processing of each message remains for Apache Storm - the choice was made in its favor. Then I will try to explain what is the difference, what is the similarity of frameworks and what means "greater control over the processing of each message."
Next, I will try to briefly tell you about the basic steps of placing and executing your code in a cluster.
The ready code for each system is loaded into the cluster using special utilities (specific for each framework), while the ready code in both cases is uberjar / shadowJar (ie, the jar file containing all the necessary dependencies, except for the framework itself, of course). In both cases, the entry point classes and the code operation parameters are specified (as one of the possible utility keys).
Next, your code is converted to topology for Apache Storm and an application for Apache Spark.
You declare the topology at your entry point in a similar way:
everything is converted to something similar (Apache Spark topology):
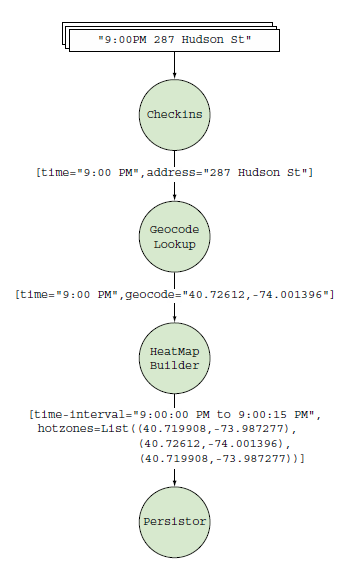
As a result, we have a graph (possibly containing cycles), on whose branches Tuples run (data packets or messages are indicated on the graph), where each node is either a Tuple source - Spout, or their Bolt handler.
When creating a topology, you determine which Spout / Bolt will participate in its work, how they are interconnected, how messages are grouped within a cluster based on keys (or not grouped at all). As a result, you can merge, split, transform your messages (executing external interactions or not), swallow, cycle through, run into named threads (links between cluster members have a “default” thread, but you can create your own named , for example, for packages requiring long processing).
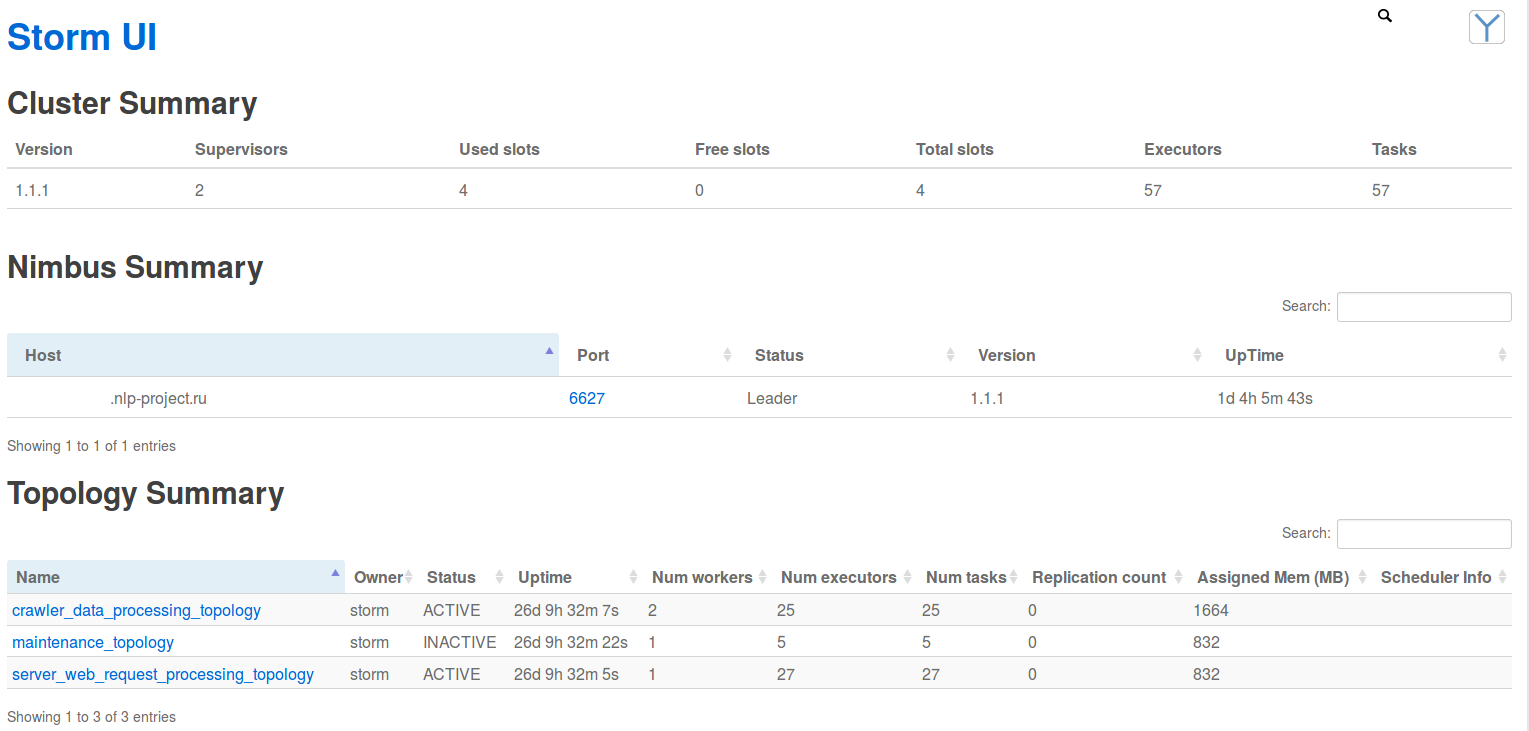
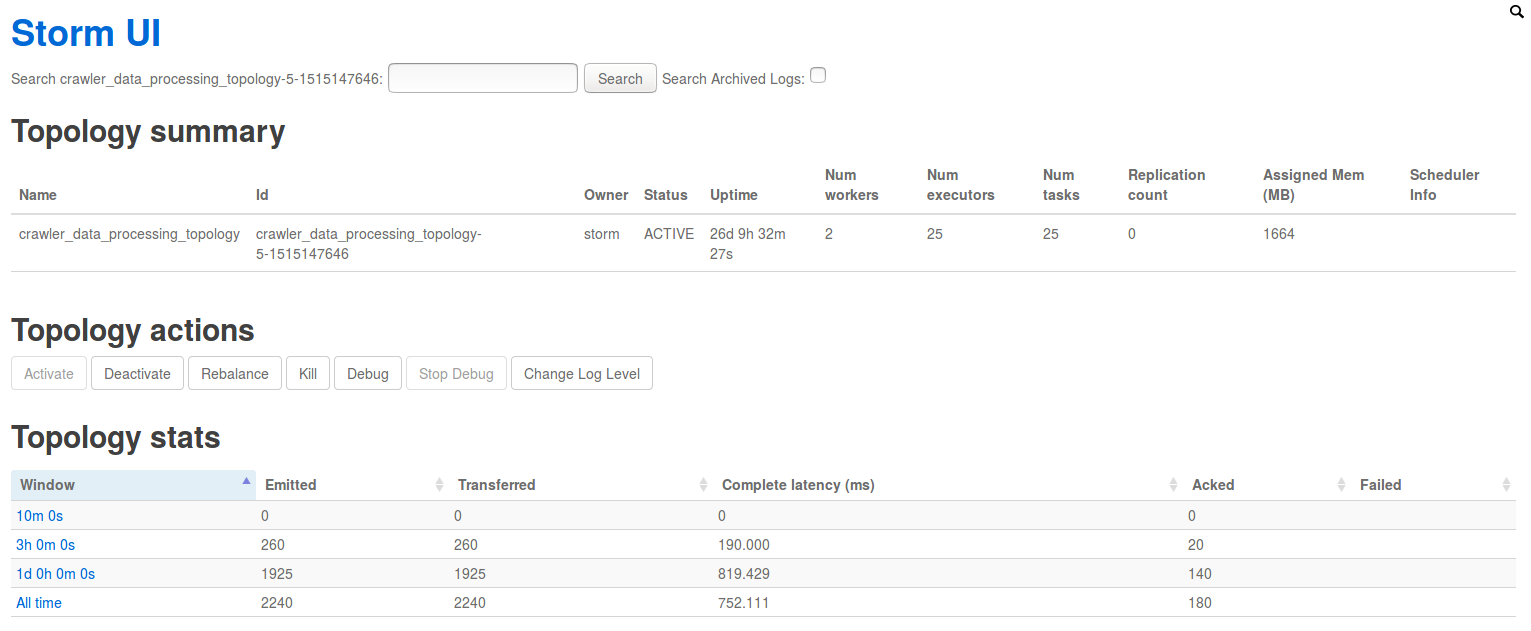
In this case, all this movement is reflected and taken into account in the statistics and metrics of "Storm UI" - a web application for tracking the status of the cluster. Next, a few screenshots:

You declare the application at your entry point in a similar way (here we will only talk about Spark Streaming):
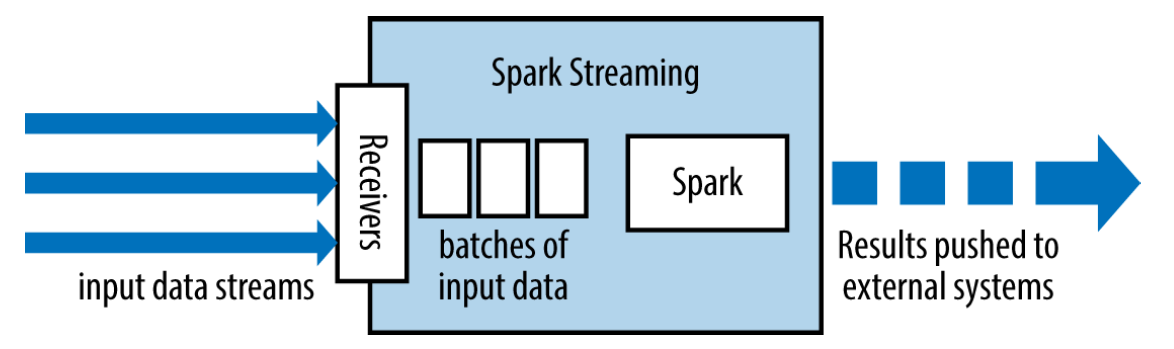
This all translates into something like “Recipient (Receiver) + Apache Spark Code + Output Operators”:
As a result, we have:
In this case, all this is reflected and taken into account in the statistics and metrics of "Spark UI" - a web application for tracking the status of the cluster. Next, a few screenshots:
As can be seen, despite the common goal, the ways of forming the processing paths and the final structures are completely different in ideology, which ultimately leads to even greater differences in the implementation.
After uploading your code to the Apache Storm cluster control machines (nimbus, analogous to Cluster Manager) from the Java entry point code using the APache Storm API, the topology and information about its execution are generated:
All this information and your code (jar files) are sent to other nodes, where the necessary elements of your topology are created (instances of classes that implement message generators (Spout) and processors (Bolt)) and additional configuration of nodes is performed. After this, the topology is considered to be expanded and work begins in accordance with the specified cluster configuration and topology.
Screenshot of working topology from Storm UI:

From the cluster / topology configuration levers, you have parameters that affect:
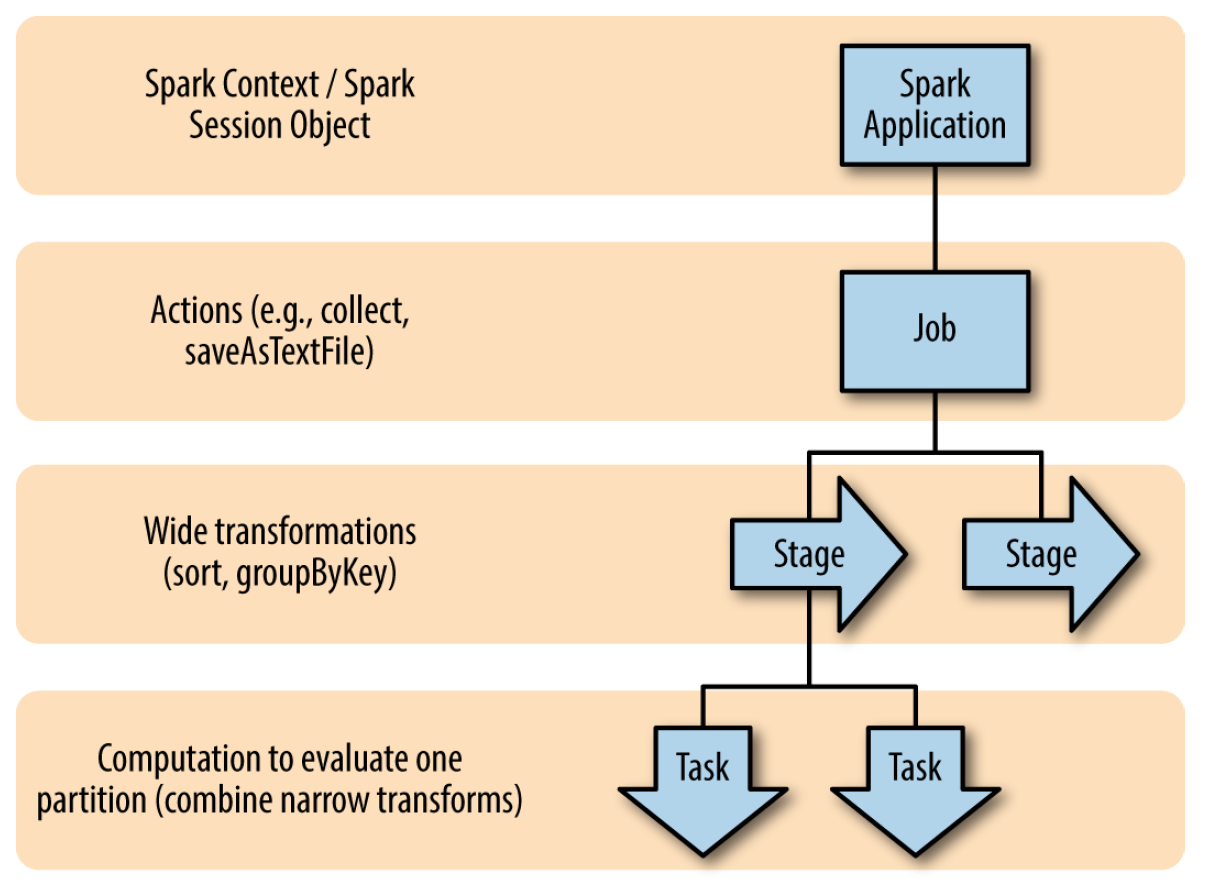
After loading your code into the cluster, an application is created that is executed by the driver (driver), which forms a large number of processing graphs RDD (directed acyclic graph, DAG) -> DAG is divided into job (action) in the form of "collect", "saveAsText", etc) -> stages are formed from the job (stage) (transformations for the most part) -> stage is divided into task (minimum units of work on the partition (partition)).
Next comes the scheduler, which distributes tasks and data across the cluster nodes. Your application code is present in the driver and code snippets sent to nodes for performing transformations / actions.
From the cluster / topology configuration levers you have:
Of course, the possibilities for working with resources may differ from the resource manager depending on the type of cluster.
In the end, it turns out that Apache Spark is focused on processing data streams, taking into account their consideration as a set, with analysis and processing them in the context of other messages for a certain period of time or in general all received during processing. While Apache Storm treats each message as a separate entity and processes it the same way. In the case of Trident-topologies, where the formation of micro packets (micro batching) takes place, this statement does not change much because batching is a means of minimizing service traffic and unnecessary connections to each message. From here we get different cluster architectures, different message processing entities and how they work in Apache Storm and Apache Spark.
As a result, it turns out that approaches to resource management in a cluster reflect the level of abstraction over the processing process (“higher abstraction means less influence”).

As you can see, the current topologies are also linear (the algorithm is quite simple) and broken down according to the principle “separate source - separate topology” in order to simplify management and update topologies on a cluster.
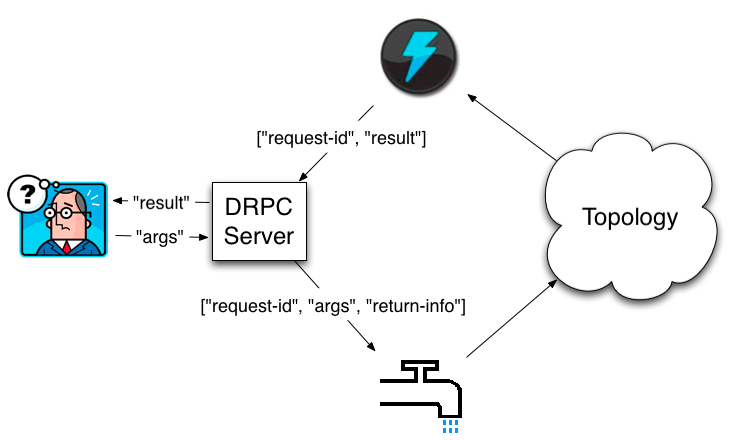
An interesting feature of Apache Storm is DPRC (Distributed RPC): the ability to make calls to methods that are actually handled by the cluster. The specified functionality is used when implementing a REST client, whose responses are later cached by Nginx.
The operation scheme is simple: a daemon receiving requests and buffering them -> special Spout, sending requests to the topology -> invisible collectors, sending data and removing requests from the input buffer. As a result, we get a simple, but powerful tool, thanks to which the processing of the request can be performed on the cluster, while for the caller it is just an RPC call.
Despite the lack of such a solution in Apache Spark (I know), I think that the implementation is not too complicated.
Trident is a high-level abstraction for performing real-time computation using Apache Storm primitives. This makes it easy to combine high bandwidth (millions of messages per second), processing streams with state tracking with low latency distributed queries. If you are familiar with high-level batch processing tools such as Pig or Cascading, Trident concepts will be very familiar — Trident has connections, aggregates, grouping, functions, and filters (essentially the same abstractions as Apache Spark RDD). In addition to this, Trident adds primitives to perform incremental processing with state tracking on top of any database or storage. Trident has a consistent, “exactly-once” semantics, therefore, it is quite easy to understand the work of the topology implemented on it.
The disadvantages of Trident can only be called a more complex relationship between the code of your topology and what Spout / Bolt will be created.
Trident allows you to write about this code:
and get something like this topology:
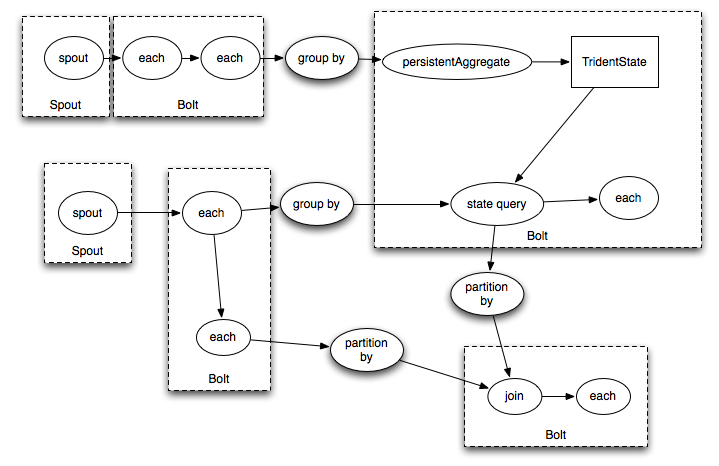
As Apache Spark (Spark Streaming) and Apache Storm have already become clear, things are different and it’s wrong to compare them head-on, due to differences in the mass of aspects, first of all in the way of forming input data for processing: Apache Spark (micro-batch) and Apache Storm Core (per-message) (a comparison of Apache Spark and Apache Storm's Trident is more appropriate here).
In the bottom line, we have 2 frameworks with their own features, the specifics of which must be taken into account in order to make the right decision.
Thanks for attention!
The main component of the system that processes raw data from “spiders” performs data enrichment, their indexing and subsequent search is the message processing system, since Only such systems can adequately respond to peak loads of input data, the shortage of certain types of resources and can be easily horizontally scalable.
')
When analyzing the future use of the system processing requests or incoming data, the following requirements were highlighted:
- Low latency (processing) of the message;
- The ability to obtain data from different sources (DB, message middleware);
- Ability to process data on multiple nodes;
- Fault tolerance to node failure situations;
- Support for the level of guaranteed processing of the message "at-least-once";
- The presence of an interface to monitor the status of the cluster and to manage it (at least partially).
As a final solution, the Apache Storm framework was chosen. For Apache Spark fans: given the prevalence of this framework (using Spark Streaming or now Spark Structured Streaming), all further narration will be built in comparison with the Apache Spark functionality.
Taking into account the fact that both systems have highly intersecting sets of functions, the choice was not easy, however, since More control over the processing of each message remains for Apache Storm - the choice was made in its favor. Then I will try to explain what is the difference, what is the similarity of frameworks and what means "greater control over the processing of each message."
Basic concepts
Next, I will try to briefly tell you about the basic steps of placing and executing your code in a cluster.
The ready code for each system is loaded into the cluster using special utilities (specific for each framework), while the ready code in both cases is uberjar / shadowJar (ie, the jar file containing all the necessary dependencies, except for the framework itself, of course). In both cases, the entry point classes and the code operation parameters are specified (as one of the possible utility keys).
Next, your code is converted to topology for Apache Storm and an application for Apache Spark.
Apache Storm Topology
You declare the topology at your entry point in a similar way:
public class HeatmapTopologyBuilder { public StormTopology build() { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("checkins", new Checkins()); builder.setBolt("geocode-lookup", new GeocodeLookup()).shuffleGrouping("checkins"); builder.setBolt("heatmap-builder", new HeatMapBuilder()).globalGrouping("geocode-lookup"); builder.setBolt("persistor", new Persistor()).shuffleGrouping("heatmap-builder"); return builder.createTopology(); } } everything is converted to something similar (Apache Spark topology):
As a result, we have a graph (possibly containing cycles), on whose branches Tuples run (data packets or messages are indicated on the graph), where each node is either a Tuple source - Spout, or their Bolt handler.
When creating a topology, you determine which Spout / Bolt will participate in its work, how they are interconnected, how messages are grouped within a cluster based on keys (or not grouped at all). As a result, you can merge, split, transform your messages (executing external interactions or not), swallow, cycle through, run into named threads (links between cluster members have a “default” thread, but you can create your own named , for example, for packages requiring long processing).
In this case, all this movement is reflected and taken into account in the statistics and metrics of "Storm UI" - a web application for tracking the status of the cluster. Next, a few screenshots:
Apache Spark application
You declare the application at your entry point in a similar way (here we will only talk about Spark Streaming):
// Create a StreamingContext with a 1-second batch size from a SparkConf val ssc = new StreamingContext(conf, Seconds(1)) // Create a DStream using data received after connecting to port 7777 on the // local machine val lines = ssc.socketTextStream("localhost", 7777) // Filter our DStream for lines with "error" val errorLines = lines.filter(_.contains("error")) // Print out the lines with errors errorLines.print() This all translates into something like “Recipient (Receiver) + Apache Spark Code + Output Operators”:
As a result, we have:
- Your control code (driver), which coordinates the execution of the Apache Spark application;
- Receiver (in the case of Spark Streaming), which reads data from the source and forms the RDD series;
- Acyclic graphs (generated by driver code) running on cluster nodes, representing the processing and generation of new RDDs.
In this case, all this is reflected and taken into account in the statistics and metrics of "Spark UI" - a web application for tracking the status of the cluster. Next, a few screenshots:
As can be seen, despite the common goal, the ways of forming the processing paths and the final structures are completely different in ideology, which ultimately leads to even greater differences in the implementation.
Running an Apache Storm topology and an Apache Spark application in a cluster
Apache Storm Cluster
After uploading your code to the Apache Storm cluster control machines (nimbus, analogous to Cluster Manager) from the Java entry point code using the APache Storm API, the topology and information about its execution are generated:
- how many tasks;
- what level of concurrency;
- what connections between message handlers should be made;
- what parameters of the cluster should be specific to this particular topology;
- how many Workers should be created, etc.
All this information and your code (jar files) are sent to other nodes, where the necessary elements of your topology are created (instances of classes that implement message generators (Spout) and processors (Bolt)) and additional configuration of nodes is performed. After this, the topology is considered to be expanded and work begins in accordance with the specified cluster configuration and topology.
Screenshot of working topology from Storm UI:
From the cluster / topology configuration levers, you have parameters that affect:
- how many instances of Spout / Bolt within the terms of the Apache Storm topology (worker / executor / task) will be launched in the cluster;
- how they can be distributed between nodes (not directly of course, but through their abstractions);
- what are the sizes of buffers in the elements;
- What is the number of unprocessed messages and how long can it “walk” in a cluster?
- cluster braking on options when abruptly filled with “backpressure” messages;
- adjusting the debug level;
- the frequency of statistics collection (for an incoming stream of 100,000 messages per second, take into account each — an extra load), etc.
Apache Spark Cluster
After loading your code into the cluster, an application is created that is executed by the driver (driver), which forms a large number of processing graphs RDD (directed acyclic graph, DAG) -> DAG is divided into job (action) in the form of "collect", "saveAsText", etc) -> stages are formed from the job (stage) (transformations for the most part) -> stage is divided into task (minimum units of work on the partition (partition)).
Next comes the scheduler, which distributes tasks and data across the cluster nodes. Your application code is present in the driver and code snippets sent to nodes for performing transformations / actions.
From the cluster / topology configuration levers you have:
- limits on memory usage;
- the number of cores;
- timeouts for data availability (data locality);
- scheduler operation algorithms (FIFO / FAIR), etc.
Of course, the possibilities for working with resources may differ from the resource manager depending on the type of cluster.
In the end, it turns out that Apache Spark is focused on processing data streams, taking into account their consideration as a set, with analysis and processing them in the context of other messages for a certain period of time or in general all received during processing. While Apache Storm treats each message as a separate entity and processes it the same way. In the case of Trident-topologies, where the formation of micro packets (micro batching) takes place, this statement does not change much because batching is a means of minimizing service traffic and unnecessary connections to each message. From here we get different cluster architectures, different message processing entities and how they work in Apache Storm and Apache Spark.
As a result, it turns out that approaches to resource management in a cluster reflect the level of abstraction over the processing process (“higher abstraction means less influence”).
Current project topologies
As you can see, the current topologies are also linear (the algorithm is quite simple) and broken down according to the principle “separate source - separate topology” in order to simplify management and update topologies on a cluster.
Additional features of Apache Storm
DPRC (Distributed RPC)
An interesting feature of Apache Storm is DPRC (Distributed RPC): the ability to make calls to methods that are actually handled by the cluster. The specified functionality is used when implementing a REST client, whose responses are later cached by Nginx.
The operation scheme is simple: a daemon receiving requests and buffering them -> special Spout, sending requests to the topology -> invisible collectors, sending data and removing requests from the input buffer. As a result, we get a simple, but powerful tool, thanks to which the processing of the request can be performed on the cluster, while for the caller it is just an RPC call.
Despite the lack of such a solution in Apache Spark (I know), I think that the implementation is not too complicated.
Trident
Trident is a high-level abstraction for performing real-time computation using Apache Storm primitives. This makes it easy to combine high bandwidth (millions of messages per second), processing streams with state tracking with low latency distributed queries. If you are familiar with high-level batch processing tools such as Pig or Cascading, Trident concepts will be very familiar — Trident has connections, aggregates, grouping, functions, and filters (essentially the same abstractions as Apache Spark RDD). In addition to this, Trident adds primitives to perform incremental processing with state tracking on top of any database or storage. Trident has a consistent, “exactly-once” semantics, therefore, it is quite easy to understand the work of the topology implemented on it.
The disadvantages of Trident can only be called a more complex relationship between the code of your topology and what Spout / Bolt will be created.
Trident allows you to write about this code:
TridentState urlToTweeters = topology.newStaticState(getUrlToTweetersState()); TridentState tweetersToFollowers = topology.newStaticState(getTweeterToFollowersState()); topology.newDRPCStream("reach") .stateQuery(urlToTweeters, new Fields("args"), new MapGet(), new Fields("tweeters")) .each(new Fields("tweeters"), new ExpandList(), new Fields("tweeter")) .shuffle() .stateQuery(tweetersToFollowers, new Fields("tweeter"), new MapGet(), new Fields("followers")) .parallelismHint(200) .each(new Fields("followers"), new ExpandList(), new Fields("follower")) .groupBy(new Fields("follower")) .aggregate(new One(), new Fields("one")) .parallelismHint(20) .aggregate(new Count(), new Fields("reach")); and get something like this topology:
Advantages of Apache Storm:
- Integration with a large number of data sources (databases, message brokers - Kafka, HBase, HDFS, Hive, Solr, Cassandra, JDBC, JMS, Dredis, Elasticsearch, Kinesis, Kestrel, MongoDB ....);
- The presence of a special language with high-level functions for working with messages (Trident);
- Availability of load control tools (Resource Aware Scheduler);
- Detailed control over the level of parallelism (which, on the other hand, entails an understanding of the operation of the elements of topology and the system's response to a sharp increase in the amount of incoming data);
- SQL query support for processed data (experimental function similar to Apache Spark SQL);
- Support for other non-JVM languages;
- Cluster deployment support (YARN, Mesos, Docker, Kubernetes).
Disadvantages of Apache Storm:
- Implementation on Clojure (this I think is a plus and a minus of this aspect). However, plans for the further development of Apache Storm talk about plans for the transition in version 2.0 to the implementation of Java. First of all, to increase the commitments base (the more, the better each version and the faster the product development takes place);
- Lack of information about the framework - information (articles, books, videos) is frankly significantly less than Apache Spark;
- More complicated from my point of view, the architecture - as a result, the steeper curve of the training of developers: a higher probability to make a mistake, someone may not have enough knowledge / perseverance to overcome the framework.
Comparison results of Apache Spark and Apache Storm
As Apache Spark (Spark Streaming) and Apache Storm have already become clear, things are different and it’s wrong to compare them head-on, due to differences in the mass of aspects, first of all in the way of forming input data for processing: Apache Spark (micro-batch) and Apache Storm Core (per-message) (a comparison of Apache Spark and Apache Storm's Trident is more appropriate here).
- Reaction speed (latency, not throughput): there are no official performance comparisons recognized by both parties, but most talk about seconds for Apache Spark and fractions of seconds for Apache Storm;
- Processing principles: Apache Storm - a stream processing framework that also performs micro-batching (Apache Storm's Trident), Apache Spark - a batch processing framework that also performs micro-batching (Spark Streaming);
- Languages: Apache Storm is more diverse in the number of languages for implementing handlers, not only JVM-based, Python and R - as is the case with Apache Spark;
- Message processing guarantees: Of the three semantics of “at-most-once”, “at-least-once” and “exactly-once”, Apache Spark supports “out of the box” only “exactly-once”;
- Fault tolerance: none of the frameworks gives a 100% guarantee of missing messages for all sources (for this, sources must meet a series of conditions, must be reliable and durable, such as Kafka. Also it is necessary to take into account that checkpoints on HDFS make their own delay - reduce latency, which may lead to a decision to disable them for some scenarios).
In the bottom line, we have 2 frameworks with their own features, the specifics of which must be taken into account in order to make the right decision.
Thanks for attention!
Source: https://habr.com/ru/post/347990/
All Articles