Data structures with program properties
As you know, a database is a repository of structured information, passive in nature. The business logic of the application is implemented somewhere outside the base, in the form of a "set of actions to achieve the desired result." If changes are made to the stored data set, the result should be the new state of the database. In short form, it can be written something like this: event → {actions} → result. Let's change this wording to: event → rules → result, and see what happens.
If the automation domain is a system of interacting values, then it can be described by the ER model, which is formed by instances of just four abstract entities: a data class , a class attribute, a class relationship , and an association of attributes . Such a model not only forms the logical structure of the database, but possesses all the properties of the program, which in essence is - in the computing environment formed by the methods of the mentioned abstract entities.
Consider this bold statement in more detail, starting with the most common definitions. (The following repetition of the well-known is necessary at least to indicate the meaning of the terms used. It will be dry and tedious - as in any other theoretical material. To enliven it slightly, examples are embedded in the text.)
Virtually any objectively existing subject area can be viewed from an informational point of view as a system of interacting values . Immediately, we note that a single value is never either independent or self-sufficient, since it exists as a certain characteristic of a data object . Therefore, a complete set of data objects with their values is necessary for an accurate description of a subject area in a certain state. At the same time, single-type objects are described by a data class , and exist on the rights of derived instances of this class - class objects .
')
The data class expresses a separate conceptual essence of the subject domain in question and is characterized by the user name of this entity. In turn, any conceptual entity has some unique set of its own characteristics / properties. The class attribute expresses a separate characteristic of an entity, is named the user name of this characteristic, has a type that defines the set (domain) of its valid values, and acts as a factory of specific characteristic values in class objects.
Accordingly, a data class owns a set of attributes (class) that it stores in a tuple format. Acting as a factory of objects, a class forms the contents of an object as a tuple of values , which is an instance derived from the attribute tuple . In addition, each value in the tuple of values of a class object is an instance derived from the corresponding class attribute.
Thus, a very specific subject area that exists as a set of objects with their values is described at the level of abstraction by a system of classes with their attributes. And at the same time, data and metadata represent a persistent data structure stored in an object database .
The basis for the implementation of communication data objects based on the principle of symmetry. In accordance with this principle, the objects being linked mutually exchange their identifiers. The object identifier ( IDO descriptor) is global within the physical database, and is a simple integer.
At the level of abstraction, the relationship of objects is described by a class relation . The declaration of a relationship is implemented by creating an attribute in each of the two classes connected by a relationship, which mutually address each other. Each of the attributes of the relationship is typed by the opposite class of the relationship (each class is considered to be an independent user data type), as a result of which the domain of values of the reference attribute is a set of object descriptors of the opposite class.
The class relationship sets a measure for the quantitative interaction of the derived objects of these classes. With all the simplicity of this definition, relations have so diverse functional behavior and mutual logical dependence that this extensive topic will be considered separately.
In the meantime, it is worth mentioning that with respect to one-to-one, both reference attributes are absolutely equal, and their value in data objects will be the only descriptor of a communication partner. In relation to the many-to-one attributes are obviously not equal: neither by the format of the stored value, nor by the order of formation of the value. If, on the side of the many , the attribute value of the [ direct link ] is still the only descriptor, then on the side of the one , as a result of strictly observing the reference symmetry, the value of the attribute [ backward reference ] will be a set of descriptors representing the key-value list. In this case, the value of the reverse link attribute is derived from the value of the direct link attribute. The mechanism for implementing this derivative will be discussed in detail below.
The interaction of values is understood as their causal functional relationship. This relationship exists only at the conceptual level of abstraction, where it takes the form of a virtual connector of two attributes. By analogy with the class relationship, the attribute association declaration is implemented by creating two sockets (parallel with TCP sockets is appropriate), each of which belongs to its own attribute, and is placed in its socket tuple .
A separate socket describing the properties of communications from its attribute is the same persistent data structure of the abstraction layer as a class and attribute. Like relationship attributes, the sockets that make up the connector mutually address each other. For these purposes, the socket declaration contains a complex identifier ( class + attribute + socket ) of the opposite socket connector. Also, the socket declaration contains a set of flags that control the transmission and reception of values through a connector.
Logically, a tuple is a simple enumeration of homogeneous (in terms of a tuple) elements containing a certain number of bytes of data. Knowledge of the content and methods of its formation lie outside the tuple. The tuple only provides space for storage and long-term storage. Features of the internal implementation of the tuple were discussed here .
A tuple element is uniquely identified by its place (sequence number) in a tuple that never changes. When added to a tuple, the new element takes its place once and for all.
The content of a tuple element can be either a unitary value or another tuple. This makes the tuple the main (and only) structure-forming component of the object representation. For example, a class declaration is a tuple whose elements are class properties, one of which is a class attribute tuple.
A tuple has the ability to create its own instance, which is an empty tuple whose elements have no content. This ability is used, for example, by a class, both when creating inheritance classes and when creating its derived objects, in which the mutual identification of attributes and values derived from them is ensured by the coincidence of the element numbers in the corresponding tuples.
The constancy of the space occupied by an element in a tuple underlies the system of internal identification of entities, which in its most general form looks like this:
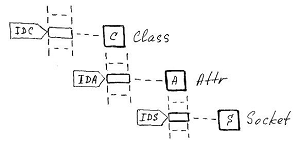
Each entity is identified by its descriptor - a sequence number in the corresponding tuple: IDC - class, IDA - attribute, IDS - socket, IDO - object (logically DAT objects should also be considered as a tuple). Logic also suggests that classes are elements of a tuple whose specific owner is covered in the class relationship article.
What is remarkable - at the level of abstraction, there are two models at once, formed by various entities of this level.
The collection of stored class declarations, attributes, and sockets forms the data model . The data model is considered to be executive , since the entities forming it perform in relation to the data level the function of the object factory (class) and the value factory (attribute).
The application model is virtual, and exists on the rights of the form of data model representation . An application model is dynamically created by a visual designer , which uses it to display an existing data model, and create new declarations in it, by creating new application model entities. Along with the real class and attribute , such virtual entities as relation and connector take part in the formation of the application model . Virtual entities do not form stored declarations, but are created dynamically from attribute and socket declarations, partially encapsulating the fact of their existence. The virtual nature of the application model does not interfere at all to consider it as a primary domain model .
In turn, all the listed real and virtual entities of the level of abstraction are instances of entities of a still higher level of abstraction - the level of meta-definitions . At this level, structurally and programmatically implemented such entities as: meta-tuple , meta-class , meta-attribute , meta-relation , meta-socket and meta-connector .
It is worth emphasizing once again that all design methods by which both models (data and applications) are created and changed, as well as all the execution methods used by the data model in relation to objects and data-level values, belong to meta-level entities. The model level, which ensures the creation and execution of all business logic of the application, is formed exclusively by declarative instances of meta-entities, and does not contain executable code.
Design methods by which instances of meta-entities are created and the values of one or another of their properties are redefined are quite obvious and do not require comments. What cannot be said about the methods of execution forming the notorious computing environment, with the help of which external influences change the state of data in accordance with the rules declared in the form of a data model. As a matter of fact, the call of the method of execution is such an external influence. In total, there are four such methods: Create , Set , Get, and Update .
The Create method belongs to the meta-class, and is used to create a derived class object. The method parameter is the IDC descriptor of the target class. The Create method creates an object as an instance of the attribute tuple of the specified class, and registers it in the DAT allocation table for the next free IDO descriptor.
Attribute methods: Set , Get and Update , belong to a meta-attribute, and allow you to operate on the values of data objects. The Set method is responsible for assigning a value, the Get method is responsible for fetching a value, and the Update method is an event that triggers an attribute to re-form a derived stored value (the meaning of this action will become clear later).
For attribute methods, the target object is identified by the IDO descriptor, and the target value itself is available exclusively through the class attribute, the path to which is represented in the IDC + IDA data model descriptors. In other words, all actions on a value are performed on behalf of a class attribute. A feature of the execution of attribute methods is that in its course each method resorts to iterating over the sockets in the attribute tuple, invoking a similar method for the target attribute addressed by the connector, provided that the flag is set to the same name in the socket.
Since the execution of any of the three methods: Create , Set or Update , will change the state of the data , they can only be called in the context of a transactional session . Calling any of these three methods is an atomic external impact on the database, which is easily formalized into a transaction format , and then saved in a log.
Consider the logic of the execution of attribute methods in a little more detail.
So, the Set method is called, to which the address parameters have been passed, and a pointer to the value to be assigned ( * value ). In the body of this method, the attribute will generate a new value, perform its assignment to the corresponding element of the object tuple, and then begin sequential search of sockets from its tuple. For each socket for which the Set [ S ] flag is set , the source attribute will call the Set method for the attribute, the path to which is specified in the socket declarations. Note that the execution of the method can be completed ahead of time, without bypassing the socket tuple, if the new value is equivalent to the stored one.
When making derived calls to Set , the attribute follows the principle of isolation - “fired, and forgot,” without worrying about the consequences. The further course of events is determined by other actors-attributes. At the same time, what is important, the transactional nature of the execution ensures the permanent consistency of all variable values, regardless of the scope and “length” of the changes.
Consider the formation of derived values for example from the life of accounts and invoices:
In the diagram, the contour arrows indicate the user input of values, the same external call Set . Any change in the attribute values Quantity or Price is actively transferred to the Sum attribute, which uses a functional , in this case - multiplicative, to form a derived value.
Functionals are predefined (for each value type) meta-attribute methods that allow the resulting value to be generated by converting argument values obtained via connectors from one or more source attributes. An attribute is assigned a functional by assigning its descriptor ( IDF ), which is a sequence number in the general list of functionals.
If an attribute is assigned a functional, then all Set and Get calls to the attribute address are processed by this functionality, if necessary with additional polling ( Get ) of sources. Note: to exclude the original call source from polls, the address part of the call ( IDC + IDA ) permanently includes the socket socket ( + IDS ) as well.
Both connectors from the above example were used in simple unconditional form.
Meanwhile, the functional behavior of the connector can be made dependent on the valid values of third-party attributes, which for the original connector form a kind of " execution context ". To implement communication with context attributes, socket declarations provide for the possibility of addressing three additional, so-called " context " sockets. Each context socket has its own, strictly fixed purpose-aspect: blocking ( lock ), reference ( ref ) and key ( key ), but at the same time these are exactly the same meta-socket instances as the " basic " sockets of the connector. To address each context socket to the base one, two descriptors are enough: IDA + IDS .

A blocking lock- socket allows the transfer of a value over a connector, if the value returned by it is relevant, and blocks otherwise. Actual is the initialized value of the socket's owner attribute ( lock-context ), which is additionally evaluated from the point of view of its type: true for logic, not zero for a number, and at least one literal is present (besides the space) for the string.
Reference ref- socket is used in external connectors linking attributes of different classes. It provides the connector with IDO descriptors for data objects of another class, using the corresponding relation attribute ( ref context ) in its class as the source of values.
The “key” key- socket provides the connector with the key values, and is required for the implementation of working with lists. As a source of key values ( key context ), the base class attribute is used by default.
Without taking into account the specifics of the reference and key aspects , the logic of the interaction of context sockets with the basic one is common for all three contexts. So the base socket on each side of the connector will immediately interrupt the execution of the current method Set | Get , if at least one of its existing (that is, actually declared and still relevant) contexts contains an irrelevant meaning. In other words, ref- and key- contexts permanently also possess lock- context properties. This is not surprising if we recall that the value of any type can be reduced to a logical type.
The initiation of a conditional connector from its contexts is performed by calling one of two internal execution methods: Reset and Unset , belonging to the meta-socket. These methods are invoked by the context attribute during the execution of the Set method to the address of the underlying socket of the connector according to the following rules. If the current value of the attribute is relevant, then before any change of the attribute, the attribute will call the Unset method for all its sockets that have the Unset [ U ] flag set . Further, after assigning a new value, in the repeated cycle of traversing the tuple to invoke the Set derived methods, the attribute will call the Reset method for its own sockets which have the Reset [ R ] flag set. In other words, an attribute performs a simulation, first de-initializing its effective value, with all the ensuing consequences for the external environment of the attribute, and then performing initialization with a new value.
In turn, the base socket , when executing the Unset | Reset , will call the Set method to the opposite attribute of the connector with a set of parameters (including the current values of the existing contexts), imitating the de-initialization (Unset) of the property of the owning attribute, or its initialization (Reset) by the external value. It is easy to implement such an imitation if, in the parametric part of the Set method, to transfer not one pointer to the value, but two: to the value before the change, and to the new value. Then in the parameters Set , derived from Unset | Reset , one of the pointers will always be NUL.
For greater clarity, we illustrate what has been said with examples.
Consider the use of a reference ref aspect with the following example: The invoice in the Total attribute summarizes the value of the Sum attribute of all its Records. Hereinafter, in such schemes, the vertical line divides the spaces of class-related classes, and the protrusion on it denotes the measure of quantitative interaction of classes as many-to-one . In our example, many are Record .
The attribute [N] is an attribute of the direct link of the Entry relationship with the Invoice . If the relationship is implemented, this attribute gets the value of the IDO of the Object of delivery note as a value.
When any change occurs, the Sum value is actively passed to the Total attribute, while the underlying socket of the connector uses the declaration of the referenced ref socket to refer to the [H] attribute. The extracted ref value will be used as the address parameter (as a pointer to the target object) of the Set method, called to the address of the Total attribute. If the relationship is not implemented, the derived Set will not be invoked.
When the value is received by the [H] attribute, the latter method Reset initiates the base socket to the call of the Set method, the significant parameters of which will be the pair NUL → [the current value of the Sum ]. If you then de-initialize the value of [H] (break the relation), then the attribute using the Unset method initiates the base socket to call the Set method with the parameters [current Amount value] → NUL. That will lead to the fact that the current value of the amount will be "withdrawn" from the current value of the attribute Total .
Note: the additive functional of the attribute Total "can" correctly change the resulting value, receiving the input change in the value of the attribute-argument. Such behavior, characteristic of the so-called "lazy" calculations, lies at the basis of the implementation of all natural functionals. In relation to the above example, the Total attribute, there is no need to resort to the Get survey of all private Sums when changing any one; it is enough for it to take into account the magnitude and direction of the change.
Returning to the example: if the previously initialized reference attribute [H] gets a new value ( Record is removed from one Invoice , and is included in the other), then this attribute will cause Unset before the change, and Reset after the change. Thus, the amount of the record will be removed from the total of the first Invoice , and added to the second total . With any combination of external influences, the system permanently preserves the logical consistency of values.
To illustrate the work of the blocking aspect, we simply supplement the previous example: let a fixed discount be provided for each heading, which can be turned off manually.
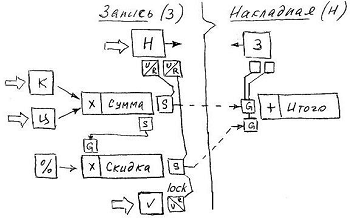
It should be noted that if the creation of a blocking sub-connector is done manually in the constructor, then the declarations of all reference sub-connectors are created automatically when the external connector binds attributes of different classes. Further, in all examples, reference sub-connectors are not shown. Also note that any attribute can be used as a blocking context, since the value of any type is automatically reduced to a logical one.
The following example illustrates the operation of the key- context of a connector: Objects of the Record class form a list of Currencies rates, which is then used to perform exchange operations with this currency.
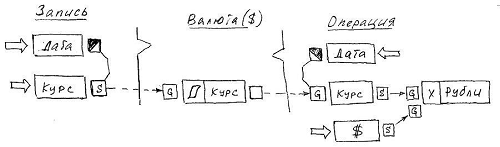 The Date attributes in the Record and Operation classes are the source of the key - the key context for the corresponding connector.
The Date attributes in the Record and Operation classes are the source of the key - the key context for the corresponding connector.
The Course attribute in the Currency class stores a list formed by the Date: Rate pairs, which are formed by the list functionality assigned to an attribute from the values that are actively (by the Set method) passed to it via the connector from the Record class. Note that in the parametric part of the Set and Get methods, a separate place is permanently allocated under the pointer to the key value.
In the Operation class, the Course attribute, using the Date method as the key in the Get method, retrieves the corresponding value from the list. Get itself is initiated by the active Reset method, generated by changing the value of: either the Date attribute or the reference attribute, a pointer to the Currency object (the corresponding reference attribute is not shown in the figure).
Note: in the previous example, the connector Course . [Currency] → Course . [Operation] is not active because the [ S ] flag is not set on the source attribute side. Accordingly, no changes in the list of courses will not be actively translated into existing Operations . However, changing the value of any of the contexts of the connector conditionally “activates” it, since it is accompanied by a call to the active methods Reset | Unset . And although Get itself is passive, nevertheless, the value returned by it will be assigned to the Course attribute during the execution of the original transaction to change the Date or the Currency reference.
A connector with the [ S ] flag is the unconditionally active connector .A connector that is devoid of its own activity, but with active contexts (as indicated by the flags [ R ] and [ U ] in its context sockets) is hereinafter referred to as a semi-active connector .
A connector with only the Get flag is considered a passive connector . If the connector resets all flags, then this is equivalent to its complete removal from the model. And pay attention: it is the Get flag that defines what is not mentioned earlier, but such an important property of a connector as a value transfer vector .
, .
. , .[] . ( .[]) , .
In addition, do not forget about emergency situations. For example, when a functionally dependent attribute is created already after the values of the attribute-arguments have been formed. In this case, you can restore data consistency only under compulsion, using Update.
Update , - , . , - .
, , . Update . , , .
, , : , , , . , - , . , , .
Meanwhile, this ability can be restored by allowing the attribute to reverse the entered value in one of the attribute-arguments. In other words, it is necessary to choose the recipient of the correction value, namely, the connector to which the reverse will be carried out. In our example, it seems logical if the Price attribute is selected by the recipient of the correction , for the connector with which the Set method can be invoked from the Sum side by setting the corresponding flag [ S ] in the Get socket, as shown in the figure.
Note that the actual performer of the reversible transfer of the value is always the attribute functional, which has the appropriate algorithm for calculating the correction value. It defines the target attribute for transmission through a socket, in which the [ S ] and [ G ] flags are set simultaneously.
Reverse values can be implemented in the address of any attribute that has the ability to accept value from the outside, including such an attribute, which itself acquired this ability due to the inclusion of the reverse:
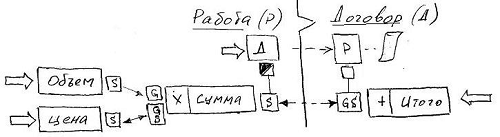
After receiving input from the outside, the Total attribute uses the list of backlinks to reversely distribute its change to the Sum attributes for all Work objects from the back reference list ( ref- context). You should not think that the given example is devoid of practical sense: here the cost of the work is adjusted to the maximum amount voiced by the customer. However, it is worthwhile to give one more example of the distribution of values, also based on the reverse mechanism.

In each of the classes, the Clock attribute is used as a key context to the reversible connector, thus providing it with basic values for the proportional distribution of the Sum value .
A socket has an inversion property that is enabled by setting the Inverse flag . The meaning and application of this property is different for sockets on different sides of the connector.
So if the inversion flag is set to an outgoing base socket or a context socket, then the value passed through that socket will be inverted: a positive number will become negative, and the logical value will change to the opposite.

Setting the inversion flag for the incoming ( Get -) socket of the connector will change the operational behavior of the attribute's functionality. So the value obtained through the inverse socket, the multiplicative number functional will be considered as a divisor, and not as a factor. Similarly, a value received via an inverse socket will be considered additive by the additive functional as a deductible.
The most remarkable thing is that the connector technology is also fully used for the internal needs of the data model itself. And in particular - for the implementation of the mutual exchange of identifiers of derived objects of classes, within the framework of the declaration of the relationship between these classes and in accordance with the requirements of the reference symmetry. The reference attributes that make up the class relationship are obviously in a direct causal relationship, which in the data model is expressed as a connector declaration.
In addition to the connector, the so-called service attributes are used to implement the relationship.. These attributes, which perform certain utilitarian functions, are declared directly in the tuple of the meta-class, and therefore are present in the tuple of each user class.
The source of the value for the reference connector is the service attribute Own . This attribute is typed by its own class descriptor. When a class creates a derived object, it stores the IDO descriptor of that object as the value of the Own attribute . Another service attribute - Del , the default is used as a lock
-context for all, without exception, outgoing external connectors connecting the attributes of different classes. This declaration provides adequate behavior for the object being deleted, namely, the removal ( Unset ) of attribute-argument values from the values of attribute-recipients localized in other classes.
Well, the actual reference attribute itself acts as a ref- context of the active reference connector, providing it with the IDO handle of the target object.
The value of the list of backlinks is formed by the list functionality of the key-value pairs, where the value is the IDO of the object that owns the direct link, and as the key source ( key-context) by default, the base class attribute is used . Thus, the formation of a list of backlinks is essentially no different from the formation of a list of courses from the example above, in which the lock context of Del , and the ref context of [B] are also present, but were not shown in the diagram.
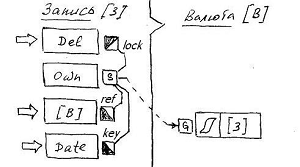
It is worth emphasizing once again that this whole structure, which includes service attributes and a reference connector, is created automatically by the relationship designer.
Although the socket has an Unset / Reset method connector , the connector does not have its own functionality. Logically linking attributes, the connector is merely a declaration of the presence and nature of the causal dependence of the derived values. The implementation of this dependency itself is carried out exclusively by attribute methods. Therefore, the connector functionality should be understood as a complex declarative property of the dependency described by it.
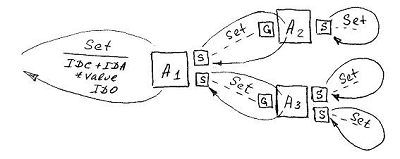
Being a purely virtual entity, the connector is made up of meta-socket instances.that are logically related by mutual addressing. Accordingly, the nature of the declared attribute dependency is determined both by the combination of the sockets forming the connector and by setting the flags of the individual instance. A separate socket can be connected to four other sockets, each of which is assigned a strictly unambiguous functional aspect: basic (opposed) ( base -), blocking ( lock -), referential ( ref -) and additional ( key -). Accordingly, the address part of the properties of a meta-socket includes three routes in terms of IDA + IDE + IDS (the meaning of the IDE descriptor will be clear later), of which a pointer to base-socket supplemented by an IDC descriptor . Property Meta socket defining its transfer function includes five flags: S et , G et , R eset , U nset , I nverse .
Not previously mentioned, but the meta-socket declaration also includes an IDF functional descriptor . The attribute allows you to generate your value in the only way, so the incoming socket ( Get-) This property is not used. But the outgoing socket, as well as the context sockets of the complex connector, can use not only the stored value of the attribute, but also the transformed value obtained through the functional.
In all the examples considered earlier, by default it was assumed that class attributes operate on persistent values that are stored in a database in tuples of class objects. The fact of long-term storage of derived values allows characterizing such attributes as static . For static attributes, data sampling, implemented by the execution of the Get method , is reduced to simple retrieval and return of the stored value, regardless of all other conditions, including the presence of incoming connectors for the attribute.
. , (, « »). Get Get . , , , . : - Get Unset/Reset , .
An exception may unexpectedly become a rule, under certain conditions. It is not necessary to use a stored value if it can be dynamically generated, based on incoming connectors for attribute arguments. To give the attribute of such behavior, it is enough to set the corresponding flag in its properties.
When implementing a sample, the dynamic attribute ignores the stored value, even if it exists in the data object, and uses only the functionals assigned to it and cause-and-effect relations expressed by connectors to form the value. During polling, Get Get calls will be made only for those sockets from the tuple that have the Get [ G ] flag set .
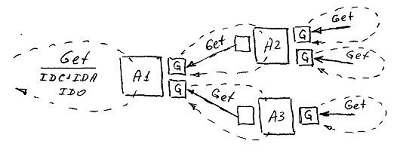
Note that even with incoming connectors, not all attributes can be translated into a dynamic form. Baseline entity characteristics, reference values, and all lists, can only exist statically. And do not forget that directly or indirectly, but the value of a dynamic attribute is formed from stored values.
Since a dynamic attribute does not form a stored value, all its incoming connectors are forcibly transferred to an inactive form by resetting the Set | Unset | Resetin all sockets. This allows you to automatically exclude an unnecessary call to the active method in the address of a dynamic attribute. In all other respects, the behavior of a dynamic attribute corresponds to all the rules and examples considered earlier and, which is of fundamental importance, ensures unconditional logical consistency of data.
The use of dynamic attributes naturally reduces the amount of stored data, but this is not the meaning of their use. If discard operations are removed from consideration, then in a data model formed only by static attributes, the execution time of a value is orders of magnitude shorter than the atomic transaction execution time, the duration of which also depends on the volume of subsequent dependencies. This imbalance is partially compensated by the quantitative ratio of samples and transactions — the samples are usually an order of magnitude larger.
. , , , . , .
The derived attribute value can be either a single ( atomic ) value or a set of similar values in a tuple format, considered as a trivial array ( enumeration ). It should be noted that the idea of an array of values as a value of the characteristic of a conceptual entity is present initially, and therefore its use is only a more accurate correspondence of the data model to the target subject domain.
The array declaration in the attribute properties, as well as its implementation, also takes the form of a tuple whose elements contain custom names for the array elements. If the tuple of names is not initialized, then this means that the attribute operates on a single value, and is considered atomic . . , . , , : “1“ “2“.
, , – IDE . , , , : IDC+IDA+IDE+IDS . , IDE . IDE 0, , .
. . , . - IDE , “" , . , , .
The list is formed by key-value pairs, while the types of key values and the actual values are the same for all list items, which is not surprising if we recall the mechanism of their formation in the above examples of backlinks list and Currency . {Course}. Nominally, there are no direct restrictions on the use of value types, both as a key and as a value itself, are not imposed. So for the backlink attribute, the value is the IDO handle of the class object. From the point of view of logical representation, the list is linear, homogeneous, and ordered in order of increasing key value.
All lists are instances of another, not previously mentioned member of the meta-definition level - the meta-list .Meta-list owns a complete set of methods for managing the list, and provides: creating a list, inserting and deleting elements, selecting data and obtaining numerical characteristics of the list. Physically, the list is implemented as a B-tree, the root, nodes and leaves of which are instances of a meta-tuple, which in turn are stored in data objects.
At the data model level, a meta-list does not create derived instances. Instead, the class attributes are assigned various functionals from the family of list functionals , which actually carry out direct work with lists, using the methods of the meta-list. List functionals are defined separately for each pair of key and value types, which allows not only to take into account the specifics of the type, but also to expand the palette of ways to control the values in the list.
The value type system forms a natural hierarchy in which the ancestor type domain includes the value domains of all its descendants. In other words, an attribute typed by an ancestor can take any value of a type of heir, leading it to an internal form of representation of its type, if necessary.
– [ U ]. – , : , . , , Undefined Type -.
[ L ] , : – true , – false. The second case also includes such particulars as zero for a number, and the absence of other literals except a space for a string.
For type String [ S ], the value is a sequence of literals of arbitrary length. In this case, the encoding type (ASCII or UTF) is the same for the entire database, and is set when it is generated. But if necessary, you can create sub-domains (subtypes) for different encodings. On the procedure for storing the values of String is not affected.
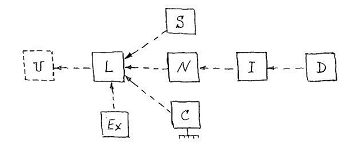
The type Numeric [ N ] combines all real numerical values considered in the decimal system with a floating or fixed decimal point. From it the type Integer is selected [I ] –– the whole set of positive integers, from which the Date [ D ] type is selected - integers in the calendar system of calculation.
The Complex [ C ] type, also known as the User Defined Type [ UDT ], is an abstract prototype domain that combines a set of user-created complex value types — data classes. Domain of class values, includes domains of values of all classes generated by inheritance from this class. As a domain value formed by a class, both a data object itself and a pointer to it, the IDO descriptor, can be equally considered as a data object derived from a class. .
External [ Ex ] , , , . External , , . External Image , .
Numeric [ N ] Date [ D ], (/) . Numeric . Date – CYMDhms, , .
As already mentioned, the functionality is a predefined method, identified by an IDF handle. The original set of functionals includes the most primitive, but most frequently used methods of forming values, but this set can be easily extended by adding new functionals to it. For each type of value, there is a set of natural functionals:
- for Logical - additive (logical OR) and multiplicative (logical AND);
- for String - additive (concatenation);
- for Numeric - additive, multiplicative, minimum, maximum;
- for Integer - additive, multiplicative, minimum, maximum;
- for Date - additive (shift), minimum, maximum;
- for Complex - additive (assignment), Autoset;
All listed functionals allow obtaining values from a variety of sources (connectors). The role of the functional of assigning values from a single source by default is played by the additive functional. For all types, except Logical and External , there are list functionals . Separately, it is also worth briefly mentioning the interval functional , which ensures the formation of interval values, and by means of which both the internal dependencies of the values forming the interval and the operations on interval values are implemented. It would be logical to assume that the interval value is complex, and has an enumerated form.
Each list functionality is a wrapper function that encapsulates a meta-list and uses meta-list methods, the internal implementation of which the functionality overrides for its own goals and objectives. The entire family of list functionals includes several groups.
The functionals that create and modify the list are identified with the actual list, more precisely, its functional type. In addition to the “ simple ” list, this group includes a “ unique ” list (the list does not allow duplicate key values), as well as its two logical modifications operating with numerical values: a “ totalization ” list (values with the same key are added together) and its subsequent modification - " integral " (values with the same key are summed with the addition of the value of the preceding element). These functionals are assigned directly to the attribute as its incoming functionality, thereby making the attribute a list attribute. Functionals of this group need at least one incoming active connector — the source of the key and value — to form the actual list.
Sample functionals that return a value from the list are always assigned to the outbound connector socket, localized in the list attribute tuple. Although this also simulates the "postscript" of such a functional to the attribute-recipient. Actually the key itself is a context (key source), can be declared for any of the basic sockets of this connector.
Functionals sampling values by key differ in the positioning condition: " equal " (precise positioning), " less " (positioning on a logically preceding element), " greater " (similarly, only the next one), " equal or less " and " equal to or more "(if not exactly then preceding or following). If there is no element that satisfies the condition, the functional will return the equivalent of the " empty " value. A subgroup of functionals similar to them instead of a value returns the position of the element — its ordinal number in the list. Another subgroup of functionals (" first / last / N " - " key / value ") returns the requested from the first, last, or specified (N) list items.
Not all problems can be solved by combining primitive functionals. To implement complex algorithms, the Script container is provided in the attribute properties, in which you can place an arbitrary script (for example, in Python) as a private functional of a specific attribute instance. The practice of creating various applications has unexpectedly shown that this tool has to be used quite rarely. Note that in the script body of a static attribute, it is allowed to use active methods addressed to the class ( Create ) or class attribute ( Set or Update ). For a dynamic attribute script, only the Get method call is allowed.
A class attribute is an instance of a meta attribute . The attribute is characterized by a custom name ( Name ), unique within its own class, value type ( Type ), type metric ( Metric ), and the Dynamic flag. In addition, the attribute owns an IDF functional descriptor, a Script container, and two tuples: array elements ( Item list ) and sockets ( Socket list ). In a tuple of a native class, the attribute is identified by an IDA descriptor.
In the data model, the attribute performs the function of a value factory , and from this point of view it is the central actor of the object data management environment. To perform operations on values, the attribute uses the Set , Get, and Update methods, as well as a set of type-dependent functionals.
Attributes connected by connectors form a topology, somewhat resembling the topology of a neural network. Recall the starting point - the subject area is considered as a system of interacting values. Accordingly, the ideal hardware platform for such a network looks like a set of independent primitive processors interconnected by serial channels. In such a hardware environment, you can simulate a variety of processes.
Service attributes are permanently present in a tuple of any class where they occupy strictly fixed positions. These attributes are used by the data model to solve its own problems. So the Del and Own attributes mentioned earlier provide the implementation of a symmetric connection of class objects. Another, not mentioned earlier, service attribute - Type , in the class object stores the structural type of the object - the IDC descriptor of the factory class.
A data class is an instance of a metaclass regardless of how this instance was obtained. A class is characterized by a custom name ( Name ), unique in the full set of classes, a visual image ( Image ), and an attribute tuple ( Attribute list ). In the full set of classes, a single class is identified by an IDC descriptor. If the class was created by inheriting from another ancestor class, then in the Parent property the class stores the IDC of the ancestor class.
In the object management computing environment, the class performs the function of a factory of objects using the Create meta method of the class. A class object is created as an instance of a class attribute tuple.
Deleting an object is not a class prerogative. The object is logically deleted by initializing the value of the service attribute Del , which, in order to ensure logical integrity, is automatically present in all external connectors as a lock context. The initialization of Del entails the de-initialization of all the effective connections of the object, putting the object into an isolated state. Subsequently, a logically isolated object will be physically deleted by the garbage collector.
A data class can be created not only as an instance of a meta-class, but also by inheriting from another class. The object of inheritance is the full tuple of attributes of the ancestor class, which is permanently present in the tuple of attributes of the heir class. This allows an ancestor class to include into its domain all objects, generated by both direct and mediated by its heirs, without exception, regardless of the depth of inheritance. An inherited tuple is the natural interface to all objects in the ancestor class domain.
The mechanism for implementing attribute tuple inheritance is extremely simple: an instance (!) Of ancestor attribute tuple is created in the heir class. This instance, by definition, contains no values, since there is no need to duplicate the attribute declarations - the required declarations can be obtained by referring to the ancestor class tuple. A descendant class will generate a complete declaration of an attribute only if it makes its own private changes to it, or if it creates a new attribute of its own. When a new attribute is created in an ancestor class, then, in advance, the full set of its heirs determines the maximum size of the attribute tuple, after which the created attribute is allocated an element in the ancestor's tuple beyond this size. Thus, the new attribute of the ancestor automatically becomes available to all his heirs. The non-initialized elements generated in the tuples can be neglected, since they practically do not take up space.
Heir polymorphism is implemented by overriding the rules for obtaining values for inherited attributes, while preserving their type. At the same time, it is forbidden to change inherited connectors, which, if necessary, should be deactivated and created new ones.
Looking ahead, it is worth mentioning that a user data class, being a complex entity, has many forms of its interface (including visual) presentation. The descendant class fully inherits the ancestor's presentation forms, with the possibility of overriding them. The natural combination of polymorphism with " polyformism " is a powerful tool for developing an application.
In the total mass of class attributes, one can always single out one whose value is used for user identification of a specific object of this class, such as the Name attribute in the Counterparty class. Such an attribute performs the function of a basic class attribute .
It is logical to assume that it is the base attribute that should automatically be used as a key context for any connector to the list functionality, including lists of backlinks. For this, the base attribute must have a fixed position in the tuple of any class, namely, it must be placed immediately after the service attributes.
Of all existing value types, only two types, String and Date , can be meaningfully assigned to the base attribute when it is created. These two types of typing predetermine the existence of two prototype classes: Named class and Event class , with corresponding basic attributes.
It is convenient to use prototype classes as templates when creating custom user classes, which not only seems logical, but also gives a small gain: the class created immediately includes the basic attribute of the desired type with the necessary name.
Already repeatedly checked - you can’t create a regular program with the mouse. In the case of using the application / data model, everything is strictly the opposite: textual notation looks like a dull, little informative listing of declarations. But in the visual environment, the same declarations look natural and very clear: there is a common space displayed in whole or in part connected by class relations, and the transition to the visual space of a class opens up many of its attributes with their connections. However, the principles of interface presentation and the mechanisms for its implementation are also a topic for a separate article.
An executive data model is created and modified through its presentation form — an application model. The editor of this model is a visual designer, operating with images of model entities. The transition from the user interface of the application to the visual environment of the designer and returning back to the application execution environment while preserving the current state of the interface is performed simultaneously with a hot key. In this case, all changes made by the designer take effect immediately. If something is done wrong, it will become immediately obvious: in the form of an erroneous result or lack of response to an interface event, without interrupting the application.
The constructor creates new model components as declarative instances of meta-entities, while completely hiding the real descriptors of derived instances. The initial set of basic meta-entities is small, which makes it easy to control the logical consistency of newly created declarations that already exist in the model by simply excluding the conflicting editor tool or structural component from access.
A valid data model is a simple type declaration for an entity-property, which means it can be exported in text format: XML, JSON, or in the form of a sequence of transactions to create its components. Internal descriptors are not exported to the text view; instead, custom class and attribute names are used.
A data model describes an information system with states . Accordingly, it cannot be used to implement a driver, for example.
Also with its help it is impossible to implement a separate algorithm or subroutine - the data model describes the subject area only as a whole.
For performance reasons (due to the lack of appropriate hardware), the data model cannot be used to directly simulate physical processes in real time. Although there is such potential.
Seeming to be senseless attempts to create a universal model of "everything in the world." An application program always reflects the subject area only from a strictly defined point of view and within certain limits. And for another point of view, the same subject area may look different.
Otherwise, the computing environment based on the data model is designed to solve the same problems that are solved on the basis of all other databases. But it has some useful properties.
Agree, the visual model of the application gives a more visual perception of business logic.
Reference symmetry allows you to use all the power of natural navigation methods, both in data and in meta-data.
The executive data model that forms the application is only a declaration stored in the database, which is completely independent of the processor architecture or the operating system.
The speed of development, algorithmic reliability, strict referential integrity, permanent consistency - all this is a direct consequence of the integration of business logic directly into the logical structure of the database. And while fundamentally changing the approach to the implementation of the interface of the application, which is subject to a separate detailed consideration.
Nature shows us its infinite variety, obtained by the infinite combination of elements in a very tiny base set (nod towards DNA). This is her favorite trick.
Only four abstract entities form a basis, which is enough to informationally describe any subject area. Declarative instances of all three meta-entities are sufficient to formalize this description as a data model. And, in the computational environment of the object representation formed by the six executive methods of meta-entities, the model will behave like a program, giving the desired result.
All of the above is just a further development of the EFKodd relational model, as well as K.Date's ideas on combining relational and object technologies. The essence of the relational model remains the same: tables, columns, tables connection. It just added a fourth element, so natural, but for some reason not mentioned by Codd, the connection of columns in the tables.
If the automation domain is a system of interacting values, then it can be described by the ER model, which is formed by instances of just four abstract entities: a data class , a class attribute, a class relationship , and an association of attributes . Such a model not only forms the logical structure of the database, but possesses all the properties of the program, which in essence is - in the computing environment formed by the methods of the mentioned abstract entities.
Consider this bold statement in more detail, starting with the most common definitions. (The following repetition of the well-known is necessary at least to indicate the meaning of the terms used. It will be dry and tedious - as in any other theoretical material. To enliven it slightly, examples are embedded in the text.)
Virtually any objectively existing subject area can be viewed from an informational point of view as a system of interacting values . Immediately, we note that a single value is never either independent or self-sufficient, since it exists as a certain characteristic of a data object . Therefore, a complete set of data objects with their values is necessary for an accurate description of a subject area in a certain state. At the same time, single-type objects are described by a data class , and exist on the rights of derived instances of this class - class objects .
')
Classes and Attributes
The data class expresses a separate conceptual essence of the subject domain in question and is characterized by the user name of this entity. In turn, any conceptual entity has some unique set of its own characteristics / properties. The class attribute expresses a separate characteristic of an entity, is named the user name of this characteristic, has a type that defines the set (domain) of its valid values, and acts as a factory of specific characteristic values in class objects.
Accordingly, a data class owns a set of attributes (class) that it stores in a tuple format. Acting as a factory of objects, a class forms the contents of an object as a tuple of values , which is an instance derived from the attribute tuple . In addition, each value in the tuple of values of a class object is an instance derived from the corresponding class attribute.
Thus, a very specific subject area that exists as a set of objects with their values is described at the level of abstraction by a system of classes with their attributes. And at the same time, data and metadata represent a persistent data structure stored in an object database .
Class relationship
The basis for the implementation of communication data objects based on the principle of symmetry. In accordance with this principle, the objects being linked mutually exchange their identifiers. The object identifier ( IDO descriptor) is global within the physical database, and is a simple integer.
At the level of abstraction, the relationship of objects is described by a class relation . The declaration of a relationship is implemented by creating an attribute in each of the two classes connected by a relationship, which mutually address each other. Each of the attributes of the relationship is typed by the opposite class of the relationship (each class is considered to be an independent user data type), as a result of which the domain of values of the reference attribute is a set of object descriptors of the opposite class.
The class relationship sets a measure for the quantitative interaction of the derived objects of these classes. With all the simplicity of this definition, relations have so diverse functional behavior and mutual logical dependence that this extensive topic will be considered separately.
In the meantime, it is worth mentioning that with respect to one-to-one, both reference attributes are absolutely equal, and their value in data objects will be the only descriptor of a communication partner. In relation to the many-to-one attributes are obviously not equal: neither by the format of the stored value, nor by the order of formation of the value. If, on the side of the many , the attribute value of the [ direct link ] is still the only descriptor, then on the side of the one , as a result of strictly observing the reference symmetry, the value of the attribute [ backward reference ] will be a set of descriptors representing the key-value list. In this case, the value of the reverse link attribute is derived from the value of the direct link attribute. The mechanism for implementing this derivative will be discussed in detail below.
Attribute Relationship
The interaction of values is understood as their causal functional relationship. This relationship exists only at the conceptual level of abstraction, where it takes the form of a virtual connector of two attributes. By analogy with the class relationship, the attribute association declaration is implemented by creating two sockets (parallel with TCP sockets is appropriate), each of which belongs to its own attribute, and is placed in its socket tuple .
A separate socket describing the properties of communications from its attribute is the same persistent data structure of the abstraction layer as a class and attribute. Like relationship attributes, the sockets that make up the connector mutually address each other. For these purposes, the socket declaration contains a complex identifier ( class + attribute + socket ) of the opposite socket connector. Also, the socket declaration contains a set of flags that control the transmission and reception of values through a connector.
Tuple
Logically, a tuple is a simple enumeration of homogeneous (in terms of a tuple) elements containing a certain number of bytes of data. Knowledge of the content and methods of its formation lie outside the tuple. The tuple only provides space for storage and long-term storage. Features of the internal implementation of the tuple were discussed here .
A tuple element is uniquely identified by its place (sequence number) in a tuple that never changes. When added to a tuple, the new element takes its place once and for all.
The content of a tuple element can be either a unitary value or another tuple. This makes the tuple the main (and only) structure-forming component of the object representation. For example, a class declaration is a tuple whose elements are class properties, one of which is a class attribute tuple.
A tuple has the ability to create its own instance, which is an empty tuple whose elements have no content. This ability is used, for example, by a class, both when creating inheritance classes and when creating its derived objects, in which the mutual identification of attributes and values derived from them is ensured by the coincidence of the element numbers in the corresponding tuples.
Identification system
The constancy of the space occupied by an element in a tuple underlies the system of internal identification of entities, which in its most general form looks like this:
Each entity is identified by its descriptor - a sequence number in the corresponding tuple: IDC - class, IDA - attribute, IDS - socket, IDO - object (logically DAT objects should also be considered as a tuple). Logic also suggests that classes are elements of a tuple whose specific owner is covered in the class relationship article.
Models and Meta Entities
What is remarkable - at the level of abstraction, there are two models at once, formed by various entities of this level.
The collection of stored class declarations, attributes, and sockets forms the data model . The data model is considered to be executive , since the entities forming it perform in relation to the data level the function of the object factory (class) and the value factory (attribute).
The application model is virtual, and exists on the rights of the form of data model representation . An application model is dynamically created by a visual designer , which uses it to display an existing data model, and create new declarations in it, by creating new application model entities. Along with the real class and attribute , such virtual entities as relation and connector take part in the formation of the application model . Virtual entities do not form stored declarations, but are created dynamically from attribute and socket declarations, partially encapsulating the fact of their existence. The virtual nature of the application model does not interfere at all to consider it as a primary domain model .
In turn, all the listed real and virtual entities of the level of abstraction are instances of entities of a still higher level of abstraction - the level of meta-definitions . At this level, structurally and programmatically implemented such entities as: meta-tuple , meta-class , meta-attribute , meta-relation , meta-socket and meta-connector .
It is worth emphasizing once again that all design methods by which both models (data and applications) are created and changed, as well as all the execution methods used by the data model in relation to objects and data-level values, belong to meta-level entities. The model level, which ensures the creation and execution of all business logic of the application, is formed exclusively by declarative instances of meta-entities, and does not contain executable code.
Execution methods
Design methods by which instances of meta-entities are created and the values of one or another of their properties are redefined are quite obvious and do not require comments. What cannot be said about the methods of execution forming the notorious computing environment, with the help of which external influences change the state of data in accordance with the rules declared in the form of a data model. As a matter of fact, the call of the method of execution is such an external influence. In total, there are four such methods: Create , Set , Get, and Update .
The Create method belongs to the meta-class, and is used to create a derived class object. The method parameter is the IDC descriptor of the target class. The Create method creates an object as an instance of the attribute tuple of the specified class, and registers it in the DAT allocation table for the next free IDO descriptor.
Attribute methods: Set , Get and Update , belong to a meta-attribute, and allow you to operate on the values of data objects. The Set method is responsible for assigning a value, the Get method is responsible for fetching a value, and the Update method is an event that triggers an attribute to re-form a derived stored value (the meaning of this action will become clear later).
For attribute methods, the target object is identified by the IDO descriptor, and the target value itself is available exclusively through the class attribute, the path to which is represented in the IDC + IDA data model descriptors. In other words, all actions on a value are performed on behalf of a class attribute. A feature of the execution of attribute methods is that in its course each method resorts to iterating over the sockets in the attribute tuple, invoking a similar method for the target attribute addressed by the connector, provided that the flag is set to the same name in the socket.
Since the execution of any of the three methods: Create , Set or Update , will change the state of the data , they can only be called in the context of a transactional session . Calling any of these three methods is an atomic external impact on the database, which is easily formalized into a transaction format , and then saved in a log.
Consider the logic of the execution of attribute methods in a little more detail.
Assignment of value
So, the Set method is called, to which the address parameters have been passed, and a pointer to the value to be assigned ( * value ). In the body of this method, the attribute will generate a new value, perform its assignment to the corresponding element of the object tuple, and then begin sequential search of sockets from its tuple. For each socket for which the Set [ S ] flag is set , the source attribute will call the Set method for the attribute, the path to which is specified in the socket declarations. Note that the execution of the method can be completed ahead of time, without bypassing the socket tuple, if the new value is equivalent to the stored one.
When making derived calls to Set , the attribute follows the principle of isolation - “fired, and forgot,” without worrying about the consequences. The further course of events is determined by other actors-attributes. At the same time, what is important, the transactional nature of the execution ensures the permanent consistency of all variable values, regardless of the scope and “length” of the changes.
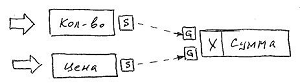
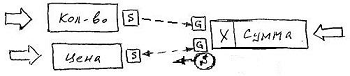
Consider the formation of derived values for example from the life of accounts and invoices:
In the diagram, the contour arrows indicate the user input of values, the same external call Set . Any change in the attribute values Quantity or Price is actively transferred to the Sum attribute, which uses a functional , in this case - multiplicative, to form a derived value.
Functionals are predefined (for each value type) meta-attribute methods that allow the resulting value to be generated by converting argument values obtained via connectors from one or more source attributes. An attribute is assigned a functional by assigning its descriptor ( IDF ), which is a sequence number in the general list of functionals.
If an attribute is assigned a functional, then all Set and Get calls to the attribute address are processed by this functionality, if necessary with additional polling ( Get ) of sources. Note: to exclude the original call source from polls, the address part of the call ( IDC + IDA ) permanently includes the socket socket ( + IDS ) as well.
Dependent connector
Both connectors from the above example were used in simple unconditional form.
Meanwhile, the functional behavior of the connector can be made dependent on the valid values of third-party attributes, which for the original connector form a kind of " execution context ". To implement communication with context attributes, socket declarations provide for the possibility of addressing three additional, so-called " context " sockets. Each context socket has its own, strictly fixed purpose-aspect: blocking ( lock ), reference ( ref ) and key ( key ), but at the same time these are exactly the same meta-socket instances as the " basic " sockets of the connector. To address each context socket to the base one, two descriptors are enough: IDA + IDS .
A blocking lock- socket allows the transfer of a value over a connector, if the value returned by it is relevant, and blocks otherwise. Actual is the initialized value of the socket's owner attribute ( lock-context ), which is additionally evaluated from the point of view of its type: true for logic, not zero for a number, and at least one literal is present (besides the space) for the string.
Reference ref- socket is used in external connectors linking attributes of different classes. It provides the connector with IDO descriptors for data objects of another class, using the corresponding relation attribute ( ref context ) in its class as the source of values.
The “key” key- socket provides the connector with the key values, and is required for the implementation of working with lists. As a source of key values ( key context ), the base class attribute is used by default.
Without taking into account the specifics of the reference and key aspects , the logic of the interaction of context sockets with the basic one is common for all three contexts. So the base socket on each side of the connector will immediately interrupt the execution of the current method Set | Get , if at least one of its existing (that is, actually declared and still relevant) contexts contains an irrelevant meaning. In other words, ref- and key- contexts permanently also possess lock- context properties. This is not surprising if we recall that the value of any type can be reduced to a logical type.
Socket methods
The initiation of a conditional connector from its contexts is performed by calling one of two internal execution methods: Reset and Unset , belonging to the meta-socket. These methods are invoked by the context attribute during the execution of the Set method to the address of the underlying socket of the connector according to the following rules. If the current value of the attribute is relevant, then before any change of the attribute, the attribute will call the Unset method for all its sockets that have the Unset [ U ] flag set . Further, after assigning a new value, in the repeated cycle of traversing the tuple to invoke the Set derived methods, the attribute will call the Reset method for its own sockets which have the Reset [ R ] flag set. In other words, an attribute performs a simulation, first de-initializing its effective value, with all the ensuing consequences for the external environment of the attribute, and then performing initialization with a new value.
In turn, the base socket , when executing the Unset | Reset , will call the Set method to the opposite attribute of the connector with a set of parameters (including the current values of the existing contexts), imitating the de-initialization (Unset) of the property of the owning attribute, or its initialization (Reset) by the external value. It is easy to implement such an imitation if, in the parametric part of the Set method, to transfer not one pointer to the value, but two: to the value before the change, and to the new value. Then in the parameters Set , derived from Unset | Reset , one of the pointers will always be NUL.
For greater clarity, we illustrate what has been said with examples.
Execution examples
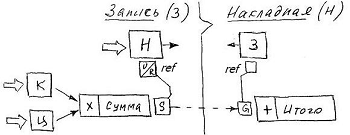
Consider the use of a reference ref aspect with the following example: The invoice in the Total attribute summarizes the value of the Sum attribute of all its Records. Hereinafter, in such schemes, the vertical line divides the spaces of class-related classes, and the protrusion on it denotes the measure of quantitative interaction of classes as many-to-one . In our example, many are Record .
The attribute [N] is an attribute of the direct link of the Entry relationship with the Invoice . If the relationship is implemented, this attribute gets the value of the IDO of the Object of delivery note as a value.
When any change occurs, the Sum value is actively passed to the Total attribute, while the underlying socket of the connector uses the declaration of the referenced ref socket to refer to the [H] attribute. The extracted ref value will be used as the address parameter (as a pointer to the target object) of the Set method, called to the address of the Total attribute. If the relationship is not implemented, the derived Set will not be invoked.
When the value is received by the [H] attribute, the latter method Reset initiates the base socket to the call of the Set method, the significant parameters of which will be the pair NUL → [the current value of the Sum ]. If you then de-initialize the value of [H] (break the relation), then the attribute using the Unset method initiates the base socket to call the Set method with the parameters [current Amount value] → NUL. That will lead to the fact that the current value of the amount will be "withdrawn" from the current value of the attribute Total .
Note: the additive functional of the attribute Total "can" correctly change the resulting value, receiving the input change in the value of the attribute-argument. Such behavior, characteristic of the so-called "lazy" calculations, lies at the basis of the implementation of all natural functionals. In relation to the above example, the Total attribute, there is no need to resort to the Get survey of all private Sums when changing any one; it is enough for it to take into account the magnitude and direction of the change.
Returning to the example: if the previously initialized reference attribute [H] gets a new value ( Record is removed from one Invoice , and is included in the other), then this attribute will cause Unset before the change, and Reset after the change. Thus, the amount of the record will be removed from the total of the first Invoice , and added to the second total . With any combination of external influences, the system permanently preserves the logical consistency of values.
To illustrate the work of the blocking aspect, we simply supplement the previous example: let a fixed discount be provided for each heading, which can be turned off manually.
It should be noted that if the creation of a blocking sub-connector is done manually in the constructor, then the declarations of all reference sub-connectors are created automatically when the external connector binds attributes of different classes. Further, in all examples, reference sub-connectors are not shown. Also note that any attribute can be used as a blocking context, since the value of any type is automatically reduced to a logical one.
The following example illustrates the operation of the key- context of a connector: Objects of the Record class form a list of Currencies rates, which is then used to perform exchange operations with this currency.
The Course attribute in the Currency class stores a list formed by the Date: Rate pairs, which are formed by the list functionality assigned to an attribute from the values that are actively (by the Set method) passed to it via the connector from the Record class. Note that in the parametric part of the Set and Get methods, a separate place is permanently allocated under the pointer to the key value.
In the Operation class, the Course attribute, using the Date method as the key in the Get method, retrieves the corresponding value from the list. Get itself is initiated by the active Reset method, generated by changing the value of: either the Date attribute or the reference attribute, a pointer to the Currency object (the corresponding reference attribute is not shown in the figure).
Connector activity
Note: in the previous example, the connector Course . [Currency] → Course . [Operation] is not active because the [ S ] flag is not set on the source attribute side. Accordingly, no changes in the list of courses will not be actively translated into existing Operations . However, changing the value of any of the contexts of the connector conditionally “activates” it, since it is accompanied by a call to the active methods Reset | Unset . And although Get itself is passive, nevertheless, the value returned by it will be assigned to the Course attribute during the execution of the original transaction to change the Date or the Currency reference.
A connector with the [ S ] flag is the unconditionally active connector .A connector that is devoid of its own activity, but with active contexts (as indicated by the flags [ R ] and [ U ] in its context sockets) is hereinafter referred to as a semi-active connector .
A connector with only the Get flag is considered a passive connector . If the connector resets all flags, then this is equivalent to its complete removal from the model. And pay attention: it is the Get flag that defines what is not mentioned earlier, but such an important property of a connector as a value transfer vector .
Logical consistency
, .
. , .[] . ( .[]) , .
In addition, do not forget about emergency situations. For example, when a functionally dependent attribute is created already after the values of the attribute-arguments have been formed. In this case, you can restore data consistency only under compulsion, using Update.
Event Update
Update , - , . , - .
, , . Update . , , .
, , : , , , . , - , . , , .
Meanwhile, this ability can be restored by allowing the attribute to reverse the entered value in one of the attribute-arguments. In other words, it is necessary to choose the recipient of the correction value, namely, the connector to which the reverse will be carried out. In our example, it seems logical if the Price attribute is selected by the recipient of the correction , for the connector with which the Set method can be invoked from the Sum side by setting the corresponding flag [ S ] in the Get socket, as shown in the figure.
Note that the actual performer of the reversible transfer of the value is always the attribute functional, which has the appropriate algorithm for calculating the correction value. It defines the target attribute for transmission through a socket, in which the [ S ] and [ G ] flags are set simultaneously.
Reverse values can be implemented in the address of any attribute that has the ability to accept value from the outside, including such an attribute, which itself acquired this ability due to the inclusion of the reverse:
After receiving input from the outside, the Total attribute uses the list of backlinks to reversely distribute its change to the Sum attributes for all Work objects from the back reference list ( ref- context). You should not think that the given example is devoid of practical sense: here the cost of the work is adjusted to the maximum amount voiced by the customer. However, it is worthwhile to give one more example of the distribution of values, also based on the reverse mechanism.
In each of the classes, the Clock attribute is used as a key context to the reversible connector, thus providing it with basic values for the proportional distribution of the Sum value .
Invert Socket
A socket has an inversion property that is enabled by setting the Inverse flag . The meaning and application of this property is different for sockets on different sides of the connector.
So if the inversion flag is set to an outgoing base socket or a context socket, then the value passed through that socket will be inverted: a positive number will become negative, and the logical value will change to the opposite.
Setting the inversion flag for the incoming ( Get -) socket of the connector will change the operational behavior of the attribute's functionality. So the value obtained through the inverse socket, the multiplicative number functional will be considered as a divisor, and not as a factor. Similarly, a value received via an inverse socket will be considered additive by the additive functional as a deductible.
Relationship implementation
The most remarkable thing is that the connector technology is also fully used for the internal needs of the data model itself. And in particular - for the implementation of the mutual exchange of identifiers of derived objects of classes, within the framework of the declaration of the relationship between these classes and in accordance with the requirements of the reference symmetry. The reference attributes that make up the class relationship are obviously in a direct causal relationship, which in the data model is expressed as a connector declaration.
In addition to the connector, the so-called service attributes are used to implement the relationship.. These attributes, which perform certain utilitarian functions, are declared directly in the tuple of the meta-class, and therefore are present in the tuple of each user class.
The source of the value for the reference connector is the service attribute Own . This attribute is typed by its own class descriptor. When a class creates a derived object, it stores the IDO descriptor of that object as the value of the Own attribute . Another service attribute - Del , the default is used as a lock
-context for all, without exception, outgoing external connectors connecting the attributes of different classes. This declaration provides adequate behavior for the object being deleted, namely, the removal ( Unset ) of attribute-argument values from the values of attribute-recipients localized in other classes.
Well, the actual reference attribute itself acts as a ref- context of the active reference connector, providing it with the IDO handle of the target object.
The value of the list of backlinks is formed by the list functionality of the key-value pairs, where the value is the IDO of the object that owns the direct link, and as the key source ( key-context) by default, the base class attribute is used . Thus, the formation of a list of backlinks is essentially no different from the formation of a list of courses from the example above, in which the lock context of Del , and the ref context of [B] are also present, but were not shown in the diagram.
It is worth emphasizing once again that this whole structure, which includes service attributes and a reference connector, is created automatically by the relationship designer.
Connector functionality
Although the socket has an Unset / Reset method connector , the connector does not have its own functionality. Logically linking attributes, the connector is merely a declaration of the presence and nature of the causal dependence of the derived values. The implementation of this dependency itself is carried out exclusively by attribute methods. Therefore, the connector functionality should be understood as a complex declarative property of the dependency described by it.
Being a purely virtual entity, the connector is made up of meta-socket instances.that are logically related by mutual addressing. Accordingly, the nature of the declared attribute dependency is determined both by the combination of the sockets forming the connector and by setting the flags of the individual instance. A separate socket can be connected to four other sockets, each of which is assigned a strictly unambiguous functional aspect: basic (opposed) ( base -), blocking ( lock -), referential ( ref -) and additional ( key -). Accordingly, the address part of the properties of a meta-socket includes three routes in terms of IDA + IDE + IDS (the meaning of the IDE descriptor will be clear later), of which a pointer to base-socket supplemented by an IDC descriptor . Property Meta socket defining its transfer function includes five flags: S et , G et , R eset , U nset , I nverse .
Not previously mentioned, but the meta-socket declaration also includes an IDF functional descriptor . The attribute allows you to generate your value in the only way, so the incoming socket ( Get-) This property is not used. But the outgoing socket, as well as the context sockets of the complex connector, can use not only the stored value of the attribute, but also the transformed value obtained through the functional.
Sampling value
In all the examples considered earlier, by default it was assumed that class attributes operate on persistent values that are stored in a database in tuples of class objects. The fact of long-term storage of derived values allows characterizing such attributes as static . For static attributes, data sampling, implemented by the execution of the Get method , is reduced to simple retrieval and return of the stored value, regardless of all other conditions, including the presence of incoming connectors for the attribute.
. , (, « »). Get Get . , , , . : - Get Unset/Reset , .
An exception may unexpectedly become a rule, under certain conditions. It is not necessary to use a stored value if it can be dynamically generated, based on incoming connectors for attribute arguments. To give the attribute of such behavior, it is enough to set the corresponding flag in its properties.
When implementing a sample, the dynamic attribute ignores the stored value, even if it exists in the data object, and uses only the functionals assigned to it and cause-and-effect relations expressed by connectors to form the value. During polling, Get Get calls will be made only for those sockets from the tuple that have the Get [ G ] flag set .
Note that even with incoming connectors, not all attributes can be translated into a dynamic form. Baseline entity characteristics, reference values, and all lists, can only exist statically. And do not forget that directly or indirectly, but the value of a dynamic attribute is formed from stored values.
Since a dynamic attribute does not form a stored value, all its incoming connectors are forcibly transferred to an inactive form by resetting the Set | Unset | Resetin all sockets. This allows you to automatically exclude an unnecessary call to the active method in the address of a dynamic attribute. In all other respects, the behavior of a dynamic attribute corresponds to all the rules and examples considered earlier and, which is of fundamental importance, ensures unconditional logical consistency of data.
Performance balancing
The use of dynamic attributes naturally reduces the amount of stored data, but this is not the meaning of their use. If discard operations are removed from consideration, then in a data model formed only by static attributes, the execution time of a value is orders of magnitude shorter than the atomic transaction execution time, the duration of which also depends on the volume of subsequent dependencies. This imbalance is partially compensated by the quantitative ratio of samples and transactions — the samples are usually an order of magnitude larger.
. , , , . , .
The derived attribute value can be either a single ( atomic ) value or a set of similar values in a tuple format, considered as a trivial array ( enumeration ). It should be noted that the idea of an array of values as a value of the characteristic of a conceptual entity is present initially, and therefore its use is only a more accurate correspondence of the data model to the target subject domain.
The array declaration in the attribute properties, as well as its implementation, also takes the form of a tuple whose elements contain custom names for the array elements. If the tuple of names is not initialized, then this means that the attribute operates on a single value, and is considered atomic . . , . , , : “1“ “2“.
, , – IDE . , , , : IDC+IDA+IDE+IDS . , IDE . IDE 0, , .
. . , . - IDE , “" , . , , .
The list is formed by key-value pairs, while the types of key values and the actual values are the same for all list items, which is not surprising if we recall the mechanism of their formation in the above examples of backlinks list and Currency . {Course}. Nominally, there are no direct restrictions on the use of value types, both as a key and as a value itself, are not imposed. So for the backlink attribute, the value is the IDO handle of the class object. From the point of view of logical representation, the list is linear, homogeneous, and ordered in order of increasing key value.
All lists are instances of another, not previously mentioned member of the meta-definition level - the meta-list .Meta-list owns a complete set of methods for managing the list, and provides: creating a list, inserting and deleting elements, selecting data and obtaining numerical characteristics of the list. Physically, the list is implemented as a B-tree, the root, nodes and leaves of which are instances of a meta-tuple, which in turn are stored in data objects.
At the data model level, a meta-list does not create derived instances. Instead, the class attributes are assigned various functionals from the family of list functionals , which actually carry out direct work with lists, using the methods of the meta-list. List functionals are defined separately for each pair of key and value types, which allows not only to take into account the specifics of the type, but also to expand the palette of ways to control the values in the list.
Typing of values
The value type system forms a natural hierarchy in which the ancestor type domain includes the value domains of all its descendants. In other words, an attribute typed by an ancestor can take any value of a type of heir, leading it to an internal form of representation of its type, if necessary.
– [ U ]. – , : , . , , Undefined Type -.
[ L ] , : – true , – false. The second case also includes such particulars as zero for a number, and the absence of other literals except a space for a string.
For type String [ S ], the value is a sequence of literals of arbitrary length. In this case, the encoding type (ASCII or UTF) is the same for the entire database, and is set when it is generated. But if necessary, you can create sub-domains (subtypes) for different encodings. On the procedure for storing the values of String is not affected.
The type Numeric [ N ] combines all real numerical values considered in the decimal system with a floating or fixed decimal point. From it the type Integer is selected [I ] –– the whole set of positive integers, from which the Date [ D ] type is selected - integers in the calendar system of calculation.
The Complex [ C ] type, also known as the User Defined Type [ UDT ], is an abstract prototype domain that combines a set of user-created complex value types — data classes. Domain of class values, includes domains of values of all classes generated by inheritance from this class. As a domain value formed by a class, both a data object itself and a pointer to it, the IDO descriptor, can be equally considered as a data object derived from a class. .
External [ Ex ] , , , . External , , . External Image , .
Numeric [ N ] Date [ D ], (/) . Numeric . Date – CYMDhms, , .
As already mentioned, the functionality is a predefined method, identified by an IDF handle. The original set of functionals includes the most primitive, but most frequently used methods of forming values, but this set can be easily extended by adding new functionals to it. For each type of value, there is a set of natural functionals:
- for Logical - additive (logical OR) and multiplicative (logical AND);
- for String - additive (concatenation);
- for Numeric - additive, multiplicative, minimum, maximum;
- for Integer - additive, multiplicative, minimum, maximum;
- for Date - additive (shift), minimum, maximum;
- for Complex - additive (assignment), Autoset;
All listed functionals allow obtaining values from a variety of sources (connectors). The role of the functional of assigning values from a single source by default is played by the additive functional. For all types, except Logical and External , there are list functionals . Separately, it is also worth briefly mentioning the interval functional , which ensures the formation of interval values, and by means of which both the internal dependencies of the values forming the interval and the operations on interval values are implemented. It would be logical to assume that the interval value is complex, and has an enumerated form.
List functionals
Each list functionality is a wrapper function that encapsulates a meta-list and uses meta-list methods, the internal implementation of which the functionality overrides for its own goals and objectives. The entire family of list functionals includes several groups.
The functionals that create and modify the list are identified with the actual list, more precisely, its functional type. In addition to the “ simple ” list, this group includes a “ unique ” list (the list does not allow duplicate key values), as well as its two logical modifications operating with numerical values: a “ totalization ” list (values with the same key are added together) and its subsequent modification - " integral " (values with the same key are summed with the addition of the value of the preceding element). These functionals are assigned directly to the attribute as its incoming functionality, thereby making the attribute a list attribute. Functionals of this group need at least one incoming active connector — the source of the key and value — to form the actual list.
Sample functionals that return a value from the list are always assigned to the outbound connector socket, localized in the list attribute tuple. Although this also simulates the "postscript" of such a functional to the attribute-recipient. Actually the key itself is a context (key source), can be declared for any of the basic sockets of this connector.
Functionals sampling values by key differ in the positioning condition: " equal " (precise positioning), " less " (positioning on a logically preceding element), " greater " (similarly, only the next one), " equal or less " and " equal to or more "(if not exactly then preceding or following). If there is no element that satisfies the condition, the functional will return the equivalent of the " empty " value. A subgroup of functionals similar to them instead of a value returns the position of the element — its ordinal number in the list. Another subgroup of functionals (" first / last / N " - " key / value ") returns the requested from the first, last, or specified (N) list items.
Software insert
Not all problems can be solved by combining primitive functionals. To implement complex algorithms, the Script container is provided in the attribute properties, in which you can place an arbitrary script (for example, in Python) as a private functional of a specific attribute instance. The practice of creating various applications has unexpectedly shown that this tool has to be used quite rarely. Note that in the script body of a static attribute, it is allowed to use active methods addressed to the class ( Create ) or class attribute ( Set or Update ). For a dynamic attribute script, only the Get method call is allowed.
Attribute functionality
A class attribute is an instance of a meta attribute . The attribute is characterized by a custom name ( Name ), unique within its own class, value type ( Type ), type metric ( Metric ), and the Dynamic flag. In addition, the attribute owns an IDF functional descriptor, a Script container, and two tuples: array elements ( Item list ) and sockets ( Socket list ). In a tuple of a native class, the attribute is identified by an IDA descriptor.
In the data model, the attribute performs the function of a value factory , and from this point of view it is the central actor of the object data management environment. To perform operations on values, the attribute uses the Set , Get, and Update methods, as well as a set of type-dependent functionals.
Attributes connected by connectors form a topology, somewhat resembling the topology of a neural network. Recall the starting point - the subject area is considered as a system of interacting values. Accordingly, the ideal hardware platform for such a network looks like a set of independent primitive processors interconnected by serial channels. In such a hardware environment, you can simulate a variety of processes.
Service attributes
Service attributes are permanently present in a tuple of any class where they occupy strictly fixed positions. These attributes are used by the data model to solve its own problems. So the Del and Own attributes mentioned earlier provide the implementation of a symmetric connection of class objects. Another, not mentioned earlier, service attribute - Type , in the class object stores the structural type of the object - the IDC descriptor of the factory class.
Class functionality
A data class is an instance of a metaclass regardless of how this instance was obtained. A class is characterized by a custom name ( Name ), unique in the full set of classes, a visual image ( Image ), and an attribute tuple ( Attribute list ). In the full set of classes, a single class is identified by an IDC descriptor. If the class was created by inheriting from another ancestor class, then in the Parent property the class stores the IDC of the ancestor class.
In the object management computing environment, the class performs the function of a factory of objects using the Create meta method of the class. A class object is created as an instance of a class attribute tuple.
Deleting an object is not a class prerogative. The object is logically deleted by initializing the value of the service attribute Del , which, in order to ensure logical integrity, is automatically present in all external connectors as a lock context. The initialization of Del entails the de-initialization of all the effective connections of the object, putting the object into an isolated state. Subsequently, a logically isolated object will be physically deleted by the garbage collector.
Class inheritance
A data class can be created not only as an instance of a meta-class, but also by inheriting from another class. The object of inheritance is the full tuple of attributes of the ancestor class, which is permanently present in the tuple of attributes of the heir class. This allows an ancestor class to include into its domain all objects, generated by both direct and mediated by its heirs, without exception, regardless of the depth of inheritance. An inherited tuple is the natural interface to all objects in the ancestor class domain.
The mechanism for implementing attribute tuple inheritance is extremely simple: an instance (!) Of ancestor attribute tuple is created in the heir class. This instance, by definition, contains no values, since there is no need to duplicate the attribute declarations - the required declarations can be obtained by referring to the ancestor class tuple. A descendant class will generate a complete declaration of an attribute only if it makes its own private changes to it, or if it creates a new attribute of its own. When a new attribute is created in an ancestor class, then, in advance, the full set of its heirs determines the maximum size of the attribute tuple, after which the created attribute is allocated an element in the ancestor's tuple beyond this size. Thus, the new attribute of the ancestor automatically becomes available to all his heirs. The non-initialized elements generated in the tuples can be neglected, since they practically do not take up space.
Heir polymorphism is implemented by overriding the rules for obtaining values for inherited attributes, while preserving their type. At the same time, it is forbidden to change inherited connectors, which, if necessary, should be deactivated and created new ones.
Looking ahead, it is worth mentioning that a user data class, being a complex entity, has many forms of its interface (including visual) presentation. The descendant class fully inherits the ancestor's presentation forms, with the possibility of overriding them. The natural combination of polymorphism with " polyformism " is a powerful tool for developing an application.
Base attribute and class prototypes
In the total mass of class attributes, one can always single out one whose value is used for user identification of a specific object of this class, such as the Name attribute in the Counterparty class. Such an attribute performs the function of a basic class attribute .
It is logical to assume that it is the base attribute that should automatically be used as a key context for any connector to the list functionality, including lists of backlinks. For this, the base attribute must have a fixed position in the tuple of any class, namely, it must be placed immediately after the service attributes.
Of all existing value types, only two types, String and Date , can be meaningfully assigned to the base attribute when it is created. These two types of typing predetermine the existence of two prototype classes: Named class and Event class , with corresponding basic attributes.
It is convenient to use prototype classes as templates when creating custom user classes, which not only seems logical, but also gives a small gain: the class created immediately includes the basic attribute of the desired type with the necessary name.
Model Constructor
Already repeatedly checked - you can’t create a regular program with the mouse. In the case of using the application / data model, everything is strictly the opposite: textual notation looks like a dull, little informative listing of declarations. But in the visual environment, the same declarations look natural and very clear: there is a common space displayed in whole or in part connected by class relations, and the transition to the visual space of a class opens up many of its attributes with their connections. However, the principles of interface presentation and the mechanisms for its implementation are also a topic for a separate article.
An executive data model is created and modified through its presentation form — an application model. The editor of this model is a visual designer, operating with images of model entities. The transition from the user interface of the application to the visual environment of the designer and returning back to the application execution environment while preserving the current state of the interface is performed simultaneously with a hot key. In this case, all changes made by the designer take effect immediately. If something is done wrong, it will become immediately obvious: in the form of an erroneous result or lack of response to an interface event, without interrupting the application.
The constructor creates new model components as declarative instances of meta-entities, while completely hiding the real descriptors of derived instances. The initial set of basic meta-entities is small, which makes it easy to control the logical consistency of newly created declarations that already exist in the model by simply excluding the conflicting editor tool or structural component from access.
A valid data model is a simple type declaration for an entity-property, which means it can be exported in text format: XML, JSON, or in the form of a sequence of transactions to create its components. Internal descriptors are not exported to the text view; instead, custom class and attribute names are used.
Application area
A data model describes an information system with states . Accordingly, it cannot be used to implement a driver, for example.
Also with its help it is impossible to implement a separate algorithm or subroutine - the data model describes the subject area only as a whole.
For performance reasons (due to the lack of appropriate hardware), the data model cannot be used to directly simulate physical processes in real time. Although there is such potential.
Seeming to be senseless attempts to create a universal model of "everything in the world." An application program always reflects the subject area only from a strictly defined point of view and within certain limits. And for another point of view, the same subject area may look different.
Otherwise, the computing environment based on the data model is designed to solve the same problems that are solved on the basis of all other databases. But it has some useful properties.
Agree, the visual model of the application gives a more visual perception of business logic.
Reference symmetry allows you to use all the power of natural navigation methods, both in data and in meta-data.
The executive data model that forms the application is only a declaration stored in the database, which is completely independent of the processor architecture or the operating system.
The speed of development, algorithmic reliability, strict referential integrity, permanent consistency - all this is a direct consequence of the integration of business logic directly into the logical structure of the database. And while fundamentally changing the approach to the implementation of the interface of the application, which is subject to a separate detailed consideration.
Summary
Nature shows us its infinite variety, obtained by the infinite combination of elements in a very tiny base set (nod towards DNA). This is her favorite trick.
Only four abstract entities form a basis, which is enough to informationally describe any subject area. Declarative instances of all three meta-entities are sufficient to formalize this description as a data model. And, in the computational environment of the object representation formed by the six executive methods of meta-entities, the model will behave like a program, giving the desired result.
All of the above is just a further development of the EFKodd relational model, as well as K.Date's ideas on combining relational and object technologies. The essence of the relational model remains the same: tables, columns, tables connection. It just added a fourth element, so natural, but for some reason not mentioned by Codd, the connection of columns in the tables.
Source: https://habr.com/ru/post/347856/
All Articles