Special projects at Sberbank Technologies: how banks are preparing Hadoop, Spark, Kafka and other Big Data
We all love to laugh at the dense legacy of Java, which supposedly lives in banks. After reading this article, you will have an understanding of another facet of this story. It turns out that there are entire large departments dealing with breakthrough technologies and areas, including Big Data and Machine Learning, in Sberbank Technologies. Moreover, we may soon find ourselves in a world where Machine Learning is built into almost every coffee maker. For good or for ill, but the Internet of Things, following us with a thousand eyes from each ATM, is a much more relevant reading of this old joke.
As you, probably, noticed, I write on Habré about virtual computers, interiors of OpenJDK, JVM and other system development. Why is this article about banking software? Because it is more relevant than ever. Just imagine, you are so white, twice Data Scientist and four times the important guru of JIT compilation. What's next? Who needs all this right here and now? Often I hear arguments on the topic: “Now you are picking on your favorite Java, and tomorrow nobody will take you to work.” This is a very funny and dangerous delusion. Thanks to such comrades, which will be discussed in this article, we will always work.
 Of course, no one should believe in my word, therefore, especially for Habr, I fell on a plane to Moscow to talk with the head of the special projects development department at Sberbank Technologies. Vadim Surpin spent a little more than an hour on me, and in this interview there will be only the most important thoughts from our conversation. In addition, we managed to persuade Vadim to apply for participation in our JBreak conference . Moreover, Vadim is the first person who seemed worthy of an invite to Habr: vadsu (the invitee was honestly earned by the article about hacking ChromeDriver ).
Of course, no one should believe in my word, therefore, especially for Habr, I fell on a plane to Moscow to talk with the head of the special projects development department at Sberbank Technologies. Vadim Surpin spent a little more than an hour on me, and in this interview there will be only the most important thoughts from our conversation. In addition, we managed to persuade Vadim to apply for participation in our JBreak conference . Moreover, Vadim is the first person who seemed worthy of an invite to Habr: vadsu (the invitee was honestly earned by the article about hacking ChromeDriver ).
- Can you tell our readers on Habré a few words about your team, what are you doing?
')
- We have a center of competence for big data. Accordingly, we are engaged in Hadoop, everything that is near him, and everything that allows us to process big data. In addition to Hadoop, these are key-value repositories, distributed text indexes, auxiliary Zookeeper coordinators, MPP solutions from the Hadoop orbit, like Impala (if this can be called a full-fledged MPP - but, nevertheless, it claims it). This, of course, Spark, Kafka and other popular things. It is technologically.
Conceptually, Hadoop for a bank is a platform that allows processing large volumes of internal and external banking data. At conferences they often talk about PRBR , and this is a transactional system. Hadoop is an analytical system. The FPRB processes more operational information, and Hadoop accumulates the entire historical volume of information. This and data on transactions, and some customer data, accounts, transactions. This applies to both natural persons and legal entities. There are also a number of external data, for example, Spark Interfax for corporate use, some sources of credit history and so on. All this data is aggregated in Hadoop to build customer profiles, make decisions for retail about marketing campaigns, calculate the probability of customer churn. To intelligently build different graphs, for example, schedules of units. Recently, we built a model that allows us to identify failures in the Sberbank mobile application based on reviews on Google Play - that is, we began to make free text analysis. Experimented with image analysis - this is necessary in order to better determine the bank's customer from video or camera photos. The bank has many such directions.
In addition, there is infrastructural hardcore when we need to integrate with other banking systems. When you need a WAY4, SmartVista or CEN to download a huge amount of data in realtime mode. That is, it is a kind of combination of Big Data and high load. This is where interesting purely technological questions arise. If usually all conferences say that Big Data and machine learning are one and the same, then here it is not. Along the way of building an enterprise platform, we realized that there are many purely technical tasks that are not solved out of the box in the world of Big Data. In particular, this is a simple task - to get a stream of real data on Hadoop. But on streams the size of only a few terabytes per hour, it turns from a simple one into a separate large task. Providing realtime data access on Hadoop is another area that is not very covered in ready-made solutions.
- Wait. Hadoop was not originally designed for realtime. Isn't that batch processing?
- Big data has evolved very interesting. At the beginning it was just the distribution of data across a large number of servers. And analytical systems - building profiles, etc. It all started with the search, indexing sites, and this is really offline. Now, and this is evident in many publications, it is increasingly moving towards streaming information processing. It is closer to realtime. When talking about Big Data, the topic of log processing always loomed — that is, text information. There are distributed indexes like Elastic, Solr and so on. This is also Big Data, but it is real-time. That is, I would not say that Big Data is necessarily batch.
- Yeah. And how do you deal with realtime in Hadoop?
- We divide realtime into stream processing and into realtime access. What is meant by realtime access? We can process the data, then provide point access to it. Basically, these are the key-value of the repository and the above text indexes of the Elastic type. They serve as final windows. It is clear that access to such storefronts can be carried out only on a pre-selected key or a set of keys in the case of full-text search. As you know, in an enterprise environment, many customers just want SQL data access.
- / * sighs heavily / *
- Yes. Moreover, these data may even lie in the NoSQL databases. And here you have to think how to do it. Of course, there is no complete solution to this, but due to various caching in memory, by organizing the same indices, we are trying to build something more or less generalized.
- Do you get any frameworks as a result or are these ad-hoc solutions just at the place of the problem?
- The fact of the matter is that we are trying to do frameworks. When we look at the market, what is generally done in the world - in general, at large conferences like Strata , it is clear that people make decisions “in place”. In the bank, in the presence of DKA ...
- Department of Corporate Architecture?
- Yes. In the presence of DKA there is always a desire to make for centuries, carved in stone. Therefore, we have to find ways to make a more or less common solution. It is not always possible to cross two different worlds of SQL and NoSQL, but we try to make some more or less common solutions.
- How much will it live? Year, two, three, ten? What are your plans?
- The question is interesting. It depends on what we are talking about. Anyway, Big Data technologies evolve very quickly. As it seems to me, there are things that concern data storage, batch processing, which are more or less settled - they have a slightly longer lifespan. Everything related to newer directions, the same stream processing, realtime - there will be some kind of turbulence here. These solutions are more subject to rework in the coming years.
- And which front is moving forward most of all, is being remade, something else?
“Now we are working for the platform, for the“ Data Cloud ”- this is the name of Hadoop in the bank. I must say that the name "cloud" at first seemed strange to us. Because the “cloud” is a well-known cloud platform: OpenStack, Amazon, and so on. Therefore, it seemed that Hadoop is not a “cloud”. Moreover, Hadoop is made on our hardware. The name “AS Cloud Data” should be understood as: “data as a service”. Not the infrastructure itself is cloudy, but rather the data lives in the cloud and can be provided to the customer as a service. Now the most demanded part of the business customer is the availability of all banking data on one platform, so that it is possible to conduct experiments, have a data laboratory and be able to integrate data. That is, to compare data about one client, about one event from different sources. This is for us now the most difficult front of work. Capturing data and integrating it together is a classic repository task, but it also arises on Hadoop.
Next front. After the data appears in sufficient volume, it is necessary to extract some business result from them. These are various pilots and data experiments. Based on successful experiments, a number of automated systems are being developed, such as Geomarketing, which we wanted to talk about.
- And about the matching of data - is it a Labyrinth?
- No, the Labyrinth is a graph platform. It absorbs the graph representation of pre-processed data. That is, matching is only part of the Labyrinth. Part of preparing data for styling in the graph. I don’t even know how to say ... This is not the whole Labyrinth, but this is a very important part of it. The graph is useful in order to reveal connections between various objects, subjects, phenomena.
- Come in order. “Labyrinth” is the name of the project, right?
- In general, the project began under the code name U1.
- U1? Sounds like the name of the aircraft.
- Initially, the customer of this project was a division of the URPA - Department for Work with Problem Assets, that is - the search for people who do not want to pay on loans. Hence the letter "U" and "1" - the first project for URPA. Then we realized that this is applicable not only for this customer. After some time, the name “Labyrinth” was born among our customers. Why precisely "Labyrinth"? It is already difficult to say now, but probably because the graph of user and organization connections allowed to walk, navigate, discover new relationships in the graphical user interface, and it was like finding a path in a maze.
- And it sounds cool.
- Yes. There were also other names for this system, but it was the “Labyrinth” that caught on.
- Tell me in more detail what business scenarios does she decide?
- Initially, the business scenario was the search for mass executives. There are interesting financial schemes, when several companies look independent from each other, and for example, they take loans, and then simultaneously disappear simultaneously. Well, either at the expense of some kind of interaction with each other, this money scrolls, leads away somewhere and disappears at once. At the same time, the connection between these companies is not visible on the surface, but with the involvement of external additional data, it can be detected and highlighted the risk that the company is a conglomerate of suspicious entities.
- Hidden holding? I remember your slides from Innopolis.
- Yes, but the “hidden holding” is a different scenario. If the search for such general executives is rather to discover an interesting kind of fraud, fraud, then “hidden holdings” is another scenario. As is known, Sberbank has quite a lot of clients - both individuals and legal entities. On the basis of transactions you can find some production chains. For example, when enterprises with each other regularly pay for services, and, in fact, form a de facto holding, although they have not been drawn up. And if we find such production chains, then this group of companies can offer special corporate products that are convenient for holding companies. This allows them to make payments among themselves more quickly, more conveniently, with fewer delays, etc., than if, from the point of view of the system, they were completely independent companies. This is a positive use. It allows companies to more conveniently use the services of Sberbank.
- How does this happen from the point of view of the company? One morning an officer of the Security Council calls you and says: “You know, we have found that you are working in the same chain!” It sounds shocking.
- That's how it happens, unfortunately, I can not say. How this business in fact applies, conversation scripts - unfortunately, I don’t know. I can only assume.
- That is, you simply provide information to the business.
- Yes, we provide information, and how to sell a product based on this information is the task of business units. It can be assumed that if client managers have a well-established relationship with people, then, knowing what to ask a person, you can always bring the conversation to the desired topic.
- From the point of view of the user of this system, what is the result of a response when such a chain is detected? Is a text file just generated with a listing of the elements of the chain?
- Not. This is a graphic image. Typically, a certain company is depicted in and around it - a cloud of interconnected customers. If we consider a similar task for large corporate clients, then it is immediately clear where to come from, from which companies. We take the largest customers, looking for their counterparties, with whom they work. Knowing the type of activity of a large customer, one can easily think of the direction of each production chain. Who does what to him, to whom they provide what services. Graphically, it looks like a client, and around it are such diverging rays, and these are counterparties. Accordingly, usually go on the filter, starting with large customers. And from them all the chains unfold further.
- Is this exactly snapshot or can you track something in time? Growth of the company or, on the contrary, its collapse?
- This is a slightly different task. In order to find hidden holdings, at the first stage historical information is not so important. What is important is just up to date information. Tracking the status of the customer and the customer according to historical information is a slightly different project. He is now in development, not in commercial operation. This is the project "News Monitoring". When we are trying to process news sources as text and to detect important events relating to our customers. For example, if in the news there is a large amount of information about court cases with some organization, it is an occasion for the relevant client manager to ask, for example, in more detail about their financial condition.
- So, you have a large number of prototypes and experiments?
- Yes. Indeed, now the Big Data platform is being developed in such a way that many experiments are being done on it. A classic enterprise, banking software, develops like this: we buy a box, it performs functions, and all this is simply given to the customer. Big Data works a little differently. Here we are trying to find in the laboratory those functions, on the basis of which then we can make a box for internal use. Box production itself is a longer process, but often, based on the results of experiments, a business can get benefits right now.
- Who is doing this? Is this state made up of researchers, developers? Or, on the contrary, two thirds are analysts, and with them two programmers? What does this look like?
- As for the experiments, the majority of the people here are analysts and data scientists, and a little less are programmers. That is, developers in the process of experiments are attracted when, for example, an extremely large amount of data is to be processed, with which the analyst or the data scientist cannot cope on his own. But research and relationships are analysts and data scientists. And this is not necessarily the staff of our unit. Often these are employees of business units and so on.
- What tools do data scientists use during their work?
“They tend to prefer Python, Jupyter Notebook, numerous python-language libraries that all data scientists use around the world. As for Big Data, this is PySpark (Python API for Apache Spark), Hive (in order to prepare the data), sometimes these are very custom interesting solutions. For example, once inside Spark we built xgboost and ran it distributed. Out of the box, the Spark machine learning libraries gave good results, but xgboost worked better on small data. I had to take the best of both worlds.
- So you can use any tools? You do not have a certain set of bodies?
- There are two environments: a laboratory (in which new tula are easier to make) and an industrial circuit (in which the introduction of new ones requires a justification process). It is necessary to show with the architect why the zoo needs a new animal - in the laboratory it is simpler, in the field it is somewhat more difficult. But of course, there is no closed circle of technologies. We try to look at the situation.
- And in terms of architecture, who defines it? For example, the architecture of Big Data solutions?
- There is a traditional organizational structure here, when there are corporate architects who paint architecture that seems to be further implemented. In practice, of course, given that something is constantly changing in Big Data, trends are constantly changing, something is taking a back seat, this is not always the case. If you really dig in, map-reduce at some point almost completely left the radar as a technology used directly by programmers. In fact, it turns out that corporate architects work closely with architects who are at our center of competence and with team leaders. By and large, many decisions are made at the level of the team leader. Initially initiated by team leaders, then they are fully discussed with interested people.
- What is the Competence Center?
- This is an organizational structure that focuses on certain technologies. For example, we have big data. There is everything in GPRB around Grid Gain. There are CCs involved in processing, CRM, and so on. — BI, SQL-. — : , .
— , , - Agile-?
- Yes. , , . . , , , , . «»… , , IT, . , , .
— . ?
— , ?
— , ( ). - ? -, .
— . , , , , . , — , , . , , : , , , , , , .
. — , . - , -, . — , , . , , , , , - . , , . , , , , . . , - …
— , .
— , , - . , . - ( — ) , -. . , (, , ), , , , - .
— - ? , , -?
— , — . - , . , , , , - . , , . . : , , -. — , , — .
— ?
— . — , - , . , - , .
— ?
— . . - , , , — , , . , . — -, . , , .
— — . , ?
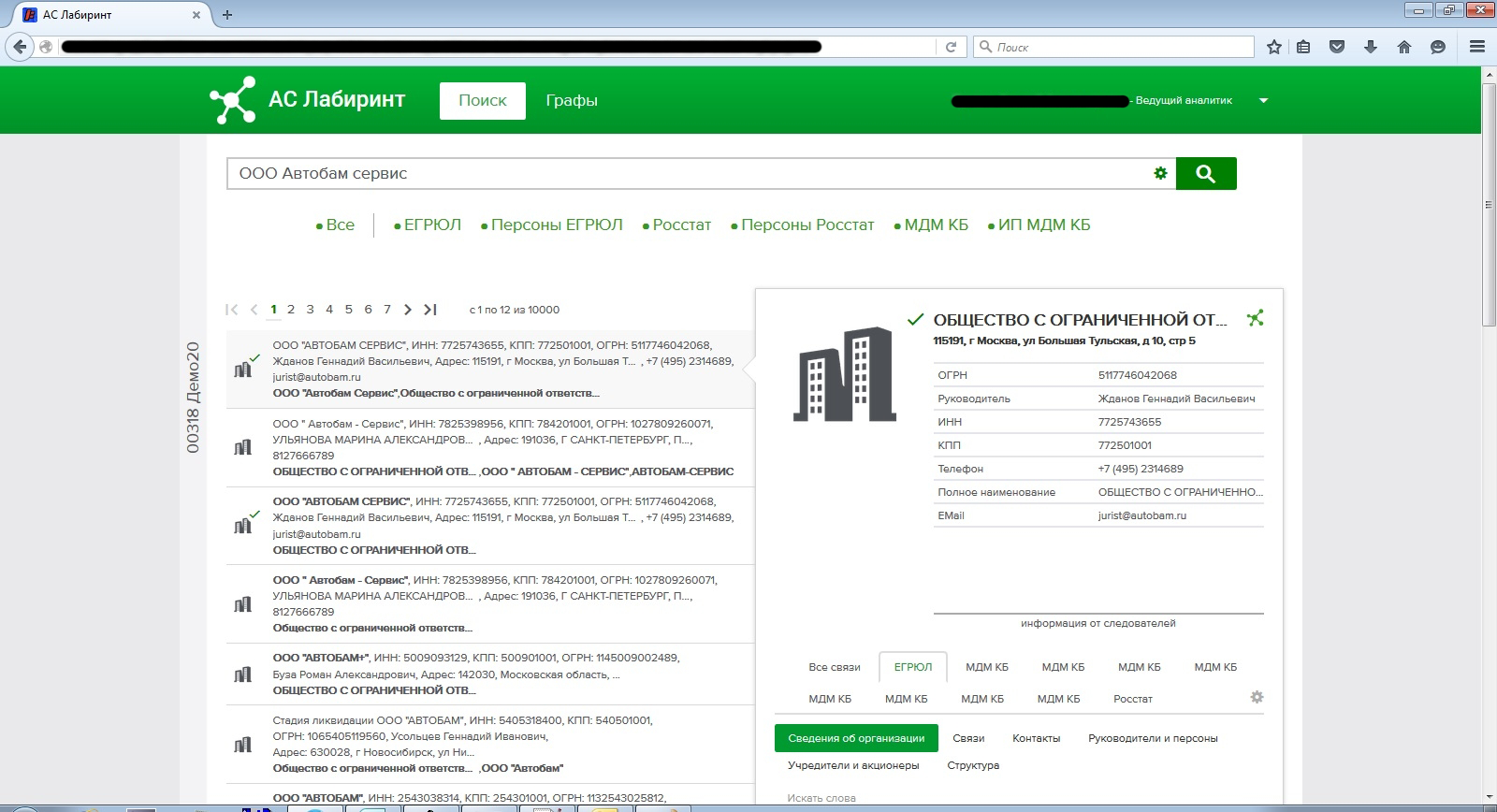
— — , . , Big Data- , . , . , open source, . , . , ? . , , , - , , — . . - … . , . , — . . , . , , . (, , , ) .
— . . - ?
— , , . , - - . .
— ?
— , TigerGraph . , , , . , . . , , — , - .
— , , .
- Yes. , , , — , , , . - . . , — GraphX , Giraph , . , Hadoop, , . , , , , . .
— , ?
— . , — . . . « »? , : , — . , . , , :-) — , — .
— ? ?
— . ID, , . .
— . , , , ?
— , , . , . . , , , — .
— , ?
— . , Elastic Solr ( Elastic, — ), key-value (assandra HBase, ) , .
— - Java API , ?
— API, . . , , . , - -, . «». , — . , . , . , 10-20-50-100 , , . UI — .
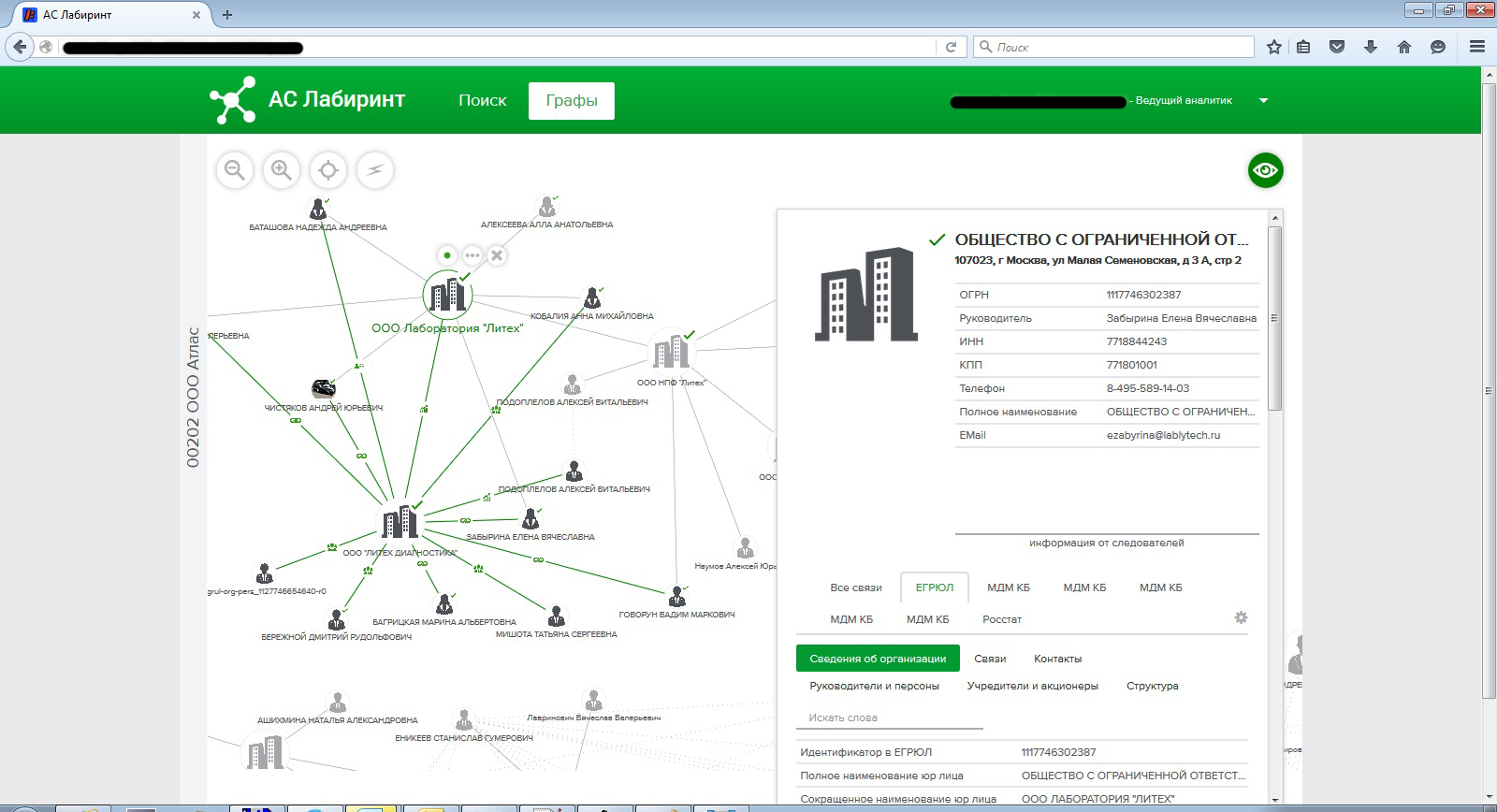
— UI JavaScript ?
— JavaScript, .
— ?
— D3 . , . — , , . , , , , . . D3 — , - , . , . , , , , , .
— ? Java- -, ?
— , . , , , , - , . , , — .
— , , — .
— , , . — . - , . , , .
— . « 2.0»?
— — , , — , . — , , . . , ( ) , , . — - , , . , , - , , . , , , — , , , -? , , , , . . — .
— . ?
— ? , , - - , . — . (, , ) , , , .
, , , . , - . , . , , , . , , …
— — , .
- Yes. , , , . , — . , , — . , — , , , . — .
— -?
— . , , , . , , , . , , . .
— , , — ?
— — , .
— , .
— . , — , . , — . , , . , , , . - , . , . .
— , , - ?
— , ? , . , . , . , .
— .
— — -. : , , , .
— , ?
— , Big Data, - . . . , - , , . -, . Hadoop. — , .
— ?
— , . - , — . , — — , , . , . , - .
— . , , — . . — , - , . -, - . .
— ?
— - . , , . . , — . .
— , , ?
— , — Hadoop, — Spark . , — Leaflet , ( ). , , , .
— , , ?
— , . , - , -, . - .
— — - ?
— , . — , , . - , , , . , . , , -.
, … - — . - , , , , , , - . .
— - , — ? …
— , . , . : , , — . , . -. , . , . . -.
— , , . , ?
— , , , , . ? open source. , enterprise, , , , open source- — IT.
— , ?
— , . IT, - . . , — , , , IT- . , IT . , .
What problems? , Big Data — , , , . , ad-hoc. , - , — . , , . . , . , — , .
Hadoop , , . SQL- Hadoop, , , . SELECT , - , , , . — . , , — realtime- Hadoop. , , , . , IT-, — Hadoop. — Big Data . , . , - .
— , — . ?
— , , . — , . . . , . , , , , . — . .
— - , - ?
— . realtime- Hadoop — ? . Hadoop — , batch, , , . , , .
, . ( - ) , , , . .
, — Hadoop. — - , , HDFS, — , ! ? , , - . . source control devops stack.
— , , ( - )?
— , , Java-, . . , , , — , . , . , , SQL, . — data scientist. , ( ) . , . — . , — , - . , .
— -.
— . , -, .
— -?
— , , Hadoop, Spark, Hive, , — HBase, Cassandra, Solr, Elastic , Hadoop. , Java — . . — ( - Hadoop ).
— . , , — . - SmartData. — JBreak JPoint . , !
As you, probably, noticed, I write on Habré about virtual computers, interiors of OpenJDK, JVM and other system development. Why is this article about banking software? Because it is more relevant than ever. Just imagine, you are so white, twice Data Scientist and four times the important guru of JIT compilation. What's next? Who needs all this right here and now? Often I hear arguments on the topic: “Now you are picking on your favorite Java, and tomorrow nobody will take you to work.” This is a very funny and dangerous delusion. Thanks to such comrades, which will be discussed in this article, we will always work.
Of course, no one should believe in my word, therefore, especially for Habr, I fell on a plane to Moscow to talk with the head of the special projects development department at Sberbank Technologies. Vadim Surpin spent a little more than an hour on me, and in this interview there will be only the most important thoughts from our conversation. In addition, we managed to persuade Vadim to apply for participation in our JBreak conference . Moreover, Vadim is the first person who seemed worthy of an invite to Habr: vadsu (the invitee was honestly earned by the article about hacking ChromeDriver ).- Can you tell our readers on Habré a few words about your team, what are you doing?
')
- We have a center of competence for big data. Accordingly, we are engaged in Hadoop, everything that is near him, and everything that allows us to process big data. In addition to Hadoop, these are key-value repositories, distributed text indexes, auxiliary Zookeeper coordinators, MPP solutions from the Hadoop orbit, like Impala (if this can be called a full-fledged MPP - but, nevertheless, it claims it). This, of course, Spark, Kafka and other popular things. It is technologically.
Conceptually, Hadoop for a bank is a platform that allows processing large volumes of internal and external banking data. At conferences they often talk about PRBR , and this is a transactional system. Hadoop is an analytical system. The FPRB processes more operational information, and Hadoop accumulates the entire historical volume of information. This and data on transactions, and some customer data, accounts, transactions. This applies to both natural persons and legal entities. There are also a number of external data, for example, Spark Interfax for corporate use, some sources of credit history and so on. All this data is aggregated in Hadoop to build customer profiles, make decisions for retail about marketing campaigns, calculate the probability of customer churn. To intelligently build different graphs, for example, schedules of units. Recently, we built a model that allows us to identify failures in the Sberbank mobile application based on reviews on Google Play - that is, we began to make free text analysis. Experimented with image analysis - this is necessary in order to better determine the bank's customer from video or camera photos. The bank has many such directions.
In addition, there is infrastructural hardcore when we need to integrate with other banking systems. When you need a WAY4, SmartVista or CEN to download a huge amount of data in realtime mode. That is, it is a kind of combination of Big Data and high load. This is where interesting purely technological questions arise. If usually all conferences say that Big Data and machine learning are one and the same, then here it is not. Along the way of building an enterprise platform, we realized that there are many purely technical tasks that are not solved out of the box in the world of Big Data. In particular, this is a simple task - to get a stream of real data on Hadoop. But on streams the size of only a few terabytes per hour, it turns from a simple one into a separate large task. Providing realtime data access on Hadoop is another area that is not very covered in ready-made solutions.
- Wait. Hadoop was not originally designed for realtime. Isn't that batch processing?
- Big data has evolved very interesting. At the beginning it was just the distribution of data across a large number of servers. And analytical systems - building profiles, etc. It all started with the search, indexing sites, and this is really offline. Now, and this is evident in many publications, it is increasingly moving towards streaming information processing. It is closer to realtime. When talking about Big Data, the topic of log processing always loomed — that is, text information. There are distributed indexes like Elastic, Solr and so on. This is also Big Data, but it is real-time. That is, I would not say that Big Data is necessarily batch.
- Yeah. And how do you deal with realtime in Hadoop?
- We divide realtime into stream processing and into realtime access. What is meant by realtime access? We can process the data, then provide point access to it. Basically, these are the key-value of the repository and the above text indexes of the Elastic type. They serve as final windows. It is clear that access to such storefronts can be carried out only on a pre-selected key or a set of keys in the case of full-text search. As you know, in an enterprise environment, many customers just want SQL data access.
- / * sighs heavily / *
- Yes. Moreover, these data may even lie in the NoSQL databases. And here you have to think how to do it. Of course, there is no complete solution to this, but due to various caching in memory, by organizing the same indices, we are trying to build something more or less generalized.
- Do you get any frameworks as a result or are these ad-hoc solutions just at the place of the problem?
- The fact of the matter is that we are trying to do frameworks. When we look at the market, what is generally done in the world - in general, at large conferences like Strata , it is clear that people make decisions “in place”. In the bank, in the presence of DKA ...
- Department of Corporate Architecture?
- Yes. In the presence of DKA there is always a desire to make for centuries, carved in stone. Therefore, we have to find ways to make a more or less common solution. It is not always possible to cross two different worlds of SQL and NoSQL, but we try to make some more or less common solutions.
- How much will it live? Year, two, three, ten? What are your plans?
- The question is interesting. It depends on what we are talking about. Anyway, Big Data technologies evolve very quickly. As it seems to me, there are things that concern data storage, batch processing, which are more or less settled - they have a slightly longer lifespan. Everything related to newer directions, the same stream processing, realtime - there will be some kind of turbulence here. These solutions are more subject to rework in the coming years.
- And which front is moving forward most of all, is being remade, something else?
“Now we are working for the platform, for the“ Data Cloud ”- this is the name of Hadoop in the bank. I must say that the name "cloud" at first seemed strange to us. Because the “cloud” is a well-known cloud platform: OpenStack, Amazon, and so on. Therefore, it seemed that Hadoop is not a “cloud”. Moreover, Hadoop is made on our hardware. The name “AS Cloud Data” should be understood as: “data as a service”. Not the infrastructure itself is cloudy, but rather the data lives in the cloud and can be provided to the customer as a service. Now the most demanded part of the business customer is the availability of all banking data on one platform, so that it is possible to conduct experiments, have a data laboratory and be able to integrate data. That is, to compare data about one client, about one event from different sources. This is for us now the most difficult front of work. Capturing data and integrating it together is a classic repository task, but it also arises on Hadoop.
Next front. After the data appears in sufficient volume, it is necessary to extract some business result from them. These are various pilots and data experiments. Based on successful experiments, a number of automated systems are being developed, such as Geomarketing, which we wanted to talk about.
- And about the matching of data - is it a Labyrinth?
- No, the Labyrinth is a graph platform. It absorbs the graph representation of pre-processed data. That is, matching is only part of the Labyrinth. Part of preparing data for styling in the graph. I don’t even know how to say ... This is not the whole Labyrinth, but this is a very important part of it. The graph is useful in order to reveal connections between various objects, subjects, phenomena.
- Come in order. “Labyrinth” is the name of the project, right?
- In general, the project began under the code name U1.
- U1? Sounds like the name of the aircraft.
- Initially, the customer of this project was a division of the URPA - Department for Work with Problem Assets, that is - the search for people who do not want to pay on loans. Hence the letter "U" and "1" - the first project for URPA. Then we realized that this is applicable not only for this customer. After some time, the name “Labyrinth” was born among our customers. Why precisely "Labyrinth"? It is already difficult to say now, but probably because the graph of user and organization connections allowed to walk, navigate, discover new relationships in the graphical user interface, and it was like finding a path in a maze.
- And it sounds cool.
- Yes. There were also other names for this system, but it was the “Labyrinth” that caught on.
- Tell me in more detail what business scenarios does she decide?
- Initially, the business scenario was the search for mass executives. There are interesting financial schemes, when several companies look independent from each other, and for example, they take loans, and then simultaneously disappear simultaneously. Well, either at the expense of some kind of interaction with each other, this money scrolls, leads away somewhere and disappears at once. At the same time, the connection between these companies is not visible on the surface, but with the involvement of external additional data, it can be detected and highlighted the risk that the company is a conglomerate of suspicious entities.
- Hidden holding? I remember your slides from Innopolis.
- Yes, but the “hidden holding” is a different scenario. If the search for such general executives is rather to discover an interesting kind of fraud, fraud, then “hidden holdings” is another scenario. As is known, Sberbank has quite a lot of clients - both individuals and legal entities. On the basis of transactions you can find some production chains. For example, when enterprises with each other regularly pay for services, and, in fact, form a de facto holding, although they have not been drawn up. And if we find such production chains, then this group of companies can offer special corporate products that are convenient for holding companies. This allows them to make payments among themselves more quickly, more conveniently, with fewer delays, etc., than if, from the point of view of the system, they were completely independent companies. This is a positive use. It allows companies to more conveniently use the services of Sberbank.
- How does this happen from the point of view of the company? One morning an officer of the Security Council calls you and says: “You know, we have found that you are working in the same chain!” It sounds shocking.
- That's how it happens, unfortunately, I can not say. How this business in fact applies, conversation scripts - unfortunately, I don’t know. I can only assume.
- That is, you simply provide information to the business.
- Yes, we provide information, and how to sell a product based on this information is the task of business units. It can be assumed that if client managers have a well-established relationship with people, then, knowing what to ask a person, you can always bring the conversation to the desired topic.
- From the point of view of the user of this system, what is the result of a response when such a chain is detected? Is a text file just generated with a listing of the elements of the chain?
- Not. This is a graphic image. Typically, a certain company is depicted in and around it - a cloud of interconnected customers. If we consider a similar task for large corporate clients, then it is immediately clear where to come from, from which companies. We take the largest customers, looking for their counterparties, with whom they work. Knowing the type of activity of a large customer, one can easily think of the direction of each production chain. Who does what to him, to whom they provide what services. Graphically, it looks like a client, and around it are such diverging rays, and these are counterparties. Accordingly, usually go on the filter, starting with large customers. And from them all the chains unfold further.
- Is this exactly snapshot or can you track something in time? Growth of the company or, on the contrary, its collapse?
- This is a slightly different task. In order to find hidden holdings, at the first stage historical information is not so important. What is important is just up to date information. Tracking the status of the customer and the customer according to historical information is a slightly different project. He is now in development, not in commercial operation. This is the project "News Monitoring". When we are trying to process news sources as text and to detect important events relating to our customers. For example, if in the news there is a large amount of information about court cases with some organization, it is an occasion for the relevant client manager to ask, for example, in more detail about their financial condition.
- So, you have a large number of prototypes and experiments?
- Yes. Indeed, now the Big Data platform is being developed in such a way that many experiments are being done on it. A classic enterprise, banking software, develops like this: we buy a box, it performs functions, and all this is simply given to the customer. Big Data works a little differently. Here we are trying to find in the laboratory those functions, on the basis of which then we can make a box for internal use. Box production itself is a longer process, but often, based on the results of experiments, a business can get benefits right now.
- Who is doing this? Is this state made up of researchers, developers? Or, on the contrary, two thirds are analysts, and with them two programmers? What does this look like?
- As for the experiments, the majority of the people here are analysts and data scientists, and a little less are programmers. That is, developers in the process of experiments are attracted when, for example, an extremely large amount of data is to be processed, with which the analyst or the data scientist cannot cope on his own. But research and relationships are analysts and data scientists. And this is not necessarily the staff of our unit. Often these are employees of business units and so on.
- What tools do data scientists use during their work?
“They tend to prefer Python, Jupyter Notebook, numerous python-language libraries that all data scientists use around the world. As for Big Data, this is PySpark (Python API for Apache Spark), Hive (in order to prepare the data), sometimes these are very custom interesting solutions. For example, once inside Spark we built xgboost and ran it distributed. Out of the box, the Spark machine learning libraries gave good results, but xgboost worked better on small data. I had to take the best of both worlds.
- So you can use any tools? You do not have a certain set of bodies?
- There are two environments: a laboratory (in which new tula are easier to make) and an industrial circuit (in which the introduction of new ones requires a justification process). It is necessary to show with the architect why the zoo needs a new animal - in the laboratory it is simpler, in the field it is somewhat more difficult. But of course, there is no closed circle of technologies. We try to look at the situation.
- And in terms of architecture, who defines it? For example, the architecture of Big Data solutions?
- There is a traditional organizational structure here, when there are corporate architects who paint architecture that seems to be further implemented. In practice, of course, given that something is constantly changing in Big Data, trends are constantly changing, something is taking a back seat, this is not always the case. If you really dig in, map-reduce at some point almost completely left the radar as a technology used directly by programmers. In fact, it turns out that corporate architects work closely with architects who are at our center of competence and with team leaders. By and large, many decisions are made at the level of the team leader. Initially initiated by team leaders, then they are fully discussed with interested people.
- What is the Competence Center?
- This is an organizational structure that focuses on certain technologies. For example, we have big data. There is everything in GPRB around Grid Gain. There are CCs involved in processing, CRM, and so on. — BI, SQL-. — : , .
— , , - Agile-?
- Yes. , , . . , , , , . «»… , , IT, . , , .
— . ?
— , ?
— , ( ). - ? -, .
— . , , , , . , — , , . , , : , , , , , , .
. — , . - , -, . — , , . , , , , , - . , , . , , , , . . , - …
— , .
— , , - . , . - ( — ) , -. . , (, , ), , , , - .
— - ? , , -?
— , — . - , . , , , , - . , , . . : , , -. — , , — .
— ?
— . — , - , . , - , .
— ?
— . . - , , , — , , . , . — -, . , , .
— — . , ?
— — , . , Big Data- , . , . , open source, . , . , ? . , , , - , , — . . - … . , . , — . . , . , , . (, , , ) .
— . . - ?
— , , . , - - . .
— ?
— , TigerGraph . , , , . , . . , , — , - .
— , , .
- Yes. , , , — , , , . - . . , — GraphX , Giraph , . , Hadoop, , . , , , , . .
— , ?
— . , — . . . « »? , : , — . , . , , :-) — , — .
— ? ?
— . ID, , . .
— . , , , ?
— , , . , . . , , , — .
— , ?
— . , Elastic Solr ( Elastic, — ), key-value (assandra HBase, ) , .
— - Java API , ?
— API, . . , , . , - -, . «». , — . , . , . , 10-20-50-100 , , . UI — .
— UI JavaScript ?
— JavaScript, .
— ?
— D3 . , . — , , . , , , , . . D3 — , - , . , . , , , , , .
— ? Java- -, ?
— , . , , , , - , . , , — .
— , , — .
— , , . — . - , . , , .
— . « 2.0»?
— — , , — , . — , , . . , ( ) , , . — - , , . , , - , , . , , , — , , , -? , , , , . . — .
— . ?
— ? , , - - , . — . (, , ) , , , .
, , , . , - . , . , , , . , , …
— — , .
- Yes. , , , . , — . , , — . , — , , , . — .
— -?
— . , , , . , , , . , , . .
— , , — ?
— — , .
— , .
— . , — , . , — . , , . , , , . - , . , . .
— , , - ?
— , ? , . , . , . , .
— .
— — -. : , , , .
— , ?
— , Big Data, - . . . , - , , . -, . Hadoop. — , .
— ?
— , . - , — . , — — , , . , . , - .
— . , , — . . — , - , . -, - . .
— ?
— - . , , . . , — . .
— , , ?
— , — Hadoop, — Spark . , — Leaflet , ( ). , , , .
— , , ?
— , . , - , -, . - .
— — - ?
— , . — , , . - , , , . , . , , -.
, … - — . - , , , , , , - . .
— - , — ? …
— , . , . : , , — . , . -. , . , . . -.
— , , . , ?
— , , , , . ? open source. , enterprise, , , , open source- — IT.
— , ?
— , . IT, - . . , — , , , IT- . , IT . , .
What problems? , Big Data — , , , . , ad-hoc. , - , — . , , . . , . , — , .
Hadoop , , . SQL- Hadoop, , , . SELECT , - , , , . — . , , — realtime- Hadoop. , , , . , IT-, — Hadoop. — Big Data . , . , - .
— , — . ?
— , , . — , . . . , . , , , , . — . .
— - , - ?
— . realtime- Hadoop — ? . Hadoop — , batch, , , . , , .
, . ( - ) , , , . .
, — Hadoop. — - , , HDFS, — , ! ? , , - . . source control devops stack.
— , , ( - )?
— , , Java-, . . , , , — , . , . , , SQL, . — data scientist. , ( ) . , . — . , — , - . , .
— -.
— . , -, .
— -?
— , , Hadoop, Spark, Hive, , — HBase, Cassandra, Solr, Elastic , Hadoop. , Java — . . — ( - Hadoop ).
— . , , — . - SmartData. — JBreak JPoint . , !
Source: https://habr.com/ru/post/347854/
All Articles