Anatomy of a thousand fonts

Translation of the article The anatomy of a thousand typefaces .
Even years after the release of the Avatar movie, something remains that even Ryan Gosling cannot handle - using the Papyrus font in the film's logo. In the parody of Saturday Night Live , the font designer opens the menu, enumerates the fonts and randomly selects Papyrus.
')
The main problem of choosing fonts is at the same time too many and too few options.
On the one hand, choosing only from system fonts can lead to a bad decision, because among standard fonts, nothing interesting is simply represented.
On the other hand, web font libraries with hundreds and thousands of titles are striking in abundance, which sometimes leads to paradoxical choice of fonts.
Bitter taste of the font selection menu
In the average menu, the fonts are sorted by name, but they are not interconnected with each other: behind the font created for bold headers there is a font designed for small screen interfaces, followed by an ornate handwritten font for wedding invitations. And you have to waste time on paging through the entire list from beginning to end, or simply select the first suitable font from the top of the list and round it out.
Obviously, such an interface solution was created not for systematic work, but for endless surprises. And although many people like surprises, but still want to influence the success of finding a good font.

Font selection menu from the “Papyrus” video. Limited choice, all sorts of styles, but not the best fonts from all possible.
A systematic approach to finding fonts
There are various ways to limit redundancy choices. Before analyzing font files, glyphs, and metadata tables, let's first talk about classification, selected lists, and anatomy.
1. Classification
There is a complex system for classifying fonts. The simplest division into categories: serif fonts (serif), grotesques (sans-serif), monospaced, handwritten (script) and fonts for displays (display). Usually these categories are used as filters on different font sites:

But even these simple filters still confront us with an overly rich selection of fonts. Here already there are more fractional gradations, for example, serif fonts are divided into transitional, humanistic and gothic.
Sometimes these subcategories are available as tags. But sometimes the authors of font sites generally ignore them. Perhaps too many categories? Perhaps users simply do not understand all these details? Or simply the authors do not have complete and consistent information for the detailed classification of fonts?
2. Selected listings
An alternative way to restore order is to rely on the knowledge of other people: you can use the lists of fonts, someone selected. Such lists are, for example, on Fontshop . You can find here collections sorted by decades, by degree of similarity or by scope.
Similar lists are also on Typekit , TypeWolf and FontsInUse . This is a great idea, and you can recommend everyone to start making their own lists of fonts with which you have already worked or seen. In the future, these developments will be very useful to you.
3. Anatomy
The most difficult thing in finding a good font is to focus on the design features and to understand which properties make the font good or special. Fortunately, there are enough books on font design, fonts and typography. These books can teach us how to create fonts, how to choose and use them.
For example, the book “ The Anatomy of Type ” by Stephen Coles. It contains information about 100 well-designed headsets. To describe the quality of fonts, Stephen uses terms such as the height of lowercase letters (x-height, x-height), width , weight , ball terminal , serif shape, and many others.

“The Anatomy of Type” is a Stephen Coles graphic guide for 100 headsets. A wonderful book to study the history and design features of popular headsets.
But only 100 fonts are described here, but what about the rest? What about installed on your computers? And used on the net? What are their x-heights, widths, weights and contrasts? How can you find out?
Inside the font file: lack of metadata
Before I started coding, I believed that you can quickly get the necessary information about the properties of fonts. Theoretically, each font file should contain different metadata tables with the name, author name, supported languages, and visual properties. The most obvious ones are the width, weight, and class of the font . You can also find information about the x-height, height of capital letters, the average width of the character, the upper and lower offset elements of the letters. Another set of metadata, called Panose, describes even more properties: serif shapes, proportions, contrast, and more. To view all this information, you can use font design applications, for example, Glyphs:

Screenshot panel with information about the font. Here is the family name, designer name, link, version, date. You can also see a range of Unicode and Panose data. The 10-digit code describes many characteristics, but the information is not always available, as it is contributed by the designer or the creator of the file. On the right screenshot you can see metrics such as top and bottom outrigger, x-height and angle of inclination.
But the availability of this information depends on how responsibly the font creator approached his work. In some font files there is a lot of data, but often there is not enough information, especially in free or open source fonts. And even if there is information in the file, it may be incorrect or incomplete.

A comparison of the Panose data for Roboto and Fira Sans fonts, both available on Google Fonts. For Fira Sans, a lot of information is indicated, but for Roboto - a little. This metadata cannot be used to compare fonts.
DIY: Analyzing fonts with opentype.js
Let's analyze the font files and figure out how to automatically extract the necessary information. Files have different formats, but you can almost always find versions in TTF (TrueType Font).
In OTF (OpenType) format files, you can find information about additional properties, such as ligatures. WOFF (Web Open Font Format) files have additional metadata, and fonts are stored in a compressed form.
Thanks to opentype.js, you can analyze font files directly in your browser using JavaScript. Opentype.js provides access to vector information for all typesetters included in a file, as well as to the main metrics and metadata tables.
Font Characteristics Database
Below we look at how to measure the contrast, x-height, width and weight of all fonts from the Google Fonts library. The same methods can be applied to other font libraries, such as Typekit or fonts on your computer.
Contrast
Contrast describes the ratio of thin and thick strokes of a symbol. There are low contrast fonts, such as squared fonts, or many grotesques created for interfaces, such as Roboto or San Francisco. And there are fonts with high contrast, for example, Bodoni or Didot. To measure contrast, we can look at the contours of the letter “o” and compare the largest and smallest distance between the inner and outer contour.

Font contrast can be measured in the thickest and thinnest part of the letter “o”.
This simple and easily comparable letter almost always consists of two parts. She is a good candidate for assessing the contrast of a font (note: the “o” shape is simple only at first glance, in fact, it is rather difficult to draw it well, because the strokes should smoothly change their thickness).

Using opentype.js, it’s convenient to get data for drawing characters as SVG elements. For example, you can draw the outer and inner contours separately. Then, using a single algorithm, you can follow each contour, measuring the distance between them. After that, we calculate the ratio between the longest and shortest distance, and voila - we got the contrast value, by which the fonts can be compared.
x-height
x-height is an important characteristic that can be an indicator of readability and subjectively perceived font size. Usually this parameter is measured as the height of a lowercase letter "x".

x-height can be measured using information provided by opentype.js.
opentype.js for each character provides the parameter yMax .
In addition to the absolute measurement of the x-height, it may be necessary to compare the x-height with the height of the protruding risers. That is, get values like "x-height is 60% of uppercase letters."
In order for the obtained values to be used for comparison (in some fonts, 1000 units are used per Em (typographical unit of measure), in others 2048), it is necessary to normalize them and compare them with a range from 0 to 1.
Width / Proportion
Using this value, you can estimate the font density. How tight is it, compressed, or, on the contrary, stretched, free? One could, for example, measure the width of the letter “M” in different fonts, but then one would have to take into account the overall size or x-height. In addition, in some fonts "M" is very specific and not typical for the rest of the character set.
You can also calculate the average character width based on a reference word like “Hamburgefontsiv”. This is a good option, but you still need to do a normalization, taking into account the overall design and font height.
Another approach is to determine the proportion of the letter “o”. This gives us surprisingly good values by which we can compare the widths of different headsets.

Weight
To measure the weight, you can display a lowercase “o” on the HTML page, fill it with black, and the background white. Then calculate the ratio of black and white pixels. A handwritten or very thin font will have a very small value, while a heavy, bulky font will have a large ratio. The results are quite satisfactory, but they can be further improved by measuring the full width of characters.

Distance
If all characters of the font have the same width, such a font is called monospaced. It is important to note that to determine the width we don’t have to look at the characters themselves. Even in monospaced font, the point symbol visually takes up less space than “m”. Therefore, you should take into account the advanceWidth property, which describes invisible fields around a symbol. Surprisingly, Google Fonts uses the term monospaced as a style definition, not a technical property. Fonts like Lekton or Libre Barcode are not at all classified as monospaced, although technically they are.
Similarity
Having obtained a table of values, we can normalize them and calculate the distances in order to evaluate the similarity of the fonts. Here is the simplest version of the calculation, but the result will be better if you increase the accuracy of the data. In addition, a person can evaluate the similarity of fonts in a different way than an algorithm for which all characteristics are the same. In this case, we must take into account some properties more than others.
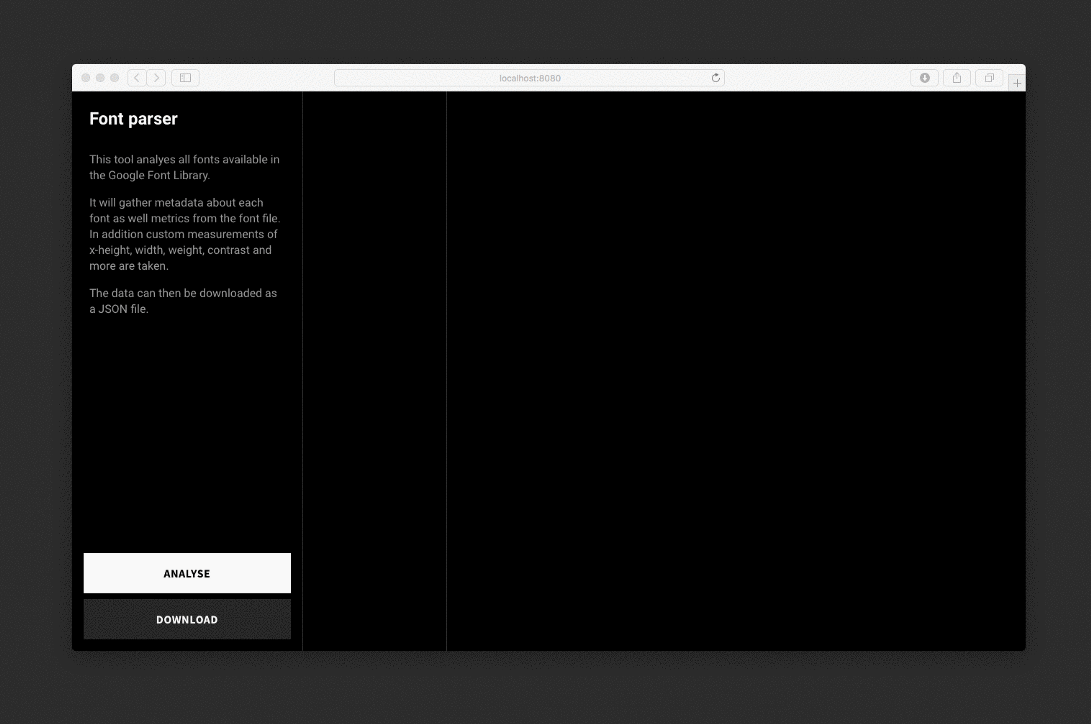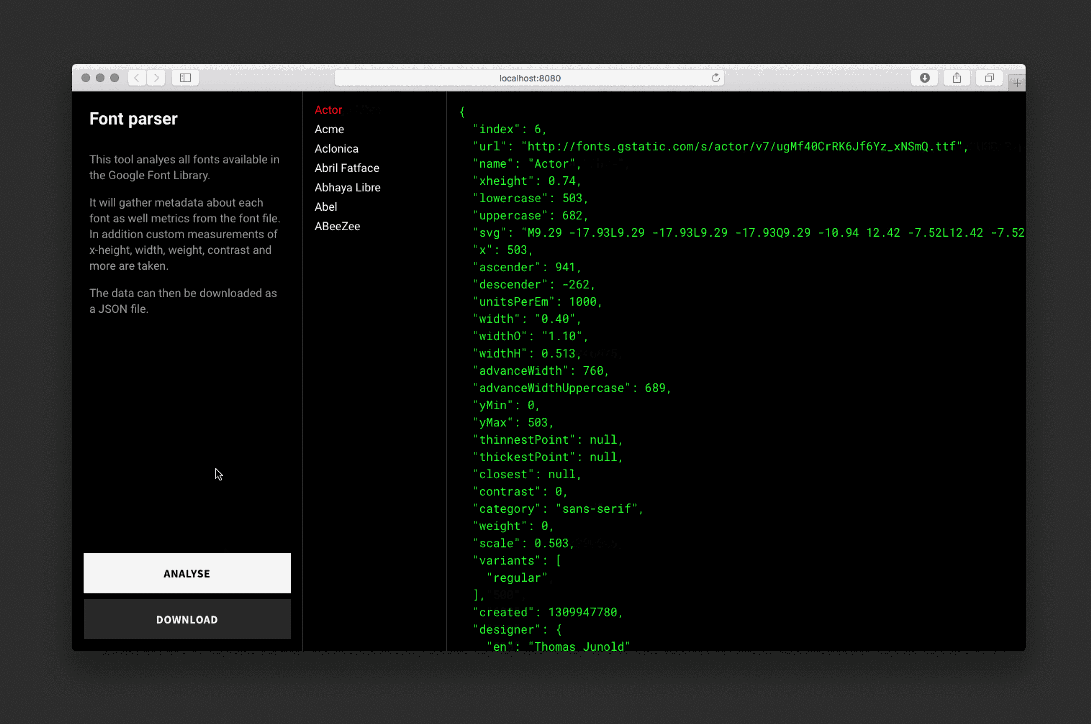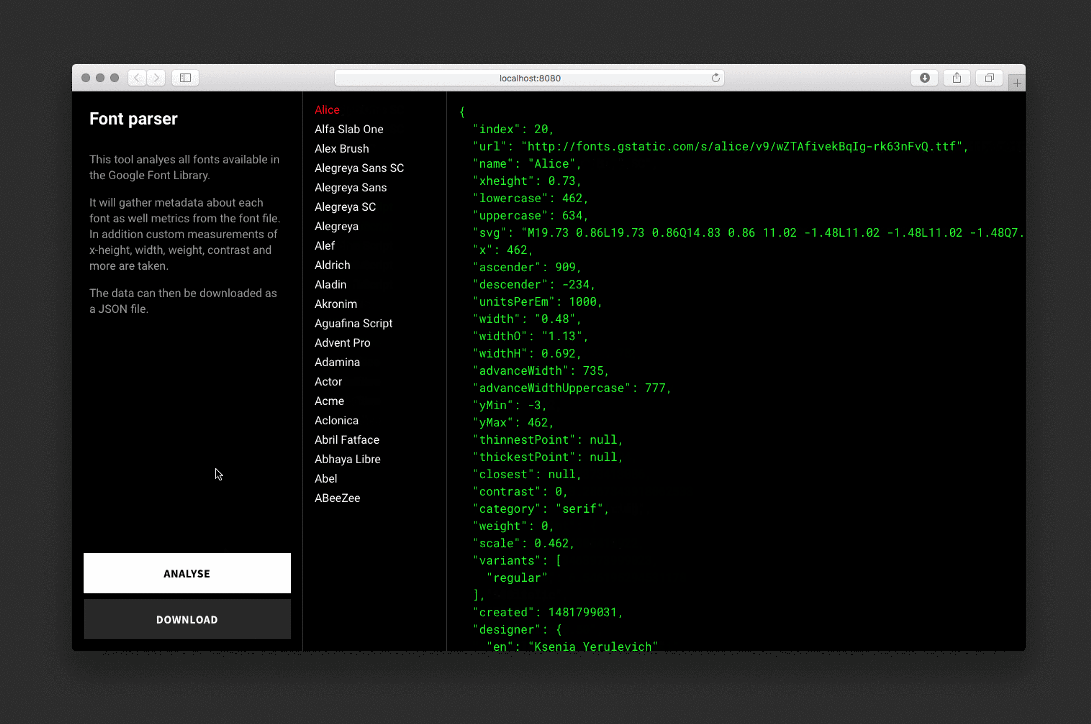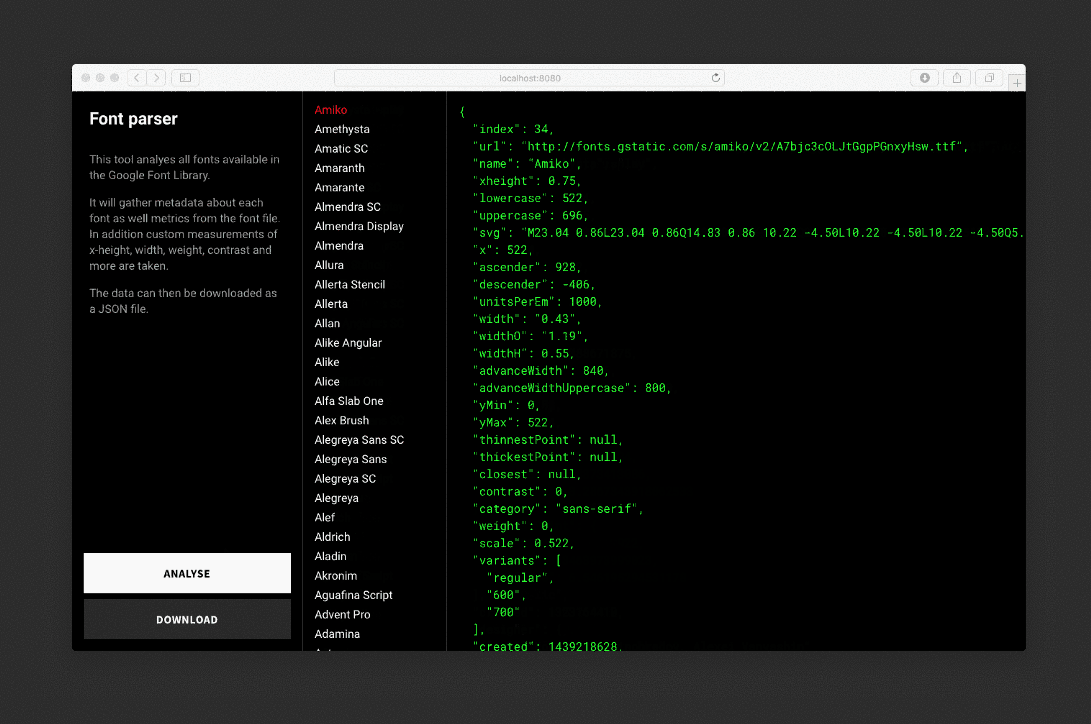
The parser analyzes each font, draws invisible SVG and background elements, takes measurements, and saves the data to a JSON file.
Demo
To access the database interface is written. Fonts can be viewed as a grid with a cell of a different size in order to cover a lot of fonts at once or in more detail to evaluate some of them.
Fonts can be sorted by weight, x-height, contrast, width, name and number of styles. Charts show the distribution of values and can be used to filter out certain values. For each font there is a detailed display with several examples, symbols, metrics, Panose-data and an enumeration of similar fonts.

Dataset
For some reason, some fonts do not load in Safari, so I recommend using Chrome.
Discoveries
You can explore datasets yourself in search of similarities and inconsistencies. If you set a low contrast and the presence of serifs, then the program will issue all squared fonts. If you set a low x-height, then the issue will consist mostly of handwritten fonts. Very high values are usually characteristic of fonts consisting solely of capital letters.
Outcasts
When choosing extreme values, very strange fonts usually “crawl out”. As a rule, they are classified as screen fonts.
Unpleasant differences
A grid view reveals the terrible differences between baselines and alignments. Some fonts categorically do not fit into the grid. And even if the differences are small, it becomes obvious that a simple replacement of fonts in the project is hardly possible, except for several popular fonts with a very similar structure.
Golden mean
It is curious that the frequently used fonts, which are considered good, the program puts in a list similar to each other. If you adjust the filters, you can reduce the list by about half, but all the popular fonts will remain. So if you need to filter out strange and extreme fonts, just select the average values.
Forked Fonts
There are fonts that are called differently, but look exactly the same. Some of them are forks with an extended character set to support different languages, for example, Alegreya & Sahitya.
Number of styles
The number of font styles is a good indicator of its quality. Variable fonts are already looming on the horizon, and it is quite possible that the future is endless customization. But until then, it is recommended to work with fonts belonging to several styles. So sorting the collection by number of styles is a good way to find out about the best fonts available.
Results
This is a rather complicated approach to finding fonts. In general, search results depend on the quality of the fonts and related data. If you use only Google Fonts, then you are very limited because there are not the best fonts in their class. When analyzing the contents of Typekit, it turned out that the interface had performance problems when working with so many fonts. You need to use caching and preloading, but this has not yet reached the hands.
You can get a good idea of the contents of the font files and the missing data without any neural networks. The more you do it, the more clearly you realize the scale of the font history and the industry standing on its shoulders.
Opportunities
What can be done with this dataset:
- Find replacement fonts of similar width or style.
- Based on the x-height, automatically adjust font sizes and line heights.
- Find combinations of fonts based on their similarities or differences.
- Create your own font selection menu for the Avatar movie poster designer.
- ...
application
Additional materials
Panose Classification Metrics Guide
A 1991 manual detailing how to measure individual characters in order to get suitable metrics for comparison. Unfortunately, these measurements need to be done manually, which will take a long time.
Taking The Robots To Design School, Part 1 by Jon Gold
In May 2016, Jon Gold wrote about his approach to font analysis. He touched on topics such as rule based design, AI and dataset matching to designer tools.
Google Fonts Tools
A set of open source tools for analyzing fonts on Google Fonts. For example, to determine the angle of the font.
Font Bakery
This is a set of Python tools for checking TrueType files and metadata files for fonts with Google Fonts.
Why not just use data from web font services?
All such services — for example, Typekit, Google Fonts, Fontstand, Fontshop, MyFonts, and so on — have their own filter sets with varying degrees of customization. The APIs of these services for each font provide a different amount of information.
For example, for the Roboto font from the Google Fonts web API, you can get the category "grotesque" and font options. https://gist.github.com/getflourish/d79836b0bebb6b44f76389b623fd7dc1
API Typekit provides more width, x-height, weight, classification, contrast, capital letters and recommendations.
https://gist.github.com/getflourish
Source: https://habr.com/ru/post/347834/
All Articles