Learning the Spring Framework is 100% through practice. Active Tutorials and KML Markup Language. Project KciTasks (beta)
Spring Framework is traditionally considered one of the most difficult and at the same time highly paid . However, the existing approaches to its study are extremely inefficient. I would like to offer you a fundamentally new approach to the study of spring, which is to use the concept of active tutorials . They are a balanced set of instructions that support the attention of the developer and guide him through certain aspects of the framework.
As a result, we get targeted training , but WITHOUT stupor, problems of misunderstanding of the form “where to use it”, as well as without boring and passive reading of the theory. Totally.
')
The article presents 5 training tasks that cover Spring Jdbc / Transactions for 50% of the knowledge required for certification. The main task of the article is to massively test the idea itself, as well as to work with you to develop a large number of unique tasks on all topics.
First, a little about yourself. My name is Jaroslav, and I work at Middle Java Developer's position at EPAM Systems. One of my hobbies is the creation of training systems (bachelor’s degree, master’s degree). Over the past 4 years, I have tried more than a hundred of the most varied approaches to learning various areas of knowledge (including Java / Spring), and created more than twenty prototype programs to test these approaches. Most of them did not bring any super-benefits, and therefore I continue to work in this direction.
This article is devoted to one of my ideas, which, theoretically , can take off. It is necessary to massively test it, this is the task of this article. Looking ahead, I recommend that you go and see the web page with the puzzles to understand what it is about ( https://kciray8.imtqy.com/KciTasks/App/src/ ).
I am a perfectionist and I want the training to be close to perfect. In my understanding, it is learning that does not cause negative emotions, delays and brings pleasure. Unfortunately, the study of many modern (and highly paid) technologies causes difficulties. The Spring Framework has traditionally been considered one of the most difficult to learn, and its study is extremely inefficient.
How do you usually learn Spring
There are 2 extremes in learning frameworks. The first is when a person works in a company and simply does the tasks that the customer gives. This is a slow, very slow way of development , but most developers follow it. It is logical to do only what they ask for, especially when they pay for it, isn't it? However, learning “at work” only seems to be effective. Most of the tasks that modern programmers solve are systems maintenance. Everything is already written to us, you only need to fix bugs \ edit configs, and modify the system with a file. There is nothing wrong with that, but learning about the technology itself is extremely slow. Of course, sooner or later you will have to dig up the documentation of the spring and you will remember everything you need, but it will take years . Maybe it is worth trying first to “wind up” knowledge and experience, and then take more practical tasks more difficult (and for a significantly larger salary, of course)? (With Java, this works for sure, you can purposefully study Java SE for 2-3 months and this can be counted for a year or two of experience. Many acquaintances from the university who did this).
The second extreme is targeted learning . This is a quick, but VERY hard way. It lies in the fact that a person moves up the book (or course), and then tries to put it into practice and somehow remember. And if with Java SE this approach still works somehow, then with spring everything is deaf and tight. Even in the best books, it is often not explained where to apply particular features, you have to catch up with it yourself. But the most annoying thing here is the forgetting of information obtained by such hard work. One of the learning problems is the lack of effective repetition. If you studied the spring in the classical way (for example, read a book and tried the code in practice), then enormous efforts were spent on this, but WITHOUT the possibility of recovery. A simple re-reading of the book in 1-2 years will not return to you the forgotten information (which you received through the practice, parallel to the reading). There is a certain dilemma - how to make it so that there is a lot of practice, but at the same time the programmer is “directed” to the right areas?
Learning problems
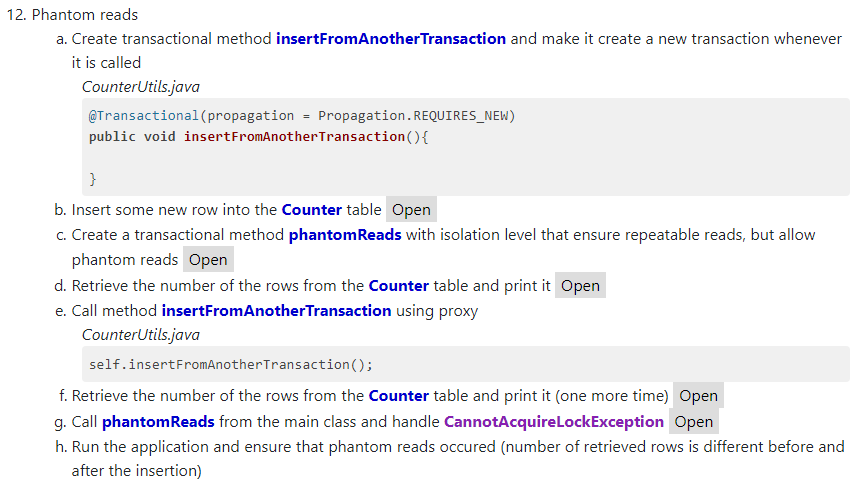
So, we concluded that extremes in learning are bad. Let's think about how to optimize the process. Purposeful learning looks like the right idea to develop further . Let us consider in more detail why this causes difficulties for most people.
To begin with, we will select materials on which it is worth studying. The main requirement for them is a limited set of information (only what is needed for certification / interviewing / practice), as well as a consistent and logically interrelated presentation of this information. According to these criteria, the books are best suited ( Spring in action , Certification manual from Juliana , etc.) They are very well thought out and decorated (in my opinion, it’s much nicer and more detailed than the udemy video courses). It would seem, read to yourself, understand, try, experiment - and there will be knowledge! But it was not there.
The fact is that the process of reading a book and analyzing a theory in it is very poorly connected with the process of testing this theory in practice . He is not natural . Whatever book is perfect, it remains a book. It is not by its nature intended to teach programming. The programmer, in the end, must fill the good habits of the conscious use of certain technologies of the framework. Between "I read and understand" and "I know how to apply it and know where" there is a huge gap . To overcome it, you have to invest a lot of effort. Frankly, I wrote quite a few web applications on Spring, but I still had many difficulties reading the chapters of the book Spring in Action. At the moment, I have disassembled in detail about 30% of both books, and is ready for Spring 5 certification by about 60%.
I observed similar problems when studying the Android SDK in 2014. The solution here is quite simple - each framework introduces some new concepts of its own which are quite difficult to understand and start thinking through them (if you use the traditional ways of learning).
The process of linking the information presented in the book with habits is very difficult and not effective. It often causes a lot of negative emotions (when something does not work or does not start), makes a lot of Google and solve problems. Is it really impossible to make some “ways (trails)” by which the developer can be led, show him the right decisions, and in a way that he himself does them? After all, experienced developers are well aware of such paths. For them, this is something obvious. But there is a problem in the form of knowledge transfer. As we have already found out, books are not suitable for this purpose.
Another problem that I would like to draw attention to is the problem of repetition . Even if we overcome all the difficulties and broadly pump up the knowledge of the spring, with time they will fade away (not counting the small percentage that we managed to associate with current tasks). It is human nature to forget, and nothing can be done about it. The only thing we can do is try to optimize the repetition. When I studied at the undergraduate level , I had high hopes for the theory of interval repetition and knowledge storage in the form of flash cards ( Habrostatya about a bachelor's degree ). However, flash cards are too independent of each other (not suitable for storing related spring knowledge). Even for learning Java, their effectiveness is average. Yes, and they are also not natural, because the programmer must repeat through practice .
For many years I have been puzzled over how to make training 100% tied to practice ( as a result - not boring and with high efficiency ). Now I will briefly talk about the options that have been tried. To begin with, I tried to find a set of detailed and training TK that would, apart from the tasks, give technical hints (develop such-and-such REST Api using such-and-such classes). I did not find anything sensible, and spent a lot of time. Yes, I saw some author's courses on some parts of the spring, but nowhere to collect full certification coverage. And the “book” problem of these tutorials remains (although some authors tried to make step-by-step tutorials, they still have flaws). PS: If you have something like "Training TK" for spring, be sure to send them to me at kciray8@gmail.com.
One of the problems of books and tutorials is that they are very boring and tedious to read. This is even more painful than google bugs. I do not want to read, I want to code! What if you use the book only for guidance on topics and class names , and then independently (through experiments and Google) to catch up with everything else? And only then reread the chapter, overpowering itself and collecting the remaining bits of knowledge. Actually, I studied the spring. Not from the beginning of the chapter (sad introduction), but from the middle, trying to grasp something and experiment around it. The IDE helps a lot with autofilling, JavaDoc browsing and source code, convenient debugging. I would call it “learning through API experiments . ” I even developed a number of special techniques around this method, but there still remain some fundamental problems.
Namely, the problem of "stupors" does not go anywhere. It still causes a lot of pain, although it is already more natural and closer to practice (in real projects you will have to solve many such stupors, it will be useful to pump the skill). In fact, this method can be quite a walk to the final goal (certification). But it will require a lot of effort, 3-4 times larger than if you go on the thumb track . Yes, and the problem of repeating information still remains. And I want to do something more close to the ideal. Suddenly my new technique will be useful to a lot of people and change the world? And at the end of 2017, I came up with such an idea, so much so that I wanted to implement it immediately and initially I did very large stakes on success.
Let's think about how learning takes place in a classic (mostly passive) tutorial. Most Spring tutorials are simply disgusting in their structure (including spring.io guides). Their biggest drawback, which I just can not stand, is linearity. Many authors “dump” large chunks of code that need to copy-paste to themselves. It would be more correct to start with a simple example (the smallest possible demonstration that you can run and experiment with), and then wind it up with various bells and whistles. The principle “from simple to complex” is the golden law of learning! But not because. Each author considers it necessary to wind the information in 2-4 times more than necessary, disassemble it in pieces and only then run it.
For example, we’ll open the guide to raising the SOAP-service in the spring ( https://spring.io/guides/gs/producing-web-service , recently it took to work). They screwed up the spring-boot, and wsdl4j with the process of generating Java classes using gradle, and the whole in-memory repository CountryRepository (although a simple “Hello world” line would be enough for me). It was only at the very end that they explained how to use curl to start the whole system. No, I certainly understand everything - the authors wanted to give a vivid example of “all in one” and disassemble it. But, from the point of view of understanding information, this approach is not suitable.
Do you like to “read” a boring analysis and copy-paste pieces of code (each half a page)? I can not stand it. I want to get experience experimentally, and that's it.
The idea of active tutorials (KciTasks)
What if you make a kind of virtual teacher who simply gives small instructions like " do this and that", and if the programmer made a mistake or forgot, the teacher simply gives a code fragment. At its core, xi-hauls are those. The essence of them is that we have a small set of instructions, each of which has an answer and it is under the spoiler (hidden). The difference between them and the usual tutorial can be seen on the following graph:

The concept of the project from scratch
Before continuing the analysis of active tutorials, I would like to talk about one important concept on which they are based. You can use this concept together with any teaching method, but for some reason it is rarely written or mentioned somewhere. So, its essence is that training projects need to be done from scratch . No start.spring.io, every day go to File-> new Project-> Hello world and base all your projects on it, including the web. And all the maven-dependencies also score in a new way. Thanks to this, you will remember the dependencies between the spring modules, why you need each of them, etc. In practice, this is very useful when there are any problems with dependencies.
Practical orientation
Do you like XML? The authors of both books on Spring agree that sooner or later XML will become a relic of the past. However, they themselves bring the majority of solutions in two versions (XML + Annotations). I didn’t like XML until I got a big company. Now it's just part of the job. Too many ready-made solutions are made that are simply permeated with XML and rewritten without him - to spend huge amounts of money and get incomparably little. No one will do that. Therefore, I tried to alternate XML / Annotations in my puzzles, which I recommend to you . If one is properly trained (according to the method described in the article), then XML does not cause problems, but, on the contrary, helps to look at some solutions from the other side and remember them better. Writing XML code (with autocompletions and prompts, using the IDE) is as good as writing Java code.
Approaching the ideal (0.5% copy-paste, 5% reading)
Each instruction in the active tutorial must be executable WITHOUT copy-paste. Modern IDEs allow you to multiply it by zero. Yes, even beans.xml with all its pribluda, even dependencies - everything can be done inside the IDE. This is much nicer than mindlessly copy code. As I said, I want to make learning enjoyable and this is one of the manifestations.
Each instruction in xi-taske makes you think a little and remember something. This is the "activity" of this tutorial. This process is much more pleasant than reading or copying code. Here you need to maintain a balance - the instruction should not be too stupid (otherwise it will not be so pleasant), and should not be too complicated (which would entail large pieces of code and problems similar to tutorials). I have never seen such developments anywhere, although I have seen many different training systems.
Special language for active tutorials (KML)
One of the reasons why no one has yet distributed active tutorials is the lack of a format for storing them. Existing markup languages are completely unsuitable for mixing code and text . I did the first version of KciTasks as an add-on for HTML, and it was just awful how uncomfortable! Then I made my own small markup language, which is great for puzzles and compiles to HTML. And it happens right at the time of loading the web page. Here are some examples:
Example 1 - Creating a JdbcTemplate bean
=Create a @@JdbcTemplate@@ as a @@@Bean@@ with @@DataSource@@ injected into it +Main.java @Bean JdbcTemplate getJdbcTemplate(DataSource dataSource){ return new JdbcTemplate(dataSource); } 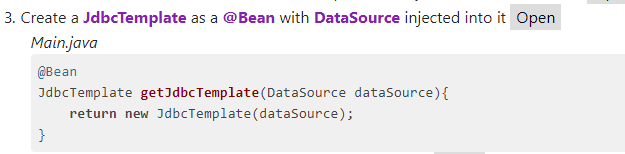
Example 2 - Creating a schema.sql file
=Create a file ~~schema.sql~~ with a DDL-statement for creating a new table ##Product## (name, price) +schema.sql CREATE TABLE Product(name VARCHAR(100), price DOUBLE) 
Full sample task (JdbcTemplate2.kml)
###name=Jdbc template and datasource part 2 ###full = JdbcTemplate2.zip =Create a spring-based modern application ==Create a Java project from scratch using your favorite IDE +<<MainEmpty ==Add ##maven## support to it ==Annotate class @@Main@@ as a configuration (with automatic scan) +<<spring-context +<<MainConfiguration ==Create a ##run## method inside the @@Main@@ class +Main.java void run(){ } ==Create a new context and call @@Main.run()@@ +Main.java public static void main(String[] args){ AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(Main.class); context.getBean(Main.class).run(); } =Add Apache Derby as a @@@Bean@@ using builder (embedded) +<<derby +<<spring-jdbc +Main.java @Bean public DataSource dataSource(){ return new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseType.DERBY).build(); } =Create @@JdbcTemplate@@ as a @@@Bean@@ and inject @@DataSource@@ into it +Main.java @Bean public JdbcTemplate jdbcTemplate(DataSource dataSource){ return new JdbcTemplate(dataSource); } =Retrieve the url from ##JdbcTemplate## and print it to the console +Main.java @Autowired JdbcTemplate jdbcTemplate; +Main.java void run(){ String url = jdbcTemplate.execute((ConnectionCallback<String>) con -> con.getMetaData().getURL()); System.out.println(url); } =Run the application and ensure that the url contains "derby" +Output jdbc:derby:memory:testdb =Create a file ~~schema.sql~~ with a DDL-statement for creating a new table ##Product## (name, price) +schema.sql CREATE TABLE Product(name VARCHAR(100), price DOUBLE) =Create a file ~~test-data.sql~~ with a few DML-statements that insert distinct products +test-data.sql INSERT INTO Product VALUES('Milk', 3.5) INSERT INTO Product VALUES('Eggs', 6) =Inject ~~schema.sql~~ and ~~test-data.sql~~ into the ##Main## class as spring-resources +Main.java @Value("schema.sql") Resource schema; @Value("test-data.sql") Resource testData; =Create a resource-based database populator and use it to init the database +Main.java ResourceDatabasePopulator populator = new ResourceDatabasePopulator(); populator.addScript(schema); populator.addScript(testData); DataSourceInitializer initializer = new DataSourceInitializer(); initializer.setDatabasePopulator(populator); DatabasePopulatorUtils.execute(populator, dataSource); =Retrive the names of the products to a list and print it +Main.java List<String> productNames = jdbcTemplate.queryForList("SELECT name FROM Product", String.class); System.out.println(productNames); =Run the application and ensure that the names of the products were printed accordingly with ~~test-data.sql~~ +Output [Milk, Eggs] =Create a domain object @@Product@@ (with custom !!toString!!) +Product.java public class Product { String name; Double price; @Override public String toString() { return "Product{" + "name='" + name + '\'' + ", price=" + price + '}'; } } =Retrieve a @@List<Product>@@ using a row mapper and print it +Main.java List<Product> products = jdbcTemplate.query("SELECT * FROM Product", (RowMapper<Product>) (rs, rowNum) -> { Product product = new Product(); product.name = rs.getString("name"); product.price = rs.getDouble("price"); return product; }); System.out.println(products); =Create a class with name @@ProductSet@@ that has a list of products as its member +ProductSet.java public class ProductSet { public List<Product> products = new ArrayList<>(); } =Retrieve a @@ProductSet@@ using a result set extractor and print its products +Main.java ProductSet productSet = jdbcTemplate.query("SELECT * FROM Product", (ResultSetExtractor<ProductSet>) rs->{ ProductSet set = new ProductSet(); while (rs.next()){ Product product = new Product(); product.name = rs.getString("name"); product.price = rs.getDouble("price"); set.products.add(product); }; return set; }); System.out.println(productSet.products); =Run the application and ensure that the products was printed correctly (two times) +Output [Product{name='Milk', price=3.5}, Product{name='Eggs', price=6.0}] [Product{name='Milk', price=3.5}, Product{name='Eggs', price=6.0}] Core Spring 5.0 Certification Full Coverage Plan
On the Internet, there is a holivar about whether certificates are needed. You can write a separate article about this, but within the framework of this article I’ll just write “you need and as much as possible . ” A month ago the Study Guide for Spring 5 was released (and the pivotal exam itself ), so it makes sense to focus on it. For us, this can serve as a plan , or some standard set that is asked at interviews and which can be useful for your projects.
For each topic, 6-8 unique tasks need to be done that affect the required amount of knowledge and feed information from different points of view (for example, a DataSource is created in different ways - using builders, manually, using tools, annotations or XML, automatically via Boot and etc.). Having trained, the programmer will reliably remember what the DataSource is and how it is used (instead of “learning, passing and forgetting,” as many do). In addition, threads often overlap each other (Container and AOP are used in Spring Data). This allows you to very well deepen the basics of the basics.
Despite the maximum automation of the process through the markup language, the development of tasks is a very time consuming task . Especially if you do them qualitatively (showing everything in a simple form and from the right perspective). For example, it took me about 10 hours to develop a puzzle for isolation levels in transactions. It would seem that you only need to demonstrate the difference between the 4 levels, running the transaction in parallel. But it was not there! For H2 and MySQL, the difference between some levels is not visible, and they handle conflict situations in different ways (some databases return old copies of data, others put the translation into standby mode). And only in DerbyDB you can clearly see the difference between all levels. All authors of books are so clever - they copy the theory, but to show it in practice - a full-fledged example was never found, I had to deduce myself.
The essence of my plan is to combine my efforts with yours and together develop a large number of unique tasks for Spring 5. All that is required of you is to send me an * .kml file with a problem, and a zip-archive of the project. The tasks will be available free of charge and without registration, for everyone, through the GitHub-website . Or you can make a pull-request (if you need to modify something in the engine itself). I believe that together we can create a new principle of learning and carry it to the masses.
| Subject ( % of exam ) | KciTasks Coating | Users (coverage plan) |
|---|---|---|
| Container (28%) | ten% | |
| AOP (14%) | ten% | |
| JDBC (4%) | 50% | |
| Transactions (10%) | 50% | kciray8@gmail.com (+ 20%) |
| MVC (10%) | 0 | |
| Security (6%) | 0 | |
| REST (6%) | 0 | |
| JPA Spring Data (4%) | 0 | kciray8@gmail.com (+ 50%) |
| Boot (14%) | 0 | |
| Testing (4%) | 0 |
Also, I want to draw attention to the request to support the project in the form of a donate (banner in the site header). I would very much like to receive compensation for the effort expended (and the Java-developers community is far from being poor).
Recommendations
For each topic of the spring, you can come up with many unique tasks. For example, you can give instructions for developing some REST API via MVC spring, and then retrieve data from it via RestTemplate and output it to the console. It turns out 2 to 1, some closed ring. In general, the scope for creativity here is very large, you need only time and desire. And the more unique tasks, the better! If you want to add something of your own (unusual) - go ahead. The versatility of learning is very important. It is necessary to show the same knowledge from a large number of different angles, then they will be well remembered. The main thing is to keep the balance mentioned above (each instruction requires doing something, but not too much). Together we will be able to convert knowledge from books into the form of tasques and make a big deal!
PS: If someone from the readers passed the exam and / or the official course from pivotal, write to me at kciray8@gmail.com.
Learning system or system of repetition?
I see two ways you can use KciTasks. The first is to use it for in-depth study of the spring. In my opinion, this should be effective. You simply follow the instructions for the instructions, referring to the decision and correcting yourself. At first, you will “pry” a lot there, but this is normal. The next day, try to pry as little as possible and do everything yourself. All tasks are designed to be made without deploying spoilers, ALL. You need to come to this. Please note that you do not google (!!!), do not read the docks or book . Tasks are self-sufficient, just read the instructions and the solution to it, and derive knowledge from the experiments .
The second way is to use KciTasks for repetition . When you learn a frame or programming language by book / course, you put a lot of effort into it. And let them not be in vain - put all the experience gained in the task, so that after six months you can walk along the beaten track and remember everything.
Both ways are not tested (beta), so I am waiting for your feedback. And the more, the better. After all, all people are different, different perceptions, and we must see the reaction of the community. I hope that the article will be useful.
Source: https://habr.com/ru/post/347816/
All Articles