Apply CatBoost models inside ClickHouse. Yandex lecture
In what situations is it convenient to apply pre-trained machine learning models inside ClickHouse? Why is CatBoost best suited for this task? Not so long ago, we had a meeting dedicated to the simultaneous use of these two open-source technologies. Developer Nikolay Kochetov spoke at the meeting - we decided to share his lecture with you. Nikolay analyzes the described problem on the example of the algorithm for predicting the probability of purchase.
- First about how ClickHouse works. ClickHouse is an analytic distributed DBMS. It is columnar and open source. The most interesting word here is “columnar”. What does it mean?
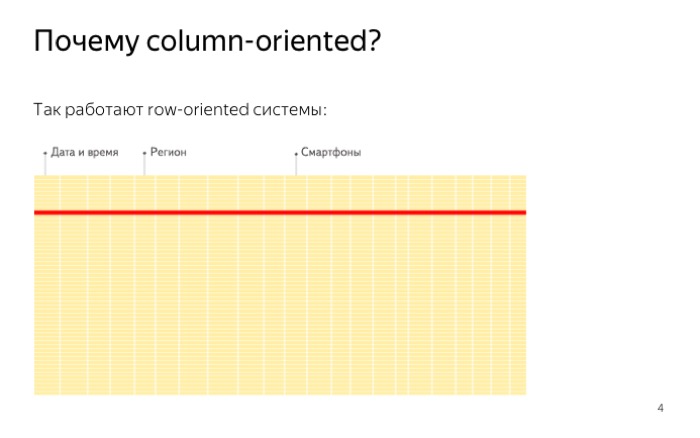
This is how data is stored in regular databases. Are stored line by line, files are recorded in a row. In other words, if we need to read the data for just one value, we are forced to read the whole line. This is due to the characteristics of the hard disk. It is impossible to read one byte, and random reading is much more expensive than sequential. As a result, we read a lot of unnecessary data.

In ClickHouse, everything is completely different. ClickHouse stores data by columns, which means that when we have to read only one sign, one column, we read exactly one file. This is done much faster, much like on the slide.
Additionally, ClickHouse compresses the data, and the fact that we store data in columns gives us an advantage. Data is more distant and better compressed.
')
Compression also saves us disk space and allows us to perform queries faster in many scenarios.
How fast is ClickHouse? We conducted speed tests in the company. I will show better testing people from the outside.
The graph compares ClickHouse, Spark and the Amazon Redshift database. ClickHouse works much faster on all requests, although the databases are similar in structure, they are also columnar.

ClickHouse supports SQL syntax. This is not fair SQL, this is a dialect. Also, ClickHouse has the ability to use special functions: work with arrays, built-in data structures or functions specific to working with URLs. Insertion in ClickHouse also happens quickly. We inserted the data and immediately can work with them. It turns out work online not only for requests, but also for inserts.
Speaking of distributed data - ClickHouse can work on laptops, but it feels great on hundreds of servers. For example, in Yandex. Metric.
We turn to the second part. We will use some auxiliary task - the prediction of the probability of purchase. The task is quite simple. Suppose there is data from the store. We want to benefit from them, find out more information about users. It would be possible to consider the probability of a purchase, something to do with it. About what exactly to do with it, I will not tell in detail. I'll tell you by example. For example, you can divide users into two categories: good and not. A good show more ads, not very good less. And - save on advertising or get more conversion.
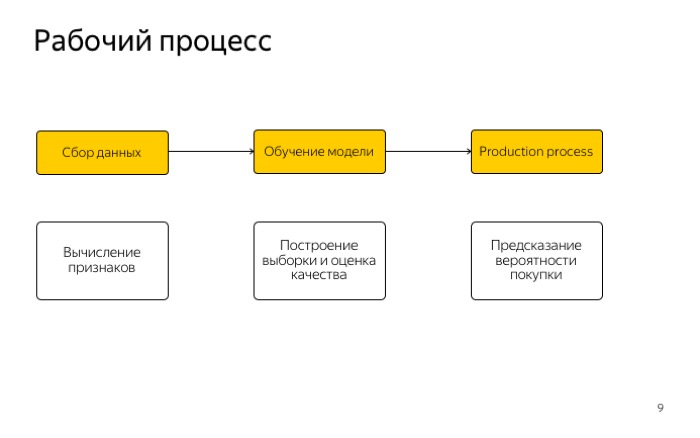
Let's look at the workflow. It is very simple and is familiar to all of you, in three stages: working with signs, collecting data and getting a sample.
The second stage is training the model and assessing its quality.
The last is the use of the model in production.
Where to get the data from? You can take from Yandex. Metrics, where data is stored inside ClickHouse. We will also use ClickHouse. But the data that we took, we took using the Logs API metrics. We presented ourselves to external users and loaded data using what was available to external people.
What data could we get? First, the information about the pages viewed, what products saw what he visited. This is also the state of the user's basket and what purchases he made for this.
The latter is the device from which the user logged in, the type of browser, desktop or mobile client.

The fact that we store data in ClickHouse gives us advantages. Specifically, in that we can count almost any signs that we can think of, since ClickHouse stores data in a non-aggregated form, there is an example - calculating the average session duration.

The example has several features. The first one is clipping by dates. We used start and end_date, and ClickHouse works effectively with this, it will not read what we have not requested. We also used sampling: we said that we would read 1/10 of the data. ClickHouse does it efficiently, it discards unnecessary data immediately after reading the data from the disk.

Mention training models. What classifiers did we use?
We have a trained model, it gives out good quality. How to implement it now?
It would seem a simple question. Let's do it simply: every Monday, unload the data for the previous month from ClickHouse, run Python scripts, get the probability of purchase and upload back to, say, the same ClickHouse table. This all works well, it is simply and efficiently written, but some drawbacks arise.
The first disadvantage is that the data must be unloaded. It can brake, and not inside ClickHouse, but most likely inside Python scripts.
The second drawback is that we prepare answers in advance, and if we considered the probability of a purchase from Monday to Sunday, we cannot simply find out from Wednesday to Thursday, for example, or over the past year.
One way to solve this is to carefully look at the model. The model is simple: addition operations, multiplications, conditional transitions. Let's write the model in the form of ClickHouse queries, and immediately get rid of our shortcomings. Firstly, we do not use data upload, and secondly, we can substitute any dates and everything will work.
But the question arises: what algorithms can we transfer to the DBMS? The first thing that comes to mind is the use of linear classifiers.

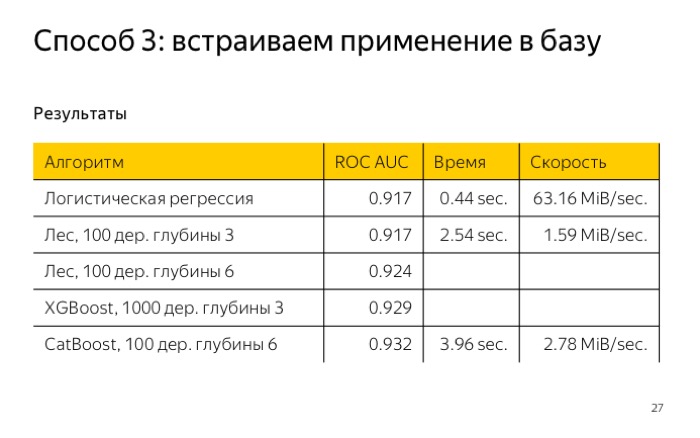
To use it, you need to multiply the weights vectors by the value of the signs and compare them with some threshold. For example, I trained our logistic regression samples and obtained log loss quality of 0.041. Then I checked how fast it works in ClickHouse, wrote a request, and it worked in less than half a second. Not a bad result.
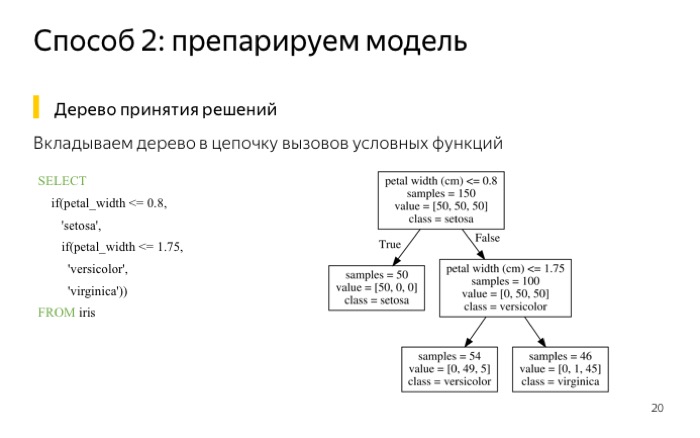
If we have something more complicated than a linear model, for example, trees, they can also be written as a ClickHouse query. What I've done? Took a selection of irises . This sample is good because you can train a small tree for it with a depth of two. She gets an error of less than 5%. If you are so lucky that you have a good sample, you can use a small tree.

You can write a query, conditionally, in the form of two choice functions, and everything will also work well. Ingredient boosting or wood, for example. It is necessary to calculate the amount or average. I also tested it for a small forest, 100 trees of depth 3, in the end I got the quality even worse, and it works in ClickHouse for 2.5 seconds.
Not everything is so bad, if I trained more trees, the quality would be better. But why did I not do that? That's why.

This is what the third part of the forest looks like on 100 trees. I can see that this is very similar to the forest. And if you make the request even more, then ClickHouse just starts to slow down on parsing.

And got additional drawbacks. In addition to the fact that the query is very long, we have to invent it, and this can slowly work in the database itself. For example, for trees, in order to apply them, ClickHouse is forced to read the value at each node of the tree. And this is inefficient, because we could only calculate the values on the way from the root to the leaf.
There is a problem with performance, something can slow down and work inefficiently. This is not what we want.

We would like simpler things: to tell the database that you yourself will figure out how to apply the model, we just tell you that the machine learning library is here, and you just give me the modelEvaluate function, in which we put our list of signs . Such an approach, firstly, has all the advantages of the previous one, and secondly, it shifts all the work to the database. And all there is one drawback - your base must support the application of these models.
In ClickHouse, we implemented it for CatBoost, of course, we tested it. Received the best quality, despite the fact that I taught ... The training time is not very long, just 4 seconds. This is comparatively good compared to a forest 100 of depth 3.

What can be seen in the end?
If it is important for you to see the speed of work, the speed of burdening the algorithm, the quality is not so important, then you can use logistic regression, this will all work quickly.
If quality is important to you, train CatBoost and use it. How to use CatBoost in ClickHouse?

We need to do some pretty simple steps. The first is to describe the configuration of the model. Only 4 significant lines. Model type - now it's CatBoost, maybe sometime we'll add a new one.
The name of the model that will be used as a parameter to the modelEvaluate () function.
The location of the trained model on the file system.
Update time. Here, 0 means that we will not reread the disc material. If it were 5, they would reread every 5 seconds.

Next you need to tell ClickHouse where the configuration file is located, this is the bottom parameter on the slide. It uses an asterisk, which means that all files that fit this mask will be loaded.
You also need to tell ClickHouse where the machine learning library itself is located, namely the wrapper module for CatBoost.

Everything, when we indicated this, we get the possibility of the modelEvaluate () function, which takes the model name from the configuration file as the first argument, and our attributes for the rest. And you must first specify the numerical characteristics, then categorical. But do not worry if you confuse something. First, ClickHouse will tell you that you have a mistake. Secondly, you can test the quality and understand that everything is not as you thought.

To make it easier to test, we also added support for reading from the CatBoost data pool. Probably, someone worked with CatBoost from the console instead of working with it from Python or from R. Then you would have to use a special format for describing your sample. The format is quite simple - just two files. The first one is TSV with three columns, the sign number and its type: categorical, numerical or target. Plus an optional optional name parameter. The second file is the data itself, also TSV.

Just in ClickHouse, we added a table function atBoostPool, which takes these two files as arguments, and returns a special table of the file type, temporary, from which data can be read.
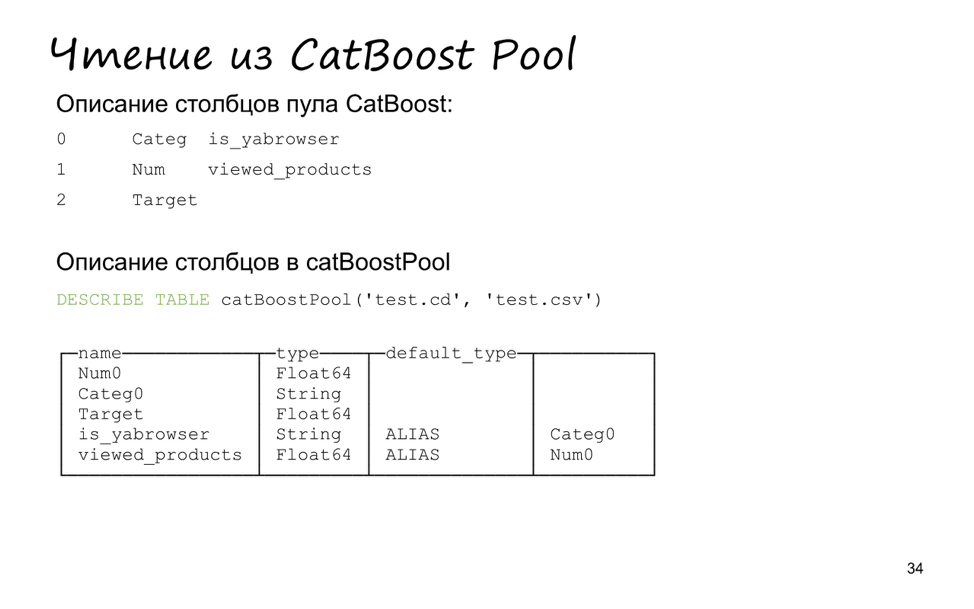
I created a small CatBoost Pool of three values: two signs and a target. It contains five lines. Two are signs, one is a target, two more are additionally ALIAS.
Also, the numeric and categorical features have been swapped. This is done for convenience so that you can submit the parameters to the playModule function in the correct order.

If we make describe what gives the SELECT * query, then the values become less, only two signs remain in the right order. This is done again so that you can conveniently use the CatBoost Pool, namely, passing an asterisk as the remaining arguments to the moduleEvaluate function.

Let's try to apply something. To begin with, we calculate the probability of a purchase. What will we use? First of all, we will consider from the CatBoost Pool, use the moduleEvaluate function and pass the asterisk to the second parameter.
The last line, the third, the application of sigmoid.

Let's complicate the query, consider the quality. Let's write the previous query as a ClickHouse subquery. In total, we added two significant lines, counting the logloss metrics. Calculated the average, got the value from the table.
I was interested in how quickly such a query works. I spent three tests and got this schedule.

On the left - reading from the table, on the right - from the pool. It can be seen that the columns are almost identical, there is almost no difference, but reading from the ClickHouse table works a little faster - apparently because ClickHouse compresses the data, and we don’t spend too much time reading from the file. And CatBoost Pool does not compress, so we spend time reading and transposing signs. It turns out a little faster, but still it is convenient to use CatBoost Pool for tests.
Let's sum up. The integration is that we can apply trained models, use the CatBoost Pool and read data from it, which is quite convenient. The plans - add the use of other models. Also, the task of training within the database is in question, but so far we have not decided whether to do it. If there are a lot of requests, we will seriously consider this.
We have Russian and English groups in Telegram, where we actively respond, there is a GitHub mailing list . If you have questions, you can send questions to me in the mail , in the Telegram or in the Google group . Thank!
- First about how ClickHouse works. ClickHouse is an analytic distributed DBMS. It is columnar and open source. The most interesting word here is “columnar”. What does it mean?
This is how data is stored in regular databases. Are stored line by line, files are recorded in a row. In other words, if we need to read the data for just one value, we are forced to read the whole line. This is due to the characteristics of the hard disk. It is impossible to read one byte, and random reading is much more expensive than sequential. As a result, we read a lot of unnecessary data.
In ClickHouse, everything is completely different. ClickHouse stores data by columns, which means that when we have to read only one sign, one column, we read exactly one file. This is done much faster, much like on the slide.
Additionally, ClickHouse compresses the data, and the fact that we store data in columns gives us an advantage. Data is more distant and better compressed.
')
Compression also saves us disk space and allows us to perform queries faster in many scenarios.
How fast is ClickHouse? We conducted speed tests in the company. I will show better testing people from the outside.
The graph compares ClickHouse, Spark and the Amazon Redshift database. ClickHouse works much faster on all requests, although the databases are similar in structure, they are also columnar.
ClickHouse supports SQL syntax. This is not fair SQL, this is a dialect. Also, ClickHouse has the ability to use special functions: work with arrays, built-in data structures or functions specific to working with URLs. Insertion in ClickHouse also happens quickly. We inserted the data and immediately can work with them. It turns out work online not only for requests, but also for inserts.
Speaking of distributed data - ClickHouse can work on laptops, but it feels great on hundreds of servers. For example, in Yandex. Metric.
We turn to the second part. We will use some auxiliary task - the prediction of the probability of purchase. The task is quite simple. Suppose there is data from the store. We want to benefit from them, find out more information about users. It would be possible to consider the probability of a purchase, something to do with it. About what exactly to do with it, I will not tell in detail. I'll tell you by example. For example, you can divide users into two categories: good and not. A good show more ads, not very good less. And - save on advertising or get more conversion.
Let's look at the workflow. It is very simple and is familiar to all of you, in three stages: working with signs, collecting data and getting a sample.
The second stage is training the model and assessing its quality.
The last is the use of the model in production.
Where to get the data from? You can take from Yandex. Metrics, where data is stored inside ClickHouse. We will also use ClickHouse. But the data that we took, we took using the Logs API metrics. We presented ourselves to external users and loaded data using what was available to external people.
What data could we get? First, the information about the pages viewed, what products saw what he visited. This is also the state of the user's basket and what purchases he made for this.
The latter is the device from which the user logged in, the type of browser, desktop or mobile client.
The fact that we store data in ClickHouse gives us advantages. Specifically, in that we can count almost any signs that we can think of, since ClickHouse stores data in a non-aggregated form, there is an example - calculating the average session duration.
The example has several features. The first one is clipping by dates. We used start and end_date, and ClickHouse works effectively with this, it will not read what we have not requested. We also used sampling: we said that we would read 1/10 of the data. ClickHouse does it efficiently, it discards unnecessary data immediately after reading the data from the disk.
Mention training models. What classifiers did we use?
We have a trained model, it gives out good quality. How to implement it now?
It would seem a simple question. Let's do it simply: every Monday, unload the data for the previous month from ClickHouse, run Python scripts, get the probability of purchase and upload back to, say, the same ClickHouse table. This all works well, it is simply and efficiently written, but some drawbacks arise.
The first disadvantage is that the data must be unloaded. It can brake, and not inside ClickHouse, but most likely inside Python scripts.
The second drawback is that we prepare answers in advance, and if we considered the probability of a purchase from Monday to Sunday, we cannot simply find out from Wednesday to Thursday, for example, or over the past year.
One way to solve this is to carefully look at the model. The model is simple: addition operations, multiplications, conditional transitions. Let's write the model in the form of ClickHouse queries, and immediately get rid of our shortcomings. Firstly, we do not use data upload, and secondly, we can substitute any dates and everything will work.
But the question arises: what algorithms can we transfer to the DBMS? The first thing that comes to mind is the use of linear classifiers.
To use it, you need to multiply the weights vectors by the value of the signs and compare them with some threshold. For example, I trained our logistic regression samples and obtained log loss quality of 0.041. Then I checked how fast it works in ClickHouse, wrote a request, and it worked in less than half a second. Not a bad result.
If we have something more complicated than a linear model, for example, trees, they can also be written as a ClickHouse query. What I've done? Took a selection of irises . This sample is good because you can train a small tree for it with a depth of two. She gets an error of less than 5%. If you are so lucky that you have a good sample, you can use a small tree.
You can write a query, conditionally, in the form of two choice functions, and everything will also work well. Ingredient boosting or wood, for example. It is necessary to calculate the amount or average. I also tested it for a small forest, 100 trees of depth 3, in the end I got the quality even worse, and it works in ClickHouse for 2.5 seconds.
Not everything is so bad, if I trained more trees, the quality would be better. But why did I not do that? That's why.
This is what the third part of the forest looks like on 100 trees. I can see that this is very similar to the forest. And if you make the request even more, then ClickHouse just starts to slow down on parsing.
And got additional drawbacks. In addition to the fact that the query is very long, we have to invent it, and this can slowly work in the database itself. For example, for trees, in order to apply them, ClickHouse is forced to read the value at each node of the tree. And this is inefficient, because we could only calculate the values on the way from the root to the leaf.
There is a problem with performance, something can slow down and work inefficiently. This is not what we want.
We would like simpler things: to tell the database that you yourself will figure out how to apply the model, we just tell you that the machine learning library is here, and you just give me the modelEvaluate function, in which we put our list of signs . Such an approach, firstly, has all the advantages of the previous one, and secondly, it shifts all the work to the database. And all there is one drawback - your base must support the application of these models.
In ClickHouse, we implemented it for CatBoost, of course, we tested it. Received the best quality, despite the fact that I taught ... The training time is not very long, just 4 seconds. This is comparatively good compared to a forest 100 of depth 3.
What can be seen in the end?
If it is important for you to see the speed of work, the speed of burdening the algorithm, the quality is not so important, then you can use logistic regression, this will all work quickly.
If quality is important to you, train CatBoost and use it. How to use CatBoost in ClickHouse?
We need to do some pretty simple steps. The first is to describe the configuration of the model. Only 4 significant lines. Model type - now it's CatBoost, maybe sometime we'll add a new one.
The name of the model that will be used as a parameter to the modelEvaluate () function.
The location of the trained model on the file system.
Update time. Here, 0 means that we will not reread the disc material. If it were 5, they would reread every 5 seconds.
Next you need to tell ClickHouse where the configuration file is located, this is the bottom parameter on the slide. It uses an asterisk, which means that all files that fit this mask will be loaded.
You also need to tell ClickHouse where the machine learning library itself is located, namely the wrapper module for CatBoost.
Everything, when we indicated this, we get the possibility of the modelEvaluate () function, which takes the model name from the configuration file as the first argument, and our attributes for the rest. And you must first specify the numerical characteristics, then categorical. But do not worry if you confuse something. First, ClickHouse will tell you that you have a mistake. Secondly, you can test the quality and understand that everything is not as you thought.
To make it easier to test, we also added support for reading from the CatBoost data pool. Probably, someone worked with CatBoost from the console instead of working with it from Python or from R. Then you would have to use a special format for describing your sample. The format is quite simple - just two files. The first one is TSV with three columns, the sign number and its type: categorical, numerical or target. Plus an optional optional name parameter. The second file is the data itself, also TSV.
Just in ClickHouse, we added a table function atBoostPool, which takes these two files as arguments, and returns a special table of the file type, temporary, from which data can be read.
I created a small CatBoost Pool of three values: two signs and a target. It contains five lines. Two are signs, one is a target, two more are additionally ALIAS.
Also, the numeric and categorical features have been swapped. This is done for convenience so that you can submit the parameters to the playModule function in the correct order.
If we make describe what gives the SELECT * query, then the values become less, only two signs remain in the right order. This is done again so that you can conveniently use the CatBoost Pool, namely, passing an asterisk as the remaining arguments to the moduleEvaluate function.
Let's try to apply something. To begin with, we calculate the probability of a purchase. What will we use? First of all, we will consider from the CatBoost Pool, use the moduleEvaluate function and pass the asterisk to the second parameter.
The last line, the third, the application of sigmoid.
Let's complicate the query, consider the quality. Let's write the previous query as a ClickHouse subquery. In total, we added two significant lines, counting the logloss metrics. Calculated the average, got the value from the table.
I was interested in how quickly such a query works. I spent three tests and got this schedule.
On the left - reading from the table, on the right - from the pool. It can be seen that the columns are almost identical, there is almost no difference, but reading from the ClickHouse table works a little faster - apparently because ClickHouse compresses the data, and we don’t spend too much time reading from the file. And CatBoost Pool does not compress, so we spend time reading and transposing signs. It turns out a little faster, but still it is convenient to use CatBoost Pool for tests.
Let's sum up. The integration is that we can apply trained models, use the CatBoost Pool and read data from it, which is quite convenient. The plans - add the use of other models. Also, the task of training within the database is in question, but so far we have not decided whether to do it. If there are a lot of requests, we will seriously consider this.
We have Russian and English groups in Telegram, where we actively respond, there is a GitHub mailing list . If you have questions, you can send questions to me in the mail , in the Telegram or in the Google group . Thank!
Source: https://habr.com/ru/post/347696/
All Articles