How I made AI to identify fake news with an accuracy of 95% and almost went crazy
A brief retelling: we made a program that determines the reliability of news with an accuracy of 95% (on a validation sample) using machine learning and natural language processing technologies. Download it here . In reality, accuracy may be somewhat lower, especially after some time, as the canons of writing news articles will change.
Looking at the rapid development of machine learning and the processing of natural language, I thought: what the hell is not joking, maybe I will be able to create a model that would reveal news content with inaccurate information, and thus at least a little to smooth out the catastrophic consequences that now spreading fake news .

')
It is possible to argue with this, but, in my opinion, the most difficult stage in creating your own machine learning model is collecting materials for training. When I was teaching a face recognition model , I had to collect photos of each of the NBA league players in the 2017/2018 season for several days. Now I did not even suspect that I would have to spend several agonizing months immersed in this process and face very unpleasant and creepy things that people try to pass off as real news and reliable information.
The first obstacles came as a surprise to me. After studying the fake news sites more closely, I quickly discovered that there are many different categories that may include false information. There are articles with frank lies, there are some that give real facts, but then they are misinterpreted, there are pseudoscientific texts, there are just essays with the author’s opinions disguised as news notes, there is a satire, there are compiler articles consisting mainly of foreign tweets and quotes. I googled a bit and found different classifications in which people tried to break up such sites into groups - “satire”, “fake”, “misleading” and so on.
I decided that we could just as well take them as a basis, and went through the list of sites listed in order to collect examples from there. Almost immediately, a problem arose: some of the sites marked as “fake” or “misleading” actually contained authentic articles. I realized that it would not be possible to collect data from them without checking for trivial errors.
Then I began to ask myself: is it necessary to take into account satire and subjective texts and, if so, where to refer them to reliable materials, fake or in a separate category?
After scoring a week over sites with fake news, I wondered if I was not too complicating the problem. It may be worthwhile to simply take some of the already existing teaching models for the analysis of tonality and try to identify patterns. I decided to make a simple tool that will collect data: headings, descriptions, information about the authors and the text itself, and send them to the model for tonality analysis. For the latter, I used Textbox - it was convenient, because I can run it locally, on my machine, and quickly get results.
The textbox gives an estimate of tonality that can be interpreted as positive or negative. Then I bungled an algorithm that assigned the tonality of each kind of uploaded data (title, authors, text, and so on) to a certain degree of significance, and put the whole system together to see if I could get a general assessment of the news article.
At first, everything seemed to be going well, but after the seventh or eighth loaded article the system began to sink. In general, all this did not even come close to the tool for identifying fake news that I wanted to create.
It was a complete failure.
At this stage, my friend David Hernandez advised me to train the model to independently process the text. In order to do this, we needed as many examples as possible from different categories of texts that, according to our plan, the model would have to be able to recognize.
Since I was already tortured in my attempts to identify patterns in fake sites, we decided to just take and collect data from domains, the category of which we were precisely known in order to quickly gain a base. Literally in a few days, my inferior tool collected a volume of content, which we considered sufficient to train the model.
The result was bad. Having dug our learning materials deeper, we found that they simply could not be accurately packaged in clearly limited categories, as we would like. Somewhere, the fake news was mixed with normal, somewhere there were completely posts from third-party blogs, and some articles were 90% Trump tweets. It became clear that our entire base would have to be processed from scratch.
This is where the fun began.
On one beautiful Saturday, I took up this endless process: manually reviewing each article, determining which category it falls into, and then clumsily copying it into a huge spreadsheet that was becoming increasingly immense. In these articles came across truly disgusting, malicious, racist remarks, to which I initially tried not to pay attention. But after the first few hundred, they began to put pressure on me. Everything was ruffling before my eyes, color perception began to falter, and the state of mind was greatly depressed. How did our civilization come to this? Why are people unable to critically perceive information? Do we still have any hope? So it went on for several more days, while I tried to scrape together enough materials for the model to be meaningful.
I caught myself not already sure what I meant by “fake news”, that I get angry when I see a point of view in which I disagree, and with difficulty resist the temptation to take only what I think true to. In the end, what generally can be considered true and what is not?
But in the end I nevertheless reached the magic number I was aiming for, and with great relief sent the materials to David.
The next day, he again conducted training. I looked forward to the results.
We achieved an accuracy of about 70%. In the first minute it seemed to me that this is an excellent result. But then, having tested the system on spot checks of several random articles from the Network, I realized that no one would really benefit from it.
It was a complete failure.
We return to the stage of drawing on the board. What am I wrong? David suggested that perhaps simplifying the mechanism is the key to higher accuracy. Following his advice, I seriously thought about what problem I'm trying to solve. And then it hit me: maybe the solution is to identify not fake news, but reliable. Reliable news is much easier to bring into a single category. They are based on facts, present them briefly and clearly, and contain a minimum of subjective interpretation. And reliable resources, where you can collect materials, enough for them.
So I returned to the Internet and once again started to collect a new database for training. I decided to distribute materials in two groups: true and untrue. The satirical notes, articles with subjective opinions, fake news and everything else that did not contain strictly factual information and did not fit the standards of the Associated Press were treated as untrue.
It took me a few more weeks. Every day I spent several hours collecting new content from all the sites you can imagine, from The Onion to Reuters . I loaded several thousand examples of true and untrue texts into a giant table, and every day their number increased by several hundred more. Finally, I decided that there was enough material to try again. I sent the table to David and could not wait for the results.
Seeing accuracy above 95%, I almost jumped for joy. So, we still managed to identify patterns in the writing of articles that distinguish reliable news from everything that should not be taken seriously.
It was a success (well, in a sense)!
The whole point of these scams was to prevent the dissemination of false information, so I am very pleased to share the result with you. We called the system Fakebox , and it's very easy to use. You just need to insert the text of the article, which causes you to doubt, and click on the "Ananlyze" button.
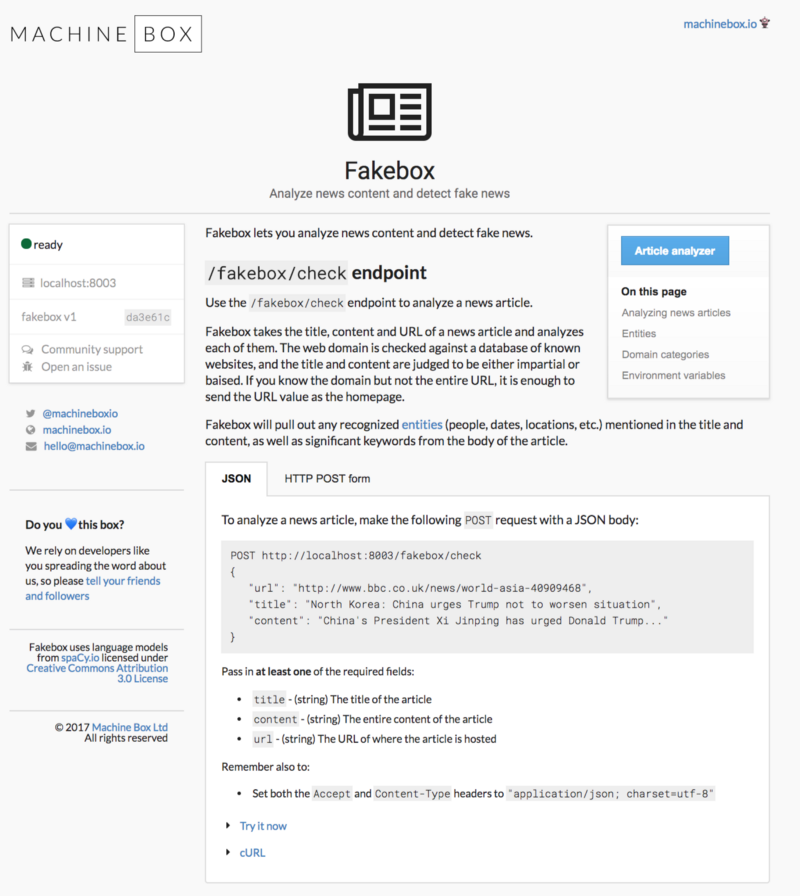
With the REST API, Fakebox can be integrated into any environment. This is a Docker container, so you can deploy and scale it wherever and as you like. Shovel unlimited amounts of content at the speed you need and automatically tag everything that needs your attention.
Remember: the system determines whether the text is written in a language characteristic of a reliable news article. If it gives a very low score, it means that the text is not a fact-based news note in its classic form: it may be misinformation, satire, the author’s subjective opinion or something else.
To summarize, we taught the model to analyze how the text was written and to determine whether it contains evaluative vocabulary, author's judgments, words with emotional coloring, or obscene expressions. It may falter if the text is very short or mainly consists of quotes (or tweets) from other people. Fakebox, of course, will not solve the problem of fake news definitively, but it can help identify those materials that need to be treated with skepticism. Enjoy!
Looking at the rapid development of machine learning and the processing of natural language, I thought: what the hell is not joking, maybe I will be able to create a model that would reveal news content with inaccurate information, and thus at least a little to smooth out the catastrophic consequences that now spreading fake news .
')
It is possible to argue with this, but, in my opinion, the most difficult stage in creating your own machine learning model is collecting materials for training. When I was teaching a face recognition model , I had to collect photos of each of the NBA league players in the 2017/2018 season for several days. Now I did not even suspect that I would have to spend several agonizing months immersed in this process and face very unpleasant and creepy things that people try to pass off as real news and reliable information.
Fake definition
The first obstacles came as a surprise to me. After studying the fake news sites more closely, I quickly discovered that there are many different categories that may include false information. There are articles with frank lies, there are some that give real facts, but then they are misinterpreted, there are pseudoscientific texts, there are just essays with the author’s opinions disguised as news notes, there is a satire, there are compiler articles consisting mainly of foreign tweets and quotes. I googled a bit and found different classifications in which people tried to break up such sites into groups - “satire”, “fake”, “misleading” and so on.
I decided that we could just as well take them as a basis, and went through the list of sites listed in order to collect examples from there. Almost immediately, a problem arose: some of the sites marked as “fake” or “misleading” actually contained authentic articles. I realized that it would not be possible to collect data from them without checking for trivial errors.
Then I began to ask myself: is it necessary to take into account satire and subjective texts and, if so, where to refer them to reliable materials, fake or in a separate category?
Tonality analysis
After scoring a week over sites with fake news, I wondered if I was not too complicating the problem. It may be worthwhile to simply take some of the already existing teaching models for the analysis of tonality and try to identify patterns. I decided to make a simple tool that will collect data: headings, descriptions, information about the authors and the text itself, and send them to the model for tonality analysis. For the latter, I used Textbox - it was convenient, because I can run it locally, on my machine, and quickly get results.
The textbox gives an estimate of tonality that can be interpreted as positive or negative. Then I bungled an algorithm that assigned the tonality of each kind of uploaded data (title, authors, text, and so on) to a certain degree of significance, and put the whole system together to see if I could get a general assessment of the news article.
At first, everything seemed to be going well, but after the seventh or eighth loaded article the system began to sink. In general, all this did not even come close to the tool for identifying fake news that I wanted to create.
It was a complete failure.
Natural language processing
At this stage, my friend David Hernandez advised me to train the model to independently process the text. In order to do this, we needed as many examples as possible from different categories of texts that, according to our plan, the model would have to be able to recognize.
Since I was already tortured in my attempts to identify patterns in fake sites, we decided to just take and collect data from domains, the category of which we were precisely known in order to quickly gain a base. Literally in a few days, my inferior tool collected a volume of content, which we considered sufficient to train the model.
The result was bad. Having dug our learning materials deeper, we found that they simply could not be accurately packaged in clearly limited categories, as we would like. Somewhere, the fake news was mixed with normal, somewhere there were completely posts from third-party blogs, and some articles were 90% Trump tweets. It became clear that our entire base would have to be processed from scratch.
This is where the fun began.
On one beautiful Saturday, I took up this endless process: manually reviewing each article, determining which category it falls into, and then clumsily copying it into a huge spreadsheet that was becoming increasingly immense. In these articles came across truly disgusting, malicious, racist remarks, to which I initially tried not to pay attention. But after the first few hundred, they began to put pressure on me. Everything was ruffling before my eyes, color perception began to falter, and the state of mind was greatly depressed. How did our civilization come to this? Why are people unable to critically perceive information? Do we still have any hope? So it went on for several more days, while I tried to scrape together enough materials for the model to be meaningful.
I caught myself not already sure what I meant by “fake news”, that I get angry when I see a point of view in which I disagree, and with difficulty resist the temptation to take only what I think true to. In the end, what generally can be considered true and what is not?
But in the end I nevertheless reached the magic number I was aiming for, and with great relief sent the materials to David.
The next day, he again conducted training. I looked forward to the results.
We achieved an accuracy of about 70%. In the first minute it seemed to me that this is an excellent result. But then, having tested the system on spot checks of several random articles from the Network, I realized that no one would really benefit from it.
It was a complete failure.
Fakebox
We return to the stage of drawing on the board. What am I wrong? David suggested that perhaps simplifying the mechanism is the key to higher accuracy. Following his advice, I seriously thought about what problem I'm trying to solve. And then it hit me: maybe the solution is to identify not fake news, but reliable. Reliable news is much easier to bring into a single category. They are based on facts, present them briefly and clearly, and contain a minimum of subjective interpretation. And reliable resources, where you can collect materials, enough for them.
So I returned to the Internet and once again started to collect a new database for training. I decided to distribute materials in two groups: true and untrue. The satirical notes, articles with subjective opinions, fake news and everything else that did not contain strictly factual information and did not fit the standards of the Associated Press were treated as untrue.
It took me a few more weeks. Every day I spent several hours collecting new content from all the sites you can imagine, from The Onion to Reuters . I loaded several thousand examples of true and untrue texts into a giant table, and every day their number increased by several hundred more. Finally, I decided that there was enough material to try again. I sent the table to David and could not wait for the results.
Seeing accuracy above 95%, I almost jumped for joy. So, we still managed to identify patterns in the writing of articles that distinguish reliable news from everything that should not be taken seriously.
It was a success (well, in a sense)!
Fake news - fight
The whole point of these scams was to prevent the dissemination of false information, so I am very pleased to share the result with you. We called the system Fakebox , and it's very easy to use. You just need to insert the text of the article, which causes you to doubt, and click on the "Ananlyze" button.
With the REST API, Fakebox can be integrated into any environment. This is a Docker container, so you can deploy and scale it wherever and as you like. Shovel unlimited amounts of content at the speed you need and automatically tag everything that needs your attention.
Remember: the system determines whether the text is written in a language characteristic of a reliable news article. If it gives a very low score, it means that the text is not a fact-based news note in its classic form: it may be misinformation, satire, the author’s subjective opinion or something else.
To summarize, we taught the model to analyze how the text was written and to determine whether it contains evaluative vocabulary, author's judgments, words with emotional coloring, or obscene expressions. It may falter if the text is very short or mainly consists of quotes (or tweets) from other people. Fakebox, of course, will not solve the problem of fake news definitively, but it can help identify those materials that need to be treated with skepticism. Enjoy!
Source: https://habr.com/ru/post/347586/
All Articles