Xception: compact deep neural network
In the past few years, neural networks have made their way into all branches of machine learning, but they have undoubtedly produced the greatest sensation in the field of computer vision. As part of the ImageNet competition, a number of different architectures of convolutional networks were presented, which then diverged across frameworks and libraries.

In order to improve the quality of recognition of their networks, the researchers tried to add more layers to the networks, however, over time, it came to be understood that sometimes performance limitations simply do not allow training and using such deep networks. This was the motivation to use depthwise separable convolutions and create an Xception architecture.
If you want to know what it is, and see how to use such a network in practice to learn how to distinguish cats from dogs, welcome to Cat.
Every time we add another layer to the convolutional network, we need to make a strategic decision about its characteristics. What size of core do we use? 3x3? 5x5? Or maybe put max pooling?

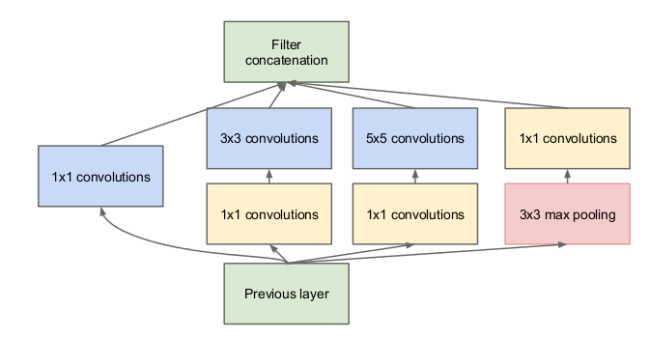
In 2015, the Inception architecture was proposed, the idea of which was as follows: instead of choosing the kernel size, let's take several options at once, use them all at the same time and concatenate the results. However, this significantly increases the number of operations that must be performed to calculate single layer activations, so the authors of the original article propose such a trick: let's make a convolution with a 1x1 core in front of each convolutional block, reducing the dimension of the signal that goes to the input of convolutions with larger core sizes .
The resulting construction in the figure below constitutes the complete Inception module.
But what does this have to do with making our network more compact?
In 2016, François Chollet, the author and developer of the Keras framework, published an article in which he suggested going further and using the so-called Extreme Inception module, also known as depthwise separable convolution.
')
Imagine we took a standard convolutional layer with filters of size 3x3, to the input of which the dimension tensor is supplied where Is the width and height of the tensor, and - number of channels.
What does this layer do? It collapses all the channels of the original signal at the same time. different bundles. At the exit of such a layer, a dimension tensor is obtained. .
Let's take two steps in succession instead:

Let's look at a specific example. Let we collapse the image with 16 channels with a convolution layer with 32 filters. In total, this convolutional layer will have weights as we will have 3x3 bundle.
How many scales will there be in a similar depthwise separable convolution block? First, we will have weights have pointwise convolution. Secondly, we will have scales at depthwise convolution. In total, we get 800 weights, which is much smaller than that of the ordinary convolutional layer.
A regular convolutional layer simultaneously processes both spatial information (the correlation of neighboring points within one channel) and inter-channel information, since the convolution is applied to all channels at once. The Xception architecture is based on the assumption that these two types of information can be processed sequentially without losing network quality, and decomposes the usual convolution into pointwise convolution (which only processes inter-channel correlation) and spatial convolution (which only processes spatial correlation within a single channel) .
Let's look at the real effect. For comparison, let's take two truly deep convolutional network architectures - ResNet50 and InceptionResNetV2.
The ResNet50 has 25,636,712 weights, and the pre-trained model in Keras weighs 99 MB. The accuracy that this model achieves on ImageNet dataset is 75.9%.
InceptionResNetV2 has 55,873,736 learning parameters and weighs 215 MB, reaching an accuracy of 80.4%.
What happens with the Xception architecture? The network has 22,910,480 weights and weighs 88 MB. The accuracy of classification on ImageNet is 79%.
Thus, we get the network architecture, which exceeds ResNet50 in accuracy and only slightly inferior to InceptionResNetV2, while significantly gaining in size , and therefore the required resources both for training and for using this model.
Let us analyze with a short example how to apply this architecture to a real task. For these purposes, we will take Dogs vs Cats with Kaggle and in half an hour we will teach our network to distinguish cats from dogs.
Let's break the data into three parts: train (4000 images), validation (2000 images) and test (10,000 images).

Since Francois Chollet, the author of the Xception architecture, is also the creator of Keras, he kindly provided the weights of this network, trained on ImageNet, in his framework, which we will use to finish the network under our task using transfer learning.
Load the weights from ImageNet into Xception, from which the last fully connected layers are removed. Run our dataset through this network to get the signs that the convolutional network can extract from the images (the so-called bottleneck features):
Create a fully meshed network and train it on features derived from convolutional layers, using the specially deferred part of the initial data set for validation:
Already after this stage, which takes a couple of minutes on the GeForce GTX 1060 video card, we get accuracy of about 99.4% on the validation dataset.
Now we will try to train the network with augmentation of the input data, loading weights into the convolutional layers from ImageNet, and into fully connected layers - weights that our network has just learned:
Having trained the network in this mode, for another five epochs (about twenty minutes), we will achieve an accuracy of 99.5% on validation data.
Checking the model on the data that she has never seen, and which were not used to set up hyper parameters (test dataset), we see an accuracy of about 96.9%, which looks quite acceptable.

The complete code for this experiment can be found on GitHub .
In 2017, Google added pre-trained networks of the MobileNet architecture to TensorFlow , using principles similar to Xception to make models even smaller. These models are suitable for performing computer vision tasks directly on mobile phones or IoT devices, which have extremely limited memory reserves and a weak processor.
Thus, we quietly came to the point in the history of computer science, when you write an application that determines whether a bird is depicted in the photo, it can be done in fifteen minutes, and this application will run directly on your smartphone.
In order to improve the quality of recognition of their networks, the researchers tried to add more layers to the networks, however, over time, it came to be understood that sometimes performance limitations simply do not allow training and using such deep networks. This was the motivation to use depthwise separable convolutions and create an Xception architecture.
If you want to know what it is, and see how to use such a network in practice to learn how to distinguish cats from dogs, welcome to Cat.
Inception module
Every time we add another layer to the convolutional network, we need to make a strategic decision about its characteristics. What size of core do we use? 3x3? 5x5? Or maybe put max pooling?
In 2015, the Inception architecture was proposed, the idea of which was as follows: instead of choosing the kernel size, let's take several options at once, use them all at the same time and concatenate the results. However, this significantly increases the number of operations that must be performed to calculate single layer activations, so the authors of the original article propose such a trick: let's make a convolution with a 1x1 core in front of each convolutional block, reducing the dimension of the signal that goes to the input of convolutions with larger core sizes .
The resulting construction in the figure below constitutes the complete Inception module.
But what does this have to do with making our network more compact?
In 2016, François Chollet, the author and developer of the Keras framework, published an article in which he suggested going further and using the so-called Extreme Inception module, also known as depthwise separable convolution.
')
Depthwise separable convolution
Imagine we took a standard convolutional layer with filters of size 3x3, to the input of which the dimension tensor is supplied where Is the width and height of the tensor, and - number of channels.
What does this layer do? It collapses all the channels of the original signal at the same time. different bundles. At the exit of such a layer, a dimension tensor is obtained. .
Let's take two steps in succession instead:
- We fold the original 1x1 tensor by convolution, just as we did in the Inception block, getting the tensor . This operation is called pointwise convolution.
- We turn each channel separately 3x3 convolutions (in this case, the dimension will not change, since we are not turning all the channels together, as in the usual convolutional layer). This operation is called depthwise spatial convolution
A little tricks on terminology.
In fact, usually when it comes to depthwise separable convolution, it is implied that they first do the convolution through the channels, and then the 1x1 convolution, but I give exactly the order of operations that is specified in the original article. In general, according to the author, the order of these operations does not affect the final result.
Why does this make the network more compact?
Let's look at a specific example. Let we collapse the image with 16 channels with a convolution layer with 32 filters. In total, this convolutional layer will have weights as we will have 3x3 bundle.
How many scales will there be in a similar depthwise separable convolution block? First, we will have weights have pointwise convolution. Secondly, we will have scales at depthwise convolution. In total, we get 800 weights, which is much smaller than that of the ordinary convolutional layer.
Why does this even work?
A regular convolutional layer simultaneously processes both spatial information (the correlation of neighboring points within one channel) and inter-channel information, since the convolution is applied to all channels at once. The Xception architecture is based on the assumption that these two types of information can be processed sequentially without losing network quality, and decomposes the usual convolution into pointwise convolution (which only processes inter-channel correlation) and spatial convolution (which only processes spatial correlation within a single channel) .
Let's look at the real effect. For comparison, let's take two truly deep convolutional network architectures - ResNet50 and InceptionResNetV2.
The ResNet50 has 25,636,712 weights, and the pre-trained model in Keras weighs 99 MB. The accuracy that this model achieves on ImageNet dataset is 75.9%.
InceptionResNetV2 has 55,873,736 learning parameters and weighs 215 MB, reaching an accuracy of 80.4%.
What happens with the Xception architecture? The network has 22,910,480 weights and weighs 88 MB. The accuracy of classification on ImageNet is 79%.
Thus, we get the network architecture, which exceeds ResNet50 in accuracy and only slightly inferior to InceptionResNetV2, while significantly gaining in size , and therefore the required resources both for training and for using this model.
Less words, more code
Let us analyze with a short example how to apply this architecture to a real task. For these purposes, we will take Dogs vs Cats with Kaggle and in half an hour we will teach our network to distinguish cats from dogs.
Let's break the data into three parts: train (4000 images), validation (2000 images) and test (10,000 images).
Since Francois Chollet, the author of the Xception architecture, is also the creator of Keras, he kindly provided the weights of this network, trained on ImageNet, in his framework, which we will use to finish the network under our task using transfer learning.
Load the weights from ImageNet into Xception, from which the last fully connected layers are removed. Run our dataset through this network to get the signs that the convolutional network can extract from the images (the so-called bottleneck features):
input_tensor = Input(shape=(img_height,img_width,3)) base_model = xception.Xception(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg') data_generator = image.ImageDataGenerator(rescale=1. / 255) train_generator = data_generator.flow_from_directory( train_data_dir, target_size=(img_height, img_width), batch_size=batch_size, class_mode=None, shuffle=False) bottleneck_features_train = base_model.predict_generator( train_generator, nb_train_samples // batch_size) np.save(open('bottleneck_features_train.npy', 'wb'), bottleneck_features_train) Create a fully meshed network and train it on features derived from convolutional layers, using the specially deferred part of the initial data set for validation:
model = Sequential() model.add(Dense(256, activation='relu', input_shape=base_model.output_shape[1:])) model.add(Dropout(0.5)) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=SGD(lr=0.01), loss='binary_crossentropy', metrics=['accuracy']) checkpointer = ModelCheckpoint(filepath='top-weights.hdf5', verbose=1, save_best_only=True) history = model.fit(train_data, train_labels, epochs=epochs, batch_size=batch_size, callbacks=[checkpointer], validation_data=(validation_data, validation_labels)) Already after this stage, which takes a couple of minutes on the GeForce GTX 1060 video card, we get accuracy of about 99.4% on the validation dataset.
Now we will try to train the network with augmentation of the input data, loading weights into the convolutional layers from ImageNet, and into fully connected layers - weights that our network has just learned:
input_tensor = Input(shape=(img_height,img_width,3)) base_model = xception.Xception(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg') top_model = Sequential() top_model.add(Dense(256, activation='relu', input_shape=base_model.output_shape[1:])) top_model.add(Dropout(0.5)) top_model.add(Dense(128, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(1, activation='sigmoid')) top_model.load_weights('top-weights.hdf5') model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) model.compile(optimizer=SGD(lr=0.005, momentum=0.1, nesterov=True), loss='binary_crossentropy', metrics=['accuracy']) Having trained the network in this mode, for another five epochs (about twenty minutes), we will achieve an accuracy of 99.5% on validation data.
Checking the model on the data that she has never seen, and which were not used to set up hyper parameters (test dataset), we see an accuracy of about 96.9%, which looks quite acceptable.
The complete code for this experiment can be found on GitHub .
What's next?
In 2017, Google added pre-trained networks of the MobileNet architecture to TensorFlow , using principles similar to Xception to make models even smaller. These models are suitable for performing computer vision tasks directly on mobile phones or IoT devices, which have extremely limited memory reserves and a weak processor.
Thus, we quietly came to the point in the history of computer science, when you write an application that determines whether a bird is depicted in the photo, it can be done in fifteen minutes, and this application will run directly on your smartphone.
Source: https://habr.com/ru/post/347564/
All Articles