Major advances in natural language processing in 2017
Hello. Immediately divide the audience into two parts - those who like to watch the video, and those who, like me, better perceive the texts. In order not to torment the first ones, the recording of my speech on Date-Elk:
There are all the main points, but the presentation format does not imply a detailed review of the articles. Fans of links and detailed analysis, welcome under cat.
Those who have read this far can finally find out that everything written below can be used against them in court is solely my point of view, and other people's points of view can differ from mine.
Trends
In 2017, the year in the development of our field (natural language processing, NLP), I highlight two main trends:
- acceleration and parallelization - all models strive to accelerate, including at the expense of greater parallelism;
- learning without a teacher - approaches with learning without a teacher have long been popular in computer vision, but are relatively rare in NLP (perhaps word22c is a rare but vivid example of the use of these ideas); This year, the use of such approaches has become very popular.
Now we will examine in more detail the main ideas of this year.
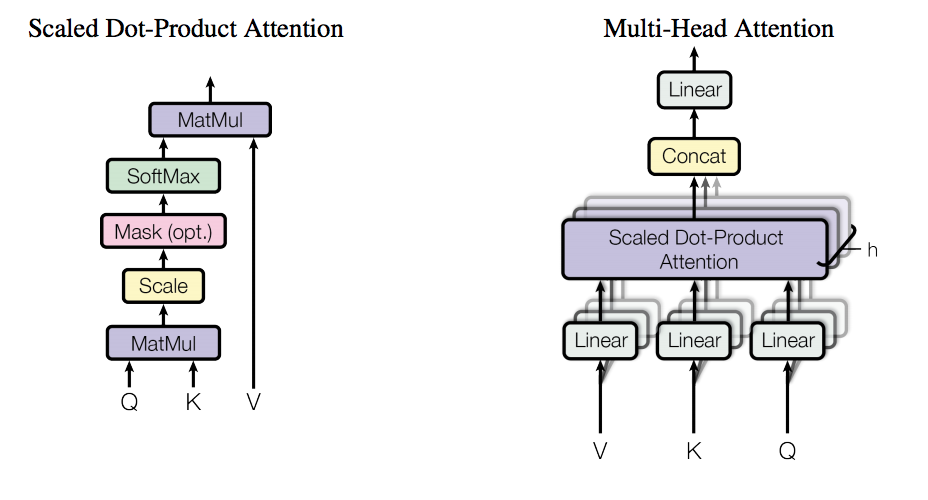
Attention Is All You Need

This already well-known work marks the second coming of fully connected networks in the NLP domain. Its authors are Google employees (by the way, one of the authors, Ilya Polosukhin, will speak at our hackathon DeepHack.Babel ). The idea behind the Transformer architecture (exactly it is shown in the picture) is as simple as all ingenious: let's forget about recurrence and all this and just use attention to achieve a result.
But first, let's remember that all current advanced machine translation systems work on recurrent networks. Intuitively recurrent neural networks should be well suited for natural language processing tasks, including machine translation, because they have an explicit memory used in the process of working. This feature of the architecture has obvious advantages, but also its inseparable disadvantages: since we use memory to work with data, we can process them only in a specific sequence. As a result, full data processing can take a lot of time (compared to, for example, CNN). And this is exactly what the authors wanted to compete with.
And now Transformer is an architecture for machine translation that has no recurrence. And only the attention that does all the work.
Let's first recall what the standard approach to attention offered by Dmitry Bogdanov (Dzmitry Bahdanau) looks like.
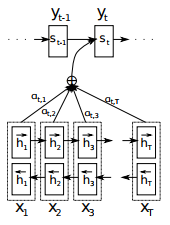
The idea of the attentional mechanism is that we need to focus on some relevant input to the encoder in order to produce better decoding. In the simplest case, relevance is defined as the similarity of each input to the current output. This similarity is determined in turn as the sum of the inputs with weights, where the weights are summed to 1, and the largest weight corresponds to the most relevant input.
The picture above shows the classical approach of authorship of Dmitry Bogdanov: we have one set of inputs - the hidden state of the encoder (h), as well as the set of coefficients for these inputs (a). These coefficients are calculated each time, based on some other input that is different from the hidden states.
In contrast to the classical approach, the authors of this work proposed the so-called self-attention on the input data. The word "self" in this case means that attention is applied to the same data on which it is calculated. At the same time, in the classical approach, attention is computed from some additional input relative to the data to which it is applied.
Moreover, this self-attention is called Multi-Head , because performs one operation several times in parallel. This feature may remind convolutional filters, since each of the "heads" looks at different places in the input sequence. Another important feature is that in this version attention takes three entities as input, rather than two, as in the standard approach. As you can see in the picture above, the "sub-attention" is first calculated on the Q (request) and K (key) inputs, and then the sub-attention output is combined with the V (value) from the input. This feature refers us to the concept of memory, a variation of which is the mechanism of attention.
In addition to the most important, there are two more significant features:
- positional encoding ,
- masked attention for the decoder ( masked attention ).
Positional encoding - as we remember, the entire architecture of the model is a fully connected network, so the very concept of a sequence inside the network is not embedded. To add knowledge about the existence of sequences, positional encoding has been proposed. As for me, the use of trigonometric functions (sin and cos), which creates positional encoding, seems to be a completely non-obvious choice, but it works: the position encoding vector combined with the word vector (for example, with the word2vec mentioned above) delivers knowledge of the meaning of the word and its relative position in the sequence in the network.
Masked attention is a simple but important feature: again, because there is no concept of sequences in the network, we need to somehow filter the network's representations of the following words that are not available during decoding. So, as you can see in the picture, we insert a mask that "closes" words that the network should not yet see.
All these features allow the network to not only work, but even improve the current results of machine translation.
Parallel Decoder for Neural Machine Translation
The last of the described features of the architecture did not suit the authors of the following work , the staff of Richard Soher's group (Richard Socher) from Salesforce Research (by the way, one of the employees, Romain Paulus, the author of another well-known work on summatrization , will also perform on our Hackathon DeepHack .Babel ). The masked attention for the decoder was not fast enough for them compared to a fast parallel encoder, so they decided to take the next step: "Why not make a parallel decoder if we already have a parallel encoder?" This is my guess, but I am ready to guarantee that the authors of this work had some similar thoughts in their heads. And they found a way to carry out their plans.

They called it Non-Autoregressive Decoding, the entire Non-Autoregressive Transformer architecture, which means that now no word depended on another when decoding. This is some exaggeration, but not such a big one. The idea is that the encoder here will additionally produce a so-called fertility rate for each input word. This level of fertility is used to generate the translation itself for each word, based only on the word itself. You can look at this as an analogue of the standard correspondence matrix in machine translation (alignment matrix):

As you can see, some of the words correspond to several words, and some do not correspond to any specific word of another language. Thus, the fertility rate simply cuts this matrix into pieces, where each piece refers to a specific word of the source language.
So, we have a fertility level, but this is not enough for fully parallel decoding. You can notice in the picture a few additional levels of attention - positional attention (which correlates with positional encoding) and inter-attention (which replaced the masked attention from the original work).
Unfortunately, giving a serious gain in speed (8 times in some cases), the Non-Autoregressive Decoder gives quality by several BLEU units worse than the original. But this is a reason to look for ways to improve!
Unsupervised Machine Translation
The next part of the article is devoted to a task that seemed impossible a few years ago: machine translation, trained without a teacher. Works that we will discuss:
- Unsupervised Neural Machine Translation
- Unsupervised Machine Translation Using Monolingual Corpora Only
- Style-Transfer from Non-Parallel Text by Cross-Alignment
The last work, judging by the name, is superfluous in this series, but as they say, the first impression is deceptive. All three works have a common idea at the base. In a nutshell, it can be stated as follows: we have two auto-encoders for two different text sources (for example, different languages, or texts of different styles), and we simply swap the decoding parts of these auto-encoders. How it works? Let's try to figure it out.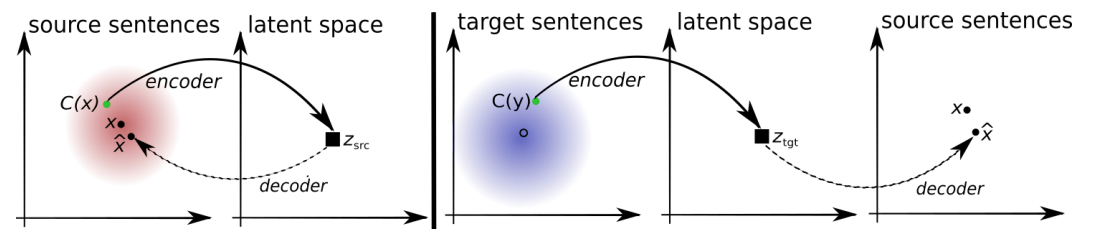
The autocoder (on the left in the picture above) is the encoder decoder (encoder-decoder), where the decoder decodes back to the original space. This means that the input and output belong to the same language (or style). Thus, we have some text and train the encoder to make a vector representation of this text so that the decoder can reconstruct the original sentence. Ideally, the reconstructed sentence would be exactly the same. But in most cases this is not the case, and we need to somehow measure the similarity of the original and reconstructed sentences. And for machine translation, such a measure was invented. This is the standard metric now called BLEU.
- BLEU - this metric measures how many words and n-grams (n consecutive words) overlap between a given translation and some reference, previously known translation. The most commonly used version is BLUE, which is called BLUE-4, which works with words and phrases of length from 2 to 4. Additionally, a penalty for a too short translation (relative to the reference one) is introduced.
As you might have guessed, this metric is not differentiable, so we need some other way to train our translator. For an autocoder, this may be standard cross-entropy, but this is not enough for translation. For now, let’s skip it and continue.
OK, now we have a way to build our autoencoder. The next thing we have to do is train them a couple: one for the source language (style) and the other for the target language. And we also need to cross them so that the decoder of the target language can “recover” the encoded strings of the source language, and vice versa, which in this case is all the same.
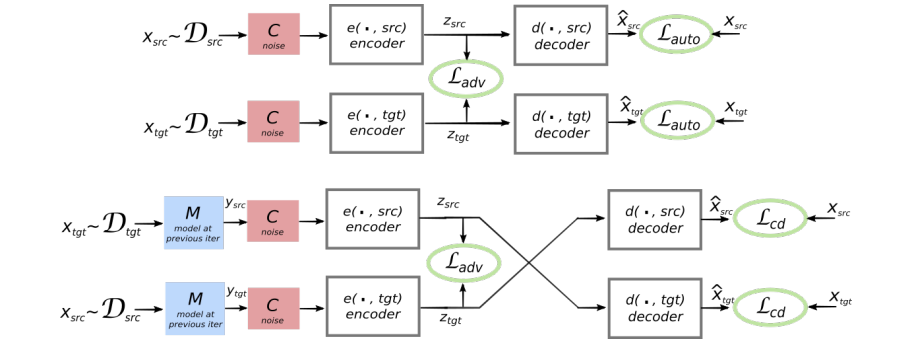
Now it will be the most difficult to understand: in the auto-encoder (or any other encoder-decoder) in the middle there is the so-called hidden representation - a vector from a certain space of high dimensionality. If we want two auto-encoders to be compatible (in the sense that we need), we must ensure that the hidden representation is from the same space. How to achieve this? By adding an extra penalty for these autocoders. This penalty is imposed by the discriminator, which refers us to the GAN concept.
- GAN - Generative Adversarial Network. The idea of GAN can be expressed as "the network plays with itself and tries to deceive itself." The GAN architecture has three main components: a generator — it produces performances that should be as real as possible, the Golden Source gives real performances, and a discriminator — it must distinguish the input from which it came from, the generator or the Golden Source; the generator is punished if the discriminator can guess it. But the opposite is also true - the discriminator is punished if he cannot guess. In this way they train together in competition among themselves.
In our case, the discriminator (L_adv in the picture) should say where the input came from — from the source language or the target language. The picture above shows two auto-encoders in the form of separate blocks - encoders and decoders. In the middle there is a connection between them, where the discriminator is located. By training two auto-encoders with such an additional penalty, we force the model to make hidden views for both auto-encoders similar (upper part of the picture), and then everything is clear - just replace the original decoder with its counterpart from another auto-encoder (lower part of the picture) and voila - our model can transfer!
All three works mentioned in this section have this idea basically, of course, with their own peculiarities. The explanation above is mostly based on the work of Unsupervised Machine Translation Using Monolingual Corpora Only , so I should mention the previous work of these authors, especially since its results are used in the discussed work above:
The idea of this work is as simple as all ingenious:
Let's say we have vector representations for the words of two different languages. (Suppose we work with texts from one domain, for example, news or fiction.) We can reasonably assume that the dictionaries for these languages will be very close: for most of the words from the source case, we can find matches to the words of the target case. for example, words denoting concepts, president, ecology, and taxes will most likely be in newsrooms in both languages. So why not just link these words together and pull one vector space onto another? Actually, they did. Found a function that converts vector spaces and imposes points of one (word) on the points of another. In this paper, the authors showed that this can be done without a teacher, which means that they do not need a dictionary as such.
The work of Style-Transfer from Non-Parallel Text by Cross-Alignment is placed in this section, because Languages can be considered as different styles of text, and the authors themselves mention this in their work. Also this work is interesting because implementation is available to it.
Controllable Text Generation
This section is close in spirit to the previous one, but still quite significantly different. Works that will be reviewed here:
The first work presents a different approach to transferring style to texts, which is closer to controlled generation, so this work is placed here, unlike the previous one. The idea of controlled generation can be illustrated with the following picture: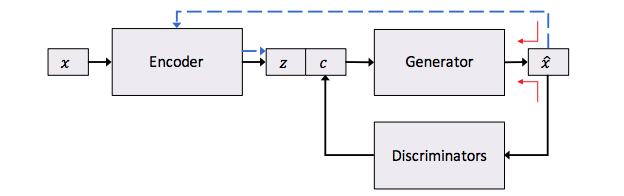
Here we again see the auto-encoder in the text, but it has a feature: the hidden view (which is responsible for the meaning here) is additionally enriched with special features. These signs encode specific properties of the text, such as tonality or grammatical time.
In the picture you can also notice the discriminator in addition to the auto-encoder. There may be more than one discriminator if we want to encode more specific properties. As a result, we have a complex loss function - a reconstruction loss from an auto-encoder and an additional penalty for specific text properties. Thus, the reconstruction loss here is responsible only and exclusively for the meaning of the proposal, without other properties.
Simple Recurrent Unit
Last but not the least important section. It also focuses on computation speed. Despite the fact that at the beginning of the article we discussed the shock of the basics in the form of the return of fully connected networks, nevertheless all modern systems in NLP work on recurrent networks. And everyone knows that RNN is much slower than CNN. Or not? To answer this question, let's consider the following article:
I think the authors of this paper tried to answer the question: why are the RNNs so slow? What makes them so? And they found the key to the solution: RNN - consistent in nature. But what if you can leave only a small piece of this consistent nature, and do everything else in parallel? Let's assume that (almost) everything does not depend on its previous state. Then we can process the entire sequence of inputs in parallel. So the task is to throw out all unnecessary dependencies on previous states. And this is what led to it:
As you can see, only the last two equations depend on the previous state. And in these two equations, we work with vectors, not matrices. And all the heavy calculations can be done independently and in parallel. And then we just do some multiplications to process the data sequentially. This formulation showed excellent results, see for yourself: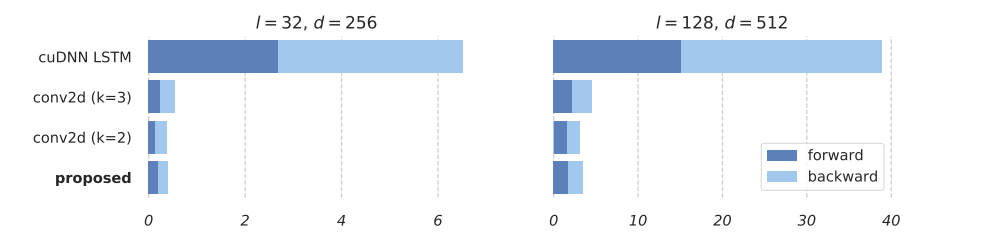
The Simple Recurrent Unit (SRU) speed is almost the same as that of CNN!
Conclusion
In 2017, new strong players, such as Transformer, appeared in our region, and breakthroughs were made like working machine translation without a teacher, but the old people do not give up - SRU will still stand up for the honor of RNN in this fight. So I look to the 2018th with the hope of new breakthroughs, which I still can not imagine.
')
Source: https://habr.com/ru/post/347524/
All Articles