Death of microservice madness in 2018
Note trans. : This material, written by an experienced developer, is not intended to bury the idea of microservices, as you might think, looking at the title. The article is a reasonable warning for those who decided that microservices are a “silver bullet”, which in itself solves all architectural and operational problems. To demonstrate this, the author has collected and systematized popular problems that are often found in today's projects that already use microservices or migrate to them.

In recent years, microservices have become a very popular topic. "Microservice madness" looks like this:
')
There are a lot of cases when significant efforts were made to introduce microservice patterns without necessarily understanding what disadvantages and advantages this will lead to in the context of the specific problem being solved.
I will tell in detail about what microservices are, why their pattern is so attractive and what are some of the main difficulties in the way of their use. I will finish with simple questions that you should ask yourself when the relevance of the microservice pattern for your needs is considered. These questions are presented at the end of the article.
Let's start with the basics. Here is an example of a possible implementation of a hypothetical video sharing platform: first in a monolithic representation (one large block), and then in a microservice.
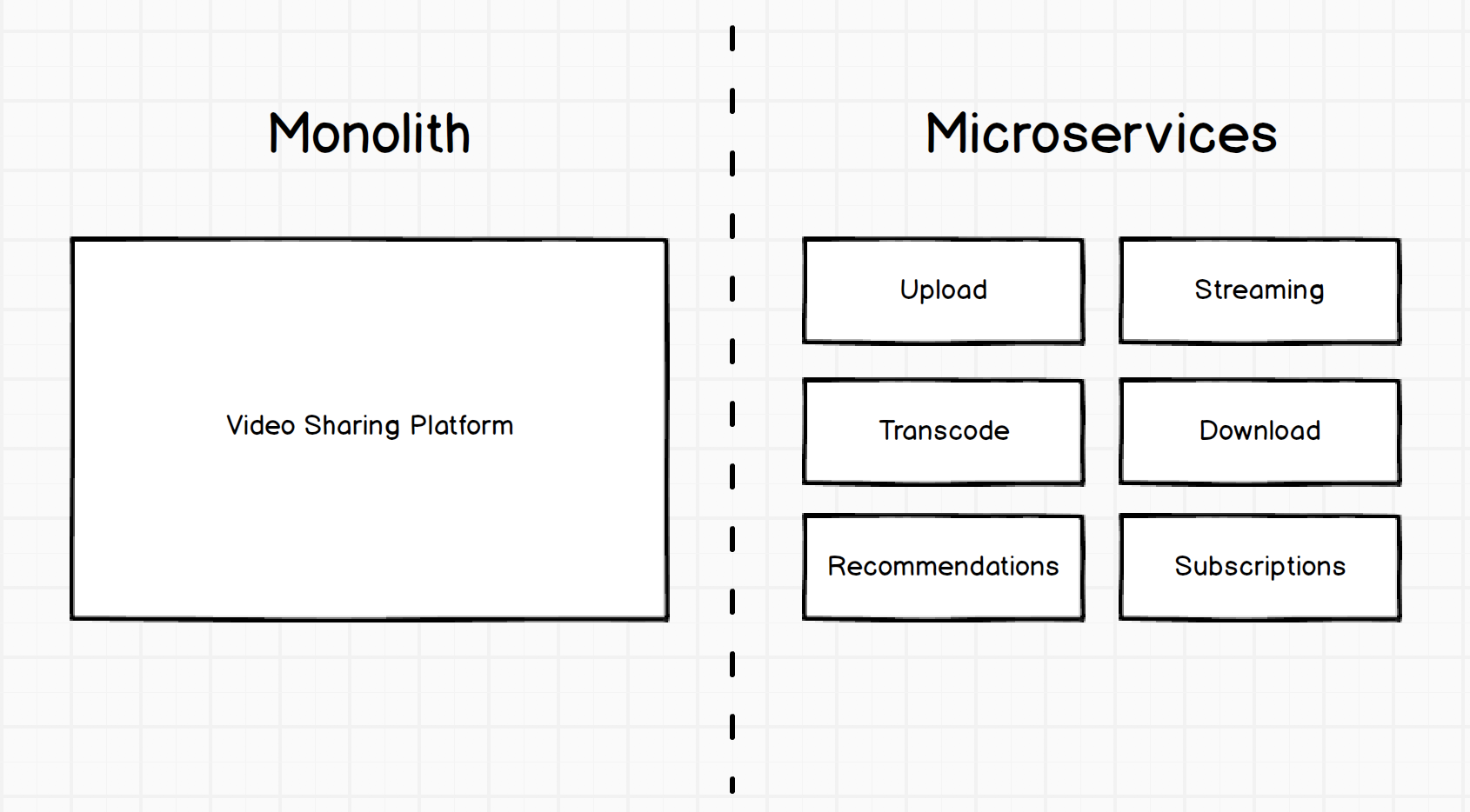
The difference between these two systems is that the first is a single large block, i.e. monolith. The second is a set of small specific services. Each service has its own specific role.
When the scheme is presented at this level of detail, it is easy to see its appeal. There is a whole set of potential advantages:
Independent development . Small independent components can be created by small independent teams. The group can work on changes in the Upload service without affecting the Transcode service or even knowing about it. The amount of time required to study a component is significantly reduced, and it becomes easier to develop new functions.
Independent deployment . Every single component can be deployed independently. This allows you to release new features quickly and with less risk. Corrections or features for the Streaming component can be deployed without the need to add other components.
Independent scalability . Each component can be scaled independently of the other. In times of increased user demand, when new broadcasts come out, the Download component can be scaled for increased load without the need to scale each component, which makes scaling flexible and reduces costs.
Reusability . Components realize their small specific function. This means that it is easier to adapt them for use in other systems, services or products. The Transcode component can be used by other business units or even turned into a new business offering transcoding services to a different audience.
At this level of detail, the advantages of the microservice model over the monolithic seem obvious. If so, then why did the pattern come into fashion only now? Where has he been all my life?
There are two answers to this question. The first - actually did , to the best of technical capabilities. Second - recent technological improvements have allowed us to reach a new level in this approach.
When I started preparing an answer to this question, I got a long description, so I’ll better highlight it in a separate article and post it a little later. Here, the path from one program to the set, ESB (enterprise service bus, i.e. "enterprise service bus" - approx. Transl.) And SOA (service-oriented architecture, i.e. "service-oriented architecture" ) will be omitted . - approx. Transl. , Component design and bounded contexts ("limited context" - pattern from Domain-Driven Design - approx. Transl.) , Etc.
Instead, I’ll write that in many ways we’ve done it all for a while, but only with the recent explosive growth of container technologies (especially Docker) and orchestration technologies (such as Kubernetes, Mesos, Consul, etc.) the pattern has become much more expedient to implement from a technical point of view.
If we take for granted the possibility of implementing a microservice approach, it is necessary to carefully consider the need . We saw high-level theoretical advantages, but what about the difficulties?
If microservices are so beautiful, what's the matter? Here are some of the most significant problems that I have seen.
Developing life can be much harder. If a developer wants to work on features that affect many [journey] services, he will have to run all of them on his machine and connect to them. This is often more difficult than just running one program.
This complexity can be partially alleviated with the help of appropriate tools [tooling] , but the greater the number of services that make up the system, the more difficulties developers will have when starting the system as a whole.
For teams that do not develop services, but support them, there will be an explosion in potential complexity. Instead of managing several running services, they will have to work with tens, hundreds, or thousands. More services, more ways to interact and more opportunities for potential problems.
Looking at the two previous points, it may seem - especially because of the popularity of DevOps as a practice (of which I am a big supporter) - that exploitation and development are considered separately. So, isn’t it getting better thanks to DevOps?
The difficulty is that many organizations still have separate development and operation teams, and in such cases they are likely to have a hard time adapting microservices.
For organizations already using DevOps, this is also not so simple. Being at the same time a developer and a sysadmin is already difficult (but critical for creating good software), and with the need to also understand the nuances of container orchestration systems and, in particular, systems that are rapidly evolving, even harder. So I come to the next item.
The results can be great if the work was done by experts. But imagine an organization in which not everything is perfect with the work of a single monolithic system. Why, with an increase in the number of systems, which complicates the operation, the situation will become better?
Yes, with efficient automation, monitoring, orchestration, etc. - all this is possible. However, complexity is rarely a technology - usually this is a search for people who can use it effectively. The demand for such skills is huge now, and finding them is not easy.
In all the examples used to describe the benefits of microservices, it was about independent components. However, in many cases, the components are not simply independent. If on paper certain areas may look related, then in reality, when you get to the bottom of all the details, it is easy to find that everything is much more complicated than in the intended model.
This is where everything becomes very complicated. If the boundaries are not really well defined, it will happen that - even in the case of the theoretical possibility of an isolated deployment of services - interdependencies will emerge between the services, due to which the sets of services will have to be deployed as a group.
In turn, this means that it is necessary to maintain consistent versions of services that have been tested and tested in working with each other. It turns out that there is actually no system, parts of which can be deployed independently, because deploying a new feature will have to carefully manage the deployment of multiple services.
In the previous example, the occasional need for a simultaneous rollout of multiple versions of multiple services during a delay feature is mentioned. I would like to say that thoughtful deployment techniques will make life easier: for example, blue-green deployments (require minimal effort on most platforms for service orchestration) or parallel launch of multiple versions of a service with the possibility of choosing the right one on the side of their user.
These techniques remove many obstacles if the services are stateless. But working with stateless services is actually quite simple. Actually, if you have stateless-services, I recommend thinking about skipping all these microservices and using the serverless model.
In reality, many services need to store the state. An example for a video sharing platform is a subscription service. Let the new version of the subscription service stores data in the database of a new type. If both services are running in parallel, then you have a system that simultaneously uses two schemes. If you make a blue-green patch, and other services depend on data in a new form, they need to be updated at the same time. If the subscription service has failed and is rolled back, then most likely it is necessary to roll back these services too, and then “by the cascade”.
Again, it is tempting to think that such schema-related problems will go away with databases from the world of NoSQL, but this is not the case. Databases that do not require strict schemas do not mean that the system does not have schemas, because in essence it simply means the need to manage the schema at the application level, not at the DBMS level. It is impossible to eradicate the fundamental problem of understanding the type of your data and how it changes.
Since you are creating a large network of services dependent on each other, a large field for interservice interaction is likely to appear. There are a number of difficulties. First, there are more places for potential failures. It is necessary to foresee the possibility that network calls will not work, that is, each time one service accesses another, it must at least try to repeat its attempts. When the service needs to address a variety of services, the situation will become more complicated.
Imagine that a user uploads a video to a sharing service. We need to start the download service, transfer the data to the transcoding service, update the subscriptions, update the recommendations, and so on. All of these challenges require a certain orchestration, and if something breaks, the action must be repeated.
Repeat calls can be difficult to manage. Attempts to do everything synchronously often become untenable, because they have too many points of failure. In this case, a more reliable solution will be the use of asynchronous interaction patterns. But the difficulty lies in the fact that due to asynchronous patterns, the system becomes stateful. And as already mentioned in the last paragraph, it is very difficult to manage stateful-systems and systems with distributed states.
When a message queue for inter-service communication is used in a microservice system, you basically have a large database (message queue or broker) that sticks together all the services. Again, even though all this does not seem to be a problem at first, the circuit will catch up with you and remind you of yourself. Service version X can write messages in a specific format, so services that depend on such a message also need to be updated when the sender service changes something in its message.
You can have services that process messages in many different formats, but they are difficult to manage. When deploying new versions of services, it will happen that two versions of the service will try to process messages from the same queue and, possibly, even from the sending services of different versions too. This can lead to confusing, inadequate situations. It may turn out that in order to avoid them it is easier to allow only certain versions of messages to exist: this means that you have to deploy consistent sets of versions for sets of services, ensuring that messages of old versions are processed appropriately (first).
This again confirms the idea that, if we go into details, independent deployments do not always work as intended.
To overcome the mentioned obstacles, it is necessary to manage versions very carefully. Again, there is a tendency to believe that following a standard like semver will solve the problem. This is not true. Semver is an agreement that is advisable to use, but you still have to keep track of the versions of services and APIs that can interact.
Very quickly, you can come to significant difficulties and find yourself in a situation where you do not know which versions of the services actually work correctly with each other.
It is well known how hard it is to manage dependencies in software systems, whether they are modules for Node or Java, libraries for C, etc. It is very difficult to deal with the problems of conflicts of independent components used by one entity.
It is difficult to cope with these problems when dependencies are static and can be patched, updated, edited, and so on. If the working services serve as dependencies, it will not be possible to simply update them: you need to run several versions (with the problems described above) or pause the system until everything is completely fixed.
In situations where transactional integrity is required during operation, microservices can be a big pain. It’s not easy to work with a distributed state, and the multitude of small components that can break make transaction orchestration really hard.
It may seem attractive to try to avoid problems by making the operations idempotent, suggesting retry mechanisms, etc. - and in many cases it will work. However, there may be scenarios in which a successful or unsuccessful transaction is simply needed, without an intermediate state. The complexity of the workaround for this task or its implementation in the microservice model can be very high.
Yes, individual services and components can be deployed in isolation, but in most cases some kind of orchestration platform like Kubernetes will be launched. If you use a managed service like GKE from Google or EKS from Amazon, most of the cluster management has been solved for you.
However, if you manage the cluster yourself, then you are working with a large, complex and critical system. Although individual services may have all the advantages described above, it is necessary to manage the cluster very thoughtfully. Deploying such a system can be tricky, upgrades are tricky, failover is tricky, and so on.
In many cases, the overall benefits remain, but it is important not to simplify or underestimate the additional complexity caused by managing another large and complex system. Managed services can help, but they are often too young (for example, Amazon EKS was announced only at the end of 2017).
Avoid madness by making prudent and thoughtful decisions. And to help with this, I prepared several questions that you can ask yourself, and explanations for the answers to them. Note trans. : The original image is translated and presented in text below.
Is it possible to seat your whole team at one big table?
Is your system primarily stateless?
Are you building a solution for a single application or service?
Do you have a solid dependency?
Do you have any experts in container, orchestration, DevOps?
Download the original PDF with all questions and answers (in English) here .
I intentionally avoided the word “a” in this article. But my friend Zoltan , checking it, made a very good comment.
Microservice architecture does not exist. Microservices are just another pattern or implementation of components, no more, no less. Whether they are presented in the system or not does not mean that the system architecture is ready.
Microservices are in many ways more related to technical processes related to packaging and operation than to the system architecture itself. Appropriate boundaries for components remain one of the main difficulties in engineering systems.
Regardless of the size of your services, whether they are in Docker containers or not - you should always think carefully about how to put the system together. There are no correct answers, but there are many options.
Read also in our blog:
In recent years, microservices have become a very popular topic. "Microservice madness" looks like this:
')
“Netflix is good at DevOps. Netflix make microservices. So, if I do microservices, I'm good at DevOps. ”
There are a lot of cases when significant efforts were made to introduce microservice patterns without necessarily understanding what disadvantages and advantages this will lead to in the context of the specific problem being solved.
I will tell in detail about what microservices are, why their pattern is so attractive and what are some of the main difficulties in the way of their use. I will finish with simple questions that you should ask yourself when the relevance of the microservice pattern for your needs is considered. These questions are presented at the end of the article.
What are microservices and why are they so popular?
Let's start with the basics. Here is an example of a possible implementation of a hypothetical video sharing platform: first in a monolithic representation (one large block), and then in a microservice.
The difference between these two systems is that the first is a single large block, i.e. monolith. The second is a set of small specific services. Each service has its own specific role.
When the scheme is presented at this level of detail, it is easy to see its appeal. There is a whole set of potential advantages:
Independent development . Small independent components can be created by small independent teams. The group can work on changes in the Upload service without affecting the Transcode service or even knowing about it. The amount of time required to study a component is significantly reduced, and it becomes easier to develop new functions.
Independent deployment . Every single component can be deployed independently. This allows you to release new features quickly and with less risk. Corrections or features for the Streaming component can be deployed without the need to add other components.
Independent scalability . Each component can be scaled independently of the other. In times of increased user demand, when new broadcasts come out, the Download component can be scaled for increased load without the need to scale each component, which makes scaling flexible and reduces costs.
Reusability . Components realize their small specific function. This means that it is easier to adapt them for use in other systems, services or products. The Transcode component can be used by other business units or even turned into a new business offering transcoding services to a different audience.
At this level of detail, the advantages of the microservice model over the monolithic seem obvious. If so, then why did the pattern come into fashion only now? Where has he been all my life?
If everything is so great, then why hasn't anyone done it before?
There are two answers to this question. The first - actually did , to the best of technical capabilities. Second - recent technological improvements have allowed us to reach a new level in this approach.
When I started preparing an answer to this question, I got a long description, so I’ll better highlight it in a separate article and post it a little later. Here, the path from one program to the set, ESB (enterprise service bus, i.e. "enterprise service bus" - approx. Transl.) And SOA (service-oriented architecture, i.e. "service-oriented architecture" ) will be omitted . - approx. Transl. , Component design and bounded contexts ("limited context" - pattern from Domain-Driven Design - approx. Transl.) , Etc.
Instead, I’ll write that in many ways we’ve done it all for a while, but only with the recent explosive growth of container technologies (especially Docker) and orchestration technologies (such as Kubernetes, Mesos, Consul, etc.) the pattern has become much more expedient to implement from a technical point of view.
If we take for granted the possibility of implementing a microservice approach, it is necessary to carefully consider the need . We saw high-level theoretical advantages, but what about the difficulties?
What is the problem of microservices?
If microservices are so beautiful, what's the matter? Here are some of the most significant problems that I have seen.
Increased complexity for developers
Developing life can be much harder. If a developer wants to work on features that affect many [journey] services, he will have to run all of them on his machine and connect to them. This is often more difficult than just running one program.
This complexity can be partially alleviated with the help of appropriate tools [tooling] , but the greater the number of services that make up the system, the more difficulties developers will have when starting the system as a whole.
Increased complexity for operation
For teams that do not develop services, but support them, there will be an explosion in potential complexity. Instead of managing several running services, they will have to work with tens, hundreds, or thousands. More services, more ways to interact and more opportunities for potential problems.
Increased difficulty for DevOps
Looking at the two previous points, it may seem - especially because of the popularity of DevOps as a practice (of which I am a big supporter) - that exploitation and development are considered separately. So, isn’t it getting better thanks to DevOps?
The difficulty is that many organizations still have separate development and operation teams, and in such cases they are likely to have a hard time adapting microservices.
For organizations already using DevOps, this is also not so simple. Being at the same time a developer and a sysadmin is already difficult (but critical for creating good software), and with the need to also understand the nuances of container orchestration systems and, in particular, systems that are rapidly evolving, even harder. So I come to the next item.
Requires serious competence
The results can be great if the work was done by experts. But imagine an organization in which not everything is perfect with the work of a single monolithic system. Why, with an increase in the number of systems, which complicates the operation, the situation will become better?
Yes, with efficient automation, monitoring, orchestration, etc. - all this is possible. However, complexity is rarely a technology - usually this is a search for people who can use it effectively. The demand for such skills is huge now, and finding them is not easy.
Real systems usually do not have clearly defined boundaries.
In all the examples used to describe the benefits of microservices, it was about independent components. However, in many cases, the components are not simply independent. If on paper certain areas may look related, then in reality, when you get to the bottom of all the details, it is easy to find that everything is much more complicated than in the intended model.
This is where everything becomes very complicated. If the boundaries are not really well defined, it will happen that - even in the case of the theoretical possibility of an isolated deployment of services - interdependencies will emerge between the services, due to which the sets of services will have to be deployed as a group.
In turn, this means that it is necessary to maintain consistent versions of services that have been tested and tested in working with each other. It turns out that there is actually no system, parts of which can be deployed independently, because deploying a new feature will have to carefully manage the deployment of multiple services.
Stateful difficulties are often ignored.
In the previous example, the occasional need for a simultaneous rollout of multiple versions of multiple services during a delay feature is mentioned. I would like to say that thoughtful deployment techniques will make life easier: for example, blue-green deployments (require minimal effort on most platforms for service orchestration) or parallel launch of multiple versions of a service with the possibility of choosing the right one on the side of their user.
These techniques remove many obstacles if the services are stateless. But working with stateless services is actually quite simple. Actually, if you have stateless-services, I recommend thinking about skipping all these microservices and using the serverless model.
In reality, many services need to store the state. An example for a video sharing platform is a subscription service. Let the new version of the subscription service stores data in the database of a new type. If both services are running in parallel, then you have a system that simultaneously uses two schemes. If you make a blue-green patch, and other services depend on data in a new form, they need to be updated at the same time. If the subscription service has failed and is rolled back, then most likely it is necessary to roll back these services too, and then “by the cascade”.
Again, it is tempting to think that such schema-related problems will go away with databases from the world of NoSQL, but this is not the case. Databases that do not require strict schemas do not mean that the system does not have schemas, because in essence it simply means the need to manage the schema at the application level, not at the DBMS level. It is impossible to eradicate the fundamental problem of understanding the type of your data and how it changes.
Interaction difficulties are often ignored.
Since you are creating a large network of services dependent on each other, a large field for interservice interaction is likely to appear. There are a number of difficulties. First, there are more places for potential failures. It is necessary to foresee the possibility that network calls will not work, that is, each time one service accesses another, it must at least try to repeat its attempts. When the service needs to address a variety of services, the situation will become more complicated.
Imagine that a user uploads a video to a sharing service. We need to start the download service, transfer the data to the transcoding service, update the subscriptions, update the recommendations, and so on. All of these challenges require a certain orchestration, and if something breaks, the action must be repeated.
Repeat calls can be difficult to manage. Attempts to do everything synchronously often become untenable, because they have too many points of failure. In this case, a more reliable solution will be the use of asynchronous interaction patterns. But the difficulty lies in the fact that due to asynchronous patterns, the system becomes stateful. And as already mentioned in the last paragraph, it is very difficult to manage stateful-systems and systems with distributed states.
When a message queue for inter-service communication is used in a microservice system, you basically have a large database (message queue or broker) that sticks together all the services. Again, even though all this does not seem to be a problem at first, the circuit will catch up with you and remind you of yourself. Service version X can write messages in a specific format, so services that depend on such a message also need to be updated when the sender service changes something in its message.
You can have services that process messages in many different formats, but they are difficult to manage. When deploying new versions of services, it will happen that two versions of the service will try to process messages from the same queue and, possibly, even from the sending services of different versions too. This can lead to confusing, inadequate situations. It may turn out that in order to avoid them it is easier to allow only certain versions of messages to exist: this means that you have to deploy consistent sets of versions for sets of services, ensuring that messages of old versions are processed appropriately (first).
This again confirms the idea that, if we go into details, independent deployments do not always work as intended.
Versioning can be tricky
To overcome the mentioned obstacles, it is necessary to manage versions very carefully. Again, there is a tendency to believe that following a standard like semver will solve the problem. This is not true. Semver is an agreement that is advisable to use, but you still have to keep track of the versions of services and APIs that can interact.
Very quickly, you can come to significant difficulties and find yourself in a situation where you do not know which versions of the services actually work correctly with each other.
It is well known how hard it is to manage dependencies in software systems, whether they are modules for Node or Java, libraries for C, etc. It is very difficult to deal with the problems of conflicts of independent components used by one entity.
It is difficult to cope with these problems when dependencies are static and can be patched, updated, edited, and so on. If the working services serve as dependencies, it will not be possible to simply update them: you need to run several versions (with the problems described above) or pause the system until everything is completely fixed.
Distributed transactions
In situations where transactional integrity is required during operation, microservices can be a big pain. It’s not easy to work with a distributed state, and the multitude of small components that can break make transaction orchestration really hard.
It may seem attractive to try to avoid problems by making the operations idempotent, suggesting retry mechanisms, etc. - and in many cases it will work. However, there may be scenarios in which a successful or unsuccessful transaction is simply needed, without an intermediate state. The complexity of the workaround for this task or its implementation in the microservice model can be very high.
Microservices can be disguised monoliths
Yes, individual services and components can be deployed in isolation, but in most cases some kind of orchestration platform like Kubernetes will be launched. If you use a managed service like GKE from Google or EKS from Amazon, most of the cluster management has been solved for you.
However, if you manage the cluster yourself, then you are working with a large, complex and critical system. Although individual services may have all the advantages described above, it is necessary to manage the cluster very thoughtfully. Deploying such a system can be tricky, upgrades are tricky, failover is tricky, and so on.
In many cases, the overall benefits remain, but it is important not to simplify or underestimate the additional complexity caused by managing another large and complex system. Managed services can help, but they are often too young (for example, Amazon EKS was announced only at the end of 2017).
Death of microservice madness!
Avoid madness by making prudent and thoughtful decisions. And to help with this, I prepared several questions that you can ask yourself, and explanations for the answers to them. Note trans. : The original image is translated and presented in text below.
1. Team size
Is it possible to seat your whole team at one big table?
- Yes! Perhaps microservices are not needed yet. The difficulties associated with deployment, development, operation, etc., are probably easily solved with the help of good communications and good architecture , and microservices can be a solution to a problem that you don’t have.
- Not! Microservices can help. If you have a large team or several teams, it may be difficult to strictly define the boundaries of components using only one architecture. Extracting components into isolated services can help in implementing these boundaries.
2. Stateless / stateful
Is your system primarily stateless?
- Yes! Consider serverless. If your system is basically stateless, you can probably skip the microservice step and go straight to serverless — at least partially.
- Not! Microservices will bring complexity. This does not mean that you should not use microservices, but remember that it is not easy to implement and manage them - especially because the system changes over time .
3. "Users" of the system
Are you building a solution for a single application or service?
- Yes! Be careful - there may be “blurry” subject areas. If everything you build is intended for the same user application, it may become clear that building features will require the simultaneous updating of multiple services. Microservices may be appropriate, but be very careful with the design of subject areas.
- Not! Microservices can be very useful. If you design a system that will be used by different applications, microservices can be a very appropriate pattern to quickly deliver new features to new “user” applications.
4. Dependencies
Do you have a solid dependency?
- Yes! Performance can cause problems. In this case, independently scalable services are unlikely to help, because the effect of dependency performance remains. It turns out that one of the main advantages will not be relevant. In addition, the boundaries of your services may be worse defined.
- Not! Microservices can be very useful. If the monoliths do not pull you to the bottom, you may be able to achieve the high level of independence required to effectively scale up microservices.
5. Competence
Do you have any experts in container, orchestration, DevOps?
- Yes! Microservices can be very useful. If you have the appropriate frames, you should study microservices. Existing skills will deal with potential difficulties and take advantage.
- Not! Test the ground first! In the absence of due competence or in the case of existing difficulties with DevOps, you can jump over your head. Consider adapting one simple service as proof of concept. Get the first experience you need on projects that are not critical for business.
Download the original PDF with all questions and answers (in English) here .
Last thoughts: do not confuse microservices with architecture
I intentionally avoided the word “a” in this article. But my friend Zoltan , checking it, made a very good comment.
Microservice architecture does not exist. Microservices are just another pattern or implementation of components, no more, no less. Whether they are presented in the system or not does not mean that the system architecture is ready.
Microservices are in many ways more related to technical processes related to packaging and operation than to the system architecture itself. Appropriate boundaries for components remain one of the main difficulties in engineering systems.
Regardless of the size of your services, whether they are in Docker containers or not - you should always think carefully about how to put the system together. There are no correct answers, but there are many options.
PS from translator
Read also in our blog:
- Statistics The New Stack on the Difficulties of Implementing Kubernetes ;
- " Our experience with Kubernetes in small projects " (video of the report, which includes an introduction to the technical device Kubernetes);
- " Infrastructure with Kubernetes as an affordable service ";
- “ Why do you need Kubernetes and why is it more than PaaS? ";
- “ What is a service mesh and why do I need it [for a cloud microservice application]? ";
- " Operators for Kubernetes: how to run stateful applications ."
Source: https://habr.com/ru/post/347518/
All Articles