As we ivi rewrote etl: Flink + Kafka + ClickHouse
A year ago, we decided to redo the scheme of data collection in the application and data on customer actions. The old system worked fine, but each time it was becoming more and more difficult to make changes there.

In this article I will tell you what technologies we began to use for collecting and aggregating data in a new project.
Thinking about how we want to see the new ETL and trying on technology and prayers, we got the following scheme:

If there is no point in writing about a custom http-service storing data in kafka, and about kafka service itself, then I want to stop in more detail about how we use Flink and ClickHouse.
Apache Flink is an open source stream processing platform for distributed applications with a high degree of fault tolerance and crash tolerance.
When data is needed for analysis faster and fast aggregation of large data flow is necessary for quick response to certain events — the standard, ETL approach does not work. This is where streaming-processing will help us.
The beauty of this approach is not only in the speed of data delivery, but also in the fact that all processing is in one place. You can weigh everything with tests, instead of a set of scripts and sql queries, it becomes like a project that can be supported.
The flink cluster can be started in yarn, mesos or with the help of separate (embedded in the flink package) task- and job-manager's.
In addition to the obvious task of storing data in the right format, we wrote code using Flink to solve the following problems:
For fast work of all this machinery, I had to do a couple of simple tricks:
At the time of design, Clickhouse looked like an ideal option for our storage and analytical tasks. Column storage with compression (similar in structure to parquet), distributed query processing, sharding, replication, query sampling, nested tables, external dictionaries from mysql and any ODBC connection, data deduplication (albeit deferred), and many other goodies ...
We started testing ClickHouse a week after the release, and to say that everything was rosy at once was to lie.
There is no imputed allocation of access rights. Users get through the xml file. You cannot configure the readOnly user to access one database and full access to another database. Either full or only reading.
There is no normal join. If the right side of the join does not fit in memory, I'm sorry. No window functions. But we decided to do this by building a “funnel” mechanism in Flink, which allows you to track sequences of events and tag them. The minus of our “funnels” is that we cannot look at them retroactively before being added by the analyst. Or you need to reprocess data.
For a long time there was no normal ODBC driver. This is a huge barrier to implement the database, because many BI (Tableau in particular) have this very interface. Now there is no problem.
Having been at the last conference on CH (December 12, 2017), the developers of the database encouraged me. Most of the problems that I care about should be solved in the first quarter of 2018.
Many people criticize ClickHouse for syntax, but I like it. As one of my esteemed colleague put it, Clickhouse is a “database for programmers”. And this is a little truth. You can greatly simplify requests if you use the coolest and unique functionality. For example, higher order functions . Lambda calculations on arrays right in sql. Is this a miracle ??? Or that I really liked - combinators of aggregate functions .
This functionality allows attaching a set of suffixes (-if, -merge, -array) to functions, modifying the operation of this function. Extremely interesting developments.
Our Clickhouse solution is based on the ReplicatedReplacingMergeTree tabular engine.
The distribution of data across the cluster looks like this:
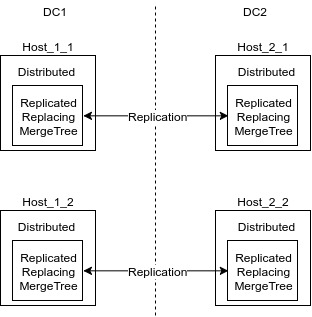
A distributed table is a wrapper over a local table (ReplicatedReplacingMergeTree) that all insert and select go to. These tables deal with sharding data when inserting. Queries to these tables will be distributed. Data, if possible, is distributed distributed on remote servers.
ReplicatedReplacingMergeTree is an engine that replicates data and at the same time, at every turn, it collapses duplicates on certain keys. Keys for deduplication are specified when creating the table.
This ETL scheme allowed us to have a replicable tolerant repository. If there is an error in the code, we can always roll back the consumer offset to kafka and process part of the data again, without making any special efforts to move the data.
In this article I will tell you what technologies we began to use for collecting and aggregating data in a new project.
And that's why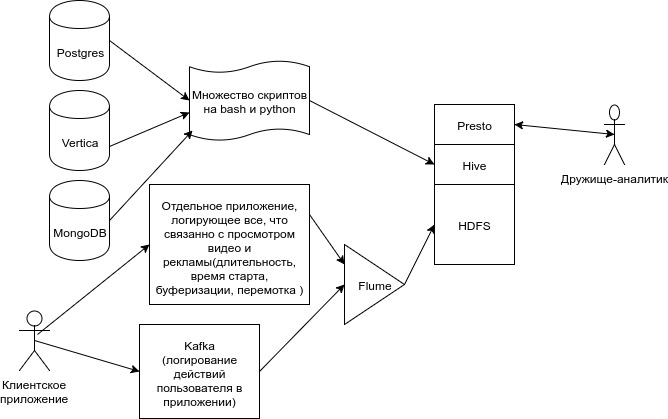
This is how our old data flow pattern looked like.
')
A lot of data from our microservices, overflowed with scripts in Hive.
Flume loaded client data from Kafka into several more tables, plus Flume loaded information about views from the file system of one of the services. In addition, there were dozens of scripts in cron and oozie.
At some point, we realized that it was impossible to live like this. Such a data loading system is almost impossible to test. Each unloading is accompanied by prayers. Each new ticket for revision - a quiet rattle of the heart and teeth. Making it so that the system is completely tolerant to the fall of any of its components has become very difficult.
This is how our old data flow pattern looked like.
')
A lot of data from our microservices, overflowed with scripts in Hive.
Flume loaded client data from Kafka into several more tables, plus Flume loaded information about views from the file system of one of the services. In addition, there were dozens of scripts in cron and oozie.
At some point, we realized that it was impossible to live like this. Such a data loading system is almost impossible to test. Each unloading is accompanied by prayers. Each new ticket for revision - a quiet rattle of the heart and teeth. Making it so that the system is completely tolerant to the fall of any of its components has become very difficult.
Thinking about how we want to see the new ETL and trying on technology and prayers, we got the following scheme:
- All data comes on http. From all services. Data in json.
- We store raw (not processed) data in kafka for 5 days. In addition to ETL, data from kafka also uses other backend services.
- All data processing logic is in one place. For us, this has become java-code for the Apache Flink framework. About this wonderful framework later.
- For storing intermediate calculations, use redis. Flink has its own state-storage , it is tolerant to crashes and makes checkpoints, but its problem is that you cannot recover from it when the code changes.
- We store everything in Clickhouse. We connect with external dictionaries all tables, data from which microservices do not send us events via http.
If there is no point in writing about a custom http-service storing data in kafka, and about kafka service itself, then I want to stop in more detail about how we use Flink and ClickHouse.
Apache flink
Apache Flink is an open source stream processing platform for distributed applications with a high degree of fault tolerance and crash tolerance.
When data is needed for analysis faster and fast aggregation of large data flow is necessary for quick response to certain events — the standard, ETL approach does not work. This is where streaming-processing will help us.
The beauty of this approach is not only in the speed of data delivery, but also in the fact that all processing is in one place. You can weigh everything with tests, instead of a set of scripts and sql queries, it becomes like a project that can be supported.
Consider the simplest example of processing a stream from kafka based on Apache Flink
About how to quickly create a maven project with flink dependencies and small examples.
Here is a detailed description of the DataStream API, with which you can perform almost any conversion with the data stream.
package ivi.ru.groot; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010; import org.apache.flink.streaming.util.serialization.SimpleStringSchema; import org.apache.flink.util.Collector; import org.json.JSONException; import org.json.JSONObject; import java.util.Properties; public class Test { public static void main(String[] args) throws Exception { // flink- final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // kafka Properties kafkaProps = new Properties(); kafkaProps.setProperty("bootstrap.servers", "kafka.host.org.ru:9092"); kafkaProps.setProperty("zookeeper.connect", "zoo.host.org.ru:9092"); kafkaProps.setProperty("group.id", "group_id_for_reading"); FlinkKafkaConsumer010 eventsConsumer = new FlinkKafkaConsumer010<>("topic_name", new SimpleStringSchema(), kafkaProps); // (DataStreamApi) DataStream<String> eventStreamString = env.addSource(eventsConsumer).name("Event Consumer"); // . Hello eventStreamString = eventStreamString.filter(x -> x.contains("Hello")); // json JSONObject DataStream<JSONObject> jsonEventStream = eventStreamString.flatMap(new FlatMapFunction<String, JSONObject>() { @Override public void flatMap(String value, Collector<JSONObject> out) throws Exception { try{ // json out.collect(new JSONObject(value)); } catch (JSONException e){} } }); // stout json-. jsonEventStream.print(); // env.execute(); } } About how to quickly create a maven project with flink dependencies and small examples.
Here is a detailed description of the DataStream API, with which you can perform almost any conversion with the data stream.
The flink cluster can be started in yarn, mesos or with the help of separate (embedded in the flink package) task- and job-manager's.
Flink has a great web interface.
The web interface allows you to see how much data on which part of the graph is processed, how much a specific worker has processed, and how much a separate subtask of an individual worker has processed. In the web-interface, you can display metrics, you can determine which part of the code slows down using the back-pressure mechanism. Back-pressure determines what percentage of the data did not have time to filter through the graph section. Example graph for our ETL:
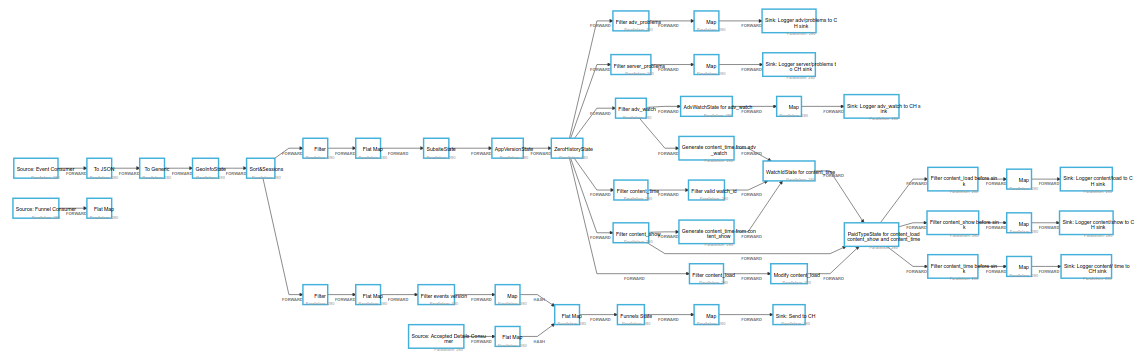
In addition to the obvious task of storing data in the right format, we wrote code using Flink to solve the following problems:
- Generate sessions for events. Session becomes uniform for all events of one user_id. Regardless, what was the source of the message.
- We enter the geo-information for each event (city, region, country, latitude and longitude).
- Calculate the “funnels”. Our analysts describe a specific sequence of events. We are looking for this sequence for a user within one client session and label events that have fallen into the funnel.
- The combination of data from different sources. In order not to make unnecessary joines, it can be understood in advance that a column from table A may be needed in future in table B. This can be done at the processing stage.
For fast work of all this machinery, I had to do a couple of simple tricks:
- All data is partitioned by user_id at the fill stage in kafka.
- We use redis as state storage. Redis is simple, reliable and super fast when we talk about key-value storage.
- Get rid of all window functions. No to all delays!
Clickhouse
At the time of design, Clickhouse looked like an ideal option for our storage and analytical tasks. Column storage with compression (similar in structure to parquet), distributed query processing, sharding, replication, query sampling, nested tables, external dictionaries from mysql and any ODBC connection, data deduplication (albeit deferred), and many other goodies ...
We started testing ClickHouse a week after the release, and to say that everything was rosy at once was to lie.
There is no imputed allocation of access rights. Users get through the xml file. You cannot configure the readOnly user to access one database and full access to another database. Either full or only reading.
There is no normal join. If the right side of the join does not fit in memory, I'm sorry. No window functions. But we decided to do this by building a “funnel” mechanism in Flink, which allows you to track sequences of events and tag them. The minus of our “funnels” is that we cannot look at them retroactively before being added by the analyst. Or you need to reprocess data.
For a long time there was no normal ODBC driver. This is a huge barrier to implement the database, because many BI (Tableau in particular) have this very interface. Now there is no problem.
Having been at the last conference on CH (December 12, 2017), the developers of the database encouraged me. Most of the problems that I care about should be solved in the first quarter of 2018.
Many people criticize ClickHouse for syntax, but I like it. As one of my esteemed colleague put it, Clickhouse is a “database for programmers”. And this is a little truth. You can greatly simplify requests if you use the coolest and unique functionality. For example, higher order functions . Lambda calculations on arrays right in sql. Is this a miracle ??? Or that I really liked - combinators of aggregate functions .
This functionality allows attaching a set of suffixes (-if, -merge, -array) to functions, modifying the operation of this function. Extremely interesting developments.
Our Clickhouse solution is based on the ReplicatedReplacingMergeTree tabular engine.
The distribution of data across the cluster looks like this:
A distributed table is a wrapper over a local table (ReplicatedReplacingMergeTree) that all insert and select go to. These tables deal with sharding data when inserting. Queries to these tables will be distributed. Data, if possible, is distributed distributed on remote servers.
ReplicatedReplacingMergeTree is an engine that replicates data and at the same time, at every turn, it collapses duplicates on certain keys. Keys for deduplication are specified when creating the table.
Summary
This ETL scheme allowed us to have a replicable tolerant repository. If there is an error in the code, we can always roll back the consumer offset to kafka and process part of the data again, without making any special efforts to move the data.
Source: https://habr.com/ru/post/347408/
All Articles