Smart search: how artificial intelligence hh.ru selects jobs to resume
More than half of the applicants are not looking for anything, but create a resume and just wait for them to be invited for an interview, or at least send a suitable vacancy. When we thought about how a job search site should look for them, we realized that they only needed one button.

We started to make such a system a year and a half ago - we decided to build an algorithm for machine learning that would choose the jobs that suit the user. But we understood very quickly that vacancies similar to resumes and vacancies to which the resume owner would like to respond are not the same thing.
')
In this article I will describe how we did a smart search - with all the problems, subtleties and compromises that we had to go to.
On hh.ru there are mailings with suitable vacancies. We took up with them in the first place: we began with the creation of a recommendation system that will bring suitable vacancies to candidates.
To understand the question, we made a log of what vacancies are shown to users and what users do with them further. We developed a system of a / b-tests, infrastructure in order to predict the likelihood of response for a couple of "resume / vacancy" using machine learning.
In production, we added the calculation of static features for indexing and consistent application of several filtering models for resumes with increasing resource intensity, and then the models for the final ranking.
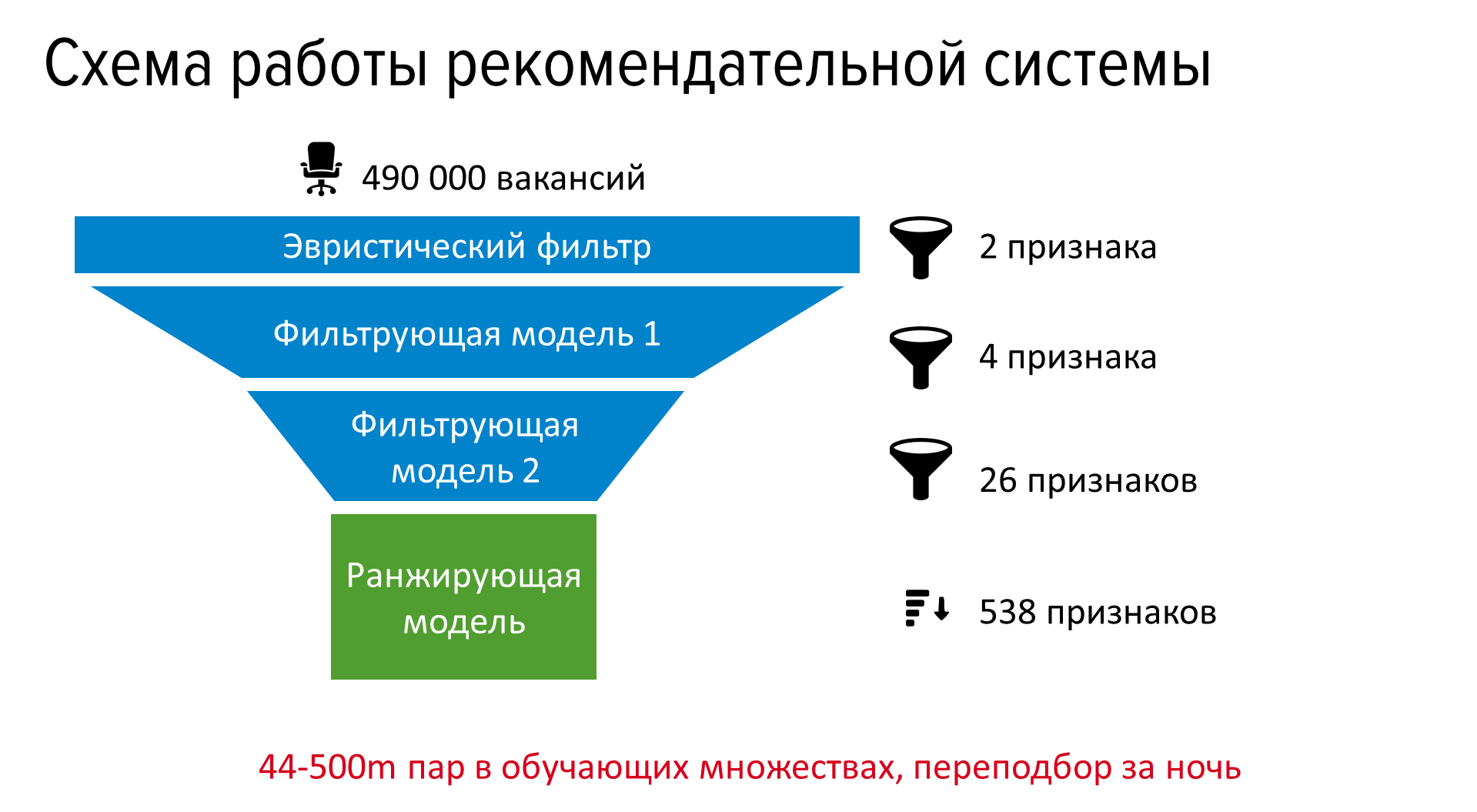
The system began to bring us about 1.2 million additional responses per month, which is about 120 thousand invited for an interview and 20 thousand hired. The vacancies selected by the recommendatory system come by mail, are shown in the “We recommend you personally” block on the main hh.ru and in suitable vacancies for resumes.
But even a relatively small improvement in the search is more profitable than a large one in the recommendation system. Therefore, the next step was the use of machine learning in the search.
We began by analyzing search queries. It turned out that in 35% of requests, users who have a resume leave the search box empty. If we count and anonymous queries, then the number of empty search queries reaches 50%.
For cases where the user has a summary, we decided to apply a recommender system: replace the rank by textual match with the rank from the recommender system. It did not require big changes and it turned out to be done pretty quickly.
The use of rank from the recommender system gave several thousand additional responses per day. But the effect was less than expected. Since users view, on average, only the first one and a half pages of issue, in large cities the changes concerned, in fact, only premium vacancies. The system showed suitable Premiums at the top, and then inappropriate, even if there were more suitable jobs like “Standard”, “Standard +” and free ones.
Therefore, we decided to try to make sure that the vacancies were divided into two groups: “Premiums”, “Standard +” and “Standard” went first, and free ones, for which the predicted response probability is more than a certain value, and then all the others are in the same order.
Since we absolutely needed that current vacancies for our clients-employers not to work worse, we very carefully approached these changes, even the experiment by 5% was supported by calculations and justifications. As a result, we did an experiment and saw an increase in responses for all types of vacancies.
Before applying the model, you need to count on the summary and on the vacancy signs, and then - the pair for their combination. In the recommender system, the load on which was not so high, static signs for vacancies were already considered when they were indexed and placed in a special index, and resumes and pairs were considered at the time of processing the request.
Since we understood that when you turn on search by an empty query, the load on the search engine will increase by about 6 times, we needed to cache attributes for resumes. First we tried to count the tags for the resume and put them in Cassandra. But to achieve the desired performance from her failed. Therefore, everything was decided by the table in PostgreSQL.
What had to be added to achieve the desired performance from the system:
Simplistically, in terms of components and data flows between them, the recommender search engine is designed like this.

Data streams in the system:
In the process, we needed to add about 10 servers to the cluster, more powerful than those that have been there until now. It was necessary to rationally use their power. Increased the likelihood that some of the servers will be unavailable. Therefore, we redesigned balancing on meta from a simple, unconditional round-robin, so that it takes into account the response time and the number of non-responses and sends more requests to those servers where they are less.
In addition to the use of new servers, it also made it possible to experience a sudden failure of 20% of the cluster without visible effects to users.
Simply, in terms of architecture layers and component instances in them, the system is structured as follows:
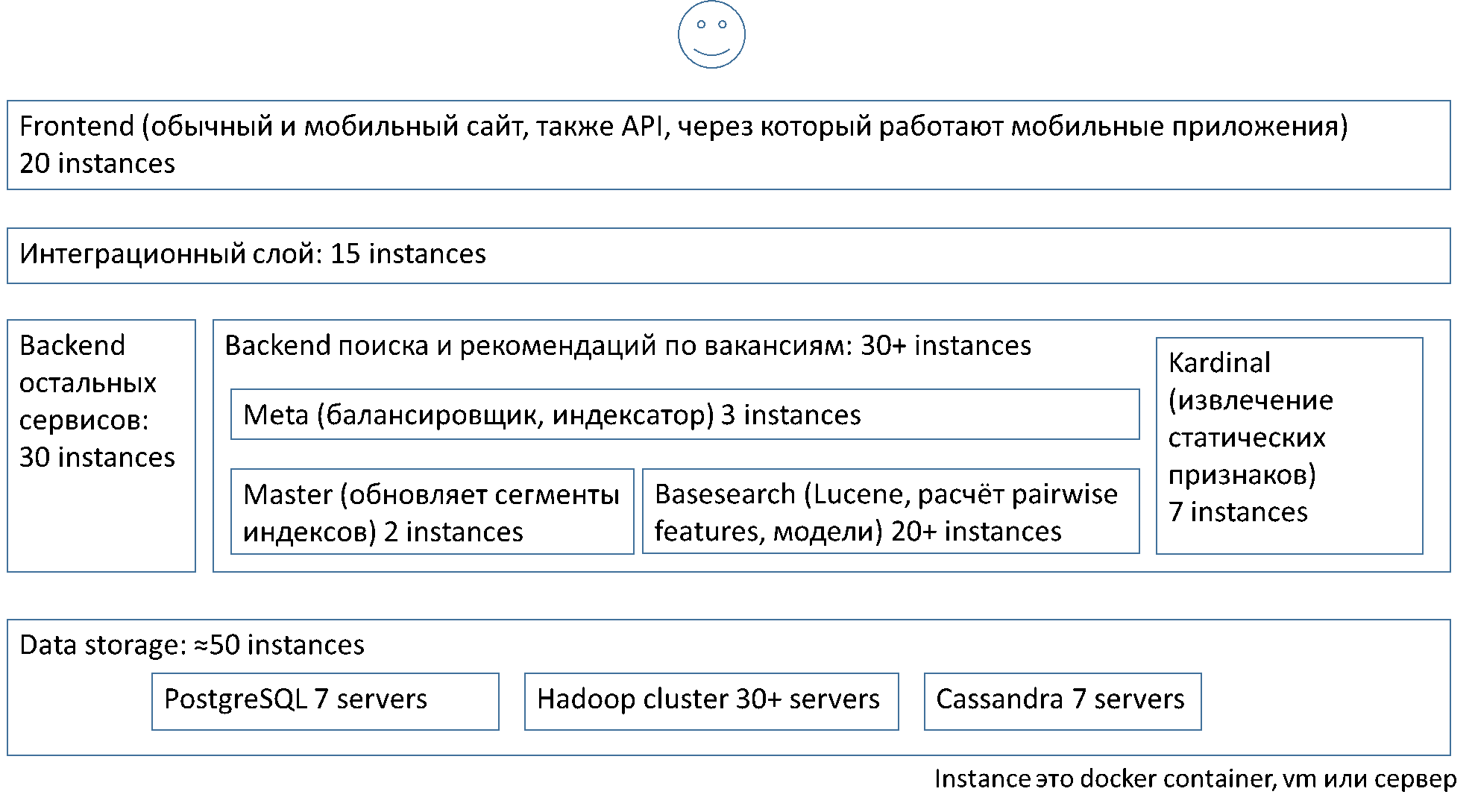
The balancing described above works between the average metasearch (meta) and the basic search (basesearch).
At the same time, we, without ceasing, worked on the recommender system. Included signs by text interactions, graded target function, signs by “raw” svd-vectors by texts, meta-signs by linear regression over tf / idf-vectors. There was another improvement: we repeated the unloading, cleaning and combining the initial data for machine learning from the logs and the database and made it so that it could be started with a single command.
Almost simultaneously, we began to do a search for a non-empty query.
First, we tried to apply to vacancies with words from a search query that Lucene gives out, filters and rankings from a recommender system. This did not result in statistically significant improvements. Therefore, we made a special upload “request - resume - vacancy - action” and taught two models:
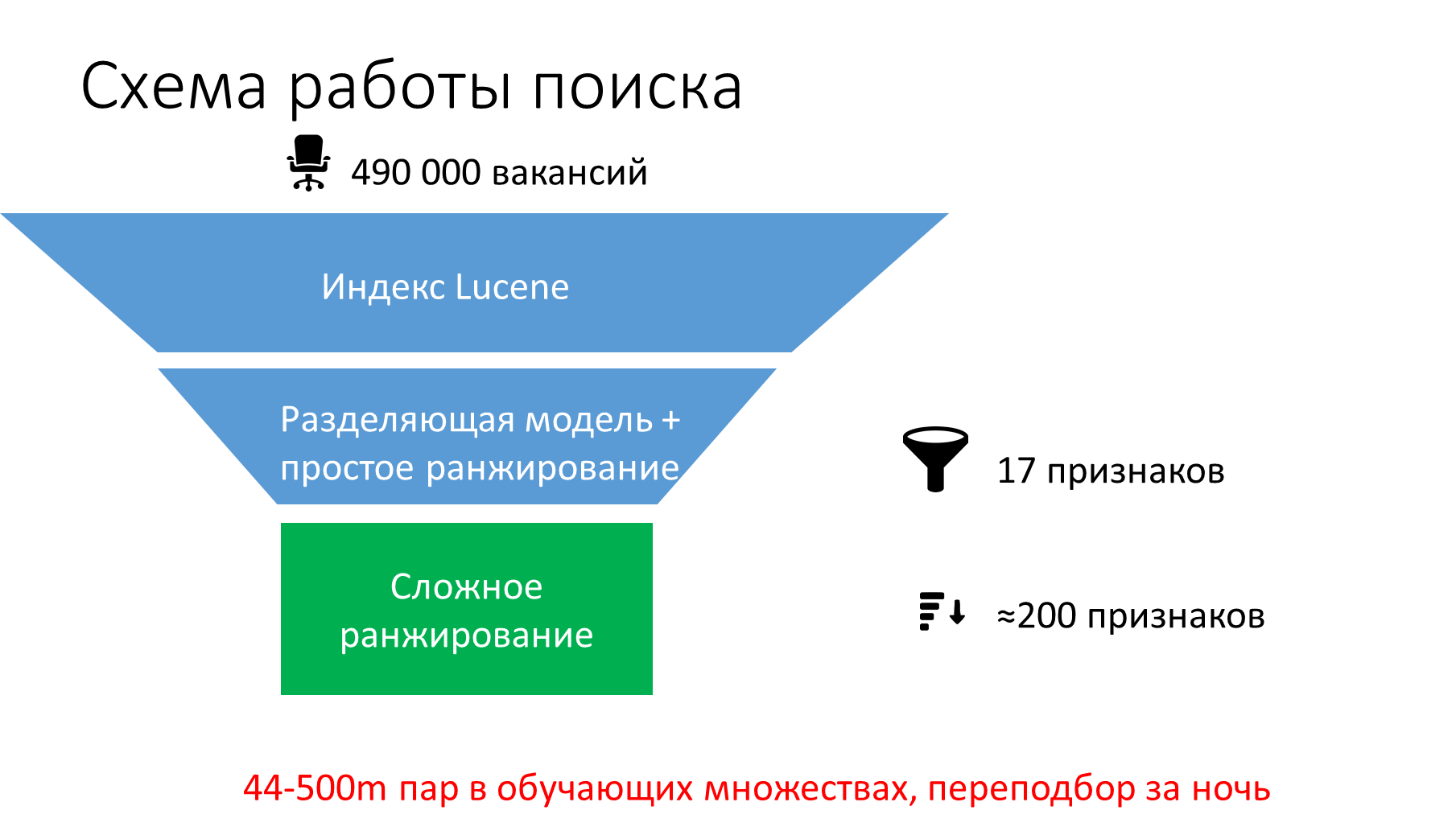
We reused signs from the recommender system: static (calculated before the query was executed), text, numeric and categorical, as well as dynamic, which are considered when processing the query. Added to the usual signs of signs that compare the text, taking into account textual interactions.
Schematically, the work of machine learning can be represented as:

When calculating the recommended vacancies and processing search queries, only the green part is performed, when models change (changes in linguistics, vectorization, signs, objective functions, models, just retraining models with more relevant data) - both green and blue.
Since there are a lot of signs and the code for calculating them when training models and processing requests had to be added to different places, it took a long time and led to errors. Therefore, we decided to make for them a framework, feature group. It’s not the first time to make this framework convenient, it even increased the project timeline a little.
We made a measurement of the quality of the models by selecting the local ndcg and map metrics for all volumes, @ 10, @ 20, using kfold by users and time-based-validation. Indeed, if, without time-based-validation, an increase in the complexity of models (for example, the number of trees) showed an improvement in local metrics, then it became clear to him that overfitting took place, which allowed us to select reasonable hyperparameters.
We first tried to teach a linear model to predict the likelihood of response for individual combinations of "request - resume - vacancy", but it turned out that the result in a / b tests is better when the linear model compares the probabilities for two vacancies. In this configuration, some experiments have already yielded statistically significant positive results. But still less than expected.
We added separate thresholds for suitable regular jobs, suitable ClickMe advertising jobs, to calculate the xgboost ranking model, as well as for the number of trees from the ensemble to be counted in production. We understood that there was not enough time to check all the options, so we took the most high-frequency queries, reformulated them, and checked the quality of the issue with different settings for applicants with a typical resume in the relevant professions, marking the vacancies.
To mark which vacancies are well suited for them, which are medium and which are not very good, I had to study the specifics of the professions quite deeply. There was very little time left, so we rolled out the settings that showed the best for markup, and a few more options by 5%, leaving only the control split without machine learning.
It turned out that it was not for good reason that the option included on the majority of users really showed itself best!
Users usually do not very well notice the changes in the ranking - to make a noticeable launch, you need to change the interface. In these changes, the negative effect of novelty is strongly manifested; improvements must be very strong in order to defeat it. For example, you need to make the first screen much more useful. We made a new graphic design, in which space from above horizontally and to the right vertically was not occupied by advertising.
Advertising can be treated differently, but it gives HeadHunter a substantial part of the profit. In order to share less of this profit with other advertising networks, HeadHunter made its network - ClickMe. Advertising that is in it can be divided into advertising vacancies and non-vacancies. In the new design, using the same technologies and models that are used in the search and recommendation system, we began to show instead of the top block of advertising several suitable advertised vacancies.

We made changes in design in very small parts in order to run experiments and understand in time if something we do causes a negative effect.
We are still measuring the effect of launching a smart search, but it is clear that in the first week after launch, the success of the search sessions of applicants reached a historical maximum. It was one of the fastest and quietest projects to launch systems of this class - at least in my experience. Largely due to the best team.
Unfortunately, it is impossible to make the search engine once and for all so that it is perfectly looking for something that is constantly changing, and itself was completely unchanged. Therefore, we continue to improve the search on HeadHunter to make users better. In addition, there are many more areas in HeadHunter where ML, search technologies, as well as metrics and a / b tests will be useful.
If you know how to search technology, machine learning and work with your hands - join. We hire, see our vacancies .
We started to make such a system a year and a half ago - we decided to build an algorithm for machine learning that would choose the jobs that suit the user. But we understood very quickly that vacancies similar to resumes and vacancies to which the resume owner would like to respond are not the same thing.
')
In this article I will describe how we did a smart search - with all the problems, subtleties and compromises that we had to go to.
Started with a recommendation system
On hh.ru there are mailings with suitable vacancies. We took up with them in the first place: we began with the creation of a recommendation system that will bring suitable vacancies to candidates.
To understand the question, we made a log of what vacancies are shown to users and what users do with them further. We developed a system of a / b-tests, infrastructure in order to predict the likelihood of response for a couple of "resume / vacancy" using machine learning.
In production, we added the calculation of static features for indexing and consistent application of several filtering models for resumes with increasing resource intensity, and then the models for the final ranking.
The system began to bring us about 1.2 million additional responses per month, which is about 120 thousand invited for an interview and 20 thousand hired. The vacancies selected by the recommendatory system come by mail, are shown in the “We recommend you personally” block on the main hh.ru and in suitable vacancies for resumes.
But even a relatively small improvement in the search is more profitable than a large one in the recommendation system. Therefore, the next step was the use of machine learning in the search.
Search by empty query
We began by analyzing search queries. It turned out that in 35% of requests, users who have a resume leave the search box empty. If we count and anonymous queries, then the number of empty search queries reaches 50%.
For cases where the user has a summary, we decided to apply a recommender system: replace the rank by textual match with the rank from the recommender system. It did not require big changes and it turned out to be done pretty quickly.
The use of rank from the recommender system gave several thousand additional responses per day. But the effect was less than expected. Since users view, on average, only the first one and a half pages of issue, in large cities the changes concerned, in fact, only premium vacancies. The system showed suitable Premiums at the top, and then inappropriate, even if there were more suitable jobs like “Standard”, “Standard +” and free ones.
Therefore, we decided to try to make sure that the vacancies were divided into two groups: “Premiums”, “Standard +” and “Standard” went first, and free ones, for which the predicted response probability is more than a certain value, and then all the others are in the same order.
Since we absolutely needed that current vacancies for our clients-employers not to work worse, we very carefully approached these changes, even the experiment by 5% was supported by calculations and justifications. As a result, we did an experiment and saw an increase in responses for all types of vacancies.
System performance
Before applying the model, you need to count on the summary and on the vacancy signs, and then - the pair for their combination. In the recommender system, the load on which was not so high, static signs for vacancies were already considered when they were indexed and placed in a special index, and resumes and pairs were considered at the time of processing the request.
Since we understood that when you turn on search by an empty query, the load on the search engine will increase by about 6 times, we needed to cache attributes for resumes. First we tried to count the tags for the resume and put them in Cassandra. But to achieve the desired performance from her failed. Therefore, everything was decided by the table in PostgreSQL.
What had to be added to achieve the desired performance from the system:
- Recalculation cache when changing signs. For users who have not updated their resumes and have not visited the site for more than two years, the cache is not considered, and the distribution of recommended jobs goes according to textual correspondence. If you come so-so suitable jobs, it may be this: you just need to update your resume.
- We noticed that if each server with a basic search continues to index all the objects for the indices that it has (vacancies, resumes, companies) separately, then we will not have enough servers ordered. Therefore, we redid the system of vacancy indexing and resumes from “every basic master to himself” to “main master - spare master - basic searches that collect index segments”, where only masters are engaged in indexing, with optimization and sequential pumping of the entire base every night (Moscow time). time) to reduce the amount of indexes.
- Did failfast - the http 500 quick response to basic searches if an error occurred while processing the request. With machine learning, the response time in some cases is greatly increased, and instead of filing such requests in a queue, the basic search gives the average meta-search a quick answer of http 500, after which the average meta-search manages to make a second request and in most cases give the user results. After this, we did a speculative retry: if there is no more than 2/3 timeout response from the basic search, then the average meta-search refers in advance to another basic search.
Simplistically, in terms of components and data flows between them, the recommender search engine is designed like this.
Data streams in the system:
- red arrows, (1) - (15) - contour of the response to a search query, starts automatically with each search query;
- blue arrows, (16) - (24) - contour of indexation, starts automatically when vacancies, resumes, companies change;
- green arrows, (25) - (33) - machine learning contour, started manually with each change of models (changes in linguistics, vectorization, signs, objective functions, models, just re-training of models using more relevant data);
- purple arrows (34) - (36) - contour for calculating metrics in A / B tests and business metrics (it starts automatically, once a day).
In the process, we needed to add about 10 servers to the cluster, more powerful than those that have been there until now. It was necessary to rationally use their power. Increased the likelihood that some of the servers will be unavailable. Therefore, we redesigned balancing on meta from a simple, unconditional round-robin, so that it takes into account the response time and the number of non-responses and sends more requests to those servers where they are less.
In addition to the use of new servers, it also made it possible to experience a sudden failure of 20% of the cluster without visible effects to users.
Simply, in terms of architecture layers and component instances in them, the system is structured as follows:
The balancing described above works between the average metasearch (meta) and the basic search (basesearch).
At the same time, we, without ceasing, worked on the recommender system. Included signs by text interactions, graded target function, signs by “raw” svd-vectors by texts, meta-signs by linear regression over tf / idf-vectors. There was another improvement: we repeated the unloading, cleaning and combining the initial data for machine learning from the logs and the database and made it so that it could be started with a single command.
Search for non-empty query: machine learning
Almost simultaneously, we began to do a search for a non-empty query.
First, we tried to apply to vacancies with words from a search query that Lucene gives out, filters and rankings from a recommender system. This did not result in statistically significant improvements. Therefore, we made a special upload “request - resume - vacancy - action” and taught two models:
- linear: used to quickly and with low resource consumption to separate suitable vacancies from inappropriate and roughly rank inappropriate;
- XGBoost: used to more accurately rank suitable ones.
We reused signs from the recommender system: static (calculated before the query was executed), text, numeric and categorical, as well as dynamic, which are considered when processing the query. Added to the usual signs of signs that compare the text, taking into account textual interactions.
Schematically, the work of machine learning can be represented as:
When calculating the recommended vacancies and processing search queries, only the green part is performed, when models change (changes in linguistics, vectorization, signs, objective functions, models, just retraining models with more relevant data) - both green and blue.
Since there are a lot of signs and the code for calculating them when training models and processing requests had to be added to different places, it took a long time and led to errors. Therefore, we decided to make for them a framework, feature group. It’s not the first time to make this framework convenient, it even increased the project timeline a little.
We made a measurement of the quality of the models by selecting the local ndcg and map metrics for all volumes, @ 10, @ 20, using kfold by users and time-based-validation. Indeed, if, without time-based-validation, an increase in the complexity of models (for example, the number of trees) showed an improvement in local metrics, then it became clear to him that overfitting took place, which allowed us to select reasonable hyperparameters.
We first tried to teach a linear model to predict the likelihood of response for individual combinations of "request - resume - vacancy", but it turned out that the result in a / b tests is better when the linear model compares the probabilities for two vacancies. In this configuration, some experiments have already yielded statistically significant positive results. But still less than expected.
We added separate thresholds for suitable regular jobs, suitable ClickMe advertising jobs, to calculate the xgboost ranking model, as well as for the number of trees from the ensemble to be counted in production. We understood that there was not enough time to check all the options, so we took the most high-frequency queries, reformulated them, and checked the quality of the issue with different settings for applicants with a typical resume in the relevant professions, marking the vacancies.
To mark which vacancies are well suited for them, which are medium and which are not very good, I had to study the specifics of the professions quite deeply. There was very little time left, so we rolled out the settings that showed the best for markup, and a few more options by 5%, leaving only the control split without machine learning.
It turned out that it was not for good reason that the option included on the majority of users really showed itself best!
New interface and advertising
Users usually do not very well notice the changes in the ranking - to make a noticeable launch, you need to change the interface. In these changes, the negative effect of novelty is strongly manifested; improvements must be very strong in order to defeat it. For example, you need to make the first screen much more useful. We made a new graphic design, in which space from above horizontally and to the right vertically was not occupied by advertising.
Advertising can be treated differently, but it gives HeadHunter a substantial part of the profit. In order to share less of this profit with other advertising networks, HeadHunter made its network - ClickMe. Advertising that is in it can be divided into advertising vacancies and non-vacancies. In the new design, using the same technologies and models that are used in the search and recommendation system, we began to show instead of the top block of advertising several suitable advertised vacancies.
We made changes in design in very small parts in order to run experiments and understand in time if something we do causes a negative effect.
Finally
We are still measuring the effect of launching a smart search, but it is clear that in the first week after launch, the success of the search sessions of applicants reached a historical maximum. It was one of the fastest and quietest projects to launch systems of this class - at least in my experience. Largely due to the best team.
Unfortunately, it is impossible to make the search engine once and for all so that it is perfectly looking for something that is constantly changing, and itself was completely unchanged. Therefore, we continue to improve the search on HeadHunter to make users better. In addition, there are many more areas in HeadHunter where ML, search technologies, as well as metrics and a / b tests will be useful.
If you know how to search technology, machine learning and work with your hands - join. We hire, see our vacancies .
Source: https://habr.com/ru/post/347276/
All Articles