Own DBMS for 3 weeks. You just need a little time every day ...
Own DBMS for 3 weeks. All you need is just a little time each day to devote to architecture; and all the rest of the time to work on the result, typing and reprinting hundreds of lines of code.
By law, Murphy, if there is more than one project to choose from - I will take up the most difficult of the proposed. It happened with the last task of the course on database management systems (DBMS).

According to the statement of work, it was necessary to create a DBMS from scratch on Vanilla Python 3.6 (without third-party libraries). The final product must have the following properties:
')
Developing a DBMS from scratch seemed like a non-trivial task (oddly enough, the way it turned out). Therefore, we - ecat3 and @ratijas - have approached this matter scientifically. There are only two of us in the team (apart from myself and my person), which means it is easier to cut tasks and coordinate their implementation than, in fact, to fulfill them. At the end of the cut came out as follows:
Initially, the time was allocated two weeks, so it was supposed to perform individual tasks for the week, and the remaining time was spent jointly on gluing and testing.
With the formal part finished, we turn to the practical. DBMS should be modern and relevant. In modern Innopolis, the Telegraph messenger, chat bots and group communication with the help of "/ slash tags" (this is # hashtags, just start with / slash) is relevant. Therefore, the query language, closely resembling SQL, is not only case-insensitive, it is also not sensitive to / slash immediately before any identifier: 'SELECT' and '/ select' are absolutely the same thing. In addition, like any university student, each language statement (statement) must be completed with '/ drop'. (Of course, also irrespective of the register. Who in general in such a situation is concerned with some sort of register?)
So the idea of the name was born: dropSQL . Actually / drop'om is called the expulsion of a student from the university; for some reason, this word has become widespread in our Innopolis. (Another local phenomenon: autism, or, more correctly, / autism. But we saved it for a special occasion.)
First of all, decomposed the dropSQL grammar on BNF (and in vain - left-handed recursions are not suitable for downstream parsers).
After several months with Rust as the main language, I really didn’t want to get bogged down again in exception handling. An obvious argument against exceptions is that it is expensive to throw them around and cumbersome to catch. The situation is worsened by the fact that Python, even in version 3.6 with Type Annotations, in contrast to the same Java, does not allow you to specify the types of exceptions that can fly out of the method. In other words: looking at the method signature, it should become clear what to expect from it. So why not unite these types under one roof, which is called “enum Error”? And above this, create another “roof” called Result; it will be discussed below. Of course, in the standard library there are places that can "explode"; but such calls in our code are reliably enclosed with try'yami from all sides, which reduce any exception to the return of an error, minimizing the occurrence of abnormal situations during execution.
So, it was decided to cycle the algebraic type of the result (hello, Rust). In python with algebraic types, everything is bad; and the module of the standard enum library is more like a clean sishechka.
In the worst traditions of OOP, we use inheritance to determine the result constructors: Ok and Err. And don't forget about static typing ( Well, maaam, I already have the third version! Can I finally have static typing in Python, well, please? ):
Fine! Spice up a bit of functional transformation sauce. Not all are needed, so take the necessary minimum.
And immediately use example:
Scribble in this style still takes 3 lines for each challenge. But, on the other hand, there comes a clear understanding of where any mistakes could occur, and what will happen to them. Plus, the code continues at the same level of nesting; this is a very important quality if the method contains half a dozen homogeneous calls.
Parser took a significant part of the development time. A competently composed parser should provide the user with the convenience of using the front-end of the product. The most important tasks of the parser are:
Having “not only the whole” standard python library, but also our modest knowledge of writing parsers, we understood that we would have to roll up our sleeves, and scroll down to a manual recursive descending parser. This is a long, dreary business, but it gives a high degree of control over the situation.
One of the first questions that required an answer: how to deal with errors? How to be - have already figured out above. But what exactly is a mistake? For example, after “/ create table” there may be “if not exists” or it may not be — is this a mistake? If so, what kind? where should be processed? ("Pause," and offer your options in the comments.)
The first version of the parser distinguished two types of errors: Expected (they expected one, but received something else) and EOF (end of file) as a subclass of the previous one. Nothing, until it came to the REPL. Such a parser does not distinguish between partial input (the beginning of a command) and the absence of something (EOF, if you can say so about interactive input from a terminal). Only a week later, through trial and error, we managed to find a scheme that would satisfy our domain domain.
The scheme is that everything is a thread, and the parser is only a modest next () method for the stream. And also that the error class should be rewritten to algebraic (like Result), and instead of EOF , the Empty and Incomplete variants are introduced.

Stream is an abstraction. Flow anyway, what elements to produce. The stream knows when to stop. All that is required to implement your thread is to rewrite the single abstract method next_impl () -> IResult [T] . What should this method return? Consider the flow of tokens as an example:
Threads are organized into a hierarchy . Each level contains its own buffer, which allows you to look ahead ( peek () -> IResult [T] ) and roll back ( back (n: int = 1) -> None ) if necessary.
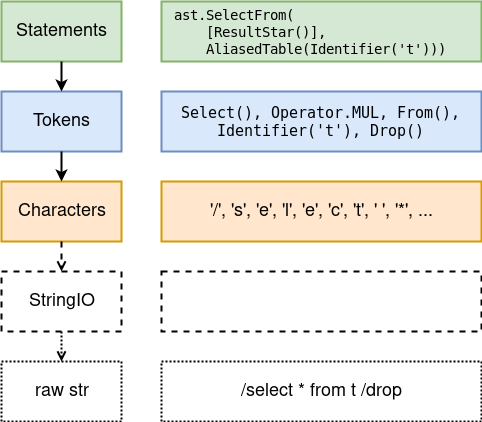
And the best part is that the stream can be " collected " into one big list of all IOk ( elements ) , which gives next () - before the first IErr () , of course. At what the list will return only when IErr contained Empty ; otherwise, an error is forwarded above. This design makes it easy and elegant to build a REPL.
This thread traverses the string characters. The only type of error: Empty at the end of the line.
Stream tokens. His middle name is Lexer. There are errors, strings without closing quotes, and all ...
Each type of tokens, including each keyword separately, is represented by a separate class-variant of the abstract class Token (or is it better to think about it as enum Token?) This is so that the statements parser can conveniently cast tokens to specific types.
The climax, the parser itself. Instead of a thousand words, a couple of snippets:
It is important to note that any errors of type Empty , except the very first one, parsers must convert to Incomplete , for the REPL to work correctly. For this there is an auxiliary function empty_to_incomplete () -> Error . What is not, and never will be, is a macro: the line if not t: return IErr (t.err (). Empty_to_incomplete ()) occurs in the codebase at least 50 times, and nothing can be done here. Seriously, at some point, I wanted to use Sishny preprocessor.
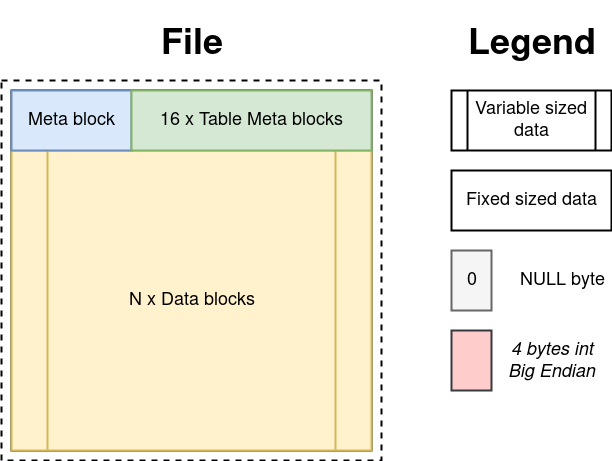
Globally, the database file is divided into blocks, and the file size is a multiple of the block size. The default block size is 12 KiB, but can optionally be increased to 18, 24, or 36 KiB. If you are a Satanist on the master's date, and you have very big data, you can even raise up to 42 KiB.
The blocks are numbered from scratch. The null block contains metadata about the entire database. Behind him are 16 blocks under the table metadata. Block # 17 begins with data blocks. A pointer to the block is the ordinal number of the block.
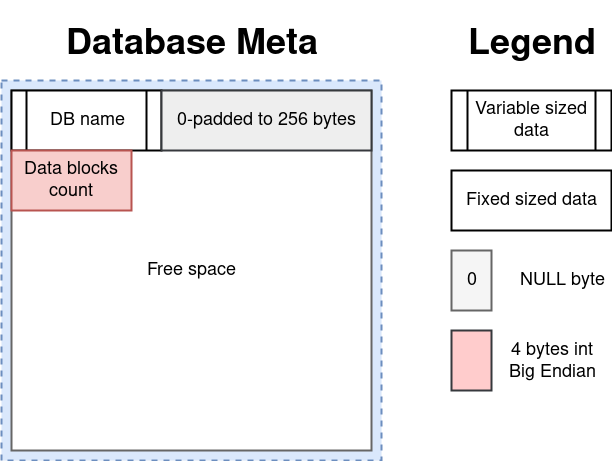
The base metadata is currently not so much: the name is up to 256 bytes in length and the number of data blocks.
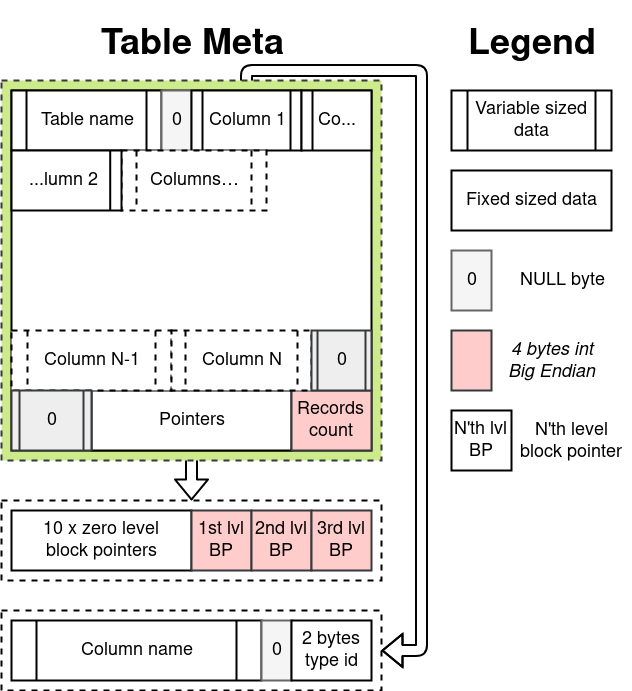
Meta-block table is the most difficult. The table name, the list of all columns with their types, the number of records and pointers to data blocks are stored here.
The number of tables is fixed in the code. Although this can be corrected relatively easily, if you store pointers to table meta-blocks in the base meta-block.
Pointers to blocks operate on the principle of pointers in the inode . Tanenbaum and dozens of other respected people wrote beautifully about this. Thus, the tables see their data blocks as “pages”. The difference is that the pages that come from the point of view of the table in order, are physically located in the file as God will put per capita. Drawing analogies with virtual memory in operating systems, page: virtual page number, block: physical page number.
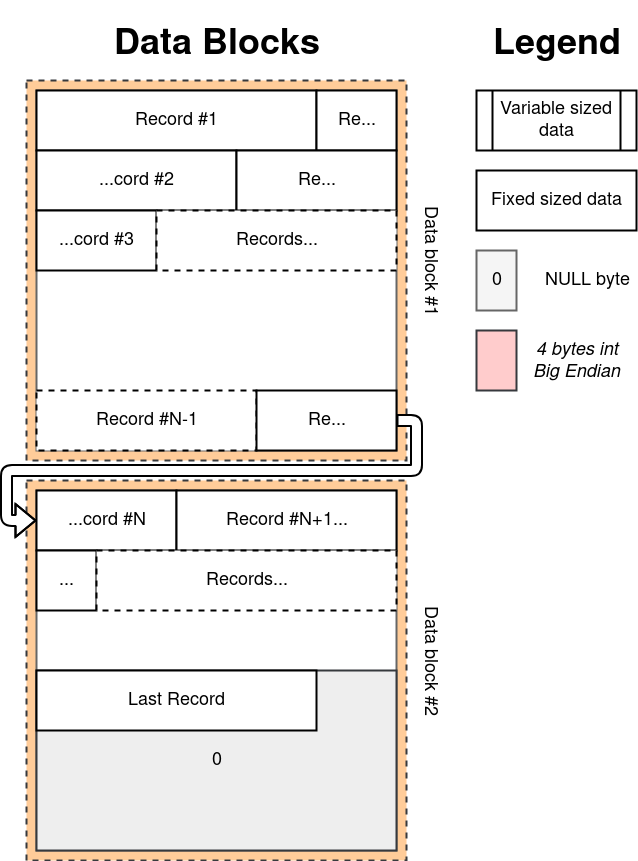
Data blocks do not have a specific structure by themselves. But when they are combined in the order dictated by pointers, they will appear as a continuous stream of records (record / tuple) of a fixed length. Thus, knowing the sequence number of the record, extract or write it - an operation of almost constant time, O (1 * ), with depreciation on the allocation of new blocks, if necessary.
The first byte of the record contains information about whether this record is alive or has been deleted. The rest of the work on packing and unpacking data takes the standard module struct .
The / update operation always does an in-place rewrite, and the / delete only replaces the first byte. VACUUM operation is not supported.
The time has come to firmly fasten the best of two worlds with a few skeins of tape.
MC on the left - AST top level nodes (AstStmt subclasses). Their execution occurs in the context of a database connection. Positional arguments are also supported - "? N" tokens in expressions in the request body, for example: "/ delete from student / where name =? 1 / drop". The expressions themselves are recursive, and their calculation does not constitute a scientific breakthrough.
The MC on the right is the database driver, which operates on the records one at a time, using the sequence number inside the table as an identifier. Only he knows which tables exist and how to work with them.
Go!
Their first joint single about creativity . Creating a new table is no more difficult than taking the first empty descriptor from 16, and enter the name and list of columns there.
Then, the track with the symbolic name / drop . In the home version of the demo, the following happens: 1) find the table descriptor by name; 2) reset. Who cares about non-freed blocks with data pages?
Insert is lenient to disrupting the order of columns, so before sending a tuple to write, it is passed through a special filter transition_vector .
Next, we will talk about working with records of tables, so let us immediately introduce our referee: RowSet .
The main specific subspecies of this beast - TableRowSet - is engaged in the selection of all live (not deleted) records in order. Other varieties of RowSet in dropSQL implement the necessary minimum of relational algebra .
In addition, there is still a programmable MockRowSet. It is good for testing. Also, it can be used to access the master table called " / autism ".
The beauty is that different RowSets can be combined as you wish: choose the student table, specify the alias S, filter the / where scholarship> 12k, choose another table of courses, connect the / on (course / sid = S / id) / and (course / grade <'B') ", project to" S / id, S / first_name / as / name "- this is represented by the following hierarchy:
So, armed with such a powerful instrument, we return to the lute music of the XVI century ...
About the fourth track, / select , there is nothing more to add. The symphony from RowSet is such that it fascinates the soul. Due to this, the implementation was extremely concise.
The last two: / update and / delete use the predecessor's work. With that, / update uses a technique similar to the “transition_vector” described above.
Such a concert! Thanks for attention! A curtain!..
Dreams that haven't come true yet:
Since this was an educational project, we did not get a penny for it. Although, judging by the statistics of sloc, you could now eat red caviar.
And next time we will implement our non-relational, with aggregate pipelines and transactions; and call it - / noDropSQL!
By law, Murphy, if there is more than one project to choose from - I will take up the most difficult of the proposed. It happened with the last task of the course on database management systems (DBMS).
Formulation of the problem
According to the statement of work, it was necessary to create a DBMS from scratch on Vanilla Python 3.6 (without third-party libraries). The final product must have the following properties:
')
- stores database in binary format in a single file
- DDL: supports three data types: Integer, Float and Varchar (N). For simplicity, they are all fixed lengths.
- DML: supports basic SQL operations:
- INSERT
- UPDATE
- DELETE
- SELECT with WHERE and JOIN. With which particular JOIN - it was not indicated, so just in case we did both CROSS and INNER
- maintains 100'000 records
Design Approach
Developing a DBMS from scratch seemed like a non-trivial task (oddly enough, the way it turned out). Therefore, we - ecat3 and @ratijas - have approached this matter scientifically. There are only two of us in the team (apart from myself and my person), which means it is easier to cut tasks and coordinate their implementation than, in fact, to fulfill them. At the end of the cut came out as follows:
| Task | Artist (s) |
|---|---|
| Parser + AST + REPL | ratijas, who wrote more than one calculator on every lex / yacc |
| Base file structure | ecat3, who ate the dog on file systems |
| Engine (low-level base operations) | ecat3 |
| Interface (high-level gluing) | Together |
Initially, the time was allocated two weeks, so it was supposed to perform individual tasks for the week, and the remaining time was spent jointly on gluing and testing.
With the formal part finished, we turn to the practical. DBMS should be modern and relevant. In modern Innopolis, the Telegraph messenger, chat bots and group communication with the help of "/ slash tags" (this is # hashtags, just start with / slash) is relevant. Therefore, the query language, closely resembling SQL, is not only case-insensitive, it is also not sensitive to / slash immediately before any identifier: 'SELECT' and '/ select' are absolutely the same thing. In addition, like any university student, each language statement (statement) must be completed with '/ drop'. (Of course, also irrespective of the register. Who in general in such a situation is concerned with some sort of register?)
Typical / day in / chat
So the idea of the name was born: dropSQL . Actually / drop'om is called the expulsion of a student from the university; for some reason, this word has become widespread in our Innopolis. (Another local phenomenon: autism, or, more correctly, / autism. But we saved it for a special occasion.)
First of all, decomposed the dropSQL grammar on BNF (and in vain - left-handed recursions are not suitable for downstream parsers).
BNF grammar dropSQL
Full version of the link
/stmt : /create_stmt | /drop_stmt | /insert_stmt | /update_stmt | /delete_stmt | /select_stmt ; /create_stmt : "/create" "table" existence /table_name "(" /columns_def ")" "/drop" ; existence : /* empty */ | "if" "not" "exists" ; /table_name : /identifier ; /columns_def : /column_def | /columns_def "," /column_def ; /column_def : /column_name type /primary_key ; ... Examples of valid dropSQL commands from the online product help
/create table t(a integer, b float, c varchar(42)) /drop /insert into t (a, c, b) values (42, 'morty', 13.37), (?1, ?2, ?3) /drop /select *, a, 2 * b, c /as d from t Alias /where (a < 100) /and (c /= '') /drop /update t set c = 'rick', a = a + 1 /drop /delete from t where c > 'r' /drop /drop table if exists t /drop We work on the result! No exceptions!
After several months with Rust as the main language, I really didn’t want to get bogged down again in exception handling. An obvious argument against exceptions is that it is expensive to throw them around and cumbersome to catch. The situation is worsened by the fact that Python, even in version 3.6 with Type Annotations, in contrast to the same Java, does not allow you to specify the types of exceptions that can fly out of the method. In other words: looking at the method signature, it should become clear what to expect from it. So why not unite these types under one roof, which is called “enum Error”? And above this, create another “roof” called Result; it will be discussed below. Of course, in the standard library there are places that can "explode"; but such calls in our code are reliably enclosed with try'yami from all sides, which reduce any exception to the return of an error, minimizing the occurrence of abnormal situations during execution.
So, it was decided to cycle the algebraic type of the result (hello, Rust). In python with algebraic types, everything is bad; and the module of the standard enum library is more like a clean sishechka.
In the worst traditions of OOP, we use inheritance to determine the result constructors: Ok and Err. And don't forget about static typing ( Well, maaam, I already have the third version! Can I finally have static typing in Python, well, please? ):
result.py
import abc from typing import * class Result(Generic[T, E], metaclass=abc.ABCMeta): """ enum Result< T > { Ok(T), Err(E), } """ # def is_ok(self) -> bool: return False def is_err(self) -> bool: return False def ok(self) -> T: raise NotImplementedError def err(self) -> E: raise NotImplementedError ... class Ok(Generic[T, E], Result[T, E]): def __init__(self, ok: T) -> None: self._ok = ok def is_ok(self) -> bool: return True def ok(self) -> T: return self._ok ... class Err(Generic[T, E], Result[T, E]): def __init__(self, error: E) -> None: self._err = error def is_err(self) -> bool: return True def err(self) -> E: return self._err ... Fine! Spice up a bit of functional transformation sauce. Not all are needed, so take the necessary minimum.
result.py (continued)
class Result(Generic[T, E], metaclass=abc.ABCMeta): ... def ok_or(self, default: T) -> T: ... def err_or(self, default: E) -> E: ... def map(self, f: Callable[[T], U]) -> 'Result[U, E]': # -! ? # , Python "forward declaration". # -. PEP 484: # https://www.python.org/dev/peps/pep-0484/#forward-references ... def and_then(self, f: Callable[[T], 'Result[U, E]']) -> 'Result[U, E]': ... def __bool__(self) -> bool: # `if` return self.is_ok() And immediately use example:
Result usage example
def try_int(x: str) -> Result[int, str]: try: return Ok(int(x)) except ValueError as e: return Err(str(e)) def fn(arg: str) -> None: r = try_int(arg) # 'r' for 'Result' if not r: return print(r.err()) # one-liner, shortcut for `if r.is_err()` index = r.ok() print(index) # do something with index Scribble in this style still takes 3 lines for each challenge. But, on the other hand, there comes a clear understanding of where any mistakes could occur, and what will happen to them. Plus, the code continues at the same level of nesting; this is a very important quality if the method contains half a dozen homogeneous calls.
Parser, iResult, Error :: {Empty, Incomplete, Syntax}, REPL, 9600 baud and all
Parser took a significant part of the development time. A competently composed parser should provide the user with the convenience of using the front-end of the product. The most important tasks of the parser are:
- Distinct error reports
- Interactive incremental line input, or, more simply, REPL
Having “not only the whole” standard python library, but also our modest knowledge of writing parsers, we understood that we would have to roll up our sleeves, and scroll down to a manual recursive descending parser. This is a long, dreary business, but it gives a high degree of control over the situation.
One of the first questions that required an answer: how to deal with errors? How to be - have already figured out above. But what exactly is a mistake? For example, after “/ create table” there may be “if not exists” or it may not be — is this a mistake? If so, what kind? where should be processed? ("Pause," and offer your options in the comments.)
The first version of the parser distinguished two types of errors: Expected (they expected one, but received something else) and EOF (end of file) as a subclass of the previous one. Nothing, until it came to the REPL. Such a parser does not distinguish between partial input (the beginning of a command) and the absence of something (EOF, if you can say so about interactive input from a terminal). Only a week later, through trial and error, we managed to find a scheme that would satisfy our domain domain.
The scheme is that everything is a thread, and the parser is only a modest next () method for the stream. And also that the error class should be rewritten to algebraic (like Result), and instead of EOF , the Empty and Incomplete variants are introduced.
New type of error
class Error(metaclass=abc.ABCMeta): """ enum Error { Empty, Incomplete, Syntax { expected: str, got: str }, } """ def empty_to_incomplete(self) -> 'Error': if isinstance(self, Empty): return Incomplete() else: return self class Empty(Error): ... class Incomplete(Error): ... class Syntax(Error): def __init__(self, expected: str, got: str) -> None: ... # stream-specific result type alias IResult = Result[T, Error] IOk = Ok[T, Error] IErr = Err[T, Error] Flow interface
class Stream(Generic[T], metaclass=abc.ABCMeta): def current(self) -> IResult[T]: ... def next(self) -> IResult[T]: ... def collect(self) -> IResult[List[T]]: ... def peek(self) -> IResult[T]: ... def back(self, n: int = 1) -> None: ... @abc.abstractmethod def next_impl(self) -> IResult[T]: ... Stream is an abstraction. Flow anyway, what elements to produce. The stream knows when to stop. All that is required to implement your thread is to rewrite the single abstract method next_impl () -> IResult [T] . What should this method return? Consider the flow of tokens as an example:
| What's next | Example (input) | Result Type | Example (result) |
|---|---|---|---|
| Everything is fine, another element | / delete from t ... | IOk (token) | IOk (Delete ()) |
| Only spaces and comments left | \ n - wubba - lubba - dub dub! | IErr (Empty ()) | IErr (Empty ()) |
| The beginning of something bigger | 'string ...(no closing quote) | IErr (Incomplete ()) | IErr (Incomplete ()) |
| Do you rub me some game | # $% | IErr (Syntax (...)) | IErr (Syntax (expected = 'token', got = '#')) |
Threads are organized into a hierarchy . Each level contains its own buffer, which allows you to look ahead ( peek () -> IResult [T] ) and roll back ( back (n: int = 1) -> None ) if necessary.
And the best part is that the stream can be " collected " into one big list of all IOk ( elements ) , which gives next () - before the first IErr () , of course. At what the list will return only when IErr contained Empty ; otherwise, an error is forwarded above. This design makes it easy and elegant to build a REPL.
The basis of the REPL
class Repl: def reset(self): self.buffer = '' self.PS = self.PS1 def start(self): self.reset() while True: self.buffer += input(self.PS) self.buffer += '\n' stmts = Statements.from_str(self.buffer).collect() if stmts.is_ok(): ... # execute one-by-one self.reset() elif stmts.err().is_incomplete(): self.PS = self.PS2 # read more elif stmts.err().is_syntax(): print(stmts.err()) self.reset() else: pass # ignore Err(Empty()) Characters
This thread traverses the string characters. The only type of error: Empty at the end of the line.
Tokens
Stream tokens. His middle name is Lexer. There are errors, strings without closing quotes, and all ...
Each type of tokens, including each keyword separately, is represented by a separate class-variant of the abstract class Token (or is it better to think about it as enum Token?) This is so that the statements parser can conveniently cast tokens to specific types.
Typical lexer part
def next_impl(self, ...) -> IResult[Token]: ... char = self.characters.current().ok() if char == ',': self.characters.next() return IOk(Comma()) elif char == '(': self.characters.next() return IOk(LParen()) elif ... Statements
The climax, the parser itself. Instead of a thousand words, a couple of snippets:
streams / statements.py
class Statements(Stream[AstStmt]): def __init__(self, tokens: Stream[Token]) -> None: super().__init__() self.tokens = tokens @classmethod def from_str(cls, source: str) -> 'Statements': return Statements(Tokens.from_str(source)) def next_impl(self) -> IResult[AstStmt]: t = self.tokens.peek() if not t: return Err(t.err()) tok = t.ok() if isinstance(tok, Create): return CreateTable.from_sql(self.tokens) if isinstance(tok, Drop): return DropTable.from_sql(self.tokens) if isinstance(tok, Insert): return InsertInto.from_sql(self.tokens) if isinstance(tok, Delete): return DeleteFrom.from_sql(self.tokens) if isinstance(tok, Update): return UpdateSet.from_sql(self.tokens) if isinstance(tok, Select): return SelectFrom.from_sql(self.tokens) return Err(Syntax('/create, /drop, /insert, /delete, /update or /select', str(tok))) ast / delete_from.py
class DeleteFrom(AstStmt): def __init__(self, table: Identifier, where: Optional[Expression]) -> None: super().__init__() self.table = table self.where = where @classmethod def from_sql(cls, tokens: Stream[Token]) -> IResult['DeleteFrom']: """ /delete_stmt : "/delete" "from" /table_name /where_clause /drop ; """ # next item must be the "/delete" token t = tokens.next().and_then(Cast(Delete)) if not t: return IErr(t.err()) t = tokens.next().and_then(Cast(From)) if not t: return IErr(t.err().empty_to_incomplete()) t = tokens.next().and_then(Cast(Identifier)) if not t: return IErr(t.err().empty_to_incomplete()) table = t.ok() t = WhereFromSQL.from_sql(tokens) if not t: return IErr(t.err().empty_to_incomplete()) where = t.ok() t = tokens.next().and_then(Cast(Drop)) if not t: return IErr(t.err().empty_to_incomplete()) return IOk(DeleteFrom(table, where)) It is important to note that any errors of type Empty , except the very first one, parsers must convert to Incomplete , for the REPL to work correctly. For this there is an auxiliary function empty_to_incomplete () -> Error . What is not, and never will be, is a macro: the line if not t: return IErr (t.err (). Empty_to_incomplete ()) occurs in the codebase at least 50 times, and nothing can be done here. Seriously, at some point, I wanted to use Sishny preprocessor.
Pro binary format
Globally, the database file is divided into blocks, and the file size is a multiple of the block size. The default block size is 12 KiB, but can optionally be increased to 18, 24, or 36 KiB. If you are a Satanist on the master's date, and you have very big data, you can even raise up to 42 KiB.
The blocks are numbered from scratch. The null block contains metadata about the entire database. Behind him are 16 blocks under the table metadata. Block # 17 begins with data blocks. A pointer to the block is the ordinal number of the block.
The base metadata is currently not so much: the name is up to 256 bytes in length and the number of data blocks.
Meta-block table is the most difficult. The table name, the list of all columns with their types, the number of records and pointers to data blocks are stored here.
The number of tables is fixed in the code. Although this can be corrected relatively easily, if you store pointers to table meta-blocks in the base meta-block.
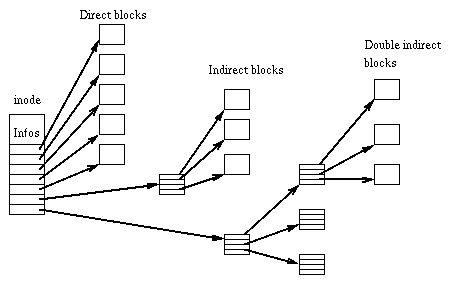
Pointers to blocks operate on the principle of pointers in the inode . Tanenbaum and dozens of other respected people wrote beautifully about this. Thus, the tables see their data blocks as “pages”. The difference is that the pages that come from the point of view of the table in order, are physically located in the file as God will put per capita. Drawing analogies with virtual memory in operating systems, page: virtual page number, block: physical page number.
Data blocks do not have a specific structure by themselves. But when they are combined in the order dictated by pointers, they will appear as a continuous stream of records (record / tuple) of a fixed length. Thus, knowing the sequence number of the record, extract or write it - an operation of almost constant time, O (1 * ), with depreciation on the allocation of new blocks, if necessary.
The first byte of the record contains information about whether this record is alive or has been deleted. The rest of the work on packing and unpacking data takes the standard module struct .
The / update operation always does an in-place rewrite, and the / delete only replaces the first byte. VACUUM operation is not supported.
About table operations, RowSet and joins
The time has come to firmly fasten the best of two worlds with a few skeins of tape.
MC on the left - AST top level nodes (AstStmt subclasses). Their execution occurs in the context of a database connection. Positional arguments are also supported - "? N" tokens in expressions in the request body, for example: "/ delete from student / where name =? 1 / drop". The expressions themselves are recursive, and their calculation does not constitute a scientific breakthrough.
The MC on the right is the database driver, which operates on the records one at a time, using the sequence number inside the table as an identifier. Only he knows which tables exist and how to work with them.
Go!
Their first joint single about creativity . Creating a new table is no more difficult than taking the first empty descriptor from 16, and enter the name and list of columns there.
Then, the track with the symbolic name / drop . In the home version of the demo, the following happens: 1) find the table descriptor by name; 2) reset. Who cares about non-freed blocks with data pages?
Insert is lenient to disrupting the order of columns, so before sending a tuple to write, it is passed through a special filter transition_vector .
Next, we will talk about working with records of tables, so let us immediately introduce our referee: RowSet .
Spherical RowSet in vacuum
class RowSet(metaclass=abc.ABCMeta): @abc.abstractmethod def columns(self) -> List[Column]: """ Describe columns in this row set. """ @abc.abstractmethod def iter(self) -> Iterator['Row']: """ Return a generator which yields rows from the underlying row stream or a table. """ The main specific subspecies of this beast - TableRowSet - is engaged in the selection of all live (not deleted) records in order. Other varieties of RowSet in dropSQL implement the necessary minimum of relational algebra .
| Relational algebra operator | Designation | Class |
|---|---|---|
| Projection | π (ID, NAME) expr | ProjectionRowSet |
| Rename | ρ a / b expr | ProjectionRowSet + RenameTableRowSet |
| Sample | σ (PRICE> 90) expr | FilteredRowSet |
| Cartesian product | PRODUCTS × SELLERS | CrossJoinRowSet |
| Inner join (let's call it an extension) | σ (cond) (A x B) | InnerJoinRowSet =
FilteredRowSet (
CrossJoinRowSet (...)) |
In addition, there is still a programmable MockRowSet. It is good for testing. Also, it can be used to access the master table called " / autism ".
The beauty is that different RowSets can be combined as you wish: choose the student table, specify the alias S, filter the / where scholarship> 12k, choose another table of courses, connect the / on (course / sid = S / id) / and (course / grade <'B') ", project to" S / id, S / first_name / as / name "- this is represented by the following hierarchy:
ProjectionRowSet([S/id, S/first_name/as/name]) FilteredRowSet((course/sid = S/id) /and (course/grade < 'B')) CrossJoinRowSet FilteredRowSet(scholarship > '12k') RenameTableRowSet('S') TableRowSet('student') TableRowSet('courses') So, armed with such a powerful instrument, we return to the lute music of the XVI century ...
About the fourth track, / select , there is nothing more to add. The symphony from RowSet is such that it fascinates the soul. Due to this, the implementation was extremely concise.
Implementation / select ... from
class SelectFrom(AstStmt): ... def execute(self, db: 'fs.DBFile', args: ARGS_TYPE = ()) -> Result['RowSet', str]: r = self.table.row_set(db) if not r: return Err(r.err()) rs = r.ok() for join in self.joins: r = join.join(rs, db, args) if not r: return Err(r.err()) rs = r.ok() if self.where is not None: rs = FilteredRowSet(rs, self.where, args) rs = ProjectionRowSet(rs, self.columns, args) return Ok(rs) The last two: / update and / delete use the predecessor's work. With that, / update uses a technique similar to the “transition_vector” described above.
Such a concert! Thanks for attention! A curtain!..
Wishlist
Dreams that haven't come true yet:
- Support / primary key not only in the parser
- Unary operators
- Subqueries
- Type inference for expressions
- Convenient API for Python
Since this was an educational project, we did not get a penny for it. Although, judging by the statistics of sloc, you could now eat red caviar.
Sloccount report
Have a non-directory at the top, so creating directory top_dir Creating filelist for dropSQL Creating filelist for tests Creating filelist for util Categorizing files. Finding a working MD5 command.... Found a working MD5 command. Computing results. SLOC Directory SLOC-by-Language (Sorted) 2764 dropSQL python=2764 675 tests python=675 28 util python=28 Totals grouped by language (dominant language first): python: 3467 (100.00%) Total Physical Source Lines of Code (SLOC) = 3,467 Development Effort Estimate, Person-Years (Person-Months) = 0.74 (8.85) (Basic COCOMO model, Person-Months = 2.4 * (KSLOC**1.05)) Schedule Estimate, Years (Months) = 0.48 (5.73) (Basic COCOMO model, Months = 2.5 * (person-months**0.38)) Estimated Average Number of Developers (Effort/Schedule) = 1.55 Total Estimated Cost to Develop = $ 99,677 (average salary = $56,286/year, overhead = 2.40). SLOCCount, Copyright (C) 2001-2004 David A. Wheeler SLOCCount is Open Source Software/Free Software, licensed under the GNU GPL. SLOCCount comes with ABSOLUTELY NO WARRANTY, and you are welcome to redistribute it under certain conditions as specified by the GNU GPL license; see the documentation for details. Please credit this data as "generated using David A. Wheeler's 'SLOCCount'." Thanks
- University Innopolis for a cozy environment and cool acquaintances.
- Professor Evgeny Zuev for the course on compilers in general, and for a lecture on parsers in particular
- Professor Manuel Mazzara and TA Ruslan for the course on DBMS. / GodBlessMazzara
And next time we will implement our non-relational, with aggregate pipelines and transactions; and call it - / noDropSQL!
Source: https://habr.com/ru/post/347274/
All Articles