Own pix2code with blackjack, but without neurons
Newton - Leibniz, Lobachevsky - Gauss, Belle - Gray, Bond - Lassel ... These pairs of surnames are united by one thing: they can be given as examples of the so-called multiple discoveries: situations when several scientists or inventors do their work simultaneously and independently.
Something similar happened with my project. A little less than a year ago I began to develop a system for generating HTML - a raster-based layout. Some time passed, and in May 2017, a work entitled pix2code was published , while getting a good spread in specialized media. Time passed, I did not despair, moving on my way. But a terrible thing happened recently: the developers from FloydHub, based on pix2code, created their own neural network , which makes up sites on the basis of pictures. In runet, this news was picked up, and a lot of people became aware of the FloydHub release. And this is the moment when, according to a plan I had predetermined, I had to release my demo. But, as you know, the best is the enemy of the good, and the desire to improve the project “more and more” postponed the release indefinitely.
At that moment I understood: coding is, of course, good, but it is necessary to carry out your work in the light. Meet: The Nutcracker is an alternative to pix2code with blackjack, but, alas, without neurons.
First of all, I want to correct myself. Multiple opening "The Nutcracker" (the history of the name of the project so far out of the brackets), and pix2code can not be called: the implementation of tasks differs radically. But the purpose of both systems coincides a little more than completely: create an algorithm that takes a simple bitmap image as input and returns an acceptable html / css layout, which, on the one hand, will fairly accurately recreate the original drawing, and on the other, it will not cause nausea and even will be quite suitable for further maintenance.
')
I must say that there are already products for solving problems close to those set (I will not give advertising to specific services, but it’s pretty easy to google):
Each of these ways to quickly get a site perfectly copes with the task in certain conditions. More talk about it now does not make sense. I touched on them only in order to more precisely make it clear how I see the purpose of the “img -> html” algorithms, and in what context it is worth considering them.
In the comments to the publications on the work of FloydHub, you can often see something like “bye, layout designers”, “- frontend'ery”, etc. Exactly, this is not true. That pix2code, that Nutcracker, that any other analogue should not be considered as the killer of the profession of a frontend developer. Frontend-developer does not work in a vacuum - there are customer requirements, there are corporate standards, there is logic, there is a professional sense, and in the end, talent. Embed these components in modern AI is impossible.
So why then is it necessary? Let us turn, finally to the point and define the requirements for the Nutcracker. The algorithm must recognize the structure of the image, select as many characteristics of objects in this structure as possible (color, font, indents ...) and generate a code that implements the construction of a recognized structure.
It does not require:
Ideally, it is enough for the algorithm to correctly generate about 85% of the code so that the designer of any qualification could easily add the remaining 15% - right here, specify the font of the text correctly, put the image on the background, and do something untouchable somewhere the main thing is not to fundamentally change the structure of the code, as well as to think about how, for example, to align those three columns in the footer in height.
Once again, in other words, the goal: to automate the work of creating html / css layout, following the obvious elements, leaving the person to either very simple cases where the algorithm is trivially wrong, or nontrivial, giving the opportunity to show their genius.
As I see it, such a model is useful in the following cases:
I will say a few words about your potential competitor. I will make a reservation right away that I respect the work done and I am not even going to “blame” on obviously intelligent and talented people. I will only express my opinion about what they did and, more importantly for the current article, why I did it differently.
The first thought that came to my mind when I just took on the task: "neurons". Well, the truth would seem to be something simpler: take a huge number of pages from the Internet, make a dataset from (roughly speaking) screenshots and the corresponding html-code, build a neuron ... better a recurrent neuron ..., no, better a Bayesian neuron ..., no, better neuron composition ... yes, a lot of neurons, deep-very deep. We set on the training sample - profit! So?
So, yes, not so. The more I walked this path, the more I saw problems. The problems are not technical, but rather conceptual. Let's start by compiling a training sample. As you know, not a single volume strongly machine learning. Of course, for the successful application of deep learning, the sample must be significantly large. But it is equally important that it be representative. But with this there are problems. I think that I’m not mistaken if I say that 90% of sites have layout, which ... to put it mildly, I don’t want to borrow. Even more, the situation is complicated by the fact that visually similar sites can have syntactically fundamentally different layout. How to be in this situation? To make separate samples for each of the frameworks, for each of the methodology? Generate your own training sample? I understand that there are solutions to these questions, but, in my opinion, the complexity of their implementation exceeds the advantages of using neural networks.
I also want to draw attention to one more thing. Here I risk to fall under the scope of all adherents of machine learning. As written in the introduction of the article describing the work of pix2code, in order to process the input data, neither the process of extracting “engineering” characteristics, nor expert heuristics were designed. It would seem that this is the essence of machine learning: not to rely on the rules previously set by experts, but to start from what is directly in the data, restoring the existing law of nature. But here I am forced to argue. As I said earlier, not everything that the fronted specialist is guided by is incorporated in the markup code. There are other meta-parameters that change over time in the industry, and which need to be monitored to ensure that the quality of the generated code is maintained at the proper level. You can give me an anathema, but I can not refuse in this task from the element of expert heuristics.
However, it must be admitted that the neural networks didn’t lead me away from the path of impossibility or incorrectness of their use, but banal laziness and insufficient qualification of using a powerful and complex tool. On the other hand, I consider the orientation to the means of labor, and not to the goal, to be the most incorrect. Therefore, I decided to start with a more logical path for me, which I will describe below. Perhaps, if I do not give up this job and this really requires a situation, I will apply neural networks.
But back to pix2code and the development of FloydHub. I read all the published material and did not find a solution to the problems that I described above. Well, maybe it is not so important if the code really works? To begin with, I could not get the result on the images, except for those presented in the examples. Given that this is a prototype, you can forgive.
But the most important thing I could not understand. I admit honestly, I didn’t dig deep enough, and I’m grateful if they explain it to me in the comments, but how can I explain that after 550 iterations I get a code that is absolutely identical to the original one? That is completely, 100%. I can understand how the same comments turned out to be there, but absolutely identical names of images along with absolutely identical relative paths make me extremely surprised.
Here I have two thoughts: either this is a fraud (which I really do not want to believe), or this is the most severe retraining that I have seen. Again, I do not have a goal to overthrow the project - I just want to say that this is most likely the result of the fact that the problems that I described at the beginning of the section were not taken into account. I believe that the developers will correct this situation, but at the moment I do not see any refutations of my arguments. The arguments that led me to the architecture that eventually became the foundation of the Nutcracker.
One intelligent person said that when you are looking for a method to solve a problem, find 5-6 popular articles affecting this task, and select the method that is most criticized in these articles. In this article, there will be no modern approaches and amazing know-how. Everything is pretty prosaic and simple. Nevertheless, the more I do it, the more, fortunately, I am convinced of the correctness of the approach.
I decided to push off from understanding the natural process of creating the layout. Let's be honest, most designers use the eternal, one-off and unique copy-paste method. Initially, copy-paste is used in the literal sense. I myself remember how, being a hungry student, I earned my first money, continually typing in google “press the footer to the bottom of the page”, “align the block vertically”, “columns of the same height”. When you meet an unfamiliar block layout pattern, you describe it in natural language in the search box, then you find the example code in the next tutorial, and finally change it to fit your needs. Further, with experience, there are less and less appeals to google, but the principle does not go anywhere: when faced with another pattern, you get a suitable example out of your head and adapt it to the current situation.
In science, such thinking is called precedent. And in IT there is an implementation of this process: case-based reasoning or “reasoning based on precedents”. This method is quite old (however, neural networks also cannot be called a baby), it goes away with history in the 70s of the last century, and, it must be admitted, now it is far from the peak of its development. However, in this situation, it fits perfectly into the described process.
For those who are not familiar with this approach, first, I recommend reading, for example, an article by Janet Kolodner , and second, continuing reading this article.
Describing CBR in one sentence, we can say that this is a way to solve problems by adapting old solutions to similar situations. The key concept of CBR is precedent (case). A precedent is a triple of elements:
Use cases are stored in the repository, or database. Storage, indexing, structure - open questions: you can use any suitable tool.
The most important thing in case-based reasoning is the so-called CBR-cycle. Actually, this cycle is the way to solve problems.
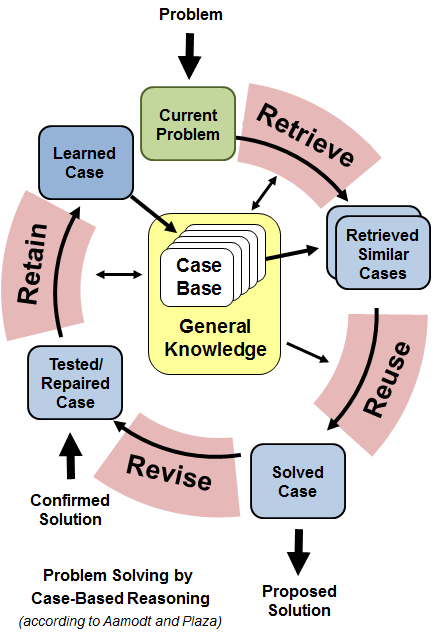
The cycle consists of four steps (four RE):
Before describing exactly how case-based reasoning was used to solve this problem, it is worth describing the overall system architecture.
In a global sense, processing consists of two parts:
The main task of the first stage is to extract all significant blocks from the image and build a tree-like structure with respect to the attachment.
Image processing occurs in several stages:
Collecting such a tree, where each node is a potential dom-element, is the task of the first stage. Each node is described by a set of predefined parameters. Building a tree is not a trivial task at all. However, it must be said that of all the architecture at the moment this stage is best implemented, and if the design was not done by epileptic, then a very accurate description of the image structure is always guaranteed.
When the tree is ready, go to the second stage. We traverse the tree in the prefix way, and we process each node with the help of the cbr-cycle.
It is time to describe the implementation of case based reasoning in Nutcracker in a little more detail.
The precedent in the Nutcracker has the following structure:
The use cases are stored in the json representation in the MongoDB database. I call it the “global repository”. There is also local storage - about it a little later. In the global repository, use cases only have a problem and a solution. There is no result - after all, it appears only when the template is applied to a specific situation.
And here we have a json object describing the structure of the image, as well as a database of precedents that contain information on how to impose each node. As I said earlier, tree traversal is prefix, that is, we start from the root. We take the properties of the root itself, we add to it the properties of the closest descendants - here we have a problem.
The extraction stage has arrived. We need to find a precedent with the most similar problem. Here the scope for creativity of ml-specialist unfolds. In fact, we have a classic multi-class classification problem: there are object properties, and there are n classes (n use cases in the database). It is required to attribute an object unfamiliar to us to one of the classes. Want to try logistic regression? Why not! Perhaps, RandomForest would be better? Quite possibly! In the end, nobody canceled neural networks!
But at the first iteration I managed ... with the k-nearest-neighbor method. Moreover, k is equal to 1. You have correctly understood everything: I simply use the Euclidean measure and find the nearest object. Already, I come across all the drawbacks of such a simple approach, but it more than allows achieving acceptable quality and not getting stuck at this moment, but gradually moving on all fronts and bringing the overall picture to the end.
Having obtained the closest precedent, we now need to adapt its solution for the node being processed. There are several tasks here:
According to the canons of case based reasoning, the next step is to evaluate the result obtained. And here, I confess, I was stumped. How to estimate that the layout turned out really the one that is required? What criteria can you come up with? The tormenting torment and search for insight led me to write in the function “return true” and move on. I have not yet implemented the assessment. And something tells me that I may never realize it: it will be enough to make a good classifier at the extraction stage and a suitable adaptation.
The last step is saving. The precedent, which initially contained only the problem, now got its solution and result. It must be recorded in the repository, so that later on the basis of it it would be possible to more easily put together a similar block. But here I came up with a trick. The precedent is not recorded in the “global repository”, but in the local one. Local storage is a kind of context for a particular image. It contains blocks that are already present in the current document. This allows, firstly, it is easier to find similar precedents, secondly, to spend less resources on adaptation and to minimize errors in general, when the same structure is made up differently. When processing the next tree node, an attempt will be made to retrieve a similar problem first from the local storage, and only then, if nothing like this could be found, the algorithm will go to the global storage.
If we describe all these steps less formally, then the essence boils down to something like this:
Tired of letters? Now there will be pictures. And the code.
Personally, I move from simple to complex. Take a deliberately complex site with a bunch of elements - so you can kill your psyche and lose nights of sleep, raking the results and causes of failures. Therefore, my “Hello World” is, in essence, a modular grid of a typical site.

I prepared this layout: a site with a fixed content width, a rubber cap, a basement pressed to the bottom of the page, and a sidebar. Let's see how the Nutcracker will cope with it.
The first stage is the recognition of the structure. The result is:
The key properties here are type (can be node, text, or image) and alignment (0 - the children are horizontal, 1 is vertical). You can analyze json yourself, but for clarity, I displayed which tree the algorithm built (the background colors of the blocks correspond to the color of the circle, the black circles are compositional blocks, the number in the circle corresponds to the alignment parameter):

We begin bypassing the tree. We form a problem from the root node description:
In the database of precedents, a precedent search is performed with the most similar problem. The following precedent is extracted:
As we see, in order to generate the html code, it is necessary to get the content property from the children, and this can be done only by processing each of the children in the same way as the current node. Therefore, we go around the tree further until we reach all the leaves whose content is an empty string.
As for css, all the generated code from the template is written to a single file, conflicts are handled simultaneously.
The result was the following code (a large image was processed, respectively, such large values were obtained):
At the moment, the Nutcracker handles the following tasks:
In the near future it is planned to implement:
In my opinion, it turns out quite promising system, which has many points of growth. Even with the most primitive methods, the Nutcracker copes with simple tasks. If you pack it with smarter methods, both in terms of image recognition, and when extracting the nearest precedents, the program will be fully capable of working with the overwhelming part of the design layouts.
Another nice feature is the layout variation. Having several versions of use case databases, you can force the Nutcracker to typeset, for example, using the bem-methodology, or use a specific version's bootstrap. And even companies can put their corporate standards in it, and he will not only type himself as an employee of the company, but also it will be possible to evaluate how this or that imposition follows standards by comparing with the generated code.
It may seem that filling out such a base is a very time consuming process. With this, of course, it is difficult to argue, but personally I assume that about 100 precedents will be enough to cover most of the tasks. And to fill such a volume, in principle, commensurate with the time on a typical project. Thus, frontend-specialists will be able, once, by investing time to fill the base, then dramatically increase their productivity.
One of the goals of the article is to get feedback from the community. Now I have a clear feeling that, having dug deep into this project, I may not see the woods behind the trees. Therefore, I would be grateful for constructive and even not very constructive criticism in the comments.
Something similar happened with my project. A little less than a year ago I began to develop a system for generating HTML - a raster-based layout. Some time passed, and in May 2017, a work entitled pix2code was published , while getting a good spread in specialized media. Time passed, I did not despair, moving on my way. But a terrible thing happened recently: the developers from FloydHub, based on pix2code, created their own neural network , which makes up sites on the basis of pictures. In runet, this news was picked up, and a lot of people became aware of the FloydHub release. And this is the moment when, according to a plan I had predetermined, I had to release my demo. But, as you know, the best is the enemy of the good, and the desire to improve the project “more and more” postponed the release indefinitely.
At that moment I understood: coding is, of course, good, but it is necessary to carry out your work in the light. Meet: The Nutcracker is an alternative to pix2code with blackjack, but, alas, without neurons.
First of all, I want to correct myself. Multiple opening "The Nutcracker" (the history of the name of the project so far out of the brackets), and pix2code can not be called: the implementation of tasks differs radically. But the purpose of both systems coincides a little more than completely: create an algorithm that takes a simple bitmap image as input and returns an acceptable html / css layout, which, on the one hand, will fairly accurately recreate the original drawing, and on the other, it will not cause nausea and even will be quite suitable for further maintenance.
')
Purpose of the Nutcracker
I must say that there are already products for solving problems close to those set (I will not give advertising to specific services, but it’s pretty easy to google):
- Generate html from PSD. It would seem that the ideal scheme for the world of site building: the designer makes the layout in Photoshop - the programmer gets the html-code. The problem is that the quality of such a layout should be of the appropriate level: the designer must understand how the page is being made up, and invest this understanding in the logic of building his own layout. In fact, a well-designed psd layout is a half-folded site. In a perfect world, such web designer skills are basic. In the real world, unfortunately, the share of designers of such competence leaves much to be desired.
- Site builder. A person without programming experience enters the program and drag & drop throws in elements, resulting in a real web site with fashionable styles, working scripts and all the charms of the modern web. Perhaps even adaptive. Perhaps even cross-browser. Cons, I think you know everything yourself. Omit even the quality of the code and the complexity of its further support. The biggest problem I see here is the mixing of roles. Imagining that a designer will exchange His Majesty Photoshop for dubious designers is as difficult as imagining a building architect who creates layouts with LEGO. So it turns out that instead of the work of a team of professionals, the site is created by “Myself a designer / frontend / seo-specialist”.
- Templating sites. Modified version of the constructor. Choose a template - fill in the fields - that's it. Due to the determinism one can expect a good quality of the code. But the choice, you know, is limited.
Each of these ways to quickly get a site perfectly copes with the task in certain conditions. More talk about it now does not make sense. I touched on them only in order to more precisely make it clear how I see the purpose of the “img -> html” algorithms, and in what context it is worth considering them.
In the comments to the publications on the work of FloydHub, you can often see something like “bye, layout designers”, “- frontend'ery”, etc. Exactly, this is not true. That pix2code, that Nutcracker, that any other analogue should not be considered as the killer of the profession of a frontend developer. Frontend-developer does not work in a vacuum - there are customer requirements, there are corporate standards, there is logic, there is a professional sense, and in the end, talent. Embed these components in modern AI is impossible.
So why then is it necessary? Let us turn, finally to the point and define the requirements for the Nutcracker. The algorithm must recognize the structure of the image, select as many characteristics of objects in this structure as possible (color, font, indents ...) and generate a code that implements the construction of a recognized structure.
It does not require:
- recognize all attributes
- recreate pixel-in-pixel image
Ideally, it is enough for the algorithm to correctly generate about 85% of the code so that the designer of any qualification could easily add the remaining 15% - right here, specify the font of the text correctly, put the image on the background, and do something untouchable somewhere the main thing is not to fundamentally change the structure of the code, as well as to think about how, for example, to align those three columns in the footer in height.
Once again, in other words, the goal: to automate the work of creating html / css layout, following the obvious elements, leaving the person to either very simple cases where the algorithm is trivially wrong, or nontrivial, giving the opportunity to show their genius.
As I see it, such a model is useful in the following cases:
- Web agencies in times of big dam - cheaper and faster than hiring the next junior or outsourcing;
- for prototyping and / or "testing" the design - it is possible to more flexibly test frontend solutions;
- “I want a site like they have” - yes, yes, any stick has two ends, including not the risk of increased theft, but such moments must be foreseen.
Little bit about pix2code
I will say a few words about your potential competitor. I will make a reservation right away that I respect the work done and I am not even going to “blame” on obviously intelligent and talented people. I will only express my opinion about what they did and, more importantly for the current article, why I did it differently.
The first thought that came to my mind when I just took on the task: "neurons". Well, the truth would seem to be something simpler: take a huge number of pages from the Internet, make a dataset from (roughly speaking) screenshots and the corresponding html-code, build a neuron ... better a recurrent neuron ..., no, better a Bayesian neuron ..., no, better neuron composition ... yes, a lot of neurons, deep-very deep. We set on the training sample - profit! So?
So, yes, not so. The more I walked this path, the more I saw problems. The problems are not technical, but rather conceptual. Let's start by compiling a training sample. As you know, not a single volume strongly machine learning. Of course, for the successful application of deep learning, the sample must be significantly large. But it is equally important that it be representative. But with this there are problems. I think that I’m not mistaken if I say that 90% of sites have layout, which ... to put it mildly, I don’t want to borrow. Even more, the situation is complicated by the fact that visually similar sites can have syntactically fundamentally different layout. How to be in this situation? To make separate samples for each of the frameworks, for each of the methodology? Generate your own training sample? I understand that there are solutions to these questions, but, in my opinion, the complexity of their implementation exceeds the advantages of using neural networks.
I also want to draw attention to one more thing. Here I risk to fall under the scope of all adherents of machine learning. As written in the introduction of the article describing the work of pix2code, in order to process the input data, neither the process of extracting “engineering” characteristics, nor expert heuristics were designed. It would seem that this is the essence of machine learning: not to rely on the rules previously set by experts, but to start from what is directly in the data, restoring the existing law of nature. But here I am forced to argue. As I said earlier, not everything that the fronted specialist is guided by is incorporated in the markup code. There are other meta-parameters that change over time in the industry, and which need to be monitored to ensure that the quality of the generated code is maintained at the proper level. You can give me an anathema, but I can not refuse in this task from the element of expert heuristics.
However, it must be admitted that the neural networks didn’t lead me away from the path of impossibility or incorrectness of their use, but banal laziness and insufficient qualification of using a powerful and complex tool. On the other hand, I consider the orientation to the means of labor, and not to the goal, to be the most incorrect. Therefore, I decided to start with a more logical path for me, which I will describe below. Perhaps, if I do not give up this job and this really requires a situation, I will apply neural networks.
But back to pix2code and the development of FloydHub. I read all the published material and did not find a solution to the problems that I described above. Well, maybe it is not so important if the code really works? To begin with, I could not get the result on the images, except for those presented in the examples. Given that this is a prototype, you can forgive.
But the most important thing I could not understand. I admit honestly, I didn’t dig deep enough, and I’m grateful if they explain it to me in the comments, but how can I explain that after 550 iterations I get a code that is absolutely identical to the original one? That is completely, 100%. I can understand how the same comments turned out to be there, but absolutely identical names of images along with absolutely identical relative paths make me extremely surprised.
Here I have two thoughts: either this is a fraud (which I really do not want to believe), or this is the most severe retraining that I have seen. Again, I do not have a goal to overthrow the project - I just want to say that this is most likely the result of the fact that the problems that I described at the beginning of the section were not taken into account. I believe that the developers will correct this situation, but at the moment I do not see any refutations of my arguments. The arguments that led me to the architecture that eventually became the foundation of the Nutcracker.
Architecture
One intelligent person said that when you are looking for a method to solve a problem, find 5-6 popular articles affecting this task, and select the method that is most criticized in these articles. In this article, there will be no modern approaches and amazing know-how. Everything is pretty prosaic and simple. Nevertheless, the more I do it, the more, fortunately, I am convinced of the correctness of the approach.
I decided to push off from understanding the natural process of creating the layout. Let's be honest, most designers use the eternal, one-off and unique copy-paste method. Initially, copy-paste is used in the literal sense. I myself remember how, being a hungry student, I earned my first money, continually typing in google “press the footer to the bottom of the page”, “align the block vertically”, “columns of the same height”. When you meet an unfamiliar block layout pattern, you describe it in natural language in the search box, then you find the example code in the next tutorial, and finally change it to fit your needs. Further, with experience, there are less and less appeals to google, but the principle does not go anywhere: when faced with another pattern, you get a suitable example out of your head and adapt it to the current situation.
In science, such thinking is called precedent. And in IT there is an implementation of this process: case-based reasoning or “reasoning based on precedents”. This method is quite old (however, neural networks also cannot be called a baby), it goes away with history in the 70s of the last century, and, it must be admitted, now it is far from the peak of its development. However, in this situation, it fits perfectly into the described process.
For those who are not familiar with this approach, first, I recommend reading, for example, an article by Janet Kolodner , and second, continuing reading this article.
Describing CBR in one sentence, we can say that this is a way to solve problems by adapting old solutions to similar situations. The key concept of CBR is precedent (case). A precedent is a triple of elements:
- problem - the state of the world that you want to "resolve",
- the solution is actually the method of fixing the problem,
- the result is a state of peace after the problem is resolved.
Use cases are stored in the repository, or database. Storage, indexing, structure - open questions: you can use any suitable tool.
The most important thing in case-based reasoning is the so-called CBR-cycle. Actually, this cycle is the way to solve problems.
The cycle consists of four steps (four RE):
- retrieve: the closest (similar) precedent for the problem in question is extracted from the case database,
- adaptation (reuse): the extracted solution is adapted to better fit the new problem,
- assessment (revise): an adapted solution can be evaluated either before its application or after; in any case, if the solution did not fit, then it must be adapted once again, or additional solutions must be extracted,
- save (retain): if the solution passed the test successfully, a new precedent is added to the database.
Before describing exactly how case-based reasoning was used to solve this problem, it is worth describing the overall system architecture.
In a global sense, processing consists of two parts:
- Image recognition
- Generate html code
The main task of the first stage is to extract all significant blocks from the image and build a tree-like structure with respect to the attachment.
Image processing occurs in several stages:
- All text is recognized (here tesseract comes to the rescue), all properties associated with it are retrieved - font, color, size, style, etc. - and then it is completely erased with a background color so as not to interfere further.
- All images are retrieved - i.e. everything that later becomes either an img tag or a background image of blocks. They are also overwritten.
- Finally, all blocks are recognized, from which a hierarchy will be assembled, or in other words, a tree.
Collecting such a tree, where each node is a potential dom-element, is the task of the first stage. Each node is described by a set of predefined parameters. Building a tree is not a trivial task at all. However, it must be said that of all the architecture at the moment this stage is best implemented, and if the design was not done by epileptic, then a very accurate description of the image structure is always guaranteed.
When the tree is ready, go to the second stage. We traverse the tree in the prefix way, and we process each node with the help of the cbr-cycle.
It is time to describe the implementation of case based reasoning in Nutcracker in a little more detail.
The precedent in the Nutcracker has the following structure:
- Problem: a set of node properties, as well as properties of its closest descendants in json-format.
- Solution: jinja2 html template and css code that implements the layout of the described structure.
- Result: html and css code that was generated from the solution-template for a specific case.
The use cases are stored in the json representation in the MongoDB database. I call it the “global repository”. There is also local storage - about it a little later. In the global repository, use cases only have a problem and a solution. There is no result - after all, it appears only when the template is applied to a specific situation.
And here we have a json object describing the structure of the image, as well as a database of precedents that contain information on how to impose each node. As I said earlier, tree traversal is prefix, that is, we start from the root. We take the properties of the root itself, we add to it the properties of the closest descendants - here we have a problem.
The extraction stage has arrived. We need to find a precedent with the most similar problem. Here the scope for creativity of ml-specialist unfolds. In fact, we have a classic multi-class classification problem: there are object properties, and there are n classes (n use cases in the database). It is required to attribute an object unfamiliar to us to one of the classes. Want to try logistic regression? Why not! Perhaps, RandomForest would be better? Quite possibly! In the end, nobody canceled neural networks!
But at the first iteration I managed ... with the k-nearest-neighbor method. Moreover, k is equal to 1. You have correctly understood everything: I simply use the Euclidean measure and find the nearest object. Already, I come across all the drawbacks of such a simple approach, but it more than allows achieving acceptable quality and not getting stuck at this moment, but gradually moving on all fronts and bringing the overall picture to the end.
Having obtained the closest precedent, we now need to adapt its solution for the node being processed. There are several tasks here:
- From the template on jinja2 get the real code.
- Process css-classes: most likely, in the previous steps we have already encountered classes with this name. There are several options for how to handle this situation: either create a completely new class, and make the necessary replacements in html; or create another class that specifies the properties of the object, and in html add it where necessary; either understand that this is a special case of the previous result and do nothing at all - and so everything is wonderful.
According to the canons of case based reasoning, the next step is to evaluate the result obtained. And here, I confess, I was stumped. How to estimate that the layout turned out really the one that is required? What criteria can you come up with? The tormenting torment and search for insight led me to write in the function “return true” and move on. I have not yet implemented the assessment. And something tells me that I may never realize it: it will be enough to make a good classifier at the extraction stage and a suitable adaptation.
The last step is saving. The precedent, which initially contained only the problem, now got its solution and result. It must be recorded in the repository, so that later on the basis of it it would be possible to more easily put together a similar block. But here I came up with a trick. The precedent is not recorded in the “global repository”, but in the local one. Local storage is a kind of context for a particular image. It contains blocks that are already present in the current document. This allows, firstly, it is easier to find similar precedents, secondly, to spend less resources on adaptation and to minimize errors in general, when the same structure is made up differently. When processing the next tree node, an attempt will be made to retrieve a similar problem first from the local storage, and only then, if nothing like this could be found, the algorithm will go to the global storage.
If we describe all these steps less formally, then the essence boils down to something like this:
- We look at the layout from the point of view of the highest level of abstraction.
- We see that, for example, this is a three-column layout. We ask ourselves how to impose such a layout?
- We are looking for the most suitable case in the case database.
- Get the template html and css.
- Substitute the concrete values of the considered case into this template (width, color, indents, etc.).
- Next, recursively process each of the children:
- So, what we have here ... In the left column are five blocks, arranged vertically. How is it to make up? We look at the database ...
- ...
- In the central block we see three blocks located vertically, the first occupies 20% of the height, the second - 70%, the third - 10%
- etc.
- So, what we have here ... In the left column are five blocks, arranged vertically. How is it to make up? We look at the database ...
Example
Tired of letters? Now there will be pictures. And the code.
Personally, I move from simple to complex. Take a deliberately complex site with a bunch of elements - so you can kill your psyche and lose nights of sleep, raking the results and causes of failures. Therefore, my “Hello World” is, in essence, a modular grid of a typical site.
I prepared this layout: a site with a fixed content width, a rubber cap, a basement pressed to the bottom of the page, and a sidebar. Let's see how the Nutcracker will cope with it.
The first stage is the recognition of the structure. The result is:
Recognized image structure
{ "width": 2560, "margin_bottom": null, "the_same_bkgr_as_parent": null, "margin_left": null, "depth": 1, "children_amount": 2, "width_portion": 1.0, "height": 1450, "padding_right": 0, "height_portion": 1.0, "alignment": 1, "background": null, "margin_top": null, "children_proportion": [ 0.12275862068965518, 0.8772413793103448 ], "relative_position": null, "children": [ { "width": 2560, "margin_bottom": 0, "the_same_bkgr_as_parent": false, "margin_left": 0, "depth": 2, "children_amount": 0, "width_portion": 1.0, "height": 178, "padding_right": null, "height_portion": 0.12275862068965518, "alignment": null, "background": [ 252, 13, 28 ], "margin_top": 0, "children_proportion": null, "relative_position": [ 0.0, 0.0, 1.0, 0.12275862068965518 ], "children": [], "padding_bottom": null, "margin_right": 0, "padding_top": null, "font_weight": null, "the_same_bkgr_as_global": false, "type": "node", "padding_left": null }, { "width": 2560, "margin_bottom": 0, "the_same_bkgr_as_parent": true, "margin_left": 0, "depth": 2, "children_amount": 3, "width_portion": 1.0, "height": 1272, "padding_right": 0, "height_portion": 0.8772413793103448, "alignment": 0, "background": null, "margin_top": 0, "children_proportion": [ 0.1171875, 0.765625, 0.1171875 ], "relative_position": [ 0.0, 0.12275862068965518, 1.0, 1.0 ], "children": [ { "width": 300, "margin_bottom": 0, "the_same_bkgr_as_parent": false, "margin_left": 0, "depth": 3, "children_amount": 0, "width_portion": 0.1171875, "height": 1272, "padding_right": null, "height_portion": 0.8772413793103448, "alignment": null, "background": [ 255, 255, 255 ], "margin_top": 0, "children_proportion": null, "relative_position": [ 0.0, 0.0, 0.1171875, 1.0 ], "children": [], "padding_bottom": null, "margin_right": 0, "padding_top": null, "font_weight": null, "the_same_bkgr_as_global": true, "type": "node", "padding_left": null }, { "width": 1960, "margin_bottom": 0, "the_same_bkgr_as_parent": true, "margin_left": 0, "depth": 3, "children_amount": 2, "width_portion": 0.765625, "height": 1272, "padding_right": 0, "height_portion": 0.8772413793103448, "alignment": 1, "background": null, "margin_top": 0, "children_proportion": [ 0.8742138364779874, 0.12578616352201258 ], "relative_position": [ 0.1171875, 0.0, 0.8828125, 1.0 ], "children": [ { "width": 1960, "margin_bottom": 0, "the_same_bkgr_as_parent": false, "margin_left": 0, "depth": 4, "children_amount": 1, "width_portion": 0.765625, "height": 1112, "padding_right": 1560, "height_portion": 0.766896551724138, "alignment": 0, "background": [ 128, 128, 128 ], "margin_top": 0, "children_proportion": [ 0.20408163265306123 ], "relative_position": [ 0.0, 0.0, 1.0, 0.8742138364779874 ], "children": [ { "width": 400, "margin_bottom": 112, "the_same_bkgr_as_parent": false, "margin_left": 0, "depth": 5, "children_amount": 0, "width_portion": 0.15625, "height": 1000, "padding_right": null, "height_portion": 0.6896551724137931, "alignment": null, "background": [ 14, 126, 18 ], "margin_top": 0, "children_proportion": null, "relative_position": [ 0.0, 0.0, 0.20408163265306123, 0.8992805755395683 ], "children": [], "padding_bottom": null, "margin_right": 1560, "padding_top": null, "font_weight": null, "the_same_bkgr_as_global": false, "type": "node", "padding_left": null } ], "padding_bottom": 112, "margin_right": 0, "padding_top": 0, "font_weight": null, "the_same_bkgr_as_global": false, "type": "node", "padding_left": 0 }, { "width": 1960, "margin_bottom": 0, "the_same_bkgr_as_parent": false, "margin_left": 0, "depth": 4, "children_amount": 0, "width_portion": 0.765625, "height": 160, "padding_right": null, "height_portion": 0.1103448275862069, "alignment": null, "background": [ 11, 36, 251 ], "margin_top": 0, "children_proportion": null, "relative_position": [ 0.0, 0.8742138364779874, 1.0, 1.0 ], "children": [], "padding_bottom": null, "margin_right": 0, "padding_top": null, "font_weight": null, "the_same_bkgr_as_global": false, "type": "node", "padding_left": null } ], "padding_bottom": 0, "margin_right": 0, "padding_top": 0, "font_weight": null, "the_same_bkgr_as_global": false, "type": "node", "padding_left": 0 }, { "width": 300, "margin_bottom": 0, "the_same_bkgr_as_parent": false, "margin_left": 0, "depth": 3, "children_amount": 0, "width_portion": 0.1171875, "height": 1272, "padding_right": null, "height_portion": 0.8772413793103448, "alignment": null, "background": [ 255, 255, 255 ], "margin_top": 0, "children_proportion": null, "relative_position": [ 0.8828125, 0.0, 1.0, 1.0 ], "children": [], "padding_bottom": null, "margin_right": 0, "padding_top": null, "font_weight": null, "the_same_bkgr_as_global": true, "type": "node", "padding_left": null } ], "padding_bottom": 0, "margin_right": 0, "padding_top": 0, "font_weight": null, "the_same_bkgr_as_global": false, "type": "node", "padding_left": 0 } ], "padding_bottom": 0, "margin_right": null, "padding_top": 0, "font_weight": null, "the_same_bkgr_as_global": false, "type": "node", "padding_left": 0 } The key properties here are type (can be node, text, or image) and alignment (0 - the children are horizontal, 1 is vertical). You can analyze json yourself, but for clarity, I displayed which tree the algorithm built (the background colors of the blocks correspond to the color of the circle, the black circles are compositional blocks, the number in the circle corresponds to the alignment parameter):
We begin bypassing the tree. We form a problem from the root node description:
Root node description
{ "width": 2560, "margin_bottom": null, "the_same_bkgr_as_parent": null, "margin_left": null, "depth": 1, "children_amount": 2, "width_portion": 1.0, "height": 1450, "padding_right": 0, "height_portion": 1.0, "alignment": 1, "background": null, "margin_top": null, "children_proportion": [ 0.12275862068965518, 0.8772413793103448 ], "relative_position": null, "children": [ { "width": 2560, "margin_bottom": 0, "the_same_bkgr_as_parent": false, "margin_left": 0, "depth": 2, "children_amount": 0, "width_portion": 1.0, "height": 178, "padding_right": null, "height_portion": 0.12275862068965518, "alignment": null, "background": [ 252, 13, 28 ], "margin_top": 0, "children_proportion": null, "relative_position": [ 0.0, 0.0, 1.0, 0.12275862068965518 ], "children": [], "padding_bottom": null, "margin_right": 0, "padding_top": null, "font_weight": null, "the_same_bkgr_as_global": false, "type": "node", "padding_left": null }, { "width": 2560, "margin_bottom": 0, "the_same_bkgr_as_parent": true, "margin_left": 0, "depth": 2, "children_amount": 3, "width_portion": 1.0, "height": 1272, "padding_right": 0, "height_portion": 0.8772413793103448, "alignment": 0, "background": null, "margin_top": 0, "children_proportion": [ 0.1171875, 0.765625, 0.1171875 ], "relative_position": [ 0.0, 0.12275862068965518, 1.0, 1.0 ], "padding_bottom": 0, "margin_right": 0, "padding_top": 0, "font_weight": null, "the_same_bkgr_as_global": false, "type": "node", "padding_left": 0 } ], "padding_bottom": 0, "margin_right": null, "padding_top": 0, "font_weight": null, "the_same_bkgr_as_global": false, "type": "node", "padding_left": 0 } In the database of precedents, a precedent search is performed with the most similar problem. The following precedent is extracted:
Nearest precedent
{ "_id" : ObjectId("5a1ec4681dbf2cce65357bc4"), "problem" : { "children_proportion" : [ 0.11, 0.89 ], "alignment" : 1, "depth" : 1, "height_portion" : 1.0, "width_portion" : 1.0, "children_amount" : 2, "children" : [ { "relative_position" : [ 0.0, 0.0, 1.0, 0.11 ], "depth" : 2, "height_portion" : 0.11, "width_portion" : 1.0, "the_same_bkgr_as_global" : false }, { "children_proportion" : [ 0.15, 0.7, 0.15 ], "alignment" : 0, "relative_position" : [ 0.0, 0.11, 1.0, 1.0 ], "depth" : 2, "height_portion" : 0.89, "width_portion" : 1.0, "children_amount" : 3, "the_same_bkgr_as_global" : false, "children" : [ { "relative_position" : [ 0.0, 0.0, 0.15, 1.0 ], "depth" : 3, "height_portion" : 0.89, "width_portion" : 0.15, "children_amount" : 0, "the_same_bkgr_as_global" : true }, { "the_same_bkgr_as_parent" : true, "children_proportion" : [ 0.89, 0.11 ], "alignment" : 1, "relative_position" : [ 0.15, 0.0, 0.85, 1.0 ], "depth" : 3, "height_portion" : 0.89, "width_portion" : 0.7, "children_amount" : 2, "the_same_bkgr_as_global" : false }, { "relative_position" : [ 0.85, 0.0, 1.0, 1.0 ], "depth" : 3, "height_portion" : 0.89, "width_portion" : 0.15, "children_amount" : 0, "the_same_bkgr_as_global" : true } ] } ], "the_same_bkgr_as_global" : false }, "solution" : { "html" : "<div class=\"wrapper\"><header>{{ children[0]['content'] }}</header><div class=\"content container\">{{ children[1]['children'][1]['children'][0]['content'] }}</div></div><footer class=\"container\">{{ children[1]['children'][1]['children'][1]['content'] }}</footer>", "css" : "html,body,.wrapper {height: 100%;}.content {box-sizing: border-box;min-height: 100%;padding-top: {{ children[0]['height'] }};padding-bottom: {{ children[0]['height'] }};background:{{ children[1]['children'][1]['children'][0]['background'] }};}header{height: {{ children[0]['height'] }};margin-bottom: -{{ children[0]['height'] }};background:{{ children[0]['background'] }};position:relative;z-index:10;}.container{width:{{ children[1]['children'][1]['width'] }};margin-left: auto;margin-right: auto;}footer {height: {{ children[1]['children'][1]['children'][1]['height'] }};margin-top: -{{ children[1]['children'][1]['children'][1]['height'] }};background:{{ children[1]['children'][1]['children'][1]['background'] }};}" }, "outcome" : null } As we see, in order to generate the html code, it is necessary to get the content property from the children, and this can be done only by processing each of the children in the same way as the current node. Therefore, we go around the tree further until we reach all the leaves whose content is an empty string.
As for css, all the generated code from the template is written to a single file, conflicts are handled simultaneously.
The result was the following code (a large image was processed, respectively, such large values were obtained):
<!DOCTYPE html> <html> <head> <title> </title> <meta charset="utf-8"/> <link href="reset.css" rel="stylesheet" type="text/css"/> <link href="style.css" rel="stylesheet" type="text/css"/> </head> <body> <div class="wrapper"> <header> </header> <div class="content container"> <aside class="left"> </aside> </div> </div> <footer class="container"> </footer> </body> </html> aside.left { background : rgb(14, 126, 18); height : 1000px; width : 400px; float : left; } html,body,.wrapper { height : 100%; } footer { background : rgb(11, 36, 251); height : 160px; margin-top : -160px; } .container { width : 1960px; margin-left : auto; margin-right : auto; } header { background : rgb(252, 13, 28); height : 178px; margin-bottom : -178px; z-index : 10; position : relative; } .content { box-sizing : border-box; min-height : 100%; padding-top : 178px; padding-bottom : 178px; background : rgb(128, 128, 128); } results
At the moment, the Nutcracker handles the following tasks:
- Extract structure from image.
- Recognition of text, font, size, style.
- Extract images from the screenshot.
- Recognize indents and margins.
- Search for the closest precedent.
- Handling conflicts when compiling a css file
In the near future it is planned to implement:
- Borders recognition: color, type, width, rounding.
- Recognition tables.
- Gradient Recognition.
- Handling fixed blocks (display: fixed and display: absolute)
In my opinion, it turns out quite promising system, which has many points of growth. Even with the most primitive methods, the Nutcracker copes with simple tasks. If you pack it with smarter methods, both in terms of image recognition, and when extracting the nearest precedents, the program will be fully capable of working with the overwhelming part of the design layouts.
Another nice feature is the layout variation. Having several versions of use case databases, you can force the Nutcracker to typeset, for example, using the bem-methodology, or use a specific version's bootstrap. And even companies can put their corporate standards in it, and he will not only type himself as an employee of the company, but also it will be possible to evaluate how this or that imposition follows standards by comparing with the generated code.
It may seem that filling out such a base is a very time consuming process. With this, of course, it is difficult to argue, but personally I assume that about 100 precedents will be enough to cover most of the tasks. And to fill such a volume, in principle, commensurate with the time on a typical project. Thus, frontend-specialists will be able, once, by investing time to fill the base, then dramatically increase their productivity.
One of the goals of the article is to get feedback from the community. Now I have a clear feeling that, having dug deep into this project, I may not see the woods behind the trees. Therefore, I would be grateful for constructive and even not very constructive criticism in the comments.
Source: https://habr.com/ru/post/347120/
All Articles