Introduction to modern network balancing and proxying

Recently, I realized the lack of introductory teaching materials about modern network balancing and proxying. I thought, “Why so? Load balancing is one of the key concepts for building reliable distributed systems. After all, should high-quality information about this be available? ”I looked and found that there is little information. Wikipedia articles on balancing and proxy servers contain reviews of some concepts, but they cannot boast of a consistent description of the subject, especially with regard to modern microservice architectures. Google's search for balancing information basically returns vendor sites that are filled with fashionable terms and are stingy for details.
In this article I will try to fill the lack of a gradual introduction to modern network balancing and proxying. Truth be told, this is a voluminous topic worthy of a whole book. And so that the article did not turn out to be dimensionless, I tried to submit a number of difficult tasks in the form of a simple review.
What is network balancing and proxying?
Wikipedia defines load balancing as:
In computing, load balancing improves the distribution of workloads across multiple computing resources: computers, computer clusters, network connections, CPUs, and disk devices. Load balancing is designed to optimize resource utilization, maximize throughput, minimize response time, and avoid overloading individual resources. Using multiple components with balancing instead of one component can increase reliability and availability due to the resulting power reserve. Load balancing usually involves the use of special software or hardware such as a multi-level switch or a DNS server.
This definition applies to all aspects of data processing, and not just to work with the network. Operating systems use balancing to dispatch tasks among multiple physical processors. Container orchestrators like Kubernetes use balancing to dispatch tasks among several compute clusters. And network balancers distribute network tasks among available backends. This article is about network balancing only.

Figure 1: network balancing
Figure 1 shows a simplified network balancing scheme. Some customers request resources from some backends. The balancer is between clients and backends and performs several important tasks:
- Service discovery What backends are available? What are their addresses (i.e. how can the balancer contact them)?
- Check status . What backends are currently working and ready to process requests?
- Balancing . What algorithms are needed for balancing individual requests among normally functioning backends?
Proper use of balancing in a distributed system provides several advantages:
- Abstraction of names . Instead of each client knowing about each backend (discovery of services), clients can contact the balancer through a predefined mechanism, and then the name resolution procedure can be delegated to the balancer. The predefined mechanism includes built-in libraries and well-known DNS / IP / ports. Below we take a closer look at this.
- Resistance to failure . Using state checking and various algorithms, the balancer is able to efficiently route data bypassing failed or overloaded backends. That is, the operator can fix the failed backend at his leisure, and not urgently.
- Reduced cost and increased productivity . Networks of distributed systems are rarely homogeneous. Usually the system is divided into several network zones and regions. Within the network zone, networks are usually built with under-utilization of bandwidth, and between zones, re-use becomes the norm (in this case, re-use and under-use mean the percentage of network card bandwidth to channel width between routers). A smart balancer can keep query traffic within a zone as long as possible, which improves performance (less latency) and reduces overall costs in the system (there are much fewer channels between zones and they can be narrower).
Balancer or proxy?
The terms balancer and proxy are often used interchangeably. In this article, we will also generally consider them to be analogues (strictly speaking, not all proxies are balancers, but the primary function of the overwhelming majority is balancing). Someone might argue that if balancing is part of the built-in client library, then the balancer is not a proxy. But I will answer that such a division unnecessarily complicates an already difficult subject. Below, we will take a closer look at the types of balancers topologies, but in this article the topology of the integrated balancer will be considered a special case of proxying: the application proxies using the built-in library offering the same abstractions as the balancer outside of the application process.
L4 (connect / session) -balancing
Modern balancing solutions for the most part can be divided into two categories: L4 and 7 . They relate to level 4 and level 7 of the OSI model . For reasons that will become apparent during the discussion of L7 balancing, I consider the choice of these terms to be unsuccessful. The OSI model very poorly reflects the complexity of balancing solutions that include not only traditional protocols of the fourth level, such as TCP and UDP, but often elements of protocols of other OSI levels. For example, if the L4 TCP balancer also offers a TLS interrupt, is it now a L7 balancer?

Figure 2: L4 interrupt TCP balancer
Figure 2 reflects the traditional L4 TCP balancer . In this case, the client creates a TCP connection to the balancer, the client interrupts the connection (i.e., responds directly to the SYN), selects the backend and creates a new connection to this backend (that is, sends data to the new SYN). The details of the scheme are not so important now; we will discuss them in the section on L4 balancing.
The key point is that the L4 balancer usually operates only at the L4 level of TCP / UDP connections / sessions. Consequently, the balancer moves the bytes so that the bytes from one session arrive on one backend. Such a balancer is unimportant features of applications, whose bytes it manipulates. These can be bytes of HTTP, Redis, MongoDB, or any other application protocol.
L7 (applications) -balancing
L4 balancing is simple and widely used. What are its features make investing in L7-balancing at the application level? Consider the specific case of L4 as an example:
- Two gRPC / HTTP2 clients want to communicate with the backend and connect through an L4 balancer.
- The L4 balancer creates one outgoing TCP connection for each incoming TCP connection, so that two incoming and two outgoing.
- But client A sends 1 request per minute (RPM) through its connection, while client B sends 50 requests per second (RPS).
If the backend decides to handle the traffic of client A, then it will handle the load about 3000 times less than if it were processing the traffic of client B! This is a big problem, due to which the meaning of balancing is lost in the first place. Also note that the problem is valid for any multiplexing protocol that supports persistent connections (keep-alive) (multiplexing is sending competitive application requests through one L4 connection, and keep-alive is maintaining connection in the absence of active requests). All modern protocols are simultaneously multiplexing and supporting permanent connections, this requires efficiency considerations (in general, creating a connection is expensive, especially if it is encrypted using TLS), so the load mismatch in the L4 balancer increases over time. This problem is solved with the help of the L7-balancer.
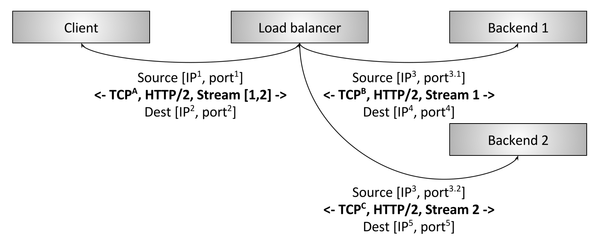
Figure 3: interrupt L7 HTTP / 2 balancer
Figure 3 shows the L7 HTTP / 2 balancer. In this case, the client creates one HTTP / 2 TCP connection to the balancer, which then creates two connections to the backends. When a client sends two HTTP / 2 streams to the balancer, the first stream goes to backend 1, and the second goes to backend 2. So even multiplexed clients with very different request traffic will be effectively balanced across backends. Therefore, L7-balancing is so important for modern protocols (it has a lot of advantages due to the ability to inspect application traffic, but we'll discuss this later).
L7 balancing and OSI model
As mentioned above, it is problematic to use the OSI model to describe the properties of balancing. The reason is that L7, at least according to the OSI model, itself covers several discrete levels of balancing abstraction. For example, for HTTP traffic there are several sublevels:
- Optional Transport Layer Security (TLS). Please note that network specialists argue about which OSI layer TLS belongs to. Here we will refer TLS to L7.
- Physical HTTP protocol (HTTP / 1 or HTTP / 2).
- Logical HTTP protocol (headers, body and trailers).
- Message protocol (gRPC, REST, etc.).
The sophisticated L7 balancer works with all these sublevels. A simpler L7 balancer may have only a small set of properties for which it is referred to as L7. In other words, the properties of L7 balancers vary much more widely than in category L4. And of course, here we touched only HTTP, but Redis, Kafka, MongoDB and others are all examples of L7 protocols of applications that benefit from the use of L7 balancing.
Balancer properties
Here we briefly review the basic properties of balancers. Not all balancers are characterized by all the mentioned properties.
Definition of services
Defining services is a way for the balancer to determine the set of available backends. This can be done in different ways, for example, using:
- Static configuration file.
- DNS.
- Zookeeper , Etcd , Consul , etc.
- Universal API data transfer level development of Envoy.
Condition check
This is a definition of whether the backend can handle traffic. Status check happens:
- Active : the balancer regularly pings backends (for example, sends HTTP requests to the end point
/healthcheck). - Passive : the balancer determines the status of the backend on the primary data stream. For example, the L4 balancer may decide that the backend fails after three connection errors in a row. And the L7 balancer will consider the backend to fail if there were three HTTP 503 responses in a row.
Balancing
Yes, balancers should still balance the load! How will the backend be selected to handle a specific connection or request if there are working backends? Balancing algorithms are an area of active research; they range from as simple as random and round-robin to more complex, taking into account differences in latency and backend loads. One of the most popular algorithms due to its performance and simplicity is power of 2 .
Sticky sessions
For certain applications, it is important that requests from one session fall on the same backend. This is due to caching, temporary complex state and other things. There are different definitions of the term “session”, it may include HTTP cookies, client connection properties and other attributes. Many L7 balancers support sticky sessions. I note that the “stickiness” of the session is inherently fragile (the backend hosting the session may die), so keep your ears open while designing a system that relies on sticky sessions.
TLS interrupt
The topic of TLS and its role in processing and ensuring the security of inter-service interaction deserves a separate article. Many L7 balancers perform a large amount of TLS processing, including interrupts, checking and securing certificates, servicing certificates using SNI , etc.
Observability
As I like to repeat: "Observability, observability, observability." Networks are a priori unreliable, and the balancer is often responsible for exporting statistics, tracking and logging: it helps the operator understand what is happening and fix the problem. Balancers have a variety of possibilities for providing results of monitoring the system. The most advanced provide extensive data, including numeric statistics, distributed tracing, and custom logging. I note that advanced observability does not come for free: balancers have to perform additional work. However, the benefits of the resulting data far outweigh the relatively small performance degradation.
Security and DoS mitigation
Balancers often implement various security functions, especially in the edge topology of deployment (see below), including speed limits, authentication and reduction of DoS consequences (for example, marking and identification of IP addresses, tarpitting , etc.).
Configuration and Management Level
Balancers need to be configured. In large deployments, this becomes an important duty. The system that configures the balancers is called the control plane, which can be implemented in different ways. For details, see the article .
And much more
We just walked on the surface of the balancers functionality theme. We will talk more about this in the part dedicated to L7-balancers.
Types of balancers topologies
We now turn to the topologies of distributed systems in which balancers are deployed. Each topology applies to both L4 and L7.
Intermediate Proxy

Figure 4: intermediate proxy balancer topology
The intermediate proxy topology shown in Figure 4 is one of the most well-known balancing techniques. Such balancers include Cisco, Juniper, F5, and other hardware solutions; cloud software solutions like Amazon ALB and NLB , Google Cloud Load Balancer ; pure software standalone solutions like HAProxy , NGINX and Envoy . The advantage of an intermediate proxy scheme is simplicity. Users connect to the balancer via DNS and are not worried about anything else. A disadvantage of the scheme is that the proxy (even clustered) is a single point of failure, as well as a bottleneck when scaling. In addition, an intermediate proxy is often a black box, which makes it difficult to operate. Did the problem occur on the client? In the physical network? In the proxy itself? In the backend? Sometimes it is very difficult to determine.
Terminal proxy

Figure 5: balancer topology with terminal proxy
The topology in Figure 5 is a variant of the topology with an intermediate proxy in which the balancer is available via the Internet. And in this case, the balancer usually provides additional “API gateway” features like TLS interrupts, speed limits, authentication, and advanced traffic routing. The advantages and disadvantages are the same as in the previous topology. It is usually impossible to avoid using a top proxy topology in large, open-source distributed systems. As a rule, clients need access to the system via DNS using various network libraries that are not controlled by the owner of the service (it is not advisable to use built-in client libraries or side-proxy topologies described in the following sections directly on clients). In addition, for security reasons, it is better to have a single gateway through which all Internet traffic enters the system.
Built-in client library
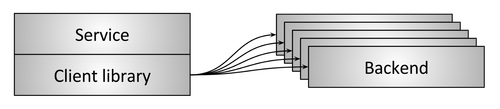
Figure 6: Balancing through the built-in client library
To avoid a single point of failure or problems with scaling inherent in topologies with an intermediate proxy, in more complex infrastructures, embedding the balancer by means of the library directly into the services is used, as shown in Figure 6 . Libraries support various functions, the most famous and advanced solutions are Finagle , Eureka / Ribbon / Hystrix and gRPC (based on Google’s internal system called Stubby). The main advantage of the library-based solution is that the balancer functionality is fully distributed across all clients, which means there is no single point of failure and scaling difficulties. The main disadvantage is that the library must be implemented in every language used by the organization. Distributed architectures become real polyglots (multilingual). In such an environment, the main obstacle is the cost of implementing an extremely complex network library in many languages. Finally, deploying a library update in a large service architecture turns into a huge headache, and as a result, a bunch of different versions of the library usually work in production, which increases the operational cognitive load.
Considering the above, it is advisable to use libraries in companies that can limit the diversity of programming languages and overcome the difficulties of updating the library.
Side proxy

Figure 7: Side Proxy Balancing
Side proxy topology is a topology variant with a built-in client library. In recent years, this topology has been popularized as a service mesh. The idea is that you can get all the benefits of the version with the built-in library without any problems with programming languages, but at the expense of a small increase in the delay in the transition to another process. Today, the most popular side proxy balancers are Envoy , NGINX , HAProxy , and Linkerd . You can read more about the approach in my article on Envoy , as well as in the article on the service mesh data level and management level .
Advantages and disadvantages of different topologies
- An intermediate proxy topology is usually the easiest to use. Its drawbacks: a single point of failure, the difficulty of scaling and working with a black box.
- Topology with a terminal proxy is similar to the previous one, but usually it has to be used.
- Topology with a built-in client library has better performance and scalability, but suffers from the need to implement the library in each language and update the library across all services.
- A side proxy topology does not work as well as the previous one, but does not have its limitations.
I believe that the topology with a side proxy (service mesh) in the interservice interaction will gradually replace all other topologies. A scheme with a terminal proxy will always be needed before traffic enters the service mesh.
Current L4 Balancing Advances
Are L4 balancers still relevant?
We have already talked about the advantages of L7-balancers for modern protocols, and we will discuss their possibilities in more detail below. Does this mean that L4 balancers are no longer relevant? Not! Although I believe that L7 balancers will completely replace L4 in interservice interaction , however L4 balancers are still very relevant at the ends of the network, because almost all modern large distributed architectures use two-tier L4 / L7 balancing for Internet traffic. Here are the advantages of placing dedicated L4 balancers over L7 balancers at the ends:
- Since L7 balancers perform significantly more complex analysis, conversion, and routing of application traffic, they can handle relatively small amounts of traffic (packets per second and bytes per second) compared to an optimized L4 balancer. Therefore, it is better to use L4 for protection against certain types of DoS-attacks (for example, SYN-streams, common attacks by packet streams, etc.).
- L7 balancers are more actively developed, more often deployed and have more bugs than L4 balancers. The presence of an L4 balancer that checks the state of backends and diverts traffic during the deployment of an L7 balancer is much simpler than the deployment mechanisms in modern L4 balancers, which usually use BGP and ECMP (more below). Finally, since L7-balancers have a higher probability of bugs due to complexity, an L4-balancer driving traffic past failures and anomalies increases the stability of the entire system.
Next, I will describe several different L4 balancers with an intermediate / terminal proxy. These schemes are not applicable to client library and side proxy topologies.
TCP / UDP interrupt balancers

Figure 8: Interrupting L4 Balancer
The first type of L4 balancers, still used. This is the same balancer as in the introductory section on L4 balancers. There are two separate TCP connections: one between the client and the balancer, the second between the balancer and the backend.
Interrupting L4 balancers are still in use for two reasons:
- They are fairly simple to implement.
- Interrupting the connection close to the client (low latency) significantly affects performance. In particular, if the interrupting balancer can be placed close to clients using networks with a large number of missing packets (for example, cellular networks), then retransmissions will most likely be performed faster before the data reaches reliable cable transit along the route to the destination. In other words, this type of balancer can be used at points of presence (Point of Presence, POP) to interrupt raw TCP connections.
TCP / UDP transit balancers
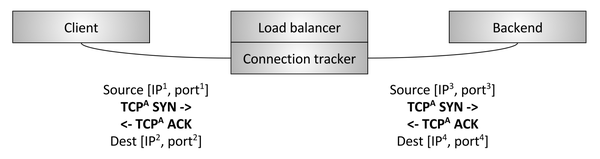
Figure 9: Transit L4 Balancer
The second type of L4-balancer - transit - is shown in Figure 9 . Here the TCP connection by the balancer is not interrupted. Instead, after connection tracking and network address translation ( NAT ), packets for each connection are sent to the selected backend. First let's define the connection tracking and NAT:
- Connection tracking is the process of tracking the status of all active TCP connections: checking the completeness of a handshake, whether a FIN was received, how long the connection was idle, which backend was selected for the connection, etc.
- NAT is a process that uses connection tracking data to change IP / port information for packets as they pass through the balancer.
With the help of connection tracking and NAT, the balancer can bypass mainly raw TCP traffic from the client to the backend by transit. Suppose a client contacts 1.2.3.4:80 , and the selected backend is at 10.0.0.2:9000 . TCP client packets will come to the balancer at 1.2.3.4:80 . The balancer will change the IP and port for packets to 10.0.0.2:9000 , and also change their outgoing IP and port to their own. Thus, when the backend responds to a TCP connection, the packets will return to the balancer, which will track the connection and NAT in the opposite direction.
Why use a balancer of this type instead of the interrupter described above? After all, it is more complicated. There are several reasons:
- Productivity and use of resources . Since transit balancers do not interrupt TCP connections, they do not need to buffer its window. The size of the state stored for each connection is quite small, and it can be retrieved using effective hash table searches. Therefore, transit balancers are usually able to handle far more active connections and packets per second than terminating balancers.
- The backend can use different congestion control algorithms . TCP congestion management is the mechanism by which endpoints on the Internet slow down sending data so as not to overload the available channel and buffers. Since the transit balancer does not interrupt a TCP connection, it does not participate in congestion management. This allows backends to use different congestion control algorithms depending on the particular application. It also simplifies congestion control experiments (for example, the recent roll out of BBR ).
- You can use direct server return (DSR) and clustered L4 balancing. Transit balancers are needed for more advanced L4 balancing schemes, such as DSR and distributed consistency hashing clustering (discussed below).
Direct Return from Server (DSR)

Figure 10: L4 direct return from server (DSR)
Figure 10 shows the direct return balancer from the server. It is created on the basis of a transit balancer. In essence, DSR is an optimization in which incoming request packets pass through a balancer, and outgoing response packets bypass it and go straight to the client. The benefit of using DSR is that with many types of workloads, the response traffic is many times greater than the request traffic (for example, this is typical of HTTP requests / responses). Suppose 10% of traffic is requests, and the remaining 90% are responses, and then using DSR there will be enough balancer with a capacity of 1/10 system capacity. Since balancers are historically very expensive, such optimization greatly reduces the cost of the system and increases reliability. DSR-balancers - development of the concept of a transit balancer:
- The balancer still partially tracks the connection. Since response packets do not go through the balancer, it is not interested in the full state of the TCP connection. However, the balancer can make assumptions about its condition by evaluating client packages and applying different types of timeouts.
- To encapsulate IP packets from the balancer to the backend, instead of NAT, the balancer usually uses common route encapsulation ( GRE ). So, when the backend receives an encapsulated packet, it can decapsulate it and find out the original IP and TCP port of the client. This allows the backend to respond directly, bypassing the balancer.
- An important feature of the DSR is that the backend is involved in balancing . It needs a properly configured GRE tunnel, and depending on low-level network features, you may need your own connection tracking, NAT, etc.
Please note that the transit and DSR balancer schemes on the balancer and the backend can be configured with different ways to monitor connections, organize NAT, GRE, etc. But this is already beyond the scope of the article.
Resilience due to high availability pairs

Figure 11: L4 fault tolerance due to HA pairs and connection tracking
So far, we have been considering the L4-balancers scheme without regard to the environment. The transit and DSR balancer needs some amount of connection and state tracking data. And what if the balancer dies? If he was alone, then all connections that went through him would break. Depending on the situation, this can greatly affect the performance of the application.
Historically, L4 balancers were hardware solutions from different manufacturers (Cisco, Juniper, F5, etc.). These devices are very expensive and handle a large amount of traffic. To avoid the termination of all connections due to the failure of a single balancer, two balancers are usually made, combining them into highly accessible pairs , as shown in Figure 11 . The layout of a typical HA pair is as follows:
- Two highly available end routers serve a number of virtual IP ( VIP ). These routers declare VIPs using the Border Gateway Protocol ( BGP ). The primary router has a higher BGP weight than the spare, so in normal mode it serves all traffic. BGP — , BGP , , . , , .
- L4- , BGP-, , .
- - . , , .
- - . BGP- - , .
- . :
- VIP' . - VIP , VIP VIP'.
- . 50 % . , .
- , «/», . . . , .
- . , .

12: L4
2000- - , L4 , 12 . :
- .
- , .
. :
- N Anycast VIP' BGP-. , ( ECMP ). — L4- IP/ IP/. , ECMP — . , , , , , .
- N L4- VIP' BGP-. ECMP, - .
- L4- , . , , GRE.
- DSR.
- . , , . .
, , :
- . , .
- .
- , .
, : « ECMP? ?» DoS . BGP, .
L4- ( ). — Google Maglev Amazon Network Load Balancer (NLB) . OSS-, , , 2018-. , L4- — OSS .
L7-
- — -. « ». Nginx , HAProxy, linkerd, Envoy, . proxy-as-a-service/routing-as-a-service SaaS- . !
— @copyconstruct
, L7-/. . , , , . , , , IP . , , . , L7-.
L7- . , , , . . , Envoy L7- HTTP/1, HTTP2, gRPC, Redis, MongoDB DynamoDB. , MySQL Kafka.
, . — Istio . .
L7- , , , , (circuit breaking), (shadowing), , .
. , L7- — , . , L7-.
L7- . , . , Lua .
L4- . L7-? (stateless). L7- . , , L7-, , L4. L7 , .
L4 L7 , .

13:
. , . 13 . :
- (A, B C).
- , 90 % C, 5 % — A B.
- . , , , . .
- .
, . For example:
- .
- .
- , DDoS-.
- , .
, L4-. ?
OSI- . , - :
— @infosecdad
, , :
- .
- L3/L4 , , IPVS , DPDK fd.io . - 5 . 80 / , Linux , DPDK. - ASIC, ECMP- , .
- L7- NGINX, HAProxy Envoy , F5. L7- .
- IaaS, CaaS FaaS, , , ( « » «, »).
:
- — .
- : L4 L7.
- .
- L4- , , .
- L7- .
- , .
- OSS- . , F5 OSS- . Arista/Cumulus/ . on-premise , .
, ! OSS . , «» .
')
Source: https://habr.com/ru/post/347026/
All Articles