“Knowledge Day” for AI: published by the TOP30 of the most impressive machine learning projects over the past year (v.2018)

To select the TOP 30 (only 0.3%), over the past year, the Mybridge team compared almost 8,800 open source machine learning projects.
This is an extremely competitive list, and it contains the best open source libraries for machine learning, data sets and applications published from January to December 2017. To give you an idea of the quality of projects, we point out that the average number of Github stars is 3558.
Open source projects can be useful not only to scientists. You can add something amazing on top of your existing projects. Check out the projects you may have missed last year.
')

Carefully, under the cut a lot of pictures and gif.
1. FastText
fastText is a library for teaching word representations and sentence classification, allowing you to organize automatic categorization of arbitrary text using machine learning methods. [11786 stars on Github]. Courtesy of Facebook Research .

[ Muse : Multilingual Unsupervised or Supervised word Embeddings, based on Fast Text. 695 stars on Github]

2. Deep Photo Style Transfer
Code and data for scientific work Deep Photo Style Transfer [9747 stars on Github] . An approach to transferring a photographic style from one image to another is described, with successful suppression of distortion and preservation of photorealism in a variety of scenarios, including the transfer of features of the time of day, weather, season, and artistic changes. Merit Fujun Luan, Ph.D. at Cornell University.

3. Face Recognition
The world's easiest Python face recognition API. The model has an accuracy of 99.38% in the Labeled Faces in the Wild benchmark. It also offers a simple tool that allows you to recognize faces from images in a folder using the command line. Developer - Adam Geitgey [8672 stars on Github] .

4. Magenta
Generate art and music using machine learning [8113 stars on Github] .
5. Sonnet
Sonnet is a machine learning library based on TensorFlow for building complex neural networks. [5731 star on Github] . Provided by Malcolm Reynolds from Deepmind

6. deeplearn.js
deeplearn.js is the Webhl-accelerated JavaScript library for machine learning with open source code from Nikhil Thorat from Google Brain.

7. Fast Style Transfer in TensorFlow
Fast style transfer using TensorFlow [4843 stars on Github] . Logan Engstrom from MIT.

Add styles of famous artists to any photo in a split second! You can even create videos.
8. Pysc2: StarCraft II Learning Environment [3683 stars on Github] , courtesy of Timo Ewalds from DeepMind

9. AirSim
AirSim is a simulator for unmanned aerial vehicles, cars and other vehicles created on the Unreal Engine. This is an open source platform for physically and visually realistic simulations. The goal is to develop a platform for AI research and experiments with algorithms of deep learning, computer vision and stimulated learning of autonomous vehicle systems. [3861 stars on Github] . Developer - Shital Shah from Microsoft
10. Facets
The power of machine learning is related to its ability to study patterns in large amounts of data. Understanding your data is crucial for creating a powerful machine learning system. The Facets project offers two robust visualization types that help you understand and analyze data sets: Facets Overview and Facets Dive.
The visualization is easily embedded in Jupyter notebooks or webpage reports ( Polymer web components, backed by Typescript code).
[3371 stars on Github] . Courtesy of Google Brain

Sample report FACETS OVERVIEW
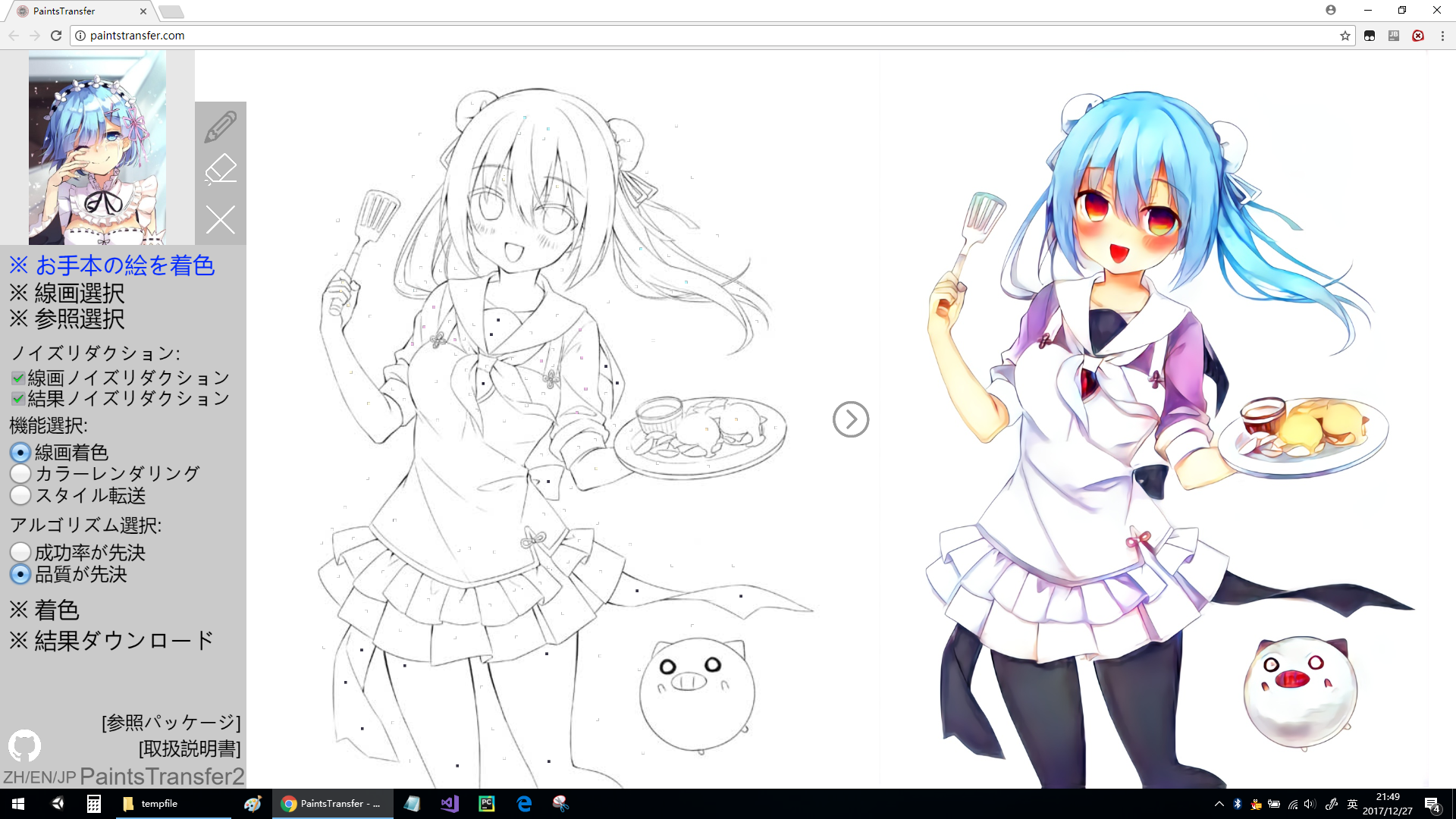
11. Style2Paints
AI coloring images [3310 stars on Github] , can paint in accordance with a specific color style, create your own drawing style or convey an illustration style example.


12. Tensor2Tensor
The authors of the scientific work “One Model for Learning Everything” from the Google Brain Team asked a natural question: “Can we create a unified depth learning model that will solve problems from different areas?”
Google did it - and opened the Tensor2Tensor for public use, the code is published on GitHub . [3087 stars on Github .
In a scientific article, they describe the MultiModel architecture - a unified universal model of deep learning, which can simultaneously be trained in tasks from different domains.
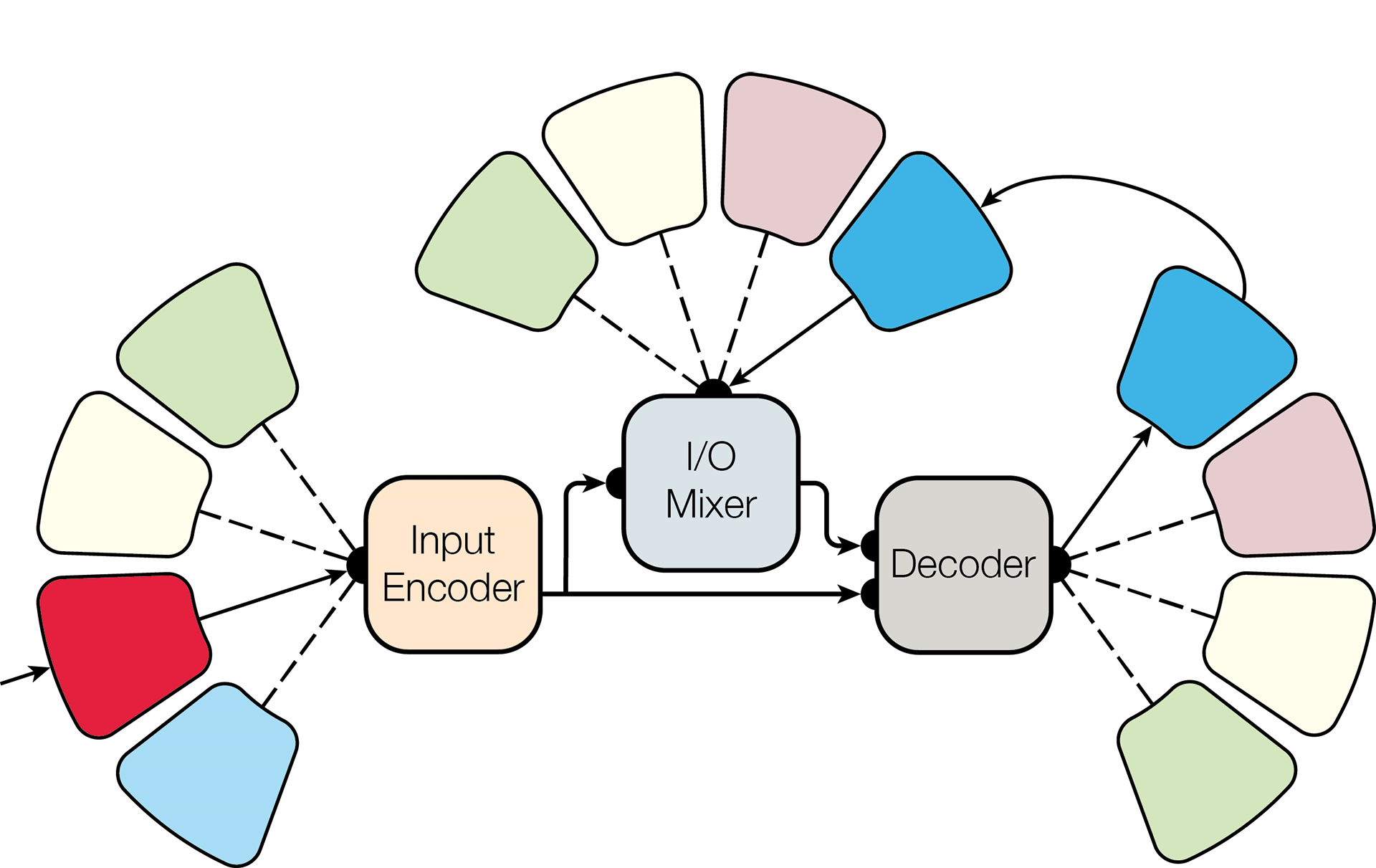
MultiModel Architecture
In particular, the researchers trained MultiModel to test simultaneously on eight data sets:
- WSJ Speech Recognition Body
- ImageNet Image Base
- Base of common objects in the context of COCO
- WSJ parsing database
- English to German translation body
- Reverse previous: German to English translation corps
- Translation from English to French
- Reverse the previous: the case of translation from French to English
Read more here .
13. Image-to-image translation in PyTorch (for example, horse2zebra, edges2cats, and so on)
[2847 stars on Github] . Courtesy of Jun-Yan Zhu, Ph.D at Berkeley

14. Faiss
Faiss is a library for efficiently looking for similarity and clustering vectors [2629 stars on Github] . Quite often, programmers and experts in the field of data science are faced with the task of finding similar user profiles or selecting similar music. Solutions can be reduced to the transformation of objects into a vector shape and finding the closest ones. More on Habré.

Given the first and last image, the algorithm calculates the smoothest path between them from the YFCC100M (95 million images). Taken here .
15. Fashion-mnist, Han Xiao, Research Scientist Zalando Tech
Fashion-MNIST [2780 stars on Github] is proposed as a replacement for the MNIST DB (short for Mixed National Institute of Standards and Technology), since MNIST is too simple. Fashion-MNIST has the same image size and structure for training and testing.
MNIST is a voluminous handwritten number sample database. The database is a standard proposed by the National Institute of Standards and Technology of the United States to calibrate and compare image recognition methods using machine learning, primarily based on neural networks. The data consists of pre-prepared examples of images, on the basis of which training and testing of systems is carried out. The database was created after processing the original set of black and white samples of 20x20 pixels NIST. The creators of the NIST database, in turn, used a set of samples from the US Census Bureau, to which more test samples written by students of American universities were added. NIST samples were normalized, smoothed, and reduced to a gray halftone image with a size of 28x28 pixels.
The MNIST database contains 60,000 images for training and 10,000 images for testing. Half of the samples for training and testing were taken from the NIST set for training, and the other half from the NIST set for testing.
There have been numerous attempts to achieve a minimum error after learning from the MNIST database, which have been discussed in the scientific literature. Record results were indicated in publications on the use of convolutional neural networks, the error level was increased to 0.23%. The creators of the database provided several testing methods. In the original paper it is indicated that the use of the support vector method allows to reach the error level of 0.8%.

Fashion-MNIST
16. ParlAI
ParlAI is the basis for learning and evaluating AI models on a set of dialog [2578 stars on Github] dialogs. Courtesy of Alexander Miller from Facebook Research

17. Fairseq: Facebook AI Research Sequence-to-Sequence Toolkit [2571 stars on Github]
The Facebook AI Research team (FAIR) has published impressive results on the implementation of a convolutional neural network for machine translation. She argues that the fairseq, a new tool, works 9 times faster than traditional recurrent neural networks, while yielding only a small amount of accuracy.

18. Pyro: Deep universal probabilistic programming with Python and PyTorch [2387 stars on Github] . Courtesy of Uber AI Labs

19. iGAN
Interactive image generation [2369 stars on Github] .

20. Deep-image-prior
Image recovery using neural networks without learning [2188 stars on Github ]. Courtesy of Dmitry Ulyanov, Ph.D at Skoltech

21. Face classification and detection of the B-IT-BOTS robotics team
Real-time face detection and emotional + gender classification using the fer2013 / IMDB data sets [1967 stars on Github] .
Gender Classification Accuracy (IMDB): 96%.
Emotion classification accuracy (fer2013): 66%.

22. Speech-to-Text-WaveNet by Namju Kim from Kakao Brain
End-to-end speech recognition in English using DeepMind's WaveNet and tensorflow [1961 stars on Github] .

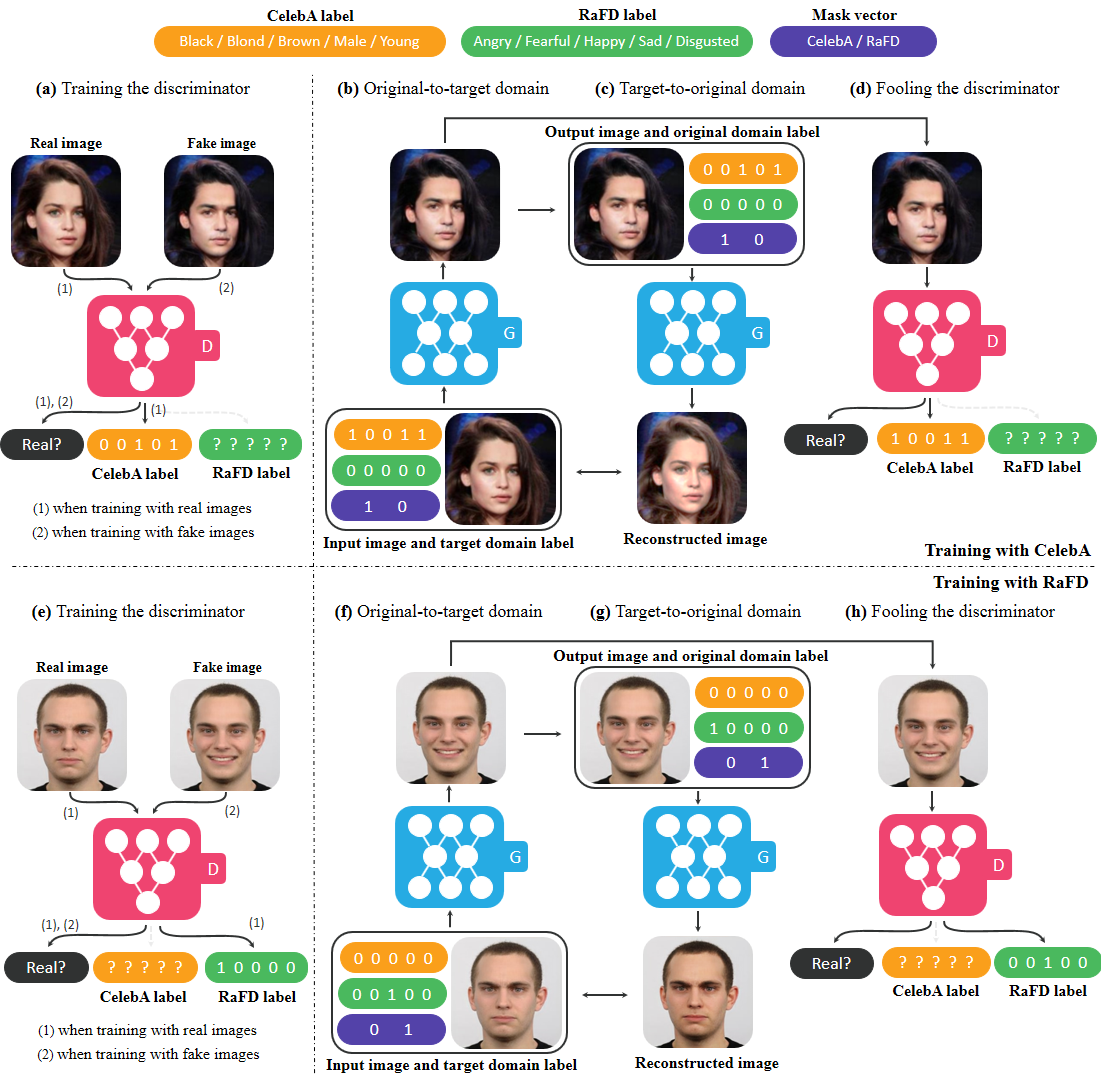
23. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation [1954 stars on Github] . Yunjey Choi at Korea University

24. Ml-agents: Unity Machine Learning Agents [1658 stars on Github] . Courtesy of Arthur Juliani, Deep Learning at Unity3D
Unity Machine Learning Agents allows researchers and developers to create games and simulation environments for machine learning using the Unity Editor using an easy-to-use Python API.

25. DeepVideoAnalytics [1494 stars on Github] . Courtesy of Akshay Bhat, Ph.D. at Cornell University
A platform for searching and analyzing visual data.

26. OpenNMT: Open-Source Neural Machine Translation in Torch [1490 stars on Github] .

27. Pix2pixHD: [1283 stars on Github] . Ming-Yu Liu at AI Research Scientist at Nvidia
Pix2pixHD is designed for photo-realistic synthesis or transformation of high-resolution images (for example, 2048x1024). It can be used to transform semantic label maps into photo-realistic images or to synthesize portraits using a face label map.

28. Horovod: Distributed training framework for TensorFlow. [1188 stars on Github] . Courtesy of Uber Engineering

29. AI-Blocks [899 stars on Github]
Powerful and intuitive WYSIWYG interface that allows anyone to create models for machine learning.
30. Deep neural networks for voice conversion (voice style transfer) in Tensorflow [845 stars on Github]. Dabi Ahn, AI Research at Kakao Brain

The goal of the project is to transfer the voice style or turn someone's voice into the voice of a specific person. Work on this project was aimed at transforming into the voice of famous English actress Kate Winslet.
Disclaimer
The materials listed above are purely research in nature. Using the results to achieve illegal goals may entail criminal, administrative and (or) civil liability. The author is not responsible for such incidents.

Source: https://habr.com/ru/post/346968/
All Articles