Amazon MTurk and Emotion Miner: Crowdsourcing, Big Data, Emotional Technologies
Let's ask ourselves: to what extent are crowded sourcing tools in demand in the sphere of emotional (and neurocognitive) technologies? How can you collect, mark up and pre-process large amounts of data, based on the resources of the crowd? As indicative cases we will discuss the Amazon MTurk platform and, in addition to the emotional issues, the project of the Neurodata Lab - Emotion Miner .
A common place in recent decades has been the mention of the fact that in the modern - globalized - world a new network society has emerged and is developing, to a certain extent, combined with the concept of a “thinned society” or “fluid modernity” if we use the famous wording of the British sociologist Zygmunt Bauman.
The systemic, multiple, synchronous nature of the changes occurring before our eyes creates a critical mass of phenomena (whatever it is in practice - from cryptocurrency and augmented reality to “sharing” initiatives and big data) of varying degrees of penetration and depth paradigm (in the sense of Kuhn) to fundamentally new horizons. Even to a different matrix, if we argue more comprehensively, anthropologically. If the network becomes the defining way of organization and the metaphor of life, then life “creeps” into the network. And on several levels in parallel: professional, private, intellectual ... and emotional - not least.
')
For a business whose core is innovative concepts and technological solutions, and the goal is to analyze and interpret a person as a thinking, acting and, above all, feeling, subject who is also a consumer of goods and services, migration of capital, resources, tools for generating ideas and the production of value, jobs finally in the Internet - a source of new opportunities that should not be neglected. Unification, the gradual introduction of norms and standards shared by all - also help build long-term strategies. And experiment with the tools and approaches to solving the challenges.
Crowdsourcing has long come into the field of IT and high technologies based on data science, artificial intelligence, neural network development, deep learning and computer vision. The popularity, authority and public attention to the Kaggle site (as part of Alphabet Inc.) and other "Kagglo-like" initiatives is the most vivid example, relevant both in the context of training and gaming, as well as serious research and business projects. Crowdsourcing and the direction of emotional (and behavioral) technologies did not avoid.
Recall some of the nuances. Affective computing and emotion detection and recognition systems (EDRS) are an integral and important part of the global big data industry and artificial intelligence technologies. This is a young, actively growing sub-industry (with market estimates from $ 6 billion in 2016 to about $ 32 billion by 2022 with a stable outlook), developing at an intensive pace and gradually forming its own ecosystem of theoretical views, concepts and technology products - Emotion AI ( in other words, emotional artificial intelligence). To date, both corporations (Facebook, Apple, Microsoft, IBM, etc.) and private companies are already involved in it - “old” players who entered the market in the early 2010s. (or earlier, as Beyond Verbal Communications ) and still defining its rhythm (for example, Affectiva , Eyeris , Noldus or Sightcorp ).
We are talking about the direction of extremely resource-intensive and high-tech, focused on the analysis of emotions, physiological parameters and behavioral patterns, moreover, both in a static mode (through image analysis - photographs, frames, etc.), and dynamically (an audio-video stream is studied in various forms - from Skype and youtube to television and network content and videos shot on ordinary cameras of smartphones).
In the case of Neurodata Lab, when mentioning the most accurate detection and recognition algorithms, a fundamentally multimodal approach is implied, when the data required for complex analysis are extracted from multiple channels simultaneously: facial microexpression, eye movements, voice in its totality, body language, movements, gestures, subcutaneous blood flow, physiological and behavioral nuances. All of them manifest themselves in dynamics: at the moments of communication of a person with people, with the outside world.
When detecting and recognizing emotions, it is important to take into account that human emotions are a very variable, somewhat elusive essence, which often changes from person to person, from society to society, there are ethnic, age, gender, sociocultural differences. It is difficult to declare the absolute universality of emotions, - despite the fact that there is a constant mixing and averaging, fine-tuning the world to more or less common patterns. To identify patterns, you need to train algorithms on huge samples of qualitative data.
Accordingly, to collect huge amounts of unstructured, untreated, “raw” information, and then cluster it, extract the required features (features) suitable for training neural networks, without recourse to crowdsourcing tools and the community of involved remote specialists.
Of course, the most well-known brand and “advanced” crowdsourcing platform - a platform for microtasks - is Amazon Mechanical Turk (hereinafter MTurk). An indicator of its success - in addition to the cumulative number of participants and parallel ongoing projects - can be considered the fact that it is not only used for scientific research, but also from time to time serves as their object (for example, we will talk about it now).
So, if you turn to natural and cognitive sciences for a moment, what types of cases and tasks are “thrown out” on MTurk? There are several:
No less noteworthy is the MTurk statistics:
Amazon claims that over 500,000 workers are registered with MTurk, but their active part is disproportionately smaller. A pool of participants suitable for research projects, often longer and more complex, is already - this is considered normal, although it entails the exhaustion of the community (updated and replenished - to replace the departed - about once every seven months, but some remain there for several years) , open to typical scientific issues and specific requirements of laboratories and centers of competence. At the same time, many participants perceive MTurk as a full-fledged work and agree to spend n hours a week filling out questionnaires and questionnaires. An MTurk member, on average, reports engagement in about 160 academic studies for the reporting month and a desire to work more if the opportunity presents itself. About 60% of the participants communicate on the forums, but only 10% had experience of direct contact with other site workers, even if they meant the same project. These are the facts.
It is probably appropriate to briefly highlight - as an alternative example - our own experience of integrating crowdsourcing into emotional and behavioral research. Having carefully studied all the relevant microtasks and data processing sites (including MTurk and CrowdSource ) and came to the conclusion that their predefined functionality does not fully satisfy us, we decided to implement the project ourselves.
So what is Emotion Miner today? The minimum required version for PC and Facebook browser is now online, the multifunctional platform will be available by spring 2018.
What allows you to make the site in its current form:
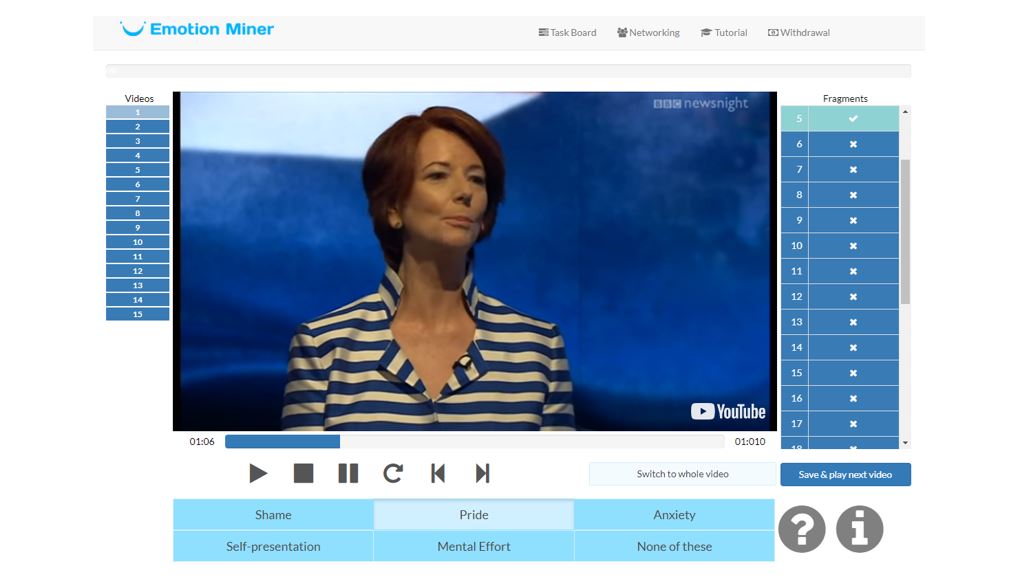
Structurally and stylistically, this type of work optimally adapts not so much to the usual forms of freelancing / crowdsourcing, but rather to the context and psychology of digital nomads - “digital nomads” of the 21st century, whose daily work is inseparable from mobility, not only physical, but also intellectual.
In our project, any adult user who speaks English can act as an annotator, provided that it meets the participation criteria, as well as the conditions and rules set forth in the offer, which is published on the website.
A few numbers for a more comprehensive view of the subject. There are more than 16 thousand (constantly growing community) registered and verified annotators on our platform. The database is at our disposal - tens of millions of consistent fragments across a huge emotional spectrum (more precisely, we are talking about a classification model that includes basic emotions and complex emotional and mental states, as well as social behavioral patterns and physiology, from which everything is an order of magnitude more difficult, because here in addition, more sophisticated computer vision mechanisms are required, etc.).
User geography is impressive: leading positions in the Asia-Pacific countries (India, Malaysia, the Philippines, etc.), the USA and Canada, Europe and Latin America, with some Africa (Kenya, South Africa, Nigeria). We collect all the available statistics (and publish it separately) so that the platform in the final configuration meets the expectations and needs of the “remote employees”, whoever they are and where they come from. There are no shortages in the channels for attracting either: from Facebook groups and specialized forums to sites for searching remote work and targeted Google advertising.
The project includes:
In contrast to MTurk, we focus not only on the scale and universality, but on in-depth study and expertise in our industry, which turns out to be at the crossroads of many disciplines.
Release of a full-fledged platform in 2018 with a mobile version and applications (IOS / Android). Diversification of content (video, audio, images, text), languages (other than English and Russian are relevant and others), tasks as such (not focusing exclusively on emotions and behavior, but shifting to other aspects of ML / CV at the request of partners; for example, research in the field of synthesis and neuro-editing of persons often rests on “training data”), testing all the necessary infrastructure for this.
We are open to scientific collaborations and invite colleagues - in particular, Russian laboratories and departments - to use Emotion Miner in their work within the framework of bilateral cooperation.
A hub approach based on the Neurodata Lab cooperation with partner investment funds is being prepared for approbation: the platform packed into the product is interesting for both start-ups and corporate players whose needs and demands are often pragmatic, business-like, out of direct connection with fundamental science, which, however, is no less interesting.
A closely related one - as part of a single package - will be the Datacombats platform - for holding competitions and online hackathons both in DS / ML environment and in the circle of neurocognitive groups.
We have quite a lot of ideas that I want to realize. Of course, the project, which is interactive in its essence, will scale if there is support, active participation and enthusiasm of the external community, sharing with us the most important postulate: General artificial intelligence (AGI, Artificial General Intelligence), about which so much is written, is hardly possible without artificial emotional intelligence (Emotion AI), at least for now, man remains the main driving and initiating force of the world of everyday life, business and technology.
Emotional man: Homo Sentiens as is.
Theoretical introductory (can be skipped)
A common place in recent decades has been the mention of the fact that in the modern - globalized - world a new network society has emerged and is developing, to a certain extent, combined with the concept of a “thinned society” or “fluid modernity” if we use the famous wording of the British sociologist Zygmunt Bauman.
The systemic, multiple, synchronous nature of the changes occurring before our eyes creates a critical mass of phenomena (whatever it is in practice - from cryptocurrency and augmented reality to “sharing” initiatives and big data) of varying degrees of penetration and depth paradigm (in the sense of Kuhn) to fundamentally new horizons. Even to a different matrix, if we argue more comprehensively, anthropologically. If the network becomes the defining way of organization and the metaphor of life, then life “creeps” into the network. And on several levels in parallel: professional, private, intellectual ... and emotional - not least.
')
For a business whose core is innovative concepts and technological solutions, and the goal is to analyze and interpret a person as a thinking, acting and, above all, feeling, subject who is also a consumer of goods and services, migration of capital, resources, tools for generating ideas and the production of value, jobs finally in the Internet - a source of new opportunities that should not be neglected. Unification, the gradual introduction of norms and standards shared by all - also help build long-term strategies. And experiment with the tools and approaches to solving the challenges.
Crowdsourcing has long come into the field of IT and high technologies based on data science, artificial intelligence, neural network development, deep learning and computer vision. The popularity, authority and public attention to the Kaggle site (as part of Alphabet Inc.) and other "Kagglo-like" initiatives is the most vivid example, relevant both in the context of training and gaming, as well as serious research and business projects. Crowdsourcing and the direction of emotional (and behavioral) technologies did not avoid.
Recall some of the nuances. Affective computing and emotion detection and recognition systems (EDRS) are an integral and important part of the global big data industry and artificial intelligence technologies. This is a young, actively growing sub-industry (with market estimates from $ 6 billion in 2016 to about $ 32 billion by 2022 with a stable outlook), developing at an intensive pace and gradually forming its own ecosystem of theoretical views, concepts and technology products - Emotion AI ( in other words, emotional artificial intelligence). To date, both corporations (Facebook, Apple, Microsoft, IBM, etc.) and private companies are already involved in it - “old” players who entered the market in the early 2010s. (or earlier, as Beyond Verbal Communications ) and still defining its rhythm (for example, Affectiva , Eyeris , Noldus or Sightcorp ).
We are talking about the direction of extremely resource-intensive and high-tech, focused on the analysis of emotions, physiological parameters and behavioral patterns, moreover, both in a static mode (through image analysis - photographs, frames, etc.), and dynamically (an audio-video stream is studied in various forms - from Skype and youtube to television and network content and videos shot on ordinary cameras of smartphones).
In the case of Neurodata Lab, when mentioning the most accurate detection and recognition algorithms, a fundamentally multimodal approach is implied, when the data required for complex analysis are extracted from multiple channels simultaneously: facial microexpression, eye movements, voice in its totality, body language, movements, gestures, subcutaneous blood flow, physiological and behavioral nuances. All of them manifest themselves in dynamics: at the moments of communication of a person with people, with the outside world.
When detecting and recognizing emotions, it is important to take into account that human emotions are a very variable, somewhat elusive essence, which often changes from person to person, from society to society, there are ethnic, age, gender, sociocultural differences. It is difficult to declare the absolute universality of emotions, - despite the fact that there is a constant mixing and averaging, fine-tuning the world to more or less common patterns. To identify patterns, you need to train algorithms on huge samples of qualitative data.
Accordingly, to collect huge amounts of unstructured, untreated, “raw” information, and then cluster it, extract the required features (features) suitable for training neural networks, without recourse to crowdsourcing tools and the community of involved remote specialists.
Amazon MTurk : features and features
Of course, the most well-known brand and “advanced” crowdsourcing platform - a platform for microtasks - is Amazon Mechanical Turk (hereinafter MTurk). An indicator of its success - in addition to the cumulative number of participants and parallel ongoing projects - can be considered the fact that it is not only used for scientific research, but also from time to time serves as their object (for example, we will talk about it now).
So, if you turn to natural and cognitive sciences for a moment, what types of cases and tasks are “thrown out” on MTurk? There are several:
- "Economic Games" - the so-called. social dilemmas and prisoner dilemmas ;
- “Crowd Creativity” - writing stories, scripts, etc .;
- "Field studies" - for example, participants are asked to send photos of home thermostats, which allows you to track the correctness of the indicators and the correctness of the settings;
- “Tests for children's attention” - when children watch, say, video clips, when webcams record real-time eye movement, “stop” and “switching”;
- so-called “Transactive crowds” - for example, MTurk participants provided their own cognitive reassessment in response to negative thoughts of other workers: an application was even developed that allows people with visual impairments to upload images and get descriptions of their content in almost real time, which clearly contains social promise;
- “Timing and diaries” - here, for example, participants were asked to take notes about alcohol intake, distribution of cases or work being done, which allows collecting data in a longer cut (longitudinal research), not limited to the period of the participant’s physical presence in the laboratory, and analyze , the degree of productivity of spatial attention, habits, etc .;
- “Crowd as a community of scientific assistants” - in the case of a statistically large sample, people, as it turned out, often formulate judgments equivalent or superior to expert estimates. For example, MTurk was used to study the ideology of statements from an array of political texts: it was found that 15 participants made assessments with a quality commensurate with the five PhD candidates in political science. It is important to note that the crowd can quickly deliver data: remote participants processed the contents of 22,000 sentences in less than 5 hours and for as little as $ 360.
No less noteworthy is the MTurk statistics:
- the overwhelming majority of participants are Americans and Indians; for comparison, Europeans are more likely to work at other sites ( Prolific and Clickworker ), residents of Southeast Asia prefer Microworkers , and the Japanese prefer their own national platform CrowdWorks ;
- the dominant language of communication is English;
- American participants are not limited exclusively to college students, members of the liberal professions or the socially disadvantaged, but their sample is generally not representative of the entire US population;
- an excess of the presence of Americans of European and Asian origin, a minimum - of African Americans and immigrants from Latin American countries;
- oddly enough, but in the gender section men dominate;
- the sample of teleworkers differs in youth (up to 35 years), the best education (university), less religiosity, liberal political views, but is also characterized by temporary / steady professional unemployment, lower income levels;
- project participants are usually distinguished by purposefulness, diligence, speed of reaction and pronounced needs for knowledge that sometimes (we repeat, this is not frequent) is compensated by introversion, social anxiety, weaker resistance to physical and psychological discomfort, a certain level neuroticism and traits inherent in autistic spectrum disorders (ASD) in a mild form.
Amazon claims that over 500,000 workers are registered with MTurk, but their active part is disproportionately smaller. A pool of participants suitable for research projects, often longer and more complex, is already - this is considered normal, although it entails the exhaustion of the community (updated and replenished - to replace the departed - about once every seven months, but some remain there for several years) , open to typical scientific issues and specific requirements of laboratories and centers of competence. At the same time, many participants perceive MTurk as a full-fledged work and agree to spend n hours a week filling out questionnaires and questionnaires. An MTurk member, on average, reports engagement in about 160 academic studies for the reporting month and a desire to work more if the opportunity presents itself. About 60% of the participants communicate on the forums, but only 10% had experience of direct contact with other site workers, even if they meant the same project. These are the facts.
Emotion Miner: from home project to full platform
It is probably appropriate to briefly highlight - as an alternative example - our own experience of integrating crowdsourcing into emotional and behavioral research. Having carefully studied all the relevant microtasks and data processing sites (including MTurk and CrowdSource ) and came to the conclusion that their predefined functionality does not fully satisfy us, we decided to implement the project ourselves.
So what is Emotion Miner today? The minimum required version for PC and Facebook browser is now online, the multifunctional platform will be available by spring 2018.
What allows you to make the site in its current form:
- Post audio-video files, pre-extracted from any available content (talk shows, debates, monologues, interviews, public performances, presentations, etc.), sorted, chopped and broken into short scenes (timing - up to 5 seconds - can vary) with full-time professional annotators, or “hooking up” longer original recordings from third-party channels and sources, of course, taking into account legally binding moments and the rights of content owners;
- To carry out multiple markup (multiple annotation) of the mentioned video clips with the hands of hundreds and thousands of third-party annotators, each of which, as a rule, is not only interesting to take part in this kind of initiative from a financial point of view (participation is paid), but I also want to “pump” their initial skills by recognizing emotions.
Structurally and stylistically, this type of work optimally adapts not so much to the usual forms of freelancing / crowdsourcing, but rather to the context and psychology of digital nomads - “digital nomads” of the 21st century, whose daily work is inseparable from mobility, not only physical, but also intellectual.
In our project, any adult user who speaks English can act as an annotator, provided that it meets the participation criteria, as well as the conditions and rules set forth in the offer, which is published on the website.
A few numbers for a more comprehensive view of the subject. There are more than 16 thousand (constantly growing community) registered and verified annotators on our platform. The database is at our disposal - tens of millions of consistent fragments across a huge emotional spectrum (more precisely, we are talking about a classification model that includes basic emotions and complex emotional and mental states, as well as social behavioral patterns and physiology, from which everything is an order of magnitude more difficult, because here in addition, more sophisticated computer vision mechanisms are required, etc.).
User geography is impressive: leading positions in the Asia-Pacific countries (India, Malaysia, the Philippines, etc.), the USA and Canada, Europe and Latin America, with some Africa (Kenya, South Africa, Nigeria). We collect all the available statistics (and publish it separately) so that the platform in the final configuration meets the expectations and needs of the “remote employees”, whoever they are and where they come from. There are no shortages in the channels for attracting either: from Facebook groups and specialized forums to sites for searching remote work and targeted Google advertising.
The project includes:
- effective learning algorithm: tutorials and the ability to view the entire record, contextualization;
- testing: required to pass an English proficiency test;
- the participants' accomplishment of tasks of different levels of complexity: a ladder of tasks has been laid with the complication from step to step;
- interactive process control: real-time communication with annotators and streamlined quality management (the project team provides practical support to the annotators, we have an English-speaking support team 24/7).
In contrast to MTurk, we focus not only on the scale and universality, but on in-depth study and expertise in our industry, which turns out to be at the crossroads of many disciplines.
Plans and prospects
Release of a full-fledged platform in 2018 with a mobile version and applications (IOS / Android). Diversification of content (video, audio, images, text), languages (other than English and Russian are relevant and others), tasks as such (not focusing exclusively on emotions and behavior, but shifting to other aspects of ML / CV at the request of partners; for example, research in the field of synthesis and neuro-editing of persons often rests on “training data”), testing all the necessary infrastructure for this.
We are open to scientific collaborations and invite colleagues - in particular, Russian laboratories and departments - to use Emotion Miner in their work within the framework of bilateral cooperation.
A hub approach based on the Neurodata Lab cooperation with partner investment funds is being prepared for approbation: the platform packed into the product is interesting for both start-ups and corporate players whose needs and demands are often pragmatic, business-like, out of direct connection with fundamental science, which, however, is no less interesting.
A closely related one - as part of a single package - will be the Datacombats platform - for holding competitions and online hackathons both in DS / ML environment and in the circle of neurocognitive groups.
We have quite a lot of ideas that I want to realize. Of course, the project, which is interactive in its essence, will scale if there is support, active participation and enthusiasm of the external community, sharing with us the most important postulate: General artificial intelligence (AGI, Artificial General Intelligence), about which so much is written, is hardly possible without artificial emotional intelligence (Emotion AI), at least for now, man remains the main driving and initiating force of the world of everyday life, business and technology.
Emotional man: Homo Sentiens as is.
Source: https://habr.com/ru/post/346952/
All Articles