Incident Management Process in Tutu.ru
For each company, sooner or later the topic of incident management becomes relevant. Some already have configured and streamlined processes, someone is just starting their way in this direction. Today I want to talk about how we in Tutu.ru built the process of handling "failures in battle", and what we did.

Analysis of incidents in our company is engaged in the maintenance department (or, easier, support). Therefore, I will begin by describing how it works. In Tutu.ru we have a certain set of products, it is - railway, air, tours, trains, buses. In the team of each product there are specialists in the operation department Also, representatives of our department are in the cross-functional and infrastructure teams.
We are responsible for ensuring that our users have no problems when using the service. This includes team-specific tasks to support our external and internal customers, as well as work to ensure that at all the speed of change, the site experienced equipment failures, withstood loads and continued to solve user problems well and quickly.
')
An incident (or failure, emergency) is a kind of critical (usually massive) problem that significantly reduces the availability, correctness, efficiency, or reliability of the business functionality or infrastructure systems.
As part of the incident management process, we set ourselves the following main objectives :
1. As soon as possible to restore the performance of our systems.
2. Do not allow the same failure to occur twice.
3. Inform timely the interested persons.
We had a samopinny monitoring system, which meant an independent subscription of employees to reports of problems. That is, only those who subscribed to them received alerts. We learned about failures from this system, and then we acted rather scatteredly - someone from the service received an SMS, started to see what was happening, came to the people needed to solve or analyze the problem (or called them if it was a non-working time), the failure was finally decided. Then someone wrote a report on the failure in the format adopted at that time (description of the problem and causes, chronology and a set of planned actions aimed at “non-repetition”).
At the same time, there were obvious problems :
1. There was no complete certainty that someone had signed up for a critical alert. That is, there was a possibility that a failure would be noticed already when it affected other critical parts of the system.
2. There was no responsible for solving the problem, which will achieve its elimination in the shortest possible time. It is also not clear who should clarify the current status.
3. It was not possible to follow the incident information in the dynamics.
4. There was a lack of understanding if anyone saw the monitoring message? Did he react? What details have already been clarified, and is there any progress in the decision?
5. Several specialists duplicated each other’s actions. We looked at the same logs / graphics, went to the same people, and distracted them with repeated questions about whether they knew about the problem, at what stage the solution, and so on.
6. For those who did not directly participate in solving the incident, it was difficult to obtain information about its causes, ways of repair and what was happening. Because nowhere was it fixed who was doing what.
7. There was no equal understanding of what needs to be written in the failure report and what is not, how deeply to dive into the analysis. There was no clear process for formulating action games for improvement. As a result, failure reports could be incomplete, often looking different. From them it was difficult to understand what the effect was, what the reasons were, what they did in the decision process, and how they repaired it.
8. Only specialists of support and those who were directly involved in the elimination of causes and negative effects plunged into the analysis of the emergency situation. As a result, far from everyone interested received feedback about the problems.
With this failure handling process, we did not achieve our goals. Similar incidents happened, and the available reports did not help us much to cope with similar failures in the future. The reports did not always answer important questions - how the problem was solved, whether everything necessary was taken for non-repetition, and if not, why not. In addition, the inconsistency of our actions at the time of the incident did not contribute to the acceleration of the solution time, especially with the increase in the number of the department.

Now more about these changes.
Aims to achieve the first goal of the process - the rapid recovery of our systems.
At the beginning of work to improve this phase, our lack of effective communication, even within the operations department, was very painful. During working hours we could communicate on problems in the skype-chat department, but the team chat is for any business issues. It does not provide for an instant reaction to messages, and not all team members use this tool during off-hours.
Therefore, we decided that we need a separate communication channel for emergency situations in which there would be no other working correspondence. Our choice fell on Telegram, as they are easy and convenient to use from a mobile, and you can also expand its capabilities using bots. We created a chat and agreed to write to it, when someone found out that a failure had occurred, and began to deal with it. Since there are no extra messages in this chat, we must respond quickly to it at any time of the day. At first, only support staff members were chatting, but quite quickly administrators and some developers also appeared in it. That is, those people who can help quickly eliminate the failure.
This turned out to be a very convenient practice, since all participants in the process of handling incidents are gathered in one place, and everyone has information about what is happening. Often, now you don’t even need to ring up, say, administrators, one by one, to find someone who can tackle the problem. All the necessary people are in the chat, and they unsubscribe when they notice an alert (or they can be called upon). Here I will explain - we don’t have on-call as such, so the solution of incidents during off-hours is the one who is at the moment near the computer. While it works for us.
After that, the problem was almost solved with informing the people involved in the malfunctioning about what was happening “in battle” and who was engaged in the solution. Later we brought critical monitoring messages directly to this chat. Now alerts are guaranteed to come to anyone who needs it, and it does not depend on whether a person has subscribed to the sensors or not.
We also made a number of improvements to improve the manageability of the process.
We can learn about the incident in two ways:
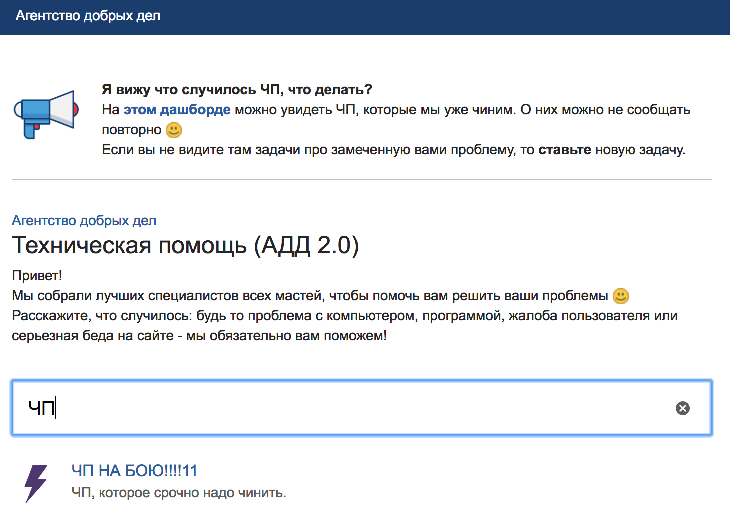
In any case, we must record the incident in JIRA - to control the time of occurrence / resolution of the problem, as well as to inform the interested parties. To do this, we have allocated a special section in the Service Desk (“PE-fight”), where any employee of the company can put the task. We also have a panel on which all active tasks with this component are displayed. The panel is available directly from the task setting interface in the Service Desk, and there you can find the answer to the question of whether there is a problem in the battle and whether it is solved.
We set up the sending of automatic notification to the Telegram-chat to solve an emergency for the event of setting the “state of emergency” task. This allows you to be sure that the problem will be noticed even after hours.
If we have learned about the problem from monitoring, then we have to set the “emergency fight” task ourselves. Since the corresponding alerts come to the chat, it seemed to us convenient to automate the formulation of the problem in JIRA. Now we can do it by pressing one button in the chat - the task is created on behalf of a special user for automation and contains the text of the triggered alert. Thus, the fixation of the incident is quick and convenient, we do not spend on it too much time.
When the task of “emergency fight” comes, we define a “navigator” - a person from the operations department who will be responsible for eliminating the failure. This does not mean that the rest cease to participate in the analysis, everyone is involved, but the navigator is necessary so that employees do not duplicate each other’s actions. The navigator should coordinate communications and actions to resolve the incident, to attract the necessary forces for this. And also in a timely manner to record information about the progress of work, so that later during the analysis you can easily restore the chronology.
The navigator is appointed the executor of the task "state of emergency". When the task is assigned, our colleagues understand that they are engaged in the problem, and, in which case, they know who to contact with questions.
When we managed to eliminate the negative effects - the active phase is completed, the task is closed.
In this phase, from the point of view of the processes, it turned out to be the most difficult to form a common understanding of who should be in the role of navigator. We decided that they could be the one who first noticed the emergency, but it would be better if this would be a supporter of the affected product.

Starts immediately after the completion of the active. Serves to achieve the second goal of the process - to prevent the repetition of the same failure.
Phase includes a comprehensive comprehensive analysis of what happened. The officer responsible for analyzing the incident should collect all available information about what happened, for what reasons, and what actions were taken to restore operability. After the causes of the incident became clear, we hold a meeting on the analysis of the incident. It usually involves people who were involved in solving the problem, as well as the team leaders of the development teams involved. The purpose of the meeting is to identify growth points for our systems or processes and to plan actions to improve them in order to prevent the occurrence of similar incidents in the future.
The result is a crash report, which contains both complete information about what happened, and what bottlenecks we have identified and what we plan to take to eliminate them.
In order for our reports to be written qualitatively and contain everything necessary, we formulated clear requirements for each section and fixed them in the standard. And also reworked the document template and added useful tips to it. In addition, we have collected in a separate document general recommendations on the design of the report, which help to properly submit the material and avoid common mistakes.
The crash report is an important document that serves the third goal of the process — informing interested parties about incidents and actions taken afterwards. It is also a tool for gathering experience and knowledge about how our systems work and break. We can always return to a particular incident, see how it proceeded and how it was processed, or recall the report for the purposes for which this or that improvement task was done.
We got the following document structure :
Description of the incident. Consists of two parts. The first is a brief description of what happened, with reasons and effects. The second part is detailing. In it, we describe in detail the reasons that led to the incident, how we learned about it, how it developed, which log entries / error messages were and how it was repaired. In general, here is going to complete technical information about what happened.
Effect. We describe how the incident affected our users - how many users faced what problems. We need to understand the effect in order to prioritize the improvement tasks.
Chronology. To record all actions related to the incident, with the time. From this section, you can get an idea of the progress of the incident, you can see how quickly we reacted, we can draw conclusions about whether the monitoring took place in time, how long the correction took.
In terms of chronology, bottlenecks in processes are usually quite well marked.
Charts and statistics. In this section, we collect all the graphs that show the effect (for example, how many were 5XX errors), as well as any other illustrations of any aspects of the incident.
Actions taken. This section is usually filled out after a technical meeting. It records all planned improvement actions, assigned tasks, and indicating the person in charge. Also here we make corrections that were made in the active phase, if they give a long-term effect. All actions in this section are formulated in such a way that it is clear which of the identified problems they help to solve. After the completion of incident handling, we continue to monitor the implementation of the assigned tasks until all of them are completed or reasonably canceled.
Separately, we highlighted the status of the document and formulated the requirements for its change. This helps to better understand what the report should look like at each stage of incident handling. There may be three statuses - “in work”, “ready for a technical meeting”, and “work completed”. Thanks to this, it has become convenient to track failures that are still underway.
Let's sum up. We began to introduce a new incident management process a year and a half ago, and since then we continue to improve it. A new organization of work helps us more effectively achieve our goals and solve emerging problems.
Now all the critical messages from the monitoring are displayed in a telegram-chat for solving a state of emergency in which there are all the necessary employees. And chat is required for quick response at any time.
Due to the emergence of the role of the navigator and the formulation of requirements for this role, each incident always has a responsible person who is aware of what is happening. He publishes all the necessary information in a timely manner, and also coordinates the incident resolution process. As a result, we managed to reduce the number of duplicate actions.
All information is now recorded in the chat. Due to this, it became possible to transfer a retrospective analysis to any employee of the operational service, regardless of whether he was present at the time of the active phase of the failure.
After we formulated and described clear requirements and recommendations for the drafting of the document, the employees of the operations department began to develop a similar understanding of what should be reflected in the report. We constantly work on the quality of the report design - for example, we conduct reviews, which also contributes to the exchange of experience.
Due to the fact that we began to hold debriefing meetings, the team leaders and administrators are also more involved in the process. They participate in meetings, they know the consequences of certain bottlenecks in the code or infrastructure and are better informed about why we need to carry out the tasks that we put in teams after analyzing incidents.
Analysis of incidents in our company is engaged in the maintenance department (or, easier, support). Therefore, I will begin by describing how it works. In Tutu.ru we have a certain set of products, it is - railway, air, tours, trains, buses. In the team of each product there are specialists in the operation department Also, representatives of our department are in the cross-functional and infrastructure teams.
We are responsible for ensuring that our users have no problems when using the service. This includes team-specific tasks to support our external and internal customers, as well as work to ensure that at all the speed of change, the site experienced equipment failures, withstood loads and continued to solve user problems well and quickly.
')
An incident (or failure, emergency) is a kind of critical (usually massive) problem that significantly reduces the availability, correctness, efficiency, or reliability of the business functionality or infrastructure systems.
As part of the incident management process, we set ourselves the following main objectives :
1. As soon as possible to restore the performance of our systems.
2. Do not allow the same failure to occur twice.
3. Inform timely the interested persons.
How to work before:
We had a samopinny monitoring system, which meant an independent subscription of employees to reports of problems. That is, only those who subscribed to them received alerts. We learned about failures from this system, and then we acted rather scatteredly - someone from the service received an SMS, started to see what was happening, came to the people needed to solve or analyze the problem (or called them if it was a non-working time), the failure was finally decided. Then someone wrote a report on the failure in the format adopted at that time (description of the problem and causes, chronology and a set of planned actions aimed at “non-repetition”).
At the same time, there were obvious problems :
1. There was no complete certainty that someone had signed up for a critical alert. That is, there was a possibility that a failure would be noticed already when it affected other critical parts of the system.
2. There was no responsible for solving the problem, which will achieve its elimination in the shortest possible time. It is also not clear who should clarify the current status.
3. It was not possible to follow the incident information in the dynamics.
4. There was a lack of understanding if anyone saw the monitoring message? Did he react? What details have already been clarified, and is there any progress in the decision?
5. Several specialists duplicated each other’s actions. We looked at the same logs / graphics, went to the same people, and distracted them with repeated questions about whether they knew about the problem, at what stage the solution, and so on.
6. For those who did not directly participate in solving the incident, it was difficult to obtain information about its causes, ways of repair and what was happening. Because nowhere was it fixed who was doing what.
7. There was no equal understanding of what needs to be written in the failure report and what is not, how deeply to dive into the analysis. There was no clear process for formulating action games for improvement. As a result, failure reports could be incomplete, often looking different. From them it was difficult to understand what the effect was, what the reasons were, what they did in the decision process, and how they repaired it.
8. Only specialists of support and those who were directly involved in the elimination of causes and negative effects plunged into the analysis of the emergency situation. As a result, far from everyone interested received feedback about the problems.
With this failure handling process, we did not achieve our goals. Similar incidents happened, and the available reports did not help us much to cope with similar failures in the future. The reports did not always answer important questions - how the problem was solved, whether everything necessary was taken for non-repetition, and if not, why not. In addition, the inconsistency of our actions at the time of the incident did not contribute to the acceleration of the solution time, especially with the increase in the number of the department.
What did:
- We divided the work with incidents into two phases - active and retrospective - and began to improve each of them separately.
- Developed a standard for processing an emergency where they fixed all the requirements and agreements, described a set of actions that are required for each phase of the process.
- We began writing recommendations documents that collected good practices for different stages of the incident review process.
Now more about these changes.
Active phase
Aims to achieve the first goal of the process - the rapid recovery of our systems.
At the beginning of work to improve this phase, our lack of effective communication, even within the operations department, was very painful. During working hours we could communicate on problems in the skype-chat department, but the team chat is for any business issues. It does not provide for an instant reaction to messages, and not all team members use this tool during off-hours.
Therefore, we decided that we need a separate communication channel for emergency situations in which there would be no other working correspondence. Our choice fell on Telegram, as they are easy and convenient to use from a mobile, and you can also expand its capabilities using bots. We created a chat and agreed to write to it, when someone found out that a failure had occurred, and began to deal with it. Since there are no extra messages in this chat, we must respond quickly to it at any time of the day. At first, only support staff members were chatting, but quite quickly administrators and some developers also appeared in it. That is, those people who can help quickly eliminate the failure.
This turned out to be a very convenient practice, since all participants in the process of handling incidents are gathered in one place, and everyone has information about what is happening. Often, now you don’t even need to ring up, say, administrators, one by one, to find someone who can tackle the problem. All the necessary people are in the chat, and they unsubscribe when they notice an alert (or they can be called upon). Here I will explain - we don’t have on-call as such, so the solution of incidents during off-hours is the one who is at the moment near the computer. While it works for us.
After that, the problem was almost solved with informing the people involved in the malfunctioning about what was happening “in battle” and who was engaged in the solution. Later we brought critical monitoring messages directly to this chat. Now alerts are guaranteed to come to anyone who needs it, and it does not depend on whether a person has subscribed to the sensors or not.
We also made a number of improvements to improve the manageability of the process.
We can learn about the incident in two ways:
- monitoring alerts,
- from our employees who noticed the problem - if monitoring for some reason did not inform us about it.
In any case, we must record the incident in JIRA - to control the time of occurrence / resolution of the problem, as well as to inform the interested parties. To do this, we have allocated a special section in the Service Desk (“PE-fight”), where any employee of the company can put the task. We also have a panel on which all active tasks with this component are displayed. The panel is available directly from the task setting interface in the Service Desk, and there you can find the answer to the question of whether there is a problem in the battle and whether it is solved.
We set up the sending of automatic notification to the Telegram-chat to solve an emergency for the event of setting the “state of emergency” task. This allows you to be sure that the problem will be noticed even after hours.
If we have learned about the problem from monitoring, then we have to set the “emergency fight” task ourselves. Since the corresponding alerts come to the chat, it seemed to us convenient to automate the formulation of the problem in JIRA. Now we can do it by pressing one button in the chat - the task is created on behalf of a special user for automation and contains the text of the triggered alert. Thus, the fixation of the incident is quick and convenient, we do not spend on it too much time.
When the task of “emergency fight” comes, we define a “navigator” - a person from the operations department who will be responsible for eliminating the failure. This does not mean that the rest cease to participate in the analysis, everyone is involved, but the navigator is necessary so that employees do not duplicate each other’s actions. The navigator should coordinate communications and actions to resolve the incident, to attract the necessary forces for this. And also in a timely manner to record information about the progress of work, so that later during the analysis you can easily restore the chronology.
The navigator is appointed the executor of the task "state of emergency". When the task is assigned, our colleagues understand that they are engaged in the problem, and, in which case, they know who to contact with questions.
When we managed to eliminate the negative effects - the active phase is completed, the task is closed.
In this phase, from the point of view of the processes, it turned out to be the most difficult to form a common understanding of who should be in the role of navigator. We decided that they could be the one who first noticed the emergency, but it would be better if this would be a supporter of the affected product.
Retrospective phase
Starts immediately after the completion of the active. Serves to achieve the second goal of the process - to prevent the repetition of the same failure.
Phase includes a comprehensive comprehensive analysis of what happened. The officer responsible for analyzing the incident should collect all available information about what happened, for what reasons, and what actions were taken to restore operability. After the causes of the incident became clear, we hold a meeting on the analysis of the incident. It usually involves people who were involved in solving the problem, as well as the team leaders of the development teams involved. The purpose of the meeting is to identify growth points for our systems or processes and to plan actions to improve them in order to prevent the occurrence of similar incidents in the future.
The result is a crash report, which contains both complete information about what happened, and what bottlenecks we have identified and what we plan to take to eliminate them.
In order for our reports to be written qualitatively and contain everything necessary, we formulated clear requirements for each section and fixed them in the standard. And also reworked the document template and added useful tips to it. In addition, we have collected in a separate document general recommendations on the design of the report, which help to properly submit the material and avoid common mistakes.
The crash report is an important document that serves the third goal of the process — informing interested parties about incidents and actions taken afterwards. It is also a tool for gathering experience and knowledge about how our systems work and break. We can always return to a particular incident, see how it proceeded and how it was processed, or recall the report for the purposes for which this or that improvement task was done.
We got the following document structure :
Description of the incident. Consists of two parts. The first is a brief description of what happened, with reasons and effects. The second part is detailing. In it, we describe in detail the reasons that led to the incident, how we learned about it, how it developed, which log entries / error messages were and how it was repaired. In general, here is going to complete technical information about what happened.
Effect. We describe how the incident affected our users - how many users faced what problems. We need to understand the effect in order to prioritize the improvement tasks.
Chronology. To record all actions related to the incident, with the time. From this section, you can get an idea of the progress of the incident, you can see how quickly we reacted, we can draw conclusions about whether the monitoring took place in time, how long the correction took.
In terms of chronology, bottlenecks in processes are usually quite well marked.
Charts and statistics. In this section, we collect all the graphs that show the effect (for example, how many were 5XX errors), as well as any other illustrations of any aspects of the incident.
Actions taken. This section is usually filled out after a technical meeting. It records all planned improvement actions, assigned tasks, and indicating the person in charge. Also here we make corrections that were made in the active phase, if they give a long-term effect. All actions in this section are formulated in such a way that it is clear which of the identified problems they help to solve. After the completion of incident handling, we continue to monitor the implementation of the assigned tasks until all of them are completed or reasonably canceled.
Separately, we highlighted the status of the document and formulated the requirements for its change. This helps to better understand what the report should look like at each stage of incident handling. There may be three statuses - “in work”, “ready for a technical meeting”, and “work completed”. Thanks to this, it has become convenient to track failures that are still underway.
Let's sum up. We began to introduce a new incident management process a year and a half ago, and since then we continue to improve it. A new organization of work helps us more effectively achieve our goals and solve emerging problems.
How the problems of the active phase were solved:
- There was no complete certainty that someone had signed up for a critical alert.
Now all the critical messages from the monitoring are displayed in a telegram-chat for solving a state of emergency in which there are all the necessary employees. And chat is required for quick response at any time.
- No responsible for solving the problem, which will achieve its elimination in the shortest possible time. It is also not clear who specify the current status.
- Absence of information related to the incident at any time.
- Several specialists duplicated each other’s actions.
Due to the emergence of the role of the navigator and the formulation of requirements for this role, each incident always has a responsible person who is aware of what is happening. He publishes all the necessary information in a timely manner, and also coordinates the incident resolution process. As a result, we managed to reduce the number of duplicate actions.
Solving the problems of the retrospective phase:
- For those who were not directly involved in solving the incident, it was difficult to obtain information about the causes, methods of repair and what was happening.
All information is now recorded in the chat. Due to this, it became possible to transfer a retrospective analysis to any employee of the operational service, regardless of whether he was present at the time of the active phase of the failure.
- There was no equal understanding of what to write in the crash report. According to reports, it was sometimes difficult to fully restore the picture of what happened.
After we formulated and described clear requirements and recommendations for the drafting of the document, the employees of the operations department began to develop a similar understanding of what should be reflected in the report. We constantly work on the quality of the report design - for example, we conduct reviews, which also contributes to the exchange of experience.
- Only support specialists and those who were directly involved in the elimination of the causes and the negative effect plunged into the emergency review. Far from everyone interested received feedback about the problems.
Due to the fact that we began to hold debriefing meetings, the team leaders and administrators are also more involved in the process. They participate in meetings, they know the consequences of certain bottlenecks in the code or infrastructure and are better informed about why we need to carry out the tasks that we put in teams after analyzing incidents.
Source: https://habr.com/ru/post/346946/
All Articles