How we chose between Elastic and Tarantool, and made our (fastest) in-memory database. With Join and Full-Text Search
Hello.
Since mid-2016, we have been designing and developing a new generation of platform. The principal difference from the first generation is the support of the thin-client API. If the old platform assumes that when the client starts, meta-information about all the content that is available to the subscriber is loaded, then the new platform should render the data slices filtered and sorted for display on each screen / page.
High-level architecture at the level of data storage within the system - permanent storage of all data in centralized relational SQL storage. The choice fell on Postgres, there are no revelations. As the main language for development, I chose golang.
The system has about 10m users. We figured that given the tele-viewing profile, 10M users can give hundreds of thousands of RPS to the entire system.

This means that requests from clients and close should not be allowed to relational SQL database without caching, and between the SQL database and customers should be a good cache.
We looked at existing solutions - we drove prototypes. There is little data by modern standards, but the filtering parameters (read business logic) are complex and, most importantly, personalized - depending on the user session, i.e. using query parameters as a caching key in KV cache will be very expensive, especially since nobody canceled paging and a rich set of sorts. In fact, a completely unique set of filtered records is formed for each request from the user.
Following the results of the finished solutions, nothing came up. Simple KV bases of the Redis type were dropped almost immediately: it does not fit in functionality - all filtering and aggregation will have to be implemented at the Application Level, and this is expensive. I looked at Tarantool. also did not fit functionally
We looked at Elastic - functionally approached. But the performance of issuing content according to the requirements of business logic came out in the region of 300-500 RPS.
With the expected load, even in 100K RPS, you need 200-300 servers for elastic butt. In the money - it is several million dollars.
When they figured it out, my plan was already almost ripe in my head - to write my own great, in-memory cache engine in C ++ and conduct our tests on it. No sooner said than done. The prototype was implemented almost a couple of weeks. Run tests.
Wow Received 15k RPS on the same gland, with the same conditions where Elastic gave 500.
The difference is 20 times. More than an order of magnitude, Karl!
The first, not Proof-Of-Concept, version of the backend with its in-memory cache appeared at the end of 2016. By mid-2017, Reindexer had already formed into a fully-featured database, acquired its own repository and full-text search engine, at the same time we published it on github .

Technical details
Reindexer is a general purpose NoSQL in-memory database. According to the data storage structure, Reindexer combines all the main approaches:
- optimized binary JSON representation with addition from a table row with indexable fields
- optional column storage of selected index fields
This combination allows you to achieve maximum speed of access to field values, and on the other hand not to require the application to define a rigid data scheme.
Indices
There are 4 types of index for query execution:
- hash table, the fastest index for sampling by value
- binary tree, with the possibility of quick samples by the conditions '<', '>' and sorting by field
- column, the minimum overhead memory, but the search is slower than the binary tree and hash
- full-text index, or rather even two: fast, not memory-demanding, and advanced based on trigrams
When inserting records into tables, the “lazy” index construction method is used. regardless of the number of indexes, the insertion occurs almost instantly, and the indexes are completed only at the moment when they are required to fulfill the query.
Disk storage
In general, Reindexer is a completely in-memory database, that is, all the data with which Reindexer works must be in RAM. Therefore, the main purpose of disk storage is to load data at the start.
When adding entries to Reindexer, data is written to the disk in the background, with almost no delays in the insertion process.
Reindexer uses leveldb as a backend of disk storage.
Full text search
For full-text search, Reindexer has two engines of its own:
fast, with minimum memory requirements, based on suffixarray, with support for morphology and typos.fuzzy, trigram - gives a better search quality, but of course it requires more memory and runs slower. While he is in experimental status.
In both engines there is support for search by transliteration and search with the wrong keyboard layout. The ranking of search results takes into account statistical probabilities (BM25), the accuracy of the match, and about 5 more parameters. The ranking formula can be flexibly configured depending on the tasks to be solved.
Also, there is the possibility of full-text search in several tables, with the output of results sorted by relevance.
For the formation of requests for full-text search using a special DSL.
Join
Reindexer can do Join. To be precise, in the world of NoSQL, as a rule, there is no Join operation in its pure form, but there is a functional that allows you to insert into each response result a field containing entities from the joined table. For example, in Elastic this functionality is called nested queries , in mongo - lookup aggregation .
In Reindexer, this functionality is called Join. The left join and inner join mechanics are supported.
Cache deserialized objects
The data in Reindexer is stored in the memory area of a managed C ++, and when a sample is received in a golang application, the results are deserialized into a golang structure. In general, by the way, the golang part of the Reindexer has a very fast deserializer: about 3-4 times faster than JSON, and 2 times faster than BSON. But even with this in mind, deserialization is a relatively slow operation that creates new objects on the heap and loads GC.
The object cache in the golang part of Reindexer solves the problem of reusing already deserialized objects, without spending too much time on slow re-de-serialization.
Using Reindexer in the Golang application
It's time to move from words to action, and see how to use Reindexer in the golang application.
The interface for Reindexer is implemented as a Query builder, for example, queries are written to tables in this way:
db := reindexer.NewReindex("builtin") db.OpenNamespace("items", reindexer.DefaultNamespaceOptions(), Item{}) it := db.Query ("media_items").WhereInt ("year",reindexer.GT,100).WhereString ("genre",reindexer.SET,"action","comedy").Sort ("ratings") for it.Next() { fmt.Println (it.Object()) } As you can see from the example, it is possible to construct complex samples for many filtering conditions and with arbitrary sorts.
package main // import ( "fmt" "math/rand" "github.com/restream/reindexer" // Reindexer ( `builtin`, ) _ "github.com/restream/reindexer/bindings/builtin" ) // , 'reindex' type Item struct { ID int64 `reindex:"id,,pk"` // 'id' Name string `reindex:"name"` // 'name' Articles []int `reindex:"articles"` // 'articles' Year int `reindex:"year,tree"` // btree 'year' Descript string // , } func main() { // , 'builtin' db := reindexer.NewReindex("builtin") // ( ) db.EnableStorage("/tmp/reindex/") // (namespace) 'items', 'Item' db.OpenNamespace("items", reindexer.DefaultNamespaceOptions(), Item{}) // for i := 0; i < 100000; i++ { err := db.Upsert("items", &Item{ ID: int64(i), Name: "Vasya", Articles: []int{rand.Int() % 100, rand.Int() % 100}, Year: 2000 + rand.Int()%50, Descript: "Description", }) if err != nil { panic(err) } } // 'items' - 1 , id == 40 elem, found := db.Query("items"). Where("id", reindexer.EQ, 40). Get() if found { item := elem.(*Item) fmt.Println("Found document:", *item) } // 'items' - query := db.Query("items"). Sort("year", false). // 'year' WhereString("name", reindexer.EQ, "Vasya"). // 'name' 'Vasya' WhereInt("year", reindexer.GT, 2020). // 'year' 2020 WhereInt("articles", reindexer.SET, 6, 1, 8). // 'articles' [6,1,8] Limit(10). // 10- Offset(0). // 0 ReqTotal() // , // iterator := query.Exec() // Iterator defer iterator.Close() // , if err := iterator.Error(); err != nil { panic(err) } fmt.Println("Found", iterator.TotalCount(), "total documents, first", iterator.Count(), "documents:") // for iterator.Next() { // elem := iterator.Object().(*Item) fmt.Println(*elem) } } In addition to the Query Builder, Reindexer has built-in support for queries in SQL format.
Performance
One of the main motivating reasons for the emergence of Reindexer was the development of the most productive solution, significantly surpassing existing solutions. Therefore, the article would not be complete without specific figures - measurements of performance.
We conducted comparative load testing of the performance of Reindexer and other popular SQL and NoSQL databases. The main object of comparison is historically Elastic and MongoDB , which are functionally closest to Reindexer.
Tarantool and Redis are Tarantool involved in the tests, which are functionally more modest, but nevertheless are also often used as a hot data cache between SQL DB and the API client.
For completeness, a couple of SQL solutions were included in the list of tested databases - Mysql and Sqlite .
Reindexer has a full-text search, so we could not deny ourselves the temptation to compare performance with Sphinx
And the last participant is Clickhouse . In general, Clickhouse is a database sharpened for other tasks, but nevertheless, periodically questions come to us, “why not Clickhouse”, so we decided to add it to the tests.
Benchmarks and their results
Let's start with the results, and the technical details of the tests, the description of the methodology and the data immediately after the graphs.
- Get a record by primary key. This functionality is in all databases participating in the test.
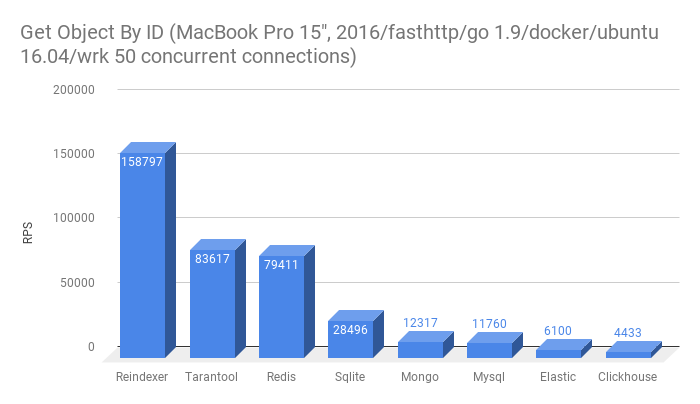
- Get a list of 10 entities filtered by one field, not primary key
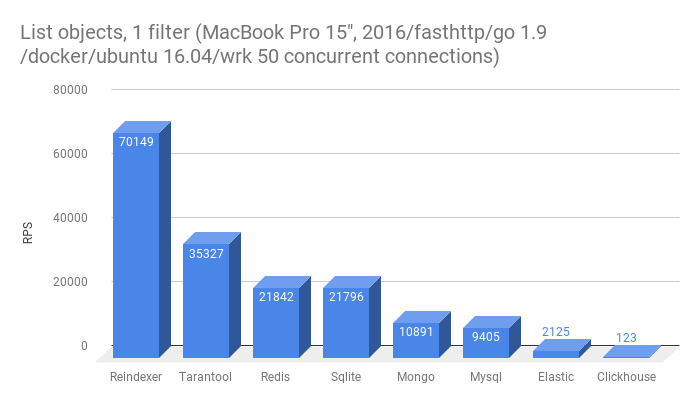
- Get a list of 10 entities filtered by two fields
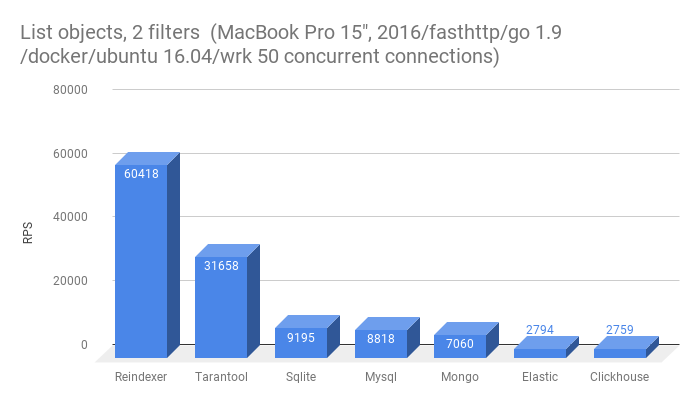
Redis dropped out of this test, and there is a possibility of emulating the secondary index , however, this requires additional actions from the application when saving / loading records in Redis .
- Overwrite entity in db
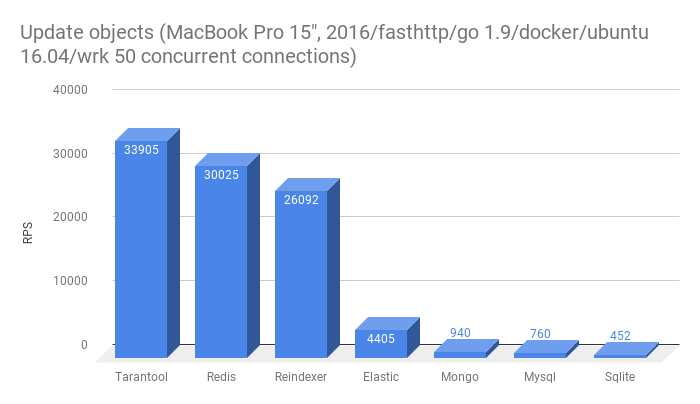
Clickhouse dropped out of this test because it does not support Update. Low rewriting speeds in many databases are most likely the result of having a full-text index in the table into which the data is inserted. Tarantool and Redis do not have full-text search.
- Full-text search for exact word forms
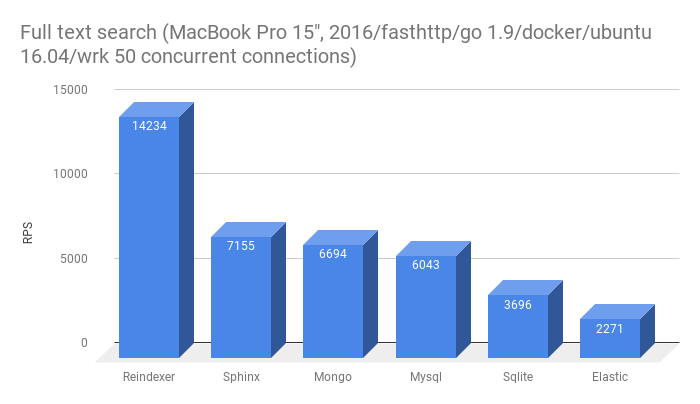
- Full-text search for inaccurate word forms (prefixes and typos)
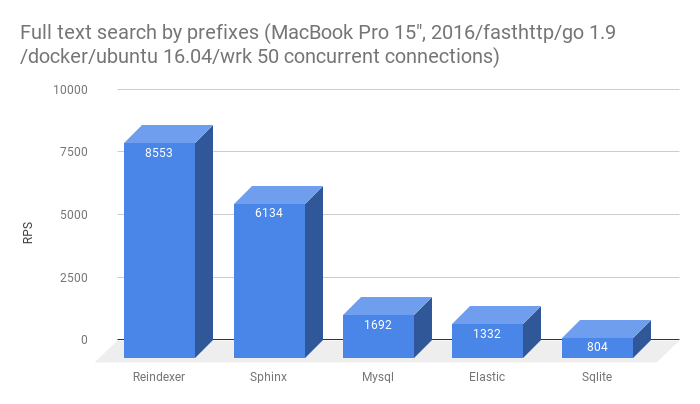
Testing environment
All tests were performed in a docker container running on MacBookPro 15 ", 2016. Guest OS - Ubuntu 16.04 LTS. To minimize the impact of the network stack, all databases, test micro-backend and shelling were launched inside the shared container and all network connections were localhost.
8GB of RAM and all 8 CPU cores are allocated to the container.
Test backend
For testing, we made a micro-backend on golang, processing a request for urls of the form: http://127.0.0.1:8080/ <test name> / <database name>
The micro-backend structure, though very simple, but repeats the structure of a real application: there is a repository layer with connectors to the test database and the http API layer, giving answers to the client in JSON format.
The fasthttp package is used to process http requests, and the standard encoding / json package is used for serialization of responses.
Working with SQL DB through the sqlx package. Connection Pool - 8 connections. A little running ahead, this number was obtained experimentally - with these settings, the SQL databases gave the best result.
gopkg.in/olivere/elastic.v5 used to work with Elastic - I had to conjure a bit with it. Regularly, he didn’t want to work in the keep alive mode - the problem was solved only by transferring http.Client to it with the MaxIdleConnsPerHost:100 setting MaxIdleConnsPerHost:100 .
The Tarantool, Redis, Mongo connectors didn’t cause any troubles - they work out of the box efficiently in a multithreaded mode and there were no settings to significantly speed them up.
Sphinx connector github.com/yunge/sphinx delivered the most trouble - it doesn’t support much threading. And testing in one stream is obviously not a valid test.
Therefore, we had no choice but to do how to implement our connection pool for this connector.
Test data
In the test data set 100k records. There are 4 fields in the record:
idunique identifier of the record, a number from 0 to 99999namename. a string of two random names. ~ 1000 unique keysyearyear. integer from 2000 to 2050descriptionrandom text 50 words from a dictionary in 100k words
The size of each entry in the format Json ~ 500 bytes. Write example
{ "id": 73, "name": "welcome ibex", "description": "cheatingly ... compunction ", "year": 2015 } Shelling
Shelling was carried out by the wrk utility in 50 competing compounds. For each test of each base, 10 attacks were conducted and the best result was selected. Between tests, a pause of a few seconds to prevent the processor from overheating and going into throttling.
Test results
As part of the tests, it was important to build a solution that is similar in structure to a production solution, without the 'triks', `hacks', and under equal conditions for all the databases in the test.
Benchmarks do not claim to be 100% complete, but they reflect the main set of cases of work with the base.
I posted the microback-up and Dockerfile source codes on github , and if you wish, they are not difficult to reproduce.
What's next
Now the core functionality of Reindexer is stabilized and Production Ready. The Golang API is stabilized, and it does not expect breaking changes in the foreseeable future.
However, Reindexer is still a very young project, it is just over a year old, not everything has been implemented in it yet. It is actively developing and improving and, as a result, the internal C ++ API is not fixed yet and sometimes it changes.
Three options for connecting Reindexer to the project are now available:
- library to golang
- C ++ library
- standalone server running http protocol
The plans have a binding implementation for Python and a binary protocol implementation in the server.
Also, at the moment, data replication between nodes at the Reindex level is not implemented. For the main case, using Reindexer as a fast cache between SQL and clients is not critical. Nodes replicate data from SQL at the Application level, and this seems to be quite enough.
Instead of conclusion
It seems that it turned out to realize a beautiful and, not afraid of this word, unique solution that combines the functionality of complex databases and performance by several times, or even an order of magnitude superior to the existing solution.
Most importantly, Reindexer allows you to save millions of dollars on hardware right now, without increasing the development costs of the Application Level - after all, Reindexer has a high-level API, the use of which is no more difficult than regular SQL or ORM.
Ps. The comments asked to add a link to github at the end of the article. Here she is:
Reindexer repository on github .
')
Source: https://habr.com/ru/post/346884/
All Articles