One-cloud - OS-level data center in Odnoklassniki

Aloha, People! My name is Oleg Anastasyev, I work in Odnoklassniki in the Platform team. And besides me, a lot of iron works in Odnoklassniki. We have four data centers, they have about 500 racks with more than 8 thousand servers. At a certain point, we realized that the introduction of a new management system would allow us to more efficiently load equipment, facilitate access management, automate (re) distribution of computing resources, speed up the launch of new services, speed up reactions to large-scale accidents.
What came of it?
In addition to me and the heaps of iron, there are still people who work with this iron: engineers who are directly in the data centers; networkers who set up network support; admins, or SREs, that provide infrastructure resiliency; and development teams, each of which is responsible for part of the portal’s functions. The software they create works something like this:

User requests are received both on the fronts of the main portal www.ok.ru , and on others, for example, on the fronts of the music API. For processing business logic, they invoke an application server, which, when processing a request, calls the necessary specialized microservices - one-graph (social networking graph), user-cache (user profile cache), etc.
Each of these services is deployed on a variety of machines, and each of them has responsible developers responsible for the functioning of the modules, their operation and technological development. All these services run on iron servers, and until recently we ran exactly one task per server, that is, it was specialized for a specific task.
Why is that? This approach had several advantages:
- Mass control is facilitated. Suppose a task requires some libraries, some settings. And then the server is assigned to exactly one specific group, the cfengine policy for this group is described (or it has already been described), and this configuration is centrally and automatically rolled out to all servers of this group.
- Simplified diagnosis . Suppose you are looking at the increased load on the CPU and you realize that only the task that runs on this iron processor could have generated this load. The search for the culprit ends very quickly.
- Monitoring is simplified. If something is wrong with the server, the monitor reports this, and you know exactly who is to blame.
A service consisting of several replicas is allocated several servers, one for each. Then the computing resource for the service is very simple: how many servers have the service, so much can it consume the most resources. “Just” is not in the sense that it is easy to use, but in the fact that the distribution of resources is done manually.
This approach also allowed us to make specialized iron configurations for a task running on this server. If the task stores large amounts of data, then we use a 4U server with a chassis of 38 disks. If the task is purely computational, then we can buy a cheaper 1U server. This is effective in terms of computing resources. Including this approach allows us to use four times fewer machines with a load comparable to one friendly social network.
Such efficiency in the use of computational resources should also ensure economic efficiency, assuming that the most expensive is servers. For a long time, it was iron that cost the most, and we invested a lot of effort in reducing the price of iron, inventing fault tolerance algorithms to reduce equipment reliability requirements. And today we have reached the stage at which the server price has already ceased to be decisive. If you do not consider the freshest exotic, then the specific configuration of servers in the rack does not matter. Now we have another problem - the price of the space occupied by the server in the data center, i.e. the space in the rack.
Realizing that this is so, we decided to calculate how effectively we use the rack.
We took the price of the most powerful server out of the economically sound ones, calculated how many such servers we can put in racks, how many tasks we would run on them based on the old model “one server = one task” and how much such tasks could utilize the equipment. Counted - wept. It turned out that the efficiency of using racks in our country is about 11%. The conclusion is obvious: it is necessary to increase the efficiency of using data centers. It would seem that the solution is obvious: you need to run several tasks on one server at once. But here begins the complexity.
Mass configuration becomes more complicated - now it is impossible to assign any one group to the server. After all, now several tasks of different teams can be run on the same server. In addition, the configuration may be conflicting for different applications. Diagnostics is also complicated: if you see an increased consumption of processors or disks on the server, then you do not know which of the tasks is causing trouble.
But the main thing is that there is no isolation between tasks running on the same machine. Here, for example, the graph of the average response time of the server task before and after another calculation program not related to the first one was launched on the same server - the response time from the main task has greatly increased.

Obviously, you need to run tasks either in containers or in virtual machines. Since almost all tasks are run under one OS (Linux) or are adapted for it, we do not need to support many different operating systems. Accordingly, virtualization is not needed, because of the additional overhead, it will be less efficient than containerization.
As a container implementation for running tasks directly on Docker servers, this is a good candidate: file system images solve problems with conflicting configurations well. The fact that images can be composed of several layers allows us to significantly reduce the amount of data required for their deployment on the infrastructure, highlighting the common parts into separate basic layers. Then the basic (and most voluminous) layers will be cached quite quickly across the entire infrastructure, and for the delivery of many different types of applications and versions, only small-sized layers will need to be transferred.
Plus, a ready registry and image tagging in Docker give us ready-made primitives for versioning and delivering code in production.
Docker, like any other similar technology, provides us with some level of isolation of containers out of the box. For example, memory isolation — each container is given a limit on the use of machine memory, above which it will not consume. You can also isolate containers by CPU usage. For us, however, standard insulation was not enough. But more about that - below.
Running containers directly on servers is only part of the problem. The other part is related to the placement of containers on servers. You need to understand which container on which server you can put. This is not such an easy task, because containers should be placed on servers as tightly as possible, without slowing down their work. This placement can be difficult in terms of fault tolerance. Often we want to place replicas of the same service in different racks or even in different halls of the data center, so that if a rack or hall fails, we will not lose all the replicas of the service at once.
Manually distributing containers is not an option when you have 8 thousand servers and 8-16 thousand containers.
In addition, we wanted to give developers more autonomy in the allocation of resources so that they could themselves place their services on production, without the help of the administrator. At the same time, we wanted to keep control so that some secondary service would not consume all the resources of our data centers.
Obviously, we need a control layer that would do this automatically.
Here we come to a simple and clear picture that all architects adore: three squares.
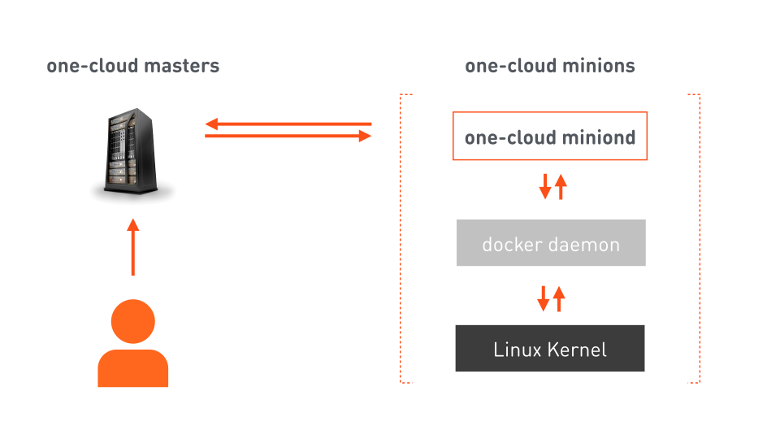
one-cloud masters is a failover cluster responsible for cloud orchestration. The developer sends to the master manifest, which contains all the information necessary for hosting the service. The wizard on its basis gives commands to selected minions (machines intended for launching containers). On the minions there is our agent, who receives the command, gives up his Docker commands, and Docker configures the linux kernel to launch the corresponding container. In addition to executing commands, the agent continuously informs the master about changes in the state of both the minion machine and the containers running on it.
Resource allocation
And now let's deal with the task of a more complex resource allocation for many minions.
The computing resource in one-cloud is:
- The computing power of the processor consumed by a specific task.
- The amount of memory available to the task.
- Network traffic Each of the minions has a specific network interface with a limited bandwidth, so you cannot distribute tasks without taking into account the amount of data transmitted by them.
- Discs. In addition to, obviously, space for these tasks, we also highlight the type of drive: HDD or SSD. Disks can serve a finite number of requests per second - IOPS. Therefore, for tasks that generate more IOPS than a single disk can serve, we also allocate “spindles” —that is, disk devices that need to be reserved exclusively for the task.
Then for some service, for example, for user-cache, we can record the consumed resources in this way: 400 processor cores, 2.5 TB of memory, 50 Gbit / s of traffic in both directions, 6 TB of space on the HDD, located on 100 spindles . Or in a more familiar form:
alloc: cpu: 400 mem: 2500 lan_in: 50g lan_out: 50g hdd:100x6T User-cache service resources consume only a fraction of all available resources in the production-infrastructure. Therefore, I want to make it so that suddenly, due to an operator error or not, user-cache does not consume more resources than it has been allocated. That is, we must limit resources. But to what could we tie the quota?
Let's go back to our highly simplified scheme of interaction between components and redraw it with more details — like this:
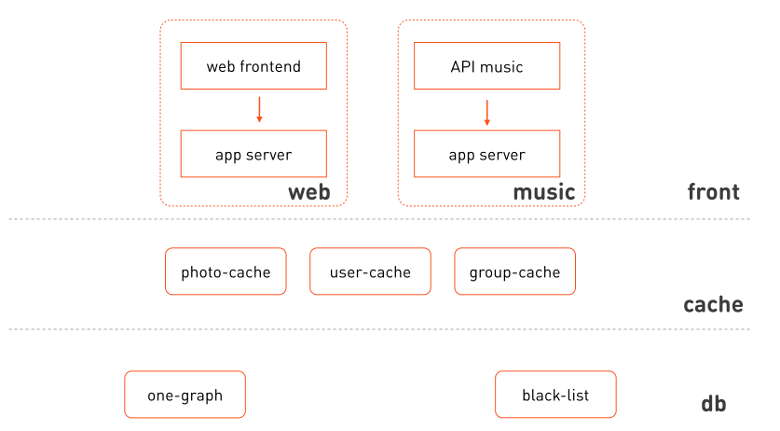
What catches your eye:
- Web frontend and music use isolated clusters of the same application server.
- You can select the logical layers to which these clusters belong: fronts, caches, data storage and management layer.
- The frontend is heterogeneous; these are different functional subsystems.
- Caches can also be scattered on the subsystem, the data of which they cache.
Redraw the image again:
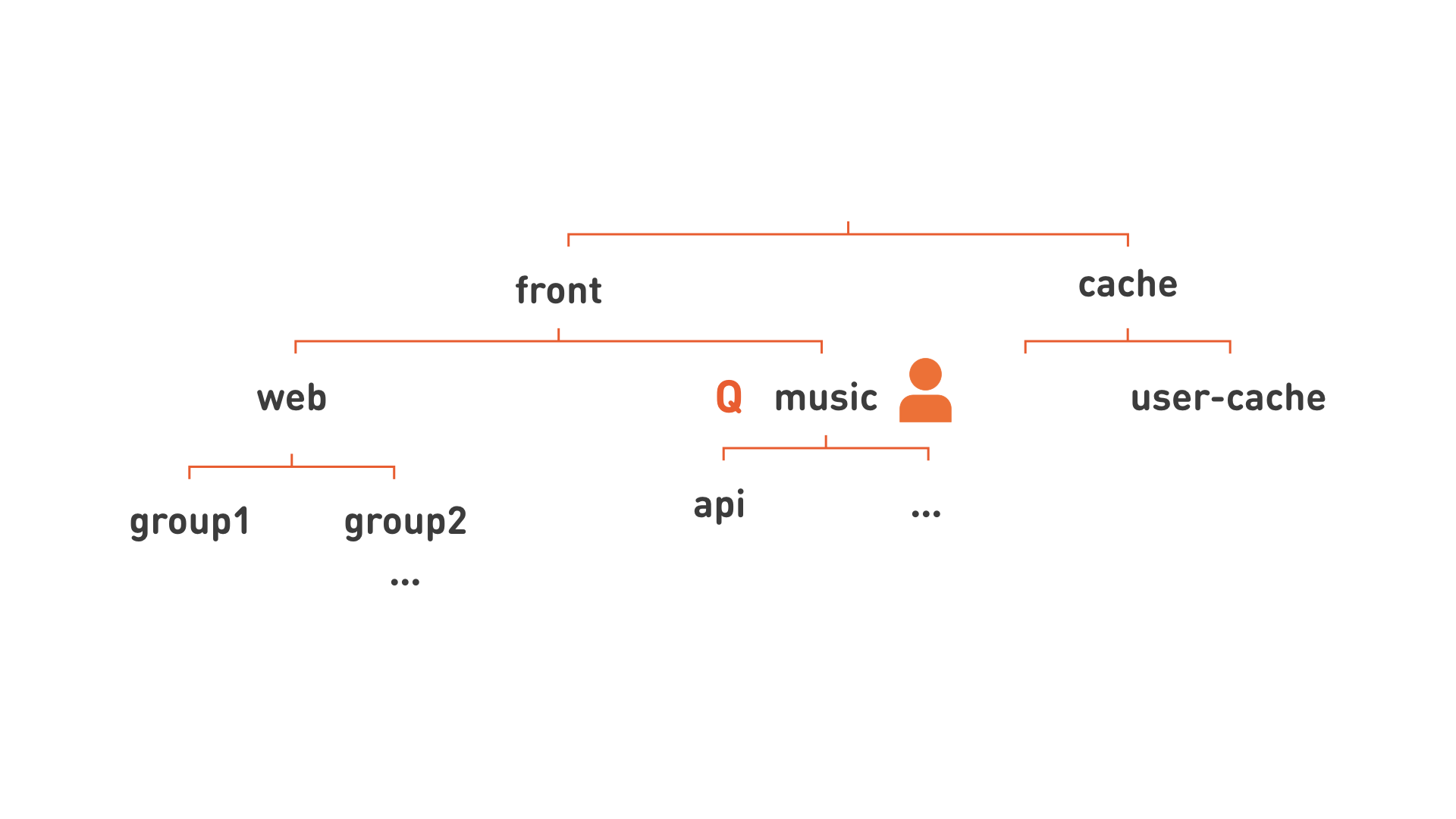
Bah! Yes, we see the hierarchy! This means that it is possible to allocate resources in larger chunks: assign the responsible developer to the node of this hierarchy corresponding to the functional subsystem (like “music” in the picture), and assign a quota to the same hierarchy level. This hierarchy also allows us to more flexibly organize services for ease of management. For example, all the web, since this is a very large grouping of servers, we divide into several smaller groups, shown in the picture as group1, group2.
By removing the extra lines, we can write each node of our image in a more flat form: group1.web.front , api.music.front , user-cache.cache .
So we come to the concept of "hierarchical queue." It has a name like "group1.web.front". It is assigned a quota for resources and user rights. We give the person from DevOps the right to send the service to the queue, and such an employee can run something in the queue, and the person from OpsDev - admin rights, and now he can manage the queue, assign people there, give these people rights, etc. The services running in this queue will run within the quota quota. If the computational quota of the queue is not enough for one-time execution of all services, then they will be executed sequentially, thus forming the actual queue.
Consider the services in more detail. The service has a full name, which always includes the name of the queue. Then the front web service will have the name ok-web.group1.web.front . And the application server service to which it accesses will be called ok-app.group1.web.front . Each service has a manifest, which indicates all the necessary information for placement on specific machines: how many resources this task consumes, what configuration is needed for it, how many replicas should be, properties for handling failures of this service. And after placing the service directly on the machines appear his copies. They are also uniquely named - as the instance number and service name: 1.ok-web.group1.web.front, 2.ok-web.group1.web.front, ...
This is very convenient: looking only at the name of the running container, we can immediately find out a lot.
And now let's take a closer look at what these instances actually do: with tasks.
Task isolation classes
All tasks in the OK (and, probably, everywhere) can be divided into groups:
- Tasks with a short delay - prod . For such tasks and services it is very important to delay the response (latency), how quickly each of the requests will be processed by the system. Examples of tasks: web fronts, caches, application servers, OLTP storage, etc.
- Calculated tasks - batch . Here, the processing speed of each specific request is unimportant. For them it is important how many calculations for a certain (large) period of time this task will do (throughput). These will be any tasks MapReduce, Hadoop, machine learning, statistics.
- Background tasks - idle . Neither latency nor throughput are very important for such tasks. This includes various tests, migrations, recounts, converting data from one format to another. On the one hand, they are similar to calculated ones, on the other hand, it is not very important for us how quickly they will be completed.
Let's see how such tasks consume resources, for example, the central processor.
Tasks with a short delay. For such a task, the CPU consumption pattern will look like this:
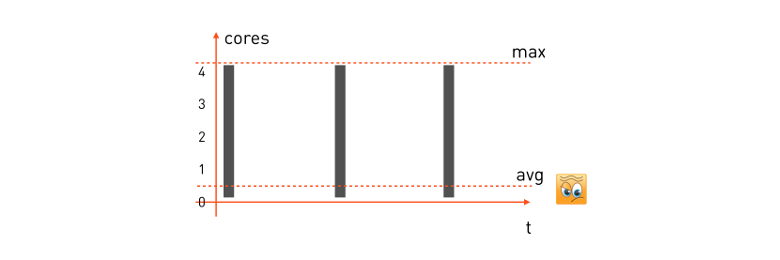
A request from the user arrives for processing, the task begins to use all available CPU cores, executes, returns an answer, waits for the next request and stands. Received the following request - again, they chose everything that was, cheated, waiting for the next one.
To guarantee the minimum delay for such a task, we must take the maximum resources it consumes and reserve the necessary number of cores on the minion (the machine that will perform the task). Then the reservation formula for our task will be:
alloc: cpu = 4 (max) and if we have a minion machine with 16 cores, then exactly four such tasks can be placed on it. We note in particular that the average processor consumption for such tasks is often very low - which is obvious, since the task is waiting for a request for a significant portion of the time and does nothing.
Calculated tasks. They will have a slightly different pattern:

The average CPU consumption for such tasks is quite high. Often we want the design task to be completed in a certain time, so you need to reserve the minimum number of processors that it needs in order for the whole calculation to end in a reasonable time. Its reservation formula will look like this:
alloc: cpu = [1,*) "Please place it on the minion, where there is at least one free core, and then how much is there - it will devour everything."
Here, with efficiency of use, it is much better than on tasks with a short delay. But the gain will be much greater if you combine both types of tasks on the same minion machine and distribute its resources on the go. When a task with a short delay requires a processor - it receives it immediately, and when resources are no longer needed - they are transferred to the calculated task, that is, something like this:

But how to do that?
First, let's take a look at prod and its alloc: cpu = 4. We need to reserve four cores. In the Docker run, this can be done in two ways:
- Using the option
--cpuset=1-4, i.e., to allocate the task four specific kernels on the machine. - Use
--cpuquota=400_000 --cpuperiod=100_000, assign a quota for processor time, i.e., indicate that every 100 ms of real time the task consumes no more than 400 ms of processor time. The same four cores are obtained.
But which of these methods will work?
It looks pretty attractive cpuset. The task has four dedicated cores, which means that processor caches will work as efficiently as possible. This has a downside: we would have to take on the task of distributing the calculations over the unloaded kernels of the machine instead of the OS, which is quite a non-trivial task, especially if we try to place batch tasks on such a machine. Tests have shown that the quota option is better suited here: this is how the operating system has more freedom in choosing the kernel to perform the task at the moment and the processor time is distributed more efficiently.
Let's figure out how to docker in the docker for the minimum number of cores. The quota for batch tasks is already inapplicable, because it is not necessary to limit the maximum, you just need to guarantee a minimum. And here the docker run --cpushares option docker run --cpushares .
We agreed that if batch requires a warranty of at least one core, then we specify --cpushares=1024 , and if at least two cores, then we specify --cpushares=2048 . Cpu shares do not interfere in the distribution of CPU time as long as it is enough. Thus, if prod does not currently use all of its four cores - nothing restricts batch tasks, and they can use additional processor time. But in a situation of processor shortage, if prod consumed all its four bark and rested on the quota - the remaining processor time will be divided proportionally to cpushares, i.e. in a situation of three free cores one will receive a task from 1024 cpushares, and the other two - a problem from 2048 cpushares
But using quota and shares is not enough. We need to make the task with a short delay receive priority over the batch task when allocating processor time. Without such prioritization, the batch task will take all the CPU time at the moment when it is needed by prod. There are no container prioritization options in the Docker run, but the CPU scheduler policies on Linux come to the rescue. You can read about them in detail here , and in the framework of this article we will take a brief look at them:
- SCHED_OTHER
By default, all normal user processes on a Linux machine are obtained. - SCHED_BATCH
Designed for demanding processes. When a task is placed in the processor, a so-called activation fee is introduced: such a task is less likely to receive processor resources if the task with SCHED_OTHER is currently using it - SCHED_IDLE
The background process has a very low priority, even lower than the nice –19. We use our open source one-nio library to set the necessary policy when launching a container by calling
one.nio.os.Proc.sched_setscheduler( pid, Proc.SCHED_IDLE ) But even if you do not program in Java, you can do the same with the chrt command:
chrt -i 0 $pid Let us reduce all our isolation levels in one table for clarity:
| Insulation class | Example alloc | Docker run options | sched_setscheduler chrt * |
|---|---|---|---|
| Prod | cpu = 4 | --cpuquota=400000 --cpuperiod=100000 | SCHED_OTHER |
| Batch | Cpu = [1, *) | --cpushares=1024 | SCHED_BATCH |
| Idle | Cpu = [2, *) | --cpushares=2048 | SCHED_IDLE |
* If you do chrt from inside the container, you may need the capability sys_nice, because by default Docker this capability takes away when the container is started.
But tasks consume not only the processor, but also traffic, which affects the delay of the network task even more than the incorrect allocation of processor resources. Therefore, we naturally want to get exactly the same picture for traffic. That is, when the prod-task sends some packets to the network, we quote the maximum speed (formula alloc: lan = [*, 500mbps) ), with which prod can do it. And for batch, we guarantee only the minimum bandwidth, but do not limit the maximum (formula alloc: lan = [10Mbps, *) ) At the same time, prod traffic should receive priority over batch tasks.
Here, the Docker has no primitives that we could use. But Linux Traffic Control comes to the rescue. We were able to achieve the desired result with the discipline of the Hierarchical Fair Service Curve . With its help, we distinguish two classes of traffic: high-priority prod and low-priority batch / idle. As a result, the configuration for outgoing traffic is obtained like this:

here 1: 0 is the "root qdisc" of the hsfc discipline; 1: 1 - a child class hsfc with a total bandwidth limit of 8 Gbit / s, under which the child classes of all containers are placed; 1: 2 is a child class hsfc common to all batch and idle tasks with a “dynamic” limit, which is described below. The remaining child classes of hsfc are dedicated classes for the currently working prod containers with limits corresponding to their manifests — 450 and 400 Mbit / s. Each hsfc class is assigned a qdisc fq or fq_codel queue, depending on the linux kernel version, in order to avoid packet loss during traffic spikes.
Typically, tc disciplines serve to prioritize only outgoing traffic. But we want to prioritize the incoming traffic too - after all, some batch task can easily select the entire incoming channel, receiving, for example, a large packet of input data for map & reduce. To do this, we use the ifb module, which creates a virtual ifbX interface for each network interface and redirects incoming traffic from the interface to the outgoing to ifbX. Further, for ifbX, all the same disciplines for controlling outgoing traffic work, for which the hsfc configuration will be very similar:
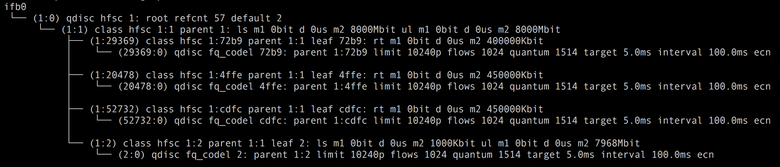
In the course of the experiments, we found out that the best results for hsfc are shown when the 1: 2 class of non-priority batch / idle traffic is limited to minion-machines not more than to some free band. Otherwise, non-priority traffic is too much affect on the delay of prod-tasks. The miniond determines the current free bandwidth every second, measuring the average traffic consumption of all the minion's prod tasks. and subtracting it from the bandwidth of the network interface with a small margin, i.e.
Bands are defined for incoming and outgoing traffic independently. And according to the new values, miniond reconfigures the non-priority class 1: 2 limit.
Thus, we implemented all three isolation classes: prod, batch and idle. These classes greatly influence the performance characteristics of tasks. Therefore, we decided to place this feature at the top of the hierarchy, so that when looking at the name of the hierarchical queue it is immediately clear what we are dealing with:
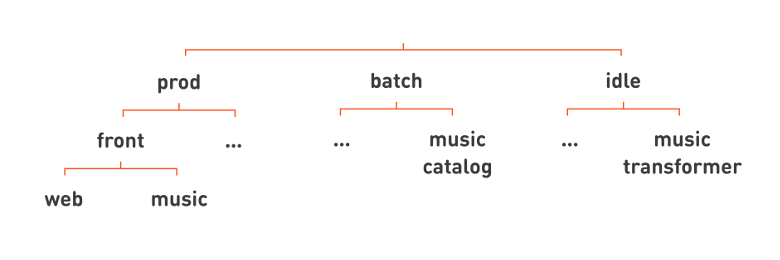
All of our familiar web and music fronts are then placed in the hierarchy under prod. For example, under the batch, let's place the music catalog service, which periodically makes a catalog of tracks from the set of mp3 files uploaded to Odnoklassniki. An example of a service under idle is music transformer , which normalizes the volume of music.
Removing unnecessary lines again, we can write the names of our services more flatly by adding the isolation class to the end of the full name of the service: web.front.prod , catalog.music.batch , transformer.music.idle .
And now, looking at the name of the service, we understand not only what function it performs, but also its isolation class, which means its criticality, etc.
Everything is great, but there is one bitter truth. It is impossible to completely isolate tasks running on the same machine.
What we have been able to achieve: if batch intensively consumes only processor resources, then the built-in Linux CPU scheduler does its job very well, and there is practically no influence on the prod-task. But if this batch task begins to work actively with memory, then the mutual influence is already manifested. This happens because the prod-tasks "flush out" the processor memory caches - as a result, the errors in the cache increase, and the processor processes the prod-task more slowly. Such a batch task can increase the latency of our typical prod container by 10%.
Isolating traffic is even more difficult due to the fact that modern network cards have an internal packet queue. If the packet from the batch task gets there first, it means that it will be the first to be transferred via cable, and there is nothing you can do.
In addition, we have so far managed to solve only the problem of prioritizing TCP traffic: for UDP, the approach with hsfc does not work. And even in the case of TCP traffic, if a batch task generates a lot of traffic, this also gives about a 10% increase in the delay of the prod task.
fault tolerance
One of the goals in the development of one-cloud was to improve the resiliency of Odnoklassniki. Therefore, I would like to discuss in more detail possible scenarios of failures and accidents. Let's start with a simple script — container failure.
The container itself can fail in several ways. This could be some kind of experiment, bug, or error in the manifest, due to which the prod-task begins to consume more resources than specified in the manifest. We had a case: the developer implemented one complex algorithm, reworked it many times, overworked himself and got confused so that in the end the task was very nontrivially looping. And since the prod task is of higher priority than all the others on the same minions, it began to consume all available processor resources. In this situation, the isolation has saved, or rather the quota for processor time. If a quota is allocated to a task, the task will not consume more. Therefore, batch- and other prod-tasks that worked on the same machine did not notice anything.
The second possible trouble is the fall of the container. And here restart policies save us, everyone knows them, Docker does it perfectly well. Almost all prod-tasks have a restart policy always. Sometimes we use on_failure for batch tasks or for debugging prod containers.
And what can be done if the whole minion is not available?
Obviously, run the container on another machine. The most interesting thing here is what happens to the IP address (s) assigned to the container.
We can assign containers the same IP addresses as the minion machines on which these containers run. Then when you start the container on another machine, its IP address changes, and all customers need to understand that the container has moved, now you need to go to another address, which requires a separate Service Discovery service.
Service Discovery is convenient. There are many solutions on the market with varying degrees of fault tolerance for organizing a registry of services. Often in such solutions the logic of the load balancer is implemented, the storage of the additional configuration in the form of a KV stack, etc.
However, we would like to do without the need to implement a separate registry, because it would mean entering a critical system that is used by all services in production. So, this is a potential point of failure, and you need to choose or develop a very fault-tolerant solution, which is obviously very difficult, time consuming and expensive.
And another big drawback: for our old infrastructure to work with a new one, we would have to rewrite absolutely all the tasks for using some kind of Service Discovery system. There is a lot of work, and in some places it is impossible when it comes to low-level devices operating at the kernel level of the OS or directly with hardware. Implementing this functionality with the help of well-established decision patterns, such as a side-car, would in some places mean additional workload, and in some places - complication of operation and additional failure scenarios. We did not want to complicate things, so we decided to make the use of Service Discovery optional.
In one-cloud IP follows the container, i.e., each instance of the task has its own IP address. «»: . — IP-, .
: production. IP- . , .
, IP- . , ( 1.ok-web.group1.web.front.prod, 2.ok-web.group1.web.front.prod, … ), , FQDN, DNS. , IP- DNS-. DNS IP- — , (, , — ). , , — , . , DNS, Service Discovery, , . , , , DNS, IP-.
IP — , , :
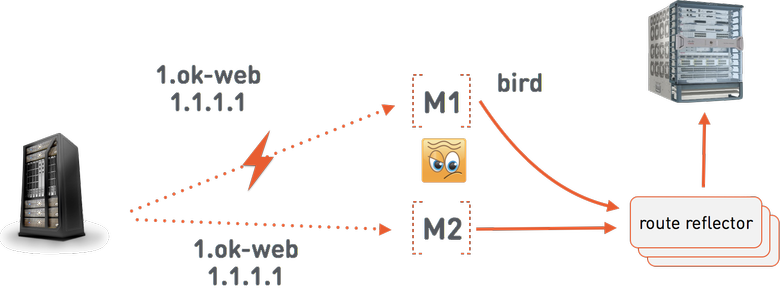
, one-cloud M1 1.ok-web.group1.web.front.prod 1.1.1.1. BIRD , route reflector . BGP- , 1.1.1.1 M1. M1 Linux. route reflector , one-cloud — one-cloud . , -, .
, one-cloud 1 . one-cloud , , 1 . 2 web.group1.web.front.prod 1.1.1.1. 1.1.1.1: 1 2. , Multi Exit Discriminator, BGP-. , . MED. one-cloud MED IP- . MED = 1 000 000. MED, 2 1.1.1.1 c MED = 999 999. , M1, , , .
- . — .
, , -.
-? , . , , , - 100 % .
. - , - , , .
?
, , . - , , . . , .
, .
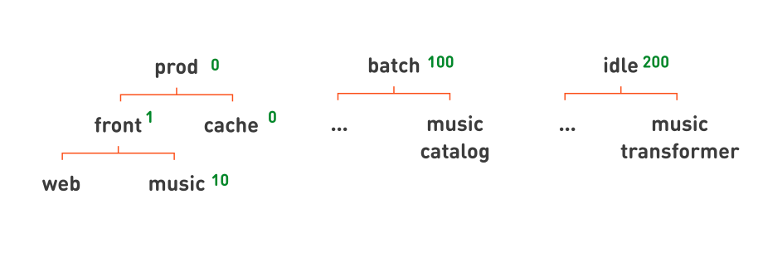
, , , . . prod. — , . - , .
prod , 0; batch — , 100; idle — , 200. . . , prod , cache = 0 front = 1. , , , , music , — 10.
— . , , -, , . , , .
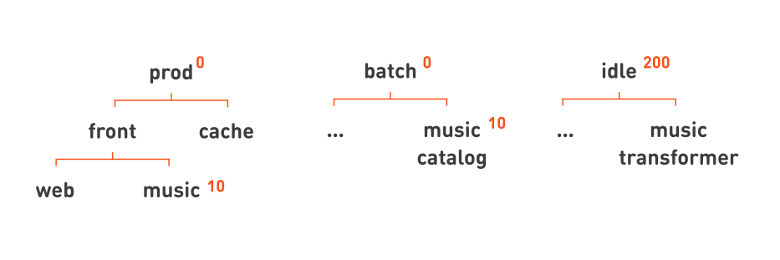
, batch-, . . , . . , . , , , . . .
, prod- batch- idle-, , idle , 200. , , , . , , , -, : 10.
-? . , - . , - , - . : , - . - . , - — . .
, # .
— . one-cloud -. - — -. : , -. .
-, , one-cloud.
, .
? - , , , . , - — , .

Results
one-cloud:
- , , , .
- prod- batch- , . cpuset CPU quotas, shares, CPU Linux QoS.
- , , , 20 %.
- .
.
- . prod- , batch idle , -.
- , :
- ;
- «» .
- , , one-cloud.
- Service Discovery; , , — , «» IP-, , , , .
, , , , . — , .
, , — !
')
Source: https://habr.com/ru/post/346868/
All Articles