Parallel STL. Fast way to speed up C ++ STL code
Over the past couple of decades, while computing systems have evolved from single-core scalar to multi-core vector architectures, the popularity of managed languages has grown significantly, and new programming languages have emerged. But the good old C ++, which allows writing high-performance code, remains more than popular. However, until recently, the language standard did not provide any tools for expressing concurrency. The new version of the standard (C ++ 17 [1]) provides a set of parallel algorithms Parallel STL, which makes it possible to convert existing sequential C ++ code into parallel, which, in turn, allows using hardware capabilities such as multithreading and vectoring. This article will introduce you to the basics of Parallel STL and its implementation in Intel Parallel Studio XE 2018.

So, the fate of supporting concurrency in C ++ was very difficult. The picture below
You can get acquainted with the available multi-level tools in different versions of C ++, including the whole "zoo" of various "external" tools for developing parallel software created by software or hardware manufacturers.
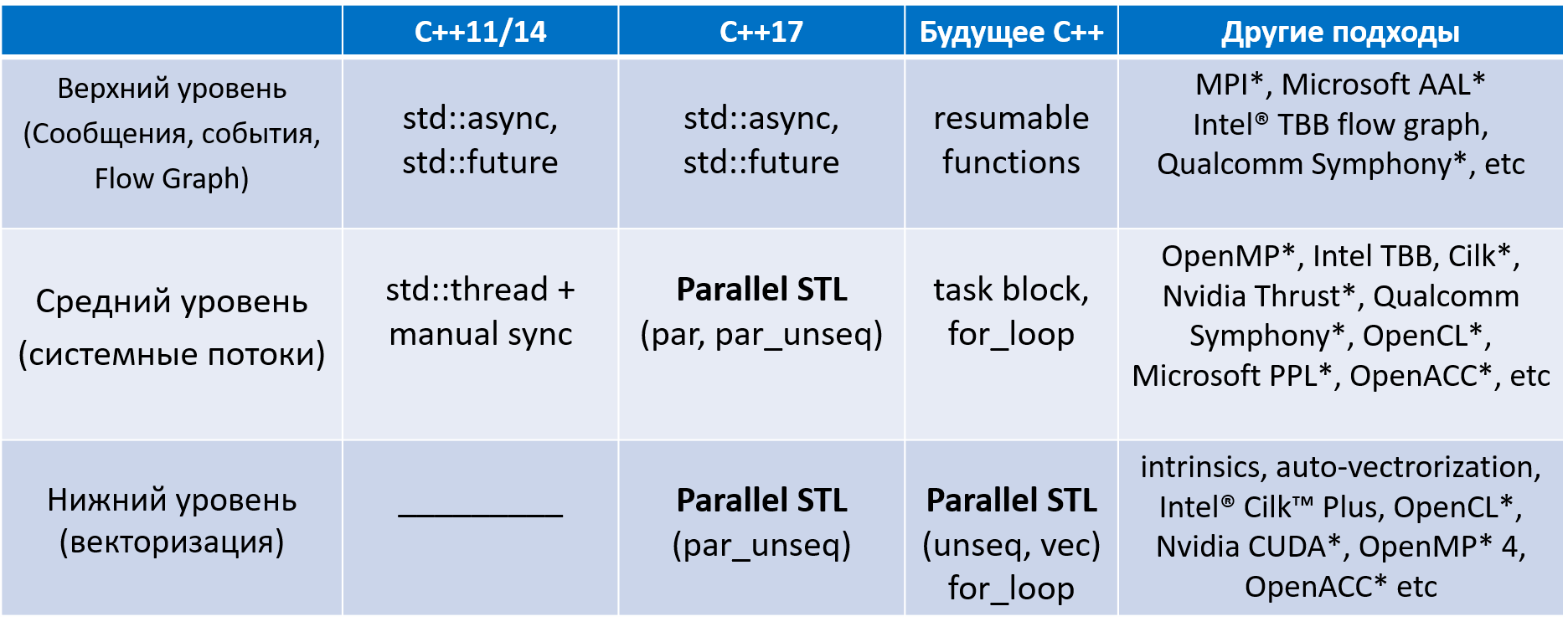
Figure 1. The evolution of concurrency in C ++
Parallel STL is an extension of the Standard Template Library C ++ (STL - Standard Template Library), which introduces the key concept of "execution policy".
The execution policy is the C ++ class used as a unique type for overloading STL algorithms. For ease of use, the standard also defines one object of each such class, which can be passed as an argument when calling algorithms. They can be used with well-known algorithms (transform, for_each, copy_if), and with new algorithms that appeared in C ++ 17 (reduce, transform_reduce, inclusive_scan, etc.). It is necessary to clarify that not all algorithms in C ++ 17 support policies.
')
Further, parallel execution of the algorithm is understood to be execution on several CPU cores; By vectorization we mean execution using the processor's vector registers. Support for parallel policies has been developed for several years as the "Technical Specification for C ++ Extensions for Parallelism *" (Parallelism TS). Now this specification is included in the standard language C ++ 17. Support for vector policies can enter the second version of the Parallelism TS specification (n4698 [2], p0076 [3]). In general, these documents describe 5 different execution policies (Fig. 2):

Figure 2. Execution Policies for Algorithms
The figure above demonstrates the relationship between these policies. The higher the policy on the scheme, the greater the degree of freedom (in terms of parallelism) it allows.
The following are examples of using STL and Parallel STL algorithms according to the C ++ 17 standard:
Where is the record
equivalent to the following cycle:
and
can be presented in the form of the following cycle (our implementation uses #pragma omp simd at the lower level, other implementations of Parallel STL may use other methods of implementing unseq policy)
and
can be expressed as follows:
Intel Parallel STL implementation is part of Intel® Parallel Studio XE 2018 . We offer a portable implementation of algorithms that can be executed both in parallel and vector. The implementation is optimized and tested for Intel® processors. We use the Intel® Threading Building Blocks (Intel TBB) for the par and par_unseq policies, unseq and par_unseq for vectorization by means of OpenMP *. The vec policy is not presented in Intel Parallel Studio XE 2018.
After installing Parallel STL, you need to set the environment variables as described in this document . There is also an up-to-date list of algorithms that have parallel and / or vector implementations. For the remaining algorithms, execution policies are also applicable, but a sequential version will be invoked.
For best results with our Parallel STL implementation, we recommend using the Intel® C ++ Compiler 2018 compiler. But you can use other compilers that support C ++ 11. To get a positive effect from vectorization, the compiler must also support OpenMP 4.0 ( #pragma omp simd ). To use the par, par_unseq policies , the Intel TBB library is required.
To add Parallel STL to your application, follow these steps:
Intel Parallel Studio XE 2018 contains examples of using Parallel STL, which you can build and run. You can download them here .
In theory, Parallel STL was developed as an intuitive way for C ++ developers to write programs for parallel computing systems with shared memory. Consider an approach in which theory correlates with best practices for parallelizing nested loops, for example, an approach such as “Vectorize the internal level, parallelize the external” (“Vectorize Innermost, Parallelize Outermost” [VIPO]) [4]. As an example, consider an image gamma correction, a non-linear operation used to change the brightness of each image pixel. Note that we need to disable auto-vectorisation for sequential execution of algorithms in order to show the difference between sequential and vector-based execution. (Otherwise, this difference can only be seen with compilers that do not support automatic vectorization, but support OpenMP vectorization)
Consider an example of sequential execution:
The ApplyGamma function takes an image by its reference, represented as a set of strings, and calls std :: for_each to iterate over the strings. The lambda function, called for each row, cycles through pixels using std :: transform to change the brightness of each pixel.
As described earlier, Parallel STL provides the parallel and vector versions of the for_each and transform algorithms. In other words, the policy passed as the first argument to the algorithm leads to the execution of a parallel and / or vector version of this algorithm.
Returning to the example above, you can see that all calculations are performed in the lambda function, which is called from the transform algorithm. So let's try to “kill two birds with one stone” and rewrite the example using the par_unseq policy:
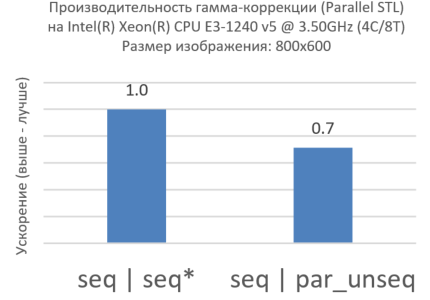
Figure 3. Par_unseq for the inner loop
Surprisingly, the miracle did not happen (Fig. 3). Performance with par_unseq is worse than sequential execution. This is a great example of how NOT to use Parallel STL. If you profile the code using, for example, Intel® VTune Amplifier XE , you can see many cache misses caused by threads running on different cores accessing the same cache lines (this effect is known as “ false sharing of resources ”[ false sharing ]).
As noted earlier, Parallel STL helps us express the parallelism of the mean (using system flows) and lower (using vectorization) levels of parallelism. In general, in order to get the greatest acceleration, estimate the execution time of the algorithm and compare it with the overhead of parallelism and vectorization. We recommend that the sequential execution time be at least 2 times longer than the overhead at each level of parallelism. Besides:
The recommendations suggest that the proper use of parallel and vector policies at different levels can provide better performance, namely:
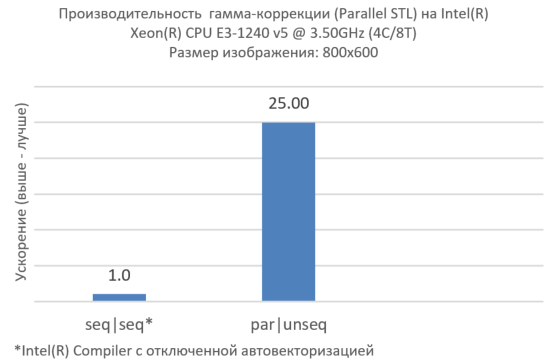
Figure 4. Vectorization at the internal level, parallelism at the external
Now we have obtained efficient parallel processing of a single image (Fig. 4), but real applications, as a rule, process many images (Fig. 5). Parallelism at a higher level can work poorly with standard algorithms. In this case, we suggest using Parallel STL in conjunction with Intel TBB.
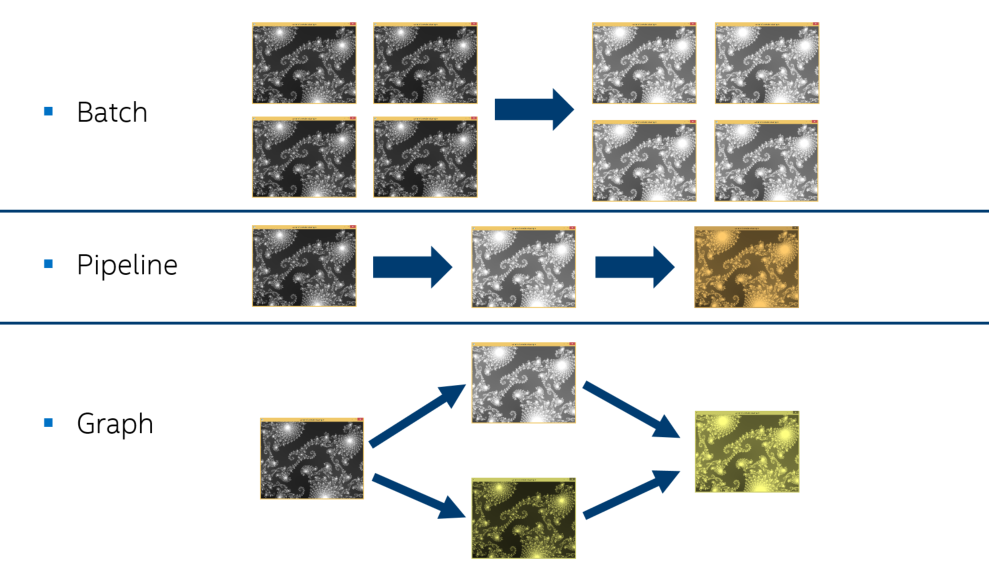
Figure 5. Methods of processing multiple images
This allows you to apply tasks or parallel constructions (for example, a computational graph [flow graph], a pipeline [pipeline]) Intel TBB at the highest level and Parallel STL algorithms at lower levels, without worrying about creating an excess of logical flows in the system . Example:
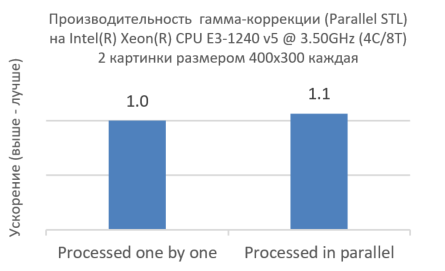
Figure 6. Intel TBB and Parallel STL sharing
As shown in Figure 6, simultaneous processing of two images using Intel TBB does not reduce performance, but on the contrary, even increases it slightly. This shows that the expression of parallelism at the level below and at the lowest level makes maximum use of the CPU cores.
Now consider the situation when we have more images for processing and more CPU cores.
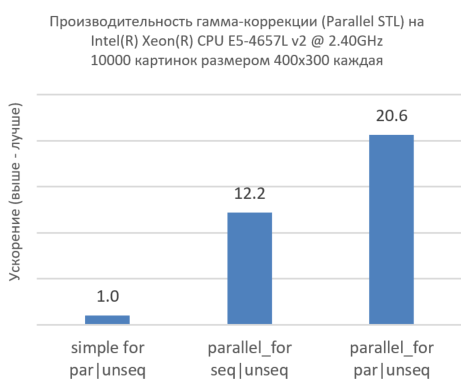
Figure 7. Intel TBB and Parallel STL sharing across more images and more CPU cores.
The figure above shows that simultaneous processing of multiple images using Intel TBB ( parallel_for ) dramatically increases performance. In fact, take a look at the first column, where we sequentially run through all the images, with each image being processed in parallel at a lower level. Adding only parallelism at the very top level ( parallel_for ) without parallelism at the level below ( par ) significantly increases performance, but this is not enough to make the most of the resources of the CPU cores. The third column shows that concurrency at all levels dramatically increases performance. This shows the effectiveness of sharing Intel TBB and our implementation of Parallel STL.
Parallel STL is a significant step in the evolution of C ++ parallelism, which makes it easily applicable to the algorithms of the standard STL library, both when upgrading code and creating new applications. This part of the standard adds to the C ++ language the possibilities of vectorization and concurrency without the use of non-standard or custom-written extensions, and execution policies provide control over the use of such features, abstracting from hardware. Parallel STL allows developers to focus on expressing parallelism in their applications, without worrying about low-level flow control and vector registers. In addition to efficient, high-performance implementations of high-level algorithms, our Parallel STL implementation demonstrates efficient sharing with Intel TBB parallel patterns. However, Parallel STL is not a panacea. Parallel and vector policies should be used deliberately, depending on the dimension of the problem, the type and amount of data, as well as the function code, functors used in the algorithms. To achieve high performance, we can recommend some methods described in [4].
You can find current versions of Parallel STL and Intel TBB, as well as additional information on the following sites:
We need your feedback. And you can leave them here:
[1] ISO / IEC 14882: 2017, Programming Languages. C ++
[2] N4698, Working Draft, Technical Specification for C ++ Extensions for Parallelism Version 2 , Programming Language C ++ (WG21)
[3] P0076r4, Vector and Wavefront Policies , Programming Language C ++ (WG21)
[4] Robert Geva, Code Modernization Best Practices: Multi-level Parallelism for Intel® Xeon® and Intel® Xeon Phi ™ Processors , IDF15 - Webcast
* other names and brands may be declared the intellectual property of others.
Introduction to Parallel STL
So, the fate of supporting concurrency in C ++ was very difficult. The picture below
You can get acquainted with the available multi-level tools in different versions of C ++, including the whole "zoo" of various "external" tools for developing parallel software created by software or hardware manufacturers.
Figure 1. The evolution of concurrency in C ++
Parallel STL is an extension of the Standard Template Library C ++ (STL - Standard Template Library), which introduces the key concept of "execution policy".
The execution policy is the C ++ class used as a unique type for overloading STL algorithms. For ease of use, the standard also defines one object of each such class, which can be passed as an argument when calling algorithms. They can be used with well-known algorithms (transform, for_each, copy_if), and with new algorithms that appeared in C ++ 17 (reduce, transform_reduce, inclusive_scan, etc.). It is necessary to clarify that not all algorithms in C ++ 17 support policies.
')
Further, parallel execution of the algorithm is understood to be execution on several CPU cores; By vectorization we mean execution using the processor's vector registers. Support for parallel policies has been developed for several years as the "Technical Specification for C ++ Extensions for Parallelism *" (Parallelism TS). Now this specification is included in the standard language C ++ 17. Support for vector policies can enter the second version of the Parallelism TS specification (n4698 [2], p0076 [3]). In general, these documents describe 5 different execution policies (Fig. 2):
- sequenced_policy (seq) says that the algorithm can be executed sequentially [1].
- parallel_policy (par) indicates that the algorithm can run in parallel [1]. User functions called while the algorithm is running should not generate a “data race”.
- parallel_unsequenced_policy (par_unseq) indicates that the algorithm can be executed in parallel and vector [1].
- unsequenced_policy (unseq) is a class that is part of the Parallelism TS v2 draft [2] and shows that the algorithm can be vectorially executed. This policy requires that all user functions, functors, passed to the algorithm as parameters, do not interfere with vectorization (do not contain data dependencies, do not cause “data races,” etc.).
- vector_policy (vec) (also from [2]) says that the algorithm can be executed vectorially, but unlike unseq , the vec policy guarantees data processing in the order in which they are processed during sequential execution (preserves associativity).
Figure 2. Execution Policies for Algorithms
The figure above demonstrates the relationship between these policies. The higher the policy on the scheme, the greater the degree of freedom (in terms of parallelism) it allows.
The following are examples of using STL and Parallel STL algorithms according to the C ++ 17 standard:
#include <execution> #include <algorithm> void increment_seq( float *in, float *out, int N ) { using namespace std; transform( in, in + N, out, []( float f ) { return f+1; }); } void increment_unseq( float *in, float *out, int N ) { using namespace std; using namespace std::execution; transform( unseq, in, in + N, out, []( float f ) { return f+1; }); } void increment_par( float *in, float *out, int N ) { using namespace std; using namespace std::execution; transform( par, in, in + N, out, []( float f ) { return f+1; }); } Where is the record
std::transform( in, in + N, out, foo ); equivalent to the following cycle:
for (x = in; x < in+N; ++x) *(out+(x-in)) = foo(x); and
std::transform( unseq, in, in + N, out, foo ); can be presented in the form of the following cycle (our implementation uses #pragma omp simd at the lower level, other implementations of Parallel STL may use other methods of implementing unseq policy)
#pragma omp simd for (x = in; x < in+N; ++x) *(out+(x-in)) = foo(x); and
std::transform( par, in, in + N, out); can be expressed as follows:
tbb::parallel_for (in, in+N, [=] (x) { *(out+(x-in)) = foo(x); }); Overview of Parallel STL implementation in Intel® Parallel Studio XE 2018
Intel Parallel STL implementation is part of Intel® Parallel Studio XE 2018 . We offer a portable implementation of algorithms that can be executed both in parallel and vector. The implementation is optimized and tested for Intel® processors. We use the Intel® Threading Building Blocks (Intel TBB) for the par and par_unseq policies, unseq and par_unseq for vectorization by means of OpenMP *. The vec policy is not presented in Intel Parallel Studio XE 2018.
After installing Parallel STL, you need to set the environment variables as described in this document . There is also an up-to-date list of algorithms that have parallel and / or vector implementations. For the remaining algorithms, execution policies are also applicable, but a sequential version will be invoked.
For best results with our Parallel STL implementation, we recommend using the Intel® C ++ Compiler 2018 compiler. But you can use other compilers that support C ++ 11. To get a positive effect from vectorization, the compiler must also support OpenMP 4.0 ( #pragma omp simd ). To use the par, par_unseq policies , the Intel TBB library is required.
To add Parallel STL to your application, follow these steps:
- Add #include "pstl / execution" . Then one or more of the following lines, depending on which algorithms you intend to use:
#include "pstl / algorithm"
#include "pstl / numeric"
#include "pstl / memory"
Note that you should not write #include <execution> , but #include “pstl / execution” . This is done specifically to avoid conflicts with the header files of the standard C ++ library. - At the place of use of algorithms and policies, specify the namespace std and pstl :: execution, respectively.
- Compile code with support for C ++ 11 or higher. Use the appropriate compilation option to enable OpenMP vectorization (for example, for Intel C ++ Compiler -qopenmp-simd ( / Qopenmp-simd for Windows *).
- For best performance, specify the target platform. For Intel® C ++ Compiler, use the appropriate options from the list: -xHOST, -xCORE-AVX2, -xMIC-AVX512 for Linux * or / QxHOST, / QxCORE AVX2, / QxMIC-AVX512 for Windows.
- Link with Intel TBB. On Windows, this will happen automatically; on other platforms add
-ltbb to linker options.
Intel Parallel Studio XE 2018 contains examples of using Parallel STL, which you can build and run. You can download them here .
Effective vectorization, parallelism and compatibility using our implementation of Parallel STL
In theory, Parallel STL was developed as an intuitive way for C ++ developers to write programs for parallel computing systems with shared memory. Consider an approach in which theory correlates with best practices for parallelizing nested loops, for example, an approach such as “Vectorize the internal level, parallelize the external” (“Vectorize Innermost, Parallelize Outermost” [VIPO]) [4]. As an example, consider an image gamma correction, a non-linear operation used to change the brightness of each image pixel. Note that we need to disable auto-vectorisation for sequential execution of algorithms in order to show the difference between sequential and vector-based execution. (Otherwise, this difference can only be seen with compilers that do not support automatic vectorization, but support OpenMP vectorization)
Consider an example of sequential execution:
#include <algorithm> void ApplyGamma(Image& rows, float g) { using namespace std; for_each(rows.begin(), rows.end(), [g](Row &r) { transform(r.cbegin(), r.cend(), r.begin(), [g](float v) { return pow(v, g); }); }); } The ApplyGamma function takes an image by its reference, represented as a set of strings, and calls std :: for_each to iterate over the strings. The lambda function, called for each row, cycles through pixels using std :: transform to change the brightness of each pixel.
As described earlier, Parallel STL provides the parallel and vector versions of the for_each and transform algorithms. In other words, the policy passed as the first argument to the algorithm leads to the execution of a parallel and / or vector version of this algorithm.
Returning to the example above, you can see that all calculations are performed in the lambda function, which is called from the transform algorithm. So let's try to “kill two birds with one stone” and rewrite the example using the par_unseq policy:
void ApplyGamma(Image& rows, float g) { using namespace pstl::execution; std::for_each(rows.begin(),rows.end(), [g](Row &r) { // Inner parallelization and vectorization std::transform(par_unseq, r.cbegin(), r.cend(), r.begin(), [g](float v) { return pow(v, g); }); }); } Figure 3. Par_unseq for the inner loop
Surprisingly, the miracle did not happen (Fig. 3). Performance with par_unseq is worse than sequential execution. This is a great example of how NOT to use Parallel STL. If you profile the code using, for example, Intel® VTune Amplifier XE , you can see many cache misses caused by threads running on different cores accessing the same cache lines (this effect is known as “ false sharing of resources ”[ false sharing ]).
As noted earlier, Parallel STL helps us express the parallelism of the mean (using system flows) and lower (using vectorization) levels of parallelism. In general, in order to get the greatest acceleration, estimate the execution time of the algorithm and compare it with the overhead of parallelism and vectorization. We recommend that the sequential execution time be at least 2 times longer than the overhead at each level of parallelism. Besides:
- Parallelize the topmost level; Look for the maximum amount of work to do in parallel mode.
- If this gives you sufficient parallelization efficiency, the goal is achieved. If not, parallelize the level below.
- Make sure the algorithm effectively uses the cache.
- Try to vectorize the lowest level. Try to reduce the number of conditional transitions in the vectorized function and observe the uniformity of memory access.
- For more recommendations, see [4].
The recommendations suggest that the proper use of parallel and vector policies at different levels can provide better performance, namely:
void ApplyGamma(Image& rows, float g) { using namespace pstl::execution; // Outer parallelization std::for_each(par, rows.begin(), rows.end(), [g](Row &r) { // Inner vectorization std::transform(unseq, r.cbegin(), r.cend(), r.begin(), [g](float v) { return pow(v, g); }); }); } Figure 4. Vectorization at the internal level, parallelism at the external
Now we have obtained efficient parallel processing of a single image (Fig. 4), but real applications, as a rule, process many images (Fig. 5). Parallelism at a higher level can work poorly with standard algorithms. In this case, we suggest using Parallel STL in conjunction with Intel TBB.
Figure 5. Methods of processing multiple images
This allows you to apply tasks or parallel constructions (for example, a computational graph [flow graph], a pipeline [pipeline]) Intel TBB at the highest level and Parallel STL algorithms at lower levels, without worrying about creating an excess of logical flows in the system . Example:
void Function() { Image img1, img2; // Prepare img1 and img2 tbb::parallel_invoke( [&img1] { img1.ApplyGamma(gamma1); }, [&img2] { img2.ApplyGamma(gamma2); } ); } Figure 6. Intel TBB and Parallel STL sharing
As shown in Figure 6, simultaneous processing of two images using Intel TBB does not reduce performance, but on the contrary, even increases it slightly. This shows that the expression of parallelism at the level below and at the lowest level makes maximum use of the CPU cores.
Now consider the situation when we have more images for processing and more CPU cores.
tbb::parallel_for(images.begin(), images.end(), [](image* img) {applyGamma(img->rows(), 1.1);} ); Figure 7. Intel TBB and Parallel STL sharing across more images and more CPU cores.
The figure above shows that simultaneous processing of multiple images using Intel TBB ( parallel_for ) dramatically increases performance. In fact, take a look at the first column, where we sequentially run through all the images, with each image being processed in parallel at a lower level. Adding only parallelism at the very top level ( parallel_for ) without parallelism at the level below ( par ) significantly increases performance, but this is not enough to make the most of the resources of the CPU cores. The third column shows that concurrency at all levels dramatically increases performance. This shows the effectiveness of sharing Intel TBB and our implementation of Parallel STL.
Conclusion
Parallel STL is a significant step in the evolution of C ++ parallelism, which makes it easily applicable to the algorithms of the standard STL library, both when upgrading code and creating new applications. This part of the standard adds to the C ++ language the possibilities of vectorization and concurrency without the use of non-standard or custom-written extensions, and execution policies provide control over the use of such features, abstracting from hardware. Parallel STL allows developers to focus on expressing parallelism in their applications, without worrying about low-level flow control and vector registers. In addition to efficient, high-performance implementations of high-level algorithms, our Parallel STL implementation demonstrates efficient sharing with Intel TBB parallel patterns. However, Parallel STL is not a panacea. Parallel and vector policies should be used deliberately, depending on the dimension of the problem, the type and amount of data, as well as the function code, functors used in the algorithms. To achieve high performance, we can recommend some methods described in [4].
You can find current versions of Parallel STL and Intel TBB, as well as additional information on the following sites:
- Open implementation of Parallel STL on github
- Intel TBB Official Website
- Intel TBB on github
- Intel TBB Documentation
We need your feedback. And you can leave them here:
- Project page on github
- Intel TBB Forum
References:
[1] ISO / IEC 14882: 2017, Programming Languages. C ++
[2] N4698, Working Draft, Technical Specification for C ++ Extensions for Parallelism Version 2 , Programming Language C ++ (WG21)
[3] P0076r4, Vector and Wavefront Policies , Programming Language C ++ (WG21)
[4] Robert Geva, Code Modernization Best Practices: Multi-level Parallelism for Intel® Xeon® and Intel® Xeon Phi ™ Processors , IDF15 - Webcast
* other names and brands may be declared the intellectual property of others.
Source: https://habr.com/ru/post/346822/
All Articles