Parsim memes in python: how to bypass the server lock
New Year's holidays are a great excuse to grow in a comfortable home environment and remember dear to me from 2k17 hearts that disappear forever, like the conscience of Electronic Arts.
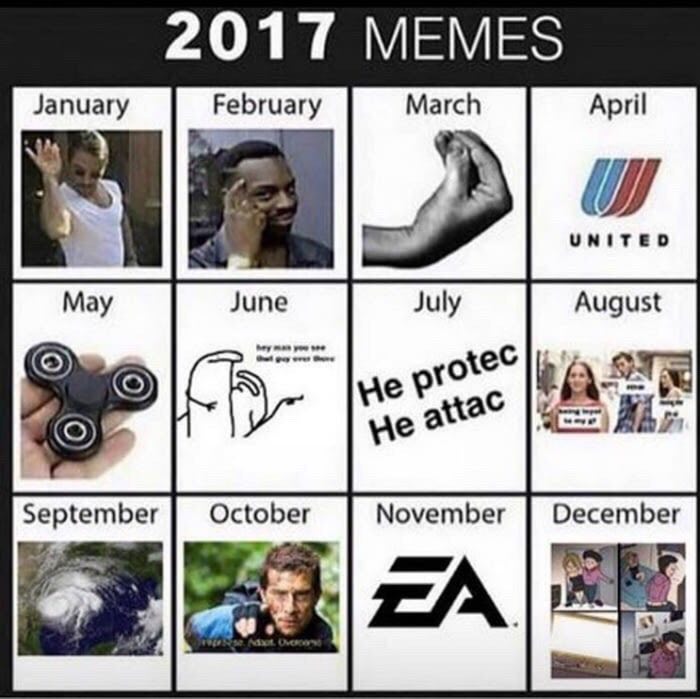
However, even the conscience, richly flavored with salads, sometimes woke up and demanded a little bit of control and engage in useful activities. Therefore, we combined business with pleasure and, using the example of our favorite memes, we looked at how we could parse our small base.
data, passing along all sorts of locks, pitfalls and restrictions placed by the server in our path. All interested kindly invite under the cat.
Machine learning, econometrics, statistics and many other data sciences are engaged in the search for patterns. Every day, valiant analyst inquisitors torture nature with different methods and extract information from it about how the great data-generating process that created our universe works. Spanish inquisitors in their daily activities used directly the physical body of their victim. Nature is omnipresent and does not have an unambiguous physical appearance. Because of this, the profession of the modern inquisitor has a strange specificity - the torture of nature occurs through the analysis of data that must be taken from somewhere. Typically, data to the inquisitors bring peace collectors. This little article is designed to slightly open the veil of secrecy about where the data come from and how to get them a little bit.
Our motto was the famous phrase of Captain Jack Sparrow: "Take everything and give nothing away." Sometimes you have to use pretty gangster methods to collect memes. Nevertheless, we will remain peaceful data collectors, and in no way will we become bandits. We will take memes from the main memorial depository.

1. Mlamyvae in the memorial
1.1. What we want to get
So, we want to parse knowyourmeme.com and get a bunch of different variables:
- Name - the name of the meme,
- Origin_year - the year of its creation,
- Views - the number of views
- About - textual description of the meme,
- and many others
Moreover, we want to do it without all this:
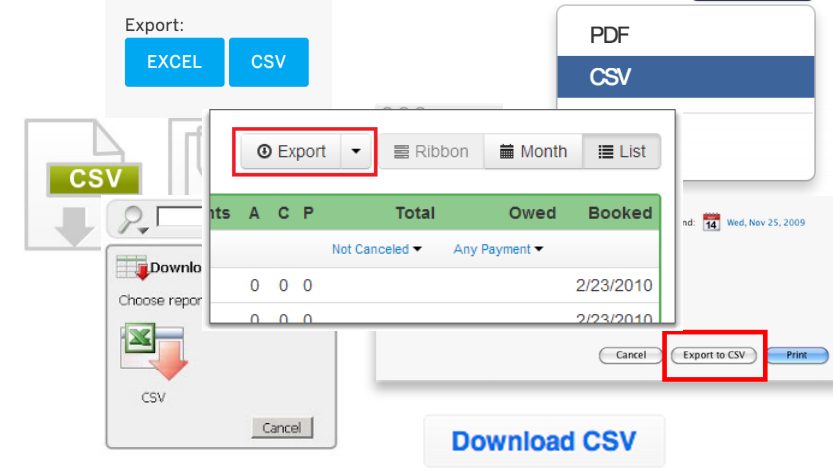
After downloading and cleaning the data from the garbage can be done building models. For example, try to predict the popularity of a meme by its parameters. But this is all later, and now we will get acquainted with a couple of definitions:
- Parser is a script that robs information from the site.
- The crawler is the part of the parser that roams the links.
- Crawling is a transition through pages and links.
- Scraping is the collection of data from pages.
- Parsing is at once crawling and scraping!
1.2. What is HTML?
HTML (HyperText Markup Language) is a markup language like Markdown or LaTeX. It is standard for writing various sites. Commands in such a language are called tags . If you open absolutely any site, click on the right mouse button, and then click View page source , then you will see the HTML skeleton of this site.
You can see that the HTML page is nothing more than a set of nested tags. You may notice, for example, the following tags:
<title>- page title<h1>…<h6>- headings of different levels<p>- paragraph (paragraph)<div>- selection of a fragment of the document in order to change the appearance of the content<table>- drawing the table<tr>- separator for rows in the table<td>- separator for columns in a table<b>- sets the bold font.
Usually the command <...> opens the tag, and </...> closes it. Everything between these two commands follows the rule that the tag dictates. For example, everything between <p> and </p> is a separate paragraph.
Tags form a kind of tree with a root in the <html> and split the page into different logical pieces. Each tag can have its own descendants (children) - those tags that are embedded in it, and their parents.
For example, an HTML tree of a page might look like this:
<html> <head> </head> <body> <div> </div> <div> <b> , </b> </div> </body> </html> 
You can work with this html as with the text, and you can as with the tree. Traversing this tree is parsing a web page. We will only find the nodes we need among all this diversity and collect information from them!
Manually bypassing these trees is not very pleasant, so there are special languages for traversing trees.
- CSS selector (this is when we search for a page element by a pair of key, value)
- XPath (this is when we write the path through the tree like this: / html / body / div [1] / div [3] / div / div [2] / div)
- All sorts of different libraries for all sorts of languages, for example, BeautifulSoup for python. This is the library we will use.
1.3. Our first request
Access to the web pages allows you to receive requests . We will load it. For the company we will load a couple more efficient packages.
import requests # import numpy as np # , import pandas as pd # import time # - For our noble research goals, we need to collect data on each topic from its corresponding page. But first you need to get the addresses of these pages. Therefore, we open the main page with all the laid out memes. It looks like this:

From here we will drag links to each of the listed memes. Let's page_link address of the main page into the page_link variable and open it with the requests library.
page_link = 'http://knowyourmeme.com/memes/all/page/1' response = requests.get(page_link) response Out: <Response [403]> And here is the first problem! Appeal to  the main source of knowledge and find out that the 403rd error is issued by the server if it is available and able to process requests, but for some personal reasons refuses to do so.
the main source of knowledge and find out that the 403rd error is issued by the server if it is available and able to process requests, but for some personal reasons refuses to do so.
Let's try to find out why. To do this, check what the final request sent by us to the server looked like, and more specifically, what our User-Agent looked like in the eyes of the server.
for key, value in response.request.headers.items(): print(key+": "+value) Out: User-Agent: python-requests/2.14.2 Accept-Encoding: gzip, deflate Accept: */* Connection: keep-alive It seems that we have made it clear to the server that we are sitting on a python and using the requests library under version 2.14.2. Most likely, this caused the server some suspicions about our good intentions and he decided to ruthlessly reject us. For comparison, you can see what the request-headers look like in a healthy person:

Obviously, our humble request does not incur such an abundance of meta-information, which is transmitted upon request from a regular browser. Fortunately, no one bothers us to pretend to be humane and throw dust into the eyes of the server by generating a fake user agent. There are a lot of libraries that cope with this task; I personally like the most fake-useragent . When the method is called from different pieces, a random combination of the operating system, specifications and browser versions will be generated, which can be sent to the request:
# from fake_useragent import UserAgent UserAgent().chrome Out: 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36' Let's try to get rid of our request again, already with the generated agent.
response = requests.get(page_link, headers={'User-Agent': UserAgent().chrome}) response Out: <Response [200]> Great, our little disguise  the deceived server worked and meekly issued the blessed 200 answer - the connection was established and the data was received, everything is wonderful! Let's see what we got after all.
the deceived server worked and meekly issued the blessed 200 answer - the connection was established and the data was received, everything is wonderful! Let's see what we got after all.
html = response.content html[:1000] Out: b'<!DOCTYPE html>\n<html xmlns:fb=\'http://www.facebook.com/2008/fbml\' xmlns=\'http://www.w3.org/1999/xhtml\'>\n<head>\n<meta content=\'text/html; charset=utf-8\' http-equiv=\'Content-Type\'>\n<script type="text/javascript">window.NREUM||(NREUM={});NREUM.info={"beacon":"bam.nr-data.net","errorBeacon":"bam.nr-data.net","licenseKey":"c1a6d52f38","applicationID":"31165848","transactionName":"dFdfRUpeWglTQB8GDUNKWFRLHlcJWg==","queueTime":0,"applicationTime":59,"agent":""}</script>\n<script type="text/javascript">window.NREUM||(NREUM={}),__nr_require=function(e,t,n){function r(n){if(!t[n]){var o=t[n]={exports:{}};e[n][0].call(o.exports,function(t){var o=e[n][1][t];return r(o||t)},o,o.exports)}return t[n].exports}if("function"==typeof __nr_require)return __nr_require;for(var o=0;o<n.length;o++)r(n[o]);return r}({1:[function(e,t,n){function r(){}function o(e,t,n){return function(){return i(e,[f.now()].concat(u(arguments)),t?null:this,n),t?void 0:this}}var i=e("handle"),a=e(2),u=e(3),c=e("ee").get("tracer")' It looks indigestible, how about making something more beautiful out of this thing? For example, a wonderful soup.
1.4. Lovely soup

Package bs4, aka BeautifulSoup (there is a hyperlink to the person’s best friend - documentation) was named after the rhyme about the wonderful soup from Alice in Wonderland.
A wonderful soup is a completely magical library, which, from raw and unprocessed HTML page code, will give you a structured array of data that makes it very convenient to search for the necessary tags, classes, attributes, texts, and other elements of web pages.
The package calledBeautifulSoupis most likely not what we need. This is the third version ( Beautiful Soup 3 ), and we will use the fourth. You will need to install thebeautifulsoup4package. To make it quite fun, when importing, you need to specify another package name -bs4, and import a function calledBeautifulSoup. In general, it is easy to get confused at first, but these difficulties must be overcome.
The package also works with the raw XML code of the page (XML is corrupted and turned into a dialect, with the help of its own commands, HTML). In order for the package to work correctly with XML markup, you will have to install the xml package in the appendage of our entire arsenal.
from bs4 import BeautifulSoup Pass the BeautifulSoup function to the text of the web page we recently received.
soup = BeautifulSoup(html,'html.parser') # lxml, # We get something like this:
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:fb="http://www.facebook.com/2008/fbml"> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <script type="text/javascript">window.NREUM||(NREUM={});NREUM.info={"beacon":"bam.nr-data.net","errorBeacon":"bam.nr-data.net","licenseKey":"c1a6d52f38","applicationID":"31165848","transactionName":"dFdfRUpeWglTQB8GDUNKWFRLHkUNWUU=","queueTime":0,"applicationTime":24,"agent":""}</script> <script type="text/javascript">window.NREUM||(NREUM={}),__nr_require=function(e,n,t){function r(t){if(!n[t]){var o=n[t]={exports:{}};e[t][0].call(o.exports,function(n){var o=e[t][1][n];return r(o||n)},o,o.exports)}return n[t].exports}if("function"==typeof __nr_require)return __nr_require;for(var o=0;o<t.length;o++)r(t[o]);return r}({1:[function(e,n,t){function r(){}function o(e,n,t){return function(){return i(e,[c.now()].concat(u(arguments)),n?null:this,t),n?void 0:this}}var i=e("handle"),a=e(2),u=e(3),f=e("ee").get("tracer"),c=e("loader"),s=NREUM;"undefined"==typeof window.newrelic&&(newrelic=s);var p= It has become much better, is not it? What lies in the variable soup ? An inattentive user will most likely say that nothing has changed at all. However, it is not. Now we can freely roam the HTML tree of the page, search for children, parents and pull them out!
For example, you can wander around the vertices, indicating the path of the tags.
soup.html.head.title Out: <title>All Entries | Know Your Meme</title> You can pull out from the place where we wandered, text using the text method.
soup.html.head.title.text Out: 'All Entries | Know Your Meme' Moreover, knowing the address of the item, we can immediately find it. For example, you can do this by class. The next command should find the element that lies inside the a tag and has the class photo .
obj = soup.find('a', attrs = {'class':'photo'}) obj Out: <a class="photo left" href="/memes/nu-male-smile" target="_self"><img alt='The "Nu-Male Smile" Is Duck Face for Men' data-src="http://i0.kym-cdn.com/featured_items/icons/wide/000/007/585/7a2.jpg" height="112" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title='The "Nu-Male Smile" Is Duck Face for Men' width="198"/> <div class="info abs"> <div class="c"> The "Nu-Male Smile" Is Duck Face for Men </div> </div> </a> However, contrary to our expectations, the pulled out object has the class "photo left" . It turns out that BeautifulSoup4 regards the class attributes as a set of separate values, so "photo left" for the library is equivalent to ["photo", "left"] , and the value of this class that we have specified "photo" is included in this list. To avoid such an unpleasant situation and passes through unnecessary links to us, you will have to use your own function and set strict correspondence:
obj = soup.find(lambda tag: tag.name == 'a' and tag.get('class') == ['photo']) obj Out: <a class="photo" href="/memes/people/mf-doom"><img alt="MF DOOM" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/149/1489698959244.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="MF DOOM"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a> The object obtained after the search also has the structure bs4. Therefore, you can continue to search for the objects we need in it already! Get a link to this meme. This can be done by the attribute href , which is our link.
obj.attrs['href'] Out: '/memes/people/mf-doom' Notice that after all these crazy transformations, the data has changed type. Now they are str . This means that you can work with them as with text and use it to sift out unnecessary information regular expressions.
print(" :", type(obj)) print(" :", type(obj.attrs['href'])) Out: : <class 'bs4.element.Tag'> : <class 'str'> If several elements on the page have the specified address, then the find method will return only the very first one. To find all items with such an address, you need to use the findAll method, and a list will be output. Thus, we can get all objects with links to pages with memes in one search at once.
meme_links = soup.findAll(lambda tag: tag.name == 'a' and tag.get('class') == ['photo']) meme_links[:3] Out: [<a class="photo" href="/memes/people/mf-doom"><img alt="MF DOOM" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/149/1489698959244.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="MF DOOM"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>, <a class="photo" href="/memes/here-lies-beavis-he-never-scored"><img alt="Here Lies Beavis. He Never Scored." data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/148/maxresdefault.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="Here Lies Beavis. He Never Scored."/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> </div> </a>, <a class="photo" href="/memes/people/vanossgaming"><img alt="VanossGaming" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/147/Evan-Fong-e1501621844732.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="VanossGaming"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>] It remains to clear the list of garbage:
meme_links = [link.attrs['href'] for link in meme_links] meme_links[:10] Out: ['/memes/people/mf-doom', '/memes/here-lies-beavis-he-never-scored', '/memes/people/vanossgaming', '/memes/stream-sniping', '/memes/kids-describe-god-to-an-illustrator', '/memes/bad-teacher', '/memes/people/adam-the-creator', '/memes/but-can-you-do-this', '/memes/people/ken-ashcorp', '/memes/heartbroken-cowboy'] Done, got exactly 16 links by the number of memes on one search page.
Well, the fact that you can search for an element by its address is, of course, cool, but where do you get this address from? You can install some kind of utility for your browser that allows you to pull the necessary tags from the page, for example, select orgadget.
However, this path is not suitable for a true samurai. For followers of bushido, there is another way - to search for tags for each item we need manually. To do this, you have to right-click on the browser window and poke the Inspect button. After all these manipulations, the browser will look something like this:

Jumped out a piece of html in which the address of the object you selected is located, you can safely copy into the code and enjoy your brutality.
Stayed last moment. When we download all the memes from the current page, we will need to somehow get to the next one. On the website, you can do this just by scrolling down the page with memes, the javascript functions pull new memes to the current window, but now you don’t want to touch these functions.
Usually, all the parameters that we set on the site to search for, are displayed on the structure of the preach. Memes are no exception. If we want to get the first batch of memes, we will need to contact the site by reference.
http://knowyourmeme.com/memes/all/page/1
If we want to get a second one with sixteen memes, we will have to modify the link a little, namely, replace the page number with 2.
http://knowyourmeme.com/memes/all/page/2
In this simple way, we will be able to go through all the pages and rob a memorial depository. Finally, we wrap up in the beautiful function all the manipulations done above:
def getPageLinks(page_number): """ , page_number: int/string """ # page_link = 'http://knowyourmeme.com/memes/all/page/{}'.format(page_number) # response = requests.get(page_link, headers={'User-Agent': UserAgent().chrome}) if not response.ok: # , return [] # html = response.content soup = BeautifulSoup(html,'html.parser') # , meme_links = soup.findAll(lambda tag: tag.name == 'a' and tag.get('class') == ['photo']) meme_links = ['http://knowyourmeme.com' + link.attrs['href'] for link in meme_links] return meme_links Test the function and make sure everything is fine.
meme_links = getPageLinks(1) meme_links[:2] Out: ['http://knowyourmeme.com/memes/people/mf-doom', 'http://knowyourmeme.com/memes/here-lies-beavis-he-never-scored'] Great, the function works and now we can theoretically get links to the whole 17171 meme, for which we will have to go through 17171/16 ~ 1074 pages. Before frustrating the server with so many requests, let's see how to get all the necessary information about a particular meme.
1.5 Final preparation for robbery
By analogy with links, you can pull anything. For this you need to take a few steps:
- Open the meme page
- Find a tag in any way for the information we need.
- Shove it all into a beautiful soup
- ......
- Profit
To fix the information in the head of an inquisitive reader, pull out the number of views of the meme.
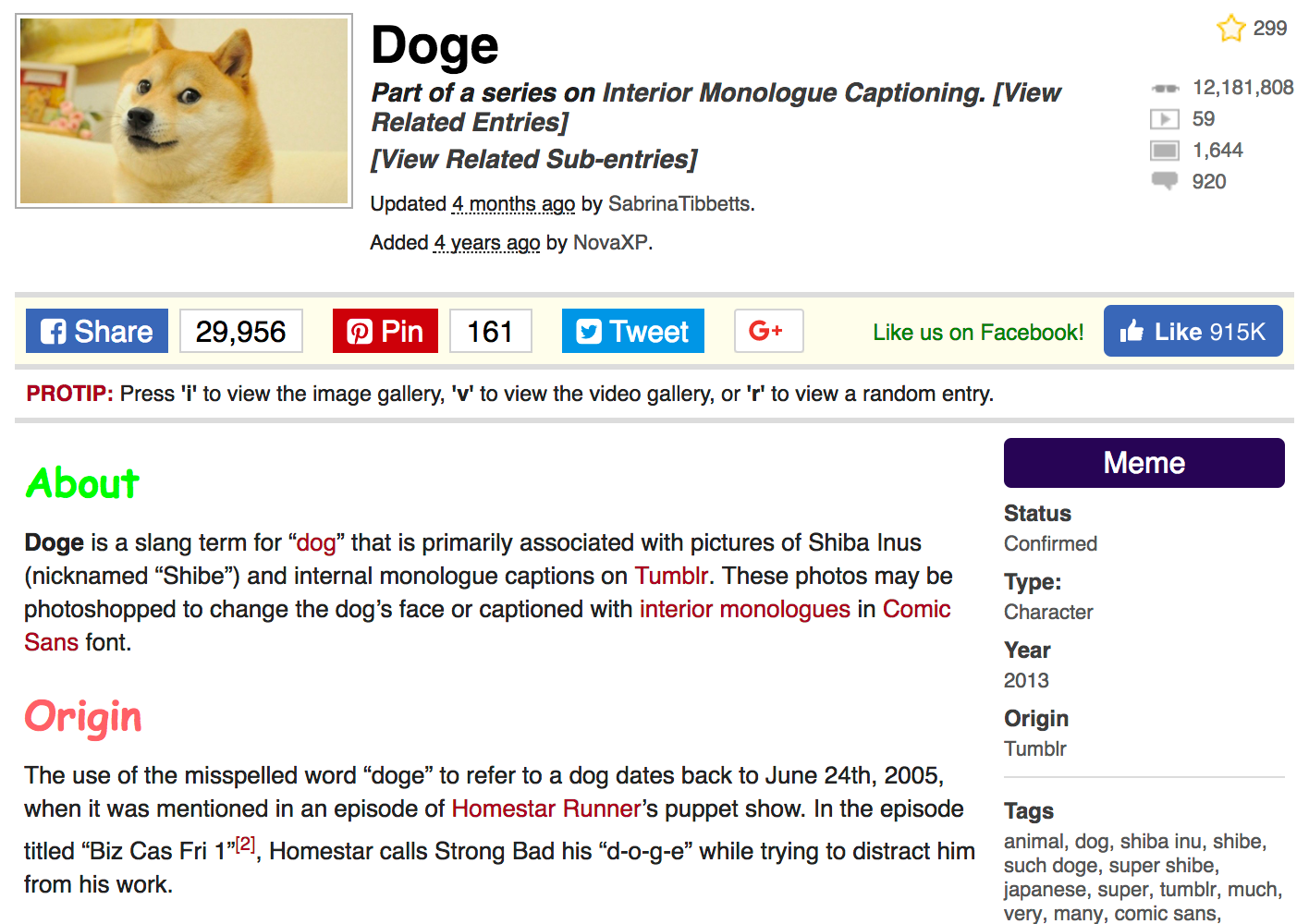
As an example, let's take the most popular meme on this site - Doge, which collected more than 12 million views as of January 1, 2018.
The very page from which we will reach the information dear to our research heart looks as follows:
As before, for a start we will save the link to the page into a variable and drag out the content on it.
meme_page = 'http://knowyourmeme.com/memes/doge' response = requests.get(meme_page, headers={'User-Agent': UserAgent().chrome}) html = response.content soup = BeautifulSoup(html,'html.parser') Let's see how you can get statistics on views, comments, and the number of downloaded videos and photos associated with our memes. All this stuff is stored in the upper right under the tags "dd" and with the classes "views" , "videos" , "photos" and "comments"
views = soup.find('dd', attrs={'class':'views'}) print(views) Out: <dd class="views" title="12,318,185 Views"> <a href="/memes/doge" rel="nofollow">12,318,185</a> </dd> Clear tags and punctuation
views = views.find('a').text views = int(views.replace(',', '')) print(views) Out: 12318185 Putting it all into a small function again.
def getStats(soup, stats): """ //... soup: bs4.BeautifulSoup stats: string views/videos/photos/comments """ obj = soup.find('dd', attrs={'class':stats}) obj = obj.find('a').text obj = int(obj.replace(',', '')) return obj All is ready!
views = getStats(soup, stats='views') videos = getStats(soup, stats='videos') photos = getStats(soup, stats='photos') comments = getStats(soup, stats='comments') print(": {}\n: {}\n: {}\n: {}".format(views, videos, photos, comments)) Out: : 12318185 : 59 : 1645 : 918 From the interesting and research, we’ll get the date and time of adding a meme. If you look at the page in the browser, you might think that the maximum information that we can pull out is the number of years since publication - Added 4 years ago by NovaXP . However, we will not give up so easily, we will climb into the intestines of html and dig out the piece responsible for this inscription:
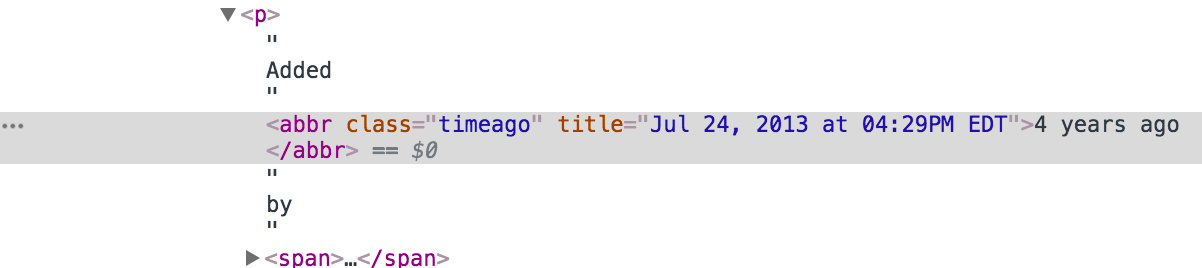
Aha Here are the details on the date of addition, up to a minute. Elementary

date = soup.find('abbr', attrs={'class':'timeago'}).attrs['title'] date Out: '2017-12-31T01:59:14-05:00' Actually, parsers are unpredictable. Often the pages we parse have a very heterogeneous structure. For example, if we parse memes, some of the pages may have a description, but some may not. As soon as the code first stumbles upon the absence of a description, it gives an error and stops. To properly collect all the data, you have to register exceptions. It seems that the storage of memes is well equipped and there should not be any abnormal situations.
However, I really do not want to wake up in the morning and see that the code made 20 iterations, ran into an error and got chopped off. To prevent this from happening, you can, for example, use the try - except construction and simply handle errors that we do not like. About exceptions can be read on the Internet . In our case, it’s possible not to bring up the error, but first check whether there is a necessary element on the page or not with the help of the usual if - else , and after that try to parse it.
For example, we want to pull out the status of a meme, for this we find the tags surrounding it:
properties = soup.find('aside', attrs={'class':'left'}) meme_status = properties.find("dd") meme_status Out: <dd> Confirmed </dd> Next you need to pull out the text from the tags, and then cut off all the extra spaces.
meme_status.text.strip() Out: 'Confirmed' However, if it suddenly turns out that the meme has no status, the find method returns void. The text method, in turn, cannot find text in tags and will generate an error. To protect yourself from such voids, you can write an exception or if - else . Since there is still a status in the current meme, we purposely set it as an empty object to check that the error is detected in both cases.
# ! , meme_status = None # ! ... # ... try: print(meme_status.text.strip()) # , , . except: print("Exception") # ... if meme_status: print(meme_status.text.strip()) else: print("Empty") Out: Exception Empty This code allows you to protect yourself from errors. In this case, we can rewrite the whole construction with if - else in the form of one convenient string. This line will check if the response meme_status and if not, it will give out emptiness.
# properties = soup.find('aside', attrs={'class':'left'}) meme_status = properties.find("dd") meme_status = "" if not meme_status else meme_status.text.strip() print(meme_status) Out: Confirmed By analogy, you can pull out all the rest of the information from the page, for which we again write the function
def getProperties(soup): """ (tuple) , , , soup: bs4.BeautifulSoup """ # - h1, meme_name = soup.find('section', attrs={'class':'info'}).find('h1').text.strip() # properties = soup.find('aside', attrs={'class':'left'}) # - meme_status = properties.find("dd") # oneliner, try-except: properties, NoneType, # text , meme_status = "" if not meme_status else meme_status.text.strip() # - meme_type = properties.find('a', attrs={'class':'entry-type-link'}) meme_type = "" if not meme_type else meme_type.text # Year, # , - meme_origin_year = properties.find(text='\nYear\n') meme_origin_year = "" if not meme_origin_year else meme_origin_year.parent.find_next() meme_origin_year = meme_origin_year.text.strip() # meme_origin_place = properties.find('dd', attrs={'class':'entry_origin_link'}) meme_origin_place = "" if not meme_origin_place else meme_origin_place.text.strip() # , meme_tags = properties.find('dl', attrs={'id':'entry_tags'}).find('dd') meme_tags = "" if not meme_tags else meme_tags.text.strip() return meme_name, meme_status, meme_type, meme_origin_year, meme_origin_place, meme_tags getProperties(soup) Out: ('Doge', 'Confirmed', 'Animal', '2013', 'Tumblr', 'animal, dog, shiba inu, shibe, such doge, super shibe, japanese, super, tumblr, much, very, many, comic sans, photoshop meme, such, shiba, shibe doge, doges, dogges, reddit, comic sans ms, tumblr meme, hacked, bitcoin, dogecoin, shitposting, stare, canine') Meme properties collected. Now we collect by analogy its text description.
def getText(soup): """ soup: bs4.BeautifulSoup """ # body = soup.find('section', attrs={'class':'bodycopy'}) # about ( ), , meme_about = body.find('p') meme_about = "" if not meme_about else meme_about.text # origin Origin History, # , - meme_origin = body.find(text='Origin') or body.find(text='History') meme_origin = "" if not meme_origin else meme_origin.parent.find_next().text # ( ) if body.text: other_text = body.text.strip().split('\n')[4:] other_text = " ".join(other_text).strip() else: other_text = "" return meme_about, meme_origin, other_text meme_about, meme_origin, other_text = getText(soup) print(" :\n{}\n\n:\n{}\n\n :\n{}...\n"\ .format(meme_about, meme_origin, other_text[:200])) Out: : Doge is a slang term for “dog” that is primarily associated with pictures of Shiba Inus (nicknamed “Shibe”) and internal monologue captions on Tumblr. These photos may be photoshopped to change the dog's face or captioned with interior monologues in Comic Sans font. : The use of the misspelled word “doge” to refer to a dog dates back to June 24th, 2005, when it was mentioned in an episode of Homestar Runner's puppet show. In the episode titled “Biz Cas Fri 1”[2], Homestar calls Strong Bad his “doge” while trying to distract him from his work. : Identity On February 23rd, 2010, Japanese kindergarten teacher Atsuko Sato posted several photos of her rescue-adopted Shiba Inu dog Kabosu to her personal blog.[38] Among the photos included a peculi... , ,
def getMemeData(meme_page): """ , meme_page: string """ # response = requests.get(meme_page, headers={'User-Agent': UserAgent().chrome}) if not response.ok: # , return response.status_code # html = response.content soup = BeautifulSoup(html,'html.parser') # views = getStats(soup=soup, stats='views') videos = getStats(soup=soup, stats='videos') photos = getStats(soup=soup, stats='photos') comments = getStats(soup=soup, stats='comments') # date = soup.find('abbr', attrs={'class':'timeago'}).attrs['title'] # , , .. meme_name, meme_status, meme_type, meme_origin_year, meme_origin_place, meme_tags =\ getProperties(soup=soup) # meme_about, meme_origin, other_text = getText(soup=soup) # , data_row = {"name":meme_name, "status":meme_status, "type":meme_type, "origin_year":meme_origin_year, "origin_place":meme_origin_place, "date_added":date, "views":views, "videos":videos, "photos":photos, "comments":comments, "tags":meme_tags, "about":meme_about, "origin":meme_origin, "other_text":other_text} return data_row , ,
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place', 'date_added', 'views', 'videos', 'photos', 'comments', 'tags', 'about', 'origin', 'other_text']) data_row = getMemeData('http://knowyourmeme.com/memes/doge') final_df = final_df.append(data_row, ignore_index=True) final_df Out: | name | status | type | origin_year | ... |
|---|---|---|---|---|
| Doge | Confirmed | Animal | 2013 | ... |
. — , meme_links .
for meme_link in meme_links: data_row = getMemeData(meme_link) final_df = final_df.append(data_row, ignore_index=True) Out: | name | status | type | origin_year | ... |
|---|---|---|---|---|
| Doge | Confirmed | Animal | 2013 | ... |
| Charles C. Johnson | Submission | Activist | 2013 | ... |
| Bat- (Prefix) | Submission | Snowclone | 2018 | ... |
| The Eric Andre Show | Deadpool | TV Show | 2012 | ... |
| Hopsin | Submission | Musician | 2003 | ... |
Fine! , , , — , , .
2.
2.1
Here he is! , , , , — . , . . try-except . .
# . # tqdm_notebook from tqdm import tqdm_notebook final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place', 'date_added', 'views', 'videos', 'photos', 'comments', 'tags', 'about', 'origin', 'other_text']) for page_number in tqdm_notebook(range(1075), desc='Pages'): # meme_links = getPageLinks(page_number) for meme_link in tqdm_notebook(meme_links, desc='Memes', leave=False): # for i in range(5): try: # data_row = getMemeData(meme_link) # final_df = final_df.append(data_row, ignore_index=True) # - break except: # , , print('AHTUNG! parsing once again:', meme_link) continue ! - - , , .

, , , . .
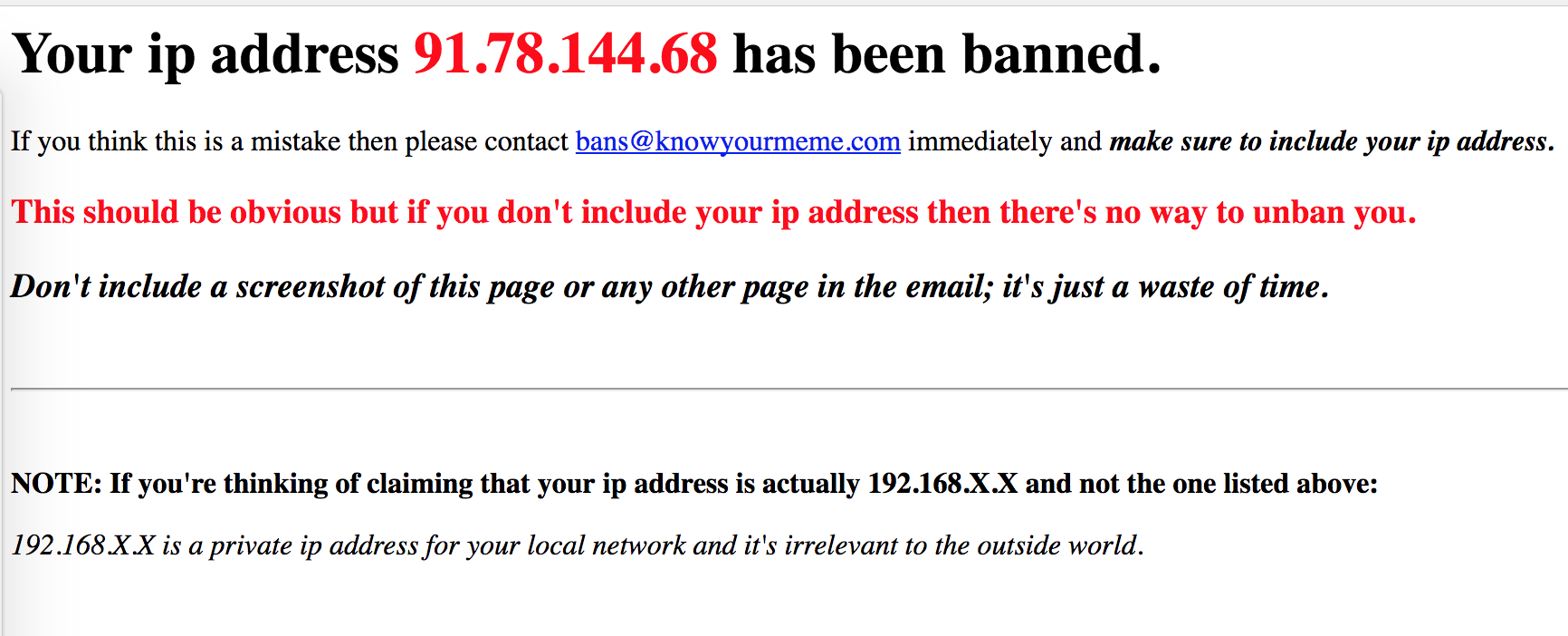
2.2 —
, . , .
. , , , request-header . , IP, , IP . , -, IP , "". : — - , — ?
Tor . , Tor , . , , , , , . , Tor, , . :
, , , Tor . ip-. get- , IP
def checkIP(): ip = requests.get('http://checkip.dyndns.org').content soup = BeautifulSoup(ip, 'html.parser') print(soup.find('body').text) checkIP() Out: Current IP Address: 82.198.191.130 ip Tor . — , — .
tor , . tor .
- Linux —
apt-get install tor, - Mac — brew ,
brew install tor. - Windows — .
2.3
. ip PySocks . , , pip3 install PySocks .
9150. socks socket . , – - .
import socks import socket socks.set_default_proxy(socks.SOCKS5, "localhost", 9150) socket.socket = socks.socksocket ip-a.
checkIP() Out: Current IP Address: 51.15.92.24 … !

ip-.
data_row = getMemeData('http://knowyourmeme.com/memes/doge') for key, value in data_row.items(): print(key.capitalize()+":", str(value)[:200], end='\n\n') Out: Name: Doge Status: Confirmed Type: Animal Origin_year: 2013 Origin_place: Tumblr Date_added: 2017-12-31T01:59:14-05:00 Views: 12318185 Videos: 59 Photos: 1645 Comments: 918 Tags: animal, dog, shiba inu, shibe, such doge, super shibe, japanese, super, tumblr, much, very, many, comic sans, photoshop meme, such, shiba, shibe doge, doges, dogges, reddit, comic sans ms, tumblr meme About: Doge is a slang term for “dog” that is primarily associated with pictures of Shiba Inus (nicknamed “Shibe”) and internal monologue captions on Tumblr... . . . .
, : , - ip 10 . , ? , , Tor torrc ( ~/Library/Application Support/TorBrowser-Data/torrc , — ) . :
CircuitBuildTimeout 10 LearnCircuitBuildTimeout 0 MaxCircuitDirtiness 10 ip 10 . .
for i in range(10): checkIP() time.sleep(5) Out: Current IP Address: 89.31.57.5 Current IP Address: 93.174.93.71 Current IP Address: 62.210.207.52 Current IP Address: 209.141.43.42 Current IP Address: 209.141.43.42 Current IP Address: 162.247.72.216 Current IP Address: 185.220.101.17 Current IP Address: 193.171.202.150 Current IP Address: 128.31.0.13 Current IP Address: 185.163.1.11 , ip 10 . . 20 .
- ;
- ;
- .....
- Profit
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place', 'date_added', 'views', 'videos', 'photos', 'comments', 'tags', 'about', 'origin', 'other_text']) for page_number in tqdm_notebook(range(1075), desc='Pages'): # meme_links = getPageLinks(page_number) for meme_link in tqdm_notebook(meme_links, desc='Memes', leave=False): # for i in range(5): try: # data_row = getMemeData(meme_link) # final_df = final_df.append(data_row, ignore_index=True) # - break except: # , , continue final_df.to_csv('MEMES.csv') . . . : , ip ?
2.4
ip . Github - TorCrawler.py . , , . . . , .
, torrc . /usr/local/etc/tor/ , /etc/tor/ . .
tor --hash-password mypassword- torrc vim , nano atom
- torrc- , HashedControlPassword
- , HashedControlPassword
- ( ) ControlPort 9051
- .
tor . : service tor start , : tor .
.
from TorCrawler import TorCrawler # , crawler = TorCrawler(ctrl_pass='mypassword') get- , bs4.
meme_page = 'http://knowyourmeme.com/memes/doge' response = crawler.get(meme_page, headers={'User-Agent': UserAgent().chrome}) type(response) Out: bs4.BeautifulSoup - .
views = response.find('dd', attrs={'class':'views'}) views Out: <dd class="views" title="12,318,185 Views"> <a href="/memes/doge" rel="nofollow">12,318,185</a> </dd> IP
crawler.ip Out: '51.15.40.23' ip 25 . n_requests . , .
crawler.n_requests Out: 25 , ip .
crawler.rotate() IP successfully rotated. New IP: 62.176.4.1 , , IP . .
. .
Conclusion
, . — , , , , - , , , . , , , , , DDoS-. , , — , — .
— - , . time.sleep() request-header — .
!
: filfonul , Skolopendriy
')
Source: https://habr.com/ru/post/346632/
All Articles