Events, processes and services: a modern approach to automating business processes
Summary
- Using event-driven architecture to reduce connectivity is a very popular idea when designing microservices.
- Event-based business logic is well suited for decentralized data and solving end-to-end functionality problems. However, it is not necessary to build complex chains on the transfer of events from service to service. Coordination of services with the help of commands, rather than events - allows you to unleash them even more.
- ESB (Enterprise Service Bus, in the context of the article - "smart bus" - note of the translation.) Does not fit well with microservice architecture. It is preferable to use simple data transfer channels and smart customers (smart endpoints, dumb pipes). But, do not refuse the coordinating service of other services only out of fears of receiving one god-like service: business logic still needs a home.
- Workflow engines of the past were mostly vendor-dependent. The so-called "zero-code" solutions - in practice turned into a nightmare for developers. There are currently lightweight and simple workflow management tools, many of which are open source.
- Do not waste time writing your own finite automata. On the contrary, use ready-made solutions to avoid difficulties.
Use event-driven architecture to achieve loose coupling.
Such advice is often found in discussions on the subject of microservices. In particular, it is popular and supported in DDD (Domain-Driven Design) communities. The authors of the article, being potential supporters of event models, nevertheless asked themselves the question: what risks can be borne by thoughtless use of events? For the answer, 3 popular hypotheses were considered:
- Events reduce connectivity
- God-like (central control) services should be avoided.
- Workflow engines have their sores.
The examples below are artificial, but inspired by the real business process of order processing in Zalando. Suppose there are 4 limited contexts ( bounded context ) in 4 isolated applications (this can be either microservices or representatives of other architectures):
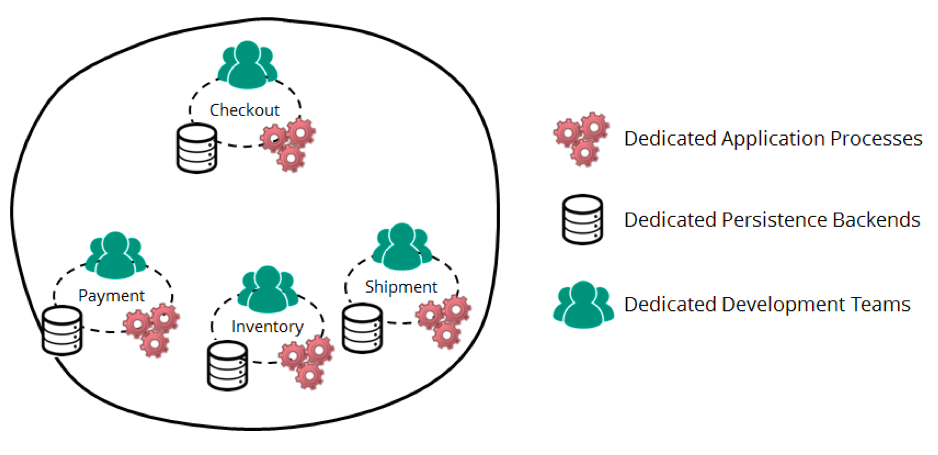
How to reduce connectivity with events
Suppose that the Checkout service must notify the user if the product has appeared in stock and can be shipped immediately. Of course, Checkout can directly poll the Inventory service about the quantity of goods in stock, but this would make Checkout dependent on Inventory, i.e. would strengthen connectivity.
Alternative approach: Inventory publishes product change events in stock. Checkout listens for events and stores fresh values in the local cache. This data is a copy, the absolute integrity of which is not at all mandatory. Although, a certain level of event integrity is usually necessary in distributed systems.
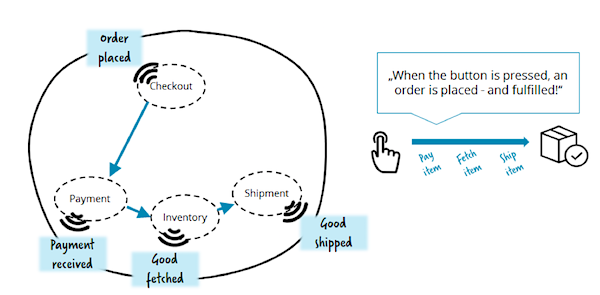
Another scenario: end-to-end functionality. Let it be necessary to send notifications to the customer at certain steps of the order. We could add to the system a fully autonomous Notification service that stores the settings and contact details of customers. Having received an event like "payment received" or "order shipped", this service would send letters without requiring changes to other services. As we can see, event-driven architecture is very flexible, and allows you to easily add new services, or expand old ones.
The dangers of complex event transmission chains
Developers who implement event-driven architecture often become obsessed: events superbly reduce the coherence of the system, so let's use events everywhere and always! Problems begin when a team implements a business process (eg order processing) through a chain of messages from one service to another. Consider the simplest example: let each service in the chain decide for itself what to do and which events to send:
Yes it works. But the problem is that none of the links in the chain has a clear vision of the whole process. This makes the business process difficult to understand and (more importantly) difficult to change. Consider also that in the real world business processes are far from being so simple, and usually involve much more services. The authors of the article have seen complex microservice systems that no one else understands in detail.
And now we will think about how we would realize the reservation of goods at the warehouse BEFORE making a payment:
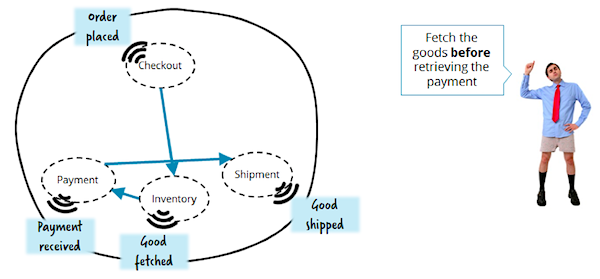
It is necessary to correct and re-assign several services in order to simply change the sequence of order execution steps! This is the anti-pattern for microservice architecture, since its key principle is to strive for less cohesiveness and greater isolation. Therefore, think twice before using events in similar “service-to-service” processes, especially where high complexity is expected.
Commands, but without the need for central control
It would be more reasonable to keep the whole business process in a separate service. Such a service manager can send commands to others, for example, “make a payment”. At the same time, one should avoid the knowledge of microservices about each other. The authors call this pattern "orchestration" (orchestration). For example: "Order controls (orchestrates) the Payment, Inventory and Shipment services".
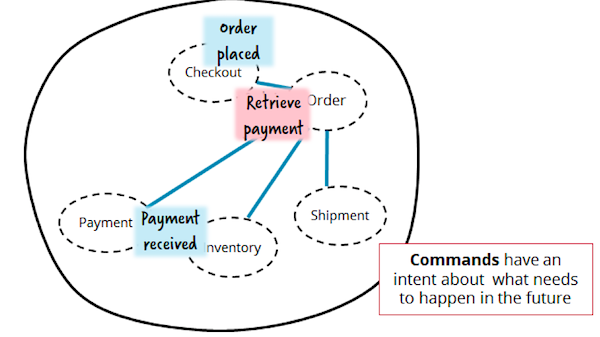
Speaking of orchestration, many come to mind with the miraculous Enterprise Service Bus (ESB) bus, as well as Business Process Modeling (BPM) solutions. These complex, proprietary tools have a bad reputation and for good reason. Often they deprive us of simple, understandable testing and lightweight application delivery. At the same time, James Lewis and Martin Fowler laid many of the foundations of the microservice architecture, suggesting the use of "smart endpoints and simple transfer channels" ( smart endpoints, dumb pipes ).
The picture above does not imply the use of a “smart bus”. All control over the processing of the order is assigned to a separate service manager Order. The team is free to implement this service as convenient, using any technology to taste. Thus, changes in the business process will affect one, and only one microservice. Moreover, a business process concentrated in one place is much easier to understand.
Sam Newman, in his book Building Microservices, considers the risk that such a service manager will grow into a godlike monster over time. Such a god service will collect all the business logic, and the rest will degenerate into anemic services, or worse: CRUD will become simple.
Did this happen due to the use of commands to the detriment of the event architecture? Or is the problem in the orchestration itself? Neither one nor the other. Let's take a look at Fowler's "smart endpoints". What defines a smart endpoint? Good API design. For the Payment service, you can develop a high-level API that responds to commands like "return payment" and publishes events like "payment made", "failed to make payment", etc. All sensitive information (for example, about the user's credit card) should be kept inside and only inside microservice. In this case, Microservice Payment will not become anemic, even if it is used by a service manager or someone else.
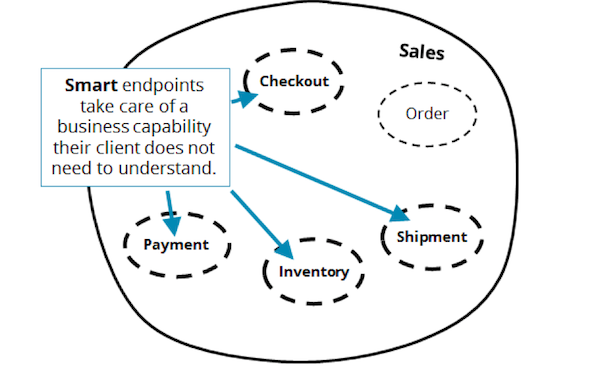
Long-term services
To develop smart endpoints and suitable client APIs, it should be assumed that some processes can be performed for a long time - they also need to solve real business problems behind the scenes! Suppose that in case of an overdue credit card, the customer should have a chance to correct the situation (an example is inspired by GitHub, where a business account is closed only 2 weeks after non-payment). If our Payment service is not going to be engaged in waiting for the customer’s actions, he can delegate this task to his customer, the Order service.
However, if you keep this functionality inside the Payment service, the architecture will become cleaner and more consistent with the idea of the "bounded context" of DDD. The fact of waiting until the customer starts a new credit card means that payment can still be made. As a result, the Payment API becomes clean and simple. Sometimes waiting can be 2 weeks - that's what we call a “long-running” business process!
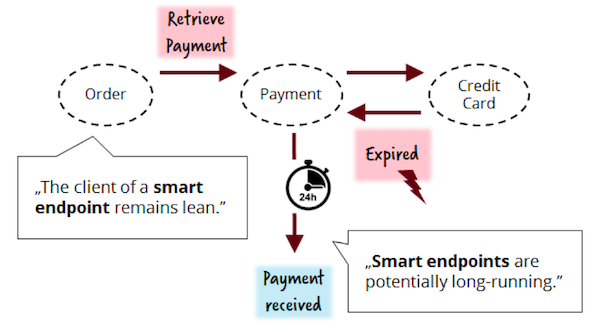
Service state storage
Long-running processes must somewhere keep their state, such as "waiting for payment", etc. To save the state of the application after a reboot is far from a new task, and here are two typical solutions:
- Create your own state storage mechanism based on Entity, Persistent Actor, etc. patterns. Has anyone ever created an Order table with a Status column? That's it!
- Understand and accept a state machine or a whole workflow engine. We have access to many such tools, including quite mature ones. But progress does not stand still: for example, Netflix and Uber are developing their open source solutions.

According to the experience of the authors of the article, their state storage bikes often evolve into homemade finite automata. Because new and new tasks are set for the written system. For example:
- support for timeouts ("let's add a scheduler"),
- reporting tools ("hey, why don't business guys just use SQL to fetch the right data")
- monitoring tools.
We write our state machines not only because of the “Not-Invented-Here” syndrome, but because of the negative reputation that old-fashioned business process automation tools deserve. Many have a painful experience with similar "zero-code" tools. Management buys technology in the hope of getting rid of developers ... which, of course, is not happening. Instead, support for heavyweight and proprietary technology falls on the shoulders of the IT department, where it remains forever an alien, rejected element.
Lightweight state machines and workflow engines
There are simple and flexible tools, to work with which it is enough to write just a few lines of code. These are not zero-code solutions, but regular developer libraries. They take on the work with finite automata, quickly pay for themselves and begin to bring benefits.

As a rule, such tools allow you to graphically describe workflow using BPMN ISO notation, or using JSON, YAML, or DSL based on Java, Golang, etc. An important point: the description of the workflow - this is the real code that is executed in the process.
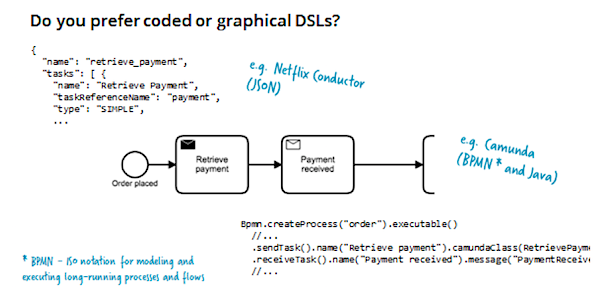
BPMN, and others like it, support quite complex operations: time management, timeouts, business transactions. And yet, this is quite a popular and mature notation, so we can talk about its suitability for solving complex problems.

In the picture above, the workflow instance is waiting for the “Goods Fetched” event ... but the wait time is limited. In the event of a timeout, we roll back the business transaction by performing a special compensating action. In this case, the payment will be returned to the sender - the state machine remembers all previously performed actions, which allows you to perform all the corresponding compensation code. What allows the state machine to manage the business transaction is the idea here is the same as in the Saga pattern .
Graphic notation is also a kind of "live documentation", which has no chance to become obsolete and break away from the real system. What about testing? Some libraries support unit tests, incl. for long-running scenarios. For example, Camunda for each test run generates HTML with a test execution script, which is easy to insert into a regular CI report. In this case, the graphical notation takes on even more meaning:

Workflow live within services
The choice and use of a specific workflow framework should be decentralized, at the discretion of each development team separately. A state machine is implementation details that should not be visible outside the service. There is no need for one and only one global framework for the company. A finite state machine is just a library that simplifies development.
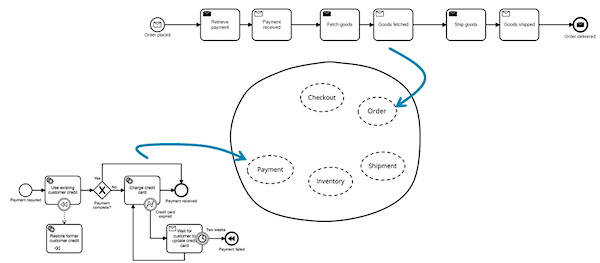
In addition, a finite state machine is part of business logic. Depending on the tool, it can be embedded in the process of your application (for example, using Java, Spring and Camunda), or as a separate process, communicating via the client library ( Zeebe ) or the REST API (Camunda and Netflix Conductor). Having a ready state machine at hand with support for long-running business tasks, you can focus on business logic and API design by implementing a real smart endpoint.
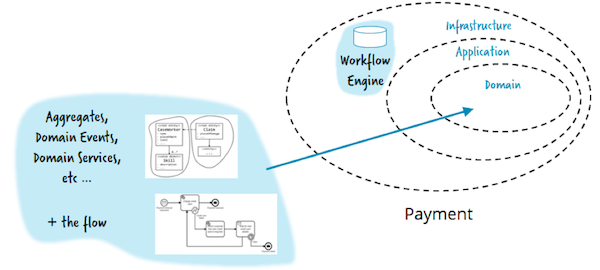
Show the code
Without slipping into a dry theory, the authors of the article wrote a demo application and posted it on GitHub . There are living examples of ideas presented in the article.
Java code using only open source libraries (Spring Boot, Camunda, Apache Kafka).
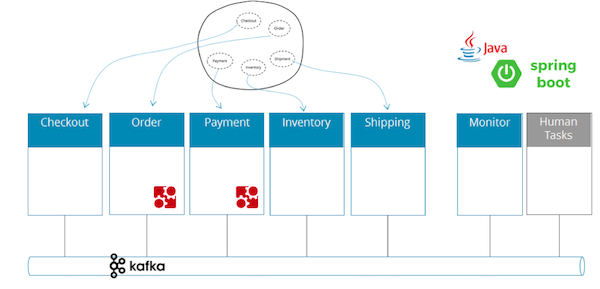
findings
- Do events reduce connectivity? Not always. Events are great for decentralization and end-to-end functionality, but you should not make complex chains of message transfer from service to service. Instead, use teams and services managers.
- Should we avoid centralization? Without fanaticism. Smart ESB does not work well with microservices. Prefer simple transmission channels and smart endpoints. Smart services with business logic inside - prevent the god-like service manager, who has absorbed everything and everyone, from coming to light. Smart service will be able to perform long-running business process.
- Is a workflow engine a pain? Not always. In the past, there was a vendor-lok and attempts to create "zero-code" tools. Now there are lightweight open source frameworks that solve typical problems. Do not cycle the state machines, use ready-made tools.
Bernd Rucker. Participated and trained in a huge number of software development projects related to long-running business processes. Including: in Zalando (international clothes seller) and several telecom companies. Contributor of several open source workflow engines. Author of the book "Real-Life BPMN", co-founder of Camunda.
Martin Schimak. Over 10 years of experience in the energy industry, telecom and ... wind tunnels. Contributor of several projects on GitHub. Speaker at ExploreDDD, O'Reilly Software Architecture Conference and KanDDDinsky. Personal blog plexiti.com . Organizer of mitapov on microservices and DDD (Vienna).
')
Source: https://habr.com/ru/post/346630/
All Articles