Correcting typos with context
I recently needed a library to correct typos. Most open spell-checkers (for example, hunspell) do not take into account the context, and without it, it is difficult to obtain good accuracy. I took Peter Norvig’s spell checker as a basis, screwed a language model (based on N-grams) onto it, sped it up (using the SymSpell approach), overcame a strong memory consumption (via bloom filter and perfect hash) and then designed it all as a library on C ++ with swig bindings for other languages.
Quality metrics
Before writing spellchecker directly, you had to think of a way to measure its quality. Norvig used a ready-made collection of typos for this purpose, which contains a list of misspelled words along with the correct version. But in our case, this method is not suitable due to the lack of context in it. Instead, the first thing to do was write a simple typo generator.
The input error generator takes the word, gives the word at the output with a certain number of errors. Errors are of the following types: replacing one letter with another, inserting a new letter, deleting an existing one, and also rearranging two letters in places. The probabilities of each type of error are adjusted separately; the total probability of a typo is also adjusted (depending on the length of the word) and the probability of a repeated typo.
So far, all the parameters have been chosen intuitively, the probability of error is about 1 in 10 words, the probability of the simplest type of error (replacing one letter with another) is 7 times higher than other types of errors.
This model has many flaws - it does not rely on real-life typo statistics, does not take into account the keyboard layout, and also does not glue or split words. However, for the initial version of it is enough. And in the next versions of the library model will be improved.
Now, having a typo generator, you can drive through any text and get the same text with errors. As a quality metric of a spell checker, you can use the percentage of errors remaining in the text after running it through this spell checker. In addition to this metric, the following were used:
- percentage of corrected words (as opposed to a metric with a percentage of errors — counted only as words that contain errors, and not across the text)
- percentage of broken words (this is when there was no error in the word, but the spell checker decided that it was there, and corrected it)
- Percentage of words for which the correct version was proposed in the list of N candidates (spellcheckers usually offer several correction options)
Peter Norvig Spellchecker
Peter Norvig described a simple spell checker version. For each word, all possible variations are generated (deletes + inserts + replacements + permutations), recursively with a depth of <= 2. The resulting words are checked for presence in the dictionary (hash table), the one that occurs most often is selected among the set of matching options. You can read more about this spell checker in the original article .
The main disadvantages of this spellchecker are a long time (especially on long words), lack of context. We begin with correcting the latter — add a language model and instead of a simple word frequency we will use the estimate returned by the language model.
N-gram based language model
| N-grams - a sequence of n elements. For example, a sequence of sounds, syllables, words or letters. |
The language model is able to answer the question - with what probability this sentence may occur in the language. To date, two approaches are mainly used: models based on N-grams and also based on neural networks . For the first version of the library, the N-gram model was chosen, since it is simpler. However, in the future there are plans to try the neural network model.
The n-gram model works as follows. According to the text used to train the model, we go through a window with a size of N words and count the number of times each combination (n-gram) has been encountered. When requesting a model, we similarly pass through the window according to the proposal and consider the product of the probabilities of all n-grams. We estimate the probability of meeting the n-gram by the number of such n-grams in the training text.
The probability P (w 1 , ..., w m ) to meet the sentence (w 1 , ..., w m ) of m words is approximately equal to the product of all n-grams of size n, of which this sentence consists: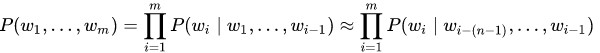
The probability of each n-gram is determined by the number of times that n-gram has been encountered relative to the number of times that the same n-gram has been encountered but without the last word:
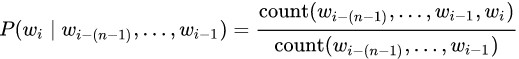
In practice, such a model is not used in its pure form, since it has the following problem. If some n-gram is not met in the training text - the whole sentence will immediately receive a zero probability. To solve this problem, use one of the options smoothing (smoothing). In its simplest form, it is the addition of a unit to the frequency of occurrence of all n-grams, and in a more complicated form, the use of n-grams of a lower order in the absence of n-grams of a higher order.
The most popular smoothing technique is Kneser – Ney smoothing . However, it requires for each n-gram to store additional information, and the gain in comparison with more simple smoothing was not strong (at least in experiments with small models, up to 50 million n-grams). For simplicity, as smoothing, we will consider the probability of each n-gram as the product of n-grams of all orders, for example, for trigrams:
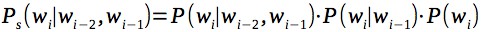
Now that we have a language model, we will choose among candidates for correcting typos for which the language model will give the best grade based on the context. In addition, we will add to the assessment a small penalty for changing the original word to avoid a large number of false positives. Changing this penalty allows you to adjust the percentage of false positives: for example, you can leave the percentage of false positives higher in a text editor, and lower for automatic correction of texts.
Symspell
The next problem with the spellchecker Norvig is the low speed of work for cases when there are no candidates. So, on a 15-letter word, the algorithm works for about a second, such performance is hardly enough for practical use. One of the options for speeding up performance is the SymSpell algorithm , which, according to the authors, works a million times faster. SymSpell works as follows: for each word from the dictionary, deletions are added to a separate index, or rather, all words derived from the original by deleting one or more letters (usually 1 and 2), with reference to the original word. At the time of searching for candidates for the word, similar deletions are made and their presence in the index is checked. This algorithm correctly handles all cases of errors - replacement of letters, permutations, additions and deletions.
For example, consider the replacement (in the example, we will consider only the distance 1). Let the original dictionary contain the word " test ". And we typed the word " temt ". The index will contain all deletions of the word “ test ”, namely: eating , tst , tet , tes . For the word “ tempt ” the deletions will be: emt , tmt , tet , emt . The deletion of “ tet ” is contained in the index, which means that a word with a typo “ tempt ” corresponds to the word “ test ”.
Perfect Hash
The next problem is memory consumption. The model, trained on the text of two million sentences (one million from Wikipedia + one million from news texts) occupied 7 GB of RAM. About half of this volume used the language model (n-grams with a frequency of occurrence) and the other half used the index for SymSpell. With such memory consumption, application usage became not very practical.
I didn’t want to reduce the size of the dictionary, as the quality began to subside markedly. As it turned out, this is not a new problem. Scientific articles offer different ways to solve the problem of memory consumption by the language model. One of the interesting approaches (described in the article Efficient Minimal Perfect Hash Language Models ) is to use perfect hash (or rather, the CHD algorithm) to store information about n-grams. Perfect hash is a hash that does not cause collisions on a fixed data set. In the absence of collisions, there is no need to store keys, since there is no need to compare them. As a result, it is possible to keep in memory an array equal to the number of n-grams in which to store their frequency of occurrence. This gives a very strong saving of memory, since the n-grams themselves take up much more space than their frequency of occurrence.
But there is one problem. When using the model, it will receive n-grams that have never been encountered in the training text. As a result, perfect hash will return a hash of some other existing n-gram. To solve this problem, the authors of the article for each n-gram suggest additionally storing another hash, by which it will be possible to compare whether the n-grams match or not. If the hash is different - this n-gram does not exist and the frequency of occurrence should be considered zero.
For example, we have three n-grams: n1, n2, n3, which met 10, 15, and 3 times, and also n-gram n4, which was not found in the source code:
| n1 | n2 | n3 | n4 | |
| Perfect Hash | one | 0 | 2 | one |
| Second hash | 42 | 13 | 24 | 18 |
| Frequency | ten | 15 | 3 | 0 |
We have got an array in which we store the frequencies of occurrence, as well as an additional hash. Use the perfect-hash value as the array index:
| 15, 13 | 10, 42 | 3, 24 |
Suppose we met n-gram n1. Its perfect-hash is 1, and second-hash 42. We go to the array at index 1, and check the hash that is there. It is the same, meaning the frequency of the n-gram 10. Now consider the n-gram n4. Its perfect hash is also 1, but second hash is 18. This is different from the hash which is at index 1, which means the frequency of occurrence is 0.
In practice, 16-bit CityHash was used as a hash. Of course, the hash does not completely eliminate false positives, but reduces their frequency to one that is not reflected in the final quality metrics.
The frequency of occurrence was also encoded more compactly, from 32-bit numbers to 16-bit, by non-linear quantization . Small numbers corresponded as 1 to 1, larger ones as 1 to 2, 1 to 4, and so on. Quantization again did not affect the resulting metrics.
Most likely, you can pack and hash, and the frequency of occurrence is even stronger - but this is in the next versions. In the current version, the model shrank to 260 MB - more than 10 times, without any quality drawdown.
Bloom filter
In addition to the language model, there was also an index from the SymSpell algorithm, which also occupied a lot of space. He had to think a little longer, since there were no ready-made solutions for it. In scientific articles about the compact representation of the language model, the bloom filter was often used. It seemed that in this task he can help. It was not possible to apply the bloom-filter to the forehead - for each word from the index with deletions we needed references to the original word, and the bloom filter does not allow storing values, only to check the fact of existence. On the other hand, if the bloom filter says that such a deletion is in the index, we can restore the original word for it by performing inserts and checking them in the index. The final adaptation of the SymSpell algorithm is as follows:
We will store all deletions of words from the original dictionary in the bloom-filter. When searching for candidates, we will first make deletions from the source word to the desired depth (similar to SymSpell). But, unlike SymSpell, the next step for each deletion is to insert it, and check the resulting word in the original dictionary. And the index with deletions stored in the bloom-filter will be used to skip inserts for those deletions that are missing in it. In this case, the false alarms are not terrible for us - we will just do a little extra work.
The performance of the resulting solution practically did not slow down, and the memory used was reduced very significantly - up to 140 MB (approximately 25 times). As a result, the total memory size was reduced from 7 GB to 400 MB.
results
The table below shows the results for English text. 300K sentences from Wikipedia and 300K sentences from news texts were used for training (texts are taken here ). The initial sample was divided into 2 parts, 95% was used for training, 5% for evaluation. Results:
| Errors | Top 7 Errors | Fix rate | Top 7 Fix Rate | Broken | Speed (words per second) | |
| JamSpell | 3.25% | 1.27% | 79.53% | 84.10% | 0.64% | 1833 |
| Norvig | 7.62% | 5.00% | 46.58% | 66.51% | 0.69% | 395 |
| Hunspell | 13.10% | 10.33% | 47.52% | 68.56% | 7.14% | 163 |
| Dummy | 13.14% | 13.14% | 0.00% | 0.00% | 0.00% | - |
JamSpell - the resulting spell checker. Dummy - corrector that does nothing, is given in order to understand what percentage of errors in the source text. Norvig is Peter Norvig's spell checker. Hunspell is one of the most popular open-source spell checkers. For the purity of the experiment - the same was checked on the artistic text. Metrics on the text "The Adventures of Sherlock Holmes":
| Errors | Top 7 Errors | Fix rate | Top 7 Fix Rate | Broken | Speed (words per second) | |
| JamSpell | 3.56% | 1.27% | 72.03% | 79.73% | 0.50% | 1764 |
| Norvig | 7.60% | 5.30% | 35.43% | 56.06% | 0.45% | 647 |
| Hunspell | 9.36% | 6.44% | 39.61% | 65.77% | 2.95% | 284 |
| Dummy | 11.16% | 11.16% | 0.00% | 0.00% | 0.00% | - |
JamSpell showed better quality and performance compared to Hunspell and Norvig spellcheckers in both tests, both in the case with one candidate and in the case with the best 7 candidates.
The following table shows the metrics for different languages and for the training sample of different sizes:
| Errors | Top 7 Errors | Fix rate | Top 7 Fix Rate | Broken | Speed | Memory | |
| English (300k wikipedia + 300k news) | 3.25% | 1.27% | 79.53% | 84.10% | 0.64% | 1833 | 86.2 MB |
| Russian (300k wikipedia + 300k news) | 4.69% | 1.57% | 76.77% | 82.13% | 1.07% | 1482 | 138.7 MB |
| Russian (1M wikipedia + 1M news) | 3.76% | 1.22% | 80.56% | 85.47% | 0.71% | 1375 | 341.4 MB |
| German (300k wikipedia + 300k news) | 5.50% | 2.02% | 70.76% | 75.33% | 1.08% | 1559 | 189.2 MB |
| French (300k wikipedia + 300k news) | 3.32% | 1.26% | 76.56% | 81.25% | 0.76% | 1543 | 83.9 MB |
Results
The result was a high-quality and fast spell-checker, which surpasses similar open solutions. Examples of use are text editors, instant messengers, preprocessing of dirty text in machine learning tasks, etc.
Sources are available on github , under the MIT license. The library is written in C ++, binders for other languages are available via swig. Example of use in python:
import jamspell corrector = jamspell.TSpellCorrector() corrector.LoadLangModel('model_en.bin') corrector.FixFragment('I am the begt spell cherken!') # u'I am the best spell checker!' corrector.GetCandidates(['i', 'am', 'the', 'begt', 'spell', 'cherken'], 3) # (u'best', u'beat', u'belt', u'bet', u'bent', ... ) corrector.GetCandidates(['i', 'am', 'the', 'begt', 'spell', 'cherken'], 5) # (u'checker', u'chicken', u'checked', u'wherein', u'coherent', ...)</td> Further improvements - improving the quality of the language model, reducing memory consumption, adding the ability to handle gluing and splitting words, support features of different languages. If someone wants to participate in improving the library - I will be glad to your pull-requests.
Links
- JamSpell sources: github.com/bakwc/JamSpell
- How to Write a Spelling Corrector, Peter Norvig : norvig.com/spell-correct.html
- Hunspell: github.com/hunspell/hunspell
- Language Modeling with N-grams, Daniel Jurafsky & James H. Martin : web.stanford.edu/~jurafsky/slp3/4.pdf
- Understanding LSTM Networks, Christopher Olah : colah.imtqy.com/posts/2015-08-Understanding-LSTMs/
- N-GRAM LANGUAGE MODELING USING RECURRENT NEURAL NETWORK ESTIMATION, Google Tech Report, Ciprian Chelba, Mohammad Norouzi, Samy Bengio : static.googleusercontent.com/media/research.google.com/ru/pubs/archive/46183.pdf
- Anonymous and Stanley F. Chen and Joshua Goodman : u.cs.biu.ac.il/~yogo/courses/mt2013/papers/cs/courses/mt2013/papers/school/99-pod
- 1000x Faster Spelling Correction algorithm, Wolf Garbe : blog.faroo.com/2012/06/07/improved-edit-distance-based-spelling-correction/
- Efficient Minimal Perfect Hash Language Models, David Guthrie, Mark Hepple, Wei Liu : www.lrec-conf.org/proceedings/lrec2010/pdf/860_Paper.pdf
- Perfect hash function, wikipedia : en.wikipedia.org/wiki/Perfect_hash_function
- Hash, displace, and compress. Djamal Belazzougui1, Fabiano C. Botelho, Martin Dietzfelbinger : cmph.sourceforge.net/papers/esa09.pdf
- Bloom Filter, habrahabr : habrahabr.ru/post/112069/
- Leipzig Corpora Collection: wortschatz.uni-leipzig.de/en/download/
')
Source: https://habr.com/ru/post/346618/
All Articles