Basics of lossy audio coding. Testing Opus 1.3 Beta
0. About the author
Hello everyone, my name is Maxim Logvinov and I am a student of Kharkov National University of Radio Electronics.
I was always interested in sound and music. I myself liked to write electronic dance music and I was always interested as a person who is not well versed in the high matters of mathematics, to find out what happens to sound in a computer: how it is written, compressed, what technologies exist for this, and so on. After all, from school and physics, I understood that sound is “analog”: it is not enough to convert it to digital (which requires devices such as ADCs), but it must somehow be preserved. Better yet, this music takes up less disk space so that you can put more music into the mean folder. And that sounded good, without any audible compression artifacts. Musician after all. A trained ear that is not devoid of a musical ear is difficult to deceive using methods that are used to compress sound with losses, at least at fairly low bit rates. Oh, how fastidious.
')
And let's see what sound is, how it is encoded, and what tools are used for this encoding itself. Moreover, let's experiment with the bitrates of one of the most advanced codecs to date - Opus and evaluate what you can encode with which digits to eat the fish, and ... Actually, just why not? Why not try to describe in simple language not only how computer audio is stored and encoded, but also to test one of the best codecs today? Especially, if we are talking about ultra-low bitrates, where almost all existing codecs are starting to create incredible things with sound in an attempt to meet the small file size. If you want to escape from the routine and find out what conclusions were obtained when testing the new codec - welcome under the cat.
1. Audio encoding
The sound has a physical nature. Any sound is a vibration in space (in this case, in the air), which is captured by our ear. Oscillations are continuous, which can be described by mathematical models. Of course, we will not do this, but we will ask ourselves the question: how are vibrations of a continuous nature recorded in a machine that operates only with zeros and ones?
1.1. No compression, no loss
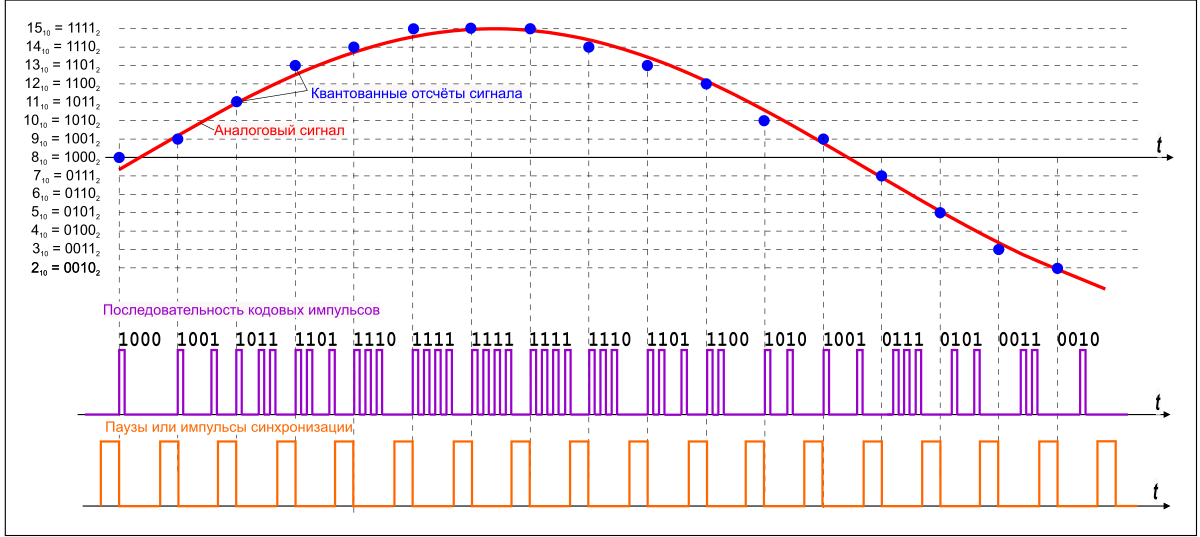
Fig. 1.1 - Graphic description of pulse code modulation
The WAV (WAVE) format saves the audio track in its true quality, without performing any manipulations with the audio file itself.
In order to record the sound, we need to convert it to a set of zeros and ones. In the case of the WAV format, this is done in the most stupid way: the incoming audio stream is divided into the smallest segments (quanta, hence the terms "quantization frequency", "sampling frequency" or " sampling frequency ") and the current value of the analog signal is written in binary to each such time interval form. WAV files can be recorded at a sampling rate, for example, from 8 kHz to 192 kHz, but, de facto, the sampling rate of 44.1 kHz is considered the standard.
It should be noted that WAV, as a container, supports other ways of storing audio information: for example, ADPCM , which is capable, depending on bandwidth, to encode audio data with a variable sampling rate.
The frequency of 44.1 kHz did not happen by chance. If you allow inaccuracies in the description, this figure occurred as a statement of Kotelnikov 's theorem: to maintain the most correct waveform at frequencies up to 20 kHz (theoretical limit of hearing of the human ear), the sampling rate is twice as high - 40 kHz. Actually, the frequency of 44.1 kHz is due to technical aspects, the details of which can be found here .
In each such segment, the actual voltage of the analog signal is encoded in binary form: the highest level can be represented as “1111”, the lowest - as “0000”. And here comes the second parameter - the depth of sound, which determines how accurately the wave value will be digitized in the interval of time. Often, WAV format files are written with a resolution of 16 bits or 32 bits. Higher digit capacity - more precisely record.
Speaking of PCM. What is the record on an ordinary CD that was so popular after audio cassettes? That is - a stream of uncompressed zeros and ones in PCM format. The bit width is 16 bits, the sampling rate is 44.1 kHz. What then will the bitrate of such a record?
- 44,100 times a second is written a 16-bit number. 44100 * 16 = 705600 bps for one channel;
- for stereo recording, this value is multiplied by 2 - 1411200 bps or ours ~ 1411 kbps;
- for 32-bit recording, this value will be twice as large - ~ 2822 kbps.
Conclusion: hence the gluttony of these files to the free space on the hard disk, but as a win there is a complete lack of loss when recording and listening to the audio file.
1.2. Lossless compression
On lossless compression, I will not write much. This term can be found here . In fact, this method is, to put it bluntly, the archiving of audio recordings by algorithms embedded in the codec, but the data are not lost and the possibility to restore audio recording with bit-to-bit accuracy is preserved. When decoding such formats, we get, in fact, the same WAVE format, only it takes up less disk space; Compression is approximately twofold and depends on the nature of the coded composition. When listening to a recording, the codec "unarchives" the composition and sends a stream of uncompressed zeros and ones to the sound card processing.
There are quite a lot of such codecs: these are FLAC (Free Lossless Audio Codec), developed by Xiph (it also developed Opus), ALAC (Apple Lossless) from the company of the same name, APE (Monkey's audio), WV (WavPack) and other, less well-known lossless audio compression formats.
1.3. Compression with losses - deceive your ears
Scientists' minds began to think that, in principle, it often does not make sense to keep complete information about the recording, since our ear is imperfect. It may not hear low sounds after loud sounds, it may not hear too high or too low frequencies, and so on. These phenomena are called the disguise effect.
As a result, they understood: you can throw it away here , prune there , and the listener will notice almost nothing - an imperfect ear will simply enable the listener to deceive himself. Therefore, it is possible to get rid of psychoacoustic redundancy in the file.
Actually, psychoacoustics exists as a discipline and studies the psychological and physiological characteristics of human perception of sounds. Actually, these psychoacoustic models were the basis for the work of lossy compression programs and MPEG 1 Layer III or just MP3 was one of the first such formats. I also make a reservation that marketing, which operates with facts almost without exaggeration, did its job: the audio file takes up ten times less space (with the proviso: this is when encoding with a bitrate of 128 kbps, which allows to get “acceptable quality for a typical listener “- we remember 1411 kbps for WAVE), and, therefore, on the CD or on the hard disk will fit an order of magnitude more audio recordings. Furor! The popularity of the format has blown up the digital recording industry. During periods of not the fastest connections to the Internet, it became very convenient to transfer such files. Convenient to transfer, convenient to store, convenient to throw a pack of songs on your player. Created many hardware decoders format MP3, in connection with which the file was played almost on the
At the time of this writing, patent restrictions have expired and licensing fees have been terminated.
As for lossy compression, and how is it possible to compress an audio file by an order of magnitude without significant loss for the listener of quality? In short, from one codec to another, the following sequence is slightly different. The description of this process is simplified to disgrace, but its flow is approximately as follows:
- the incoming stream of uncompressed data is divided into equal segments - into frames (frames);
- in order to create a continuous part of the spectrum, for analysis, in addition to the already selected frame, the previous and next frame is taken;
- Compression # 1: The region passes through MDCT (Modified Discrete Cosine Transform). Roughly speaking, this transformation carries out a spectral analysis of the sound signal - it gives you the opportunity to get information about how great the sound energy is in each segment of the spectrum.
In the case of Layer III, the second MDCT transform is performed, which improves the coding efficiency of the high frequencies at lower bitrates - this turned out to be a silver bullet for blasting the popularity of this codec.Thanks to the user interrupt for the correction : MPEG 1 Layer III uses a hybrid approach to convert audio data: first, the spectrum of the encoded audio file is divided into multiple spectral bands, as happens in SBC (Sub-band coding, Eng. ); Each of these bands is converted by the MDCT to a frequency mode, which, in fact, already gives specific information about which frequencies and with what energy are present in the frame. - The result of the MDCT analysis is transmitted to the psychoacoustic model, which is something like a “virtual ear”. At this stage, answers are given to the questions of what to leave and what can be thrown out of the audio signal without significant damage to perception.
- Compression # 2: a frame that went through such a transformation can be compressed using Huffman codes; in fact, if you talk rudely again, each frame is additionally archived, eliminating redundancy. It looks like something like wrapping long chains of zeros and ones in a shorter format;
- frames are glued together; In each such frame, the necessary information for the codec is added:
- frame number / size;
- format version (MPEG1 / 2 / 2.5);
- layer version (Layer I / II / III);
- sampling frequency;
- Stereo-base mode (mono, stereo, combined stereo).
It should be noted the fact that the MP3 format is not without significant flaws, while the format itself does not allow to properly expand its capabilities. Take, for example, the phenomenon of pre-echo . The phenomenon of this compression artifact is briefly and fairly well described here , but its essence lies in the distortion of sharply increasing sounds, such as Hi Hat, for silence. When coding such a tool in silence, due to the peculiarities of the MDCT, a sharp transition will be created with a lot of vibrations. In the original recording, these oscillations do not exist, but if they exist in the resulting recording, they are quite clearly captured by the ear. Modern codecs such as AAC and OGG are also not without this drawback, but they try to deal with them using more accurate and sophisticated algorithms. But MusePack (about it below), for example, is deprived of this disadvantage, since itdoes not use the second MDCT-conversion to increase efficiencyusing SBC along with a very high-quality psychoacoustic model, which explains its high-quality coding only starting from bitrates of 160 kbit / with. Rarely, but aptly: with such a bit rate, the codec encodes audio better than MP3 with the same bit rate.
It should be noted that the developers of the free Lame codec are still trying to improve their offspring, improving psychoacoustic models and coding algorithms with variable bitrate; Release version 3.100 is presented in December 2017.
Detailed information on how the MP3 is arranged in terms of frame format can be found here .
But an amazing article (and, more precisely, its translation) on how MP3 audio codec compression works can be found here . Recommend!
1.4. Loss coding improved: a brief description of the AAC format
At the time of this writing, the MP3 codec is more than 23 years old. In order not to repeat with the article ( its newer version ), where OGG Vorbis codecs are described (and hello again to the Xiph organization is also its development), MPC (Musepack), WMA (Windows Media Audio) and AAC, I will describe here briefly the format AAC in terms of technologies that were until recently advanced in the field of lossy coding.
In my humble opinion, AAC (Advanced Audio Codec) is one of the most advanced formats in the field of data coding. I will describe the main features of this format, starting with the popular profiles that can be represented as a doll (see figure below):
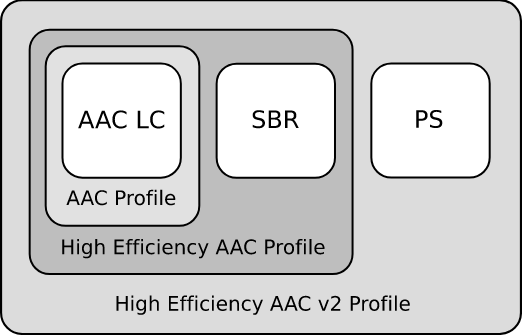
Fig. 1.2 - Hierarchy of AAC profiles, source - Wikipedia
- Low Complexity Advanced Audio Coding (LC-AAC)
Low decoding complexity is great for implementing a hardware codec; hardware requirements for the CPU and RAM are also low, which has gained great popularity for this profile. Enough effectively encodes a signal with 96 kbps.
- High-Efficiency Advanced Audio Coding (HE-AAC).
The HE-AAC profile is an extension of LC-AAC and is supplemented with the patented SBR technology (Spectral Band Replication, coarse. - “spectral repetition”, an article in English ). It is the technology of spectral repetition that allows you to "save" high frequencies when encoding with low bitrates.

Fig. 1.3 - Graphic representation of the principle of high frequency recovery
Why "save" - in quotes? Because the king is not real: the codec allocates space for additional information, which is used by the codec synthesizer to restore high frequencies, but since these frequencies are synthesized, that is, they are recreated by the codec, they are, in fact, an approximate copy of the high frequencies that existed in the source file . In practice, a signal encoded at 48 kbps will sound, for example, in the same way as mp3 @ 98 kbps if supported by the decoder; otherwise, such a file will be played simply without the restoration of high frequencies and its bitrate will correspond to its quality, similar to mp3.
- High-Efficiency Advanced Audio Coding Version 2 (HE-AACv2)
This profile is relatively young (described in 2006), it was created to more efficiently encode audio in low bandwidth conditions.
The second version of the profile is an extension of the first profile, the changes consist in the addition of the PS technology (Parametric Stereo). The principle is somewhat similar to SBR technology: the codec also allocates space for information to restore the stereo base, sacrificing accuracy.

Fig. 1.4 - Graphic image coding parametric stereo
The operating conditions for this profile are the same as for the HE-AAC described above; the lack of support for the profile by the decoder will cause the recording to sound in mono.
- AAC-LD (Advanced Audio Coding - Low Delay)
The AAC-LD profile has advanced coding algorithms for reducing delays (up to 20 ms);
- AAC-ELD (Advanced Audio Coding - Enhanced Low Delay)
This profile, which inherits all the capabilities of HE-AACv2 (uses analogues of SBR and PS technologies, but designed for low latency);
- AAC Main Profile
This profile was presented as MPEG-2 AAC or HC-AAC (High Complexity Advanced Audio Coding). Not compatible with LC-AAC;
- AAC-LTP (Advanced Audio Coding - Long Term Prediction)
This profile is more complex and resource-intensive (but better) than all the others. Also not compatible with LC-AAC.
That's all I wanted to write about this codec. I focused on the technologies that are used in various AAC profiles (which, by the way, generate a lot of abbreviations: AAC, LC-AAC, eAAC +, aacPlus, HE-AAC, etc.), as I will compare them with those in Opus, but the codec does its job: it is widely used in Internet radio, as well as in digital radio broadcasting technologies: DRM (Digital Radio Mondiale) and DAB (Digital Audio Broadcasting) (you can familiarize yourself with these technologies here ), YouTube, as audio track to a variety of videos in mp4 containers, mkv, etc.
2. Introduction to Opus: format description

Fig. 2.1 - Opus Logo
On December 21, 2017, Xiph introduced the beta version of the Opus audio codec version 1.3. I will not go into high matters when describing this codec, since such information is freely available (for example, here , here , and for those who know English - here and here .)). Information on the release of this beta version can be found here . Here I note that this codec is a great candidate for replacing the rest of the codecs. He has many advantages:
- bit rate from 6 to 510 Kbit / s;
- sampling frequency from 8 to 48KHz;
- support for constant (CBR) and variable (VBR) bit rates;
- support narrowband and wideband sound;
- voice and music support;
- stereo and mono support;
- support for variable bit rate (VBR);
- the ability to restore the audio stream in case of frame loss (PLC);
- support up to 255 channels;
- availability of implementations using floating-point and fixed-point arithmetic.
The codec is distributed under the BSD license and is completely free from all patent prosecutions, and also approved as an Internet standard. Opus can be used in any of its projects, including commercial ones, without the need to open source. At the moment, the codec is used in the Telegram messenger for VoIP implementation, in the WebRTC project, for encoding the audio track in YouTube videos, etc. The prospects of this codec should not be underestimated.
A reasonable question may arise: what is so special about the theses described above? All this is in almost any more or less modern codec. The answers will follow later in the article.
One of the key features of this codec is extremely low coding delays: from 2.5 ms. (!) up to 60 ms, which is simply necessary, like air, for applications that allow users to communicate with voice over the Internet. Such low latency also allows you to build interactive applications, for example, a digital sound studio for writing music together or something like that. It is worth noting that in this parameter the codec competes with the relatively new AAC-ELD profile described above; however, the minimum latency of the coding algorithms is approx. 20 ms, which is hardly a problem for the free, open and free codec Opus.
I will not consider all the subtleties associated with encoding audio by this codec, but I will describe below the modes that vary by codec depending on the bitrate change.
2.1. Opus: coding modes
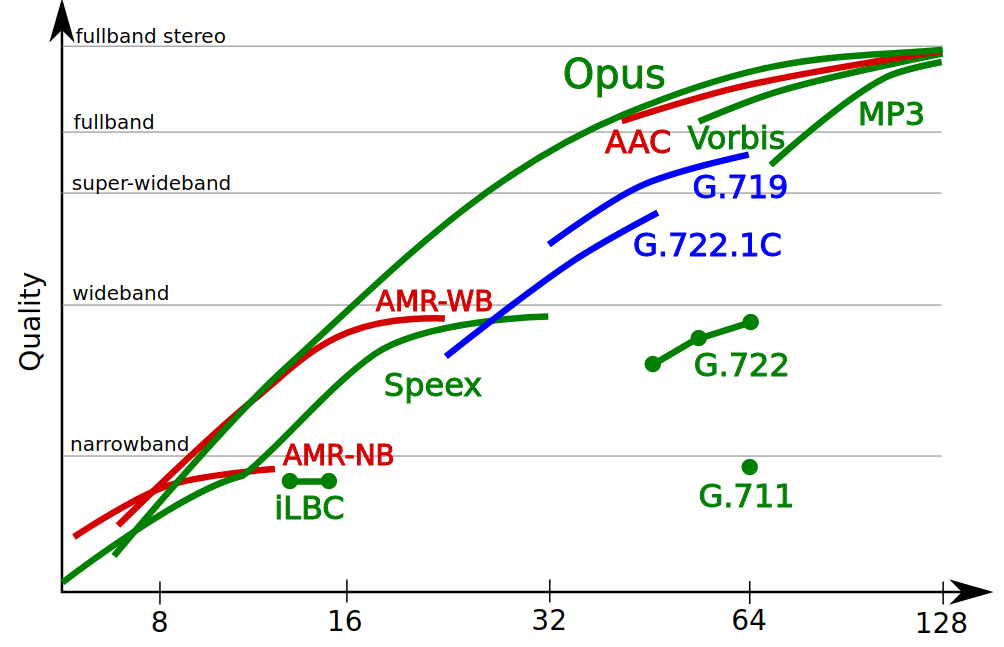
Fig. 2.2 - Comparison of coding quality by different codecs - the official schedule from the site opus-codec.org
After the release of this beta version, I wondered how the encoding modes changed depending on the bitrate, so I decided to conduct experiments, starting with the lowest bitrates, but only with them. I don’t see any point in conducting experiments with higher bitrates - it is perfectly described in articles (for example, here ).
Now we will list those modes with which the codec operates:
- Signal coding mode - LP, hybrid, MDCT:
- LPC or LP (coding with linear prediction, an article in English ) is used in voice compression codecs and allows you to encode a voice with sufficient quality for perception, using very low bit rates. Used in GSM , AMR , SILK codecs (also used in Skype), Speex (and hello again Xiph; however, she declared the codec as “deprecated” and recommends using Opus). The Opus codec uses a modified SILK codec to encode voice at low bit rates, which is not backward compatible with Skype;
- MDCT (Modified Discrete Cosine Transformation) is a kind of Fourier transform (you can read about it here ), it is used in almost all codecs to compress lossy compression music: MP3, AAC, OGG Vorbis, etc. The Opus codec uses the CELT codec ( English article );
- Hybrid mode (hybrid coding mode) is developed by Xiph and consists of using LP for coding the lower part of the signal spectrum (up to 8 kHz) and MDCT for the upper part (from 8 kHz and above) and a compromise quality at the output sound while maintaining a fairly low bitrate.
- Stereo base:
- mono encoding;
- stereo encoding;
- coding in the mode of combined stereo ( Joint Stereo ).
- Based on the above - changing the width of the spectrum depending on the bitrate:
- Narrowband (narrowband coding) - coding of a signal with a spectrum width of up to 6 kHz, corresponds to the coding quality by GSM and AMR-NB codecs;
- Wideband (wideband coding) - coding of a signal with a bandwidth from 6 kHz to 14 kHz, corresponds to the coding quality of the AMR-WB codec (or the so-called “ HD Voice ” operators), which is now used in third-generation networks ( 3G );
- Fullband (full band coding) - preservation of the entire audible human ear band (from 20 Hz to 20 kHz), mono signal;
- Fullband stereo - see above, but stereo.
2.2. Low bit rates - high frequencies. How are such results achieved?
At the beginning of this article, I knowingly considered the AAC codec and its heaped profiles, which, in fact, build a stereo base and restore high frequencies, which is called “out of thin air”. I exaggerate, of course, but the expression is not far from the truth. But the trouble is that the codec is covered by patents and is a proprietary development of the alliance from Bell Labs , the Fraunhofer Institute for Integrated Circuits (which, by the way, is the key creator of MP3), Dolby Laboratories , etc. Therefore, the use of these technologies will require license fees, which is unacceptable for a fully open and free codec. Therefore, the developers of Opus went a different way: they implemented their own high-frequency reproduction algorithms - Band Folding (Spectral Folding, Hybrid Folding). About this approach of coding of high frequencies can be found, respectively, here (there are even interactive pictures there), here (see 4.4.1) and here . The codec does not synthesize high frequencies from the additional data, as HE-AACv2 does, it takes as a basis the signal itself, based on the energy in the high-frequency region encoded in the original signal. Blind testing by enthusiasts shows that this method is very effective, not to mention that such a method of reproducing high frequencies, according to the developers, is simpler to perform than SBR or its equivalent and can be implemented with lower algorithmic delays.
By the way: the results of blind testing can be viewed on the graphs at the following link .
Let us experience this last word in the field of lossy compression of sound.
2.3. Opus: coding and testing tools
This test was conducted on a short excerpt from the Vadim Zelanda audiobook - Transurfing of reality. The book was voiced by the Russian actor and radio host Mikhail Chernyak , who has a pleasant timbre of his voice.
How was the passage obtained?
- The youtube-dl utility downloaded a fragment of a WebM format file — a container in which only the audio track is present:
youtube-dl "https://www.youtube.com/watch?v=_-OUXW3a0Yw" -f 250 - The fragment was recoded into WAV format for feeding to the opusenc codec (the source file was renamed for convenience):
ffmpeg -i tr1_original.webm -acodec pcm_s16le tr1.wav - In order not to bother with encoding a set of files with different bitrates, I used a simple one-line program in the Bash language and got a lot of files I needed:
for i in `seq 8 21`; do opusenc --bitrate $i tr1.wav tr-enc-${i}.opus ; done - All these files were imported into Audacity and into the Qmmp player in order to evaluate the sound quality by ear and to visually evaluate the corresponding track.
Fig. 2.3 - Script execution result - Dolphin screenshot
Next will be a description of almost each of them - with the application of screenshots and a subjective description of the sound, followed by small conclusions.
3. Evaluation of the sound of coded tracks
In a good way, the evaluation of the sound should be objective and be carried out, for example, using the blind ABX-testing method ( English article ). Testing is carried out in order to eliminate the effect of the pacifier (placebo) .
In short, the essence of the method is to listen with the help of auxiliary software (Foobar or similar web application, see note in Fig. 3.1) of two samples: reference and compressed - buttons A and B, respectively. The listener does not know in advance which of them is compressed and which of them is reference.
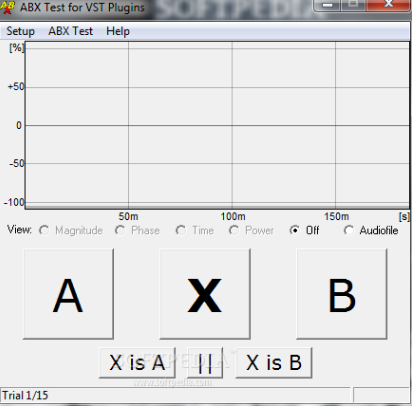
Fig. 3.1 - An example of the appearance of one of the programs of blind ABX-testing
Next, the listener listens to the audio recording, substituted by the program under the X button and tries to determine: which of the two samples (A or B) is the sample on the X button. After the listener chooses the answer, the cycle is repeated a certain number of times, after which the program displays the result, where shown, what probability did the listener press the buttons randomly.
It is worth making a reservation that there are people who do not perceive the effects of psychoacoustic compression and, in fact, cannot distinguish, for example, the recording of mp3 @ 128 kbps from FLAC - for them both files sound “wonderful”. There are a lot of such people and for them 128 kbps is a completely transparent sound, as they do not think about what kind of artifacts are there and how they sound. Is there music? Tools are heard? Fine. This is another reason for the high popularity of the MP3 format.
In principle, I did not conduct blind ABX testing, but I wanted to describe the subjective perception of sound with the screenshots of the spectrogram screen of each sample in the hope that it would be interesting for the readers of this article.
Go.
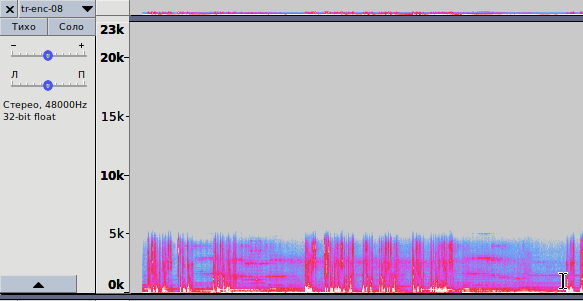
Fig. 3.2 - Spectrogram of the recording, encoded with a bitrate of 8 kbps
opus-enc-8.opus
1. In fig. 3.2 shows a spectrogram for encoding with practically the lowest bitrate. The audio file is encoded by the LP method, the codec assigns a frequency spectrum of 6 kHz; Anything higher is clipped. As a result, the file size is extremely small, the sound quality corresponds to that with the AMR-NB (Narrowband) codec. The classic of the genre in cellular networks of the second generation (GSM). The behavior of the Opus codec corresponds to the above in the range of bit rates from 6 to 9 kbps.
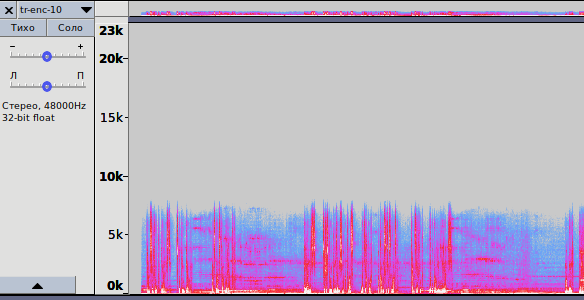
Fig. 3.3 - Spectrogram of the recording, encoded with a bit rate of 10 kbps
opus-enc-10.opus
2. In fig. 3.3 shows a spectrogram for encoding with a bit rate of 10 kbps. The same situation: coding method LP, but the frequency spectrum is already wider - up to 8 kHz. The sound is average between AMR-NB and AMR-WB.

Fig. 3.4 - Spectrogram of recordings encoded with bitrates of 12 and 13 kbps
opus-enc-12.opus
opus-enc-13.opus
3. In fig. 3.4 shows two spectrograms: for bit rates of 12 and 13 kbit / s, respectively. Here the situation is more interesting: at 12 kbps, the same LP is used, but the width of the spectrum is expanded even more: to 10 kHz and the sound is almost identical to that in AMR-WB.
Starting with a bit rate of 13 kbps, the codec switches to the hybrid mode and starts using three methods at once: LP, MDCT and Band Folding. All that lies in the range from 0 to 8 kHz, LP is encoded, from 8 to 10 kHz - MDCT; it is this segment of the 2 kHz spectrum that is used as the initial information for using Band Folding - from here we get the actually restored high frequencies, up to 20 kHz.
Clearly visible “strokes” along the record, starting with 10 kHz; visible attempt codec to keep maximum information about high frequencies. Interestingly, even at 13 kbps. the codec in the hybrid mode, using Hybrid Folding, tries to work in Fullband mode, restoring the spectrum up to 20 kHz.
What about the sound? The sound of the voice is simply Fantastic — with a capital F. It’s even that HE-AAC with its SBR isn’t capable of such a result — it’s not even close. High frequencies, in the region of which there are sizzling, whistling, clicking (S, S, S, C) sounds are reproduced amazingly, it is pleasant to listen to human speech. We don’t forget about the “13 kbps” figure, but GSM codecs (AMR-NB) used to work with such a bit rate, where you really don’t know where is, and where is »...
However, one should not forget that such a mode is still poorly suited for encoding music: due to the LP coding, there are significant distortions in the LP region, especially in the transition region, where there is no voice, but the corresponding area FX effect of “atmospheric rusty squeak”.

Fig. 3.5 - Spectrogram of recordings encoded with bitrates of 14 and 15 kbps
opus-enc-14.opus
opus-enc-15.opus

Fig. 3.6 - Pay attention to the selected area of the FX effect
4. In Figure 3.5, you can see how the coding method of the signal changes from a transition to a higher bit rate - from 14 to 15 kbit / s. As long as the recording spectrogram for a bit rate of 14 kbps is similar to the one described above with 13 kbps, then starting with a bitrate of 15 kbps, the use of the hybrid mode stops and the codec relies entirely on MDCT and Band Folding.
Why did I decide that? Because when listening to recordings in the FX effects area, all the distortions that are inherent in LP disappear. And if you look at the spectrogram of both records (see also Fig. 3.6), then you can see that the accuracy of the reproduction of the spectrum is increased. However, the characteristic “smear”, dividing the spectrum in half, in the region of 10 kHz, can be seen in both cases.
This is exactly the case when the quality here is comparable to that of mp3 @ 80 kbps, if not higher. Again, I do not have the right to make my judgments the ultimate truth, since I did not conduct blind ABX testing.
5. Starting with a bit rate of 18 kbps ( opus-enc-18.opus ), the latter becomes enough to switch to Fullband Stereo mode, which means that at this bitrate you can get “acceptable” recording quality under very low bandwidth network. No, this is not a fiasco, bro, this is a victory!
Further, everything is quite simple: proportionally, with an increase in bitrate, the codec is using Band Folding less and less often, since the actual bitrate becomes sufficient to encode higher frequencies without the need for artificially restoring them. The higher the bitrate, the wider the spectrum will be encoded without the use of Band Folding.
4. Instead of conclusion
As for me, that “threshold of transparency” (or “Transparency”, as the English speakers call it), which is expressed in my inability to distinguish the original from the compressed analogue - approx. 170 kbps For mp3, this parameter is within 224-256 kbps, depending on the nature of the music.
What can I say. Technology is developing rapidly. And not only audio data compression technologies - I’m not afraid to summarize all the technologies. It is especially pleasant that such high-quality technologies, which allow to deceive the human ear so qualitatively and allow it to be so universal, also develop and remain free and open. Thanks to the developers and those amazing people who are creating and moving progress. And also thank you all for your attention and everyone who has mastered the article to the end.
PS: The article will be edited upon detection of significant inaccuracies; syntax and semantic errors will be corrected.
PPS: Link to my own article written using the telegra.ph service . It was not published anywhere, is my author's work (the author can be checked) and is an older version of the current article.
Source: https://habr.com/ru/post/346532/
All Articles